Google DeepMindは2026年3月3日、正式にGemini 3.1 Flash-Lite Previewをリリースしました。これはGemini 3シリーズの中で最速かつ最低コストのモデルです。Gemini 3 Proアーキテクチャをベースにしており、出力速度は約380 tokens/sに達し、Gemini 2.5 Flashと比較して初トークン応答が2.5倍速く、出力速度は45%向上しています。
本記事の価値: この記事では、性能ベンチマーク、コスト比較、機能特性、適用シナリオ、API接続の5つの観点から、この新登場の軽量モデルを包括的に理解し、あなたのビジネスシナリオに適しているかどうかを判断するお手伝いをします。

Gemini 3.1 Flash-Lite Preview コアパラメータ概要
以下は、Google AI公式ドキュメントとDeepMindモデルカードから抽出したコア技術パラメータです。
| パラメータ項目 | Gemini 3.1 Flash-Lite Preview | 説明 |
|---|---|---|
| モデルID | gemini-3.1-flash-lite-preview |
API呼び出し時に使用するID |
| アーキテクチャ基盤 | Gemini 3 Pro | Proレベルのマルチモーダルアーキテクチャを継承 |
| コンテキストウィンドウ | 1,048,576 tokens (1M) | 約1,500ページのA4文書相当 |
| 最大出力 | 65,536 tokens (64K) | 長文生成をサポート |
| 出力速度 | ~380 tokens/s | 132モデル中2位の速度 |
| 入力価格 | $0.25 / 100万トークン | Gemini 3シリーズで最低 |
| 出力価格 | $1.50 / 100万トークン | Pro版の1/8の価格 |
| 知識カットオフ | 2025年1月 | Gemini 3 Proと一致 |
| ステータス | Preview | プレビュー版、正式版は未リリース |
注目すべきは、Gemini 3.1 Flash-Lite PreviewがGemini 3 Proアーキテクチャを基に構築されている点です。これは、「縮小版」のサイズでありながらProレベルのマルチモーダル理解能力を保持していることを意味します。Googleはこれを「高頻度・軽量タスク」の優先モデルとして位置づけています。
🎯 接続アドバイス: Gemini 3.1 Flash-Lite Previewは既にAPIYI (apiyi.com) で利用可能で、価格はGoogle公式と同一です。100米ドル以上のチャージで10米ドルボーナス、最低20%オフの割引が適用され、400以上の大規模言語モデルをワンストップで利用できます。
Gemini 3.1 Flash-Lite Preview 5つのコアアドバンテージ
アドバンテージ 1: 超高速推論——380 tok/sの出力速度
Gemini 3.1 Flash-Lite Previewの出力速度は約380 tokens/sに達し、Artificial Analysisの評価データによると、132の主要モデル中で2位にランクインしています。前世代のGemini 2.5 Flashの249 tok/sと比較して、性能は約45%向上しています。
初回トークン応答時間 (TTFT) の面ではさらに目覚ましく、Gemini 2.5 Flashよりも2.5倍高速です。チャットボットやリアルタイム翻訳など、即時フィードバックが必要なアプリケーションシナリオにおいて、この向上は非常に重要です。
アドバンテージ 2: 超低コスト——入力はわずか$0.25/M tokens
Gemini 3シリーズの中で、Flash-Liteの価格はProバージョンのわずか1/8です。具体的には以下の通りです:
| モデル | 入力価格 | 出力価格 | 混合レート (3:1) |
|---|---|---|---|
| Gemini 3.1 Flash-Lite | $0.25/M | $1.50/M | $0.56/M |
| Gemini 3 Pro | $2.00/M | $12.00/M | $4.50/M |
| Claude 4.5 Haiku | $1.00/M | $5.00/M | $2.00/M |
| GPT-5 mini | $0.15/M | $0.60/M | $0.26/M |
Flash-Liteは、価格と性能の間で優れたバランスを実現しています。絶対的に最も安価ではありませんが、380 tok/sの出力速度と1Mトークンのコンテキストウィンドウを考慮すると、コストパフォーマンスは非常に高いと言えます。
アドバンテージ 3: 100万トークン級のコンテキストウィンドウ
1,048,576トークンのコンテキストウィンドウは、単一リクエストで以下の処理が可能であることを意味します:
- 約1,500ページのA4文書
- 完全なコードリポジトリ
- 数時間に及ぶオーディオ/ビデオコンテンツ
これは軽量モデルにおいては非常に珍しい構成です。比較すると、GPT-5 miniは128K、Claude 4.5 Haikuは200Kしかサポートしていません。
アドバンテージ 4: 全モーダル入力サポート
軽量モデルとして位置づけられているにもかかわらず、Gemini 3.1 Flash-Lite Previewは5種類の入力モードをサポートしています:
- テキスト: コア能力
- 画像: 画像コンテンツの分析と理解
- 音声: 音声文字起こしと分析
- ビデオ: ビデオコンテンツの理解
- PDF: ドキュメント解析と要約
出力はテキストのみですが、ほとんどのデータ処理・分析タスクにおいてはこれで十分です。
アドバンテージ 5: Thinking Mode(拡張思考モード)のサポート
軽量モデルでありながら、Gemini 3.1 Flash-Lite PreviewはThinking Mode(拡張思考モード)をサポートしており、これは同クラスのモデルではほぼ唯一無二の特徴です。有効にすると、モデルは段階的に推論を行い、科学知識や数学計算などのタスクで精度が大幅に向上します。
🎯 プラットフォーム推奨: Gemini 3.1 Flash-Lite PreviewのThinking Modeのパフォーマンスを素早くテストしたいですか?APIYI apiyi.com を通じて直接呼び出すことができ、400以上の主要大規模言語モデルに対応した統一インターフェースを提供しています。
Gemini 3.1 Flash-Lite Preview ベンチマークデータ
以下はGoogle DeepMindのモデルカードとArtificial Analysisからの評価データです:
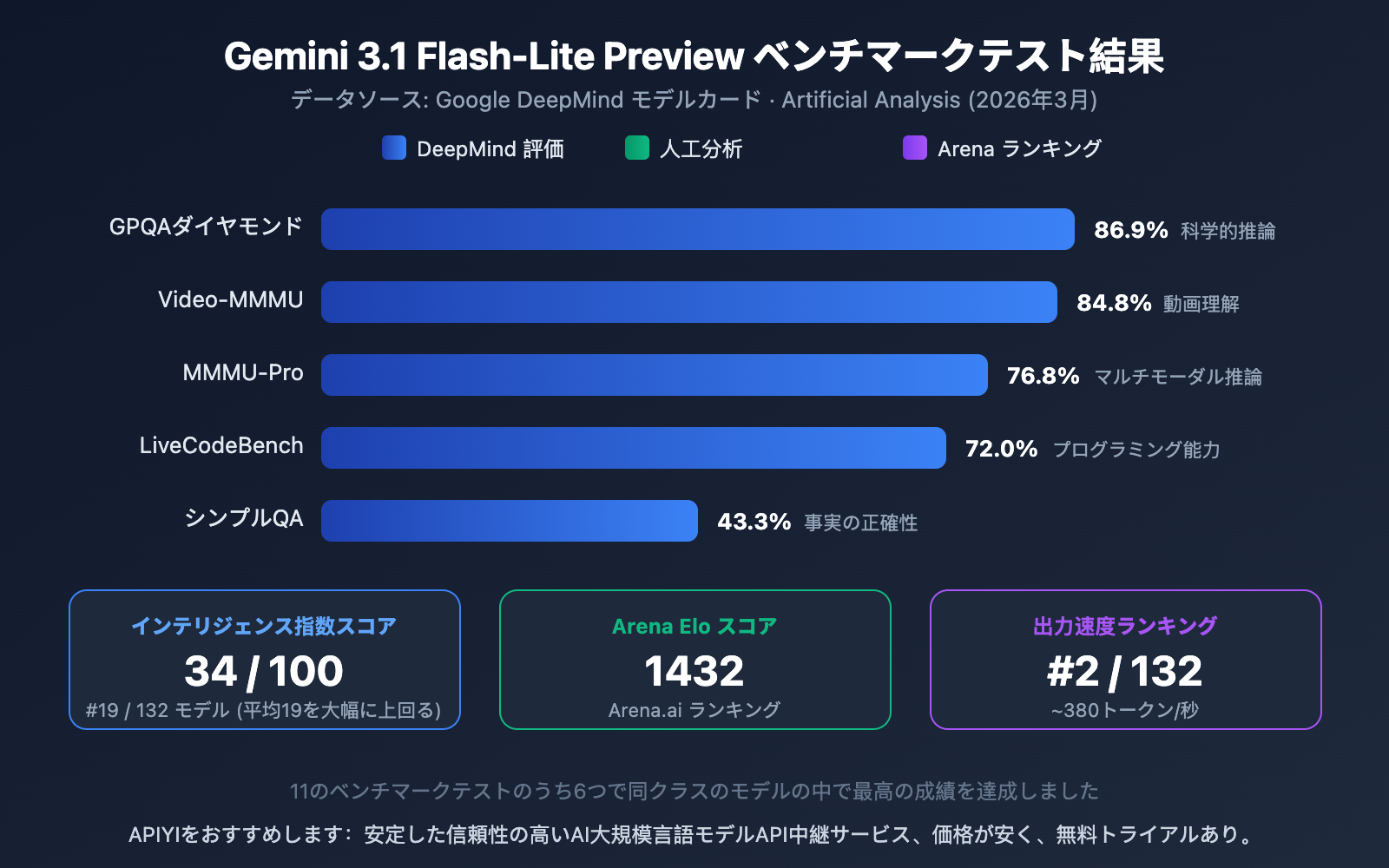
Gemini 3.1 Flash-Lite Preview ベンチマークの解説
データから見ると、Flash-Liteは軽量モデルの中で非常に優れたパフォーマンスを示しています:
- GPQA Diamond 86.9%: 科学的知識推論能力が同クラスモデルをリード
- Video-MMMU 84.8%: ビデオ理解能力はそのマルチモーダルアドバンテージの現れ
- MMMU-Pro 76.8%: マルチモーダル推論で優秀な成績
- Arena Elo 1432: Arena.aiランキングで高スコアを獲得し、実際の使用体験の良さを証明
- インテリジェンス指数 34/100: 同クラスモデルの平均値19を大きく上回り、132モデル中19位
11のベンチマークテストのうち、Flash-Liteは6項目で同クラス最高の成績を収めており、軽量モデルとしては非常に優れたパフォーマンスと言えます。
🎯 実測推奨: ベンチマークデータは参考情報です。実際の効果はシナリオによって異なります。APIYI apiyi.com を通じて実際のシナリオでのテストを行うことをお勧めします。プラットフォームは無料枠を提供し、複数モデルの迅速な比較をサポートしています。
Gemini 3.1 Flash-Lite Preview と競合モデルの比較

| 比較項目 | Gemini 3.1 Flash-Lite | Claude 4.5 Haiku | GPT-5 mini |
|---|---|---|---|
| 出力速度 | ~380 tok/s ⚡ | ~108 tok/s | ~71 tok/s |
| 入力コスト | $0.25/M | $1.00/M | $0.15/M ⚡ |
| 出力コスト | $1.50/M | $5.00/M | $0.60/M ⚡ |
| コンテキストウィンドウ | 1M tokens ⚡ | 200K tokens | 128K tokens |
| マルチモーダル入力 | 5 種類 ⚡ | 2 種類 | 2 種類 |
| Thinking Mode | ✅ | ❌ | ❌ |
| Function Calling | ✅ | ✅ | ✅ |
| Batch API | ✅ | ✅ | ✅ |
比較まとめ:
- 速度優先: Flash-Lite の 380 tok/s は Haiku の 3.5 倍、GPT-5 mini の 5.4 倍
- コスト優先: GPT-5 mini の絶対価格は低いですが、Flash-Lite の速度優位性がコスト差を補うことができます
- 機能優先: Flash-Lite はコンテキスト長(1M)とマルチモーダルサポート(5 種類)で明らかに優位
🎯 選択アドバイス: どの軽量モデルを選ぶかは具体的なシナリオによります。APIYI apiyi.com を通じて実際の比較テストを行うことをお勧めします。プラットフォームは上記すべてのモデルを統一インターフェースで呼び出し可能で、迅速な切り替えと評価に便利です。
Gemini 3.1 Flash-Lite Preview クイックスタート
最小限の例
以下は、APIYIプラットフォームを通じて Gemini 3.1 Flash-Lite Preview を呼び出す最もシンプルなコードです。10行で実行できます:
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="gemini-3.1-flash-lite-preview",
messages=[{"role": "user", "content": "量子コンピューティングを一言で説明してください"}]
)
print(response.choices[0].message.content)
完全な実装コードを表示(Thinking Mode 含む)
from openai import OpenAI
from typing import Optional
def call_flash_lite(
prompt: str,
system_prompt: Optional[str] = None,
max_tokens: int = 2000,
enable_thinking: bool = False
) -> str:
"""
Gemini 3.1 Flash-Lite Preview を呼び出す
Args:
prompt: ユーザー入力
system_prompt: システムプロンプト
max_tokens: 最大出力トークン数
enable_thinking: Thinking Mode を有効にするかどうか
"""
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
messages = []
if system_prompt:
messages.append({"role": "system", "content": system_prompt})
messages.append({"role": "user", "content": prompt})
try:
response = client.chat.completions.create(
model="gemini-3.1-flash-lite-preview",
messages=messages,
max_tokens=max_tokens
)
return response.choices[0].message.content
except Exception as e:
return f"Error: {str(e)}"
# 使用例
result = call_flash_lite(
prompt="以下のコードの時間計算量を分析し、最適化の提案をしてください",
system_prompt="あなたは上級アルゴリズムエンジニアです"
)
print(result)
おすすめ: APIYI apiyi.com で APIキー と無料テスト枠を取得し、Gemini 3.1 Flash-Lite Preview があなたのシナリオでどのように動作するかを迅速に検証してください。100ドル以上のチャージで10ドル分のボーナスが付き、最低8割引の割引が適用されます。
Gemini 3.1 Flash-Lite Preview の適用シーン
推奨使用シーン
| シーン | 説明 | Flash-Lite を選ぶ理由 |
|---|---|---|
| 大規模翻訳 | 多言語コンテンツの翻訳ワークフロー | 380 tok/s の超高速出力 + 低コスト |
| コンテンツ審査 | ユーザー生成コンテンツの分類・フィルタリング | 高頻度呼び出し + コスト管理が容易 |
| データ抽出 | 構造化データの抽出と整理 | JSON Schema 出力をサポート |
| エージェントルーティング | ルーティング層としてリクエストを振り分け | 超低遅延 + Function Calling |
| ドキュメント処理 | PDF/長文書の解析・要約 | 1M トークンのコンテキスト + マルチモーダル入力 |
| 音声文字起こし | 音声から文字への変換と分析 | ネイティブ音声入力サポート |
非推奨のシーン
- 複雑なクリエイティブライティング: 深みのある創作には Pro 級モデルの方が優れています
- 画像/音声生成: Flash-Lite はテキスト出力のみをサポートします
- リアルタイムストリーミング対話: Live API はサポートされていません
- 最高レベルの推論精度が必要な場合: 極限の精度が求められるシーンでは、Gemini 3.1 Pro の使用を推奨します
🎯 シーン別アドバイス: どのモデルが最適かわからない? APIYI (apiyi.com) を通せば、Gemini 3.1 Flash-Lite、Claude Haiku、GPT-5 mini を素早く切り替えて比較し、最適なソリューションを見つけることができます。
よくある質問
Q1: Gemini 3.1 Flash-Lite Preview と Gemini 2.5 Flash の違いは?
コアの違いはアーキテクチャと性能にあります。Flash-Lite は Gemini 2 アーキテクチャではなく Gemini 3 Pro アーキテクチャを基盤としており、最初のトークン応答が 2.5 倍速く、出力速度は ~380 tok/s と 45% 向上しています。同時に、Thinking Mode やコード実行などの高度な機能も追加されています。
Q2: Preview 版の安定性は? 本番環境での使用に適していますか?
Preview 版の機能や性能は正式版で調整される可能性があります。重要な業務以外での先行テストを推奨し、重要な業務ではフォールバック(ダウングレード)計画を設定することをお勧めします。APIYI (apiyi.com) を通じて呼び出す場合、モデル間の切り替えが容易で、柔軟なフォールバック戦略を実現できます。
Q3: Gemini 3.1 Flash-Lite Preview を素早くテストするには?
複数モデルをサポートする API 集約プラットフォームを介したテストをお勧めします:
- APIYI (apiyi.com) にアクセスしてアカウント登録
- APIキーと無料利用枠を取得
- 本記事のコード例を使用し、model を
gemini-3.1-flash-lite-previewに設定 - 100米ドル以上のチャージで10米ドルをプレゼント、最低8割引で利用可能
まとめ
Gemini 3.1 Flash-Lite Preview の核心ポイント:
- 超高速パフォーマンス: ~380 tok/s の出力速度、132モデル中2位、初回トークン応答時間は 2.5 Flash より 2.5 倍高速
- 高いコストパフォーマンス: 入力 $0.25/M、出力 $1.50/M、Gemini 3 Pro のわずか 1/8 の価格で、高頻度・大規模な呼び出しに最適
- 機能の包括性: 1M コンテキストウィンドウ + 5 種類の入力モーダリティ + シンキングモード + ファンクションコーリング、軽量モデルの中で最も包括的な構成
- Pro モデルの血統: Gemini 3 Pro アーキテクチャを基盤としており、GPQA Diamond(86.9%)などのベンチマークで優れた性能を発揮
大規模、低コスト、高速処理を必要とする AI アプリケーションシナリオにおいて、Gemini 3.1 Flash-Lite Preview は現在最も注目すべき軽量モデルの一つです。
APIYI apiyi.com を通じて迅速に接続・テストすることをお勧めします。プラットフォーム価格は Google 公式と同一で、100米ドル以上のチャージで10米ドルをプレゼント、最大20%オフの割引が可能です。400以上の大規模言語モデルをワンストップでご利用いただけます。
📚 参考資料
-
Google AI 公式モデルドキュメント: Gemini 3.1 Flash-Lite Preview の完全な技術仕様
- リンク:
ai.google.dev/gemini-api/docs/models/gemini-3.1-flash-lite-preview - 説明: 公式 API ドキュメント、最新のパラメータと機能リストを含む
- リンク:
-
Google DeepMind モデルカード: ベンチマークデータと安全性評価
- リンク:
deepmind.google/models/model-cards/gemini-3-1-flash-lite/ - 説明: 公式モデルカード、詳細なベンチマーク結果とトレーニング情報を含む
- リンク:
-
Artificial Analysis 評価レポート: 独立第三者による性能と価格分析
- リンク:
artificialanalysis.ai/models/gemini-3-1-flash-lite-preview - 説明: 出力速度、TTFT、インテリジェンスインデックスなどの独立評価データを含む
- リンク:
-
Google 公式ブログ: Gemini 3.1 Flash-Lite リリース発表
- リンク:
blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-3-1-flash-lite/ - 説明: 公式リリース記事、製品の位置づけと中核的特徴を紹介
- リンク:
著者: APIYI 技術チーム
技術交流: コメント欄での議論を歓迎します。詳細な資料は APIYI ドキュメントセンター docs.apiyi.com をご覧ください。