Should you choose Seed 2.0 Pro, Lite, or Mini? This is the core decision many developers face when integrating ByteDance's latest Large Language Model. This article compares the Seed 2.0 Pro, Seed 2.0 Lite, and Seed 2.0 Mini models, offering clear selection advice based on benchmarks, costs, and context window capabilities.
Core Value: By the end of this post, you'll know exactly which Seed 2.0 variant to pick for your specific use case and how to use a tiered strategy to get the best price-performance ratio.

Seed 2.0 Model Family Overview
The ByteDance Seed team officially released the Seed 2.0 series of Large Language Models on February 14, 2026. This is ByteDance's next-generation multimodal foundation model family, which already supports hundreds of millions of users on products like Doubao and ranks among the industry's best in various global public evaluations.
The Seed 2.0 family consists of three core members, each with a clear positioning and target scenario:
| Model | Positioning | Core Advantages | Target Users |
|---|---|---|---|
| Seed 2.0 Pro | Flagship Model | Ultimate performance and intelligence ceiling | High-complexity, high-value professional tasks |
| Seed 2.0 Lite | Efficiency Benchmark | Balanced performance, speed, and cost | Enterprise-grade general production models |
| Seed 2.0 Mini | Lightweight Pioneer | High concurrency and low latency | Fast-response and high-throughput applications |
Systematically optimized, all three models possess powerful multimodal understanding capabilities (supporting text, image, and video input) while featuring comprehensive upgrades in linguistic reasoning, code generation, and Agent tool calling.
Seed 2.0 Pro Preview Global Evaluation Performance
The Preview version of Seed 2.0 Pro has achieved leading results in the world's most authoritative evaluation systems:
- LMSYS Chatbot Arena: Ranked 6th in the Text Arena overall standings and 3rd-4th in the Vision Arena (as of February 2026).
- Math Competitions: Scored 98.3 in AIME 2025 and 97.3 in HMMT Feb, earning gold medals in ICPC, IMO, and CMO level competitions.
- 100+ Public Benchmarks: Reached the global top tier in comprehensive evaluations covering linguistic reasoning, visual understanding, and Agent capabilities.
🎯 Technical Advice: Seed 2.0 Mini is currently the first to go live via the BytePlus platform. As a BytePlus partner, APIYI has integrated this model immediately. Developers can quickly experience the full capabilities of Seed 2.0 Mini through the APIYI apiyi.com platform; Pro and Lite versions will be rolled out successively.
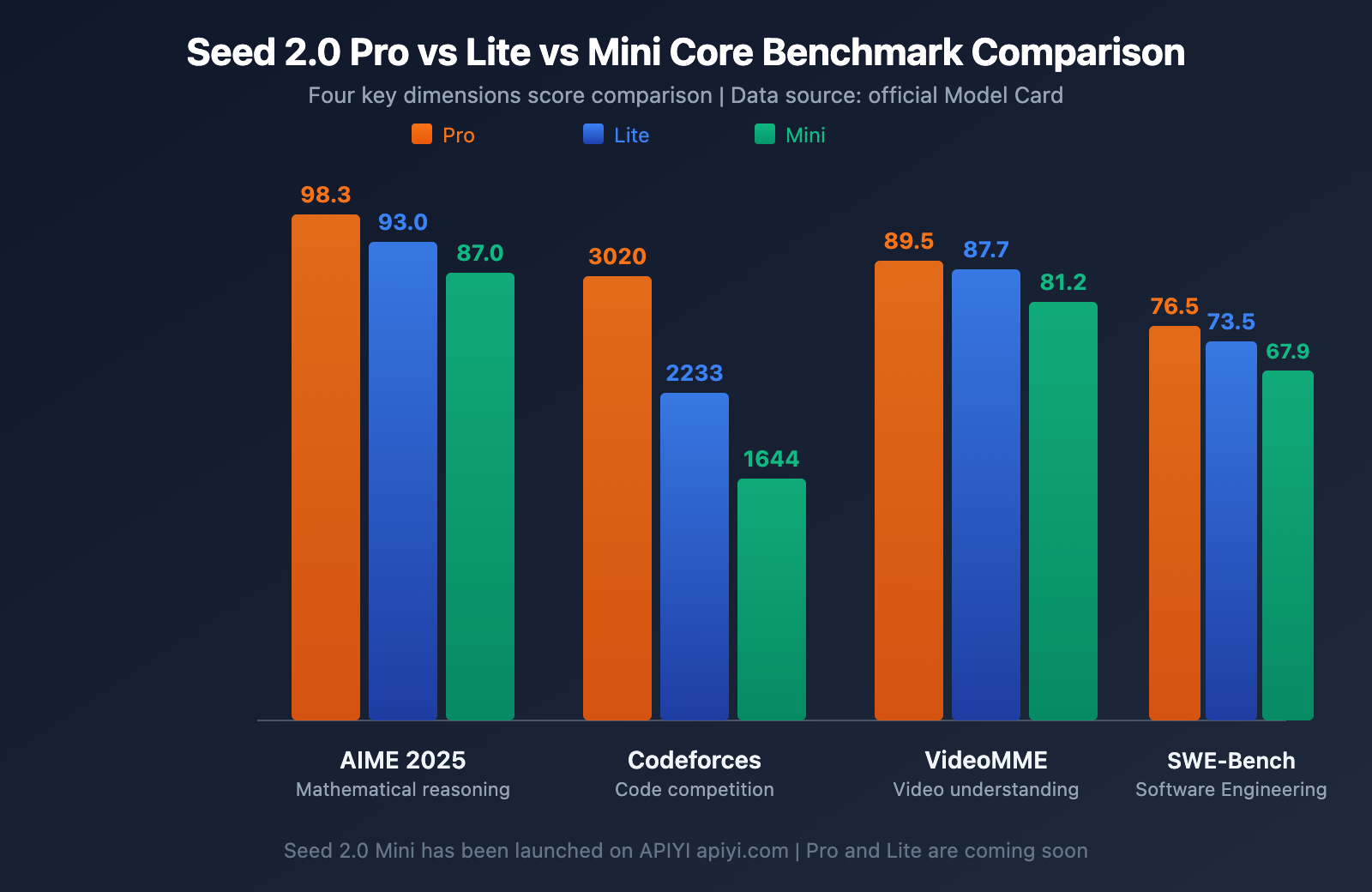
Seed 2.0 Pro vs. Lite vs. Mini Core Benchmark Comparison
Below is a complete score comparison of the three major models across key evaluation dimensions. Data is sourced from the official ByteDance Seed 2.0 Model Card and third-party evaluations.
Seed 2.0 Math and Reasoning Comparison
| Benchmark | Seed 2.0 Pro | Seed 2.0 Lite | Seed 2.0 Mini | Description |
|---|---|---|---|---|
| AIME 2025 | 98.3 | 93.0 | 87.0 | American Invitational Mathematics Examination |
| AIME 2026 | 94.2 | 88.3 | 86.7 | Latest annual math competition |
| GPQA Diamond | 88.9 | 85.1 | 79.0 | Graduate-level Q&A |
| MMLU-Pro | 87.0 | 87.7 | 83.6 | Professional knowledge understanding |
| HMMT Feb | 97.3 | 90.0 | 70.0 | Harvard-MIT Mathematics Tournament |
| MathVision | 88.8 | 86.4 | 78.1 | Visual mathematical reasoning |
Looking at the math reasoning data, the three models form a clear hierarchy:
- Pro-level: Achieving 98.3 in AIME 2025 and 97.3 in HMMT, it represents the current ceiling for Large Language Model mathematical reasoning, competing head-to-head with GPT-5.2 and Gemini 3 Pro.
- Lite-level: Reaching 93.0 in AIME 2025, and even slightly surpassing Pro's 87.0 with an 87.7 in MMLU-Pro, indicating that Lite has approached flagship standards in knowledge-understanding tasks.
- Mini-level: Scoring 87.0 in AIME 2025, which is highly impressive for a small model positioned for lightweight, high-concurrency use.
Seed 2.0 Coding and Engineering Comparison
| Benchmark | Seed 2.0 Pro | Seed 2.0 Lite | Seed 2.0 Mini | Description |
|---|---|---|---|---|
| Codeforces | 3020 | 2233 | 1644 | Competitive programming rating |
| LiveCodeBench v6 | 87.8 | 81.7 | 64.1 | Real-time programming evaluation |
| SWE-Bench Verified | 76.5 | 73.5 | 67.9 | Real-world software engineering tasks |
In terms of coding ability, Pro's Codeforces 3020 rating reaches the level of an international competition gold medalist. The gap in SWE-Bench Verified is worth noting: Pro 76.5 vs. Lite 73.5 vs. Mini 67.9. The disparity in real-world software engineering tasks is much smaller than in competitive programming, suggesting that Lite and Mini are highly practical in daily development scenarios.
Seed 2.0 Multimodal and Video Understanding Comparison
| Benchmark | Seed 2.0 Pro | Seed 2.0 Lite | Seed 2.0 Mini | Description |
|---|---|---|---|---|
| MMMU | 85.4 | 83.7 | 79.7 | Multimodal understanding |
| MMMU-Pro | 78.2 | 76.0 | 71.4 | Professional multimodal understanding |
| VideoMME | 89.5 | 87.7 | 81.2 | Video content analysis |
| MotionBench | 75.2 | 70.9 | 64.4 | Motion perception |
| TempCompass | 89.6 | 87.0 | 83.7 | Temporal reasoning |
Multimodal capability is one of the core advantages of the Seed 2.0 series. Pro's score of 89.5 on VideoMME demonstrates exceptional video understanding, with motion perception and temporal reasoning capabilities that even surpass human baseline levels. Lite follows closely behind Pro in video understanding (87.7) and temporal reasoning (87.0), making it a cost-effective choice for enterprise-level video analysis scenarios.
Seed 2.0 Agent Capability Comparison
| Benchmark | Seed 2.0 Pro | Seed 2.0 Lite | Seed 2.0 Mini | Description |
|---|---|---|---|---|
| BrowseComp | 77.3 | 72.1 | 48.1 | Web browsing understanding |
| Terminal Bench | 55.8 | 45.0 | 36.9 | Terminal operation capability |
| WideSearch | 74.7 | 74.5 | 37.7 | Breadth-first search tasks |
| HLE-Verified | 73.6 | 70.7 | 56.4 | High-difficulty reasoning verification |
Agent capability is a key dimension that distinguishes the three models. The gap between Pro and Lite on BrowseComp and WideSearch is minimal (Pro 74.7 vs. Lite 74.5), showing that Lite is nearly at flagship levels for autonomous searching and information integration. Mini scores significantly lower on Agent tasks, making it better suited as an execution end (handling simple instructions) rather than a decision-making end within an Agent system.
Seed 2.0 Mini Model Card Details
Seed 2.0 Mini is the first model from the Seed 2.0 series to launch on the APIYI platform. Here are the full model specifications:
| Parameter | Specification |
|---|---|
| Model ID | seed-2-0-mini-260215 |
| Pricing (Prompt ≤ 128K) | Input $0.1/M tokens, Output $0.4/M tokens |
| Input Types | Text + Image + Video |
| Output Types | Text |
| Context Window | 256K |
| Max Input Tokens | 256K |
| Max Output Tokens | 128K |
| Max Thinking Tokens | 128K |
| TPM (Tokens Per Minute) | 1,500K |
| RPM (Requests Per Minute) | 30K |
| Inference Mode | 4 adjustable levels: minimal / low / medium / hi |
| Available Platform | APIYI apiyi.com (BytePlus Partner) |
Seed 2.0 Mini's pricing is incredibly competitive: $0.1/M tokens for input and $0.4/M tokens for output. For comparison, GPT-5.2's input price is $1.75/M tokens, and Claude Opus 4.5 is $5.0/M tokens. Seed 2.0 Mini's input cost is just 1/17.5 of GPT-5.2, offering outstanding value.
💰 Cost Optimization: For cost-sensitive projects, Seed 2.0 Mini provides the ultimate price-performance ratio. By accessing it through the APIYI apiyi.com platform, you get pricing identical to the BytePlus official site, plus a bonus starting from 10% on $100 recharges—effectively giving you up to a 20% discount.
Seed 2.0 Scene Selection Guide
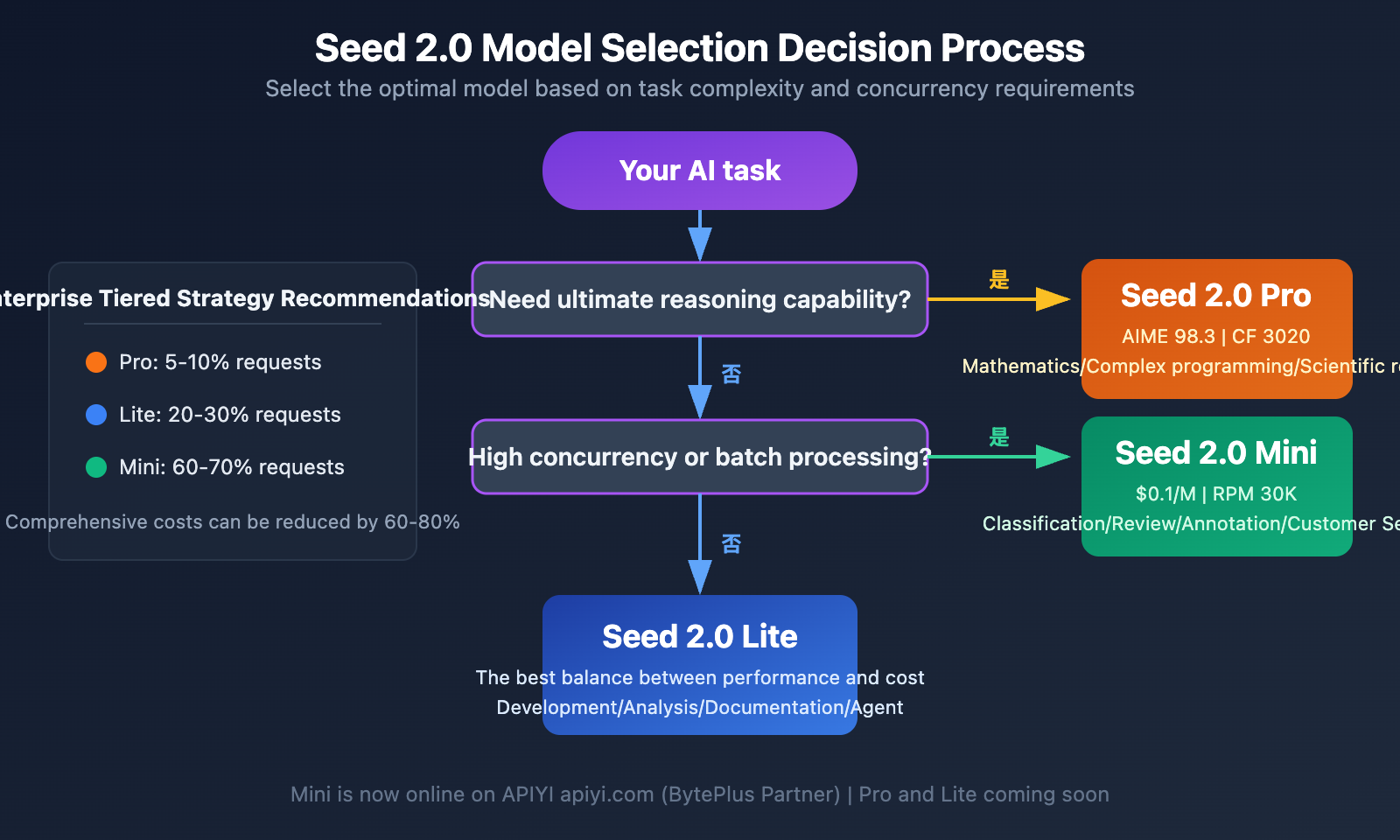
When to Choose Seed 2.0 Pro
Seed 2.0 Pro is the flagship choice for those pushing the limits of intelligence. It's perfect for these high-value scenarios:
- Frontier Research: Mathematical proofs, scientific reasoning, and academic paper assistance (AIME 98.3, GPQA 88.9).
- High-Difficulty Coding: Algorithm competitions and complex system architecture design (Codeforces 3020).
- Deep Agent Tasks: Autonomous browsing, multi-step search, and complex tool orchestration (BrowseComp 77.3, WideSearch 74.7).
- Professional Video Analysis: Long-video understanding, motion perception, and temporal reasoning (VideoMME 89.5).
- Decision-Level AI: Core business decisions that require the highest quality of reasoning.
When to Choose Seed 2.0 Lite
Seed 2.0 Lite is the best-balanced choice for enterprise production environments:
- Enterprise General Tasks: Daily code development, document processing, and data analysis (SWE-Bench 73.5).
- Content Generation: Commercial copywriting, technical documentation, and report generation (MMLU-Pro 87.7).
- Multimodal Business: Image-text understanding, video summarization, and document parsing (MMMU 83.7, VideoMME 87.7).
- Agent Workflows: Search assistants, information integration, and tool calling (WideSearch 74.5, nearly matching Pro).
- Cost-Sensitive Reasoning: Medium to large enterprises that need high quality but have a limited budget.
When to Choose Seed 2.0 Mini
Seed 2.0 Mini is the optimal choice for high-concurrency, low-cost scenarios:
- Batch Content Processing: Text classification, sentiment analysis, and keyword extraction (RPM 30K, TPM 1500K).
- Content Moderation: Image auditing, video inspection, and compliance detection (anomaly patterns reduced by 40%).
- Real-Time Customer Service: High-concurrency dialogues, automated FAQ responses, and intelligent routing.
- Data Labeling Assistance: Batch labeling, format conversion, and structured output.
- Lightweight Coding Tasks: Code completion, simple bug fixes, and code reviews (SWE-Bench 67.9).
- Cost-First Scenarios: Only $0.1 per million tokens (input), offering extreme cost-efficiency.
💡 Selection Advice: Choosing the right Seed 2.0 model mainly depends on your task complexity and concurrency requirements. For most businesses, we recommend a tiered strategy: "Lite as the workhorse + Mini as the assistant." You can be among the first to experience Seed 2.0 Mini through the APIYI apiyi.com platform, with Pro and Lite support coming soon.
Seed 2.0 Model Comparison & Decision Advice
Seed 2.0 Layered Deployment Strategy
For businesses that need to balance quality and cost, we recommend adopting the following layered architecture:
Decision Layer (Pro) — 5-10% of requests:
Handles core tasks requiring top-tier reasoning quality, such as complex logic, critical decision-making, and high-value content generation. Pro's AIME score of 98.3 and Codeforces rating of 3020 ensure the highest quality output.
Execution Layer (Lite) — 20-30% of requests:
Handles daily tasks of medium complexity, like code development, document generation, and multimodal analysis. Lite's SWE-Bench score of 73.5 and WideSearch score of 74.5 show it's incredibly reliable in real-world scenarios, with costs far lower than Pro.
Throughput Layer (Mini) — 60-70% of requests:
Handles high-frequency, standardized batch tasks such as classification, content moderation, and format conversion. Mini's 30K RPM and 1500K TPM provide massive throughput, and its input price of $0.1/M tokens is highly competitive.
Seed 2.0 vs. Competitor Price Comparison
| Model | Input Price ($/M tokens) | Output Price ($/M tokens) | Positioning |
|---|---|---|---|
| Seed 2.0 Mini | $0.10 | $0.40 | Lightweight & High Concurrency |
| GPT-4.1 mini | $0.40 | $1.60 | Lightweight General-Purpose |
| GPT-5.2 | $1.75 | $14.00 | Flagship Reasoning |
| Claude Sonnet 4.6 | $3.00 | $15.00 | Balanced & Efficient |
| Claude Opus 4.5 | $5.00 | $25.00 | Ultimate Reasoning |
| Gemini 3 Pro | $1.25 | $10.00 | Multimodal Flagship |
Seed 2.0 Mini's input and output prices are only 1/4 of GPT-4.1 mini's. Compared to GPT-5.2, the input cost is 17.5 times lower and the output cost is 35 times lower, giving it an overwhelming advantage in terms of cost-performance ratio.
Seed 2.0 Model Comparison FAQ
Q1: Is Seed 2.0 Mini currently the only version available?
Yes, as of February 2026, Seed 2.0 Mini (Model ID: seed-2-0-mini-260215) is the first model in the Seed 2.0 series to launch via the BytePlus platform. APIYI (apiyi.com), as a BytePlus partner, has integrated this model immediately, with pricing identical to the official rates. Seed 2.0 Pro and Lite are expected to roll out soon, and APIYI will support them as they become available.
Q2: In which scenarios can Seed 2.0 Lite replace Pro?
Looking at the benchmarks, Lite is already very close to Pro across several dimensions: WideSearch (74.5 vs 74.7), MMLU-Pro (87.7 vs 87.0—Lite is actually higher here), and SWE-Bench (73.5 vs 76.5). For daily development, document processing, and information synthesis, Lite can fully replace Pro while saving significant costs. Pro only shows a clear advantage in extreme scenarios like cutting-edge mathematical reasoning (AIME 98.3 vs 93.0) and high-difficulty competitive programming (Codeforces 3020 vs 2233).
Q3: How does Seed 2.0 Mini’s 4-level reasoning mode impact model selection?
Seed 2.0 Mini supports four levels for the reasoning_effort parameter: minimal (no reasoning), low, medium, and hi. In minimal mode, overall performance is about 85% of hi mode, but token consumption is only about 1/10. This means the Mini + minimal combo can cover a huge volume of tasks that don't need deep reasoning (like classification or formatting), while Mini + hi performs close to Lite's baseline. You can flexibly configure these reasoning modes through the APIYI (apiyi.com) platform for precise cost control.
Q4: How does the Seed 2.0 series stack up against GPT and Claude?
Based on benchmark data, Seed 2.0 Pro has reached the level of GPT-5.2 and Gemini 3 Pro in several evaluations, ranking 6th in Text and 3rd-4th in Vision on the LMSYS Arena. However, Seed 2.0's core competitive edge is its price: Mini's input price of $0.1/M tokens is just 1/17.5 of GPT-5.2's, and Pro's price is about 1/3.7 of GPT-5.2's. With performance being so close, the Seed 2.0 series offers a massive cost advantage.
Q5: How can I quickly integrate the Seed 2.0 Mini API?
Seed 2.0 Mini is compatible with the OpenAI SDK interface specification, so migration costs are minimal. You just need to change the base_url to https://api.apiyi.com/v1 and set the model to seed-2-0-mini-260215. The APIYI (apiyi.com) platform provides a unified, out-of-the-box interface that supports switching between various mainstream models. Plus, you can get a bonus of 10% or more when you top up $100.
Seed 2.0 Model Comparison Summary
The Seed 2.0 series is the next-generation Large Language Model family from ByteDance's Seed team. Its three core members each have a distinct focus: Pro pushes the boundaries of intelligence (AIME 98.3, Codeforces 3020), Lite strikes a balance between performance and cost (SWE-Bench 73.5, WideSearch 74.5), and Mini focuses on high concurrency and low latency (30K RPM, with input costs at just $0.1/M tokens).
Seed 2.0 Mini is already live and available for quick integration via the APIYI (apiyi.com) platform. Pricing matches the official BytePlus rates, and you'll even get extra bonuses on recharges. The Pro and Lite versions will be released soon, allowing developers to seamlessly switch and compare the entire series through the same platform.
References
-
ByteDance Seed 2.0 Official Page: Model introduction and full benchmark data.
- Link:
seed.bytedance.com/en/seed2 - Description: Includes performance comparisons for the Pro, Lite, and Mini series.
- Link:
-
Seed 2.0 Model Card Technical Whitepaper: Detailed model architecture and evaluation methodologies.
- Link:
github.com/ByteDance-Seed/Seed2.0 - Description: Covers training methods and evaluation dataset details.
- Link:
-
LMSYS Chatbot Arena: The world's largest human-preference blind test.
- Link:
lmarena.ai - Description: Seed 2.0 Pro Preview ranks #6 in Text and #3-4 in Vision.
- Link:
-
Seed 2.0 Benchmarks Guide: A compilation of third-party evaluations.
- Link:
digitalapplied.com/blog/bytedance-seed-2-doubao-ai-model-benchmarks-guide - Description: Includes head-to-head comparisons with GPT-5.2 and Claude Opus 4.5.
- Link:
Author: APIYI Team | For more AI model API comparisons and selection guides, visit the APIYI (apiyi.com) technical blog.