Seed 2.0 模型该选 Pro、Lite 还是 Mini?这是很多开发者在接入字节跳动最新大模型时面临的核心选择。本文对比 Seed 2.0 Pro、Seed 2.0 Lite 和 Seed 2.0 Mini 三大模型,从基准测试、价格成本、上下文能力等维度给出明确的选型建议。
核心价值: 看完本文,你将明确在不同业务场景下该选择哪个 Seed 2.0 模型变体,以及如何通过分层策略实现最优性价比。
Seed 2.0 模型家族概览
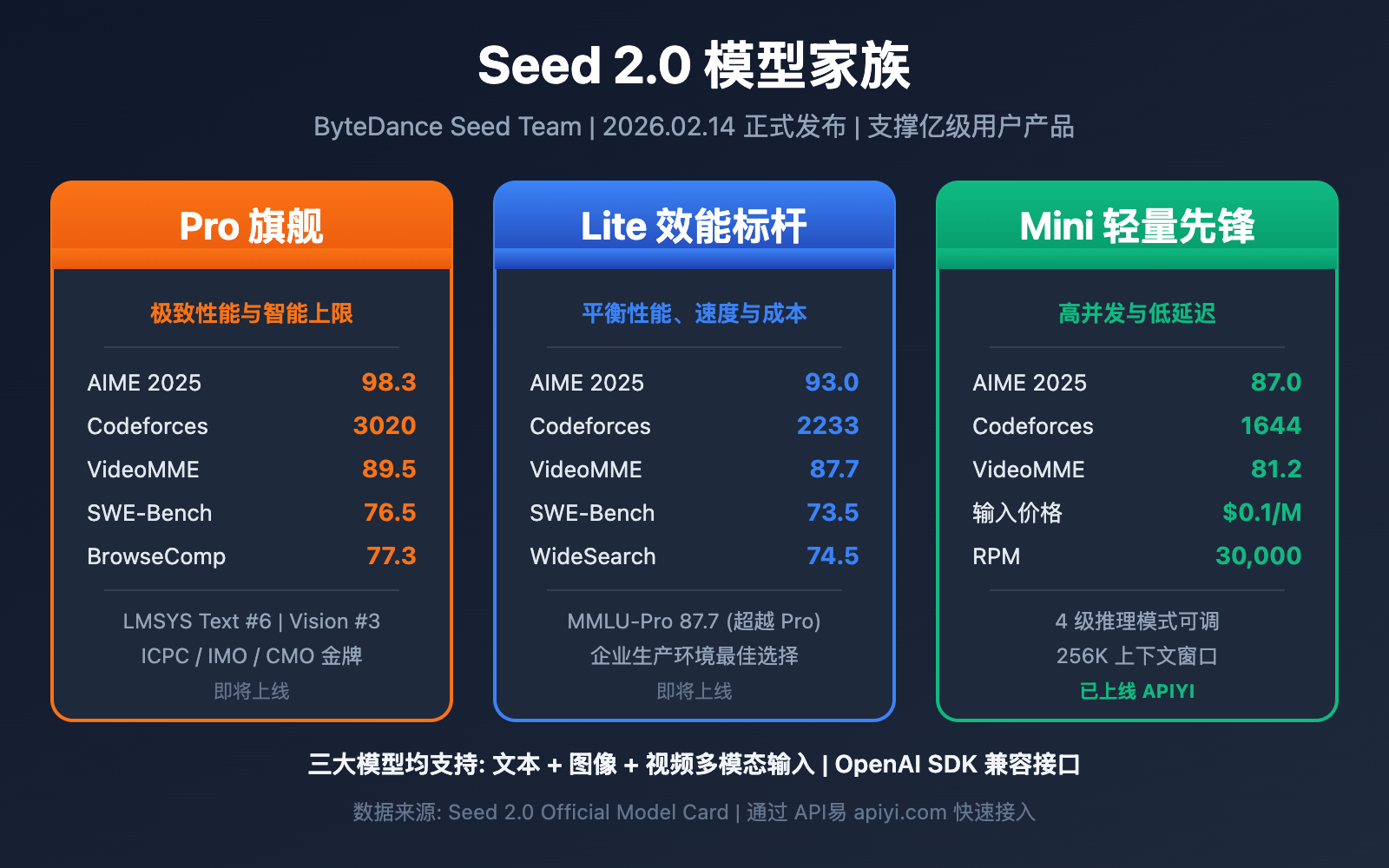
字节跳动 Seed 团队于 2026 年 2 月 14 日正式发布了 Seed 2.0 系列大模型。这是字节跳动新一代多模态基础模型家族,已支撑豆包等产品的亿级用户规模,并在全球各类公开评测中位居业界前列。
Seed 2.0 家族包含三位核心成员,各有明确的定位和目标场景:
| 模型 | 定位 | 核心优势 | 目标用户 |
|---|---|---|---|
| Seed 2.0 Pro | 旗舰模型 | 极致性能与智能上限 | 高复杂度、高价值专业任务 |
| Seed 2.0 Lite | 效能标杆 | 平衡性能、速度与成本 | 企业通用生产级模型 |
| Seed 2.0 Mini | 轻量先锋 | 高并发与低延迟 | 快速响应与高吞吐量应用 |
三个模型经过系统性优化,均具备强大的多模态理解能力(支持文本、图像、视频输入),同时在语言推理、代码生成、Agent 工具调用等维度全面升级。
Seed 2.0 Pro Preview 全球评测表现
Seed 2.0 Pro 的 Preview 版本已在全球最权威的评测体系中取得领先成绩:
- LMSYS Chatbot Arena: Text Arena 总榜排名第 6,Vision Arena 排名第 3-4(截至 2026 年 2 月)
- 数学竞赛: AIME 2025 得分 98.3,HMMT Feb 得分 97.3,获得 ICPC、IMO、CMO 竞赛金牌
- 100+ 项公开 benchmark: 在涵盖语言推理、视觉理解、Agent 能力的综合评测中达到全球第一梯队
🎯 技术建议: Seed 2.0 Mini 目前已率先通过 BytePlus 平台上线。API易作为 BytePlus 合作伙伴,第一时间接入了该模型。开发者可通过 API易 apiyi.com 平台快速体验 Seed 2.0 Mini 的完整能力,Pro 和 Lite 版本也将在后续陆续上线。
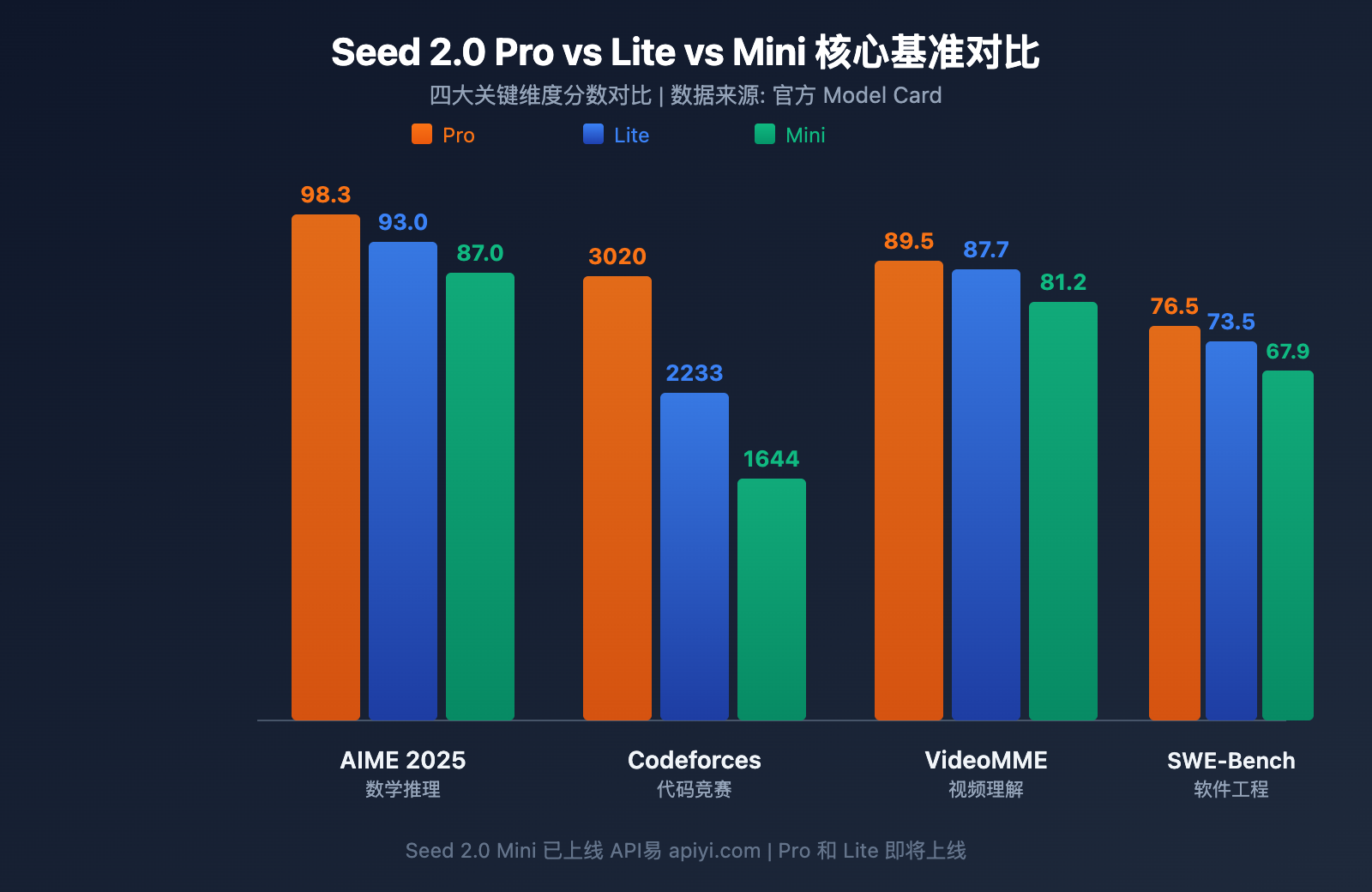
Seed 2.0 Pro vs Lite vs Mini 核心基准对比
以下是三大模型在关键评测维度上的完整分数对比。数据来源于字节跳动 Seed 2.0 官方 Model Card 和第三方评测。
Seed 2.0 数学与推理能力对比
| 评测项 | Seed 2.0 Pro | Seed 2.0 Lite | Seed 2.0 Mini | 说明 |
|---|---|---|---|---|
| AIME 2025 | 98.3 | 93.0 | 87.0 | 美国数学邀请赛 |
| AIME 2026 | 94.2 | 88.3 | 86.7 | 最新年度数学竞赛 |
| GPQA Diamond | 88.9 | 85.1 | 79.0 | 研究生级别问答 |
| MMLU-Pro | 87.0 | 87.7 | 83.6 | 专业知识理解 |
| HMMT Feb | 97.3 | 90.0 | 70.0 | 哈佛-MIT 数学锦标赛 |
| MathVision | 88.8 | 86.4 | 78.1 | 视觉数学推理 |
从数学推理数据来看,三个模型形成了清晰的梯队:
- Pro 级: AIME 2025 达到 98.3,HMMT 达到 97.3,代表当前大模型数学推理的天花板水平,可与 GPT-5.2 和 Gemini 3 Pro 正面竞争
- Lite 级: AIME 2025 达到 93.0,MMLU-Pro 甚至以 87.7 微幅超过 Pro 的 87.0,说明在知识理解类任务上 Lite 已接近旗舰水准
- Mini 级: AIME 2025 达到 87.0,对于一个定位轻量高并发的小模型而言,这个分数已经非常出色
Seed 2.0 代码与工程能力对比
| 评测项 | Seed 2.0 Pro | Seed 2.0 Lite | Seed 2.0 Mini | 说明 |
|---|---|---|---|---|
| Codeforces | 3020 | 2233 | 1644 | 竞赛编程评级 |
| LiveCodeBench v6 | 87.8 | 81.7 | 64.1 | 实时编程评估 |
| SWE-Bench Verified | 76.5 | 73.5 | 67.9 | 真实软件工程任务 |
代码能力方面,Pro 的 Codeforces 3020 评级达到国际竞赛金牌水平。值得关注的是 SWE-Bench Verified 的差距: Pro 76.5 vs Lite 73.5 vs Mini 67.9,三者在真实软件工程任务上的差距远小于竞赛编程,说明 Lite 和 Mini 在日常开发场景中的实用性很强。
Seed 2.0 多模态与视频理解对比
| 评测项 | Seed 2.0 Pro | Seed 2.0 Lite | Seed 2.0 Mini | 说明 |
|---|---|---|---|---|
| MMMU | 85.4 | 83.7 | 79.7 | 多模态理解 |
| MMMU-Pro | 78.2 | 76.0 | 71.4 | 专业多模态理解 |
| VideoMME | 89.5 | 87.7 | 81.2 | 视频内容分析 |
| MotionBench | 75.2 | 70.9 | 64.4 | 运动感知 |
| TempCompass | 89.6 | 87.0 | 83.7 | 时序推理 |
多模态是 Seed 2.0 系列的核心优势之一。Pro 在 VideoMME 上的 89.5 分展现了超强的视频理解能力,其运动感知和时序推理能力甚至超越了人类基线水平。Lite 在视频理解(87.7)和时序推理(87.0)上紧跟 Pro,是企业级视频分析场景的高性价比选择。
Seed 2.0 Agent 能力对比
| 评测项 | Seed 2.0 Pro | Seed 2.0 Lite | Seed 2.0 Mini | 说明 |
|---|---|---|---|---|
| BrowseComp | 77.3 | 72.1 | 48.1 | 网页浏览理解 |
| Terminal Bench | 55.8 | 45.0 | 36.9 | 终端操作能力 |
| WideSearch | 74.7 | 74.5 | 37.7 | 广度搜索任务 |
| HLE-Verified | 73.6 | 70.7 | 56.4 | 高难度推理验证 |
Agent 能力是区分三个模型的关键维度。Pro 和 Lite 在 BrowseComp 和 WideSearch 上差距极小(Pro 74.7 vs Lite 74.5),说明 Lite 在自主搜索和信息整合方面已经接近旗舰水平。Mini 在 Agent 任务上的得分明显偏低,更适合作为 Agent 系统中的执行端(处理简单指令)而非决策端。
Seed 2.0 Mini 模型卡详细参数
Seed 2.0 Mini 是目前已通过 APIYI 平台上线的首个 Seed 2.0 系列模型。以下是完整的模型参数:
| 参数项 | 规格 |
|---|---|
| Model ID | seed-2-0-mini-260215 |
| 模型定价 (Prompt ≤ 128K) | 输入 $0.1/M tokens,输出 $0.4/M tokens |
| 输入类型 | 文本 + 图像 + 视频 |
| 输出类型 | 文本 |
| 上下文窗口 | 256K |
| 最大输入 Token | 256K |
| 最大输出 Token | 128K |
| 最大思考内容 Token | 128K |
| TPM (Tokens Per Minute) | 1,500K |
| RPM (Requests Per Minute) | 30K |
| 推理模式 | 4 级可调: minimal / low / medium / hi |
| 可用平台 | API易 apiyi.com(BytePlus 合作伙伴) |
Seed 2.0 Mini 的定价非常有竞争力: 输入 $0.1/M tokens、输出 $0.4/M tokens。作为参考,GPT-5.2 的输入价格为 $1.75/M tokens,Claude Opus 4.5 为 $5.0/M tokens。Seed 2.0 Mini 的输入成本仅为 GPT-5.2 的 1/17.5,性价比极为突出。
💰 成本优化: 对于成本敏感的项目,Seed 2.0 Mini 提供了极致的性价比。通过 API易 apiyi.com 平台接入,价格与 BytePlus 官网持平,充值 100 美金可加赠 10% 起,最多相当于 8 折优惠。
Seed 2.0 场景选型推荐

选择 Seed 2.0 Pro 的场景
Seed 2.0 Pro 是追求极致智能上限的旗舰选择,适合以下高价值场景:
- 前沿科研: 数学证明、科学推理、论文辅助(AIME 98.3,GPQA 88.9)
- 高难度编程: 算法竞赛、复杂系统架构设计(Codeforces 3020)
- 深度 Agent 任务: 自主浏览、多步搜索、复杂工具编排(BrowseComp 77.3,WideSearch 74.7)
- 专业视频分析: 长视频理解、运动感知、时序推理(VideoMME 89.5)
- 决策层 AI: 需要最高推理质量的核心业务决策
选择 Seed 2.0 Lite 的场景
Seed 2.0 Lite 是企业生产环境的最佳平衡之选:
- 企业级通用任务: 日常代码开发、文档处理、数据分析(SWE-Bench 73.5)
- 内容生成: 商业文案、技术文档、报告生成(MMLU-Pro 87.7)
- 多模态业务: 图文理解、视频摘要、文档解析(MMMU 83.7,VideoMME 87.7)
- Agent 工作流: 搜索助手、信息整合、工具调用(WideSearch 74.5,几乎追平 Pro)
- 成本敏感的推理任务: 需要高质量但预算有限的中大型企业
选择 Seed 2.0 Mini 的场景
Seed 2.0 Mini 是高并发、低成本场景的最优选择:
- 批量内容处理: 文本分类、情感分析、关键词提取(RPM 30K,TPM 1500K)
- 内容审核: 图片审核、视频巡检、合规检测(异常模式降低 40%)
- 实时客服: 高并发对话、FAQ 自动应答、智能路由
- 数据标注辅助: 批量标注、格式转换、结构化输出
- 轻量代码任务: 代码补全、简单 Bug 修复、代码审查(SWE-Bench 67.9)
- 成本优先场景: 每百万 Token 仅 $0.1(输入),极致性价比
💡 选择建议: 选择哪个 Seed 2.0 模型主要取决于您的任务复杂度和并发需求。对于大多数企业,我们建议采用「Lite 主力 + Mini 辅助」的分层策略。通过 API易 apiyi.com 平台,目前可率先体验 Seed 2.0 Mini,后续 Pro 和 Lite 上线后也将第一时间支持。
Seed 2.0 模型对比决策建议
Seed 2.0 分层部署策略
对于需要同时兼顾质量和成本的企业,建议采用以下分层架构:
决策层(Pro)— 占请求量 5-10%:
处理需要最高推理质量的核心任务,如复杂推理、关键决策、高价值内容生成。Pro 的 AIME 98.3 和 Codeforces 3020 确保了最高质量输出。
执行层(Lite)— 占请求量 20-30%:
处理日常的中等复杂度任务,如代码开发、文档生成、多模态分析。Lite 的 SWE-Bench 73.5 和 WideSearch 74.5 说明它在实际工作场景中非常可靠,且成本远低于 Pro。
吞吐层(Mini)— 占请求量 60-70%:
处理高频、标准化的批量任务,如分类标注、内容审核、格式转换。Mini 的 RPM 30K 和 TPM 1500K 提供了超高吞吐能力,输入 $0.1/M tokens 的价格极具竞争力。
Seed 2.0 vs 竞品价格对比
| 模型 | 输入价格 ($/M tokens) | 输出价格 ($/M tokens) | 定位 |
|---|---|---|---|
| Seed 2.0 Mini | $0.10 | $0.40 | 轻量高并发 |
| GPT-4.1 mini | $0.40 | $1.60 | 轻量通用 |
| GPT-5.2 | $1.75 | $14.00 | 旗舰推理 |
| Claude Sonnet 4.6 | $3.00 | $15.00 | 均衡高效 |
| Claude Opus 4.5 | $5.00 | $25.00 | 极致推理 |
| Gemini 3 Pro | $1.25 | $10.00 | 多模态旗舰 |
Seed 2.0 Mini 的输入价格仅为 GPT-4.1 mini 的 1/4,输出价格为 1/4。与 GPT-5.2 相比,输入成本低 17.5 倍,输出成本低 35 倍,在性价比方面具有压倒性优势。
Seed 2.0 模型对比常见问题
Q1: Seed 2.0 Mini 目前是唯一可用的版本吗?
是的,截至 2026 年 2 月,Seed 2.0 Mini(Model ID: seed-2-0-mini-260215)是首个通过 BytePlus 平台上线的 Seed 2.0 系列模型。API易 apiyi.com 作为 BytePlus 合作伙伴,已第一时间接入该模型,价格与官网持平。Seed 2.0 Pro 和 Lite 预计将在后续陆续上线,届时 API易 也将同步支持。
Q2: Seed 2.0 Lite 在哪些场景下可以替代 Pro?
从基准数据来看,Lite 在多个维度已非常接近 Pro: WideSearch(74.5 vs 74.7)、MMLU-Pro(87.7 vs 87.0,Lite 甚至更高)、SWE-Bench(73.5 vs 76.5)。对于日常开发、文档处理、信息搜索整合等任务,Lite 完全可以替代 Pro,同时节省显著成本。只有在前沿数学推理(AIME 98.3 vs 93.0)和高难度竞赛编程(Codeforces 3020 vs 2233)等极端场景下,Pro 才有明显优势。
Q3: Seed 2.0 Mini 的 4 级推理模式如何影响选型?
Seed 2.0 Mini 支持 reasoning_effort 参数的 4 个档位: minimal(无推理)、low、medium、hi。在 minimal 模式下,整体性能约为 hi 模式的 85%,但 Token 消耗仅约 1/10。这意味着 Mini + minimal 模式可以覆盖大量不需要深度推理的任务(分类、标注、格式化),而 Mini + hi 模式的表现已接近 Lite 的基准水平。通过 API易 apiyi.com 平台可以灵活配置推理模式,实现精准的成本控制。
Q4: Seed 2.0 系列如何与 GPT 和 Claude 竞争?
从基准数据看,Seed 2.0 Pro 在多项评测中已达到 GPT-5.2 和 Gemini 3 Pro 的水平,LMSYS Arena 排名第 6(Text)和第 3-4(Vision)。但 Seed 2.0 的核心竞争力在于价格: Mini 的输入价格 $0.1/M tokens 仅为 GPT-5.2 的 1/17.5,Pro 的价格约为 GPT-5.2 的 1/3.7。在性能接近的情况下,Seed 2.0 系列提供了极具竞争力的成本优势。
Q5: 如何快速接入 Seed 2.0 Mini API?
Seed 2.0 Mini 兼容 OpenAI SDK 接口规范,迁移成本极低。只需修改 base_url 为 https://api.apiyi.com/v1,model 设置为 seed-2-0-mini-260215 即可。API易 apiyi.com 平台提供开箱即用的统一接口,支持多种主流模型的切换调用,充值 100 美金可加赠 10% 起。
Seed 2.0 模型对比总结
Seed 2.0 系列是字节跳动 Seed 团队推出的新一代大模型家族,三个核心成员各有明确定位: Pro 追求极致智能上限(AIME 98.3、Codeforces 3020),Lite 平衡性能与成本(SWE-Bench 73.5、WideSearch 74.5),Mini 聚焦高并发低延迟(RPM 30K、输入仅 $0.1/M tokens)。
目前 Seed 2.0 Mini 已率先上线,通过 API易 apiyi.com 平台即可快速接入,价格与 BytePlus 官网持平,充值还享额外优惠。Pro 和 Lite 版本将在后续陆续发布,届时开发者可通过同一平台无缝切换和对比全系列模型。
参考资料
-
ByteDance Seed 2.0 官方页面: 模型介绍和完整基准测试数据
- 链接:
seed.bytedance.com/en/seed2 - 说明: 包含 Pro、Lite、Mini 全系列评测对比
- 链接:
-
Seed 2.0 Model Card 技术白皮书: 详细模型架构和评测方法
- 链接:
github.com/ByteDance-Seed/Seed2.0 - 说明: 包含训练方法、评测数据集详情
- 链接:
-
LMSYS Chatbot Arena: 全球最大规模人类偏好盲评
- 链接:
lmarena.ai - 说明: Seed 2.0 Pro Preview 排名 Text #6, Vision #3-4
- 链接:
-
Seed 2.0 Benchmarks Guide: 第三方评测汇总
- 链接:
digitalapplied.com/blog/bytedance-seed-2-doubao-ai-model-benchmarks-guide - 说明: 包含与 GPT-5.2、Claude Opus 4.5 的横向对比
- 链接:
作者: APIYI Team | 了解更多 AI 模型 API 对比与选型指南,请访问 API易 apiyi.com 技术博客