Seed 2.0 模型該選 Pro、Lite 還是 Mini?這是很多開發者在接入字節跳動最新大模型時面臨的核心選擇。本文對比 Seed 2.0 Pro、Seed 2.0 Lite 和 Seed 2.0 Mini 三大模型,從基準測試、價格成本、上下文能力等維度給出明確的選型建議。
核心價值: 看完本文,你將明確在不同業務場景下該選擇哪個 Seed 2.0 模型變體,以及如何通過分層策略實現最優性價比。
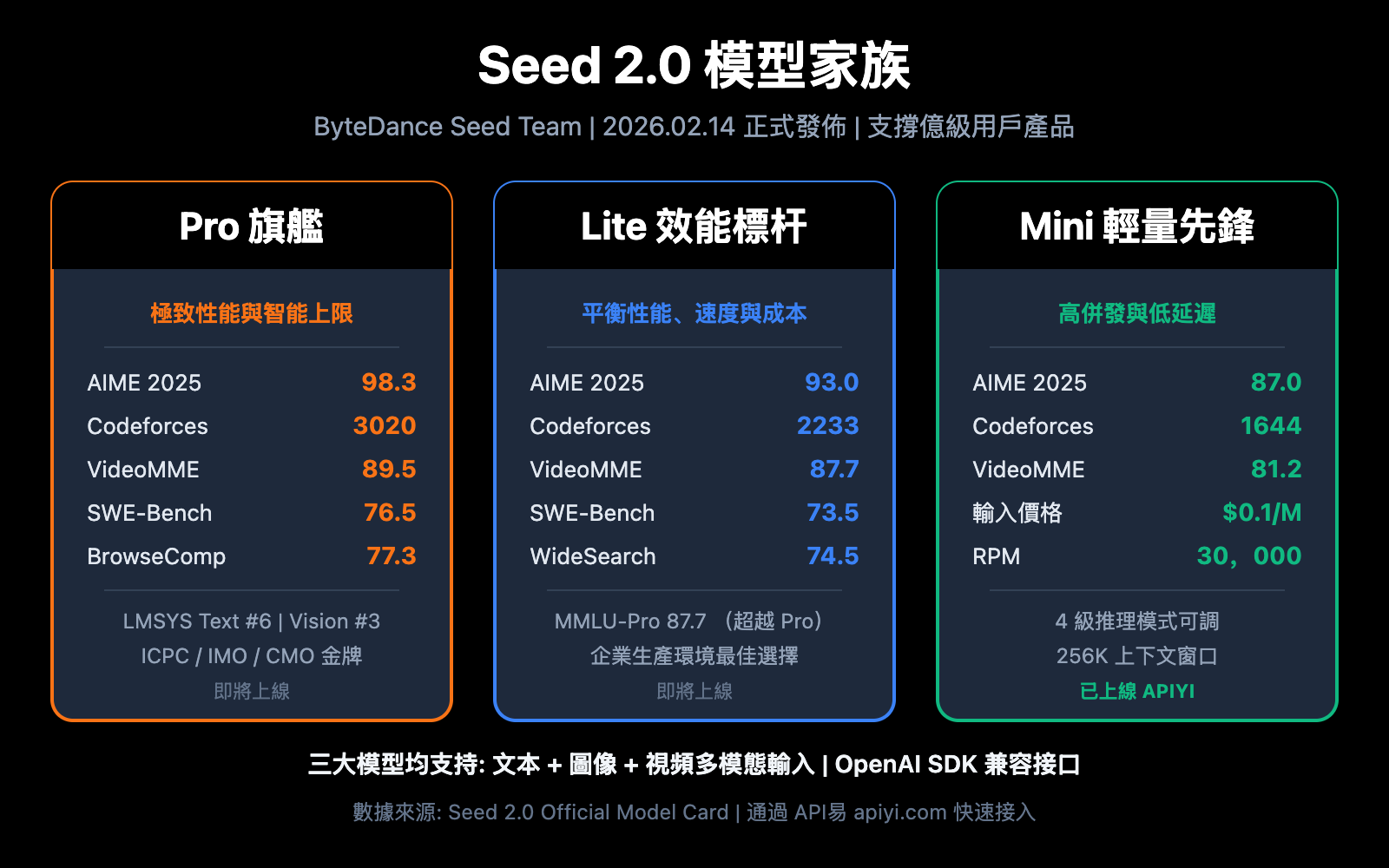
Seed 2.0 模型家族概覽
字節跳動 Seed 團隊於 2026 年 2 月 14 日正式發佈了 Seed 2.0 系列大模型。這是字節跳動新一代多模態基礎模型家族,已支撐豆包等產品的億級用戶規模,並在全球各類公開評測中位居業界前列。
Seed 2.0 家族包含三位核心成員,各有明確的定位和目標場景:
| 模型 | 定位 | 核心優勢 | 目標用戶 |
|---|---|---|---|
| Seed 2.0 Pro | 旗艦模型 | 極致性能與智能上限 | 高複雜度、高價值專業任務 |
| Seed 2.0 Lite | 效能標杆 | 平衡性能、速度與成本 | 企業通用生產級模型 |
| Seed 2.0 Mini | 輕量先鋒 | 高併發與低延遲 | 快速響應與高吞吐量應用 |
三個模型經過系統性優化,均具備強大的多模態理解能力(支持文本、圖像、視頻輸入),同時在語言推理、代碼生成、Agent 工具調用等維度全面升級。
Seed 2.0 Pro Preview 全球評測表現
Seed 2.0 Pro 的 Preview 版本已在全球最權威的評測體系中取得領先成績:
- LMSYS Chatbot Arena: Text Arena 總榜排名第 6,Vision Arena 排名第 3-4(截至 2026 年 2 月)
- 數學競賽: AIME 2025 得分 98.3,HMMT Feb 得分 97.3,獲得 ICPC、IMO、CMO 競賽金牌
- 100+ 項公開 benchmark: 在涵蓋語言推理、視覺理解、Agent 能力的綜合評測中達到全球第一梯隊
🎯 技術建議: Seed 2.0 Mini 目前已率先通過 BytePlus 平臺上線。API易作爲 BytePlus 合作伙伴,第一時間接入了該模型。開發者可通過 API易 apiyi.com 平臺快速體驗 Seed 2.0 Mini 的完整能力,Pro 和 Lite 版本也將在後續陸續上線。
Seed 2.0 Pro vs Lite vs Mini 核心基準對比
以下是三大模型在關鍵評測維度上的完整分數對比。數據來源於字節跳動 Seed 2.0 官方 Model Card 和第三方評測。
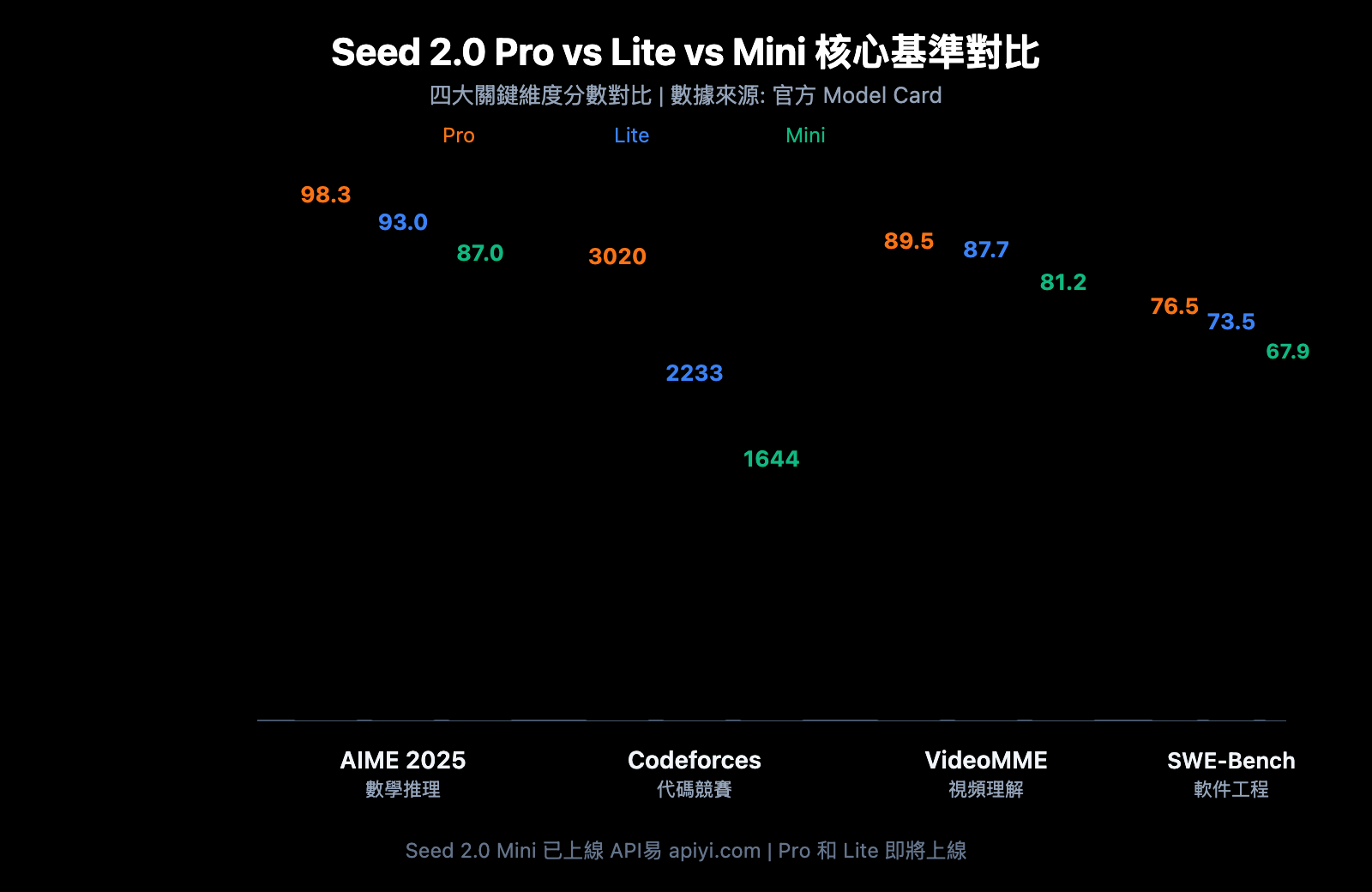
Seed 2.0 數學與推理能力對比
| 評測項 | Seed 2.0 Pro | Seed 2.0 Lite | Seed 2.0 Mini | 說明 |
|---|---|---|---|---|
| AIME 2025 | 98.3 | 93.0 | 87.0 | 美國數學邀請賽 |
| AIME 2026 | 94.2 | 88.3 | 86.7 | 最新年度數學競賽 |
| GPQA Diamond | 88.9 | 85.1 | 79.0 | 研究生級別問答 |
| MMLU-Pro | 87.0 | 87.7 | 83.6 | 專業知識理解 |
| HMMT Feb | 97.3 | 90.0 | 70.0 | 哈佛-MIT 數學錦標賽 |
| MathVision | 88.8 | 86.4 | 78.1 | 視覺數學推理 |
從數學推理數據來看,三個模型形成了清晰的梯隊:
- Pro 級: AIME 2025 達到 98.3,HMMT 達到 97.3,代表當前大模型數學推理的天花板水平,可與 GPT-5.2 和 Gemini 3 Pro 正面競爭
- Lite 級: AIME 2025 達到 93.0,MMLU-Pro 甚至以 87.7 微幅超過 Pro 的 87.0,說明在知識理解類任務上 Lite 已接近旗艦水準
- Mini 級: AIME 2025 達到 87.0,對於一個定位輕量高併發的小模型而言,這個分數已經非常出色
Seed 2.0 代碼與工程能力對比
| 評測項 | Seed 2.0 Pro | Seed 2.0 Lite | Seed 2.0 Mini | 說明 |
|---|---|---|---|---|
| Codeforces | 3020 | 2233 | 1644 | 競賽編程評級 |
| LiveCodeBench v6 | 87.8 | 81.7 | 64.1 | 實時編程評估 |
| SWE-Bench Verified | 76.5 | 73.5 | 67.9 | 真實軟件工程任務 |
代碼能力方面,Pro 的 Codeforces 3020 評級達到國際競賽金牌水平。值得關注的是 SWE-Bench Verified 的差距: Pro 76.5 vs Lite 73.5 vs Mini 67.9,三者在真實軟件工程任務上的差距遠小於競賽編程,說明 Lite 和 Mini 在日常開發場景中的實用性很強。
Seed 2.0 多模態與視頻理解對比
| 評測項 | Seed 2.0 Pro | Seed 2.0 Lite | Seed 2.0 Mini | 說明 |
|---|---|---|---|---|
| MMMU | 85.4 | 83.7 | 79.7 | 多模態理解 |
| MMMU-Pro | 78.2 | 76.0 | 71.4 | 專業多模態理解 |
| VideoMME | 89.5 | 87.7 | 81.2 | 視頻內容分析 |
| MotionBench | 75.2 | 70.9 | 64.4 | 運動感知 |
| TempCompass | 89.6 | 87.0 | 83.7 | 時序推理 |
多模態是 Seed 2.0 系列的核心優勢之一。Pro 在 VideoMME 上的 89.5 分展現了超強的視頻理解能力,其運動感知和時序推理能力甚至超越了人類基線水平。Lite 在視頻理解(87.7)和時序推理(87.0)上緊跟 Pro,是企業級視頻分析場景的高性價比選擇。
Seed 2.0 Agent 能力對比
| 評測項 | Seed 2.0 Pro | Seed 2.0 Lite | Seed 2.0 Mini | 說明 |
|---|---|---|---|---|
| BrowseComp | 77.3 | 72.1 | 48.1 | 網頁瀏覽理解 |
| Terminal Bench | 55.8 | 45.0 | 36.9 | 終端操作能力 |
| WideSearch | 74.7 | 74.5 | 37.7 | 廣度搜索任務 |
| HLE-Verified | 73.6 | 70.7 | 56.4 | 高難度推理驗證 |
Agent 能力是區分三個模型的關鍵維度。Pro 和 Lite 在 BrowseComp 和 WideSearch 上差距極小(Pro 74.7 vs Lite 74.5),說明 Lite 在自主搜索和信息整合方面已經接近旗艦水平。Mini 在 Agent 任務上的得分明顯偏低,更適合作爲 Agent 系統中的執行端(處理簡單指令)而非決策端。
Seed 2.0 Mini 模型卡詳細參數
Seed 2.0 Mini 是目前已通過 APIYI 平臺上線的首個 Seed 2.0 系列模型。以下是完整的模型參數:
| 參數項 | 規格 |
|---|---|
| Model ID | seed-2-0-mini-260215 |
| 模型定價 (Prompt ≤ 128K) | 輸入 $0.1/M tokens,輸出 $0.4/M tokens |
| 輸入類型 | 文本 + 圖像 + 視頻 |
| 輸出類型 | 文本 |
| 上下文窗口 | 256K |
| 最大輸入 Token | 256K |
| 最大輸出 Token | 128K |
| 最大思考內容 Token | 128K |
| TPM (Tokens Per Minute) | 1,500K |
| RPM (Requests Per Minute) | 30K |
| 推理模式 | 4 級可調: minimal / low / medium / hi |
| 可用平臺 | API易 apiyi.com(BytePlus 合作伙伴) |
Seed 2.0 Mini 的定價非常有競爭力: 輸入 $0.1/M tokens、輸出 $0.4/M tokens。作爲參考,GPT-5.2 的輸入價格爲 $1.75/M tokens,Claude Opus 4.5 爲 $5.0/M tokens。Seed 2.0 Mini 的輸入成本僅爲 GPT-5.2 的 1/17.5,性價比極爲突出。
💰 成本優化: 對於成本敏感的項目,Seed 2.0 Mini 提供了極致的性價比。通過 API易 apiyi.com 平臺接入,價格與 BytePlus 官網持平,充值 100 美金可加贈 10% 起,最多相當於 8 折優惠。
Seed 2.0 場景選型推薦

選擇 Seed 2.0 Pro 的場景
Seed 2.0 Pro 是追求極致智能上限的旗艦選擇,適合以下高價值場景:
- 前沿科研: 數學證明、科學推理、論文輔助(AIME 98.3,GPQA 88.9)
- 高難度編程: 算法競賽、複雜系統架構設計(Codeforces 3020)
- 深度 Agent 任務: 自主瀏覽、多步搜索、複雜工具編排(BrowseComp 77.3,WideSearch 74.7)
- 專業視頻分析: 長視頻理解、運動感知、時序推理(VideoMME 89.5)
- 決策層 AI: 需要最高推理質量的核心業務決策
選擇 Seed 2.0 Lite 的場景
Seed 2.0 Lite 是企業生產環境的最佳平衡之選:
- 企業級通用任務: 日常代碼開發、文檔處理、數據分析(SWE-Bench 73.5)
- 內容生成: 商業文案、技術文檔、報告生成(MMLU-Pro 87.7)
- 多模態業務: 圖文理解、視頻摘要、文檔解析(MMMU 83.7,VideoMME 87.7)
- Agent 工作流: 搜索助手、信息整合、工具調用(WideSearch 74.5,幾乎追平 Pro)
- 成本敏感的推理任務: 需要高質量但預算有限的中大型企業
選擇 Seed 2.0 Mini 的場景
Seed 2.0 Mini 是高併發、低成本場景的最優選擇:
- 批量內容處理: 文本分類、情感分析、關鍵詞提取(RPM 30K,TPM 1500K)
- 內容審覈: 圖片審覈、視頻巡檢、合規檢測(異常模式降低 40%)
- 實時客服: 高併發對話、FAQ 自動應答、智能路由
- 數據標註輔助: 批量標註、格式轉換、結構化輸出
- 輕量代碼任務: 代碼補全、簡單 Bug 修復、代碼審查(SWE-Bench 67.9)
- 成本優先場景: 每百萬 Token 僅 $0.1(輸入),極致性價比
💡 選擇建議: 選擇哪個 Seed 2.0 模型主要取決於您的任務複雜度和併發需求。對於大多數企業,我們建議採用「Lite 主力 + Mini 輔助」的分層策略。通過 API易 apiyi.com 平臺,目前可率先體驗 Seed 2.0 Mini,後續 Pro 和 Lite 上線後也將第一時間支持。
Seed 2.0 模型對比決策建議
Seed 2.0 分層部署策略
對於需要同時兼顧質量和成本的企業,建議採用以下分層架構:
決策層(Pro)— 佔請求量 5-10%:
處理需要最高推理質量的核心任務,如複雜推理、關鍵決策、高價值內容生成。Pro 的 AIME 98.3 和 Codeforces 3020 確保了最高質量輸出。
執行層(Lite)— 佔請求量 20-30%:
處理日常的中等複雜度任務,如代碼開發、文檔生成、多模態分析。Lite 的 SWE-Bench 73.5 和 WideSearch 74.5 說明它在實際工作場景中非常可靠,且成本遠低於 Pro。
吞吐層(Mini)— 佔請求量 60-70%:
處理高頻、標準化的批量任務,如分類標註、內容審覈、格式轉換。Mini 的 RPM 30K 和 TPM 1500K 提供了超高吞吐能力,輸入 $0.1/M tokens 的價格極具競爭力。
Seed 2.0 vs 競品價格對比
| 模型 | 輸入價格 ($/M tokens) | 輸出價格 ($/M tokens) | 定位 |
|---|---|---|---|
| Seed 2.0 Mini | $0.10 | $0.40 | 輕量高併發 |
| GPT-4.1 mini | $0.40 | $1.60 | 輕量通用 |
| GPT-5.2 | $1.75 | $14.00 | 旗艦推理 |
| Claude Sonnet 4.6 | $3.00 | $15.00 | 均衡高效 |
| Claude Opus 4.5 | $5.00 | $25.00 | 極致推理 |
| Gemini 3 Pro | $1.25 | $10.00 | 多模態旗艦 |
Seed 2.0 Mini 的輸入價格僅爲 GPT-4.1 mini 的 1/4,輸出價格爲 1/4。與 GPT-5.2 相比,輸入成本低 17.5 倍,輸出成本低 35 倍,在性價比方面具有壓倒性優勢。
Seed 2.0 模型對比常見問題
Q1: Seed 2.0 Mini 目前是唯一可用的版本嗎?
是的,截至 2026 年 2 月,Seed 2.0 Mini(Model ID: seed-2-0-mini-260215)是首個通過 BytePlus 平臺上線的 Seed 2.0 系列模型。API易 apiyi.com 作爲 BytePlus 合作伙伴,已第一時間接入該模型,價格與官網持平。Seed 2.0 Pro 和 Lite 預計將在後續陸續上線,屆時 API易 也將同步支持。
Q2: Seed 2.0 Lite 在哪些場景下可以替代 Pro?
從基準數據來看,Lite 在多個維度已非常接近 Pro: WideSearch(74.5 vs 74.7)、MMLU-Pro(87.7 vs 87.0,Lite 甚至更高)、SWE-Bench(73.5 vs 76.5)。對於日常開發、文檔處理、信息搜索整合等任務,Lite 完全可以替代 Pro,同時節省顯著成本。只有在前沿數學推理(AIME 98.3 vs 93.0)和高難度競賽編程(Codeforces 3020 vs 2233)等極端場景下,Pro 纔有明顯優勢。
Q3: Seed 2.0 Mini 的 4 級推理模式如何影響選型?
Seed 2.0 Mini 支持 reasoning_effort 參數的 4 個檔位: minimal(無推理)、low、medium、hi。在 minimal 模式下,整體性能約爲 hi 模式的 85%,但 Token 消耗僅約 1/10。這意味着 Mini + minimal 模式可以覆蓋大量不需要深度推理的任務(分類、標註、格式化),而 Mini + hi 模式的表現已接近 Lite 的基準水平。通過 API易 apiyi.com 平臺可以靈活配置推理模式,實現精準的成本控制。
Q4: Seed 2.0 系列如何與 GPT 和 Claude 競爭?
從基準數據看,Seed 2.0 Pro 在多項評測中已達到 GPT-5.2 和 Gemini 3 Pro 的水平,LMSYS Arena 排名第 6(Text)和第 3-4(Vision)。但 Seed 2.0 的核心競爭力在於價格: Mini 的輸入價格 $0.1/M tokens 僅爲 GPT-5.2 的 1/17.5,Pro 的價格約爲 GPT-5.2 的 1/3.7。在性能接近的情況下,Seed 2.0 系列提供了極具競爭力的成本優勢。
Q5: 如何快速接入 Seed 2.0 Mini API?
Seed 2.0 Mini 兼容 OpenAI SDK 接口規範,遷移成本極低。只需修改 base_url 爲 https://api.apiyi.com/v1,model 設置爲 seed-2-0-mini-260215 即可。API易 apiyi.com 平臺提供開箱即用的統一接口,支持多種主流模型的切換調用,充值 100 美金可加贈 10% 起。
Seed 2.0 模型對比總結
Seed 2.0 系列是字節跳動 Seed 團隊推出的新一代大模型家族,三個核心成員各有明確定位: Pro 追求極致智能上限(AIME 98.3、Codeforces 3020),Lite 平衡性能與成本(SWE-Bench 73.5、WideSearch 74.5),Mini 聚焦高併發低延遲(RPM 30K、輸入僅 $0.1/M tokens)。
目前 Seed 2.0 Mini 已率先上線,通過 API易 apiyi.com 平臺即可快速接入,價格與 BytePlus 官網持平,充值還享額外優惠。Pro 和 Lite 版本將在後續陸續發佈,屆時開發者可通過同一平臺無縫切換和對比全系列模型。
參考資料
-
ByteDance Seed 2.0 官方頁面: 模型介紹和完整基準測試數據
- 鏈接:
seed.bytedance.com/en/seed2 - 說明: 包含 Pro、Lite、Mini 全系列評測對比
- 鏈接:
-
Seed 2.0 Model Card 技術白皮書: 詳細模型架構和評測方法
- 鏈接:
github.com/ByteDance-Seed/Seed2.0 - 說明: 包含訓練方法、評測數據集詳情
- 鏈接:
-
LMSYS Chatbot Arena: 全球最大規模人類偏好盲評
- 鏈接:
lmarena.ai - 說明: Seed 2.0 Pro Preview 排名 Text #6, Vision #3-4
- 鏈接:
-
Seed 2.0 Benchmarks Guide: 第三方評測彙總
- 鏈接:
digitalapplied.com/blog/bytedance-seed-2-doubao-ai-model-benchmarks-guide - 說明: 包含與 GPT-5.2、Claude Opus 4.5 的橫向對比
- 鏈接:
作者: APIYI Team | 瞭解更多 AI 模型 API 對比與選型指南,請訪問 API易 apiyi.com 技術博客