هل تختار نموذج Seed 2.0 بنسخة Pro، أم Lite، أم Mini؟ هذا هو الخيار الجوهري الذي يواجهه العديد من المطورين عند دمج أحدث نماذج اللغة الكبيرة من ByteDance. يقارن هذا المقال بين النماذج الثلاثة الكبرى: Seed 2.0 Pro، و Seed 2.0 Lite، و Seed 2.0 Mini، ويقدم توصيات محددة للاختيار بناءً على اختبارات القياس، والتكلفة، وقدرات نافذة السياق.
القيمة الجوهرية: بعد قراءة هذا المقال، ستعرف بوضوح أي إصدار من Seed 2.0 تختار لمختلف سيناريوهات العمل، وكيفية تحقيق أفضل توازن بين الأداء والتكلفة من خلال استراتيجية الطبقات.
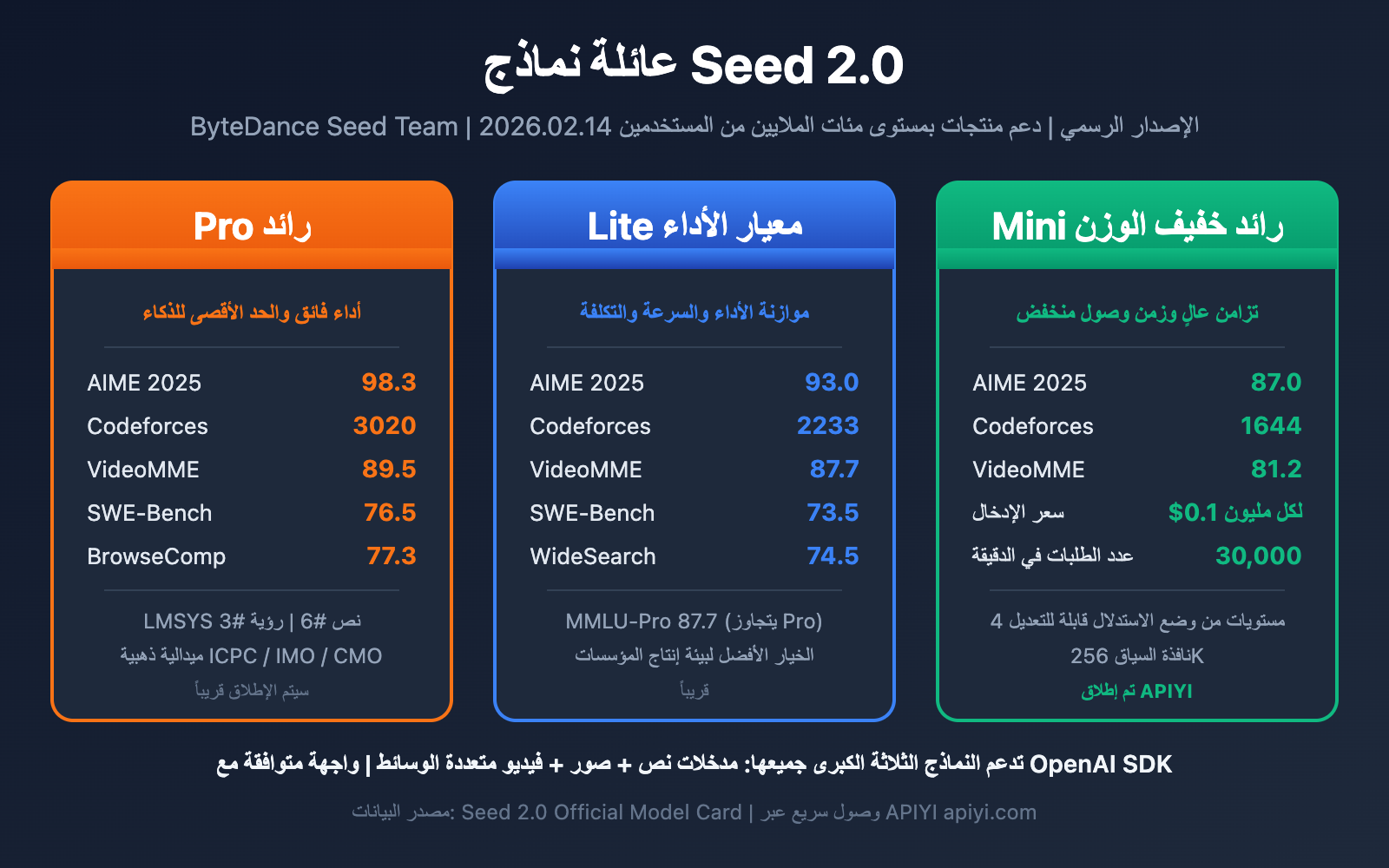
نظرة عامة على عائلة نماذج Seed 2.0
أطلق فريق Seed من ByteDance رسمياً سلسلة نماذج Seed 2.0 في 14 فبراير 2026. تعد هذه السلسلة الجيل الجديد من عائلة النماذج الأساسية متعددة الوسائط من ByteDance، والتي تدعم بالفعل مئات الملايين من مستخدمي منتجات مثل Doubao، وتتصدر المراتب الأولى في مختلف التقييمات العامة العالمية.
تضم عائلة Seed 2.0 ثلاثة أعضاء رئيسيين، لكل منهم توجه وسيناريوهات استخدام محددة:
| النموذج | التوجه | المزايا الجوهرية | المستخدمون المستهدفون |
|---|---|---|---|
| Seed 2.0 Pro | النموذج الرائد | أداء فائق وأقصى حدود الذكاء | المهام الاحترافية عالية التعقيد والقيمة |
| Seed 2.0 Lite | معيار الكفاءة | توازن بين الأداء والسرعة والتكلفة | النماذج العامة على مستوى المؤسسات |
| Seed 2.0 Mini | رائد الخفة | تزامن عالي وزمن انتقال منخفض | التطبيقات ذات الاستجابة السريعة والإنتاجية العالية |
خضعت النماذج الثلاثة لتحسينات نظامية، حيث تتمتع جميعها بقدرات قوية في الفهم متعدد الوسائط (دعم إدخال النصوص والصور والفيديو)، مع ترقية شاملة في أبعاد الاستدلال اللغوي، وتوليد الأكواد، واستدعاء أدوات الوكيل (Agent).
أداء Seed 2.0 Pro Preview في التقييمات العالمية
حققت نسخة Preview من Seed 2.0 Pro نتائج رائدة في أكثر أنظمة التقييم موثوقية في العالم:
- LMSYS Chatbot Arena: المرتبة السادسة في القائمة العامة لـ Text Arena، والمرتبة 3-4 في Vision Arena (حتى فبراير 2026).
- مسابقات الرياضيات: حصل على 98.3 في AIME 2025، و97.3 في HMMT Feb، وحصد ميداليات ذهبية في مسابقات ICPC وIMO وCMO.
- أكثر من 100 اختبار مرجعي عام: وصل إلى الفئة الأولى عالمياً في التقييمات الشاملة التي تغطي الاستدلال اللغوي، والفهم البصري، وقدرات الوكيل (Agent).
🎯 نصيحة تقنية: تم إطلاق Seed 2.0 Mini أولاً عبر منصة BytePlus. وبصفتها شريكاً لـ BytePlus، قامت منصة APIYI بدمج هذا النموذج فور صدوره. يمكن للمطورين تجربة القدرات الكاملة لـ Seed 2.0 Mini بسرعة عبر منصة APIYI (apiyi.com)، وستتوفر نسخ Pro وLite تباعاً في وقت لاحق.
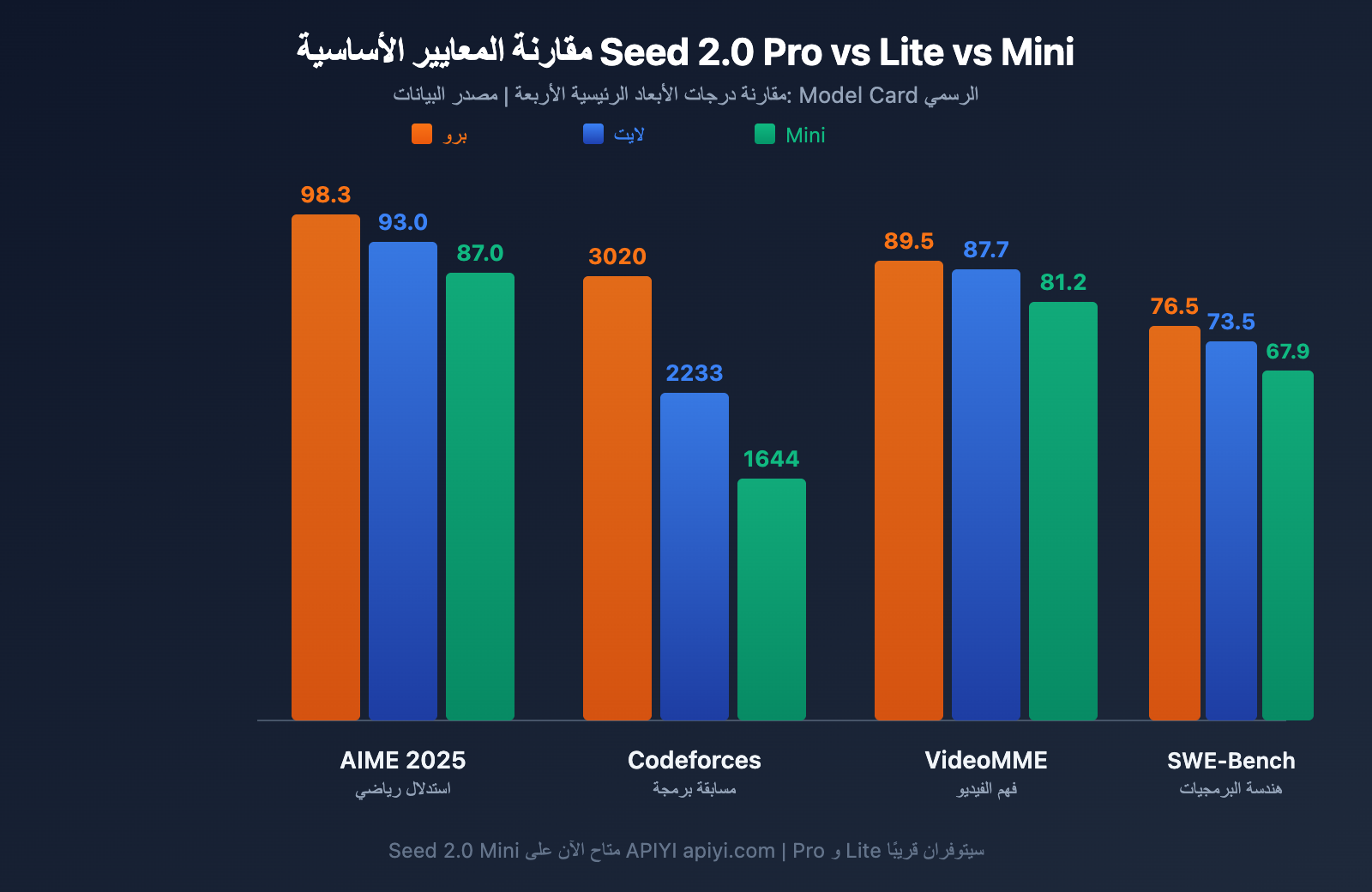
مقارنة المعايير الأساسية: Seed 2.0 Pro مقابل Lite مقابل Mini
فيما يلي مقارنة كاملة لدرجات النماذج الثلاثة في أبعاد التقييم الرئيسية. البيانات مستمدة من بطاقة تعريف نموذج Seed 2.0 الرسمية من ByteDance وتقييمات الجهات الخارجية.
مقارنة قدرات الرياضيات والاستدلال في Seed 2.0
| بند التقييم | Seed 2.0 Pro | Seed 2.0 Lite | Seed 2.0 Mini | الوصف |
|---|---|---|---|---|
| AIME 2025 | 98.3 | 93.0 | 87.0 | مسابقة الرياضيات الأمريكية للمدعوين |
| AIME 2026 | 94.2 | 88.3 | 86.7 | أحدث مسابقة رياضيات سنوية |
| GPQA Diamond | 88.9 | 85.1 | 79.0 | أسئلة وأجوبة بمستوى الدراسات العليا |
| MMLU-Pro | 87.0 | 87.7 | 83.6 | فهم المعرفة المهنية |
| HMMT Feb | 97.3 | 90.0 | 70.0 | بطولة هارفارد-MIT للرياضيات |
| MathVision | 88.8 | 86.4 | 78.1 | الاستدلال الرياضي البصري |
بناءً على بيانات الاستدلال الرياضي، تشكل النماذج الثلاثة فئات واضحة:
- فئة Pro: حققت 98.3 في AIME 2025 و97.3 في HMMT، مما يمثل سقف الاستدلال الرياضي للنماذج اللغوية الكبيرة الحالية، وتنافس بشكل مباشر GPT-5.2 وGemini 3 Pro.
- فئة Lite: حققت 93.0 في AIME 2025، بل وتفوقت قليلاً على Pro في MMLU-Pro بنتيجة 87.7 مقابل 87.0، مما يشير إلى أن Lite يقترب من المستوى الرائد في مهام فهم المعرفة.
- فئة Mini: حققت 87.0 في AIME 2025، وهي نتيجة ممتازة جداً لنموذج يستهدف الخفة والتزامن العالي.
مقارنة القدرات البرمجية والهندسية في Seed 2.0
| بند التقييم | Seed 2.0 Pro | Seed 2.0 Lite | Seed 2.0 Mini | الوصف |
|---|---|---|---|---|
| Codeforces | 3020 | 2233 | 1644 | تصنيف البرمجة التنافسية |
| LiveCodeBench v6 | 87.8 | 81.7 | 64.1 | تقييم البرمجة في الوقت الفعلي |
| SWE-Bench Verified | 76.5 | 73.5 | 67.9 | مهام هندسة البرمجيات الواقعية |
فيما يتعلق بالقدرات البرمجية، وصل تصنيف Pro في Codeforces إلى 3020، وهو مستوى الميدالية الذهبية في المسابقات الدولية. والجدير بالذكر هو الفجوة في SWE-Bench Verified: حيث سجل Pro 76.5 مقابل 73.5 لـ Lite و67.9 لـ Mini، مما يعني أن الفجوة في مهام هندسة البرمجيات الواقعية أصغر بكثير منها في البرمجة التنافسية، وهذا يؤكد الفائدة الكبيرة لـ Lite وMini في سيناريوهات التطوير اليومية.
مقارنة الفهم متعدد الوسائط والفيديو في Seed 2.0
| بند التقييم | Seed 2.0 Pro | Seed 2.0 Lite | Seed 2.0 Mini | الوصف |
|---|---|---|---|---|
| MMMU | 85.4 | 83.7 | 79.7 | الفهم متعدد الوسائط |
| MMMU-Pro | 78.2 | 76.0 | 71.4 | الفهم المهني متعدد الوسائط |
| VideoMME | 89.5 | 87.7 | 81.2 | تحليل محتوى الفيديو |
| MotionBench | 75.2 | 70.9 | 64.4 | إدراك الحركة |
| TempCompass | 89.6 | 87.0 | 83.7 | الاستدلال الزمني |
تعد الوسائط المتعددة إحدى المزايا الجوهرية لسلسلة Seed 2.0. أظهر Pro قدرة فائقة في فهم الفيديو بنتيجة 89.5 في VideoMME، حيث تجاوزت قدراته في إدراك الحركة والاستدلال الزمني مستوى البشر الأساسي. ويأتي Lite خلف Pro مباشرة في فهم الفيديو (87.7) والاستدلال الزمني (87.0)، مما يجعله خياراً عالي الكفاءة من حيث التكلفة لسيناريوهات تحليل الفيديو في المؤسسات.
مقارنة قدرات الوكيل (Agent) في Seed 2.0
| بند التقييم | Seed 2.0 Pro | Seed 2.0 Lite | Seed 2.0 Mini | الوصف |
|---|---|---|---|---|
| BrowseComp | 77.3 | 72.1 | 48.1 | فهم تصفح الويب |
| Terminal Bench | 55.8 | 45.0 | 36.9 | القدرة على تشغيل المحطة الطرفية |
| WideSearch | 74.7 | 74.5 | 37.7 | مهام البحث واسع النطاق |
| HLE-Verified | 73.6 | 70.7 | 56.4 | التحقق من الاستدلال عالي الصعوبة |
تعد قدرات الوكيل (Agent) البعد الحاسم للتمييز بين النماذج الثلاثة. الفجوة بين Pro وLite في BrowseComp وWideSearch ضئيلة جداً (74.7 لـ Pro مقابل 74.5 لـ Lite)، مما يعني أن Lite يقترب من المستوى الرائد في البحث الذاتي وتكامل المعلومات. أما Mini، فقد سجل درجات منخفضة بشكل ملحوظ في مهام الوكيل، مما يجعله مناسباً كطرف تنفيذي (لمعالجة التعليمات البسيطة) في أنظمة الوكلاء بدلاً من كونه طرفاً لاتخاذ القرار.
المواصفات التفصيلية لبطاقة نموذج Seed 2.0 Mini
يُعد Seed 2.0 Mini أول نموذج من سلسلة Seed 2.0 يتم إطلاقه حاليًا عبر منصة APIYI. فيما يلي المواصفات الكاملة للنموذج:
| المعامل | المواصفات |
|---|---|
| معرف النموذج (Model ID) | seed-2-0-mini-260215 |
| تسعير النموذج (الموجه ≤ 128K) | الإدخال: $0.1 لكل مليون رمز (Token)، الإخراج: $0.4 لكل مليون رمز (Token) |
| نوع الإدخال | نص + صور + فيديو |
| نوع الإخراج | نص |
| نافذة السياق | 256K |
| أقصى رموز للإدخال | 256K |
| أقصى رموز للإخراج | 128K |
| أقصى رموز للتفكير | 128K |
| الرموز في الدقيقة (TPM) | 1,500K |
| الطلبات في الدقيقة (RPM) | 30K |
| وضع الاستدلال | 4 مستويات قابلة للتعديل: minimal / low / medium / hi |
| المنصات المتاحة | APIYI apiyi.com (شريك BytePlus) |
يتميز تسعير Seed 2.0 Mini بتنافسية عالية جدًا: $0.1 لكل مليون رمز للإدخال و$0.4 لكل مليون رمز للإخراج. وللمقارنة، يبلغ سعر الإدخال في GPT-5.2 حوالي $1.75 لكل مليون رمز، وفي Claude Opus 4.5 يصل إلى $5.0 لكل مليون رمز. هذا يعني أن تكلفة الإدخال في Seed 2.0 Mini تبلغ 1/17.5 فقط من تكلفة GPT-5.2، مما يوفر قيمة استثنائية مقابل السعر.
💰 تحسين التكلفة: بالنسبة للمشاريع الحساسة للتكلفة، يوفر Seed 2.0 Mini كفاءة اقتصادية قصوى. من خلال الوصول عبر منصة APIYI (apiyi.com)، تظل الأسعار مطابقة للموقع الرسمي لـ BytePlus، مع إمكانية الحصول على رصيد إضافي يبدأ من 10% عند شحن 100 دولار، مما يعادل خصمًا يصل إلى 20%.
توصيات اختيار سيناريوهات Seed 2.0
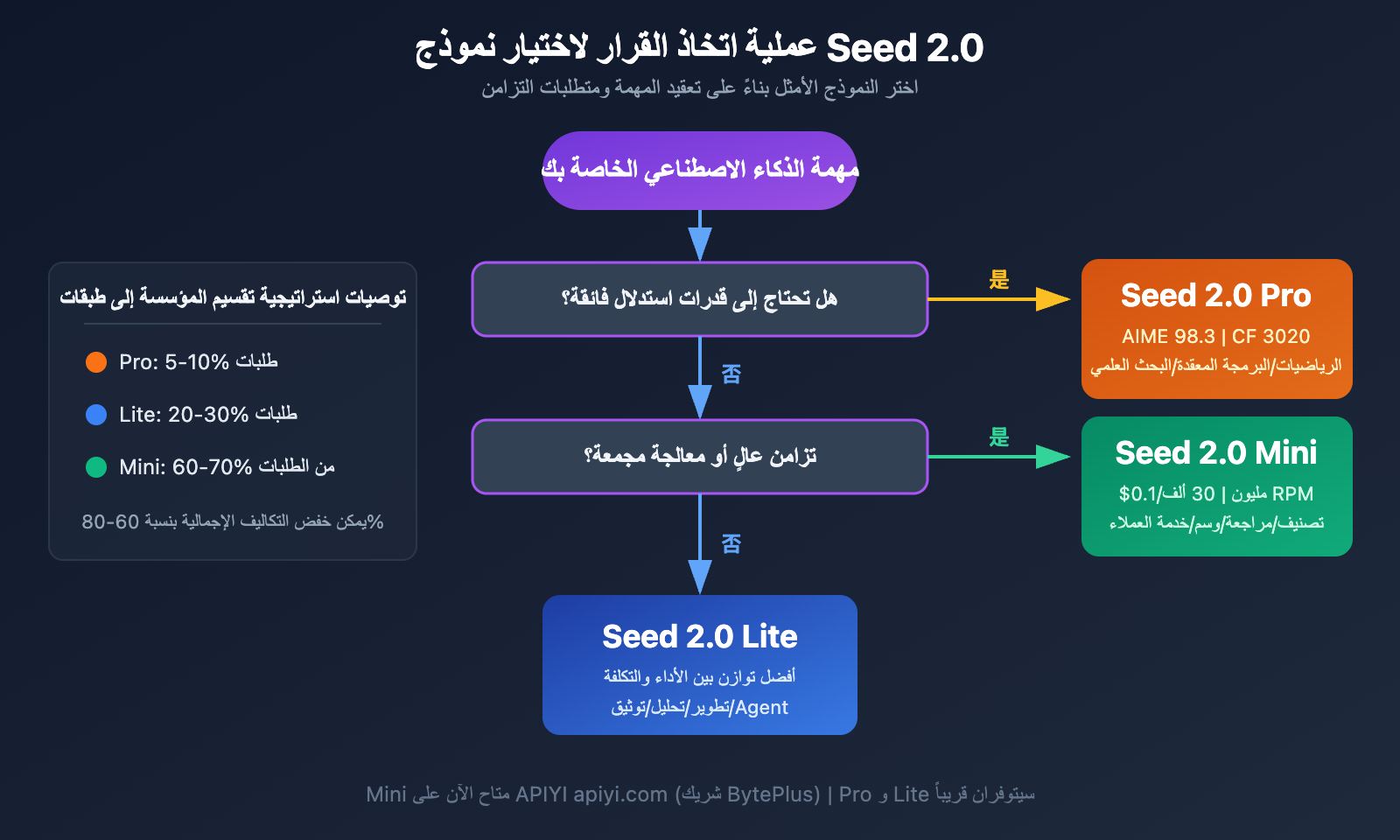
سيناريوهات اختيار Seed 2.0 Pro
يُعد Seed 2.0 Pro الخيار الرائد لمن يسعون للوصول إلى أقصى حدود الذكاء، وهو مناسب للسيناريوهات عالية القيمة التالية:
- البحث العلمي المتقدم: إثبات النظريات الرياضية، الاستدلال العلمي، والمساعدة في كتابة الأوراق البحثية (AIME 98.3, GPQA 88.9).
- البرمجة عالية الصعوبة: مسابقات الخوارزميات، وتصميم بنية الأنظمة المعقدة (Codeforces 3020).
- مهام الوكلاء (Agents) العميقة: التصفح الذاتي، البحث متعدد الخطوات، وتنسيق الأدوات المعقدة (BrowseComp 77.3, WideSearch 74.7).
- تحليل الفيديو الاحترافي: فهم الفيديوهات الطويلة، إدراك الحركة، والاستدلال الزمني (VideoMME 89.5).
- الذكاء الاصطناعي لمستوى اتخاذ القرار: قرارات الأعمال الجوهرية التي تتطلب أعلى جودة استدلال.
سيناريوهات اختيار Seed 2.0 Lite
يُعد Seed 2.0 Lite الخيار الأمثل للتوازن في بيئات الإنتاج للمؤسسات:
- المهام العامة للمؤسسات: تطوير الأكواد اليومية، معالجة المستندات، وتحليل البيانات (SWE-Bench 73.5).
- توليد المحتوى: النصوص الإعلانية التجارية، الوثائق التقنية، وتوليد التقارير (MMLU-Pro 87.7).
- الأعمال متعددة الوسائط: فهم الصور والنصوص، ملخصات الفيديو، وتحليل المستندات (MMMU 83.7, VideoMME 87.7).
- سير عمل الوكلاء (Agents): مساعدي البحث، دمج المعلومات، واستدعاء الأدوات (WideSearch 74.5، وهو أداء يقارب Pro تقريبًا).
- مهام الاستدلال الحساسة للتكلفة: للمؤسسات المتوسطة والكبيرة التي تحتاج إلى جودة عالية بميزانية محدودة.
سيناريوهات اختيار Seed 2.0 Mini
يُعد Seed 2.0 Mini الخيار الأفضل للسيناريوهات ذات الطلبات المتزامنة العالية والتكلفة المنخفضة:
- المعالجة الدفعية للمحتوى: تصنيف النصوص، تحليل المشاعر، واستخراج الكلمات المفتاحية (RPM 30K, TPM 1500K).
- تدقيق المحتوى: مراجعة الصور، فحص الفيديوهات، والكشف عن الامتثال (تقليل الأنماط الشاذة بنسبة 40%).
- خدمة العملاء الفورية: المحادثات عالية الكثافة، الرد الآلي على الأسئلة الشائعة، والتوجيه الذكي.
- المساعدة في وسم البيانات: الوسم الجماعي، تحويل التنسيقات، والمخرجات الهيكلية.
- مهام البرمجة الخفيفة: إكمال الكود، إصلاح الأخطاء البسيطة، ومراجعة الكود (SWE-Bench 67.9).
- سيناريوهات الأولوية للتكلفة: تكلفة $0.1 فقط لكل مليون رمز (إدخال)، مما يوفر كفاءة اقتصادية قصوى.
💡 نصيحة الاختيار: يعتمد اختيار أي نموذج من سلسلة Seed 2.0 بشكل أساسي على مدى تعقيد مهمتك واحتياجاتك من حيث عدد الطلبات المتزامنة. بالنسبة لمعظم المؤسسات، ننصح باعتماد استراتيجية طبقية تعتمد على "Lite كقوة أساسية + Mini كمساعد". من خلال منصة APIYI (apiyi.com)، يمكنك البدء بتجربة Seed 2.0 Mini الآن، وسيتم دعم نسختي Pro و Lite فور إطلاقهما.
مقترحات اتخاذ القرار لمقارنة نماذج Seed 2.0
استراتيجية النشر الطبقي لـ Seed 2.0
بالنسبة للشركات التي ترغب في الموازنة بين الجودة والتكلفة في آن واحد، نوصي بتبني البنية الطبقية التالية:
طبقة اتخاذ القرار (Pro) — تمثل 5-10% من حجم الطلبات:
تُستخدم لمعالجة المهام الجوهرية التي تتطلب أعلى جودة استدلال، مثل الاستدلال المعقد، والقرارات الحاسمة، وتوليد المحتوى عالي القيمة. تضمن نتائج Pro في اختبارات AIME (98.3) وCodeforces (3020) مخرجات بأعلى جودة ممكنة.
طبقة التنفيذ (Lite) — تمثل 20-30% من حجم الطلبات:
تُستخدم للمهام اليومية متوسطة التعقيد، مثل تطوير البرمجيات، وإنشاء المستندات، والتحليل متعدد الوسائط. تشير نتائج Lite في SWE-Bench (73.5) وWideSearch (74.5) إلى موثوقية عالية في سيناريوهات العمل الفعلية، وبتكلفة أقل بكثير من Pro.
طبقة الإنتاجية (Mini) — تمثل 60-70% من حجم الطلبات:
تُستخدم للمهام المتكررة والضخمة والموحدة، مثل التصنيف والوسم، ومراجعة المحتوى، وتحويل التنسيقات. توفر نسخة Mini قدرة إنتاجية هائلة مع RPM يصل إلى 30K وTPM يصل إلى 1500K، كما أن سعر الإدخال البالغ 0.1 دولار لكل مليون توكن يمنحها ميزة تنافسية قوية.
مقارنة أسعار Seed 2.0 مقابل المنافسين
| النموذج | سعر الإدخال ($/مليون توكن) | سعر الإخراج ($/مليون توكن) | التموضع |
|---|---|---|---|
| Seed 2.0 Mini | $0.10 | $0.40 | خفيف وعالي التوازي |
| GPT-4.1 mini | $0.40 | $1.60 | خفيف للأغراض العامة |
| GPT-5.2 | $1.75 | $14.00 | رائد في الاستدلال |
| Claude Sonnet 4.6 | $3.00 | $15.00 | متوازن وفعال |
| Claude Opus 4.5 | $5.00 | $25.00 | استدلال فائق |
| Gemini 3 Pro | $1.25 | $10.00 | رائد متعدد الوسائط |
يبلغ سعر إدخال Seed 2.0 Mini ربع سعر GPT-4.1 mini فقط، وكذلك سعر الإخراج. وبالمقارنة مع GPT-5.2، فإن تكلفة الإدخال أقل بـ 17.5 مرة، وتكلفة الإخراج أقل بـ 35 مرة، مما يمنحها تفوقاً كاسحاً من حيث القيمة مقابل السعر.
الأسئلة الشائعة حول مقارنة نماذج Seed 2.0
س1: هل Seed 2.0 Mini هو الإصدار الوحيد المتاح حالياً؟
نعم، اعتباراً من فبراير 2026، يعد Seed 2.0 Mini (معرف النموذج: seed-2-0-mini-260215) أول نموذج من سلسلة Seed 2.0 يتم إطلاقه عبر منصة BytePlus. وبصفتها شريكاً لـ BytePlus، قامت منصة APIYI (apiyi.com) بإتاحة هذا النموذج فور صدوره وبنفس الأسعار الرسمية. ومن المتوقع إطلاق نسختي Seed 2.0 Pro وLite لاحقاً، وستقوم APIYI بدعمهما في الوقت ذاته.
س2: في أي سيناريوهات يمكن لنسخة Seed 2.0 Lite أن تحل محل Pro؟
بناءً على البيانات المعيارية، تقترب نسخة Lite جداً من Pro في عدة أبعاد: WideSearch (74.5 مقابل 74.7)، MMLU-Pro (87.7 مقابل 87.0، حيث تفوقت Lite قليلاً)، وSWE-Bench (73.5 مقابل 76.5). بالنسبة لمهام التطوير اليومية، ومعالجة المستندات، ودمج البحث عن المعلومات، يمكن لـ Lite أن تحل محل Pro تماماً مع توفير تكاليف كبيرة. تظهر ميزة Pro بوضوح فقط في السيناريوهات القصوى مثل الاستدلال الرياضي المتقدم (AIME 98.3 مقابل 93.0) وبرمجة المسابقات عالية الصعوبة (Codeforces 3020 مقابل 2233).
س3: كيف تؤثر مستويات الاستدلال الأربعة في Seed 2.0 Mini على اختيار النموذج؟
يدعم Seed 2.0 Mini بارامتر reasoning_effort بأربعة مستويات: minimal (بدون استدلال)، low، medium، وhi. في وضع minimal، يصل الأداء العام إلى حوالي 85% من وضع hi، لكن استهلاك التوكن يبلغ حوالي 1/10 فقط. وهذا يعني أن وضع Mini + minimal يمكنه تغطية عدد كبير من المهام التي لا تتطلب استدلالاً عميقاً (مثل التصنيف، والوسم، والتنسيق)، بينما يقترب أداء Mini + hi من المستوى المعياري لنسخة Lite. يمكنك عبر منصة APIYI (apiyi.com) تهيئة أوضاع الاستدلال بمرونة لتحقيق تحكم دقيق في التكاليف.
س4: كيف تنافس سلسلة Seed 2.0 نماذج GPT وClaude؟
من حيث البيانات المعيارية، وصل Seed 2.0 Pro في العديد من التقييمات إلى مستوى GPT-5.2 وGemini 3 Pro، حيث احتل المرتبة السادسة في LMSYS Arena (للنصوص) والمرتبة 3-4 (للرؤية الحاسوبية). لكن القوة الجوهرية لـ Seed 2.0 تكمن في السعر: سعر إدخال Mini البالغ 0.1 دولار لكل مليون توكن يمثل 1/17.5 فقط من سعر GPT-5.2، وسعر Pro يمثل حوالي 1/3.7 من سعر GPT-5.2. مع تقارب الأداء، توفر سلسلة Seed 2.0 ميزة تنافسية هائلة في التكلفة.
س5: كيف يمكنني الوصول بسرعة إلى API الخاص بـ Seed 2.0 Mini؟
يتوافق Seed 2.0 Mini مع مواصفات واجهة OpenAI SDK، مما يجعل تكلفة الانتقال منخفضة للغاية. كل ما عليك فعله هو تغيير base_url إلى https://api.apiyi.com/v1 وتعيين model إلى seed-2-0-mini-260215. توفر منصة APIYI (apiyi.com) واجهة موحدة جاهزة للاستخدام، تدعم التبديل بين مختلف النماذج الرائدة، مع مكافآت شحن تبدأ من 10% عند شحن 100 دولار.
ملخص مقارنة نماذج Seed 2.0
تُعد سلسلة Seed 2.0 الجيل الجديد من عائلة نماذج اللغة الكبيرة التي أطلقها فريق Seed من شركة ByteDance، حيث يتمتع كل عضو من الأعضاء الثلاثة الأساسيين بمكانة محددة: يسعى إصدار Pro إلى أقصى حدود الذكاء (AIME 98.3، Codeforces 3020)، بينما يوازن إصدار Lite بين الأداء والتكلفة (SWE-Bench 73.5، WideSearch 74.5)، ويركز إصدار Mini على التزامن العالي وزمن الاستجابة المنخفض (RPM 30K، وسعر المدخلات $0.1 فقط لكل مليون توكن).
حالياً، تم إطلاق Seed 2.0 Mini أولاً، ويمكن الوصول إليه بسرعة عبر منصة APIYI (apiyi.com)، وبسعر يطابق الموقع الرسمي لـ BytePlus، مع مزايا إضافية عند شحن الرصيد. سيتم إصدار نسختي Pro و Lite تباعاً في الفترة القادمة، وحينها سيتمكن المطورون من التبديل والمقارنة بين السلسلة الكاملة من النماذج بسلاسة عبر نفس المنصة.
المراجع
-
الصفحة الرسمية لـ ByteDance Seed 2.0: مقدمة عن النماذج وبيانات الاختبار المعياري الكاملة.
- الرابط:
seed.bytedance.com/en/seed2 - الوصف: يتضمن مقارنات تقييمية لسلسلة Pro و Lite و Mini بالكامل.
- الرابط:
-
الورقة البيضاء التقنية لبطاقة نموذج Seed 2.0: تفاصيل بنية النموذج وطرق التقييم.
- الرابط:
github.com/ByteDance-Seed/Seed2.0 - الوصف: يتضمن طرق التدريب وتفاصيل مجموعات بيانات التقييم.
- الرابط:
-
LMSYS Chatbot Arena: أكبر تقييم أعمى لتفضيلات البشر في العالم.
- الرابط:
lmarena.ai - الوصف: حصل Seed 2.0 Pro Preview على المركز السادس في النصوص (#6 Text)، والمركز الثالث إلى الرابع في الرؤية (#3-4 Vision).
- الرابط:
-
دليل الاختبارات المعيارية لـ Seed 2.0: ملخص تقييمات الطرف الثالث.
- الرابط:
digitalapplied.com/blog/bytedance-seed-2-doubao-ai-model-benchmarks-guide - الوصف: يتضمن مقارنة أفقية مع نماذج مثل GPT-5.2 و Claude Opus 4.5.
- الرابط:
المؤلف: فريق APIYI | لمزيد من المقارنات بين واجهات برمجة تطبيقات نماذج الذكاء الاصطناعي وأدلة الاختيار، يرجى زيارة المدونة التقنية لـ APIYI (apiyi.com).