¿Seed 2.0 Pro, Lite o Mini? Esta es la duda principal de muchos desarrolladores al integrar el último Modelo de Lenguaje Grande de ByteDance. En este artículo comparamos las tres variantes principales: Seed 2.0 Pro, Seed 2.0 Lite y Seed 2.0 Mini, ofreciendo recomendaciones claras basadas en pruebas de rendimiento, costes y capacidad de contexto.
Valor principal: Al terminar de leer, sabrás exactamente qué variante de Seed 2.0 elegir para cada escenario de tu negocio y cómo aplicar una estrategia de capas para optimizar la relación calidad-precio.

Resumen de la familia de modelos Seed 2.0
El equipo Seed de ByteDance lanzó oficialmente la serie de modelos Seed 2.0 el 14 de febrero de 2026. Se trata de la nueva generación de la familia de modelos base multimodales de ByteDance, que ya da soporte a cientos de millones de usuarios en productos como Doubao y se sitúa a la vanguardia de la industria en diversas evaluaciones públicas globales.
La familia Seed 2.0 consta de tres miembros principales, cada uno con un posicionamiento y escenarios de uso definidos:
| Modelo | Posicionamiento | Ventajas clave | Usuarios objetivo |
|---|---|---|---|
| Seed 2.0 Pro | Modelo insignia | Rendimiento extremo y máximo nivel de inteligencia | Tareas profesionales de alta complejidad y gran valor |
| Seed 2.0 Lite | Referente de eficiencia | Equilibrio entre rendimiento, velocidad y coste | Modelo de nivel de producción general para empresas |
| Seed 2.0 Mini | Pionero ligero | Alta concurrencia y baja latencia | Aplicaciones de respuesta rápida y alto rendimiento |
Los tres modelos han sido optimizados sistemáticamente y cuentan con una potente capacidad de comprensión multimodal (soportan entrada de texto, imagen y video), además de mejoras integrales en razonamiento lingüístico, generación de código e invocación de herramientas para agentes (Agents).
Rendimiento de Seed 2.0 Pro Preview en evaluaciones globales
La versión Preview de Seed 2.0 Pro ya ha alcanzado resultados líderes en los sistemas de evaluación más prestigiosos del mundo:
- LMSYS Chatbot Arena: 6.º puesto en el ranking general de Text Arena y 3.º-4.º puesto en Vision Arena (a febrero de 2026).
- Competiciones de matemáticas: Puntuación de 98.3 en AIME 2025 y 97.3 en HMMT Feb, obteniendo medallas de oro en competiciones como ICPC, IMO y CMO.
- Más de 100 benchmarks públicos: Se sitúa en el primer nivel mundial en evaluaciones integrales que abarcan razonamiento lingüístico, comprensión visual y capacidades de agentes.
🎯 Sugerencia técnica: Seed 2.0 Mini ya está disponible de forma prioritaria a través de la plataforma BytePlus. APIYI, como socio de BytePlus, ha integrado este modelo de inmediato. Los desarrolladores pueden experimentar rápidamente todas las capacidades de Seed 2.0 Mini a través de la plataforma APIYI apiyi.com; las versiones Pro y Lite se lanzarán próximamente.
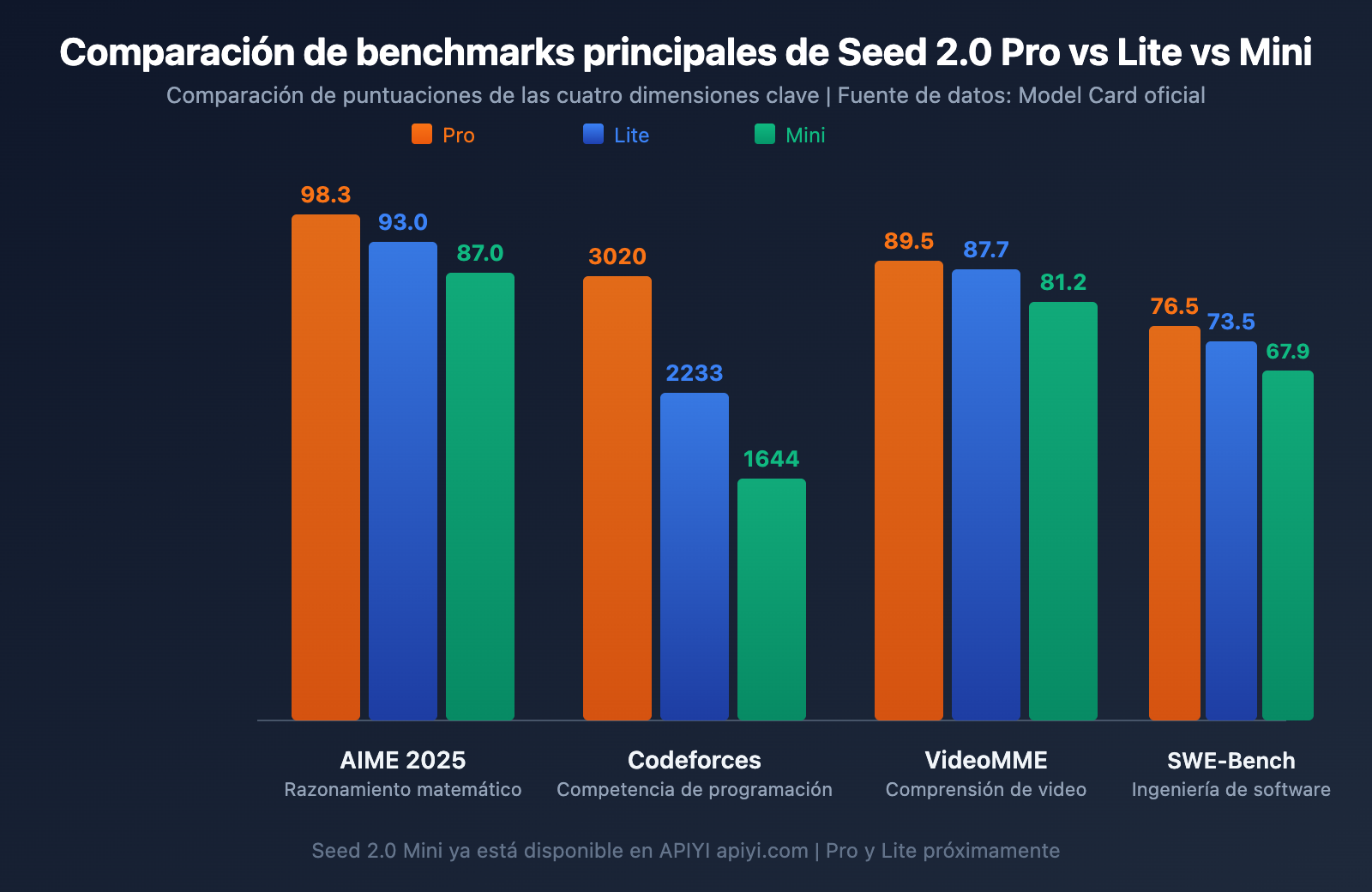
Comparativa de benchmarks principales: Seed 2.0 Pro vs Lite vs Mini
A continuación, se presenta una comparativa completa de las puntuaciones de los tres modelos en dimensiones clave de evaluación. Los datos provienen del Model Card oficial de Seed 2.0 de ByteDance y de evaluaciones de terceros.
Comparativa de razonamiento y matemáticas de Seed 2.0
| Ítem de evaluación | Seed 2.0 Pro | Seed 2.0 Lite | Seed 2.0 Mini | Descripción |
|---|---|---|---|---|
| AIME 2025 | 98.3 | 93.0 | 87.0 | Invitación Matemática de EE. UU. |
| AIME 2026 | 94.2 | 88.3 | 86.7 | Competición matemática anual más reciente |
| GPQA Diamond | 88.9 | 85.1 | 79.0 | Preguntas y respuestas de nivel de posgrado |
| MMLU-Pro | 87.0 | 87.7 | 83.6 | Comprensión de conocimientos profesionales |
| HMMT Feb | 97.3 | 90.0 | 70.0 | Torneo de Matemáticas Harvard-MIT |
| MathVision | 88.8 | 86.4 | 78.1 | Razonamiento matemático visual |
A partir de los datos de razonamiento matemático, los tres modelos forman niveles claramente diferenciados:
- Nivel Pro: Alcanza 98.3 en AIME 2025 y 97.3 en HMMT, representando el nivel máximo actual en razonamiento matemático para Modelos de Lenguaje Grande, compitiendo directamente con GPT-5.2 y Gemini 3 Pro.
- Nivel Lite: Logra 93.0 en AIME 2025, e incluso supera ligeramente al Pro en MMLU-Pro con un 87.7 frente a 87.0, lo que indica que en tareas de comprensión de conocimientos, Lite está muy cerca del nivel insignia.
- Nivel Mini: Obtiene un 87.0 en AIME 2025, una puntuación excelente para un modelo posicionado como ligero y de alta concurrencia.
Comparativa de capacidades de código e ingeniería de Seed 2.0
| Ítem de evaluación | Seed 2.0 Pro | Seed 2.0 Lite | Seed 2.0 Mini | Descripción |
|---|---|---|---|---|
| Codeforces | 3020 | 2233 | 1644 | Clasificación en programación competitiva |
| LiveCodeBench v6 | 87.8 | 81.7 | 64.1 | Evaluación de programación en tiempo real |
| SWE-Bench Verified | 76.5 | 73.5 | 67.9 | Tareas reales de ingeniería de software |
En cuanto a la capacidad de código, la clasificación de 3020 en Codeforces del modelo Pro alcanza el nivel de medalla de oro en competiciones internacionales. Es notable la diferencia en SWE-Bench Verified: Pro 76.5 vs Lite 73.5 vs Mini 67.9; la brecha en tareas reales de ingeniería de software es mucho menor que en programación competitiva, lo que demuestra la gran utilidad de Lite y Mini en escenarios de desarrollo cotidianos.
Comparativa multimodal y de comprensión de video de Seed 2.0
| Ítem de evaluación | Seed 2.0 Pro | Seed 2.0 Lite | Seed 2.0 Mini | Descripción |
|---|---|---|---|---|
| MMMU | 85.4 | 83.7 | 79.7 | Comprensión multimodal |
| MMMU-Pro | 78.2 | 76.0 | 71.4 | Comprensión multimodal profesional |
| VideoMME | 89.5 | 87.7 | 81.2 | Análisis de contenido de video |
| MotionBench | 75.2 | 70.9 | 64.4 | Percepción de movimiento |
| TempCompass | 89.6 | 87.0 | 83.7 | Razonamiento temporal |
La multimodalidad es una de las ventajas principales de la serie Seed 2.0. Los 89.5 puntos de Pro en VideoMME demuestran una capacidad superior de comprensión de video, con una percepción de movimiento y razonamiento temporal que incluso superan los niveles de referencia humanos. Lite sigue de cerca a Pro en comprensión de video (87.7) y razonamiento temporal (87.0), siendo una opción muy rentable para el análisis de video a nivel empresarial.
Comparativa de capacidades de Agente de Seed 2.0
| Ítem de evaluación | Seed 2.0 Pro | Seed 2.0 Lite | Seed 2.0 Mini | Descripción |
|---|---|---|---|---|
| BrowseComp | 77.3 | 72.1 | 48.1 | Comprensión de navegación web |
| Terminal Bench | 55.8 | 45.0 | 36.9 | Capacidad de operación en terminal |
| WideSearch | 74.7 | 74.5 | 37.7 | Tareas de búsqueda de amplio alcance |
| HLE-Verified | 73.6 | 70.7 | 56.4 | Verificación de razonamiento de alta dificultad |
La capacidad de actuar como agente es la dimensión clave que distingue a los tres modelos. La diferencia entre Pro y Lite en BrowseComp y WideSearch es mínima (Pro 74.7 vs Lite 74.5), lo que indica que Lite ya está cerca del nivel insignia en búsqueda autónoma e integración de información. Mini tiene puntuaciones significativamente más bajas en tareas de agentes, por lo que es más adecuado como extremo de ejecución (procesando instrucciones simples) en lugar de extremo de decisión en un sistema de agentes.
Especificaciones detalladas del modelo Seed 2.0 Mini
Seed 2.0 Mini es el primer modelo de la serie Seed 2.0 disponible actualmente en la plataforma APIYI. A continuación, se presentan los parámetros completos del modelo:
| Parámetro | Especificación |
|---|---|
| Model ID | seed-2-0-mini-260215 |
| Precios del modelo (Prompt ≤ 128K) | Entrada $0.1/M tokens, Salida $0.4/M tokens |
| Tipo de entrada | Texto + Imagen + Vídeo |
| Tipo de salida | Texto |
| Ventana de contexto | 256K |
| Tokens máximos de entrada | 256K |
| Tokens máximos de salida | 128K |
| Tokens máximos de razonamiento (Thinking) | 128K |
| TPM (Tokens por minuto) | 1,500K |
| RPM (Solicitudes por minuto) | 30K |
| Modo de inferencia | 4 niveles ajustables: minimal / low / medium / hi |
| Plataformas disponibles | APIYI apiyi.com (Socio de BytePlus) |
El precio de Seed 2.0 Mini es muy competitivo: $0.1 por millón de tokens de entrada y $0.4 por millón de tokens de salida. Como referencia, el precio de entrada de GPT-5.2 es de $1.75/M tokens, y el de Claude Opus 4.5 es de $5.0/M tokens. El coste de entrada de Seed 2.0 Mini es solo 1/17.5 del de GPT-5.2, lo que ofrece una relación calidad-precio excepcional.
💰 Optimización de costes: Para proyectos sensibles al presupuesto, Seed 2.0 Mini ofrece una rentabilidad extrema. Al acceder a través de la plataforma APIYI apiyi.com, los precios son los mismos que en el sitio oficial de BytePlus, y las recargas de 100 USD incluyen un bono adicional del 10% o más, lo que equivale a un descuento de hasta el 20%.
Guía de selección de escenarios Seed 2.0
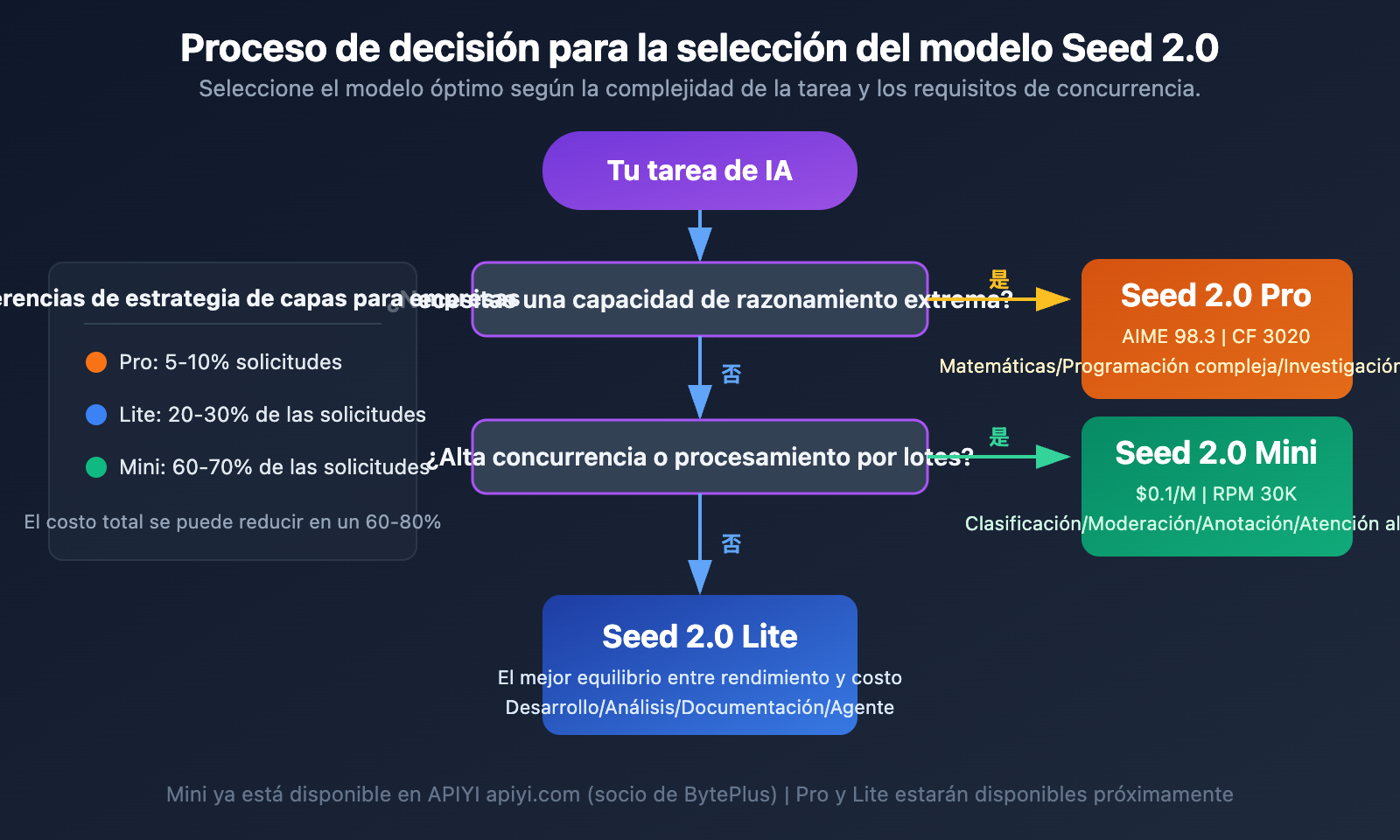
Escenarios para elegir Seed 2.0 Pro
Seed 2.0 Pro es la opción insignia para quienes buscan el límite máximo de inteligencia, ideal para los siguientes escenarios de alto valor:
- Investigación científica de vanguardia: Demostraciones matemáticas, razonamiento científico, asistencia en artículos académicos (AIME 98.3, GPQA 88.9).
- Programación de alta dificultad: Competiciones de algoritmos, diseño de arquitecturas de sistemas complejos (Codeforces 3020).
- Tareas profundas de Agentes: Navegación autónoma, búsqueda en múltiples pasos, orquestación de herramientas complejas (BrowseComp 77.3, WideSearch 74.7).
- Análisis de vídeo profesional: Comprensión de vídeos largos, percepción de movimiento, razonamiento temporal (VideoMME 89.5).
- IA para la toma de decisiones: Decisiones de negocio críticas que requieren la máxima calidad de razonamiento.
Escenarios para elegir Seed 2.0 Lite
Seed 2.0 Lite es la opción más equilibrada para entornos de producción empresarial:
- Tareas generales de nivel empresarial: Desarrollo de código diario, procesamiento de documentos, análisis de datos (SWE-Bench 73.5).
- Generación de contenido: Redacción publicitaria comercial, documentación técnica, generación de informes (MMLU-Pro 87.7).
- Negocios multimodales: Comprensión de imagen y texto, resúmenes de vídeo, análisis de documentos (MMMU 83.7, VideoMME 87.7).
- Flujos de trabajo de Agentes: Asistentes de búsqueda, integración de información, invocación de herramientas (WideSearch 74.5, casi al nivel de Pro).
- Tareas de razonamiento sensibles al coste: Empresas medianas y grandes que necesitan alta calidad pero con un presupuesto limitado.
Escenarios para elegir Seed 2.0 Mini
Seed 2.0 Mini es la mejor opción para escenarios de alta concurrencia y bajo coste:
- Procesamiento de contenido por lotes: Clasificación de texto, análisis de sentimientos, extracción de palabras clave (RPM 30K, TPM 1500K).
- Moderación de contenido: Revisión de imágenes, inspección de vídeos, detección de cumplimiento (reducción del 40% en patrones anómalos).
- Atención al cliente en tiempo real: Diálogos de alta concurrencia, respuesta automática a preguntas frecuentes (FAQ), enrutamiento inteligente.
- Asistencia en el etiquetado de datos: Etiquetado masivo, conversión de formatos, salida estructurada.
- Tareas de código ligeras: Autocompletado de código, corrección de errores simples, revisión de código (SWE-Bench 67.9).
- Escenarios donde el coste es la prioridad: Solo $0.1 por millón de tokens (entrada), rentabilidad extrema.
💡 Sugerencia de selección: La elección del modelo Seed 2.0 depende principalmente de la complejidad de su tarea y de sus necesidades de concurrencia. Para la mayoría de las empresas, recomendamos una estrategia por capas: "Lite como motor principal + Mini como apoyo". A través de la plataforma APIYI apiyi.com, ya puede experimentar con Seed 2.0 Mini, y las versiones Pro y Lite estarán disponibles tan pronto como se lancen.
Sugerencias de decisión y comparativa del modelo Seed 2.0
Estrategia de despliegue por capas de Seed 2.0
Para las empresas que necesitan equilibrar calidad y coste, se recomienda adoptar la siguiente arquitectura por capas:
Capa de decisión (Pro) — 5-10% del volumen de solicitudes:
Maneja tareas principales que requieren la máxima calidad de razonamiento, como razonamiento complejo, decisiones críticas y generación de contenido de alto valor. Los resultados de Pro en AIME (98.3) y Codeforces (3020) garantizan una salida de máxima calidad.
Capa de ejecución (Lite) — 20-30% del volumen de solicitudes:
Se encarga de tareas cotidianas de complejidad media, como desarrollo de código, generación de documentos y análisis multimodal. Los resultados de Lite en SWE-Bench (73.5) y WideSearch (74.5) demuestran que es muy fiable en escenarios de trabajo reales, con un coste muy inferior al de Pro.
Capa de rendimiento (Mini) — 60-70% del volumen de solicitudes:
Procesa tareas masivas, frecuentes y estandarizadas, como etiquetado de clasificación, moderación de contenido y conversión de formatos. El RPM de 30K y TPM de 1500K de Mini ofrecen una capacidad de procesamiento ultra alta, con un precio de entrada de $0.1/M tokens extremadamente competitivo.
Comparativa de precios: Seed 2.0 vs. Competencia
| Modelo | Precio de entrada ($/M tokens) | Precio de salida ($/M tokens) | Posicionamiento |
|---|---|---|---|
| Seed 2.0 Mini | $0.10 | $0.40 | Ligero, alta concurrencia |
| GPT-4.1 mini | $0.40 | $1.60 | Ligero, propósito general |
| GPT-5.2 | $1.75 | $14.00 | Insignia, razonamiento |
| Claude Sonnet 4.6 | $3.00 | $15.00 | Equilibrado y eficiente |
| Claude Opus 4.5 | $5.00 | $25.00 | Razonamiento extremo |
| Gemini 3 Pro | $1.25 | $10.00 | Insignia multimodal |
El precio de entrada de Seed 2.0 Mini es solo 1/4 del de GPT-4.1 mini, y su precio de salida es también 1/4. Comparado con GPT-5.2, el coste de entrada es 17.5 veces menor y el de salida 35 veces menor, lo que representa una ventaja abrumadora en términos de relación calidad-precio.
Preguntas frecuentes sobre la comparativa de modelos Seed 2.0
P1: ¿Es Seed 2.0 Mini la única versión disponible actualmente?
Sí, a partir de febrero de 2026, Seed 2.0 Mini (ID del modelo: seed-2-0-mini-260215) es el primer modelo de la serie Seed 2.0 lanzado a través de la plataforma BytePlus. APIYI (apiyi.com), como socio de BytePlus, ha integrado este modelo de inmediato, manteniendo los mismos precios que el sitio oficial. Se espera que Seed 2.0 Pro y Lite se lancen progresivamente, y APIYI les dará soporte de forma sincronizada.
P2: ¿En qué escenarios puede Seed 2.0 Lite sustituir a Pro?
Según los datos de referencia, Lite está muy cerca de Pro en varias dimensiones: WideSearch (74.5 vs 74.7), MMLU-Pro (87.7 vs 87.0, donde Lite es incluso superior) y SWE-Bench (73.5 vs 76.5). Para tareas de desarrollo diario, procesamiento de documentos e integración de búsqueda de información, Lite puede sustituir completamente a Pro, ahorrando costes significativos. Pro solo tiene una ventaja clara en escenarios extremos como razonamiento matemático de vanguardia (AIME 98.3 vs 93.0) y programación competitiva de alta dificultad (Codeforces 3020 vs 2233).
P3: ¿Cómo influyen los 4 niveles de razonamiento de Seed 2.0 Mini en la elección del modelo?
Seed 2.0 Mini admite 4 niveles para el parámetro reasoning_effort: minimal (sin razonamiento), low, medium y hi. En el modo minimal, el rendimiento general es aproximadamente el 85% del modo hi, pero el consumo de tokens es solo de 1/10. Esto significa que el modo Mini + minimal puede cubrir una gran cantidad de tareas que no requieren razonamiento profundo (clasificación, etiquetado, formateo), mientras que el rendimiento de Mini + hi ya se acerca al nivel base de Lite. A través de la plataforma APIYI (apiyi.com), puedes configurar de manera flexible el modo de razonamiento para lograr un control de costes preciso.
P4: ¿Cómo compite la serie Seed 2.0 con GPT y Claude?
Basándose en los datos de referencia, Seed 2.0 Pro ya ha alcanzado el nivel de GPT-5.2 y Gemini 3 Pro en múltiples evaluaciones, ocupando el 6º lugar en LMSYS Arena (Texto) y el 3º-4º (Visión). Sin embargo, la competitividad central de Seed 2.0 reside en el precio: el coste de entrada de Mini ($0.1/M tokens) es solo 1/17.5 del de GPT-5.2, y el precio de Pro es aproximadamente 1/3.7 del de GPT-5.2. Con un rendimiento similar, la serie Seed 2.0 ofrece una ventaja de costes extremadamente competitiva.
P5: ¿Cómo puedo integrar rápidamente la API de Seed 2.0 Mini?
Seed 2.0 Mini es compatible con las especificaciones de la interfaz del SDK de OpenAI, por lo que el coste de migración es mínimo. Solo necesitas cambiar el base_url a https://api.apiyi.com/v1 y configurar el model como seed-2-0-mini-260215. La plataforma APIYI (apiyi.com) ofrece una interfaz unificada lista para usar que admite la alternancia entre varios modelos principales, con bonificaciones a partir del 10% al recargar 100 dólares.
Resumen comparativo de los modelos Seed 2.0
La serie Seed 2.0 es la nueva generación de la familia de Modelos de Lenguaje Grande lanzada por el equipo Seed de ByteDance. Sus tres miembros principales tienen un posicionamiento claro: Pro busca el límite máximo de inteligencia (AIME 98.3, Codeforces 3020), Lite equilibra rendimiento y costo (SWE-Bench 73.5, WideSearch 74.5), y Mini se enfoca en alta concurrencia y baja latencia (RPM 30K, entrada a solo $0.1/M tokens).
Actualmente, Seed 2.0 Mini ya está disponible y puedes acceder a él rápidamente a través de la plataforma APIYI (apiyi.com). Los precios son los mismos que en el sitio oficial de BytePlus, y además obtienes descuentos adicionales al realizar tus recargas. Las versiones Pro y Lite se lanzarán próximamente; para entonces, los desarrolladores podrán alternar y comparar toda la serie de modelos sin complicaciones desde la misma plataforma.
Referencias
-
Página oficial de ByteDance Seed 2.0: Introducción al modelo y datos completos de benchmarks.
- Enlace:
seed.bytedance.com/en/seed2 - Descripción: Incluye la comparativa de evaluación de toda la serie Pro, Lite y Mini.
- Enlace:
-
Libro blanco técnico Seed 2.0 Model Card: Arquitectura detallada del modelo y métodos de evaluación.
- Enlace:
github.com/ByteDance-Seed/Seed2.0 - Descripción: Contiene métodos de entrenamiento y detalles de los conjuntos de datos de evaluación.
- Enlace:
-
LMSYS Chatbot Arena: La evaluación ciega de preferencias humanas a mayor escala global.
- Enlace:
lmarena.ai - Descripción: Seed 2.0 Pro Preview ocupa el puesto #6 en Texto y #3-4 en Visión.
- Enlace:
-
Seed 2.0 Benchmarks Guide: Recopilación de evaluaciones de terceros.
- Enlace:
digitalapplied.com/blog/bytedance-seed-2-doubao-ai-model-benchmarks-guide - Descripción: Incluye comparativas horizontales con GPT-5.2 y Claude Opus 4.5.
- Enlace:
Autor: APIYI Team | Para más comparativas de APIs de modelos de IA y guías de selección, visita el blog técnico de APIYI apiyi.com