Catatan Penulis: GPT-5.4 atau Claude Opus 4.6? Dua model AI unggulan yang paling dinanti di tahun 2026 ini saling berhadapan. Artikel ini merangkum data pengujian terbaru dari Chatbot Arena, SWE-bench, ARC-AGI-2, dan OpenClaw PinchBench, memberikan rekomendasi pilihan yang jelas dari empat dimensi: pemrograman, penalaran, tugas agen, dan efisiensi biaya.

GPT-5.4 vs Claude Opus 4.6: Sekilas Perbedaan Utama
Memilih model AI unggulan menjadi lebih mudah dengan melihat dimensi-dimensi kunci berikut:
| Dimensi Perbandingan | GPT-5.4 | Claude Opus 4.6 |
|---|---|---|
| Waktu Rilis | Akhir 2025 | Februari 2026 |
| Chatbot Arena ELO | 1463 | 1503 (#1) |
| Indeks Kecerdasan AI Komprehensif | 57 | 53 |
| Harga Input API | $2.50/M token | $5.00/M token |
| Harga Output API | $15.00/M token | $25.00/M token |
| Jendela Konteks | ~1M token | 200K (1M Beta) |
| Panjang Output Maksimum | — | 128K token |
| Status | Aktif | Aktif |
Kesimpulan Utama: GPT-5.4 memiliki indeks kecerdasan komprehensif yang lebih tinggi dengan harga sekitar 50% lebih murah; Claude Opus 4.6 menempati peringkat pertama dalam kepuasan pengguna Chatbot Arena secara global, serta lebih unggul dalam pemrograman kompleks dan tugas agen.
🎯 Saran Cepat: Jika Anda adalah pengembang yang mengutamakan efisiensi biaya, GPT-5.4 menawarkan nilai untuk uang yang lebih baik. Namun, jika proyek Anda memerlukan pembuatan kode yang kompleks atau pemrosesan dokumen panjang, Opus 4.6 lebih layak untuk diinvestasikan. Disarankan untuk mengakses kedua model ini secara bersamaan melalui APIYI (apiyi.com) untuk melakukan pengujian perbandingan langsung; platform ini mendukung peralihan cepat dengan antarmuka API yang seragam.
Benchmark Otoritatif: Perbandingan Menyeluruh GPT-5.4 vs Claude Opus 4.6
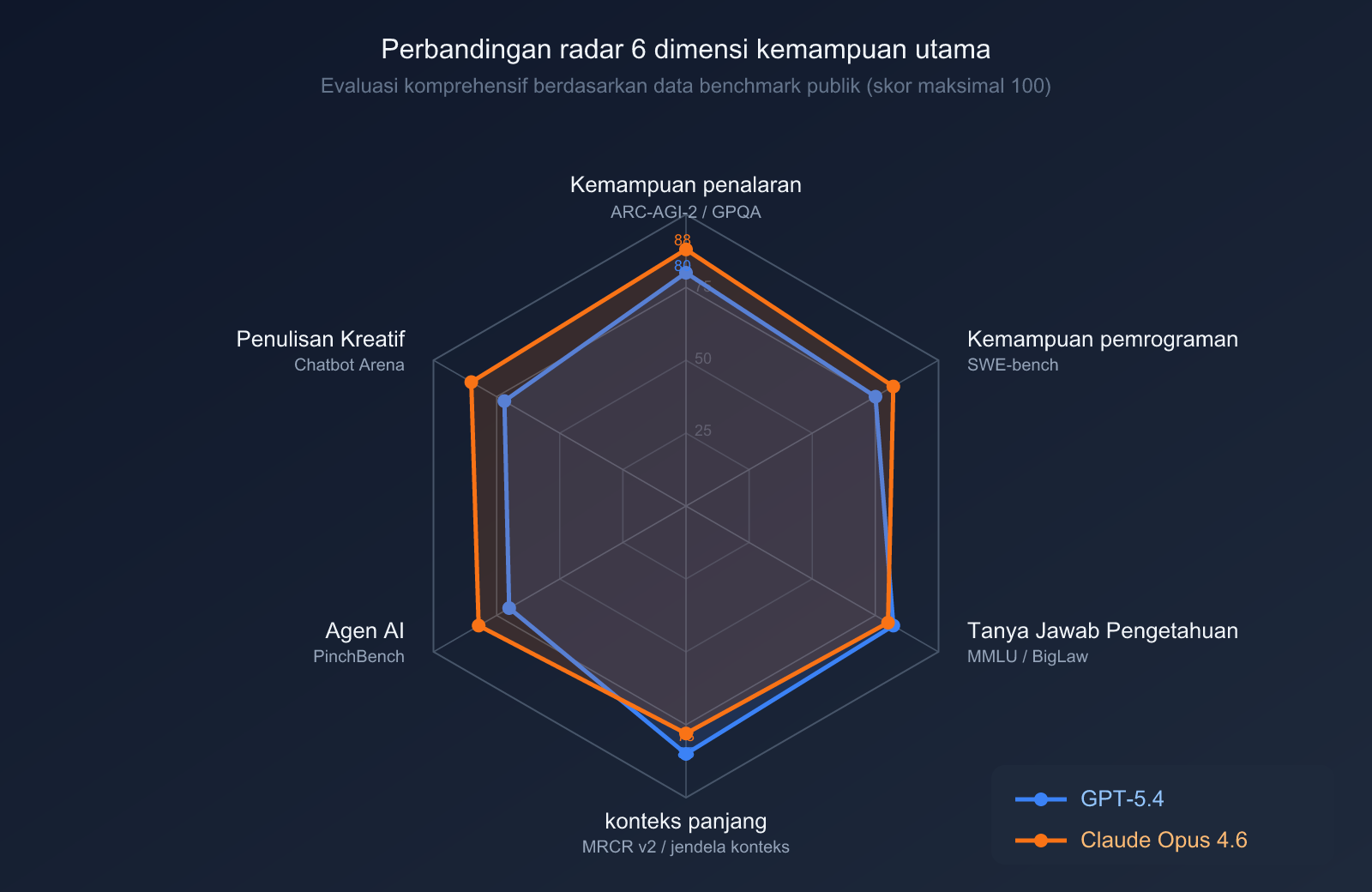
Perbandingan Kemampuan Penalaran dan Pengetahuan
| Benchmark | GPT-5.4 | Claude Opus 4.6 | Keterangan |
|---|---|---|---|
| GPQA Diamond (Soal sains tingkat pascasarjana) | 93.2% | 91.3% | GPT-5.4 unggul |
| MMLU (Pengetahuan ensiklopedis) | 89.6% | 91.1% | Opus 4.6 unggul |
| ARC-AGI-2 (Penalaran abstrak) | 52.9% | 68.8% | Opus 4.6 unggul jauh |
| BigLaw Bench (Profesional hukum) | — | 90.2% | Keunggulan khusus Opus 4.6 |
| MRCR v2 (1M Jendela konteks panjang) | — | 76% | Opus 4.6 unggul dalam dokumen sangat panjang |
| GDPval-AA ELO (Tugas profesional) | 1462 | 1606 | Opus 4.6 jauh lebih baik |
Interpretasi: GPT-5.4 memiliki keunggulan tipis dalam penalaran ilmiah (GPQA Diamond), namun dalam penalaran abstrak (ARC-AGI-2 unggul 16 poin persentase), pekerjaan pengetahuan profesional, dan pemrosesan jendela konteks panjang, Claude Opus 4.6 menunjukkan performa yang lebih kuat.
Perbandingan Kemampuan Pemrograman dan Agen
| Benchmark | GPT-5.4 | Claude Opus 4.6 | Keterangan |
|---|---|---|---|
| SWE-bench Verified (Perbaikan kode nyata) | ~77.2% | 80.8% | Opus 4.6 unggul |
| SWE-bench Pro (Kode tingkat profesional) | 57.7% | ~45% | GPT-5.4 unggul |
| Terminal-Bench 2.0 (Operasi terminal) | 64.7% | 65.4% | Opus 4.6 unggul tipis |
| OSWorld (Kontrol komputer) | 75.0% | 72.7% | GPT-5.4 unggul tipis |
| BrowseComp (Riset pencarian web) | 77.9% | 84.0% | Opus 4.6 unggul |
| OpenRCA (Analisis akar masalah) | — | 34.9% | Keunggulan khusus Opus 4.6 |
Interpretasi: Kedua model memiliki fokus yang berbeda dalam hal pemrograman. Untuk SWE-bench Verified (perbaikan kode harian), Opus 4.6 lebih kuat; untuk SWE-bench Pro (kode kompleks tingkat perusahaan), GPT-5.4 memimpin; dalam kontrol komputer GPT-5.4 menang tipis, namun Opus 4.6 sangat menonjol dalam riset web dan analisis akar masalah.
💡 Saran Pengembang: Untuk tugas pembuatan kode yang berorientasi pada pengiriman produk, disarankan untuk menguji kedua model secara terpisah melalui antarmuka terpadu APIYI apiyi.com, lalu buat keputusan berdasarkan karakteristik basis kode spesifik Anda. Biayanya hanya sekitar 60-80% dari pemanggilan model langsung ke API resmi Anthropic/OpenAI.
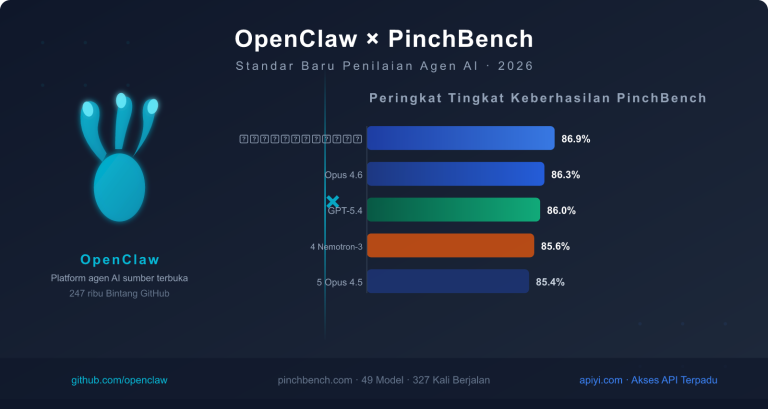
Praktik Agen Cerdas OpenClaw: Data Pengujian Terbaru PinchBench
Apa itu OpenClaw dan PinchBench?
OpenClaw adalah platform agen AI sumber terbuka yang bisa di-host sendiri (mirip dengan Claude Code). Platform ini mendukung akses terminal, pengeditan multi-file, serta integrasi dengan lebih dari 50 alat seperti WhatsApp, Telegram, dan Slack. Dibuat oleh pengembang asal Austria, Peter Steinberger, pada November 2025, proyek ini berkembang pesat di GitHub.
PinchBench adalah tolok ukur (benchmark) evaluasi yang dirancang khusus untuk agen OpenClaw, dikembangkan oleh Kilo.ai. Berbeda dengan benchmark tradisional yang hanya menguji tanya-jawab tunggal, PinchBench menguji performa model dalam tugas multi-langkah di dunia nyata:
- Mengatur pertemuan dan mengelola kalender
- Menulis proyek kode multi-file
- Klasifikasi email dan manajemen file
- Riset web dan integrasi informasi
Ini adalah salah satu pengujian yang paling mendekati skenario penggunaan Agen AI yang sebenarnya saat ini.
Papan Peringkat PinchBench (13 Maret 2026, 47 model, 277 pengujian)
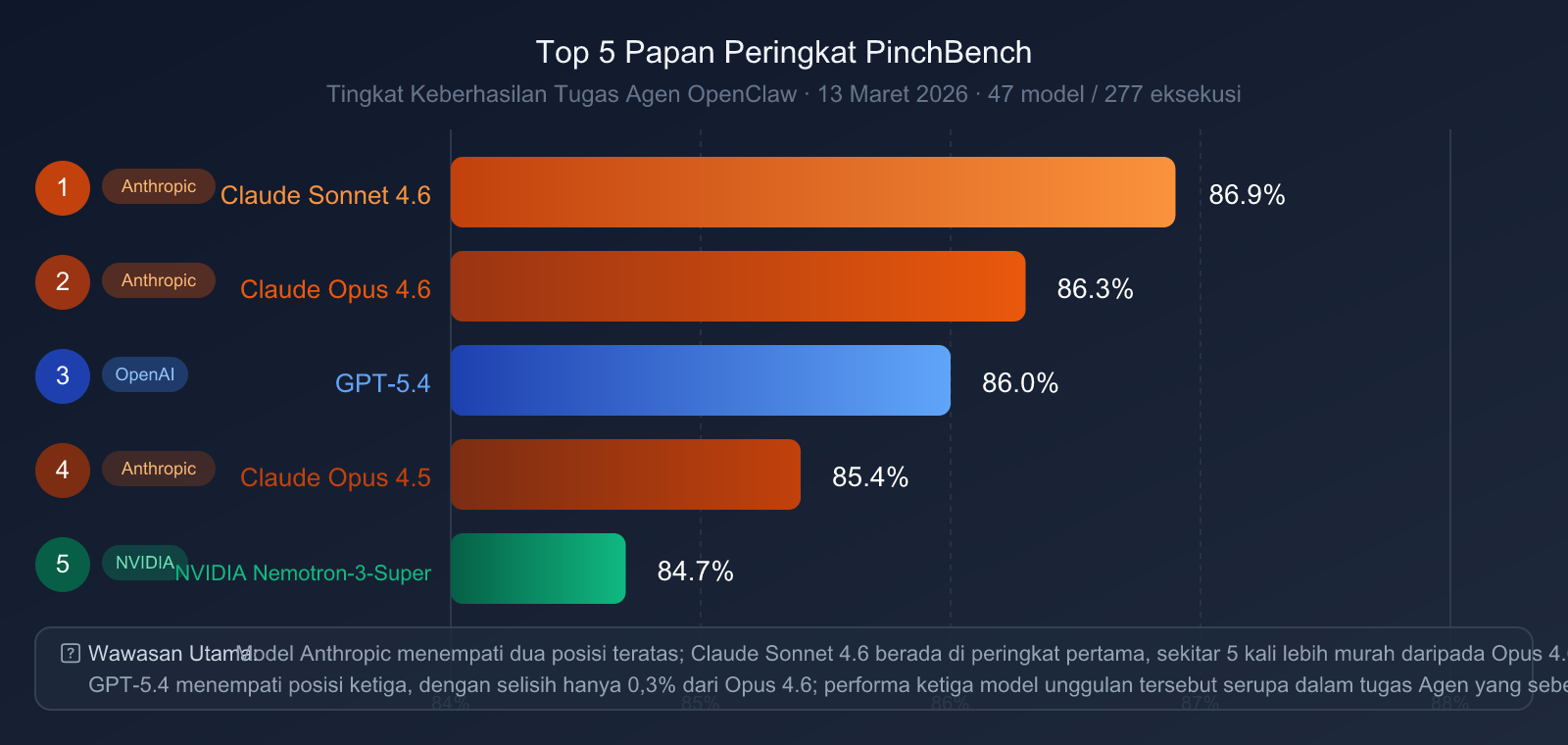
| Peringkat | Model | Tingkat Keberhasilan PinchBench |
|---|---|---|
| 🥇 1 | Claude Sonnet 4.6 | 86.9% |
| 🥈 2 | Claude Opus 4.6 | 86.3% |
| 🥉 3 | GPT-5.4 | 86.0% |
| 4 | Claude Opus 4.5 | 85.4% |
| 5 | NVIDIA Nemotron-3-Super | 84.7% |
Temuan Kunci:
- Seri Claude Mendominasi Dua Teratas: Sonnet 4.6 dan Opus 4.6 masing-masing menempati posisi pertama dan kedua, menunjukkan keunggulan sistematis Anthropic dalam rekayasa agen cerdas.
- GPT-5.4 Berada di Posisi Ketiga: Selisihnya hanya 0,3 poin persentase dari Opus 4.6, perbedaan yang sangat tipis.
- Sorotan Efisiensi Biaya: Claude Sonnet 4.6 (sekitar 5 kali lebih murah daripada Opus 4.6) justru memiliki peringkat lebih tinggi di PinchBench, membuktikan bahwa yang lebih mahal tidak selalu lebih baik.
- Claude Sonnet 4.6 Layak Dilirik Kembali: Untuk tugas agen cerdas seperti OpenClaw, Sonnet 4.6 adalah pilihan dengan rasio performa-harga terbaik.
🔍 Rekomendasi Proyek Agen: Jika Anda sedang membangun Agen AI berbasis OpenClaw, perbedaan antara tiga model teratas (Sonnet 4.6, Opus 4.6, GPT-5.4) kurang dari 1%. Direkomendasikan untuk mengaksesnya melalui APIYI (apiyi.com) sesuai kebutuhan, sehingga Anda bisa memilih model secara dinamis berdasarkan jenis tugas untuk menekan biaya sambil tetap menjaga tingkat keberhasilan yang tinggi.
Chatbot Arena ELO: Model Terkuat Pilihan Nyata Pengguna
Chatbot Arena (sebelumnya LMSYS) merupakan peringkat preferensi pengguna model AI yang paling otoritatif saat ini, di mana skor ELO dihasilkan melalui jutaan pemungutan suara buta (blind test) dari percakapan nyata.
Peringkat Terbaru Februari 2026 (Top 5):
| Peringkat | Model | Skor ELO |
|---|---|---|
| 🥇 1 | Claude Opus 4.6 | 1503 |
| 2 | Grok-4.1-Thinking | 1482 |
| 🥉 3 | GPT-5.4 | 1463 |
| 4 | Gemini 3 Pro | ~1445 |
| 5 | Claude Sonnet 4.6 | ~1438 |
Claude Opus 4.6 memimpin dengan selisih 40 poin ELO di atas GPT-5.4, dengan keunggulan yang sangat menonjol dalam dimensi percakapan multi-putaran, kontrol gaya, dan penulisan kreatif. Dalam sistem evaluasi Chatbot Arena, selisih sebesar ini dianggap sebagai keunggulan yang signifikan.
GPT-4.5 (Referensi Historis): GPT-4.5 (dengan kode nama "Orion") yang dirilis OpenAI pada Februari 2025 sempat fokus pada kecerdasan emosional dan kualitas percakapan, serta sempat memuncaki Chatbot Arena di awal perilisannya. Namun, model tersebut telah dihapus dari API pada 14 Juli 2025, dan sepenuhnya ditarik dari ChatGPT pada Agustus 2025. GPT-5.4 adalah penerusnya saat ini yang melampaui pendahulunya dalam segala aspek kemampuan.
Harga API dan Efisiensi Biaya: Cara Memilih untuk Proyek Sensitif Anggaran
| Item Biaya | GPT-5.4 | Claude Opus 4.6 | Perbedaan |
|---|---|---|---|
| Harga Input (per juta token) | $2.50 | $5.00 | Opus 4.6 lebih mahal 2x |
| Harga Output (per juta token) | $15.00 | $25.00 | Opus 4.6 lebih mahal 1.67x |
| Jendela konteks | ~1M token | 200K (1M Beta) | GPT-5.4 Unggul |
| Panjang Output Maksimum | — | 128K token | Opus 4.6 Unggul |
| Dukungan Multimodal | ✅ Input Gambar | ✅ Input Gambar | Setara |
Estimasi Biaya (Pemrosesan harian 1 juta token input + 200K token output):
- GPT-5.4: Sekitar $5.50/hari (rata-rata $165/bulan)
- Claude Opus 4.6: Sekitar $10.00/hari (rata-rata $300/bulan)
💰 Solusi Optimasi Biaya: Untuk proyek dengan konkurensi tinggi atau anggaran terbatas, disarankan menggunakan Claude Sonnet 4.6 di APIYI (apiyi.com) untuk menangani tugas sehari-hari, dan hanya melakukan pemanggilan model Opus 4.6 saat membutuhkan kemampuan penalaran terkuat. Strategi ini dapat memangkas biaya API sebesar 60-75%. APIYI mendukung penagihan terpadu untuk berbagai model dalam satu akun, memudahkan Anda melakukan manajemen biaya yang mendetail.
Rekomendasi Skenario: GPT-5.4 vs Claude Opus 4.6, Mana yang Harus Dipilih?
Skenario untuk Memilih GPT-5.4
✅ Tugas Umum dengan Efisiensi Biaya Tinggi
- Anggaran terbatas tapi butuh kemampuan kelas unggulan (flagship).
- Pembuatan konten harian, tanya jawab layanan pelanggan, ekstraksi informasi.
- Penghematan biaya yang signifikan saat biaya pemanggilan model API bulanan melebihi $500.
✅ Penelitian Ilmiah dan Tanya Jawab Teknis
- Unggul di GPQA Diamond, lebih kuat untuk penalaran ilmiah tingkat doktoral.
- Tanya jawab profesional di bidang akademik seperti kimia, fisika, dan biologi.
✅ Kode Kompleks Tingkat Perusahaan (Unggul di SWE-bench Pro)
- Menangani modifikasi tingkat arsitektur pada basis kode (codebase) yang sangat besar.
- Tugas refactoring yang membutuhkan pemahaman mendalam tentang dependensi yang kompleks.
✅ Skenario Jendela Konteks Super Panjang
- Perlu memproses dokumen atau basis kode super panjang hingga mendekati 1M token.
- Jendela konteks 1M milik Opus 4.6 masih dalam tahap Beta.
Skenario untuk Memilih Claude Opus 4.6
✅ Pembuatan dan Perbaikan Kode Tingkat Produksi
- SWE-bench Verified 80.8%, lebih andal untuk perbaikan bug harian dan pengembangan fitur.
- Kemampuan riset web BrowseComp 84%, cocok untuk aplikasi berbasis RAG yang ditingkatkan.
✅ Proyek Agen AI seperti OpenClaw
- Peringkat dua teratas di PinchBench, model Anthropic secara sistematis lebih unggul dalam tugas Agen yang nyata.
✅ Produk dengan Persyaratan Kualitas Percakapan Tinggi
- Chatbot Arena ELO 1503, kepuasan pengguna nomor satu di dunia.
- Koherensi percakapan multi-putaran dan kemampuan adaptasi gaya yang lebih kuat.
✅ Pekerjaan Pengetahuan Profesional
- Unggul 16 poin persentase di ARC-AGI-2, penalaran abstrak lebih kuat.
- BigLaw Bench 90.2%, lebih andal untuk analisis hukum, kepatuhan, dan dokumen.
✅ Output Dokumen Panjang
- Output maksimum 128K, cocok untuk menghasilkan laporan lengkap dan dokumen panjang.
🎯 Saran Keputusan Skenario: Kedua model memiliki kelebihannya masing-masing, perbedaannya terutama terlihat pada tugas-tugas spesifik. Kami menyarankan untuk melakukan pengujian A/B melalui platform APIYI (apiyi.com) sebelum peluncuran resmi. Platform ini menyediakan antarmuka terpadu yang mendukung peralihan model dengan cepat, membantu Anda menemukan pilihan terbaik yang paling sesuai dengan skenario bisnis Anda.
Akses Cepat: Gunakan Kedua Model Secara Bersamaan Melalui Satu API Terpadu
Tidak perlu mendaftar akun OpenAI dan Anthropic secara terpisah. Melalui APIYI, Anda dapat mengakses semua model utama dengan satu antarmuka terpadu:
from openai import OpenAI
# Melalui antarmuka terpadu APIYI, mendukung GPT-5.4 dan Claude Opus 4.6
client = OpenAI(
api_key="your-apiyi-key",
base_url="https://vip.apiyi.com/v1" # Alamat akses terpadu APIYI
)
# Memanggil Claude Opus 4.6
response_opus = client.chat.completions.create(
model="claude-opus-4-6",
messages=[
{"role": "user", "content": "Tolong bantu saya menganalisis potensi bug dalam kode berikut..."}
],
max_tokens=4096
)
# Memanggil GPT-5.4 (antarmuka yang sama, cukup ganti nama model)
response_gpt = client.chat.completions.create(
model="gpt-5-4",
messages=[
{"role": "user", "content": "Tolong bantu saya menganalisis potensi bug dalam kode berikut..."}
],
max_tokens=4096
)
print("Opus 4.6:", response_opus.choices[0].message.content)
print("GPT-5.4:", response_gpt.choices[0].message.content)
💡 Petunjuk Akses: Atur
base_urlkehttps://vip.apiyi.com/v1dan gantiapi_keydengan kunci API yang Anda ajukan di APIYI (apiyi.com) untuk beralih dalam satu klik. Ada bonus saldo untuk pengisian pertama, memudahkan Anda menguji perbedaan nyata antara kedua model sebelum peluncuran resmi.
Perbandingan Nama Model:
| Model | Nama Pemanggilan API | Biaya Rata-rata Bulanan (100M token/bulan) |
|---|---|---|
| Claude Opus 4.6 | claude-opus-4-6 |
Sekitar $500+ |
| Claude Sonnet 4.6 | claude-sonnet-4-6 |
Sekitar $100+ |
| GPT-5.4 | gpt-5-4 |
Sekitar $250+ |
Tanya Jawab Umum
Q: Apakah GPT-4.5 dan GPT-5.4 adalah model yang sama?
Bukan. GPT-4.5 (dengan kode nama "Orion") adalah model transisi yang dirilis OpenAI pada Februari 2025, yang mengunggulkan kecerdasan emosional dan kualitas percakapan dengan harga yang sangat tinggi ($75/$150 per M token), dan telah resmi ditarik dari API pada 14 Juli 2025. GPT-5.4 adalah Model Bahasa Besar unggulan OpenAI saat ini yang kemampuannya sepenuhnya melampaui GPT-4.5, dengan harga yang turun drastis menjadi $2.50/$15 per M token. Jika kamu ingin melakukan pemanggilan model OpenAI terkuat, gunakanlah GPT-5.4 yang bisa diakses melalui APIYI apiyi.com.
Q: Apa itu OpenClaw? Apa bedanya dengan Cursor / Claude Code?
OpenClaw adalah platform agen AI sumber terbuka (open-source) yang bisa di-host sendiri. Platform ini mendukung akses terminal, pengeditan kode multi-file, serta integrasi dengan lebih dari 50 alat seperti WhatsApp/Telegram/Slack. Ia bahkan memiliki kemampuan "evolusi mandiri" untuk membuat keahlian baru secara otomatis. Dibandingkan dengan Cursor (plugin IDE komersial) dan Claude Code (CLI resmi Anthropic), keunggulan utama OpenClaw adalah sepenuhnya open-source dan dapat diterapkan secara privat, sehingga cocok untuk skenario perusahaan yang mementingkan keamanan data. PinchBench adalah tolok ukur (benchmark) khusus untuk mengevaluasi performa model AI dalam tugas-tugas agen OpenClaw.
Q: Untuk tugas menulis AI, model mana yang lebih baik?
Berdasarkan skor Chatbot Arena ELO, Claude Opus 4.6 menempati peringkat pertama di dunia dengan skor 1503 dalam pengujian preferensi pengguna. Model ini sangat menonjol dalam penulisan kreatif, percakapan multi-putaran, dan adaptasi gaya bahasa. GPT-5.4 juga sangat baik dalam menulis, namun peringkat kepuasan penggunanya sedikit lebih rendah. Disarankan untuk melakukan pengujian pada skenario penulisan spesifik kamu melalui APIYI apiyi.com, karena gaya dan jenis tugas penulisan yang berbeda mungkin memberikan hasil yang berbeda pula.
Q: Seberapa besar perbedaan antara Claude Sonnet 4.6 dan Claude Opus 4.6?
Dari pengujian agen PinchBench, Sonnet 4.6 (86,9%) bahkan sedikit lebih tinggi dari Opus 4.6 (86,3%). Di Chatbot Arena ELO, Sonnet 4.6 berada di angka sekitar 1438, sementara Opus 4.6 di 1503, dengan selisih sekitar 65 poin. Untuk sebagian besar tugas pemrograman dan analisis, Sonnet 4.6 adalah pilihan dengan rasio performa-harga yang lebih baik (harganya sekitar 20% dari Opus 4.6). Upgrade ke Opus 4.6 baru terasa sepadan untuk skenario penalaran kompleks, pemrosesan dokumen panjang, dan kebutuhan akurasi ekstrem.
Ringkasan: Bagaimana Cara Memilih Model Unggulan di Tahun 2026?
| Skenario Kebutuhan | Model Rekomendasi | Alasan Utama |
|---|---|---|
| Pengembangan Harian + Kontrol Biaya | GPT-5.4 | Lebih murah 50%, kemampuan komprehensif kuat |
| Perbaikan Kode Kompleks (SWE-bench) | Claude Opus 4.6 | 80,8%, unggul di atas GPT-5.4 (77,2%) |
| Tugas Agen AI (OpenClaw) | Claude Sonnet 4.6 | Peringkat #1 di PinchBench, lebih murah dari Opus |
| Produk Percakapan / Kepuasan Pengguna | Claude Opus 4.6 | Peringkat #1 Chatbot Arena ELO (1503) |
| Penelitian Ilmiah / Tanya Jawab Akademik | GPT-5.4 | GPQA Diamond 93,2%, unggul tipis |
| Analisis Dokumen Sangat Panjang | Claude Opus 4.6 | Output 128K + MRCR v2 76% |
| Penalaran Abstrak / Tugas AGI | Claude Opus 4.6 | ARC-AGI-2 68,8% vs 52,9% |
Kesimpulan Penting:
- GPT-5.4 adalah pilihan dengan rasio performa-harga keseluruhan tertinggi. Indeks kecerdasan AI komprehensifnya (57 vs 53) sedikit lebih unggul, dengan harga sekitar setengah dari Opus 4.6.
- Claude Opus 4.6 adalah model dengan kepuasan pengguna nomor satu di dunia (ELO 1503), dengan keunggulan nyata pada kode kompleks, agen AI, dan penalaran abstrak.
- Untuk sebagian besar proyek praktis, Claude Sonnet 4.6 adalah solusi dengan nilai terbaik—menempati peringkat pertama di PinchBench dengan harga jauh di bawah Opus 4.6.
Tidak ada model yang "selamanya terbaik", yang ada hanyalah model yang paling cocok untuk skenario kamu.
🚀 Uji Sekarang: Di platform APIYI apiyi.com, kamu bisa menggunakan satu kunci API untuk mengakses GPT-5.4, Claude Opus 4.6, dan Claude Sonnet 4.6 secara bersamaan. Bandingkan performa dan biaya ketiga model ini dengan data bisnis nyata kamu. Pengguna baru yang mendaftar akan mendapatkan kuota uji coba untuk membantu membuat keputusan terbaik sebelum implementasi penuh.
Sumber data artikel ini: Dokumentasi resmi Anthropic, dokumentasi OpenAI API, Peringkat Chatbot Arena (Februari 2026), Peringkat PinchBench (13 Maret 2026), Perbandingan model Artificial Analysis, dan evaluasi teknis DigitalApplied. Data dapat berubah seiring pembaruan model, disarankan untuk merujuk pada dokumentasi resmi terbaru.
Penulis: Tim APIYI | Dipublikasikan di AI123.dev