Nota del autor: ¿GPT-5.4 o Claude Opus 4.6? Los dos modelos de IA insignia más importantes de 2026 se enfrentan cara a cara. Este artículo recopila los datos reales más recientes de Chatbot Arena, SWE-bench, ARC-AGI-2 y OpenClaw PinchBench, ofreciendo recomendaciones de elección claras basadas en cuatro dimensiones: programación, razonamiento, tareas de agentes y relación calidad-precio.

GPT-5.4 vs Claude Opus 4.6: Resumen rápido de diferencias principales
Al elegir un Modelo de Lenguaje Grande insignia, las dimensiones más críticas son evidentes de un vistazo:
| Dimensión de comparación | GPT-5.4 | Claude Opus 4.6 |
|---|---|---|
| Fecha de lanzamiento | Finales de 2025 | Febrero de 2026 |
| Chatbot Arena ELO | 1463 | 1503 (#1) |
| Índice de inteligencia de IA | 57 | 53 |
| Precio de entrada API | $2.50/M tokens | $5.00/M tokens |
| Precio de salida API | $15.00/M tokens | $25.00/M tokens |
| Ventana de contexto | ~1M tokens | 200K (1M Beta) |
| Máxima longitud de salida | — | 128K tokens |
| Estado | Activo | Activo |
Conclusión principal: GPT-5.4 tiene un índice de inteligencia general más alto y es aproximadamente un 50% más económico; Claude Opus 4.6 ocupa el primer lugar mundial en satisfacción de usuario en Chatbot Arena y es superior en programación compleja y tareas de agentes.
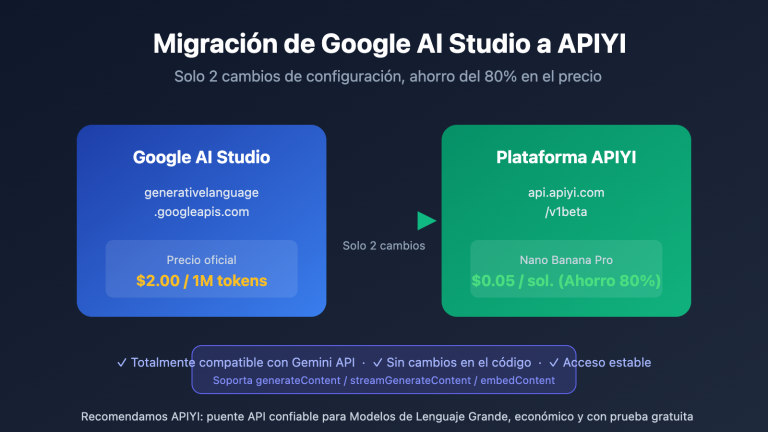
🎯 Sugerencia rápida: Si eres un desarrollador que prioriza el presupuesto, GPT-5.4 ofrece una mejor relación calidad-precio. Si tu proyecto requiere generación de código complejo o procesamiento de documentos extensos, Opus 4.6 es la mejor inversión. Te recomendamos probar ambos modelos simultáneamente a través de APIYI apiyi.com para realizar comparativas reales; la plataforma permite alternar rápidamente mediante una interfaz de API unificada.
Benchmarks autoritativos: Comparativa dimensional completa entre GPT-5.4 y Claude Opus 4.6
Comparativa de capacidades de razonamiento y conocimiento
| Benchmark | GPT-5.4 | Claude Opus 4.6 | Descripción |
|---|---|---|---|
| GPQA Diamond (Ciencias nivel posgrado) | 93.2% | 91.3% | Gana GPT-5.4 |
| MMLU (Conocimiento enciclopédico) | 89.6% | 91.1% | Gana Opus 4.6 |
| ARC-AGI-2 (Razonamiento abstracto) | 52.9% | 68.8% | Opus 4.6 lidera con amplia ventaja |
| BigLaw Bench (Especialidad legal) | — | 90.2% | Ventaja específica de Opus 4.6 |
| MRCR v2 (Contexto largo de 1M) | — | 76% | Opus 4.6 lidera en documentos extensos |
| GDPval-AA ELO (Tareas profesionales) | 1462 | 1606 | Opus 4.6 es claramente superior |
Interpretación: GPT-5.4 tiene una ligera ventaja en razonamiento científico (GPQA Diamond), pero en razonamiento abstracto (liderando por 16 puntos porcentuales en ARC-AGI-2), trabajo de conocimiento especializado y procesamiento de contexto largo, Claude Opus 4.6 muestra un desempeño más sólido.
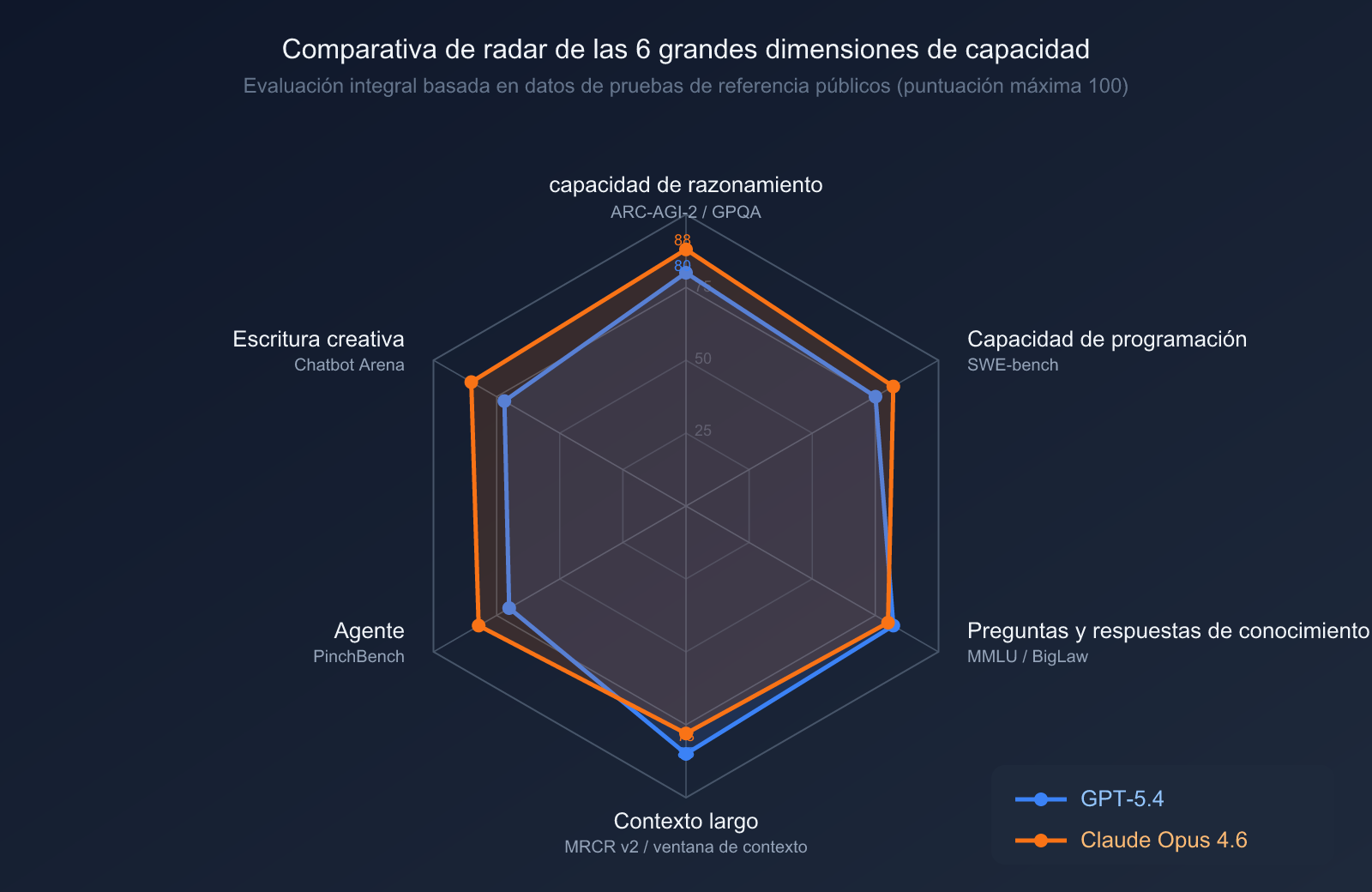
Comparativa de capacidades de programación y agentes
| Benchmark | GPT-5.4 | Claude Opus 4.6 | Descripción |
|---|---|---|---|
| SWE-bench Verified (Corrección de código real) | ~77.2% | 80.8% | Gana Opus 4.6 |
| SWE-bench Pro (Código de nivel profesional) | 57.7% | ~45% | Gana GPT-5.4 |
| Terminal-Bench 2.0 (Operaciones de terminal) | 64.7% | 65.4% | Victoria mínima de Opus 4.6 |
| OSWorld (Control de computadora) | 75.0% | 72.7% | Victoria mínima de GPT-5.4 |
| BrowseComp (Investigación de búsqueda web) | 77.9% | 84.0% | Gana Opus 4.6 |
| OpenRCA (Análisis de causa raíz) | — | 34.9% | Ventaja específica de Opus 4.6 |
Interpretación: Ambos modelos tienen enfoques distintos en el ámbito de la programación. Opus 4.6 es más fuerte en SWE-bench Verified (corrección de código cotidiano), mientras que GPT-5.4 lidera en SWE-bench Pro (código complejo de nivel empresarial). En el control de computadoras, GPT-5.4 gana por poco, pero Opus 4.6 destaca notablemente en investigación web y análisis de causa raíz.
💡 Consejo para desarrolladores: Para tareas de generación de código orientadas a la entrega de productos, se recomienda probar ambos modelos por separado a través de la interfaz unificada de APIYI (apiyi.com) y decidir según las características específicas de su base de código. El costo es solo del 60-80% de las llamadas directas a las API oficiales de Anthropic u OpenAI.
OpenClaw en acción: Últimos datos reales de PinchBench
¿Qué son OpenClaw y PinchBench?
OpenClaw es una plataforma de agentes de IA de código abierto y autohospedable (similar a Claude Code). Permite el acceso por terminal, la edición de múltiples archivos y se integra con más de 50 herramientas como WhatsApp, Telegram y Slack. Fue creada por el desarrollador austriaco Peter Steinberger en noviembre de 2025 y actualmente está creciendo rápidamente en GitHub.
PinchBench es un benchmark diseñado específicamente para los agentes de OpenClaw, desarrollado por Kilo.ai. A diferencia de los benchmarks tradicionales que miden respuestas simples, este evalúa el rendimiento del modelo en tareas de múltiples pasos del mundo real:
- Programar reuniones y gestionar calendarios.
- Escribir proyectos de código con múltiples archivos.
- Clasificar correos electrónicos y gestionar archivos.
- Investigación web e integración de información.
Esta es una de las pruebas que más se acerca al escenario de uso real de un agente de IA hoy en día.
Clasificación PinchBench (13 de marzo de 2026, 47 modelos, 277 ejecuciones)
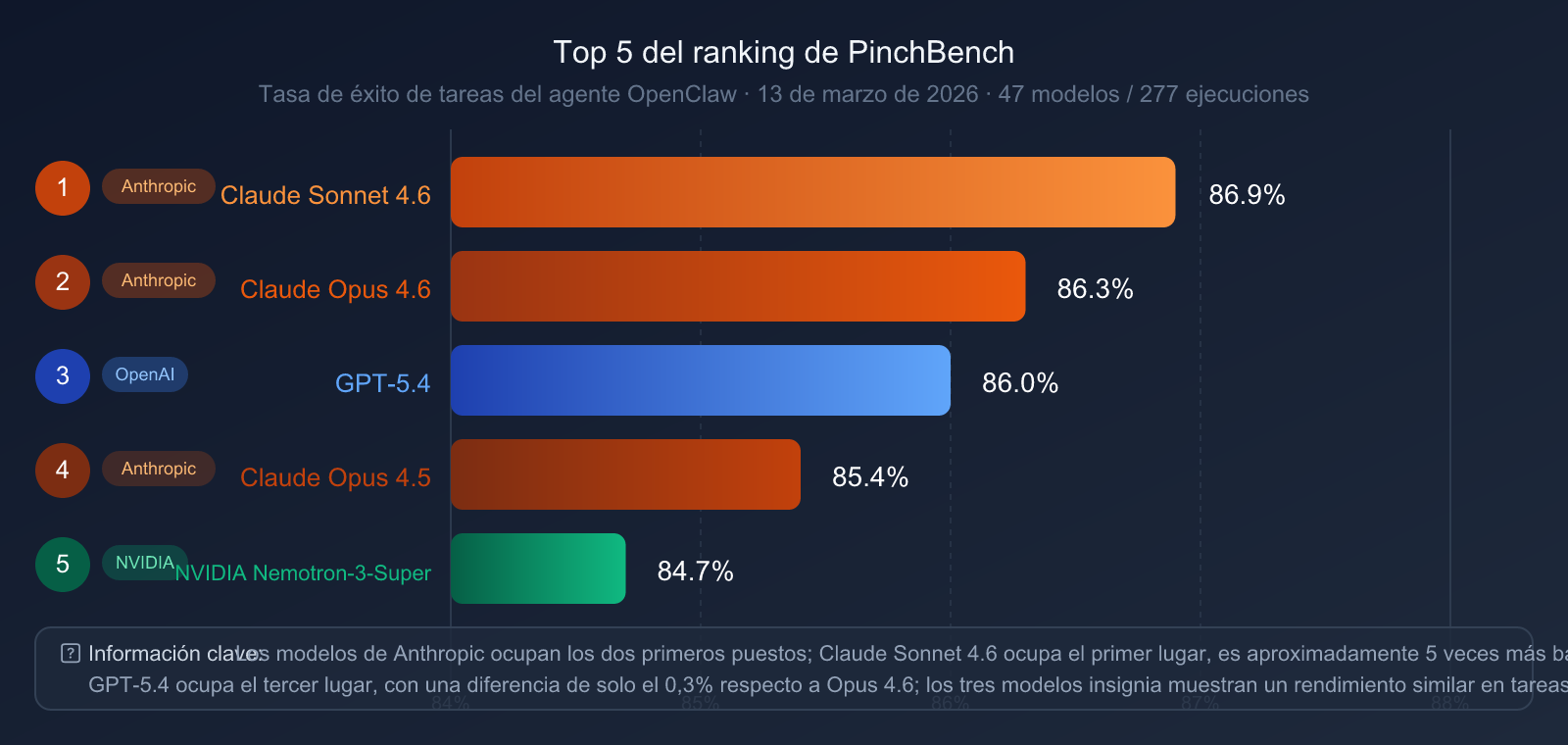
| Puesto | Modelo | Tasa de éxito en PinchBench |
|---|---|---|
| 🥇 1 | Claude Sonnet 4.6 | 86.9% |
| 🥈 2 | Claude Opus 4.6 | 86.3% |
| 🥉 3 | GPT-5.4 | 86.0% |
| 4 | Claude Opus 4.5 | 85.4% |
| 5 | NVIDIA Nemotron-3-Super | 84.7% |
Hallazgos clave:
- La serie Claude domina los dos primeros puestos: Sonnet 4.6 y Opus 4.6 ocupan el primer y segundo lugar, lo que demuestra la ventaja sistemática de Anthropic en la ingeniería de agentes.
- GPT-5.4 se sitúa en tercer lugar: Con una diferencia de solo 0.3 puntos porcentuales respecto a Opus 4.6, la brecha es mínima.
- Relación calidad-precio destacada: Claude Sonnet 4.6 (unas 5 veces más barato que Opus 4.6) tiene una clasificación más alta en PinchBench, lo que demuestra que lo más caro no siempre es lo mejor.
- Vale la pena reconsiderar el Claude Sonnet 4.6: Para tareas de agentes tipo OpenClaw, Sonnet 4.6 es la opción con mejor relación calidad-precio.
🔍 Recomendación para proyectos de agentes: Si estás construyendo un agente de IA basado en OpenClaw, la diferencia entre los tres modelos principales (Sonnet 4.6, Opus 4.6, GPT-5.4) es inferior al 1%. Te recomendamos acceder a ellos a través de APIYI (apiyi.com) bajo demanda, seleccionando el modelo dinámicamente según el tipo de tarea para reducir costes manteniendo una alta tasa de éxito.
Chatbot Arena ELO: Los modelos más potentes elegidos por votos reales de usuarios
Chatbot Arena (anteriormente LMSYS) es actualmente el ranking más prestigioso de preferencias de usuarios para modelos de IA, generando puntuaciones ELO a través de millones de pruebas ciegas en conversaciones reales.
Última clasificación de febrero de 2026 (Top 5):
| Puesto | Modelo | Puntuación ELO |
|---|---|---|
| 🥇 1 | Claude Opus 4.6 | 1503 |
| 2 | Grok-4.1-Thinking | 1482 |
| 🥉 3 | GPT-5.4 | 1463 |
| 4 | Gemini 3 Pro | ~1445 |
| 5 | Claude Sonnet 4.6 | ~1438 |
Claude Opus 4.6 lidera sobre GPT-5.4 con una diferencia de 40 puntos ELO, destacando especialmente en dimensiones como el diálogo de múltiples turnos, el control de estilo y la escritura creativa. Esta brecha representa una ventaja significativa dentro del sistema de evaluación de Chatbot Arena.
GPT-4.5 (referencia histórica): Lanzado por OpenAI en febrero de 2025, el GPT-4.5 (nombre en clave "Orion") se centró en la inteligencia emocional y la calidad del diálogo, llegando a liderar brevemente Chatbot Arena tras su lanzamiento. Sin embargo, este modelo fue retirado de la API el 14 de julio de 2025 y desapareció por completo de ChatGPT en agosto de 2025. GPT-5.4 es su sucesor actual y lo supera en todas las capacidades.
Precios de API y relación calidad-precio: Cómo elegir para proyectos sensibles al costo
| Concepto de costo | GPT-5.4 | Claude Opus 4.6 | Diferencia |
|---|---|---|---|
| Precio de entrada (por millón de tokens) | $2.50 | $5.00 | Opus 4.6 es 2x más caro |
| Precio de salida (por millón de tokens) | $15.00 | $25.00 | Opus 4.6 es 1.67x más caro |
| Ventana de contexto | ~1M tokens | 200K (1M en Beta) | Gana GPT-5.4 |
| Longitud máxima de salida | — | 128K tokens | Gana Opus 4.6 |
| Soporte multimodal | ✅ Entrada de imágenes | ✅ Entrada de imágenes | Equivalente |
Estimación de costos (procesamiento diario de 1 millón de tokens de entrada + 200K tokens de salida):
- GPT-5.4: aprox. $5.50/día (promedio mensual de $165)
- Claude Opus 4.6: aprox. $10.00/día (promedio mensual de $300)
💰 Plan de optimización de costos: Para proyectos con alta concurrencia o presupuestos limitados, se recomienda usar Claude Sonnet 4.6 en APIYI (apiyi.com) para tareas cotidianas, reservando la invocación del modelo Opus 4.6 solo para cuando se requiera la máxima capacidad de razonamiento. Esto puede reducir los costos de la API entre un 60% y 75%. APIYI permite la facturación unificada de múltiples modelos en una misma cuenta, facilitando una gestión de costos detallada.
Recomendaciones de escenarios: ¿GPT-5.4 vs Claude Opus 4.6, cuál elegir?
Escenarios donde priorizar GPT-5.4
✅ Tareas generales con alta relación costo-rendimiento
- Presupuesto limitado pero necesidad de capacidades de nivel insignia.
- Creación de contenido diario, atención al cliente (preguntas y respuestas), extracción de información.
- Cuando el costo mensual de invocación del modelo supera los $500, el ahorro es significativo.
✅ Investigación científica y consultas técnicas
- Líder en GPQA Diamond, con una razonamiento científico de nivel de doctorado más sólido.
- Consultas profesionales en campos académicos como química, física y biología.
✅ Código complejo a nivel empresarial (Líder en SWE-bench Pro)
- Manejo de modificaciones a nivel de arquitectura en bases de código ultra grandes.
- Tareas de refactorización que requieren una comprensión profunda de dependencias complejas.
✅ Escenarios de contexto ultra largo
- Necesidad de procesar documentos o bases de código extremadamente largos, cercanos a 1M de tokens.
- El contexto de 1M de Opus 4.6 aún se encuentra en fase Beta.
Escenarios donde priorizar Claude Opus 4.6
✅ Generación y corrección de código a nivel de producción
- 80.8% en SWE-bench Verified, más confiable para la corrección de errores diarios y el desarrollo de funciones.
- Capacidad de investigación web del 84% en BrowseComp, ideal para aplicaciones mejoradas con RAG.
✅ Proyectos de agentes inteligentes tipo OpenClaw
- Top 2 en PinchBench; los modelos de Anthropic son sistemáticamente superiores en tareas reales de agentes (Agents).
✅ Productos con alta exigencia en calidad de diálogo
- ELO de 1503 en Chatbot Arena, número uno mundial en satisfacción del usuario.
- Mayor coherencia en diálogos de múltiples turnos y mejor capacidad de adaptación de estilo.
✅ Trabajo de conocimiento profesional
- Lidera por 16 puntos porcentuales en ARC-AGI-2, con un razonamiento abstracto más fuerte.
- 90.2% en BigLaw Bench, más confiable para análisis legal, cumplimiento y documentos técnicos.
✅ Salida de documentos extensos
- Salida máxima de 128K, ideal para generar informes completos y documentos de gran longitud.
🎯 Sugerencia de decisión: Ambos modelos tienen sus fortalezas y la diferencia se manifiesta principalmente en tareas específicas. Te recomendamos realizar pruebas A/B a través de la plataforma APIYI (apiyi.com) antes del lanzamiento oficial. La plataforma ofrece una interfaz unificada que permite cambiar de modelo rápidamente, ayudándote a encontrar la opción óptima para tu escenario de negocio.
Acceso rápido: Use ambos modelos simultáneamente a través de una API unificada
No es necesario registrar cuentas de OpenAI y Anthropic por separado. A través de APIYI, puedes acceder a todos los modelos principales mediante una interfaz única:
from openai import OpenAI
# A través de la interfaz unificada de APIYI, compatible con GPT-5.4 y Claude Opus 4.6
client = OpenAI(
api_key="your-apiyi-key",
base_url="https://vip.apiyi.com/v1" # Dirección de acceso unificada de APIYI
)
# Invocación de Claude Opus 4.6
response_opus = client.chat.completions.create(
model="claude-opus-4-6",
messages=[
{"role": "user", "content": "Por favor, ayúdame a analizar los posibles errores en el siguiente código..."}
],
max_tokens=4096
)
# Invocación de GPT-5.4 (misma interfaz, solo cambie el nombre del modelo)
response_gpt = client.chat.completions.create(
model="gpt-5-4",
messages=[
{"role": "user", "content": "Por favor, ayúdame a analizar los posibles errores en el siguiente código..."}
],
max_tokens=4096
)
print("Opus 4.6:", response_opus.choices[0].message.content)
print("GPT-5.4:", response_gpt.choices[0].message.content)
💡 Instrucciones de acceso: Configura el
base_urlcomohttps://vip.apiyi.com/v1y sustituye laapi_keypor la clave que solicitaste en APIYI (apiyi.com) para alternar con un solo clic. La primera recarga incluye saldo de regalo, lo que facilita probar las diferencias reales entre ambos modelos antes de pasar a producción.
Comparativa de nombres de modelos:
| Modelo | Nombre de invocación de API | Costo mensual promedio (100M tokens/mes) |
|---|---|---|
| Claude Opus 4.6 | claude-opus-4-6 |
Aprox. $500+ |
| Claude Sonnet 4.6 | claude-sonnet-4-6 |
Aprox. $100+ |
| GPT-5.4 | gpt-5-4 |
Aprox. $250+ |
Preguntas frecuentes
P: ¿Son el GPT-4.5 y el GPT-5.4 el mismo modelo?
No. El GPT-4.5 (nombre en clave "Orion") fue un modelo de transición lanzado por OpenAI en febrero de 2025, centrado en la inteligencia emocional y la calidad del diálogo, con un precio extremadamente alto ($75/$150 por cada millón de tokens). Fue retirado oficialmente de la API el 14 de julio de 2025. El GPT-5.4 es el modelo insignia actual de OpenAI, con capacidades que superan por completo al GPT-4.5 y un precio que ha bajado significativamente a $2.50/$15 por cada millón de tokens. Si necesitas realizar una invocación del modelo más potente de OpenAI, debes usar GPT-5.4, disponible a través de APIYI (apiyi.com).
P: ¿Qué es OpenClaw? ¿En qué se diferencia de Cursor o Claude Code?
OpenClaw es una plataforma de agentes de IA de código abierto y autohospedada. Admite acceso por terminal, edición de código en múltiples archivos e integración con más de 50 herramientas como WhatsApp, Telegram y Slack. Además, cuenta con una capacidad de "autoevolución" para generar nuevas habilidades automáticamente. En comparación con Cursor (un plugin de IDE comercial) y Claude Code (la CLI oficial de Anthropic), la ventaja principal de OpenClaw es que es totalmente de código abierto y permite el despliegue privado, lo que lo hace ideal para empresas con requisitos estrictos de seguridad de datos. PinchBench es el punto de referencia (benchmark) especializado en evaluar el rendimiento de los modelos de IA en tareas de agentes dentro de OpenClaw.
P: Para tareas de escritura con IA, ¿qué modelo es mejor?
Según la puntuación ELO de Chatbot Arena, Claude Opus 4.6 ocupa el primer lugar mundial con 1503 puntos en las pruebas de preferencia de los usuarios, destacando especialmente en escritura creativa, diálogos de varios turnos y adaptación de estilo. GPT-5.4 también es excelente en escritura, pero su clasificación en satisfacción del usuario es ligeramente inferior. Te recomendamos realizar pruebas específicas para tu escenario de escritura a través de APIYI (apiyi.com), ya que diferentes estilos y tipos de tareas pueden arrojar resultados distintos.
P: ¿Qué tanta diferencia hay entre Claude Sonnet 4.6 y Claude Opus 4.6?
Según las pruebas de agentes de PinchBench, Sonnet 4.6 (86.9%) es incluso ligeramente superior a Opus 4.6 (86.3%). En el ELO de Chatbot Arena, Sonnet 4.6 tiene unos 1438 puntos frente a los 1503 de Opus 4.6, una diferencia de unos 65 puntos. Para la mayoría de las tareas de programación y análisis, Sonnet 4.6 es la opción con mejor relación calidad-precio (su costo es aproximadamente el 20% de Opus 4.6). Solo vale la pena actualizar a Opus 4.6 en escenarios de razonamiento complejo, procesamiento de documentos extensos y requisitos de precisión extrema.
Resumen: ¿Cómo elegir un modelo insignia en 2026?
| Escenario de necesidad | Modelo recomendado | Razón principal |
|---|---|---|
| Desarrollo diario + Control de costos | GPT-5.4 | 50% más barato, capacidad integral sólida |
| Corrección de código complejo (SWE-bench) | Claude Opus 4.6 | 80.8%, liderando frente al 77.2% de GPT-5.4 |
| Tareas de agentes de IA (OpenClaw) | Claude Sonnet 4.6 | #1 en PinchBench, más barato que Opus |
| Productos de chat / Satisfacción del usuario | Claude Opus 4.6 | #1 en Chatbot Arena ELO (1503) |
| Investigación científica / Consultas académicas | GPT-5.4 | GPQA Diamond 93.2%, ligera ventaja |
| Análisis de documentos ultra largos | Claude Opus 4.6 | Salida de 128K + MRCR v2 76% |
| Razonamiento abstracto / Tareas de AGI | Claude Opus 4.6 | ARC-AGI-2 68.8% vs 52.9% |
Conclusiones clave:
- GPT-5.4 es la opción con la mejor relación calidad-precio general, con un índice de inteligencia integral ligeramente superior (57 vs 53) y un precio que es aproximadamente la mitad que el de Opus 4.6.
- Claude Opus 4.6 es el modelo con la mayor satisfacción del usuario a nivel mundial (ELO 1503), con ventajas evidentes en código complejo, agentes y razonamiento abstracto.
- Para la mayoría de los proyectos reales, Claude Sonnet 4.6 es la solución óptima en costo-beneficio: ocupa el primer lugar en PinchBench y su precio es muy inferior al de Opus 4.6.
No existe el "mejor modelo para siempre", solo el modelo que mejor se adapta a tu escenario.
🚀 Prueba ahora: En la plataforma APIYI (apiyi.com), puedes usar una sola clave API para acceder simultáneamente a GPT-5.4, Claude Opus 4.6 y Claude Sonnet 4.6. Compara el rendimiento y el costo de los tres modelos con tus datos de negocio reales. Los nuevos usuarios que se registren recibirán una cuota de prueba para ayudarte a tomar la mejor decisión antes del lanzamiento.
Fuentes de datos: Documentación oficial de Anthropic, documentación de la API de OpenAI, clasificación de Chatbot Arena (febrero de 2026), clasificación de PinchBench (13 de marzo de 2026), comparativa de modelos de Artificial Analysis y evaluaciones técnicas de DigitalApplied. Los datos pueden variar con las actualizaciones de los modelos; se recomienda consultar la documentación oficial más reciente.
Autor: Equipo APIYI | Publicado en AI123.dev