Gemini 3.1 Pro Preview와 Gemini 3.0 Pro Preview의 가격은 완전히 동일합니다. 입력 $2.00, 출력 $12.00 / 100만 토큰이죠. 그렇다면 질문이 생깁니다. 3.1은 도대체 3.0보다 구체적으로 무엇이 더 나을까요? 전환할 가치가 있을까요?
정답은 **"매우 가치 있으며, 전환하지 않을 이유가 전혀 없다"**입니다.
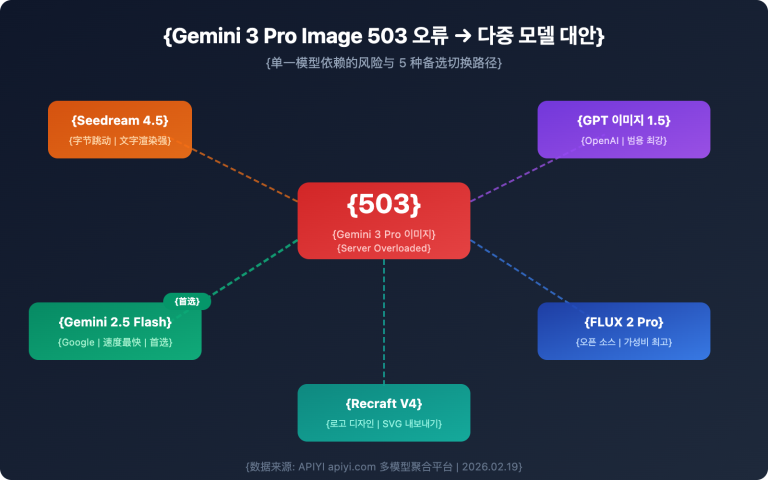
이 글에서는 실제 벤치마크 데이터를 통해 두 버전의 차이점을 항목별로 비교해 보겠습니다. 결론부터 살짝 공개하자면, 3.1 Pro의 ARC-AGI-2 추론 점수는 31.1%에서 77.1%로 2.5배나 급등했습니다. SWE-Bench 코딩은 76.8%에서 80.6%로, BrowseComp 검색은 59.2%에서 85.9%로 향상되었습니다. 이건 단순한 미세 조정이 아니라 세대 교체급 업그레이드입니다.
핵심 가치: 이 글을 읽고 나면 {Gemini 3.1 Pro Preview}가 {Gemini 3.0 Pro Preview}에 비해 개선된 구체적인 사항들과 다양한 시나리오에서의 선택 방법을 명확히 알게 될 것입니다.

Gemini 3.1 Pro와 3.0 Pro 파라미터 비교 총괄표
먼저 하드웨어 파라미터 측면의 차이점을 살펴보겠습니다.
| 비교 항목 | Gemini 3.0 Pro Preview | Gemini 3.1 Pro Preview | 변화 |
|---|---|---|---|
| 모델 ID | gemini-3-pro-preview |
gemini-3.1-pro-preview |
신규 버전 |
| 출시일 | 2025년 11월 18일 | 2026년 2월 19일 | +3개월 |
| 입력 가격 (≤200K) | $2.00 / M tokens | $2.00 / M tokens | 동일 |
| 출력 가격 (≤200K) | $12.00 / M tokens | $12.00 / M tokens | 동일 |
| 입력 가격 (>200K) | $4.00 / M tokens | $4.00 / M tokens | 동일 |
| 출력 가격 (>200K) | $18.00 / M tokens | $18.00 / M tokens | 동일 |
| 컨텍스트 윈도우 | 1M tokens | 1M tokens | 동일 |
| 최대 출력 | — | 65K tokens | 명확한 향상 |
| 파일 업로드 제한 | 20MB | 100MB | 5배 |
| YouTube URL 지원 | ❌ | ✅ | 추가됨 |
| 사고 레벨 (Thinking Level) | 2단계 (low/high) | 3단계 (low/medium/high) | medium 추가 |
| customtools 엔드포인트 | ❌ | ✅ | 추가됨 |
| 지식 컷오프 | 2025년 1월 | 2025년 1월 | 동일 |
가격, 컨텍스트 윈도우, 지식 컷오프는 완전히 동일합니다. 모든 변화는 순수한 능력 향상에 집중되어 있습니다.
🎯 핵심 결론: 가격은 그대로인데 기능은 더 많아졌습니다. 파라미터 측면에서 볼 때, 3.1 Pro는 3.0 Pro의 완벽한 상위 호환 모델입니다. APIYI(apiyi.com)를 통해 호출하는 경우,
model파라미터를gemini-3-pro-preview에서gemini-3.1-pro-preview로 바꾸기만 하면 즉시 업그레이드가 완료됩니다.
차이점 1: 추론 능력 — '우수함'에서 '최정상'으로
이는 3.0에서 3.1로 넘어오며 이루어진 가장 큰 개선 사항이자, 구글이 공식적으로 가장 강조하는 업그레이드 포인트입니다.
| 추론 벤치마크 | 3.0 Pro | 3.1 Pro | 향상 폭 | 설명 |
|---|---|---|---|---|
| ARC-AGI-2 | 31.1% | 77.1% | +148% | 새로운 논리 패턴 추론 |
| GPQA Diamond | — | 94.3% | — | 대학원 수준의 과학적 추론 |
| MMMLU | — | 92.6% | — | 다학제 다모달 이해 |
| LiveCodeBench Pro | — | Elo 2887 | — | 실시간 프로그래밍 경진대회 |
ARC-AGI-2의 향상 폭은 정말 놀랍습니다. 31.1%에서 77.1%로, 단순히 두 배가 된 것이 아니라 무려 2.5배나 뛰어올랐거든요. 이 벤치마크는 모델이 새로운 논리 패턴을 해결하는 능력, 즉 모델이 이전에 본 적 없는 유형의 추론 문제를 얼마나 잘 푸는지를 평가합니다. 77.1%라는 점수는 Claude Opus 4.6의 68.8%를 뛰어넘는 수치로, 추론 영역에서 확실한 선두 자리를 굳혔습니다.
기술적인 배경: 구글은 공식적으로 3.1 Pro를 「unprecedented depth and nuance」(전례 없는 깊이와 섬세함)를 가졌다고 묘사하는 반면, 3.0 Pro는 「advanced intelligence」(고급 지능)라고 표현합니다. 이는 단순한 마케팅 문구의 변화가 아닙니다. ARC-AGI-2 데이터가 증명하듯, 추론의 깊이 면에서 질적인 도약이 있었음을 의미합니다.
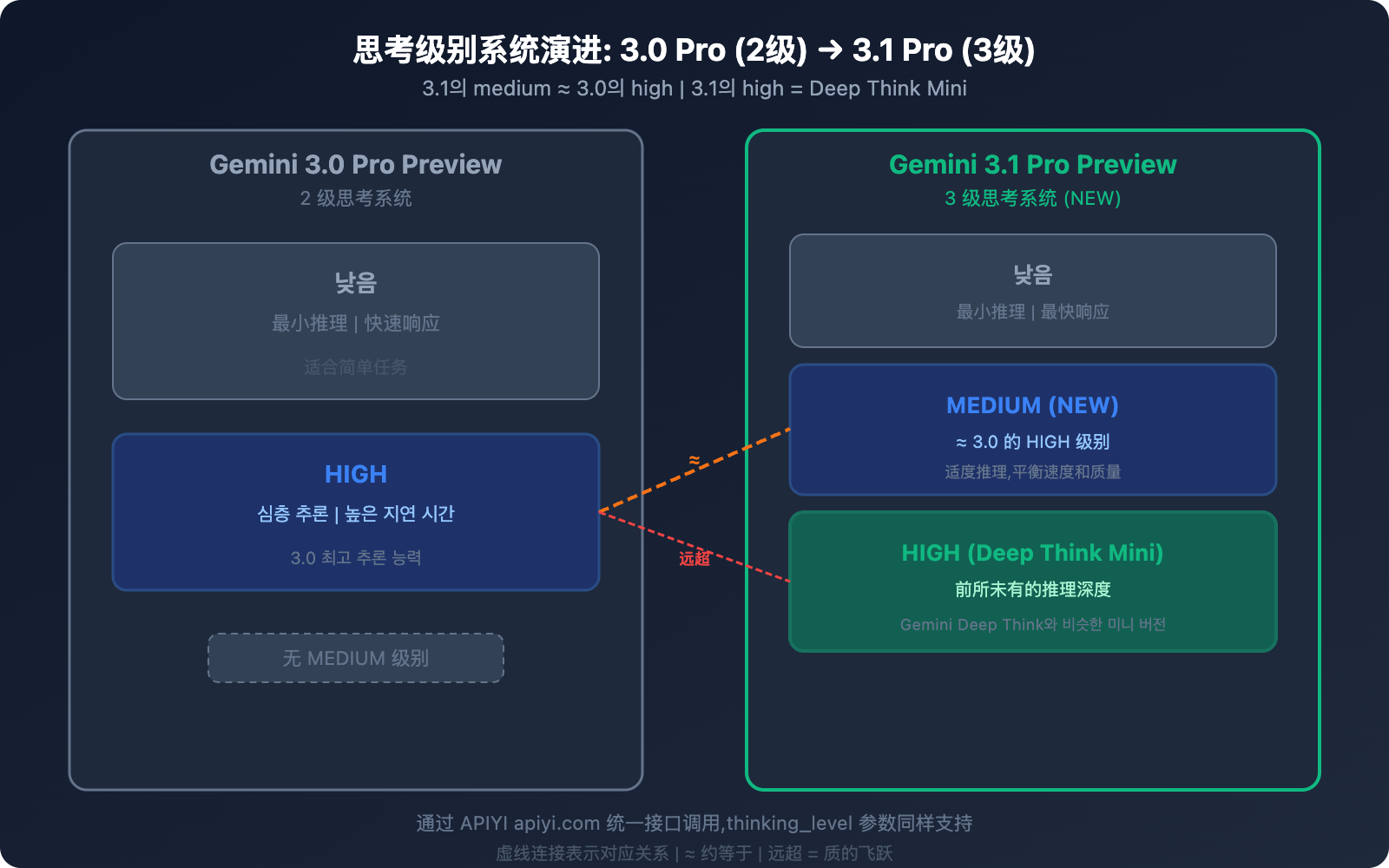
차이점 2: 사고 레벨 시스템 — 2단계에서 3단계로
이 부분은 3.1 Pro에서 가장 실무적으로 유용한 개선 사항 중 하나입니다.
3.0 Pro의 사고 시스템 (2단계)
| 레벨 | 동작 방식 |
|---|---|
| low | 최소한의 추론, 빠른 응답 |
| high | 깊은 추론, 높은 지연 시간 |
3.1 Pro의 사고 시스템 (3단계)
| 레벨 | 동작 방식 | 대응 관계 |
|---|---|---|
| low | 최소한의 추론, 빠른 응답 | 3.0의 low와 유사 |
| medium (신규) | 적절한 추론, 속도와 품질의 균형 | ≈ 3.0의 high |
| high | Deep Think Mini 모드, 가장 깊은 추론 | 3.0의 high를 훨씬 능가 |
핵심 정보: 3.1 Pro의 medium ≈ 3.0 Pro의 high입니다. 이것이 의미하는 바는 다음과 같습니다.
- 3.1의 medium만 사용해도 3.0의 최고 수준 추론 품질을 얻을 수 있습니다.
- 3.1의 high는 완전히 새로운 차원입니다. Gemini Deep Think의 미니 버전이라고 볼 수 있죠.
- 동일한 추론 품질(medium 기준)을 유지하면서도 3.0의 high보다 지연 시간이 더 짧습니다.
💡 실전 팁: 이전에 3.0 Pro의 high 모드를 주로 사용하셨다면, 3.1 Pro로 전환한 후에는 먼저 medium을 사용해 보세요. 추론 품질은 비슷하면서도 지연 시간은 더 짧습니다. 정말 복잡한 추론 작업이 필요할 때만 high(Deep Think Mini)로 전환하면, 비용을 늘리지 않고도 더 나은 전체 경험을 얻을 수 있습니다. APIYI apiyi.com 플랫폼은
thinking_level파라미터 전달을 지원합니다.
차이점 3: 코딩 능력 — 최상위권(1티어) 진입
| 코딩 벤치마크 | 3.0 Pro | 3.1 Pro | 향상 | 업계 비교 |
|---|---|---|---|---|
| SWE-Bench Verified | 76.8% | 80.6% | +3.8% | Claude Opus 4.6: 80.9% |
| Terminal-Bench 2.0 | 56.9% | 68.5% | +11.6% | 에이전트 터미널 코딩 |
| LiveCodeBench Pro | — | Elo 2887 | — | 실시간 프로그래밍 경진대회 |
SWE-Bench Verified의 점수 향상은 겉보기에는 3.8%p(76.8% → 80.6%)에 불과해 보이지만, 이 정도 고득점 구간에서 1%를 올리는 것은 매우 어려운 일이에요. 80.6%라는 성적 덕분에 Gemini 3.1 Pro는 Claude Opus 4.6(80.9%)과의 격차를 단 **0.3%**로 좁혔습니다. 이제 '2티어 선두'에서 '1티어와 어깨를 나란히 하는 수준'으로 올라선 것이죠.
Terminal-Bench 2.0의 향상은 더욱 눈에 띕니다. 56.9%에서 68.5%로 약 20.4%나 개선되었거든요. 이 벤치마크는 에이전트가 터미널 환경에서 코딩 작업을 수행하는 능력을 전문적으로 평가하는데, 11.6%p의 향상은 3.1 Pro가 자동화 프로그래밍 시나리오에서 훨씬 더 높은 신뢰성을 갖게 되었음을 의미해요.
차이점 4: 에이전트 및 검색 능력 — 비약적인 도약
| 에이전트 벤치마크 | 3.0 Pro | 3.1 Pro | 향상 폭 |
|---|---|---|---|
| BrowseComp | 59.2% | 85.9% | +45.1% |
| MCP Atlas | 54.1% | 69.2% | +27.9% |
이 두 항목은 3.0에서 3.1로 넘어오며 가장 큰 폭으로 향상된 벤치마크입니다.
BrowseComp는 에이전트의 웹 검색 능력을 평가하는데요. 59.2%에서 85.9%로 무려 26.7%p나 급등했습니다. 이는 리서치 어시스턴트, 경쟁사 분석, 실시간 정보 검색형 에이전트를 구축할 때 엄청난 이점이 됩니다.
MCP Atlas는 모델 컨텍스트 프로토콜(Model Context Protocol)을 사용하는 다단계 워크플로우 능력을 측정합니다. 54.1%에서 69.2%로 향상되었죠. MCP는 구글이 밀고 있는 에이전트 프로토콜 표준으로, 이 수치의 상승은 3.1 Pro가 복잡한 에이전트 워크플로우를 조율하고 실행하는 능력이 눈에 띄게 강화되었음을 보여줍니다.
customtools 전용 엔드포인트: 3.1 Pro에는 gemini-3.1-pro-preview-customtools라는 전용 엔드포인트가 추가되었습니다. bash 명령과 사용자 정의 함수를 혼합해서 호출하는 시나리오에 최적화되어 있죠. 특히 개발자들이 자주 사용하는 view_file, search_code 같은 도구의 호출 우선순위를 정교하게 튜닝하여, 자동화된 운영 및 관리(DevOps)나 AI 코딩 어시스턴트 같은 에이전트 환경에서 일반 엔드포인트보다 훨씬 안정적이고 신뢰할 수 있는 성능을 보여줍니다.
🎯 에이전트 개발자 참고: 코드 리뷰 봇이나 자동 배포 에이전트 등을 만들고 있다면 customtools 엔드포인트를 사용해 보시는 걸 강력히 추천해요. APIYI apiyi.com을 통해 이 엔드포인트를 바로 호출할 수 있으며, model 파라미터에
gemini-3.1-pro-preview-customtools를 입력하면 됩니다.
차이점 5: 출력 능력 및 API 기능
| 기능 | 3.0 Pro | 3.1 Pro | 변화 |
|---|---|---|---|
| 최대 출력 토큰 | 미명시 | 65,000 | 65K로 명확히 표기 |
| 파일 업로드 제한 | 20MB | 100MB | 5배 향상 |
| YouTube URL | ❌ 미지원 | ✅ 직접 입력 가능 | 신규 추가 |
| customtools 엔드포인트 | ❌ | ✅ | 신규 추가 |
| 출력 효율 | 기준 | +15% | 더 적은 토큰으로 더 나은 결과 |
65K 출력 제한: 이제 긴 문서, 방대한 코드 블록 또는 상세한 분석 보고서를 한 번에 생성할 수 있어요. 여러 번 요청해서 이어 붙일 필요가 없어진 거죠.
100MB 파일 업로드: 업로드 용량이 20MB에서 100MB로 확장되었습니다. 이는 더 큰 코드 저장소(Repository), 대용량 PDF 문서 세트 또는 미디어 파일을 직접 업로드해서 분석할 수 있다는 의미예요.
YouTube URL 직접 입력: 프롬프트에 YouTube 링크를 직접 넣으면 모델이 자동으로 영상 내용을 분석합니다. 따로 다운로드하거나 인코딩해서 업로드할 필요가 없어서 정말 편해요.
15% 출력 효율 향상: JetBrains의 AI 디렉터가 직접 테스트한 결과에 따르면, 3.1 Pro는 더 적은 토큰을 사용하면서도 더 신뢰할 수 있는 결과를 만들어냅니다. 즉, 동일한 작업을 수행할 때 실제 토큰 소모량이 줄어들어 비용 면에서 훨씬 유리합니다.
각 기능이 사용자에게 주는 가치
| 기능 | 개인 개발자에게 주는 가치 | 기업 팀에게 주는 가치 |
|---|---|---|
| 65K 출력 | 전체 코드 파일을 한 번에 생성 | 기술 문서 및 보고서 대량 생성 |
| 100MB 업로드 | 전체 프로젝트를 업로드하여 분석 | 대규모 코드 저장소 감사(Audit) |
| YouTube URL | 튜토리얼 영상의 빠른 분석 | 경쟁사 제품 데모 분석 |
| customtools | AI 프로그래밍 어시스턴트 개발 | 자동화 운영(Ops) 에이전트 구축 |
| 효율 +15% | 개인 API 호출 비용 절감 | 대규모 사용 환경에서 현저한 비용 최적화 |
💰 비용 실측: 동일한 작업에서 3.1 Pro의 실제 출력 토큰 소모량은 3.0 Pro보다 평균 10~15% 낮았습니다. 일일 평균 백만 토큰 단위를 사용하는 기업용 애플리케이션이라면, 모델 교체만으로 매달 수백 달러를 아낄 수 있어요. **APIYI (apiyi.com)**의 사용량 통계 기능을 활용하면 이 차이를 정밀하게 비교해 볼 수 있습니다.
차이점 6: 출력 효율 — 더 적은 토큰으로 더 나은 결과 얻기
이 부분은 간과하기 쉽지만 실제로는 매우 큰 개선 사항입니다. JetBrains의 AI 디렉터인 Vladislav Tankov의 실측 피드백에 따르면, 3.1 Pro는 3.0 Pro 대비 품질은 15% 향상되었으면서도 출력 토큰 소모량은 더 적습니다.
이것이 실제로 어떤 의미가 있을까요?
낮아지는 실제 사용 비용: 토큰당 단가는 같더라도, 3.1 Pro가 동일한 작업을 더 적은 토큰으로 끝내기 때문에 실제 청구되는 금액은 더 저렴해집니다. 예를 들어 하루에 100만 출력 토큰을 사용하는 앱이라면, 15%의 효율 향상만으로도 매일 약 $1.80의 비용을 절약할 수 있죠.
더 빠른 응답 속도: 출력 토큰이 적다는 것은 생성 시간이 짧아진다는 뜻이기도 합니다. 지연 시간(Latency)에 민감한 실시간 애플리케이션에서 이 개선은 매우 가치가 큽니다.
더 정교해진 출력 품질: 3.1 Pro는 단순히 '말을 적게 하는 것'이 아니라 '더 정확하게 말하는 것'에 집중합니다. 중언부언하는 군더더기를 줄이고, 더 압축된 표현으로 동일하거나 혹은 더 많은 정보를 전달해 줍니다.
차이점 7: 보안 및 안정성
| 보안 차원 | 3.0 Pro | 3.1 Pro | 변화 |
|---|---|---|---|
| 텍스트 보안성 | 기준 | +0.10% | 소폭 상승 |
| 다국어 보안성 | 기준 | +0.11% | 소폭 상승 |
| 오거부율(False Refusal Rate) | 기준 | 낮은 수준 유지 | 불변 |
| 긴 작업 안정성 | 기준 | 향상 | 더 신뢰할 수 있음 |
보안성 향상 수치가 아주 크지는 않지만, 성능을 높이면서도 보안을 희생하지 않았다는 점에서 방향성은 매우 긍정적입니다. 특히 긴 작업에서의 안정성 향상은 에이전트(Agent) 애플리케이션에 매우 중요한데요. 이는 여러 단계로 이루어진 워크플로우에서 3.1 Pro가 경로를 이탈하거나 신뢰할 수 없는 출력을 내놓을 확률이 더 낮아졌음을 의미합니다.
차이점 8: 공식 포지셔닝 설명의 변화
| 차원 | 3.0 Pro 설명 | 3.1 Pro 설명 |
|---|---|---|
| 핵심 포지셔닝 | advanced intelligence | unprecedented depth and nuance |
| 추론 특징 | advanced reasoning | SOTA reasoning |
| 코딩 특징 | agentic and vibe coding | powerful coding |
| 멀티모달 | multimodal understanding | powerful multimodal understanding |
'advanced'에서 'unprecedented'로, 'agentic and vibe coding'에서 'powerful coding'으로의 변화는 포지셔닝의 업그레이드를 잘 보여줍니다. 3.0 Pro가 '고급'과 '혁신(vibe coding)'을 강조했다면, 3.1 Pro는 '깊이'와 '강력함'에 더 방점을 찍고 있습니다.
차이점 9: 사용 권장 사항——언제 어떤 모델을 써야 할까요?

마이그레이션 코드 예시
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # APIYI 통합 인터페이스
)
# 3.0 Pro → 3.1 Pro 전환은 파라미터 하나만 바꾸면 됩니다.
# 구버전: model="gemini-3-pro-preview"
# 신버전: model="gemini-3.1-pro-preview"
response = client.chat.completions.create(
model="gemini-3.1-pro-preview", # 유일하게 수정이 필요한 부분
messages=[{"role": "user", "content": "이 코드의 성능 병목 현상을 분석해줘"}]
)
A/B 테스트 비교 코드 보기
import openai
import time
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # APIYI 통합 인터페이스
)
test_prompt = "배열 [3,1,4,1,5,9,2,6]이 주어졌을 때, 병합 정렬을 사용하고 시간 복잡도를 분석해줘"
# 3.0 Pro 테스트
start = time.time()
resp_30 = client.chat.completions.create(
model="gemini-3-pro-preview",
messages=[{"role": "user", "content": test_prompt}]
)
time_30 = time.time() - start
# 3.1 Pro 테스트
start = time.time()
resp_31 = client.chat.completions.create(
model="gemini-3.1-pro-preview",
messages=[{"role": "user", "content": test_prompt}]
)
time_31 = time.time() - start
print(f"3.0 Pro: {time_30:.2f}s, {resp_30.usage.total_tokens} tokens")
print(f"3.1 Pro: {time_31:.2f}s, {resp_31.usage.total_tokens} tokens")
print(f"\n3.0 답변:\n{resp_30.choices[0].message.content[:300]}...")
print(f"\n3.1 답변:\n{resp_31.choices[0].message.content[:300]}...")
마이그레이션 주의 사항 및 베스트 프랙티스
1단계: 핵심 시나리오 테스트
가장 자주 사용하는 3~5개의 프롬프트에서 3.0과 3.1의 출력을 비교해 보세요. 추론 품질, 코드 정확성, 출력 형식에 중점을 두어 확인합니다.
2단계: 사고 수준(Thinking Level) 조정
기존에 3.0의 high 모드를 사용했다면, 3.1로 전환 시 먼저 medium 모드를 사용해 보시길 권장합니다(추론 품질은 비슷하면서 속도는 더 빠릅니다). 정말 깊은 추론이 필요한 경우에만 high(Deep Think Mini)를 사용하세요.
3단계: 새로운 기능 탐색
100MB 파일 업로드, YouTube URL 분석, 65K 장문 출력 등 3.1만의 독보적인 기능을 시도해 보세요. 새로운 애플리케이션 시나리오를 발견할 수 있습니다.
4단계: 전체 전환
효과를 확인했다면 모든 호출을 gemini-3-pro-preview에서 gemini-3.1-pro-preview로 변경하세요. 3.1이 실제 환경에서 일주일 이상 안정적으로 작동할 때까지 3.0을 폴백(fallback)으로 유지하는 것이 좋습니다.
🚀 빠른 마이그레이션: APIYI(apiyi.com) 플랫폼을 통하면 3.0에서 3.1로의 마이그레이션은 파라미터 하나만 바꾸면 끝납니다. 먼저 몇 가지 핵심 시나리오에서 A/B 테스트를 진행해 효과를 확인한 후 전체 전환을 진행해 보세요.
자주 묻는 질문 (FAQ)
Q1: 3.1 Pro와 3.0 Pro는 완전히 호환되나요? 전환 후 프롬프트를 수정해야 할까요?
API 인터페이스는 완전히 호환되므로 model 파라미터만 수정하면 됩니다. 다만 3.1 Pro의 추론 방식이 개선되었기 때문에, 3.0에 맞춰 정교하게 튜닝된 일부 프롬프트는 3.1에서 결과가 약간 다를 수 있습니다. 보통은 더 좋아지지만, 핵심 시나리오에 대해서는 회귀 테스트를 해보는 것이 좋습니다. APIYI(apiyi.com)를 이용하면 두 버전을 동시에 호출하여 간편하게 비교할 수 있습니다.
Q2: 3.0 Pro는 계속 유지되나요? 언제 서비스가 종료되나요?
Preview 모델의 경우, 구글은 보통 종료 최소 2주 전에 공지합니다. 현재 3.0 Pro는 여전히 사용 가능하지만, 3.1 Pro가 모든 면에서 상위 호환인 대안이므로 가급적 빨리 마이그레이션하는 것을 추천합니다. APIYI(apiyi.com)를 통한 호출은 구글 측의 버전 조정에 영향을 받지 않으며, 플랫폼에서 모델 라우팅을 자동으로 처리합니다.
Q3: 3.1 Pro의 high 사고 모드는 토큰 소모가 큰가요?
high 모드(Deep Think Mini)는 모델 내부에서 더 깊은 추론 체인을 거치기 때문에 확실히 더 많은 출력 토큰을 소모합니다. 일상적인 작업에는 medium(3.0의 high 품질과 대등)을 사용하고, 수학적 추론이나 복잡한 디버깅 같은 상황에서만 high를 사용하시길 권장합니다. 이렇게 하면 대부분의 작업에서 비용을 유지하거나 오히려 낮출 수 있습니다.
Q4: 두 버전 모두 APIYI에서 사용할 수 있나요?
네, 모두 가능합니다. APIYI(apiyi.com)는 gemini-3-pro-preview와 gemini-3.1-pro-preview를 동시에 지원하며, 동일한 API Key와 base_url을 사용하므로 A/B 테스트와 유연한 전환이 매우 간편합니다.
사용자별 Gemini 3.1 Pro 업그레이드 제안
개발자 유형에 따라 3.0에서 3.1로 업그레이드했을 때 얻는 이점이 다릅니다. 나에게 맞는 제안을 확인해 보세요.
| 사용자 유형 | 가장 큰 차이점 | 업그레이드 우선순위 | 권장 작업 |
|---|---|---|---|
| AI 에이전트 개발자 | 에이전트/검색 +45%, MCP Atlas +28% | ⭐⭐⭐⭐⭐ | 즉시 전환하세요. 성능 향상이 가장 뚜렷합니다. |
| 코드 보조 도구 | SWE-Bench +5%, Terminal-Bench +20% | ⭐⭐⭐⭐ | 전환을 추천합니다. medium 모드만으로도 충분합니다. |
| 데이터 분석가 | 추론 ARC-AGI-2 +148%, 100MB 업로드 | ⭐⭐⭐⭐⭐ | 우선적으로 전환하세요. 대용량 파일 분석 능력이 대폭 강화되었습니다. |
| 콘텐츠 크리에이터 | 65K 장문 출력, YouTube URL 분석 | ⭐⭐⭐⭐ | 전환을 추천합니다. 새로운 기능들이 매우 실용적입니다. |
| 라이트 API 사용자 | 출력 효율 +15%, 비용 동일 | ⭐⭐⭐ | 편할 때 전환하세요. 같은 가격에 더 나은 성능을 얻을 수 있습니다. |
| 보안 민감형 앱 | 보안 신뢰성 향상, 긴 작업 안정성 | ⭐⭐⭐⭐ | 회귀 테스트를 먼저 거친 후 전환하세요. |
💡 공통 제안: 어떤 사용자 유형이든 APIYI(apiyi.com)를 통해 3.0과 3.1 버전을 동시에 유지할 수 있습니다. A/B 테스트로 효과를 직접 확인한 후 전체 전환을 진행해 보세요. 마이그레이션 비용과 리스크가 전혀 없습니다.
Gemini 3.1 Pro 버전 전환 의사결정 프로세스
다음 단계에 따라 전환 여부를 결정해 보세요.
- 애플리케이션이 추론 정확도에 의존하나요? → 예 → 즉시 전환 (ARC-AGI-2 148% 향상)
- 애플리케이션에 에이전트나 검색 기능이 포함되나요? → 예 → 강력 추천 (BrowseComp +45%)
- 프롬프트가 고도로 커스터마이징되어 있나요? → 예 → 먼저 medium 모드로 테스트하여 출력이 일관된지 확인 후 전환
- 단순 질의응답이나 번역만 수행하나요? → 예 → 언제든 전환하세요. 성능은 비슷하거나 더 좋으면서 효율은 더 높습니다.
- 확신이 서지 않나요? → APIYI(apiyi.com)에서 핵심 프롬프트 5개로 A/B 테스트를 해보세요. 10분이면 결론이 납니다.
요약: 9가지 차이점 정리
| # | 차이점 항목 | 3.0 Pro → 3.1 Pro | 전환 가치 |
|---|---|---|---|
| 1 | 추론 능력 | ARC-AGI-2: 31.1% → 77.1% | 매우 높음 |
| 2 | 사고 시스템 | 2단계 → 3단계 (Deep Think Mini 포함) | 높음 |
| 3 | 코딩 능력 | SWE-Bench: 76.8% → 80.6% | 높음 |
| 4 | 에이전트/검색 | BrowseComp: 59.2% → 85.9% | 매우 높음 |
| 5 | 출력/API 특성 | 65K 출력, 100MB 업로드, YouTube URL 지원 | 높음 |
| 6 | 출력 효율 | 더 적은 토큰으로 더 나은 결과 도출 (+15%) | 높음 |
| 7 | 보안 및 신뢰성 | 보안성 소폭 향상, 긴 작업 안정성 개선 | 보통 |
| 8 | 공식 포지셔닝 | advanced → unprecedented depth | 신호 |
| 9 | 적용 시나리오 | 거의 모든 시나리오에서 전환 권장 | 명확 |
한 줄 요약: 동일한 가격, API 호환성, 그리고 모든 지표에서의 성능 향상까지. Gemini 3.1 Pro Preview는 3.0 Pro Preview의 무료 세대교체 업그레이드입니다. 전환하지 않을 이유가 전혀 없죠.
모델 파라미터 하나만 수정하면 되는 APIYI(apiyi.com)를 통해 빠르게 마이그레이션을 완료해 보세요.
참고 자료
-
Google 공식 블로그: Gemini 3.1 Pro 출시 발표
- 링크:
blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-3-1-pro - 설명: 공식 벤치마크 성적 및 기능 소개
- 링크:
-
Google DeepMind 모델 카드: 3.1 Pro 기술 세부 사항 및 안전성 평가
- 링크:
deepmind.google/models/model-cards/gemini-3-1-pro - 설명: 안전성 데이터 및 상세 파라미터
- 링크:
-
VentureBeat 첫 리뷰: Deep Think Mini 기능 심층 체험
- 링크:
venturebeat.com/technology/google-gemini-3-1-pro-first-impressions - 설명: 3단계 사고 시스템 실제 사용 보고서
- 링크:
-
Artificial Analysis: 3.1 Pro vs 3.0 Pro 비교 데이터
- 링크:
artificialanalysis.ai/models/comparisons/gemini-3-1-pro-preview-vs-gemini-3-pro - 설명: 제3자 벤치마크 비교 및 성능 분석
- 링크:
📝 작성자: APIYI Team | 기술 교류는 APIYI(apiyi.com)를 방문해 주세요.
📅 업데이트 날짜: 2026년 2월 20일
🏷️ 키워드: Gemini 3.1 Pro vs 3.0 Pro, 모델 비교, 추론 성능 향상, SWE-Bench, ARC-AGI-2, Deep Think Mini