Gemini 3.1 Pro Preview und Gemini 3.0 Pro Preview kosten exakt dasselbe – Input $2,00, Output $12,00 / Million Tokens. Da stellt sich die Frage: Wo genau ist 3.1 stärker als 3.0? Lohnt sich der Wechsel?
Die Antwort lautet: Absolut, es gibt keinen Grund, nicht zu wechseln.
In diesem Artikel vergleichen wir die Unterschiede beider Versionen anhand echter Benchmark-Daten. Kleiner Spoiler vorab: Der ARC-AGI-2 Reasoning-Score von 3.1 Pro ist von 31,1 % auf 77,1 % in die Höhe geschossen – das 2,5-fache; SWE-Bench Coding stieg von 76,8 % auf 80,6 %; BrowseComp Search sprang von 59,2 % auf 85,9 %. Das ist kein bloßes Fine-Tuning, das ist ein Upgrade auf Generationsniveau.
Kernbotschaft: Nach der Lektüre dieses Artikels werden Sie jede spezifische Verbesserung von 3.1 Pro gegenüber 3.0 Pro genau kennen und wissen, wie Sie sich in verschiedenen Szenarien entscheiden sollten.

Vergleichstabelle: Gemini 3.1 Pro vs. 3.0 Pro
Schauen wir uns zunächst die Unterschiede bei den harten Fakten an:
| Vergleichsdimension | Gemini 3.0 Pro Preview | Gemini 3.1 Pro Preview | Änderung |
|---|---|---|---|
| Modell-ID | gemini-3-pro-preview |
gemini-3.1-pro-preview |
Neue Version |
| Veröffentlichungsdatum | 18. November 2025 | 19. Februar 2026 | +3 Monate |
| Input-Preis (≤200K) | $2,00 / M Tokens | $2,00 / M Tokens | Unverändert |
| Output-Preis (≤200K) | $12,00 / M Tokens | $12,00 / M Tokens | Unverändert |
| Input-Preis (>200K) | $4,00 / M Tokens | $4,00 / M Tokens | Unverändert |
| Output-Preis (>200K) | $18,00 / M Tokens | $18,00 / M Tokens | Unverändert |
| Kontextfenster | 1M Tokens | 1M Tokens | Unverändert |
| Maximaler Output | — | 65K Tokens | Deutliche Steigerung |
| Dateiupload-Limit | 20 MB | 100 MB | 5-fache Kapazität |
| YouTube-URL Support | ❌ | ✅ | Neu |
| Thinking-Level | 2 Stufen (low/high) | 3 Stufen (low/medium/high) | Neu: medium |
| customtools Endpunkt | ❌ | ✅ | Neu |
| Wissensstand | Januar 2025 | Januar 2025 | Unverändert |
Preis, Kontextfenster und Wissensstand bleiben völlig gleich. Alle Änderungen sind reine Fähigkeitssteigerungen.
🎯 Kernfazit: Kein Cent teurer, aber deutlich mehr Funktionen. Auf Parameterebene ist 3.1 Pro der strikte Nachfolger von 3.0 Pro. Über APIYI apiyi.com müssen Sie lediglich den Parameter
modelvongemini-3-pro-previewaufgemini-3.1-pro-previewändern, um das Upgrade abzuschließen.
Unterschied 1: Schlussfolgerungsfähigkeit – von „exzellent“ zu „spitzenklasse“
Dies ist die bedeutendste Verbesserung von 3.0 auf 3.1 und der von Google am stärksten hervorgehobene Upgrade-Punkt.
| Benchmark | 3.0 Pro | 3.1 Pro | Zuwachs | Beschreibung |
|---|---|---|---|---|
| ARC-AGI-2 | 31,1 % | 77,1 % | +148 % | Schlussfolgerung in völlig neuen Logikmustern |
| GPQA Diamond | — | 94,3 % | — | Wissenschaftliche Schlussfolgerungen auf Postgraduierten-Niveau |
| MMMLU | — | 92,6 % | — | Multidisziplinäres und multimodales Verständnis |
| LiveCodeBench Pro | — | Elo 2887 | — | Echtzeit-Programmierwettbewerb |
Die Steigerung bei ARC-AGI-2 ist am erstaunlichsten: Von 31,1 % auf 77,1 % ist keine bloße Verdopplung, sondern eine Steigerung um das 2,5-fache. Dieser Benchmark bewertet die Fähigkeit des Modells, völlig neue Logikmuster zu lösen – also Aufgabentypen, die das Modell zuvor noch nie gesehen hat. Mit einer Punktzahl von 77,1 % übertrifft es auch die 68,8 % von Claude Opus 4.6 und etabliert damit eine führende Position in der Dimension der logischen Schlussfolgerung.
Technische Hintergründe: Google beschreibt 3.1 Pro offiziell mit einer „unprecedented depth and nuance“ (beispiellose Tiefe und Nuanciertheit), während 3.0 Pro als „advanced intelligence“ (fortgeschrittene Intelligenz) bezeichnet wurde. Dies ist nicht nur eine Änderung im Marketing-Wording; die Daten von ARC-AGI-2 belegen, dass die Tiefe der Schlussfolgerungen tatsächlich einen Quantensprung gemacht hat.
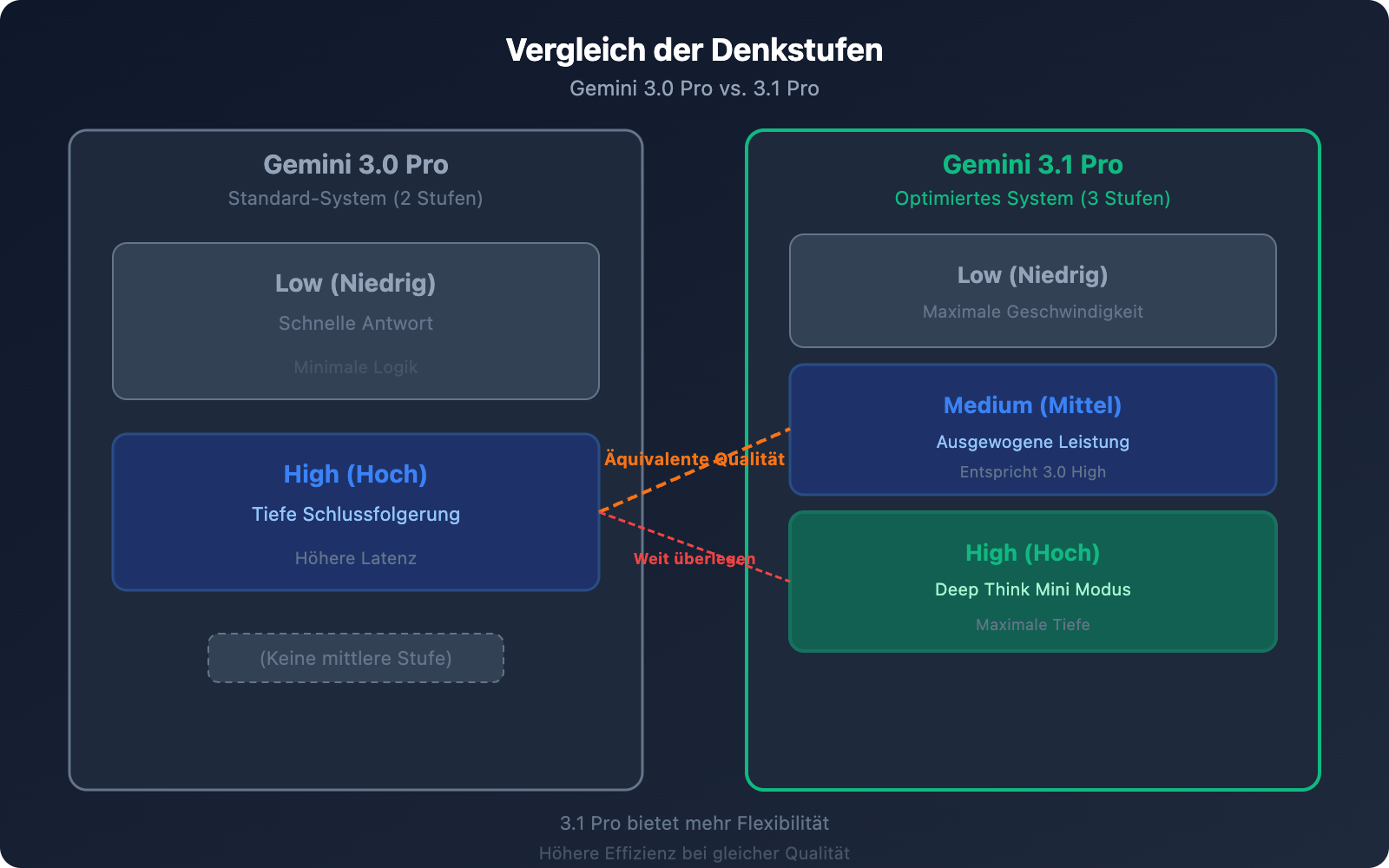
Unterschied 2: Denkstufen-System – von 2 auf 3 Stufen
Dies ist eine der praktischsten Verbesserungen von 3.1 Pro.
Das Denksystem von 3.0 Pro (2 Stufen)
| Stufe | Verhalten |
|---|---|
| low | Minimale Schlussfolgerung, schnelle Antwort |
| high | Tiefe Schlussfolgerung, höhere Latenz |
Das Denksystem von 3.1 Pro (3 Stufen)
| Stufe | Verhalten | Entsprechung |
|---|---|---|
| low | Minimale Schlussfolgerung, schnelle Antwort | Ähnlich wie 3.0 low |
| medium (Neu) | Moderate Schlussfolgerung, Balance zwischen Speed und Qualität | ≈ 3.0 high |
| high | Deep Think Mini Modus, tiefste Schlussfolgerung | Weit über 3.0 high |
Kernbotschaft: 3.1 Pro Medium ≈ 3.0 Pro High. Das bedeutet:
- Mit der Einstellung „medium“ bei 3.1 erhalten Sie die gleiche Qualität wie bei der höchsten Stufe von 3.0.
- Die Stufe „high“ bei 3.1 ist eine völlig neue Klasse – vergleichbar mit einer Mini-Version von Gemini Deep Think.
- Bei gleicher Qualität (medium) ist die Latenz geringer als bei 3.0 high.
💡 Praxis-Tipp: Wenn Sie bisher immer den „high“-Modus von 3.0 Pro genutzt haben, empfiehlt es sich, nach dem Wechsel zu 3.1 Pro zunächst „medium“ zu verwenden – die Qualität der Schlussfolgerungen ist vergleichbar, aber die Latenz ist geringer. Wechseln Sie nur dann auf „high“ (Deep Think Mini), wenn Sie wirklich komplexe logische Aufgaben haben. So erhalten Sie ein besseres Gesamterlebnis ohne zusätzliche Kosten. Die Plattform APIYI apiyi.com unterstützt die Übergabe des Parameters
thinking_level.
Unterschied 3: Coding-Fähigkeiten – Aufstieg in die erste Riege
| Coding-Benchmark | 3.0 Pro | 3.1 Pro | Steigerung | Branchenvergleich |
|---|---|---|---|---|
| SWE-Bench Verified | 76,8 % | 80,6 % | +3,8 % | Claude Opus 4.6: 80,9 % |
| Terminal-Bench 2.0 | 56,9 % | 68,5 % | +11,6 % | Agent-Terminal-Coding |
| LiveCodeBench Pro | — | Elo 2887 | — | Echtzeit-Programmierwettbewerbe |
Die Steigerung bei SWE-Bench Verified sieht oberflächlich betrachtet mit nur 3,8 Prozentpunkten (76,8 % → 80,6 %) gering aus, aber in diesem Punktebereich ist jedes zusätzliche Prozent extrem hart erkämpft. Mit einem Ergebnis von 80,6 % verringert Gemini 3.1 Pro den Abstand zu Claude Opus 4.6 (80,9 %) auf nur noch 0,3 % – der Sprung von der „Spitze der zweiten Riege“ zum „Gleichstand in der ersten Riege“.
Die Verbesserung beim Terminal-Bench 2.0 ist noch deutlicher: von 56,9 % auf 68,5 %, was einer Steigerung von 20,4 % entspricht. Dieser Benchmark bewertet speziell die Fähigkeit von Agenten, Coding-Aufgaben in einer Terminal-Umgebung auszuführen. Ein Plus von 11,6 Prozentpunkten bedeutet, dass die Zuverlässigkeit von 3.1 Pro in automatisierten Programmierszenarien massiv gestärkt wurde.
Unterschied 4: Agenten- und Suchfunktionen – Ein Quantensprung
| Agent-Benchmark | 3.0 Pro | 3.1 Pro | Zuwachs |
|---|---|---|---|
| BrowseComp | 59,2 % | 85,9 % | +45,1 % |
| MCP Atlas | 54,1 % | 69,2 % | +27,9 % |
Dies sind die beiden Benchmarks mit den größten Zuwächsen beim Sprung von 3.0 auf 3.1:
BrowseComp bewertet die Websuch-Fähigkeiten von Agenten – hier gab es einen Sprung von 59,2 % auf 85,9 %, eine Steigerung um 26,7 Prozentpunkte. Dies ist von großer Bedeutung für die Entwicklung von Forschungsassistenten, Wettbewerbsanalysen und Agenten zur Echtzeit-Informationsbeschaffung.
MCP Atlas misst die Fähigkeit für mehrstufige Workflows unter Verwendung des Model Context Protocol – eine Steigerung von 54,1 % auf 69,2 %. MCP ist der von Google vorangetriebene Standard für Agenten-Protokolle. Diese Verbesserung zeigt, dass die Koordinations- und Ausführungsfähigkeiten von 3.1 Pro in komplexen Agenten-Workflows deutlich optimiert wurden.
Spezialisierter Endpunkt customtools: Für 3.1 Pro wurde zudem der dedizierte Endpunkt gemini-3.1-pro-preview-customtools eingeführt. Dieser ist speziell für Szenarien optimiert, in denen Bash-Befehle und benutzerdefinierte Funktionen gemischt aufgerufen werden. Der Endpunkt priorisiert gezielt den Aufruf von Werkzeugen wie view_file oder search_code, die bei Entwicklern häufig zum Einsatz kommen. Dadurch ist er in Agenten-Szenarien wie der automatisierten Wartung oder bei KI-Programmierassistenten stabiler und zuverlässiger als der allgemeine Endpunkt.
🎯 Hinweis für Agent-Entwickler: Wenn Sie Tools wie Code-Review-Bots oder automatisierte Deployment-Agenten entwickeln, wird die Verwendung des
customtools-Endpunkts dringend empfohlen. Über APIYI (apiyi.com) kann dieser Endpunkt direkt aufgerufen werden; geben Sie dazu einfachgemini-3.1-pro-preview-customtoolsals Modellparameter an.
Unterschied 5: Ausgabekapazität und API-Funktionen
| Funktion | 3.0 Pro | 3.1 Pro | Änderung |
|---|---|---|---|
| Maximale Ausgabe-Token | Nicht spezifiziert | 65.000 | Explizit mit 65K angegeben |
| Limit für Datei-Uploads | 20 MB | 100 MB | 5-fache Steigerung |
| YouTube-URL | ❌ Nicht unterstützt | ✅ Direkte Übergabe | Neu hinzugefügt |
| customtools-Endpunkt | ❌ | ✅ | Neu hinzugefügt |
| Ausgabeeffizienz | Basiswert | +15 % | Weniger Token, bessere Ergebnisse |
65K Ausgabe-Limit: Ermöglicht die Generierung vollständiger langer Dokumente, umfangreicher Codeabschnitte oder detaillierter Analyseberichte in einem Durchgang, ohne dass mehrere Anfragen mühsam zusammengesetzt werden müssen.
100 MB Datei-Upload: Die Erweiterung von 20 MB auf 100 MB bedeutet, dass Sie nun deutlich größere Code-Repositories, PDF-Dokumentsammlungen oder Mediendateien direkt zur Analyse hochladen können.
Direkte Übergabe von YouTube-URLs: Wenn Sie einen YouTube-Link direkt in den Prompt einfügen, analysiert das Modell den Videoinhalt automatisch – ganz ohne Download, Transkodierung oder manuellen Upload.
15 % Steigerung der Ausgabeeffizienz: Praxistests des AI-Direktors von JetBrains zeigen, dass 3.1 Pro mit weniger Token zuverlässigere Ergebnisse liefert. Das bedeutet bei gleicher Aufgabe einen geringeren tatsächlichen Token-Verbrauch und somit optimierte Kosten.
Nutzen der Funktionen für verschiedene Anwender
| Funktion | Nutzen für Einzelentwickler | Nutzen für Unternehmensteams |
|---|---|---|
| 65K Ausgabe | Vollständige Codedateien in einem Schritt generieren | Batch-Erstellung von technischen Dokumenten und Berichten |
| 100 MB Upload | Gesamte Projekte zur Analyse hochladen | Audit großer Code-Repositories |
| YouTube-URL | Schnelle Analyse von Tutorial-Videos | Analyse von Produkt-Demos der Konkurrenz |
| customtools | Entwicklung von KI-Programmierassistenten | Automatisierte Ops-Agents |
| Effizienz +15 % | Senkung der individuellen Aufrufkosten | Signifikante Kostenoptimierung in großflächigen Szenarien |
💰 Kostentest: Bei identischen Aufgaben liegt der tatsächliche Output-Token-Verbrauch von 3.1 Pro im Durchschnitt 10–15 % niedriger als bei 3.0 Pro. Für Unternehmensanwendungen mit Millionen von Token pro Tag lassen sich nach dem Wechsel monatlich hunderte Dollar sparen. Über die Nutzungsstatistik-Funktion von APIYI apiyi.com lässt sich dies präzise vergleichen.
Unterschied 6: Ausgabeeffizienz – Bessere Ergebnisse mit weniger Token
Dies ist eine oft übersehene, aber in der Praxis sehr einflussreiche Verbesserung. Vladislav Tankov, AI-Direktor bei JetBrains, berichtet: 3.1 Pro bietet eine Qualitätssteigerung von 15 % bei gleichzeitig geringerem Verbrauch an Ausgabe-Token im Vergleich zu 3.0 Pro.
Was bedeutet das konkret?
Niedrigere tatsächliche Nutzungskosten: Obwohl der Preis pro Token identisch ist, verbraucht 3.1 Pro für die gleiche Aufgabe weniger Token, was die tatsächliche Rechnung senkt. Angenommen, eine Anwendung verbraucht täglich 1 Million Output-Token; eine Effizienzsteigerung von 15 % spart etwa 1,80 $ an täglichen Ausgabekosten.
Schnellere Reaktionszeit: Weniger Ausgabe-Token bedeuten eine kürzere Generierungszeit. In latenzkritischen Echtzeitanwendungen ist diese Verbesserung äußerst wertvoll.
Präzisere Ausgabequalität: 3.1 Pro „sagt“ nicht einfach weniger, sondern drückt sich präziser aus – dieselbe oder sogar mehr Information wird kompakter vermittelt, wodurch Redundanz und unnötiges „Füllmaterial“ reduziert werden.
Unterschied 7: Sicherheit und Zuverlässigkeit
| Sicherheitsdimension | 3.0 Pro | 3.1 Pro | Veränderung |
|---|---|---|---|
| Text-Sicherheit | Basiswert | +0,10 % | Leichte Verbesserung |
| Mehrsprachige Sicherheit | Basiswert | +0,11 % | Leichte Verbesserung |
| Falsche Ablehnungsrate | Basiswert | Bleibt auf niedrigem Niveau | Unverändert |
| Stabilität bei langen Aufgaben | Basiswert | Verbessert | Zuverlässiger |
Obwohl die Sicherheitsverbesserungen zahlenmäßig gering ausfallen, ist die Richtung entscheidend: Die Fähigkeiten wurden gesteigert, ohne die Sicherheit zu opfern. Die verbesserte Stabilität bei langen Aufgaben ist besonders wichtig für Agent-Anwendungen. Das bedeutet, dass 3.1 Pro in mehrstufigen Workflows seltener „vom Weg abkommt“ oder unzuverlässige Ergebnisse liefert.
Unterschied 8: Änderungen in der offiziellen Positionierung
| Dimension | 3.0 Pro Beschreibung | 3.1 Pro Beschreibung |
|---|---|---|
| Kernpositionierung | advanced intelligence | unprecedented depth and nuance |
| Reasoning-Merkmale | advanced reasoning | SOTA reasoning |
| Coding-Merkmale | agentic and vibe coding | powerful coding |
| Multimodalität | multimodal understanding | powerful multimodal understanding |
Von „advanced“ zu „unprecedented“, von „agentic and vibe coding“ zu „powerful coding“ – die Änderungen in der Wortwahl spiegeln das Upgrade der Positionierung wider. Während 3.0 Pro den Fokus auf „Fortschritt“ und „Innovation“ (vibe coding) legte, betont 3.1 Pro nun „Tiefe“ und „Leistungsstärke“.
Unterschied 9: Empfehlungen – Wann welches Modell nutzen?

Beispiel für den Migrationscode
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # Einheitliche Schnittstelle von APIYI
)
# 3.0 Pro → 3.1 Pro: Nur ein Parameter muss geändert werden
# Alte Version: model="gemini-3-pro-preview"
# Neue Version: model="gemini-3.1-pro-preview"
response = client.chat.completions.create(
model="gemini-3.1-pro-preview", # Die einzige Stelle, die geändert werden muss
messages=[{"role": "user", "content": "Analysiere die Performance-Engpässe dieses Codes"}]
)
A/B-Vergleichstest-Code anzeigen
import openai
import time
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # Einheitliche Schnittstelle von APIYI
)
test_prompt = "Gegeben sei das Array [3,1,4,1,5,9,2,6]. Verwende Merge Sort und analysiere die Zeitkomplexität."
# Test von 3.0 Pro
start = time.time()
resp_30 = client.chat.completions.create(
model="gemini-3-pro-preview",
messages=[{"role": "user", "content": test_prompt}]
)
time_30 = time.time() - start
# Test von 3.1 Pro
start = time.time()
resp_31 = client.chat.completions.create(
model="gemini-3.1-pro-preview",
messages=[{"role": "user", "content": test_prompt}]
)
time_31 = time.time() - start
print(f"3.0 Pro: {time_30:.2f}s, {resp_30.usage.total_tokens} Tokens")
print(f"3.1 Pro: {time_31:.2f}s, {resp_31.usage.total_tokens} Tokens")
print(f"\n3.0 Antwort:\n{resp_30.choices[0].message.content[:300]}...")
print(f"\n3.1 Antwort:\n{resp_31.choices[0].message.content[:300]}...")
Migrationshinweise und Best Practices
Schritt 1: Kernszenarien testen
Vergleichen Sie die Ausgaben von 3.0 und 3.1 bei Ihren 3–5 am häufigsten verwendeten Eingabeaufforderungen. Achten Sie besonders auf die Reasoning-Qualität, die Code-Genauigkeit und das Ausgabeformat.
Schritt 2: Reasoning-Stufe anpassen
Wenn Sie zuvor den High-Modus von 3.0 genutzt haben, empfehlen wir nach dem Wechsel zu 3.1 zunächst den Medium-Modus (vergleichbare Reasoning-Qualität, aber schneller). Nutzen Sie High (Deep Think Mini) nur, wenn wirklich tiefgehendes Reasoning erforderlich ist.
Schritt 3: Neue Funktionen erkunden
Probieren Sie exklusive 3.1-Funktionen wie 100-MB-Datei-Uploads, YouTube-URL-Analysen oder 65K-Langausgaben aus – Sie könnten neue Anwendungsfälle entdecken.
Schritt 4: Vollständige Umstellung
Sobald die Ergebnisse bestätigt sind, ändern Sie alle Aufrufe von gemini-3-pro-preview auf gemini-3.1-pro-preview. Es wird empfohlen, 3.0 als Fallback beizubehalten, bis 3.1 in Ihrem Szenario länger als eine Woche stabil läuft.
🚀 Schnelle Migration: Über die APIYI-Plattform (apiyi.com) erfordert die Migration von 3.0 auf 3.1 lediglich die Änderung eines Parameters. Wir empfehlen, zunächst einige Kernszenarien mittels A/B-Tests zu validieren und dann die vollständige Umstellung vorzunehmen.
Häufig gestellte Fragen (FAQ)
Q1: Sind 3.1 Pro und 3.0 Pro vollständig kompatibel? Muss ich meine Eingabeaufforderungen (Prompts) nach dem Wechsel anpassen?
Die API-Schnittstelle ist vollständig kompatibel; Sie müssen lediglich den Parameter model ändern. Da die Argumentationsweise von 3.1 Pro verbessert wurde, können sich einige fein abgestimmte Eingabeaufforderungen auf 3.1 etwas anders verhalten – in der Regel besser. Wir empfehlen jedoch Regressionstests für Kernszenarien. Über APIYI (apiyi.com) können Sie beide Versionen gleichzeitig aufrufen und direkt miteinander vergleichen.
Q2: Wird 3.0 Pro weiterhin gewartet? Wann wird es abgeschaltet?
Als Preview-Modell kündigt Google die Abschaltung normalerweise mindestens zwei Wochen im Voraus an. Derzeit ist 3.0 Pro noch verfügbar. Da 3.1 Pro jedoch in fast allen Bereichen ein direkter und besserer Ersatz ist, wird eine frühzeitige Migration empfohlen. Aufrufe über APIYI (apiyi.com) sind von Versionsanpassungen seitens Google weniger betroffen, da die Plattform das Modell-Routing automatisch für Sie übernimmt.
Q3: Verbraucht der „High“-Denkmodus von 3.1 Pro viele Token?
Der High-Modus (Deep Think Mini) verbraucht tatsächlich mehr Output-Token, da das Modell intern eine tiefere Argumentationskette durchläuft. Wir empfehlen für alltägliche Aufgaben den „Medium“-Modus (dieser entspricht qualitativ dem High-Modus von 3.0) und den „High“-Modus nur für mathematische Beweise, komplexes Debugging oder ähnliche Szenarien zu nutzen. So können Sie bei den meisten Aufgaben die Kosten stabil halten oder sogar senken.
Q4: Sind beide Versionen bei APIYI verfügbar?
Ja, beide. APIYI (apiyi.com) unterstützt sowohl gemini-3-pro-preview als auch gemini-3.1-pro-preview. Sie verwenden denselben API-Key und dieselbe base_url, was A/B-Tests und einen flexiblen Wechsel zwischen den Versionen extrem einfach macht.
Upgrade-Empfehlungen für Gemini 3.1 Pro nach Nutzertyp
Verschiedene Entwickler profitieren unterschiedlich stark vom Upgrade von 3.0 auf 3.1. Hier sind unsere gezielten Empfehlungen:
| Nutzertyp | Wichtigster Vorteil | Upgrade-Priorität | Empfohlene Aktion |
|---|---|---|---|
| AI Agent Entwickler | Agent/Suche +45 %, MCP Atlas +28 % | ⭐⭐⭐⭐⭐ | Sofort wechseln, hier ist die Steigerung am deutlichsten |
| Code-Assistenz-Tools | SWE-Bench +5 %, Terminal-Bench +20 % | ⭐⭐⭐⭐ | Wechsel empfohlen, der Medium-Modus reicht meist aus |
| Datenanalysten | Reasoning ARC-AGI-2 +148 %, 100MB Upload | ⭐⭐⭐⭐⭐ | Priorisierter Wechsel, die Analysefähigkeit großer Dateien ist massiv verbessert |
| Content-Ersteller | 65K langer Output, YouTube-URL-Analyse | ⭐⭐⭐⭐ | Wechsel empfohlen, die neuen Funktionen sind sehr praktisch |
| Leichtgewichtige API-Nutzer | Output-Effizienz +15 %, Kosten bleiben gleich | ⭐⭐⭐ | Wechseln, wenn es passt; bessere Leistung zum gleichen Preis |
| Sicherheitssensible Apps | Höhere Zuverlässigkeit, Stabilität bei langen Aufgaben | ⭐⭐⭐⭐ | Erst Regressionstests durchführen, dann wechseln |
💡 Allgemeiner Rat: Unabhängig vom Nutzertyp können Sie über APIYI (apiyi.com) beide Versionen (3.0 und 3.1) parallel vorhalten. Bestätigen Sie die Ergebnisse durch A/B-Tests, bevor Sie komplett umstellen. Null Migrationskosten, null Risiko.
Entscheidungsfluss für den Wechsel auf Gemini 3.1 Pro
Folgen Sie diesen Schritten, um über den Wechsel zu entscheiden:
- Hängt Ihre Anwendung von der Genauigkeit der Argumentation ab? → Ja → Sofort wechseln (ARC-AGI-2 Steigerung um 148 %)
- Beinhaltet Ihre Anwendung Agenten oder Suchen? → Ja → Dringend empfohlen (BrowseComp +45 %)
- Ist Ihre Eingabeaufforderung stark maßgeschneidert? → Ja → Erst im Medium-Modus testen, bei konsistentem Output wechseln
- Nutzen Sie das Modell nur für einfaches Q&A oder Übersetzungen? → Ja → Jederzeit wechseln, die Leistung ist mindestens gleichwertig bei höherer Effizienz
- Unsicher? → Lassen Sie 5 Kern-Eingabeaufforderungen als A/B-Test auf APIYI (apiyi.com) laufen – in 10 Minuten haben Sie Ihr Ergebnis.
Zusammenfassung: 9 wesentliche Unterschiede im Überblick
| # | Differenzierungsdimension | 3.0 Pro → 3.1 Pro | Wechsel-Mehrwert |
|---|---|---|---|
| 1 | Schlussfolgerungsfähigkeit (Reasoning) | ARC-AGI-2: 31,1 % → 77,1 % | Extrem hoch |
| 2 | Denksystem | Stufe 2 → Stufe 3 (inkl. Deep Think Mini) | Hoch |
| 3 | Coding-Fähigkeiten | SWE-Bench: 76,8 % → 80,6 % | Hoch |
| 4 | Agent/Suche | BrowseComp: 59,2 % → 85,9 % | Extrem hoch |
| 5 | Output/API-Features | 65K Output, 100MB Upload, YouTube URL | Hoch |
| 6 | Output-Effizienz | Bessere Ergebnisse mit weniger Token (+15 %) | Hoch |
| 7 | Sicherheit & Zuverlässigkeit | Leichte Sicherheitsverbesserung, höhere Stabilität bei langen Aufgaben | Mittel |
| 8 | Offizielle Positionierung | advanced → unprecedented depth | Signal |
| 9 | Anwendungsszenarien | Wechsel in fast allen Szenarien empfohlen | Eindeutig |
Zusammenfassung in einem Satz: Gleicher Preis, API-kompatibel und in jeder Metrik überlegen – Gemini 3.1 Pro Preview ist das kostenlose Generations-Upgrade für 3.0 Pro Preview. Es gibt keinen Grund, nicht zu wechseln.
Wir empfehlen die schnelle Migration über APIYI (apiyi.com) – es muss lediglich ein einziger Modell-Parameter angepasst werden.
Referenzen
-
Offizieller Google Blog: Gemini 3.1 Pro Release-Ankündigung
- Link:
blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-3-1-pro - Beschreibung: Offizielle Benchmark-Ergebnisse und Feature-Vorstellung
- Link:
-
Google DeepMind Model Card: Technische Details und Sicherheitsbewertung zu 3.1 Pro
- Link:
deepmind.google/models/model-cards/gemini-3-1-pro - Beschreibung: Sicherheitsdaten und detaillierte Parameter
- Link:
-
VentureBeat Ersttest: Tiefgehender Erfahrungsbericht zu den Deep Think Mini Features
- Link:
venturebeat.com/technology/google-gemini-3-1-pro-first-impressions - Beschreibung: Praxisbericht zum dreistufigen Denksystem
- Link:
-
Artificial Analysis: Vergleichsdaten 3.1 Pro vs. 3.0 Pro
- Link:
artificialanalysis.ai/models/comparisons/gemini-3-1-pro-preview-vs-gemini-3-pro - Beschreibung: Drittanbieter-Benchmark-Vergleich und Performance-Analyse
- Link:
📝 Autor: APIYI Team | Für technischen Austausch besuchen Sie APIYI (apiyi.com)
📅 Aktualisierungsdatum: 20. Februar 2026
🏷️ Schlagworte: Gemini 3.1 Pro vs. 3.0 Pro, Modellvergleich, Verdoppelte Schlussfolgerungsleistung, SWE-Bench, ARC-AGI-2, Deep Think Mini