Google just dropped a new model on AI Studio: Gemini 3.1 Pro Preview. The model ID is gemini-3.1-pro-preview, and the official description calls it "Our latest SOTA reasoning model with unprecedented depth and nuance, and powerful multimodal understanding and coding capabilities."
It's interesting that Gemini 3 Pro is still sporting the "Preview" tag without a final release, yet Google has already jumped to version 3.1—which is also still in Preview. This "version-hopping" strategy is definitely worth a closer look.
Core Value: In this post, we'll dive into the core upgrades of Gemini 3.1 Pro Preview, pricing details, how to get API access, and the logic behind Google's release strategy.
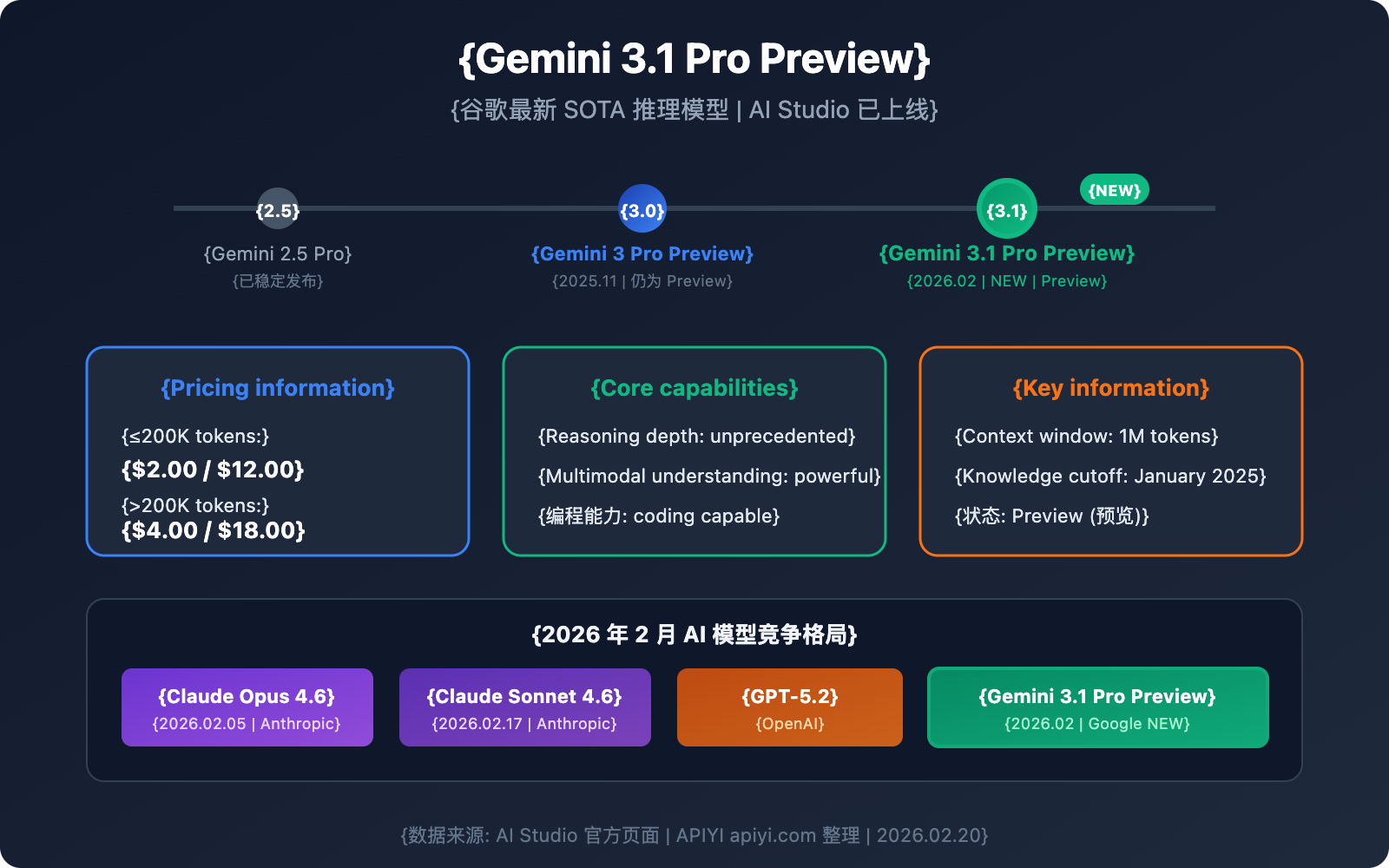
Gemini 3.1 Pro Preview: Quick Specs
Here are the official specs pulled directly from the model selection page in AI Studio:
| Parameter | Gemini 3.1 Pro Preview | Gemini 3 Pro Preview |
|---|---|---|
| Model ID | gemini-3.1-pro-preview |
gemini-3-pro-preview |
| Official Description | SOTA reasoning with unprecedented depth and nuance | Advanced intelligence with agentic and vibe coding |
| Context Window | ≤200K tokens | ≤200K tokens |
| Input Price (≤200K) | $2.00 / million tokens | $2.00 / million tokens |
| Output Price (≤200K) | $12.00 / million tokens | $12.00 / million tokens |
| Input Price (>200K) | $4.00 / million tokens | $4.00 / million tokens |
| Output Price (>200K) | $18.00 / million tokens | $18.00 / million tokens |
| Knowledge Cutoff | January 2025 | January 2025 |
| Status | Preview (New) | Preview |
As you can see from the table, the pricing for Gemini 3.1 Pro Preview is identical to version 3.0, and the knowledge cutoff remains the same. The big change is in how they describe the model's capabilities—moving from "advanced intelligence" to "unprecedented depth and nuance." This strongly suggests that reasoning depth is the star of the show for this update.
🎯 Access Tip: Gemini 3.1 Pro Preview is already live on AI Studio. Once the API officially opens up, APIYI (apiyi.com) will integrate it immediately. You'll be able to call it through a unified interface without any extra hassle.
3 Core Upgrades in Gemini 3.1 Pro Preview
Upgrade 1: Reasoning Depth Reaches New Heights (Unprecedented Depth)
The official description for Gemini 3.1 Pro Preview specifically highlights "unprecedented depth and nuance." This is the most notable textual difference compared to the 3.0 version.
What does improved reasoning depth actually mean?
In the Gemini 3 series, you can control the model's internal reasoning depth using the thinking_level parameter:
| Reasoning Level | Description | Best For |
|---|---|---|
| high (default) | Maximizes reasoning depth; may increase first-token latency. | Complex math, logical reasoning, strategic planning. |
| medium | Balances reasoning quality with response speed. | General technical Q&A, code reviews. |
| low | Fast responses with reduced deep reasoning. | Simple tasks, real-time conversations. |
Gemini 3.0 Pro Preview already achieved leading results on GPQA Diamond (graduate-level scientific reasoning) and MathArena Apex (math competitions). By emphasizing "unprecedented," the 3.1 version suggests even further breakthroughs in these high-difficulty reasoning tasks.
Upgrade 2: Enhanced Multimodal Understanding
The "powerful multimodal understanding" mentioned in the official description continues the core strength of Gemini 3 Pro—a 1M token context window that supports understanding text, audio, images, video, PDFs, and entire codebases.
Here's how Gemini 3 Pro performed on multimodal benchmarks:
| Benchmark | Score | Description |
|---|---|---|
| MMMU-Pro | 81% | Multimodal multi-discipline understanding. |
| Video-MMMU | 87.6% | Video understanding capabilities. |
| LMArena | Leading | Overall evaluation rankings. |
Version 3.1 optimizes this further, particularly regarding "nuance"—it's better at picking up subtle creative cues or breaking down overlapping layers in complex problems.
Upgrade 3: Continuously Strengthened Coding Capabilities
The "powerful coding capabilities" in the official description show that coding remains a primary focus. While Gemini 3.0 Pro Preview emphasized "agentic and vibe coding capabilities," the 3.1 description's use of "coding capabilities" suggests that its performance is at least maintained at that high level, if not improved.
Reference Gemini 3 Pro's performance in the coding field:
- SWE-bench Verified: 76.8% (just behind Claude Opus 4.6 at 80.9%).
- Over a 50% increase in the number of benchmark tasks solved compared to Gemini 2.5 Pro.

Why Gemini 3.1 Pro Preview Skipped the Official Version
This is the most intriguing question of this article: Gemini 3 Pro still hasn't seen an official release, so why did Google jump straight to 3.1?
Reason 1: External Competitive Pressure Forcing Rapid Iteration
February 2026 has been one of the most competitive months in the Large Language Model space:
| Time | Event | Impact |
|---|---|---|
| 2026.02.05 | Anthropic releases Claude Opus 4.6 | Coding SWE-bench 80.9%, surpassing Gemini 3 Pro |
| 2026.02.17 | Anthropic releases Claude Sonnet 4.6 | Mid-range model with incredible cost-performance, OSWorld 72.5% |
| 2026.02 | OpenAI GPT-5.2 continuous updates | All-around competitive pressure |
| 2026.02 | Google releases Gemini 3.1 Pro Preview | Rapid iteration to counter the competition |
Claude Opus 4.6 hit 80.9% on SWE-bench Verified, while Gemini 3 Pro sat at 76.8%—a gap of about 4 percentage points. Claude Sonnet 4.6, as a mid-range model, also reached 79.6%, nearly catching up to Gemini 3 Pro. In this landscape, Google needed to push out an improved version fast to stay in the game.
Reason 2: Business Considerations of the Preview Strategy
Google's choice to keep the model in a "Preview" state rather than releasing an official version likely stems from the following:
Lowering commitment risk: Preview models are governed by "Pre-GA Offerings Terms," meaning Google doesn't have to provide the same level of SLA guarantees as an official release. This allows Google to iterate faster without being tied down by the stability commitments required for a General Availability (GA) product.
Accelerating iteration pace: An official release implies long-term stability testing and compatibility verification. Staying in Preview allows Google to ship improved versions much faster—the jump from 3.0 to 3.1 might have only taken a few months.
Gathering user feedback: The Preview phase lets Google collect massive amounts of real-world feedback from developers, which is then used to fine-tune the eventual official release.
Reason 3: Evolution of Google's Naming Strategy
From a naming perspective, "3.1" follows Google's established iteration pattern for the Gemini series:
- Gemini 1.0 → 1.5 → 2.0 → 2.5 → 3.0 → 3.1
- Minor version updates (like .1) usually signify performance tuning, bug fixes, and specific capability enhancements rather than major architectural shifts.
This contrasts with Anthropic's naming strategy—Claude jumped from 3.5 straight to 4.5 and then 4.6, representing larger version number changes but with different release frequencies.
💡 Industry Observation: In 2026, AI model competition has entered the "Preview is the product" phase. Google, Anthropic, and OpenAI are all accelerating their iteration cycles; Preview/Beta status has become the norm rather than the exception. Through APIYI (apiyi.com), you can experience the latest models from every provider immediately, without needing to register and configure each one separately.
Gemini 3.1 Pro Preview API Integration Guide
Current Status
As of this writing, Gemini 3.1 Pro Preview is live on the AI Studio web interface, but the API might not be fully rolled out to everyone yet. The following code is applicable for when the API is officially open.
Minimal Call Example
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # APIYI unified interface, available as soon as Gemini API goes live
)
response = client.chat.completions.create(
model="gemini-3.1-pro-preview",
messages=[
{"role": "user", "content": "Analyze the time complexity of the following code and provide optimization suggestions"}
],
temperature=0.7
)
print(response.choices[0].message.content)
View Full Example (Including Reasoning Depth Control)
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # APIYI unified interface
)
# High reasoning depth call - suitable for complex reasoning tasks
response = client.chat.completions.create(
model="gemini-3.1-pro-preview",
messages=[
{
"role": "system",
"content": "You are a senior algorithm expert. Please analyze problems using rigorous mathematical reasoning."
},
{
"role": "user",
"content": """
Given an array of n integers, find all triplets that satisfy the following conditions:
1. The sum of the three elements equals the target value.
2. The indices of the three elements are distinct.
3. Return all unique triplets.
Please analyze the time and space complexity of the optimal solution and provide a full implementation.
"""
}
],
temperature=0.3,
max_tokens=4096
)
print(response.choices[0].message.content)
print(f"\nToken Usage: {response.usage}")
🚀 Quick Start: Once the API is officially open, you can call Gemini 3.1 Pro Preview directly through the APIYI (apiyi.com) platform. There's no need to apply for a Google API Key, and it supports OpenAI-compatible formats, allowing you to switch existing projects with zero code changes.
Gemini 3.1 Pro Preview Best Practices
Choosing Reasoning Depth Based on the Task
Gemini 3.1 Pro Preview allows you to control reasoning depth via parameters. Choosing the right level helps you find the perfect balance between quality and cost:
| Task Type | Recommended Reasoning Level | Expected Latency | Typical Scenarios |
|---|---|---|---|
| Mathematical Proofs, Logical Reasoning | high | 15-30s | Algorithm competitions, formal verification |
| Code Review, Architecture Design | high | 10-20s | Complex system design, performance optimization |
| Technical Documentation Generation | medium | 5-10s | API docs, tech blogs |
| Data Extraction, Format Conversion | low | 2-5s | Structured data processing, translation |
| Multi-turn Dialogue | medium | 3-8s | Customer service assistants, tutoring |
Making the Most of the 1M Token Context Window
The 1M token context window in Gemini 3.1 Pro Preview is a unique advantage over the Claude and GPT series. It's particularly effective in these scenarios:
Repository-level Code Analysis: You can feed an entire project's code into the model at once, allowing it to understand the global architecture before providing code reviews or refactoring suggestions. This is far more effective at spotting cross-module issues than file-by-file analysis.
Long Document Understanding: When dealing with ultra-long documents like legal contracts, academic paper collections, or technical specifications, the 1M token window ensures no information is lost.
Comprehensive Multimodal Analysis: You can input text descriptions, architecture diagrams, video demos, and code simultaneously, letting the model understand the problem from multiple dimensions.
Resolution Control for Multimodal Inputs
Use the media_resolution parameter to control the precision of visual processing:
# High-precision visual analysis - suitable for scenarios requiring high detail
response = client.chat.completions.create(
model="gemini-3.1-pro-preview",
messages=[{
"role": "user",
"content": [
{"type": "text", "text": "Analyze all components and data flows in this architecture diagram"},
{"type": "image_url", "image_url": {"url": "data:image/png;base64,..."}}
]
}],
extra_body={"media_resolution": "high"} # low/medium/high
)
🎯 Optimization Tip: For scenarios where you only need a rough identification of image content, using
lowresolution can significantly reduce token consumption and latency. These parameters are also supported when calling via the unified interface of APIYI (apiyi.com).
Gemini 3.1 Pro Preview vs. Competitor Models

Recommended Scenarios for Each Model
| Scenario | Recommended Model | Reason |
|---|---|---|
| Complex Reasoning + Long Context | Gemini 3.1 Pro Preview | 1M token window + unprecedented depth |
| Code Generation & Agents | Claude Opus 4.6 | Highest SWE-bench score: 80.9% |
| High Value-for-Money Coding | Claude Sonnet 4.6 | 79.6% coding capability, priced at only $3/$15 |
| Multimodal Understanding | Gemini 3.1 Pro Preview | MMMU-Pro 81%, leading in video understanding |
| General Dialogue | GPT-5.2 | Balanced overall capabilities, mature ecosystem |
| Budget-sensitive Projects | Gemini 3.1 Pro Preview | $2/$12 lowest price tier |
💰 Cost Comparison: The input price for Gemini 3.1 Pro Preview ($2.00/M tokens) is only 13% of Claude Opus 4.6 ($15.00/M tokens), making it the most cost-effective choice among current flagship models. You can quickly compare the performance of various models using the unified interface on the APIYI (apiyi.com) platform.
FAQ
Q1: When will the Gemini 3.1 Pro Preview API be available for calls?
Currently, Gemini 3.1 Pro Preview is live on the AI Studio web interface, but the official API release date hasn't been confirmed yet. Based on Google's past release patterns, the API usually opens up within a few days to a few weeks after the AI Studio launch. APIYI (apiyi.com) will integrate it as soon as the API officially opens, allowing you to call it directly through a unified interface.
Q2: What’s the difference between Gemini 3.1 Pro Preview and 3.0? Is it worth switching?
According to official descriptions, version 3.1 offers improvements in reasoning depth and nuance, while maintaining its strong multimodal understanding and coding capabilities. Since the price is exactly the same, there's no reason not to switch once the API is available—it's essentially a free upgrade. We recommend performing A/B testing through the APIYI (apiyi.com) unified interface to verify if 3.1 actually performs better in your specific scenarios.
Q3: Why hasn’t Google released a stable version of Gemini 3 Pro?
The most likely reason is a combination of competitive pressure and iteration strategy. Keeping it in "Preview" status allows Google to quickly roll out improved versions (like 3.1) without having to commit to the stability guarantees of a final release. Meanwhile, competitive pressure from Claude Opus 4.6 and GPT-5.2 requires Google to accelerate its iterations, and Preview mode is the best way to achieve that speed.
Q4: Should I choose Gemini 3.1 Pro Preview or Claude Opus 4.6?
It depends on your core needs: if you need an ultra-long context (1M tokens) and multimodal understanding, go with Gemini 3.1 Pro; if you need top-tier coding capabilities and Agent support, choose Claude Opus 4.6. If you're budget-sensitive, Gemini 3.1 Pro's $2/$12 pricing is significantly lower than Claude Opus 4.6's $15/$75. You can call both through the same interface on the APIYI (apiyi.com) platform for quick comparison.
Gemini 3 Series Model Selection Guide
The Gemini 3 series now has several available models. Choosing the right version can significantly impact both cost and performance:
| Model | Positioning | Best Use Case | Price Tier |
|---|---|---|---|
| gemini-3.1-pro-preview | Flagship Reasoning | Complex reasoning, multimodal analysis, long context | $2/$12 |
| gemini-3-pro-preview | Flagship General | Agentic programming, code generation | $2/$12 |
| gemini-3-flash-preview | High-speed Lightweight | Real-time apps, high-frequency calls, batch processing | Lower |
| gemini-3-pro-image-preview | Image Generation | Text-to-image, image editing | Per image |
Selection Advice:
- If you're already using
gemini-3-pro-previewand are happy with the results, you can seamlessly switch togemini-3.1-pro-previewfor better capabilities at the same price. - If your requirements for response speed are higher than for reasoning depth,
gemini-3-flash-previewis the better choice. - For image generation needs, use the specialized
gemini-3-pro-image-preview(note that this model has recently experienced 503 overload issues).
💡 Pro Tip: Not sure which model to use? You can use the APIYI (apiyi.com) platform to quickly test all Gemini 3 series models with a single API Key, allowing you to compare performance and latency before making a decision.
Summary: 3 Key Signals from the Gemini 3.1 Pro Preview Release
-
Google is picking up the pace: Skipping the official release to push 3.1 directly shows that "Preview" has become Google's standard release strategy. It's a clear response to the constant pressure from Anthropic and OpenAI.
-
Reasoning depth is the next battlefield: The official description has shifted from "advanced intelligence" to "unprecedented depth and nuance." Deep reasoning is becoming the core competitive edge for top-tier models.
-
The price war is far from over: With pricing at $2.00/$12.00, it's incredibly competitive for a flagship model. Google is clearly using price to win over developers.
Once the API is officially out, I recommend trying Gemini 3.1 Pro Preview via APIYI (apiyi.com). It offers a unified interface, zero configuration, and lets you quickly run side-by-side tests with models like Claude Opus 4.6.
References
-
Google AI Studio Model Selection Page: Gemini 3.1 Pro Preview official specs
- Link:
aistudio.google.com/prompts/new_chat - Description: Try the model directly online.
- Link:
-
Google DeepMind – Gemini 3 Pro: Technical documentation
- Link:
deepmind.google/models/gemini/pro - Description: Benchmark results and technical details.
- Link:
-
Gemini API Official Documentation: Model list and calling methods
- Link:
ai.google.dev/gemini-api/docs/models - Description: API parameters and usage guides.
- Link:
-
MacObserver Report: Gemini 3.1 Pro Preview discovery report
- Link:
macobserver.com/news/gemini-3-1-pro-preview-spotted - Description: Third-party discovery and analysis.
- Link:
📝 Author: APIYI Team | For technical discussions, visit APIYI (apiyi.com)
📅 Updated: February 20, 2026
🏷️ Keywords: Gemini 3.1 Pro Preview, Google AI Model, API Access, Claude Opus 4.6 Comparison, AI Reasoning Model