Les prix de Gemini 3.1 Pro Preview et Gemini 3.0 Pro Preview sont exactement les mêmes — Input 2,00 $, Output 12,00 $ / million de tokens. La question se pose alors : en quoi la version 3.1 est-elle réellement meilleure que la 3.0 ? Cela vaut-il le coup de changer ?
La réponse est : Absolument, et il n'y a aucune raison de ne pas le faire.
Cet article compare point par point les différences entre les deux versions à l'aide de données de référence réelles. Petit spoiler sur la conclusion : le score de raisonnement ARC-AGI-2 de Gemini 3.1 Pro est passé de 31,1 % à 77,1 %, soit une multiplication par 2,5 ; le codage SWE-Bench est passé de 76,8 % à 80,6 % ; et la recherche BrowseComp a bondi de 59,2 % à 85,9 %. Ce n'est pas un simple ajustement, c'est une mise à niveau générationnelle.
Valeur ajoutée : En lisant cet article, vous comprendrez clairement chaque amélioration spécifique de la version 3.1 Pro par rapport à la 3.0 Pro, et comment choisir selon vos différents cas d'usage.
Tableau comparatif des paramètres : Gemini 3.1 Pro vs 3.0 Pro
Commençons par examiner les différences au niveau des paramètres techniques :
| Dimension de comparaison | Gemini 3.0 Pro Preview | Gemini 3.1 Pro Preview | Changement |
|---|---|---|---|
| ID du modèle | gemini-3-pro-preview |
gemini-3.1-pro-preview |
Nouvelle version |
| Date de sortie | 18 novembre 2025 | 19 février 2026 | +3 mois |
| Prix Input (≤200K) | 2,00 $ / M tokens | 2,00 $ / M tokens | Inchangé |
| Prix Output (≤200K) | 12,00 $ / M tokens | 12,00 $ / M tokens | Inchangé |
| Prix Input (>200K) | 4,00 $ / M tokens | 4,00 $ / M tokens | Inchangé |
| Prix Output (>200K) | 18,00 $ / M tokens | 18,00 $ / M tokens | Inchangé |
| Fenêtre de contexte | 1M tokens | 1M tokens | Inchangé |
| Sortie maximale | — | 65K tokens | Amélioration nette |
| Limite de fichiers | 20 Mo | 100 Mo | x 5 |
| Support URL YouTube | ❌ | ✅ | Nouveau |
| Niveaux de réflexion | 2 niveaux (low/high) | 3 niveaux (low/medium/high) | Nouveau : medium |
| Endpoint customtools | ❌ | ✅ | Nouveau |
| Date de coupure | Janvier 2025 | Janvier 2025 | Inchangé |
Le prix, la fenêtre de contexte et la date de coupure des connaissances restent identiques. Tous les changements sont des améliorations pures de capacités.
🎯 Conclusion clé : Le prix ne bouge pas d'un centime, mais les fonctionnalités augmentent. D'un point de vue technique, la version 3.1 Pro remplace avantageusement la 3.0 Pro. En passant par APIYI (apiyi.com), il vous suffit de changer le paramètre
modeldegemini-3-pro-previewàgemini-3.1-pro-previewpour effectuer la mise à niveau.
Différence 1 : Capacité de raisonnement — de « Excellent » à « Sommet »
C'est l'amélioration la plus importante du passage de la version 3.0 à la 3.1, et c'est aussi le point sur lequel Google insiste le plus.
| Benchmark de raisonnement | 3.0 Pro | 3.1 Pro | Amélioration | Description |
|---|---|---|---|---|
| ARC-AGI-2 | 31,1% | 77,1% | +148% | Raisonnement sur de nouveaux schémas logiques |
| GPQA Diamond | — | 94,3% | — | Raisonnement scientifique de niveau master/doctorat |
| MMMLU | — | 92,6% | — | Compréhension multidisciplinaire et multimodale |
| LiveCodeBench Pro | — | Elo 2887 | — | Compétition de programmation en temps réel |
La progression sur ARC-AGI-2 est tout simplement stupéfiante : passer de 31,1 % à 77,1 %, ce n'est pas juste un doublement, c'est un score multiplié par 2,5. Ce benchmark évalue la capacité du modèle à résoudre des schémas logiques totalement inédits, c'est-à-dire des types de problèmes de raisonnement que le modèle n'a jamais rencontrés auparavant. Avec 77,1 %, il dépasse même les 68,8 % de Claude Opus 4.6, affirmant ainsi sa position de leader en termes de raisonnement.
La raison technique derrière cela : Google décrit officiellement la version 3.1 Pro comme possédant une « profondeur et une nuance sans précédent » (unprecedented depth and nuance), alors que la 3.0 Pro était qualifiée d'« intelligence avancée » (advanced intelligence). Ce n'est pas seulement un changement de terminologie marketing ; les données d'ARC-AGI-2 prouvent qu'il y a bien un saut qualitatif dans la profondeur du raisonnement.
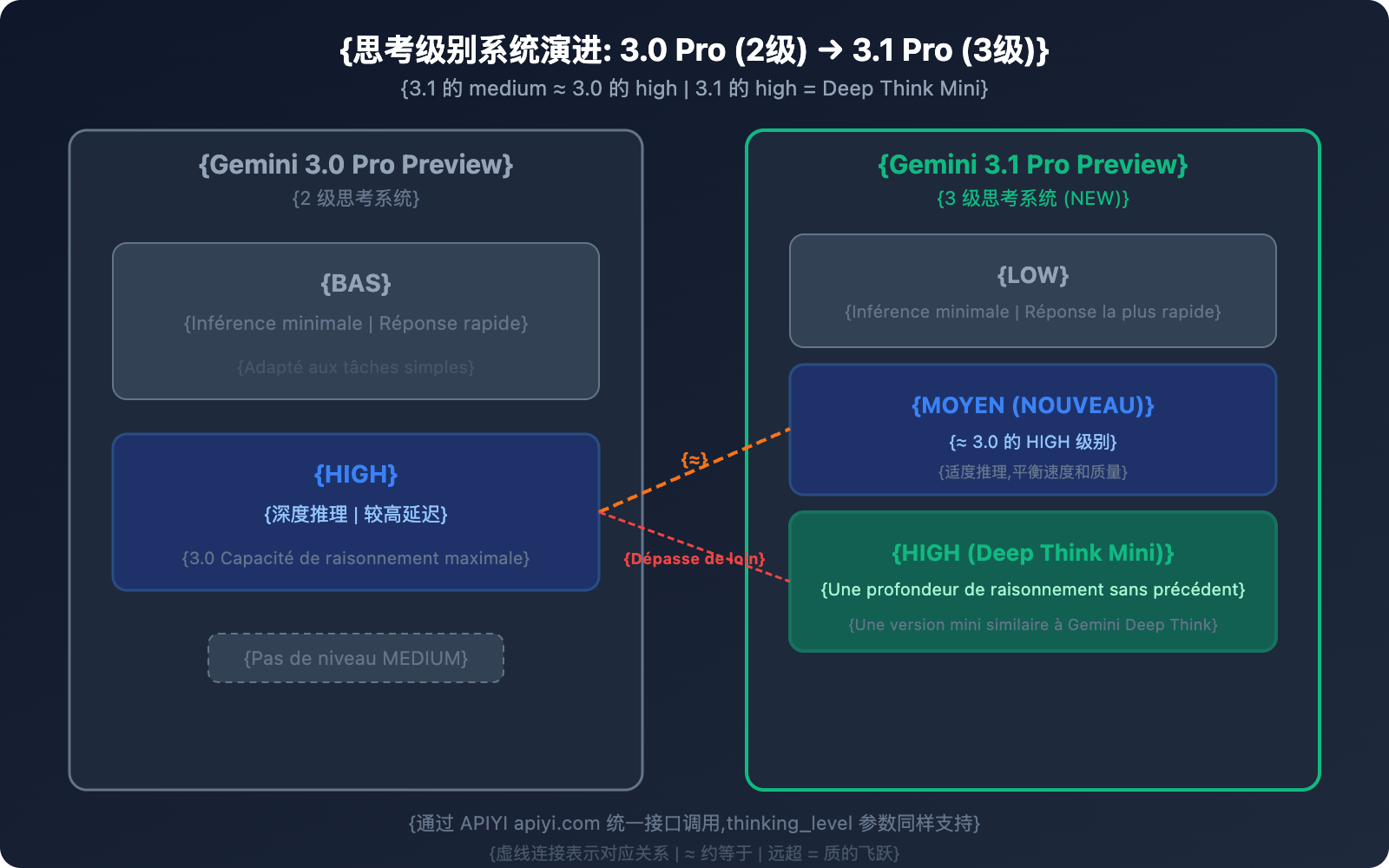
Différence 2 : Système de niveaux de réflexion — de 2 à 3 niveaux
C'est l'une des améliorations les plus concrètes pour l'utilisation quotidienne de la version 3.1 Pro.
Système de réflexion de la 3.0 Pro (2 niveaux)
| Niveau | Comportement |
|---|---|
| low | Raisonnement minimal, réponse rapide |
| high | Raisonnement approfondi, latence plus élevée |
Système de réflexion de la 3.1 Pro (3 niveaux)
| Niveau | Comportement | Correspondance |
|---|---|---|
| low | Raisonnement minimal, réponse rapide | Similaire au "low" de la 3.0 |
| medium (Nouveau) | Raisonnement modéré, équilibre vitesse/qualité | ≈ "high" de la 3.0 |
| high | Mode Deep Think Mini, raisonnement le plus profond | Bien supérieur au "high" de la 3.0 |
L'information clé à retenir : le niveau "medium" de la 3.1 Pro ≈ le niveau "high" de la 3.0 Pro. Cela signifie que :
- Avec le mode "medium" de la 3.1, vous obtenez la même qualité de raisonnement que le niveau le plus élevé de la 3.0.
- Le mode "high" de la 3.1 est d'un tout nouveau calibre — une sorte de version mini de Gemini Deep Think.
- Pour une qualité de raisonnement identique (medium), la latence est plus faible que sur le mode "high" de la 3.0.
💡 Conseil pratique : Si vous utilisiez systématiquement le mode "high" de la 3.0 Pro, nous vous recommandons de passer d'abord au mode "medium" avec la 3.1 Pro. Vous obtiendrez une qualité de raisonnement équivalente, mais avec moins de latence. Ne passez au mode "high" (Deep Think Mini) que pour des tâches de raisonnement réellement complexes. Cela vous permettra d'améliorer votre expérience globale sans augmenter vos coûts. La plateforme APIYI (apiyi.com) permet de configurer facilement le paramètre
thinking_level.
Différence 3 : Capacités de codage — Une place dans le peloton de tête
| Benchmark de codage | 3.0 Pro | 3.1 Pro | Amélioration | Comparaison sectorielle |
|---|---|---|---|---|
| SWE-Bench Verified | 76,8% | 80,6% | +3,8% | Claude Opus 4.6 : 80,9% |
| Terminal-Bench 2.0 | 56,9% | 68,5% | +11,6% | Codage terminal via Agent |
| LiveCodeBench Pro | — | Elo 2887 | — | Compétition de programmation en temps réel |
L'amélioration sur SWE-Bench Verified semble modeste à première vue (76,8% → 80,6%), mais gagner chaque point de pourcentage à ce niveau de performance est extrêmement difficile. Avec un score de 80,6%, Gemini 3.1 Pro réduit l'écart avec Claude Opus 4.6 (80,9%) à seulement 0,3% — on passe d'un statut de « leader du second peloton » à celui de « rival direct de l'élite ».
Le bond sur Terminal-Bench 2.0 est encore plus impressionnant : 56,9% → 68,5%, soit une hausse de 20,4 %. Ce benchmark évalue spécifiquement la capacité d'un Agent à exécuter des tâches de codage dans un environnement terminal. Cette progression de 11,6 points signifie que la fiabilité de 3.1 Pro dans les scénarios de programmation automatisée est considérablement renforcée.
Différence 4 : Capacités d'Agent et de recherche — Un bond en avant spectaculaire
| Benchmark d'Agent | 3.0 Pro | 3.1 Pro | Ampleur de l'amélioration |
|---|---|---|---|
| BrowseComp | 59,2% | 85,9% | +45,1% |
| MCP Atlas | 54,1% | 69,2% | +27,9% |
Ce sont les deux benchmarks où la progression entre la version 3.0 et la 3.1 est la plus flagrante :
BrowseComp évalue les capacités de recherche web des Agents. Passer de 59,2% à 85,9% (soit un gain de 26,7 points) est majeur pour la création d'assistants de recherche, d'outils d'analyse concurrentielle ou d'Agents de récupération d'informations en temps réel.
MCP Atlas mesure la capacité à gérer des flux de travail multi-étapes via le Model Context Protocol. Le passage de 54,1% à 69,2% montre que 3.1 Pro est bien plus efficace pour coordonner et exécuter des workflows complexes. Le MCP est d'ailleurs le standard de protocole pour Agents promu par Google.
Point de terminaison dédié customtools : La version 3.1 Pro introduit également le point de terminaison gemini-3.1-pro-preview-customtools, optimisé pour les appels mixtes entre commandes bash et fonctions personnalisées. Ce endpoint privilégie les outils fréquemment utilisés par les développeurs comme view_file ou search_code, offrant une stabilité et une fiabilité accrues par rapport au endpoint générique pour les scénarios d'Agents comme la maintenance automatisée ou les assistants de programmation IA.
🎯 Note pour les développeurs d'Agents : Si vous construisez des bots de revue de code ou des agents de déploiement automatisé, je vous recommande vivement d'utiliser le endpoint customtools. Vous pouvez y accéder directement via APIYI (apiyi.com) en renseignant
gemini-3.1-pro-preview-customtoolsdans le paramètremodel.
Différence 5 : Capacités de sortie et fonctionnalités API
| Caractéristique | 3.0 Pro | 3.1 Pro | Changement |
|---|---|---|---|
| Tokens de sortie max | Non spécifié | 65 000 | Spécifié à 65K |
| Limite d'upload de fichiers | 20 Mo | 100 Mo | Augmentation de 5x |
| URL YouTube | ❌ Non supporté | ✅ Passage direct | Nouveau |
| Point de terminaison customtools | ❌ | ✅ | Nouveau |
| Efficacité de sortie | Référence | +15 % | Moins de tokens, meilleurs résultats |
Limite de sortie de 65K : Vous pouvez désormais générer d'un seul coup des documents longs, de grands blocs de code ou des rapports d'analyse détaillés, sans avoir à multiplier les requêtes et à recoller les morceaux.
Upload de fichiers de 100 Mo : Passer de 20 Mo à 100 Mo signifie que vous pouvez directement uploader des dépôts de code plus volumineux, des ensembles de documents PDF ou des fichiers multimédias pour analyse.
Passage direct d'URL YouTube : Insérez directement un lien YouTube dans votre invite, et le modèle analysera automatiquement le contenu de la vidéo — plus besoin de télécharger, de transcoder ou d'uploader manuellement.
Gain d'efficacité de 15 % : Selon les tests réels du directeur de l'IA chez JetBrains, la version 3.1 Pro produit des résultats plus fiables avec moins de tokens. Cela signifie que pour une tâche identique, la consommation réelle de tokens est plus faible, optimisant ainsi les coûts.
Valeur de chaque fonctionnalité selon le profil utilisateur
| Caractéristique | Valeur pour les développeurs indépendants | Valeur pour les équipes en entreprise |
|---|---|---|
| Sortie 65K | Générer des fichiers de code complets en une fois | Génération en masse de docs techniques et rapports |
| Upload 100 Mo | Analyser un projet complet | Audit de grands dépôts de code |
| URL YouTube | Analyser rapidement des tutoriels vidéo | Analyse de démos de produits concurrents |
| customtools | Développement d'assistants de programmation IA | Agents d'automatisation pour l'exploitation (Ops) |
| Efficacité +15 % | Réduction des coûts d'appel personnels | Optimisation significative des coûts à grande échelle |
💰 Test de coût réel : Sur une même tâche, la consommation réelle de tokens de sortie de la 3.1 Pro est en moyenne 10 à 15 % inférieure à celle de la 3.0 Pro. Pour une application d'entreprise consommant un million de tokens par jour, le passage à la nouvelle version peut faire économiser des centaines de dollars par mois. Vous pouvez comparer précisément ces chiffres via les statistiques d'utilisation sur APIYI (apiyi.com).
Différence 6 : Efficacité de sortie — de meilleurs résultats avec moins de tokens
C'est une amélioration souvent négligée, mais qui a un impact réel majeur. Vladislav Tankov, directeur de l'IA chez JetBrains, a partagé ses retours : la version 3.1 Pro offre une amélioration de la qualité de 15 % tout en consommant moins de tokens de sortie par rapport à la 3.0 Pro.
Qu'est-ce que cela signifie concrètement ?
Un coût d'utilisation réel plus bas : Même si le prix unitaire est le même, la 3.1 Pro consomme moins de tokens pour accomplir la même tâche, ce qui réduit la facture finale. Pour une application consommant 1 million de tokens de sortie par jour, un gain d'efficacité de 15 % représente une économie quotidienne d'environ 1,80 $.
Une vitesse de réponse accrue : Moins de tokens à générer signifie un temps de génération plus court. Pour les applications en temps réel sensibles à la latence, cette amélioration est précieuse.
Une qualité de sortie plus concise : La 3.1 Pro ne se contente pas de « parler moins », elle « parle plus juste ». Elle utilise des formulations plus compactes pour transmettre la même quantité d'informations (voire plus), réduisant ainsi la redondance et le superflu.
Différence 7 : Sécurité et fiabilité
| Dimension de sécurité | 3.0 Pro | 3.1 Pro | Évolution |
|---|---|---|---|
| Sécurité textuelle | Référence | +0,10 % | Légère amélioration |
| Sécurité multilingue | Référence | +0,11 % | Légère amélioration |
| Taux de faux refus | Référence | Maintien à un niveau bas | Inchangé |
| Stabilité sur les tâches longues | Référence | Amélioration | Plus fiable |
L'amélioration de la sécurité, bien que numériquement faible, va dans la bonne direction : les capacités augmentent sans sacrifier la sécurité. L'amélioration de la stabilité sur les tâches longues est particulièrement cruciale pour les applications d'Agents. Cela signifie que dans des workflows multi-étapes, le 3.1 Pro est moins susceptible de « dériver » ou de générer des sorties peu fiables.
Différence 8 : Évolution de la description officielle du positionnement
| Dimension | Description 3.0 Pro | Description 3.1 Pro |
|---|---|---|
| Positionnement central | advanced intelligence | unprecedented depth and nuance |
| Raisonnement | advanced reasoning | SOTA reasoning |
| Codage | agentic and vibe coding | powerful coding |
| Multimodalité | multimodal understanding | powerful multimodal understanding |
De « advanced » à « unprecedented », de « agentic and vibe coding » à « powerful coding » — ce changement de terminologie reflète une montée en gamme du positionnement. Le 3.0 Pro mettait l'accent sur le côté « avancé » et « innovant » (vibe coding), tandis que le 3.1 Pro insiste sur la « profondeur » et la « puissance ».
Différence 9 : Conseils d'utilisation — Lequel choisir et quand ?

Exemple de code de migration
import openai
client = openai.OpenAI(
api_key="VOTRE_CLÉ_API",
base_url="https://api.apiyi.com/v1" # Interface unifiée APIYI
)
# 3.0 Pro → 3.1 Pro : un seul paramètre à changer
# Ancienne version : model="gemini-3-pro-preview"
# Nouvelle version : model="gemini-3.1-pro-preview"
response = client.chat.completions.create(
model="gemini-3.1-pro-preview", # Le seul endroit à modifier
messages=[{"role": "user", "content": "Analyser les goulots d'étranglement de performance de ce code"}]
)
Voir le code du test comparatif A/B
import openai
import time
client = openai.OpenAI(
api_key="VOTRE_CLÉ_API",
base_url="https://api.apiyi.com/v1" # Interface unifiée APIYI
)
test_prompt = "Étant donné le tableau [3,1,4,1,5,9,2,6], utiliser le tri fusion et analyser la complexité temporelle"
# Test 3.0 Pro
start = time.time()
resp_30 = client.chat.completions.create(
model="gemini-3-pro-preview",
messages=[{"role": "user", "content": test_prompt}]
)
time_30 = time.time() - start
# Test 3.1 Pro
start = time.time()
resp_31 = client.chat.completions.create(
model="gemini-3.1-pro-preview",
messages=[{"role": "user", "content": test_prompt}]
)
time_31 = time.time() - start
print(f"3.0 Pro: {time_30:.2f}s, {resp_30.usage.total_tokens} tokens")
print(f"3.1 Pro: {time_31:.2f}s, {resp_31.usage.total_tokens} tokens")
print(f"\nRéponse 3.0 :\n{resp_30.choices[0].message.content[:300]}...")
print(f"\nRéponse 3.1 :\n{resp_31.choices[0].message.content[:300]}...")
Notes de migration et meilleures pratiques
Étape 1 : Tester les scénarios clés
Comparez les sorties de la 3.0 et de la 3.1 sur vos 3 à 5 invites les plus utilisées. Concentrez-vous sur la qualité du raisonnement, la précision du code et le format de sortie.
Étape 2 : Ajuster le niveau de réflexion
Si vous utilisiez auparavant le mode "high" de la 3.0, il est conseillé de passer d'abord au mode "medium" avec la 3.1 (qualité de raisonnement équivalente mais plus rapide). N'utilisez le mode "high" (Deep Think Mini) que lorsque vous avez réellement besoin d'un raisonnement approfondi.
Étape 3 : Explorer les nouvelles capacités
Essayez les fonctionnalités exclusives à la 3.1, comme l'importation de fichiers de 100 Mo, l'analyse d'URL YouTube ou les sorties longues de 65k tokens, pour découvrir de nouveaux cas d'usage.
Étape 4 : Basculement complet
Une fois les résultats confirmés, remplacez tous vos appels de gemini-3-pro-preview par gemini-3.1-pro-preview. Il est recommandé de conserver la 3.0 comme solution de secours (fallback) jusqu'à ce que la 3.1 fonctionne de manière stable dans votre environnement pendant au moins une semaine.
🚀 Migration rapide : Via la plateforme APIYI (apiyi.com), la migration de la 3.0 vers la 3.1 ne nécessite qu'un changement de paramètre. Nous vous suggérons de lancer quelques tests A/B sur vos scénarios principaux pour confirmer les résultats avant de basculer totalement.
Questions Fréquemment Posées
Q1 : 3.1 Pro et 3.0 Pro sont-ils totalement compatibles ? Faut-il modifier les invites après le passage ?
L'interface API est totalement compatible, il suffit de modifier le paramètre model. Cependant, comme le mode de raisonnement de 3.1 Pro a été amélioré, certaines invites (prompts) finement ajustées peuvent se comporter légèrement différemment sur la 3.1 — généralement en mieux, mais il est conseillé d'effectuer des tests de non-régression sur les scénarios critiques. Via APIYI apiyi.com, vous pouvez appeler les deux versions simultanément pour comparer les résultats.
Q2 : Est-ce que la version 3.0 Pro continuera d’être maintenue ? Quand sera-t-elle retirée ?
En tant que modèle Preview, Google donne généralement un préavis d'au moins 2 semaines avant le retrait. Actuellement, la 3.0 Pro reste disponible, mais comme la 3.1 Pro est une amélioration supérieure dans toutes les dimensions, il est recommandé de migrer dès que possible. Les appels via APIYI apiyi.com ne sont pas affectés par les ajustements de version côté Google, car la plateforme gère automatiquement le routage des modèles.
Q3 : La consommation de tokens du mode de réflexion « high » de la 3.1 Pro est-elle élevée ?
Le mode "high" (Deep Think Mini) consomme effectivement plus de tokens de sortie car le modèle effectue une chaîne de raisonnement interne plus profonde. Il est conseillé d'utiliser le mode "medium" (équivalent à la qualité "high" de la 3.0) pour les tâches quotidiennes, et de réserver le mode "high" pour le raisonnement mathématique ou le débogage complexe. Cela permet de maintenir, voire de réduire les coûts sur la plupart des tâches.
Q4 : Ces deux versions sont-elles disponibles sur APIYI ?
Oui, les deux. APIYI apiyi.com prend en charge simultanément gemini-3-pro-preview et gemini-3.1-pro-preview. Ils utilisent la même clé API et la même base_url, ce qui facilite les tests comparatifs A/B et le basculement flexible.
Suggestions de mise à niveau vers Gemini 3.1 Pro selon votre profil
Le bénéfice du passage de la version 3.0 à la 3.1 varie selon le type de développeur. Voici nos recommandations ciblées :
| Type d'utilisateur | Différence la plus bénéfique | Priorité de mise à niveau | Action recommandée |
|---|---|---|---|
| Développeurs d'Agents IA | Agent/Recherche +45%, MCP Atlas +28% | ⭐⭐⭐⭐⭐ | Basculer immédiatement, l'amélioration est flagrante |
| Outils d'assistance au code | SWE-Bench +5%, Terminal-Bench +20% | ⭐⭐⭐⭐ | Passage recommandé, le mode medium suffit |
| Analystes de données | Raisonnement ARC-AGI-2 +148%, upload de 100 Mo | ⭐⭐⭐⭐⭐ | Passage prioritaire, les capacités d'analyse de gros fichiers sont décuplées |
| Créateurs de contenu | Sortie longue de 65K, analyse d'URL YouTube | ⭐⭐⭐⭐ | Passage recommandé, les nouvelles fonctionnalités sont très utiles |
| Utilisateurs API légers | Efficacité de sortie +15%, coût identique | ⭐⭐⭐ | Basculer dès que possible, meilleur rapport qualité/prix |
| Applications sensibles à la sécurité | Fiabilité accrue, stabilité sur les tâches longues | ⭐⭐⭐⭐ | Faire des tests de non-régression avant de basculer |
💡 Conseil général : Quel que soit votre profil, vous pouvez utiliser APIYI apiyi.com pour conserver les deux versions 3.0 et 3.1 en parallèle. Validez les résultats avec un test A/B avant de basculer totalement. Coût de migration nul, risque zéro.
Processus de décision pour le passage à Gemini 3.1 Pro
Suivez ces étapes pour décider de votre migration :
- Votre application dépend-elle de la précision du raisonnement ? → Oui → Basculez immédiatement (gain de 148% sur ARC-AGI-2).
- Votre application implique-t-elle des Agents ou de la recherche ? → Oui → Fortement recommandé (BrowseComp +45%).
- Vos invites sont-elles hautement personnalisées ? → Oui → Testez d'abord avec le mode medium, puis basculez après avoir confirmé la cohérence des sorties.
- Vous faites uniquement du Q&A simple ou de la traduction ? → Oui → Basculez à tout moment, les performances sont au moins équivalentes et plus efficaces.
- Un doute ? → Lancez un test A/B sur 5 invites clés via APIYI apiyi.com, vous aurez une conclusion en 10 minutes.
Résumé : Synthèse des 9 différences clés
| # | Dimension de différence | 3.0 Pro → 3.1 Pro | Valeur de la migration |
|---|---|---|---|
| 1 | Capacités de raisonnement | ARC-AGI-2 : 31,1 % → 77,1 % | Très élevée |
| 2 | Système de réflexion | Niveau 2 → Niveau 3 (incluant Deep Think Mini) | Élevée |
| 3 | Capacités de codage | SWE-Bench : 76,8 % → 80,6 % | Élevée |
| 4 | Agents / Recherche | BrowseComp : 59,2 % → 85,9 % | Très élevée |
| 5 | Sortie / Fonctionnalités API | Sortie 65K, upload 100 Mo, URL YouTube | Élevée |
| 6 | Efficacité de sortie | Meilleurs résultats avec moins de tokens (+15 %) | Élevée |
| 7 | Sécurité et fiabilité | Légère amélioration de la sécurité, meilleure stabilité sur les tâches longues | Moyenne |
| 8 | Positionnement officiel | advanced → unprecedented depth | Signal |
| 9 | Cas d'utilisation | Migration recommandée pour presque tous les cas | Clair |
En résumé : Même prix, compatibilité API totale et des performances supérieures sur tous les plans — Gemini 3.1 Pro Preview est une mise à jour gratuite et incontournable par rapport à la version 3.0 Pro Preview. Il n'y a aucune raison de ne pas franchir le pas.
Nous vous recommandons de migrer rapidement via APIYI (apiyi.com) : il suffit de modifier un seul paramètre model pour en profiter.
Références
-
Blog officiel de Google : Annonce de la sortie de Gemini 3.1 Pro
- Lien :
blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-3-1-pro - Description : Scores de référence officiels et présentation des fonctionnalités.
- Lien :
-
Fiche modèle (Model Card) Google DeepMind : Détails techniques et évaluation de la sécurité de 3.1 Pro
- Lien :
deepmind.google/models/model-cards/gemini-3-1-pro - Description : Données de sécurité et paramètres détaillés.
- Lien :
-
Premier test par VentureBeat : Immersion dans les fonctionnalités de Deep Think Mini
- Lien :
venturebeat.com/technology/google-gemini-3-1-pro-first-impressions - Description : Rapport d'expérience réelle sur le système de réflexion de niveau 3.
- Lien :
-
Artificial Analysis : Comparaison des données entre 3.1 Pro et 3.0 Pro
- Lien :
artificialanalysis.ai/models/comparisons/gemini-3-1-pro-preview-vs-gemini-3-pro - Description : Comparaisons de benchmarks tiers et analyse de performance.
- Lien :
📝 Auteur : L'équipe APIYI | Pour les échanges techniques, rendez-vous sur APIYI (apiyi.com)
📅 Dernière mise à jour : 20 février 2026
🏷️ Mots-clés : Gemini 3.1 Pro vs 3.0 Pro, comparaison de modèles, raisonnement doublé, SWE-Bench, ARC-AGI-2, Deep Think Mini