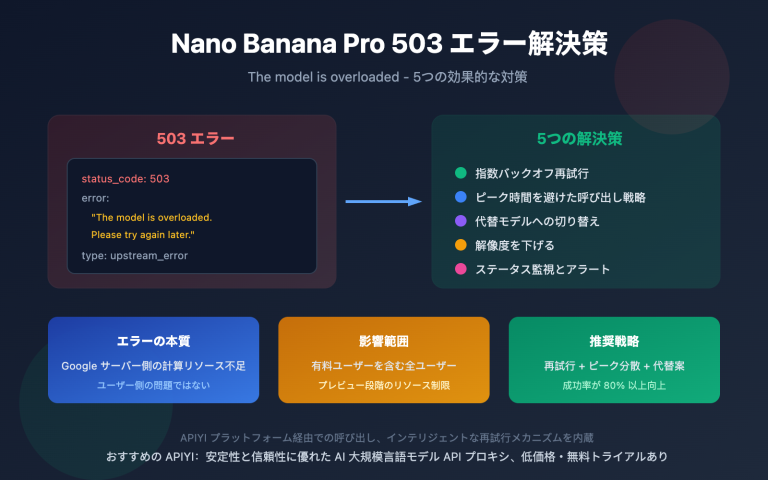
Gemini 3.1 Pro Preview 和 Gemini 3.0 Pro Preview 价格完全一样——Input $2.00、Output $12.00 / 百万 tokens。那问题来了: 3.1 到底比 3.0 强在哪? 值不值得切换?
答案是: 非常值得,而且没有任何不切换的理由。
本文将用真实基准数据逐项对比两个版本的差异。剧透一下结论——3.1 Pro 的 ARC-AGI-2 推理得分从 31.1% 飙升到 77.1%,翻了 2.5 倍; SWE-Bench 编码从 76.8% 提升到 80.6%; BrowseComp 搜索从 59.2% 跳到 85.9%。这不是微调,这是换代级升级。
核心价值: 读完本文,你将清楚了解 3.1 Pro 相对于 3.0 Pro 的每一项具体改进,以及在不同场景下该如何选择。

Gemini 3.1 Pro 与 3.0 Pro 参数对比总表
先看硬参数层面的差异:
| 对比维度 | Gemini 3.0 Pro Preview | Gemini 3.1 Pro Preview | 变化 |
|---|---|---|---|
| 模型 ID | gemini-3-pro-preview |
gemini-3.1-pro-preview |
新版本 |
| 发布日期 | 2025 年 11 月 18 日 | 2026 年 2 月 19 日 | +3 个月 |
| Input 价格 (≤200K) | $2.00 / M tokens | $2.00 / M tokens | 不变 |
| Output 价格 (≤200K) | $12.00 / M tokens | $12.00 / M tokens | 不变 |
| Input 价格 (>200K) | $4.00 / M tokens | $4.00 / M tokens | 不变 |
| Output 价格 (>200K) | $18.00 / M tokens | $18.00 / M tokens | 不变 |
| 上下文窗口 | 1M tokens | 1M tokens | 不变 |
| 最大输出 | — | 65K tokens | 明确提升 |
| 文件上传上限 | 20MB | 100MB | 5 倍 |
| YouTube URL 支持 | ❌ | ✅ | 新增 |
| 思考级别 | 2 级 (low/high) | 3 级 (low/medium/high) | 新增 medium |
| customtools 端点 | ❌ | ✅ | 新增 |
| 知识截止日期 | 2025 年 1 月 | 2025 年 1 月 | 不变 |
价格、上下文窗口、知识截止完全不变。所有变化都是纯粹的能力提升。
🎯 核心结论: 价格一分不多,功能只多不少。从参数层面看,3.1 Pro 是 3.0 Pro 的严格上位替代。通过 APIYI apiyi.com 调用,只需把 model 参数从
gemini-3-pro-preview改为gemini-3.1-pro-preview即可完成升级。
違い 1: 推理能力——「優秀」から「トップクラス」へ
これは 3.0 → 3.1 における最大の改善点であり、Googleが公式に最も強調しているアップグレードポイントです。
| 推理ベンチマーク | 3.0 Pro | 3.1 Pro | 向上率 | 説明 |
|---|---|---|---|---|
| ARC-AGI-2 | 31.1% | 77.1% | +148% | 全く新しい論理パターンの推理 |
| GPQA Diamond | — | 94.3% | — | 大学院レベルの科学的推理 |
| MMMLU | — | 92.6% | — | 多分野・マルチモーダル理解 |
| LiveCodeBench Pro | — | Elo 2887 | — | リアルタイム・コーディング・コンテスト |
ARC-AGI-2 の向上は最も驚異的です。31.1% から 77.1% へと、2倍どころか 2.5倍 に跳ね上がっています。このベンチマークは、モデルが全く新しい論理パターンを解決する能力、つまりモデルがこれまでに見たことのない推理問題を評価するものです。77.1% というスコアは Claude Opus 4.6 の 68.8% をも上回り、推理の次元において圧倒的なリードを確立しました。
技術的な背景: Google公式は 3.1 Pro を「unprecedented depth and nuance(前例のない深みと繊細さ)」を備えていると表現していますが、3.0 Pro の説明は「advanced intelligence(高度なインテリジェンス)」でした。これは単なるマーケティング用語の変化ではなく、ARC-AGI-2 のデータが推理の深さに質的な飛躍があったことを証明しています。
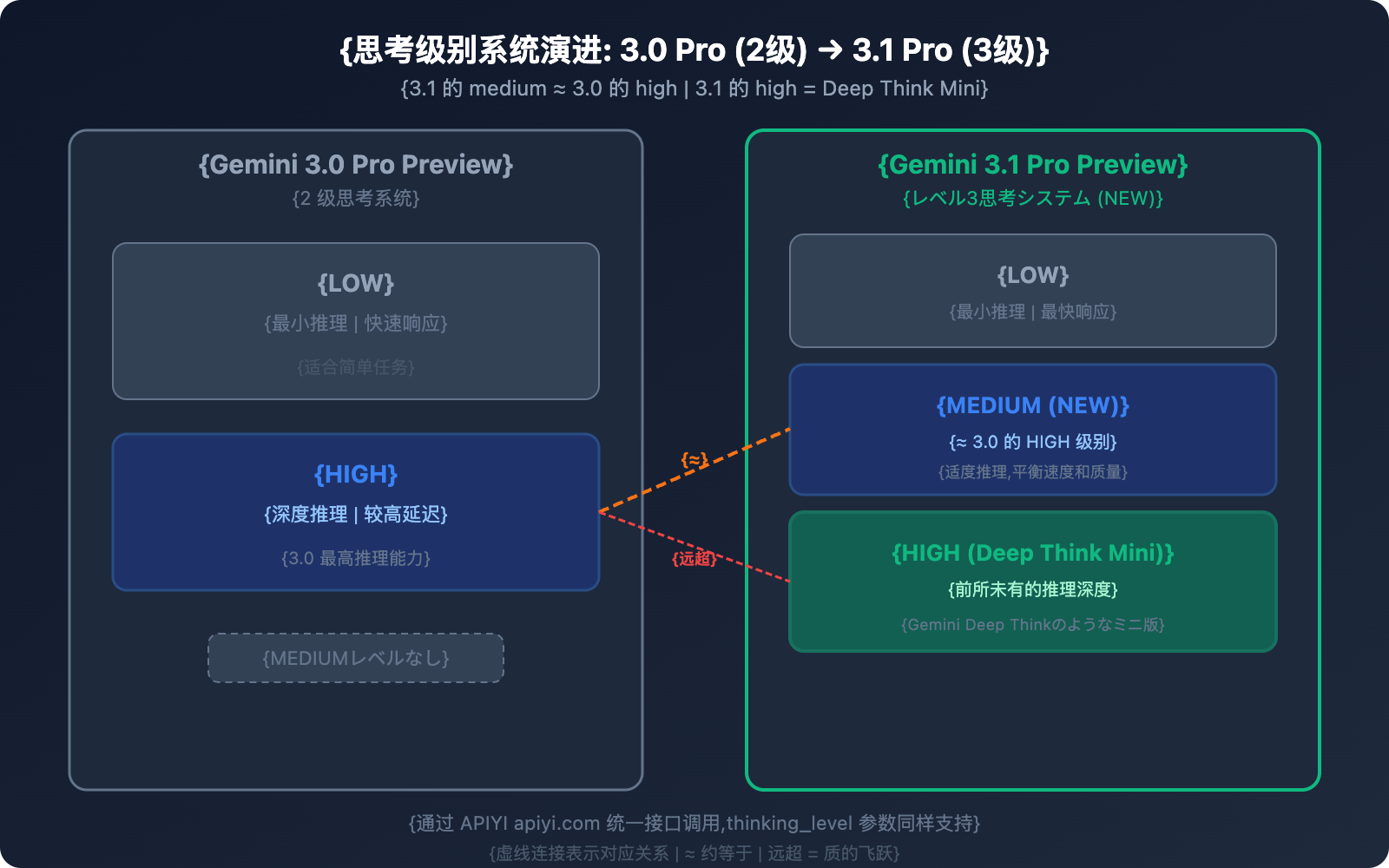
違い 2: 思考レベルシステム——2段階から3段階へ
これは 3.1 Pro において、実用面で最も意義のある改善の一つです。
3.0 Pro の思考システム (2段階)
| レベル | 挙動 |
|---|---|
| low | 最小限の推理、高速レスポンス |
| high | 深い推理、高レイテンシ |
3.1 Pro の思考システム (3段階)
| レベル | 挙動 | 対応関係 |
|---|---|---|
| low | 最小限の推理、高速レスポンス | 3.0 の low に相当 |
| medium (新規) | 適度な推理、速度と品質のバランス | ≈ 3.0 の high |
| high | Deep Think Mini モード、究極の推理 | 3.0 の high を遥かに凌駕 |
重要なポイント: 3.1 Pro の medium ≈ 3.0 Pro の high です。つまり:
- 3.1 の medium を使うだけで、3.0 の最高レベルの推理品質が得られる
- 3.1 の high は全く新しい次元——Gemini Deep Think のミニ版のようなもの
- 同じ推理品質(medium)であれば、3.0 の high よりもレイテンシが低い
💡 実践的なアドバイス: これまで 3.0 Pro の high モードを常用していた方は、3.1 Pro に切り替えた後はまず medium を試すことをお勧めします。推理品質は同等でありながら、レイテンシを抑えることができます。真に複雑な推理タスクに直面した時のみ high (Deep Think Mini) に切り替えることで、コストを抑えつつより優れた全体的な体験を得ることができます。APIYI (apiyi.com) プラットフォームは、
thinking_levelパラメータの受け渡しに対応しています。
違い 3:コーディング能力 —— 第一線級への仲間入り
| コーディング・ベンチマーク | 3.0 Pro | 3.1 Pro | 向上率 | 業界比較 |
|---|---|---|---|---|
| SWE-Bench Verified | 76.8% | 80.6% | +3.8% | Claude Opus 4.6: 80.9% |
| Terminal-Bench 2.0 | 56.9% | 68.5% | +11.6% | エージェント端末コーディング |
| LiveCodeBench Pro | — | Elo 2887 | — | リアルタイム・プログラミング・コンテスト |
SWE-Bench Verified の向上は、一見するとわずか 3.8 ポイント(76.8% → 80.6%)に見えますが、このスコア帯において 1% スコアを伸ばすことは極めて困難です。80.6% という成績により、Gemini 3.1 Pro と Claude Opus 4.6(80.9%)の差はわずか 0.3% にまで縮まりました。これは「第2グループのリーダー」から「トップティアと肩を並べる存在」へと進化したことを意味します。
Terminal-Bench 2.0 の向上はさらに顕著です。56.9% から 68.5% へと 20.4%(相対比)向上しました。このベンチマークは、エージェントがターミナル環境でコーディングタスクを実行する能力を専門に評価するもので、11.6 ポイントの向上は、3.1 Pro が自動プログラミング・シナリオにおいて信頼性を大幅に強化したことを示しています。
違い 4:エージェントおよび検索能力 —— 飛躍的な進化
| エージェント・ベンチマーク | 3.0 Pro | 3.1 Pro | 向上幅 |
|---|---|---|---|
| BrowseComp | 59.2% | 85.9% | +45.1% |
| MCP Atlas | 54.1% | 69.2% | +27.9% |
これら2つの項目は、3.0 から 3.1 へのアップデートで最も向上幅が大きかったベンチマークです。
BrowseComp は、エージェントの Web 検索能力を評価します。59.2% から 85.9% へと 26.7 ポイントも急上昇しました。これは、リサーチ・アシスタント、競合分析、リアルタイム情報検索などのエージェントを構築する上で、非常に大きな意味を持ちます。
MCP Atlas は、Model Context Protocol(MCP)を使用したマルチステップ・ワークフローの能力を測定します。54.1% から 69.2% に向上しました。MCP は Google が推進するエージェント・プロトコルの標準規格であり、この向上は 3.1 Pro が複雑なエージェント・ワークフローにおける調整・実行能力を著しく強化したことを裏付けています。
customtools 専用エンドポイント: 3.1 Pro では、新たに gemini-3.1-pro-preview-customtools 専用エンドポイントが追加されました。これは bash コマンドとカスタム関数の混合呼び出しシナリオに特化して最適化されています。このエンドポイントは、view_file や search_code といった開発者が頻繁に使用するツールの呼び出し優先度を特別に調整しており、自動化された運用保守(DevOps)や AI プログラミング・アシスタントなどのエージェント・シナリオにおいて、汎用エンドポイントよりも安定した信頼性を提供します。
🎯 エージェント開発者へのアドバイス: コードレビュー・ボットや自動デプロイ・エージェントなどのツールを構築している場合は、customtools エンドポイントの使用を強くお勧めします。APIYI(apiyi.com)を通じてこのエンドポイントを直接呼び出すことができ、model パラメータに
gemini-3.1-pro-preview-customtoolsを指定するだけで利用可能です。
差異 5: 出力能力と API 特性
| 特徴 | 3.0 Pro | 3.1 Pro | 変化 |
|---|---|---|---|
| 最大出力トークン数 | 未明示 | 65,000 | 65K と明記 |
| ファイルアップロード上限 | 20MB | 100MB | 5倍に向上 |
| YouTube URL | ❌ 非対応 | ✅ 直接入力可能 | 新規追加 |
| customtools エンドポイント | ❌ | ✅ | 新規追加 |
| 出力効率 | 基準 | +15% | より少ないトークンでより良い結果を |
65K 出力上限: 長大なドキュメント、大規模なコード、または詳細な分析レポートを一度に生成できます。複数回のリクエストに分けて繋ぎ合わせる必要はありません。
100MB ファイルアップロード: 20MB から 100MB に拡張されたことで、より大規模なコードリポジトリ、PDF ドキュメントセット、またはメディアファイルを直接アップロードして分析できるようになりました。
YouTube URL の直接入力: プロンプトに YouTube のリンクを直接入力するだけで、モデルが自動的に動画の内容を解析・分析します。ダウンロード、エンコード、アップロードの手間は一切不要です。
15% の出力効率向上: JetBrains の AI ディレクターによる実測フィードバックによると、3.1 Pro はより少ないトークンでより信頼性の高い結果を出力します。これは、同じタスクにおいて実際のトークン消費量が抑えられ、コストパフォーマンスが向上することを意味します。
各機能がユーザーにもたらす価値
| 特徴 | 個人開発者にとっての価値 | 企業チームにとっての価値 |
|---|---|---|
| 65K 出力 | 完全なコードファイルを一度に生成 | 技術ドキュメントやレポートの一括生成 |
| 100MB アップロード | プロジェクト全体をアップロードして分析 | 大規模なコードベースの監査 |
| YouTube URL | チュートリアル動画の迅速な分析 | 競合製品のデモ分析 |
| customtools | AI プログラミングアシスタントの開発 | 自動化運用エージェント |
| 効率 +15% | 個人の利用コストを削減 | 大規模な利用シーンで顕著なコスト最適化 |
💰 コストの実測: 同じタスクにおいて、3.1 Pro の実際の出力トークン消費量は 3.0 Pro よりも平均で 10〜15% 低くなっています。1 日あたり百万トークン規模を利用する企業アプリケーションの場合、切り替えるだけで毎月数百ドルを節約できる計算になります。APIYI (apiyi.com) の利用統計機能を使えば、この差を正確に比較できます。
差異 6: 出力効率 —— より少ないトークンでより良い結果を
これは見落とされがちですが、実際には非常に大きな改善点です。JetBrains の AI ディレクター、Vladislav Tankov 氏の実測フィードバックによると、3.1 Pro は 3.0 Pro と比較して品質が 15% 向上していると同時に、消費する出力トークンが少なくなっています。
これが何を意味するのでしょうか?
実際の利用コストの低下: 単価が同じであっても、3.1 Pro は同じタスクをより少ないトークンで完了できるため、実際の請求額は安くなります。例えば、1 日あたり 100 万出力トークンを消費するアプリの場合、15% の効率向上は毎日約 1.80 ドルの節約につながります。
応答速度の向上: 出力トークンが少ないということは、生成時間が短くなることを意味します。遅延に敏感なリアルタイム・アプリケーションにおいて、この向上は非常に価値があります。
より洗練された出力品質: 3.1 Pro は単に「口数が少なくなった」わけではなく、「より的確になった」のです。冗長な表現を削ぎ落とし、よりコンパクトな表現で同等、あるいはそれ以上の情報を伝えることができます。
違い 7: 安全性と信頼性
| 安全性の次元 | 3.0 Pro | 3.1 Pro | 変化 |
|---|---|---|---|
| テキストの安全性 | 基準 | +0.10% | わずかに向上 |
| 多言語での安全性 | 基準 | +0.11% | わずかに向上 |
| 誤拒否率 | 基準 | 低水準を維持 | 変化なし |
| 長期タスクの安定性 | 基準 | 向上 | より信頼性が高い |
安全性の向上は数値としてはわずかですが、方向性は正しいと言えます。能力を向上させつつ、安全性を犠牲にしていません。長期タスクの安定性向上は、Agent(エージェント)活用において特に重要です。これは、マルチステップのワークフローにおいて、3.1 Pro が「脱線」したり、信頼性の低い出力を生成したりしにくくなったことを意味します。
違い 8: 公式ポジショニングの説明の変化
| 次元 | 3.0 Pro の説明 | 3.1 Pro の説明 |
|---|---|---|
| コア・ポジショニング | advanced intelligence | unprecedented depth and nuance |
| 推論の特徴 | advanced reasoning | SOTA reasoning |
| コーディングの特徴 | agentic and vibe coding | powerful coding |
| マルチモーダル | multimodal understanding | powerful multimodal understanding |
「advanced」から「unprecedented」へ、「agentic and vibe coding」から「powerful coding」へ。表現の変化は、ポジショニングのアップグレードを反映しています。3.0 Pro が「高度さ」や「革新性(vibe coding)」を強調していたのに対し、3.1 Pro は「深み」や「強力さ」を強調しています。
差异 9: 使用建议——什么时候该用哪个

迁移代码示例
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # APIYI统一接口
)
# 3.0 Pro → 3.1 Pro 只改一个参数
# 旧版: model="gemini-3-pro-preview"
# 新版: model="gemini-3.1-pro-preview"
response = client.chat.completions.create(
model="gemini-3.1-pro-preview", # 唯一需要修改的地方
messages=[{"role": "user", "content": "分析这段代码的性能瓶颈"}]
)
查看 A/B 对比测试代码
import openai
import time
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # APIYI统一接口
)
test_prompt = "给定数组 [3,1,4,1,5,9,2,6], 使用归并排序并分析时间复杂度"
# 测试 3.0 Pro
start = time.time()
resp_30 = client.chat.completions.create(
model="gemini-3-pro-preview",
messages=[{"role": "user", "content": test_prompt}]
)
time_30 = time.time() - start
# 测试 3.1 Pro
start = time.time()
resp_31 = client.chat.completions.create(
model="gemini-3.1-pro-preview",
messages=[{"role": "user", "content": test_prompt}]
)
time_31 = time.time() - start
print(f"3.0 Pro: {time_30:.2f}s, {resp_30.usage.total_tokens} tokens")
print(f"3.1 Pro: {time_31:.2f}s, {resp_31.usage.total_tokens} tokens")
print(f"\n3.0 回答:\n{resp_30.choices[0].message.content[:300]}...")
print(f"\n3.1 回答:\n{resp_31.choices[0].message.content[:300]}...")
迁移注意事项和最佳实践
第一步: 测试核心场景
在你最常用的 3-5 个 prompt 上对比 3.0 和 3.1 的输出。重点关注推理质量、代码准确性和输出格式。
第二步: 调整思考级别
如果之前用 3.0 的 high 模式,切换到 3.1 后建议先用 medium (推理质量相当但更快)。只在真正需要深度推理时使用 high (Deep Think Mini)。
第三步: 探索新能力
尝试 100MB 文件上传、YouTube URL 分析、65K 长输出等 3.1 独有功能,可能会发现新的应用场景。
第四步: 全量切换
确认效果后,将所有调用从 gemini-3-pro-preview 改为 gemini-3.1-pro-preview。建议保留 3.0 作为 fallback,直到 3.1 在你的场景中稳定运行一周以上。
🚀 快速迁移: 通过 APIYI apiyi.com 平台,3.0 → 3.1 的迁移只需改一个参数。建议先用 A/B 测试跑几个核心场景确认效果,然后全量切换。
常见问题
Q1: 3.1 Pro 和 3.0 Pro 完全兼容吗? 切换后需要改 prompt 吗?
API 接口完全兼容,只需修改 model 参数。但由于 3.1 Pro 的推理方式有所改进,某些经过精心调教的 prompt 在 3.1 上的表现可能略有不同——通常是更好,但建议在核心场景上做回归测试。通过 APIYI apiyi.com 可以同时调用两个版本进行对比。
Q2: 3.0 Pro 还会继续维护吗? 什么时候会下线?
作为 Preview 模型,谷歌通常会提前至少 2 周通知下线。目前 3.0 Pro 仍然可用,但考虑到 3.1 Pro 在所有维度上都是严格上位替代,建议尽早迁移。通过 APIYI apiyi.com 调用不受谷歌侧版本调整影响,平台会自动处理模型路由。
Q3: 3.1 Pro 的 high 思考模式 token 消耗大吗?
high 模式 (Deep Think Mini) 确实会消耗更多输出 token,因为模型在内部进行了更深的推理链条。建议日常任务使用 medium (等价于 3.0 的 high 质量),只在数学推理、复杂调试等场景使用 high。这样可以在大多数任务上保持甚至降低成本。
Q4: 这两个版本在 APIYI 都可以用吗?
都可以。APIYI apiyi.com 同时支持 gemini-3-pro-preview 和 gemini-3.1-pro-preview,使用同一个 API Key 和 base_url,方便进行 A/B 对比测试和灵活切换。
ユーザー別 Gemini 3.1 Pro へのアップグレード推奨事項
開発者のタイプによって、3.0から3.1へのアップグレードで得られるメリットは異なります。以下にターゲット別の推奨事項をまとめました。
| ユーザータイプ | 最も恩恵を受ける差異 | アップグレード優先度 | 推奨アクション |
|---|---|---|---|
| AIエージェント開発者 | エージェント/検索 +45%、MCP Atlas +28% | ⭐⭐⭐⭐⭐ | 即座に切り替え推奨。効果の向上が最も顕著です。 |
| コード補助ツール | SWE-Bench +5%、Terminal-Bench +20% | ⭐⭐⭐⭐ | 切り替えを推奨。mediumモードの使用で十分です。 |
| データアナリスト | 推論 ARC-AGI-2 +148%、100MBアップロード | ⭐⭐⭐⭐⭐ | 優先的に切り替え。大容量ファイルの分析能力が大幅に強化されています。 |
| コンテンツクリエイター | 65Kの長文出力、YouTube URL分析 | ⭐⭐⭐⭐ | 切り替えを推奨。新機能が非常に実用的です。 |
| 軽量APIユーザー | 出力効率 +15%、コスト据え置き | ⭐⭐⭐ | 都合の良いタイミングで切り替え。同価格でより高性能です。 |
| セキュリティ重視アプリ | 安全性と信頼性の向上、長期タスクの安定性 | ⭐⭐⭐⭐ | 回帰テストを行ってから切り替えを検討してください。 |
💡 共通のアドバイス: どのユーザータイプであっても、APIYI (apiyi.com) を通じて 3.0 と 3.1 の両方のバージョンを保持し、A/Bテストで効果を確認してから完全に移行することをお勧めします。移行コストはゼロ、リスクもゼロです。
Gemini 3.1 Pro バージョン切り替えの意思決定フロー
以下のステップに従って、切り替えを判断してください。
- アプリケーションが推論の正確性に依存しているか? → はい → 即座に切り替え(ARC-AGI-2 が 148% 向上)
- アプリケーションにエージェントや検索機能が含まれるか? → はい → 強く推奨(BrowseComp が 45% 向上)
- プロンプトが高度にカスタマイズされているか? → はい → まずは medium モードでテストし、出力の一貫性を確認した後に切り替え
- 単純なQ&Aや翻訳のみを行っているか? → はい → いつでも切り替え可能。効果は同等以上で、効率が向上します
- 迷っている? → APIYI (apiyi.com) で5つの主要なプロンプトのA/Bテストを実行してください。10分で結論が出ます
まとめ:9つの差異の要約
| # | 比較項目 | 3.0 Pro → 3.1 Pro | 切り替えの価値 |
|---|---|---|---|
| 1 | 推論能力 | ARC-AGI-2: 31.1% → 77.1% | 極めて高い |
| 2 | 思考システム | レベル2 → レベル3 (Deep Think Miniを含む) | 高い |
| 3 | コーディング能力 | SWE-Bench: 76.8% → 80.6% | 高い |
| 4 | エージェント/検索 | BrowseComp: 59.2% → 85.9% | 極めて高い |
| 5 | 出力/API特性 | 65K出力、100MBアップロード、YouTube URL対応 | 高い |
| 6 | 出力効率 | より少ないトークンでより良い結果 (+15%) | 高い |
| 7 | 安全性と信頼性 | 安全性の微増、長期タスクの安定性向上 | 中程度 |
| 8 | 公式の位置付け | advanced → unprecedented depth | シグナル |
| 9 | 適用シーン | ほぼすべてのシーンで切り替えるべき | 明確 |
一言でまとめると: 価格は同じ、APIの互換性もあり、すべての指標で強化されています。Gemini 3.1 Pro Preview は 3.0 Pro Preview からの無料の次世代アップグレードであり、切り替えない理由はどこにもありません。
APIYI (apiyi.com) を利用すれば、model パラメータを1つ変更するだけで、素早く移行を完了できます。
参考文献
-
Google 公式ブログ: Gemini 3.1 Pro リリースのお知らせ
- リンク:
blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-3-1-pro - 説明: 公式ベンチマーク結果と機能紹介
- リンク:
-
Google DeepMind モデルカード: 3.1 Pro の技術的詳細と安全性評価
- リンク:
deepmind.google/models/model-cards/gemini-3-1-pro - 説明: 安全性データと詳細なパラメータ
- リンク:
-
VentureBeat 初回レビュー: Deep Think Mini 特性の詳細体験レポート
- リンク:
venturebeat.com/technology/google-gemini-3-1-pro-first-impressions - 説明: 3段階思考システムの実際の体験レポート
- リンク:
-
Artificial Analysis: 3.1 Pro vs 3.0 Pro 比較データ
- リンク:
artificialanalysis.ai/models/comparisons/gemini-3-1-pro-preview-vs-gemini-3-pro - 説明: サードパーティによるベンチマーク比較と性能分析
- リンク:
📝 著者: APIYI Team | 技術的な交流については APIYI(apiyi.com)をご覧ください
📅 更新日: 2026年2月20日
🏷️ キーワード: Gemini 3.1 Pro vs 3.0 Pro, モデル比較, 推論性能の倍増, SWE-Bench, ARC-AGI-2, Deep Think Mini