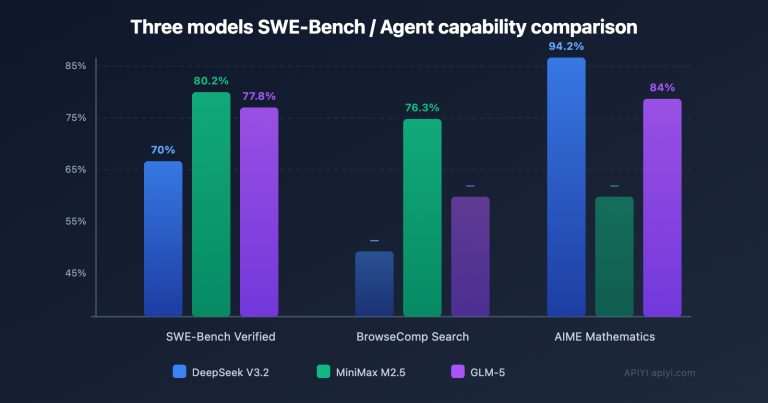
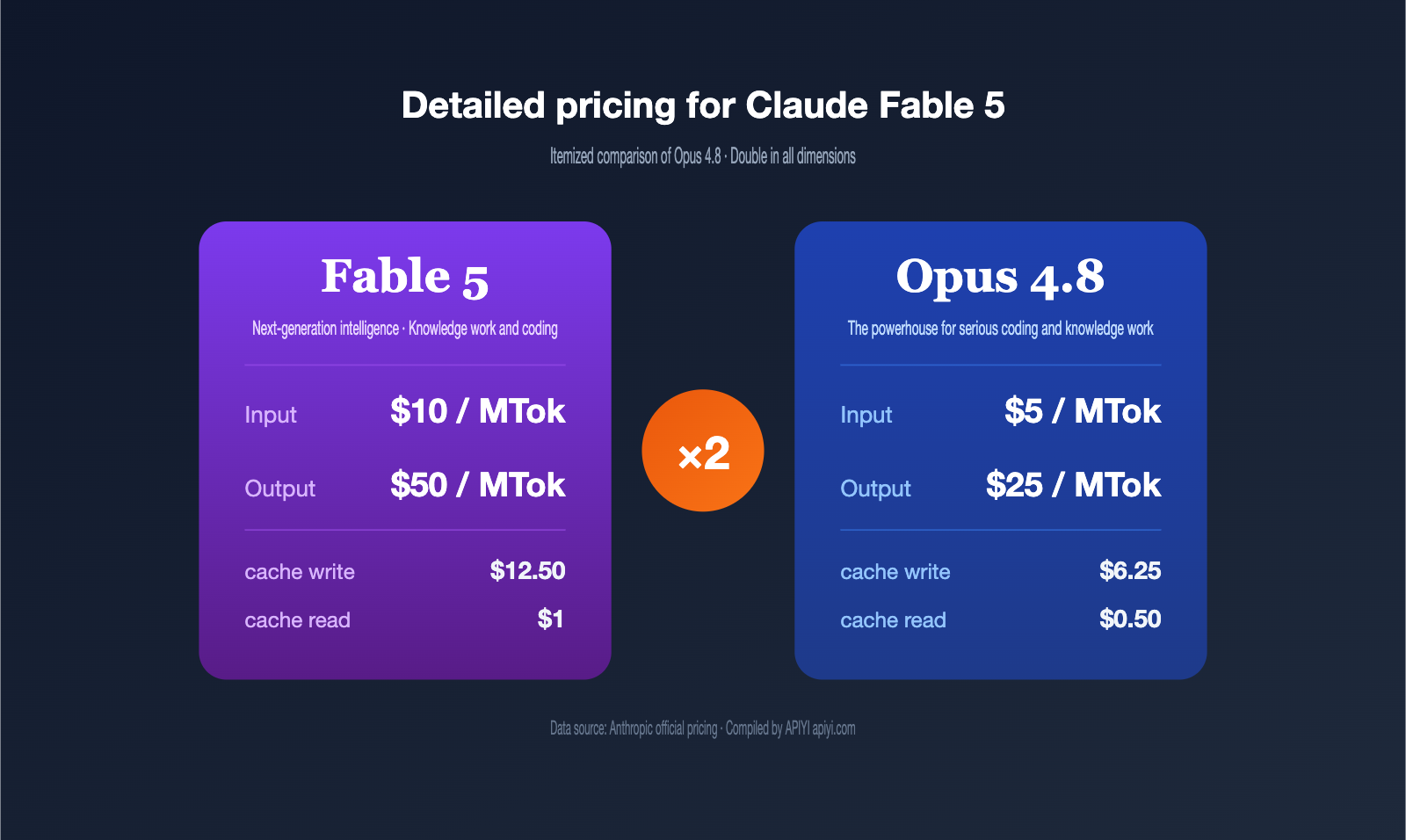
The new Claude Fable 5 model is here, but for many, the first question isn't how powerful it is—it's how expensive it is. The answer is straightforward: the official pricing is $10 per million tokens for input and $50 for output, making it exactly twice as expensive as Opus 4.8 across almost every billing dimension.
In this article, we’re cutting through the fluff. We’ll break down the pricing of Claude Fable 5, compare it item-by-item with Opus 4.8, and crunch the numbers to help you decide when to upgrade to Fable 5 and when sticking with Opus 4.8 makes more financial sense. All prices mentioned are based on official announcements and real-world testing on the APIYI (apiyi.com) platform.
I. Official Price Comparison: Claude Fable 5 vs. Opus 4.8
Let's put the critical numbers on the table. Claude Fable 5 is officially positioned as the "next-generation intelligence for knowledge work and coding," while Opus 4.8 is positioned as the "daily workhorse for serious coding and knowledge tasks." The price gap between the two perfectly reflects this "flagship" vs. "daily driver" division.
The table below provides a complete billing comparison, including the often-overlooked prompt caching costs:
| Billing Dimension | Claude Fable 5 | Opus 4.8 | Multiplier |
|---|---|---|---|
| Input | $10 / million tokens | $5 / million tokens | 2x |
| Output | $50 / million tokens | $25 / million tokens | 2x |
| Cache write | $12.50 / million tokens | $6.25 / million tokens | 2x |
| Cache read | $1 / million tokens | $0.50 / million tokens | 2x |
As you can see, Fable 5 isn't just more expensive in one area; it's exactly double across every dimension. This is actually good news: it means any cost projections you've already made for Opus can simply be multiplied by two to estimate your Fable 5 expenses, making migration assessment very straightforward.
🎯 Quick Conclusion: The pricing logic for Claude Fable 5 is simply "Opus × 2." If you've already modeled your costs for Opus on the APIYI (apiyi.com) platform, just double the numbers to estimate your Fable 5 spend—no need to rebuild your models.
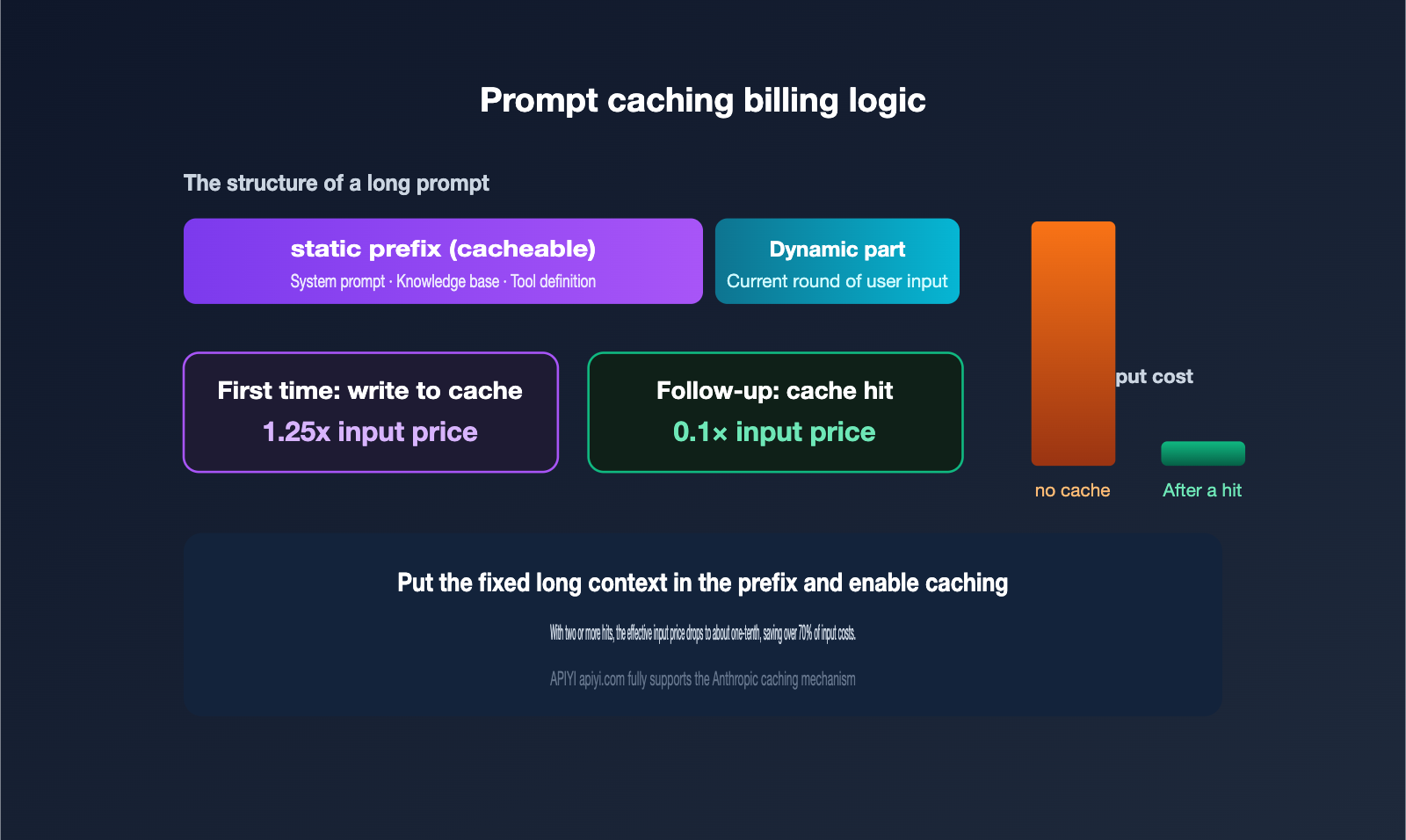
II. A Deep Dive into Prompt Caching: The Key to Cutting Claude Fable 5 Costs
Many people are scared off by the $10 input price for Fable 5, but they often overlook those two lines in the pricing table regarding cache costs. For scenarios involving large amounts of repetitive context, prompt caching is the real factor that dictates your bill.
The billing rules for caching are actually quite straightforward and align perfectly with the official pricing table:
- Cache Write (5-minute TTL): Charged at 1.25x the standard input price. For Fable 5, that’s $12.50; for Opus, it’s $6.25.
- Cache Read (Cache Hit): Charged at only 0.1x the input price. This means a Fable 5 hit costs just $1.00, and Opus costs $0.50—essentially a 90% discount.
- 1-Hour Long-Term Cache: Charged at 2x the input price, which is perfect for reusing context across longer sessions.
In other words, while writing a system prompt or a long document to the cache for the first time costs a bit more, as long as you hit that cache at least twice, your overall input costs drop significantly. For use cases like Agents, customer support, or document Q&A—where the system prompt is long and static—caching can slash your effective input costs to one-tenth of the original price.
🎯 Cost-Saving Tip: When using Claude Fable 5, be sure to place your fixed, long-form context (system prompts, knowledge bases, tool definitions) at the beginning of your prompt and enable caching. The APIYI (apiyi.com) platform fully supports Anthropic's caching mechanism, allowing you to save over 70% on input overhead with proper configuration.
III. Claude Fable 5 Real-World Cost Analysis: How Much Does a Single Invocation Actually Cost?
Looking at unit prices alone doesn't give you a real sense of the impact. Let's run the numbers for a typical scenario. Suppose an Agent invocation involves 20,000 input tokens and 5,000 output tokens—a common scale for medium-complexity tasks.
Using the official unit prices, we can create the comparison table below. For ease of comparison, we've listed both "No Cache" and "Full Cache Hit" scenarios:
| Scenario (20k Input + 5k Output) | Claude Fable 5 | Opus 4.8 |
|---|---|---|
| No Cache | ~$0.45 | ~$0.225 |
| Cache Hit | ~$0.27 | ~$0.135 |
| Savings per Request | ~40% | ~40% |
Two things are clear: First, Fable 5 costs about twice as much per invocation as Opus, which is expected. Second, regardless of the model, enabling caching can save you about 40% in costs for scenarios with repetitive context. Therefore, the real focus for cost optimization isn't agonizing over which model to choose, but rather making effective use of caching and batch processing.
🎯 Estimation Advice: Don't guess your costs. We recommend running a batch of comparison requests between Fable 5 and Opus using real traffic on the APIYI (apiyi.com) platform. Once you have the actual token consumption data, you can decide on your primary model and avoid budget overruns.
IV. Choosing Between Claude Fable 5 and Opus 4.8: A 4-Dimension Decision Framework
With the price being double, when is it actually worth paying the premium for Fable 5? The answer lies in the "value density" and "difficulty ceiling" of your tasks. Here are four dimensions to help you decide:
- Task Difficulty: For complex, multi-step tasks that require self-correction over long chains, Fable 5’s stability reduces rework, making it worth the price. For routine coding and Q&A, Opus 4.8 is more than enough.
- Invocation Frequency: Low-frequency, high-value decision points are perfect for Fable 5. For high-frequency, batch-processed tasks, Opus or even Sonnet are much more economical.
- Error Tolerance: In scenarios where the cost of failure is high (production deployments, critical documentation), the reliability premium of Fable 5 is a smart investment. For internal drafts or experimental tasks, it’s unnecessary.
- Context Reuse: In scenarios with high context reuse, both models can leverage caching to keep costs down. If you're price-sensitive in these cases, prioritize Opus.
| Decision Dimension | Lean Towards Claude Fable 5 | Lean Towards Opus 4.8 |
|---|---|---|
| Task Difficulty | Ultra-long / Complex Agent | Routine coding & Q&A |
| Invocation Frequency | Low-frequency, high-value | High-frequency, batch |
| Error Tolerance | High cost of failure | Retry-tolerant |
| Budget Sensitivity | Value-first | Cost-first |

🎯 Selection Advice: The most economical approach isn't picking one over the other, but layering them. We recommend using the APIYI (apiyi.com) platform for model routing: use Claude Fable 5 for critical nodes, downgrade to Opus 4.8 for routine tasks, and delegate high-frequency, trivial tasks to Sonnet.
V. Market Perspective: Why is Claude Fable 5 Priced This Way?
Looking at the broader market, Claude Fable 5 is undoubtedly positioned in the premium tier. For comparison, here is the pricing of mainstream flagship models from the same period.
Based on public pricing, GPT-5.4 is approximately $2.50 for input and $15 for output; Gemini 3.1 Pro is about $2 for input and $12 for output (increasing after 200k tokens), while also offering a massive 2M token context window. In contrast, Fable 5 costs $10 for input and $50 for output, which is significantly higher.
| Model | Input (per million tokens) | Output (per million tokens) | Context Window |
|---|---|---|---|
| Claude Fable 5 | $10 | $50 | 1M+ |
| Claude Opus 4.8 | $5 | $25 | 1M |
| GPT-5.4 | $2.50 | $15 | ~270K |
| Gemini 3.1 Pro | $2 | $12 | 2M |
This doesn't mean Fable 5 isn't worth it. It sells Mythos-level capability and stability for long-range tasks, targeting users for whom "the cost of a single task failure far outweighs the token cost." For those highly sensitive to price with less complex requirements, cheaper models are perfectly fine.
🎯 Horizontal Selection: If you're still torn between multiple vendors, the APIYI (apiyi.com) platform allows you to call Claude, GPT, and Gemini series using a single interface. This makes it easy to perform real-world price and performance comparisons for the same task, rather than just guessing based on a price sheet.
VI. Cost-Reduction Strategies: Making Claude Fable 5 More Affordable
Even if you've chosen Fable 5, there are ways to keep your bill in check. By combining the two major cost-reduction tools provided by Anthropic, you can see significant savings.
First is prompt caching, which we covered earlier; once a cache hit occurs, input costs are slashed to 10% of the original price. Second is the Batch API, which offers a 50% discount on both input and output for asynchronous batch processing. When used together, you can reduce your effective API spending by up to 95% for qualifying workloads.
In practice, the priority should be: first, turn your fixed long context into a cached prefix, then route tasks that are asynchronous and latency-insensitive (like batch generation or offline analysis) through the Batch channel. If you nail these two steps, the "high cost" of Fable 5 will be significantly offset in many scenarios.
🎯 Money-Saving Combo: Caching + Batch processing is the golden combination for reducing Claude Fable 5 costs. The APIYI (apiyi.com) platform supports both, making it a great fit for teams that need to scale their model invocation while keeping costs under control.
VII. FAQ
Q1: Is Claude Fable 5 really twice as expensive as Opus 4.8?
Yes, and it's double across the board. Input is 10 vs 5, output is 50 vs 25, cache write is 12.50 vs 6.25, and cache read is 1 vs 0.50—every single metric is exactly a 2x increase.
Q2: Does prompt caching always save money?
It depends on how often you reuse the data. The 5-minute cache write costs 1.25x the input price, so you break even after just one subsequent hit; the more hits you get, the more you save. However, if your context changes every time and is rarely reused, caching will actually increase your costs due to the write fees. In those scenarios, it's better to skip caching.
Q3: What kind of tasks are worth using Claude Fable 5 for?
It's best for high-value tasks where the cost of errors is high, the logic chain is long, or the model needs to perform self-correction—such as complex codebase refactoring or long-running Agents. Using it for high-frequency, simple tasks is a waste; we recommend using tiered routing on the APIYI (apiyi.com) platform.
Q4: Are there cheaper alternatives in the same class?
As public flagship models, GPT-5.4 and Gemini 3.1 Pro have lower unit prices, but their capabilities are focused differently. We recommend running actual tests for your specific tasks rather than just comparing unit prices.
VIII. Summary
The pricing story for Claude Fable 5 is actually quite straightforward: it’s exactly double that of Opus 4.8 across every billing dimension—$10 for input, $50 for output, and a proportional doubling for cache pricing. This clean multiplier makes cost estimation incredibly simple: just take your Opus budget and multiply it by two.
The real key isn't about choosing between expensive or cheap models; it's about tiered model invocation based on task value density, while making the most of two powerful cost-reduction tools: prompt caching and the Batch API. If you're looking to manage Claude Fable 5, Opus 4.8, and other models through a single interface while flexibly routing for cost efficiency, you can handle your integration and run side-by-side tests directly on the APIYI (apiyi.com) platform.
This article was compiled by the APIYI (apiyi.com) technical team, who continuously tracks pricing and best practices for the Claude 5 series and other mainstream Large Language Models.