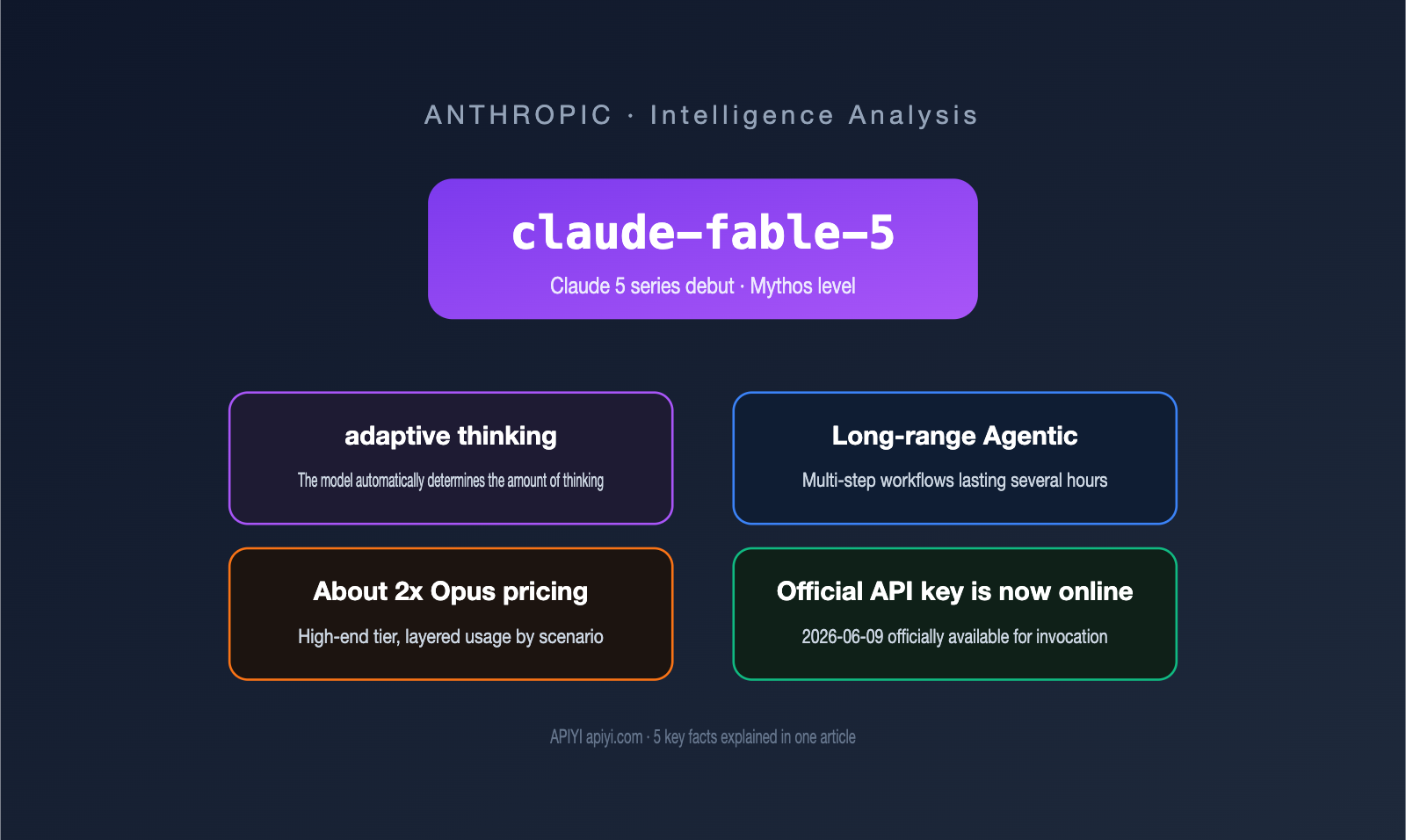
On June 9, 2026, Anthropic quietly pushed claude-fable-5 to the official api.anthropic.com/v1/messages endpoint. This means the first publicly available model in the Claude 5 series is no longer just a rumor on prediction markets—it's a real product you can get an API key for and start using right now.
This article skips the marketing fluff and focuses on one thing: providing a verifiable intelligence report that covers the origins, capability positioning, adaptive thinking, pricing, and invocation methods for claude-fable-5. All technical details are based on a combination of official release information and hands-on testing from the APIYI (apiyi.com) platform.
1. What is claude-fable-5: The debut model of the Claude 5 series
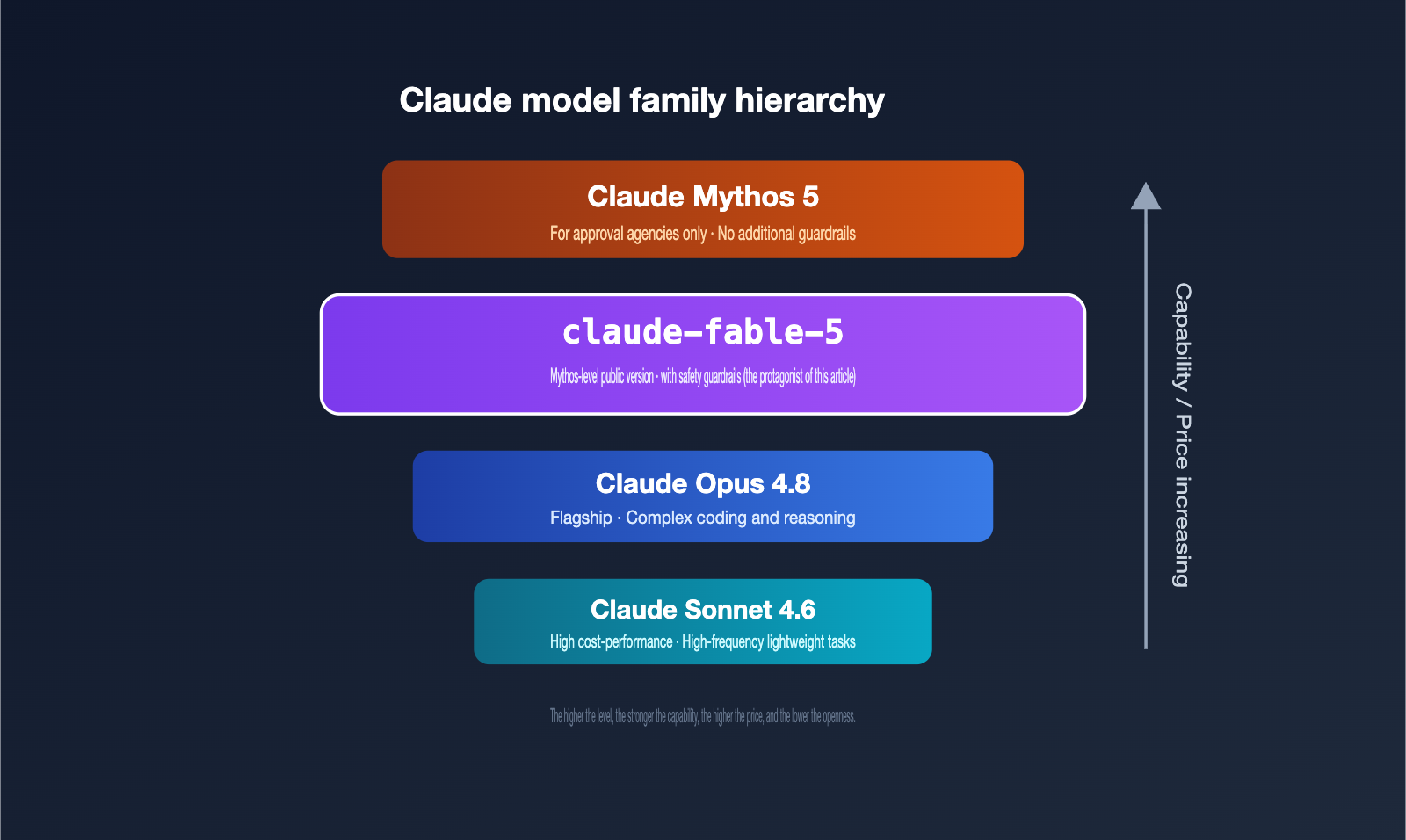
Let's start with the core positioning. claude-fable-5 is the first model in Anthropic's brand-new Claude 5 family to be opened to the public. It belongs to a new tier called "Mythos-class," with capability positioning that sits above the previous Claude Opus.
Its origins trace back to April 2026. At that time, Anthropic released the Claude Mythos Preview to a select few partners—including AWS, Microsoft, Apple, and CrowdStrike—through a restricted program called Project Glasswing. This was their most powerful frontier model at the time, particularly adept at coding, reasoning, and cybersecurity, even capable of autonomously discovering and chaining zero-day vulnerabilities across operating systems and browsers.
claude-fable-5 is the "public release version" of these capabilities. In other words, for the first time, ordinary developers have the chance to access near-Mythos-level intelligence without needing to join a restricted whitelist.
🎯 Quick Conclusion: If you've been using Claude Opus for complex agent tasks,
claude-fable-5is currently the top-tier public upgrade option. If you want to test it out immediately, you can use this model directly on the APIYI (apiyi.com) platform without needing to apply for a whitelist yourself.
II. The Relationship Between claude-fable-5 and Claude Mythos 5
Many people get confused by the names Fable and Mythos, but in reality, they are "the same foundation, two different distribution strategies." Understanding this relationship is key to grasping the positioning of claude-fable-5.
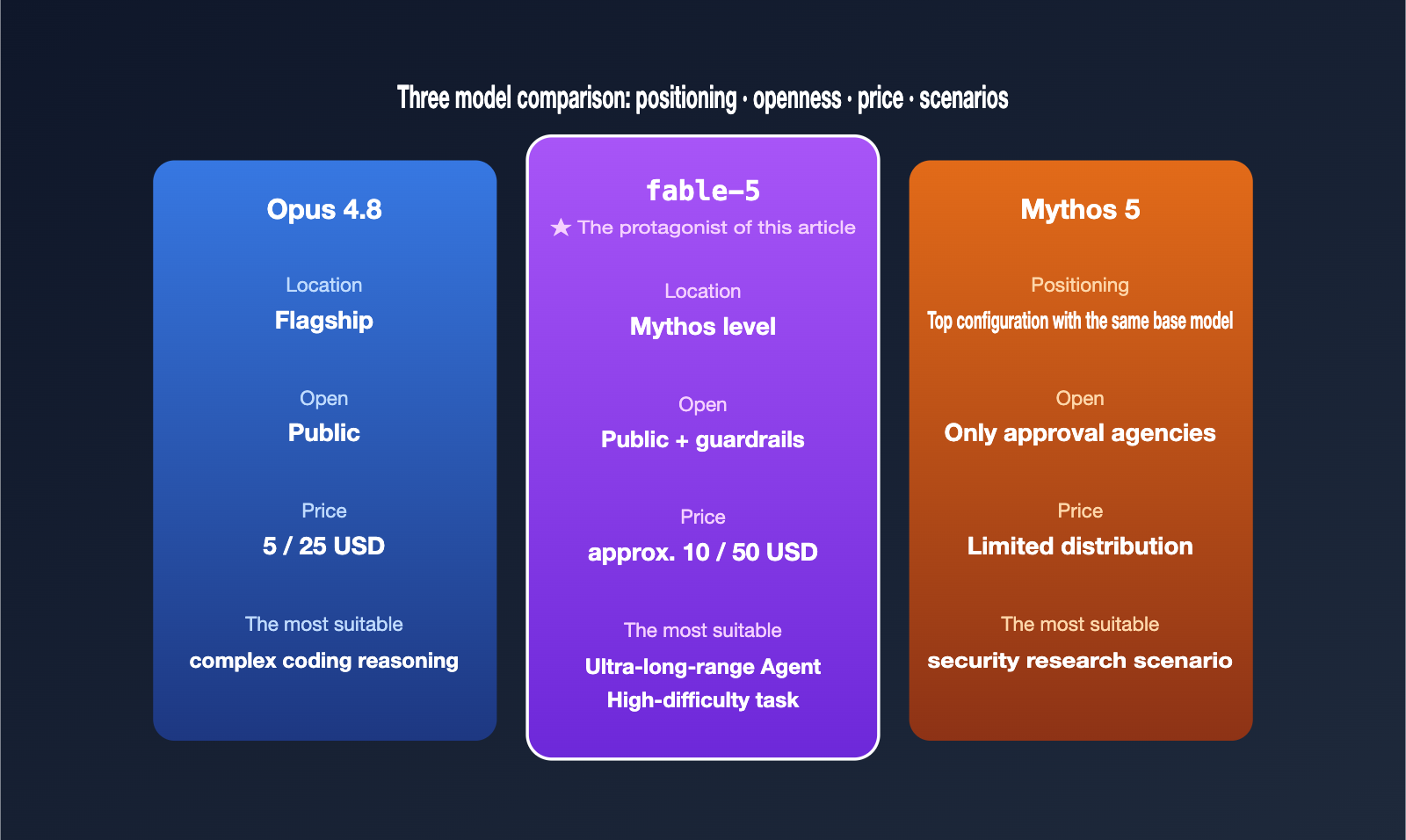
Simply put, claude-fable-5 and Claude Mythos 5 share the same underlying model; the real difference lies in their safety policies. Fable 5 is available to the public but includes additional safety guardrails for high-risk, dual-use capabilities. Mythos 5, on the other hand, lacks these restrictions and is provided only to a select group of approved institutions.
The official description of Fable 5 is "our most intelligent, generally available model." Its high-risk capabilities, such as cybersecurity, have been explicitly tightened: the public version "will not be as open in terms of cyber offensive and defensive capabilities as the version provided to Project Glasswing partners."
| Dimension | claude-fable-5 | Claude Mythos 5 |
|---|---|---|
| Underlying Model | Same foundation | Same foundation |
| Openness | Publicly available, with safety guardrails | Restricted to approved institutions |
| Dual-use Capabilities | Tightened | No additional restrictions |
| Typical Users | All developers | Project Glasswing partners |
| Access Method | Official API / Third-party gateway | Restricted distribution |
🎯 Pro Tip: For the vast majority of development scenarios, the guardrails in Fable 5 won't affect standard coding, writing, or Agent tasks. We recommend calling claude-fable-5 directly via the APIYI (apiyi.com) platform, allowing you to focus on your business rather than navigating compliance whitelist applications.
III. Core Capabilities of claude-fable-5: Long-range Agentic and High-complexity Tasks
What makes claude-fable-5 truly noteworthy isn't just its benchmark scores, but its endurance in "long-duration, multi-step" tasks. This generation of models has been explicitly strengthened to excel at long-horizon, Agent-style workflows.
Combining official information with the evolution of the previous Opus series, the strengths of claude-fable-5 are primarily reflected in three areas:
- Long-range Task Endurance: It maintains focus during multi-step workflows lasting several hours and tends to self-correct and adjust when tool calls fail, rather than simply aborting.
- Complex Coding and Reasoning: It performs better in long context window processing, multi-turn conversations, and complex codebase refactoring, making it an ideal "brain" for Agents.
- Cybersecurity Understanding: It possesses strong vulnerability analysis capabilities (though the public version has tightened offensive use cases), making it suitable for code auditing and security research assistance.
As a performance reference, the contemporary Claude Opus 4.8 solved 88.6% of problems on SWE-bench Verified and 69.2% on SWE-bench Pro. As a Mythos-class model, claude-fable-5 is positioned above Opus, specifically targeting the ultra-long-chain tasks that Opus struggles to complete reliably.
IV. Adaptive Thinking: A New Way to Invoke claude-fable-5
If you’ve taken a look at the actual request body for claude-fable-5, you’ll notice a key change: the thinking parameter no longer uses budget_tokens. Instead, it now uses {"type": "adaptive"}. This isn't just a stylistic preference; it represents a generational leap in Claude’s reasoning mechanism.
The core of "adaptive thinking" is allowing the model to evaluate the complexity of each request itself. It dynamically decides whether to think and how much effort to exert, rather than relying on developers to manually set a fixed reasoning budget. For simple questions, it might skip the thinking process entirely, while for complex tasks, it automatically allocates more reasoning power.
This mechanism also introduces two important additional capabilities. First, you can layer on an effort parameter, providing four levels—low, medium, high (default), and max—to guide the intensity of the reasoning. Second, it automatically enables "interleaved thinking," allowing the model to continue reasoning between tool calls—which is critical for Agent workflows.
It’s worth noting that on Claude Opus 4.8 / 4.7, adaptive is already the only supported reasoning mode; manual {type: "enabled", budget_tokens: N} configurations are no longer accepted. claude-fable-5 follows this same design, so please use adaptive directly when integrating.
| Comparison | Legacy Extended Thinking | Adaptive Thinking |
|---|---|---|
| Reasoning Budget | Manually set budget_tokens |
Automatically determined by model |
| Simple Tasks | Still consumes budget | Can skip thinking to save costs |
| Intensity Control | Based on token count | Four levels: low/medium/high/max |
| Interleaved Thinking | Requires manual config | Automatically enabled |
| Use Case | Fixed complexity | Bimodal tasks, long-range Agents |
🎯 Integration Tip: When migrating to
claude-fable-5, simply changethinkingto{"type": "adaptive"}and stop worrying about budget numbers. If you're unsure about parameter compatibility, the APIYI (apiyi.com) platform has already adapted toadaptive, so you can call it using the official format directly.
V. claude-fable-5 Pricing and Invocation
The more powerful the capability, the higher the cost. According to release information, claude-fable-5 is priced at approximately double that of Claude Opus. As a benchmark, Opus 4.8 is priced at $5 per million tokens for input and $25 for output, so Fable 5 lands roughly at $10 for input and $50 for output (subject to official billing).
While this price is much more accessible than the original "5x Opus" rumors surrounding the Mythos series, it still sits in the premium tier. Therefore, it’s better suited for high-value, highly complex tasks rather than high-frequency, lightweight calls.
Below is a minimal, functional code snippet showing how to connect to claude-fable-5 using the official format:
from anthropic import Anthropic
# Use APIYI for base_url to easily manage and switch between multiple models
client = Anthropic(base_url="https://api.apiyi.com", api_key="YOUR_API_KEY")
resp = client.messages.create(
model="claude-fable-5",
max_tokens=32000,
thinking={"type": "adaptive"}, # Key: Use adaptive thinking
messages=[{"role": "user", "content": "Help me refactor this module and self-verify the results"}],
)
print(resp.content)
In production, we recommend configuring a larger max_tokens (like the 32,000 shown in the snippet) for claude-fable-5, as its long-range reasoning and interleaved thinking will generate more intermediate content. Using it at critical decision nodes in your Agent pipeline while offloading high-frequency, simple tasks to cost-effective models like Sonnet is a more economical strategy.
| Model | Positioning | Price (per million tokens) | Recommended Use Case |
|---|---|---|---|
| Claude Sonnet 4.6 | High Cost-Efficiency | ~$3 / $15 | High-frequency, light tasks |
| Claude Opus 4.8 | Flagship | $5 / $25 | Complex coding, reasoning |
| claude-fable-5 | Mythos-level Public | ~$10 / $50 | Long-range Agents, difficult tasks |
🎯 Cost Optimization: You don't need to use
claude-fable-5for every call. We recommend using a unified interface on the APIYI (apiyi.com) platform for model routing: use Fable 5 for critical nodes and downgrade to Opus or Sonnet for routine tasks to keep overall costs under control.
VI. FAQ
Q1: Can I call claude-fable-5 right now?
Yes, you can. The official api.anthropic.com/v1/messages endpoint has already launched this model. In our tests, we were able to receive full streaming responses, including message_start and content_block_delta. If you don't have an official API key on hand, you can also call claude-fable-5 directly through the APIYI (apiyi.com) platform.
Q2: Should I use Fable 5 or Mythos 5?
The vast majority of users can—and only need to—use Fable 5. Mythos 5 is restricted to approved institutions and lacks dual-use safety guardrails, making it primarily intended for specific safety research scenarios. For standard development, Fable 5 is more than enough.
Q3: Is adaptive thinking mandatory, or can I set a fixed budget?
We recommend sticking with adaptive. Continuing the design philosophy from Opus 4.8/4.7, this generation of models treats adaptive as the recommended (and on Opus, the only) thinking mode; manual budget_tokens are no longer accepted. Simply set thinking to {"type": "adaptive"}.
Q4: The price is quite high—is it worth it?
It depends on the value of the task. For long-running agents that need to operate for hours with fault tolerance, or for complex codebase refactoring, the stable performance of Fable 5 can save you a significant amount of manual rework. However, for high-frequency, simple tasks, it’s overkill. The most cost-effective approach is to implement tiered model invocation based on your specific use case.
VII. Summary
The release of claude-fable-5 marks the official public debut of the Claude 5 era. Here are the five key takeaways: it’s the first publicly available Mythos-class model in the Claude 5 series; it shares the same foundation as Mythos 5 but includes safety guardrails; it’s optimized for long-range Agentic workflows and high-complexity tasks; it uses the unified adaptive thinking mode; and it’s priced at roughly twice the cost of Opus, with official API key support already live.
For developers, the best next step is to integrate it into a real-world workflow and experience its performance on long-chain tasks firsthand. If you're looking to manage claude-fable-5, Opus, and Sonnet through a single interface with flexible routing based on your needs, you can complete your integration and comparative testing directly on the APIYI (apiyi.com) platform.
This article was compiled by the APIYI (apiyi.com) technical team, dedicated to tracking the latest intelligence and best practices for the Claude 5 series and other mainstream Large Language Models.