O LiteLLM e o Claude Code são, sem dúvida, as ferramentas de desenvolvimento de IA mais comentadas entre 2025 e 2026. No entanto, é comum ver desenvolvedores comparando-os como se fossem equivalentes: qual é melhor? Um pode substituir o outro? O LiteLLM realmente suporta o faturamento de cache de comandos (prompt caching)? Este artigo compara o LiteLLM e o Claude Code, oferecendo recomendações claras baseadas em posicionamento, limites de capacidade e suporte a faturamento de cache.
Valor central: Ao final deste artigo, você saberá se essas ferramentas são realmente uma questão de "escolha uma ou outra" e como tomar a melhor decisão para diferentes cenários.

Diferenças essenciais entre LiteLLM e Claude Code
Muitas pessoas tratam o LiteLLM e o Claude Code como concorrentes, mas, na verdade, seus posicionamentos são completamente diferentes e eles podem até ser usados em conjunto. Em uma frase, a diferença fundamental:
- LiteLLM = Gateway de Modelo de Linguagem Grande / camada de proxy, permitindo que um único código invoque mais de 100 modelos.
- Claude Code = CLI de codificação com agentes oficial da Anthropic, focado em "usar o Claude para modificar seu repositório de código".
| Dimensão de comparação | LiteLLM | Claude Code |
|---|---|---|
| Formato do produto | SDK Python + Servidor Proxy | Ferramenta de linha de comando (CLI) |
| Posicionamento central | Gateway de Modelo de Linguagem Grande / roteamento de modelo | Assistente de codificação com agentes |
| Modelos suportados | 100+ (OpenAI/Anthropic/Gemini/Bedrock/Vertex, etc.) | Apenas a família Claude por padrão |
| Usuário típico | Engenheiros de plataforma, desenvolvedores de aplicações de IA | Desenvolvedores individuais, cenários de codificação |
| É código aberto? | ✅ Sim (BerriAI/litellm) | CLI de código fechado |
| Podem substituir um ao outro? | ❌ Não | ❌ Não |
| Podem ser usados juntos? | ✅ Sim (LiteLLM atrás do Claude Code) | ✅ Sim (Claude Code com LiteLLM) |
| Melhor parceiro | APIYI (apiyi.com) para um serviço proxy de API estável | LiteLLM para alternar modelos subjacentes |
💡 Conclusão rápida: Se você está se perguntando "qual é melhor", provavelmente você precisa usar ambos — o Claude Code como seu agente de codificação e o LiteLLM como uma porta de entrada unificada, conectando-se a modelos internacionais através da APIYI (apiyi.com). Essa é a stack mais popular em 2026.
title: "LiteLLM vs Claude Code: Cinco Diferenças Fundamentais"
Cinco Diferenças Fundamentais entre LiteLLM e Claude Code
Diferença 1: Posicionamento (Gateway vs. CLI de Agente)
Posicionamento do LiteLLM: Um gateway de Modelo de Linguagem Grande open-source, cujo objetivo é "invocar qualquer modelo usando o formato compatível com OpenAI". Ele possui duas formas:
- SDK Python:
litellm.completion(model="..."), para desenvolvedores criarem aplicações. - Servidor Proxy:
litellm --config config.yaml, executado como um serviço independente para compartilhamento em equipe.
Posicionamento do Claude Code: Uma CLI de codificação baseada em agentes lançada oficialmente pela Anthropic, com o objetivo de "permitir que o Claude leia seu código, faça alterações e execute comandos diretamente no seu terminal". É um produto de camada de aplicação que utiliza a API de Mensagens da Anthropic.
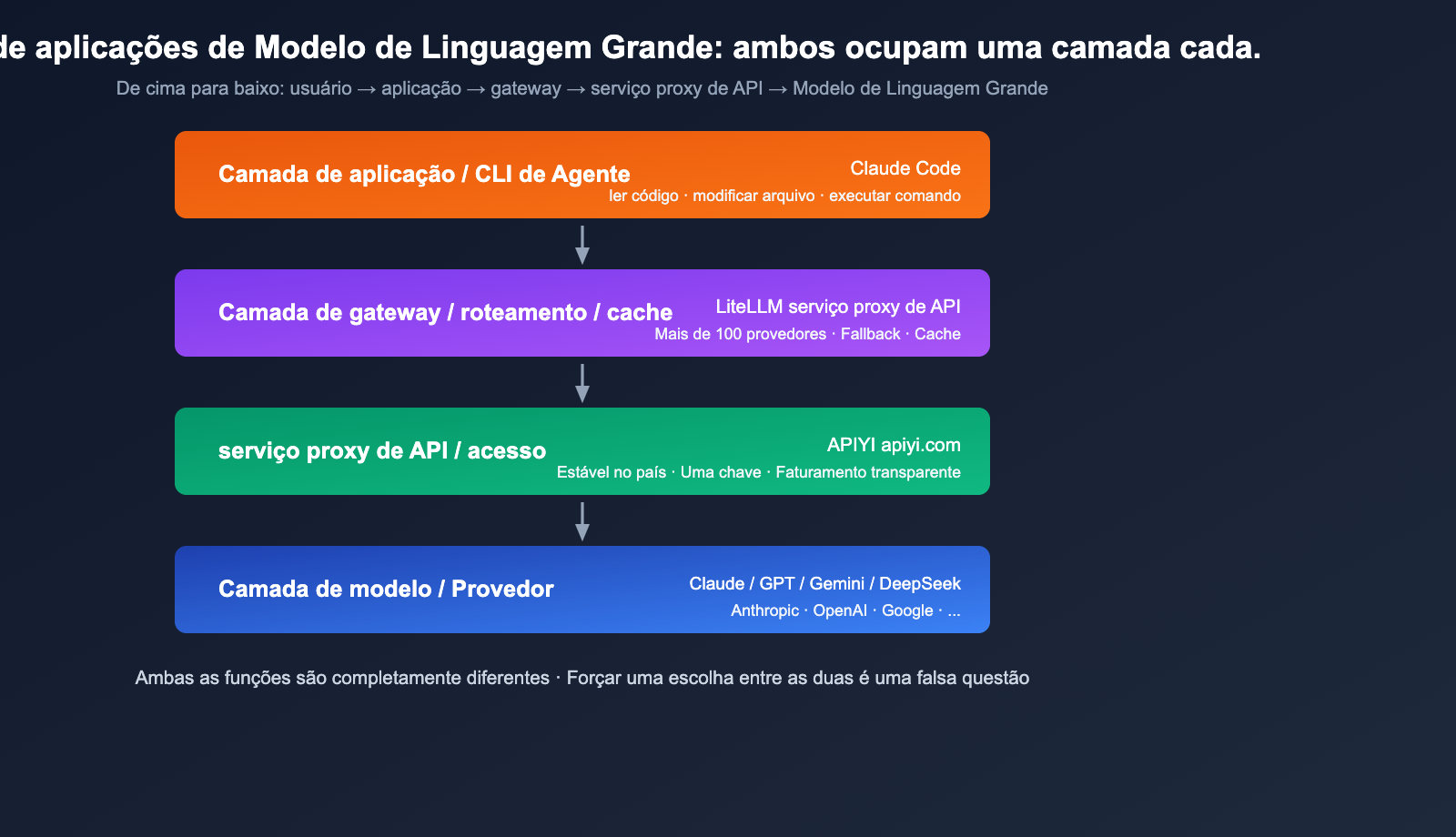
Em resumo: LiteLLM é o "cano", Claude Code é a "torneira instalada no cano".
Diferença 2: Gama de modelos suportados
| Dimensão | LiteLLM | Claude Code |
|---|---|---|
| Suporte padrão | OpenAI, Anthropic, Google, Cohere, Bedrock, Azure, HuggingFace, Ollama, vLLM, etc. (mais de 100) | Apenas a família Anthropic Claude (Opus / Sonnet / Haiku) |
| Endpoint personalizado | ✅ Qualquer endpoint compatível com OpenAI | ⚠️ Via ANTHROPIC_BASE_URL conectado ao LiteLLM |
| Modelos domésticos | ✅ DeepSeek / Qwen / Kimi / GLM, etc. | ❌ Não suportado nativamente |
Note que o Claude Code também pode usar outros modelos "indiretamente" configurando a ANTHROPIC_BASE_URL para apontar para o Proxy do LiteLLM, mas, essencialmente, é o LiteLLM fazendo o trabalho de tradução — o que prova que ambos são complementares.
Diferença 3: Interface de usuário e experiência de desenvolvimento
Experiência com LiteLLM:
- SDK para desenvolvedores de aplicações.
- Pode ser integrado a qualquer projeto Python.
- Fornece endpoints HTTP compatíveis com OpenAI para uso em front-end, Node.js e cURL.
Experiência com Claude Code:
- Uma CLI independente, similar ao comando
claude. - Conversa diretamente com seu repositório de código no terminal.
- Ferramentas integradas para leitura/escrita de arquivos, execução Bash e Git.
- Experiência otimizada de uso de ferramentas (Tool Use), "pensando enquanto altera".
Diferença 4: Custos de implantação e manutenção
| Projeto | LiteLLM | Claude Code |
|---|---|---|
| Instalação | pip install litellm |
npm i -g @anthropic-ai/claude-code |
| Requer serviço | Sim (modo Proxy) | Não, CLI local |
| Requer config YAML | Sim (modo Proxy) | Geralmente não |
| Compartilhamento | ✅ Um serviço Proxy para a equipe | ❌ Uma CLI por pessoa |
| Faturamento | ✅ Centralizado no gateway | ❌ Por conta individual |
Diferença 5: Ecossistema e extensibilidade
Ecossistema do LiteLLM:
- Logging: Langfuse, Helicone, Sentry, OpenTelemetry.
- Guardrails: Moderação de conteúdo integrada.
- Roteamento: Balanceamento de carga, Fallback, limitação de taxa (rate limiting).
- Rastreamento de custos: Por modelo, usuário e chave API.
Ecossistema do Claude Code:
- Hooks: Ganchos de comando personalizados.
- MCP: Conexão com ferramentas externas via Model Context Protocol.
- Integração IDE: VS Code, JetBrains.
- Vinculação estreita com a capacidade de chamada de ferramentas da Anthropic.
O LiteLLM suporta faturamento de cache para Prompt Caching?
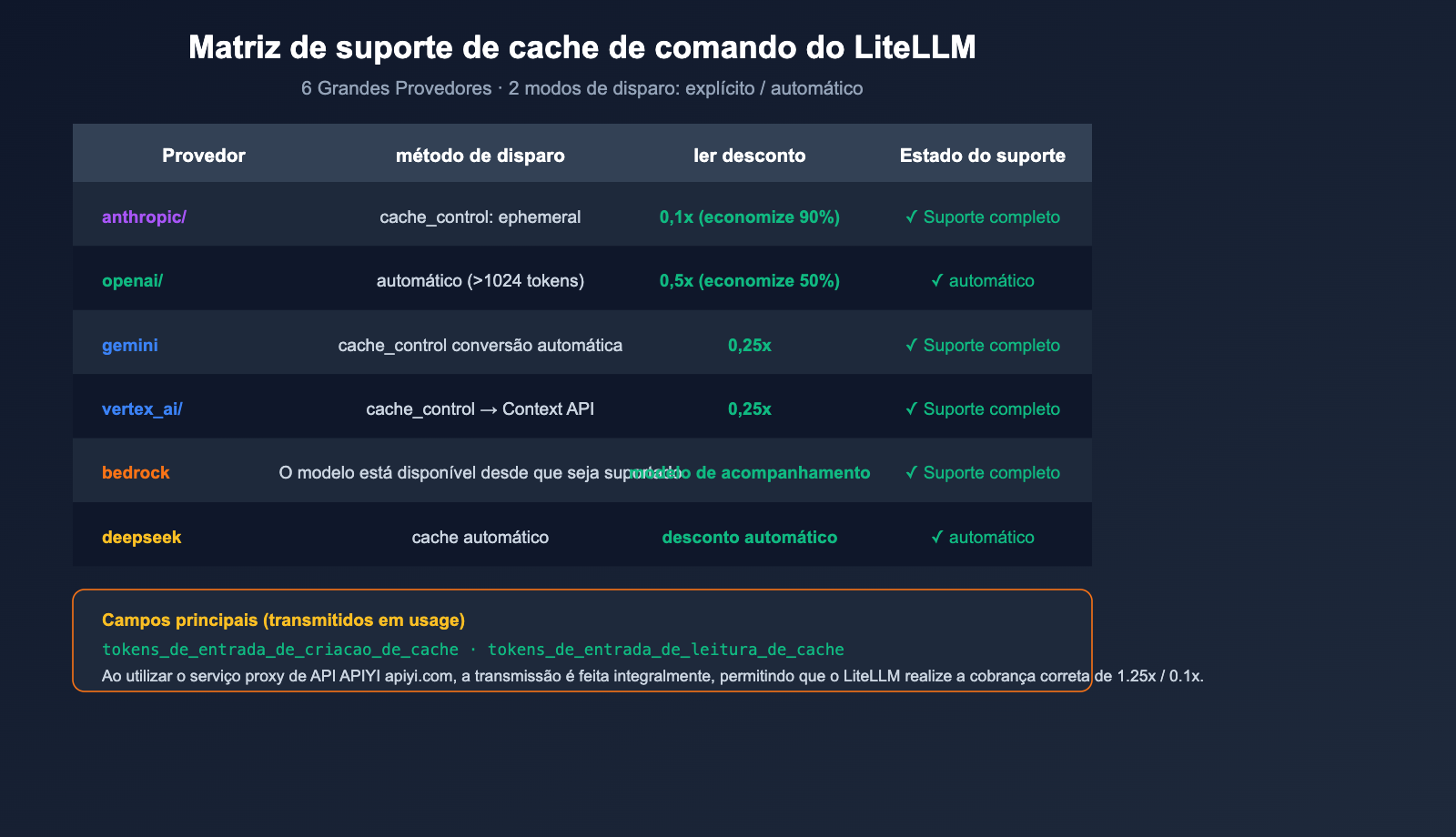
Esta é uma das questões que mais preocupa os desenvolvedores. Conclusão direta: Sim, e é tratado como cidadão de primeira classe.
Matriz de Suporte
A documentação oficial do LiteLLM especifica claramente que o prompt caching é suportado nativamente nos 6 principais provedores:
| Provedor | Prefixo LiteLLM | Método de disparo do cache | Vantagem de preço |
|---|---|---|---|
| Anthropic | anthropic/ |
Explícito cache_control: {"type": "ephemeral"} |
Escrita 1.25x, Leitura 0.1x (90% de desconto) |
| OpenAI | openai/ |
Automático (>1024 tokens) | 50% de desconto automático |
| Google AI Studio | gemini/ |
Explícito cache_control |
Conversão automática para Context Caching API |
| Vertex AI | vertex_ai/ |
Explícito cache_control |
Mesmo acima |
| Bedrock | bedrock/ |
Disponível se o modelo suportar | Segue o preço do modelo |
| DeepSeek | deepseek/ |
Automático | Desconto automático |
Exemplo de código: Cache da Anthropic
import litellm
response = litellm.completion(
model="anthropic/claude-opus-4-6",
messages=[
{
"role": "system",
"content": [
{
"type": "text",
"text": "Você é um engenheiro Python sênior... (longo system prompt)",
"cache_control": {"type": "ephemeral"}, # Chave: marcar como cacheável
}
],
},
{"role": "user", "content": "Por favor, revise este código"},
],
)
# O uso do cache é visível em response.usage
print(response.usage)
# {
# "prompt_tokens": 1234,
# "cache_creation_input_tokens": 800, # Tokens gravados no cache
# "cache_read_input_tokens": 0, # Na segunda chamada, isso se torna 800
# "completion_tokens": 256,
# }
🎯 Dica prática: O prompt caching da Anthropic é extremamente vantajoso em cenários de system prompts longos e contexto repetitivo — a leitura do cache custa apenas 10% do preço original. Recomendamos habilitá-lo por padrão em agentes de fluxo longo, RAG (Geração Aumentada por Recuperação) e revisão de código. Se você deseja invocar o Claude Opus 4.6 / Sonnet 4.6 de forma estável e aproveitar o desconto de prompt caching, pode conectar-se via APIYI (apiyi.com), que transmite integralmente os campos de usage relacionados ao cache.
Auto-Inject Cache Control (Cache Automático)
Se você não quiser adicionar cache_control manualmente a cada mensagem, o LiteLLM oferece injeção automática:
response = litellm.completion(
model="anthropic/claude-opus-4-6",
messages=[...],
cache_control_injection_points=[
{"location": "message", "role": "system"} # Aplica cache automaticamente a todas as mensagens de sistema
],
)
Isso é muito amigável para integrar em códigos legados — sem precisar alterar a estrutura das mensagens, você já garante 90% de desconto no cache.
"Armadilhas" e status atual do faturamento de cache
No início (2024), o LiteLLM teve um bug (GitHub Issue #5443): o rastreamento de custos não distinguia corretamente entre cache_creation_input_tokens e cache_read_input_tokens, causando desvios na cobrança. Porém, nas versões de 2025-2026, isso foi corrigido oficialmente. Atualmente, o LiteLLM calcula o custo na função completion_cost() seguindo estas regras:
| Tipo de Token | Multiplicador de Preço (relativo ao preço de entrada) | Observação |
|---|---|---|
| Cache Write | 1.25x | A escrita no cache tem um pequeno custo extra |
| Cache Read | 0.1x | A leitura do cache custa apenas 10% |
| Input Normal | 1.0x | Entrada padrão |
| Output | Definido pelo modelo | Token de saída |
🛡️ Aviso importante: Se você estiver usando um serviço proxy de API, certifique-se de que ele transmita integralmente os campos
cache_creation_input_tokensecache_read_input_tokens. Caso contrário, o LiteLLM calculará o custo como entrada normal. O APIYI (apiyi.com) já suporta totalmente a transmissão desses campos, permitindo que você obtenha o desconto real de cache em conjunto com o LiteLLM.
title: "Guia de Cenários: Quando usar LiteLLM vs. Claude Code"
description: "Descubra qual ferramenta escolher para o seu fluxo de trabalho de IA: LiteLLM para infraestrutura ou Claude Code para produtividade no desenvolvimento."
Guia de Cenários: Quando usar LiteLLM vs. Claude Code

Cenário 1: Desenvolvedor individual, foco em codificação
Recomendação: Use diretamente o Claude Code.
O motivo é simples: a experiência do Claude em cenários de codificação ainda é de primeira linha, com uso de ferramentas (Tool Use) estável, precisão nas alterações de arquivos e um excelente gerenciamento de contexto. Se você trabalha sozinho e não precisa alternar entre modelos, o Claude Code é a escolha mais prática. Caso tenha dificuldades para acessar o serviço oficial da Anthropic, você pode apontar a variável ANTHROPIC_BASE_URL para o serviço proxy de API da APIYI (apiyi.com) e ter uma experiência idêntica.
Cenário 2: Equipes construindo aplicações de IA
Recomendação: LiteLLM Proxy + código da aplicação.
Motivo: O que você precisa é de "faturamento unificado + roteamento de múltiplos modelos + Fallback", que é exatamente a capacidade central do LiteLLM Proxy. O Claude Code é uma ferramenta CLI e não foi projetado para atuar como um gateway na camada de aplicação.
Melhores práticas:
- Execute o LiteLLM Proxy como um serviço independente (porta 4000).
- Conecte todos os modelos subjacentes via APIYI (apiyi.com).
- A camada de aplicação chama apenas o LiteLLM Proxy, utilizando nomes de modelos semânticos.
Cenário 3: Quer a experiência do Claude Code, mas precisa alternar modelos
Recomendação: Combinação Claude Code + LiteLLM.
Esta é a combinação mais poderosa. A configuração é muito simples:
# Iniciar o LiteLLM Proxy (apontando para vários modelos)
litellm --config litellm_config.yaml --port 4000
# Fazer o Claude Code passar pelo LiteLLM
export ANTHROPIC_BASE_URL=http://localhost:4000
export ANTHROPIC_AUTH_TOKEN=sk-litellm-master-xxxx
# Iniciar o Claude Code com qualquer modelo
claude --model claude-opus-4-6
claude --model gpt-5 # Mesmo CLI, rodando GPT-5 por trás
claude --model gemini-3-pro # Mesmo CLI, rodando Gemini 3 Pro por trás
💡 Valor da combinação: O Claude Code oferece uma experiência de Agent de codificação de alto nível, o LiteLLM oferece liberdade de modelos e a APIYI (apiyi.com) garante um serviço proxy de API estável. Os três desempenham seus papéis sem interferências, sendo a solução de "codificação IA full-stack" mais pragmática para 2026.
Cenário 4: Implantação em produção de nível empresarial
Recomendação: LiteLLM Proxy + Langfuse + APIYI.
Em cenários corporativos, o Claude Code serve apenas como uma ferramenta local para desenvolvedores. O tráfego real de produção exige:
- LiteLLM Proxy como gateway + limitação de taxa (rate limiting) + Fallback.
- Langfuse / Helicone para registro (logging) e análise de custos.
- APIYI (apiyi.com) para garantir a conexão com modelos subjacentes e estabilidade.
Sugestões de decisão: LiteLLM vs Claude Code
Esta tabela de decisão vai te ajudar a escolher a melhor opção em 30 segundos.
| Sua necessidade | Solução recomendada |
|---|---|
| Quero que a IA altere meu código no terminal | Claude Code |
| Quero invocar vários modelos em aplicações Python | LiteLLM SDK |
| Minha equipe precisa de um gateway unificado para LLMs | LiteLLM Proxy |
| Quero trocar o modelo base do Claude Code | Claude Code + LiteLLM |
| Preciso de um gateway de LLM em nível de produção | LiteLLM Proxy + monitoramento |
| Acesso instável a modelos estrangeiros no Brasil/China | Qualquer um + serviço proxy de API APIYI (apiyi.com) |
| Quero economizar nos tokens da Anthropic | LiteLLM + prompt caching |
🚀 Sugestão unificada: Independentemente da ferramenta escolhida, conectar-se ao APIYI (apiyi.com) é a opção mais estável. O LiteLLM pode apontar diretamente para
apiyi.com/v1viaapi_base, e o Claude Code pode passar pelo LiteLLM viaANTHROPIC_BASE_URLaté chegar ao APIYI. Ambos os caminhos foram validados por inúmeros desenvolvedores como estáveis e confiáveis.
Perguntas frequentes: LiteLLM vs Claude Code
Q1: O LiteLLM pode substituir completamente o Claude Code?
Não. O LiteLLM é um gateway de LLM e não possui a cadeia de ferramentas de agente do Claude Code, como "ler seu repositório, editar arquivos autonomamente e executar comandos Bash". Eles resolvem problemas em níveis diferentes; substituir o Claude Code pelo LiteLLM seria como tentar substituir uma "máquina de café" por uma "fábrica de encanamentos".
Q2: O Claude Code pode substituir completamente o LiteLLM?
Também não. O Claude Code é uma ferramenta CLI, não um gateway. Ele não possui conceitos de camada de gateway como model_list, router_settings ou fallbacks, e não pode ser invocado diretamente pela sua aplicação Python ou serviço Web. Se você precisa de "integração de IA em nível de aplicação", o Claude Code não vai te ajudar.
Q3: O LiteLLM realmente suporta o faturamento de prompt caching da Anthropic?
Sim. Desde 2025, o LiteLLM oferece suporte completo a cache_control: {"type": "ephemeral"}, injeção automática de pontos de cache (cache_control_injection_points), além do repasse de uso de cache_creation_input_tokens / cache_read_input_tokens e faturamento via completion_cost(). O bug de cálculo de custo mencionado na Issue #5443 foi corrigido, então você pode usar a versão atual com tranquilidade.
Q4: Quanto posso economizar usando o cache da Anthropic via LiteLLM?
Até ~90%. A regra de preço do prompt caching da Anthropic é: o preço de escrita em cache é cerca de 1,25x o input padrão, e o preço de leitura é cerca de 0,1x o input padrão. Em cenários com system prompts longos e repetitivos (como RAG, revisão de código ou agentes de fluxo longo), a economia real costuma ficar entre 50% e 90%. Se você se conectar via APIYI (apiyi.com), esse desconto de cache será refletido integralmente na sua fatura.
Q5: O desempenho cai se eu usar o Claude Code com o GPT-5 via LiteLLM?
Haverá diferenças, mas não necessariamente uma queda de qualidade. Os comandos (prompts) de uso de ferramentas do Claude Code são otimizados para o Claude; ao mudar para o GPT-5, o estilo de chamada de função e as ações de edição de arquivo podem variar um pouco. Recomendamos manter a família Claude como modelo principal e usar outros modelos como "inspiração/comparação". O mecanismo de fallback do LiteLLM permite que você faça o downgrade automático para o GPT-5 caso o Claude atinja o limite de taxa.
Q6: Como desenvolvedores podem usar Claude Code + LiteLLM + Anthropic Caching da melhor forma?
A solução mais pragmática é uma estrutura de três camadas: Claude Code (CLI) → LiteLLM Proxy (porta local 4000) → APIYI (apiyi.com) (serviço proxy de API). O Claude Code aponta para o LiteLLM via ANTHROPIC_BASE_URL, o LiteLLM configura o modelo no YAML como anthropic/claude-opus-4-6 e o api_base aponta para apiyi.com/v1. Assim, você obtém a experiência de codificação do Claude Code, aproveita a capacidade de roteamento do LiteLLM, resolve problemas de rede e faturamento via APIYI, e mantém o desconto do prompt caching.
Resumo
LiteLLM e Claude Code não são concorrentes, mas sim ferramentas em níveis de abstração diferentes: a "camada de gateway" e a "camada de aplicação". Forçar uma escolha entre os dois é um falso dilema; a pergunta correta deveria ser: qual combinação se adapta melhor ao seu cenário?
Voltando às duas perguntas iniciais deste artigo:
- Qual é melhor? — Depende do cenário. Use o Claude Code para codificação pessoal, o LiteLLM para desenvolvimento de aplicações e, se precisar de ambos, combine Claude Code + LiteLLM.
- O LiteLLM suporta cobrança de cache? — Sim, com suporte completo cobrindo os 6 principais provedores: Anthropic, OpenAI, Gemini, Vertex, Bedrock e DeepSeek, permitindo economizar até 90% nos custos de tokens de entrada.
🚀 Sugestão de ação: Se você deseja configurar hoje mesmo um fluxo de trabalho completo de "Claude Code + LiteLLM + Caching", o caminho mais rápido é: primeiro, registre-se no APIYI (apiyi.com) e obtenha uma chave API; segundo, configure um proxy local com o LiteLLM, apontando o
api_baseparaapiyi.com/v1; terceiro, configure a variávelANTHROPIC_BASE_URLno Claude Code para apontar para o seu LiteLLM local. Todo o fluxo pode ser configurado em menos de 10 minutos, permitindo que você aproveite imediatamente as vantagens de custo do prompt caching.
Autor: Equipe APIYI — Focada em fornecer acesso estável aos principais Modelos de Linguagem Grande para desenvolvedores. Visite apiyi.com para saber mais.
Referências
-
Documentação Oficial do LiteLLM – Prompt Caching
- Link:
docs.litellm.ai/docs/completion/prompt_caching - Descrição: Matriz de suporte a cache e exemplos de código para os 6 principais provedores.
- Link:
-
Documentação Oficial do LiteLLM – Auto-Inject Cache
- Link:
docs.litellm.ai/docs/tutorials/prompt_caching - Descrição: Injeção automática de
cache_control_injection_points.
- Link:
-
Documentação Oficial do LiteLLM – Claude Code Quickstart
- Link:
docs.litellm.ai/docs/tutorials/claude_responses_api - Descrição: Configuração de
ANTHROPIC_BASE_URLe suporte a 1M de janela de contexto.
- Link:
-
Documentação Oficial do LiteLLM – Provedor Anthropic
- Link:
docs.litellm.ai/docs/providers/anthropic - Descrição: Explicação dos campos
cache_creation_input_tokens/cache_read_input_tokens.
- Link:
-
GitHub Issue #5443 – Cálculo de Custo de Cache
- Link:
github.com/BerriAI/litellm/issues/5443 - Descrição: Histórico de correções de bugs relacionados à cobrança de cache.
- Link:
-
Repositório Principal do LiteLLM no GitHub
- Link:
github.com/BerriAI/litellm - Descrição: Código-fonte, Issues e versões mais recentes.
- Link: