LiteLLM과 Claude Code는 2025-2026년 가장 주목받는 AI 개발 도구이지만, 많은 개발자가 이 둘을 비교하며 혼란을 겪곤 합니다. "어떤 게 더 좋을까?", "서로 대체할 수 있을까?", "LiteLLM은 정말 프롬프트 캐싱 비용 처리를 지원할까?"와 같은 궁금증을 해결하기 위해, 본문에서는 LiteLLM과 Claude Code를 포지셔닝, 기능 범위, 그리고 캐싱 비용 지원이라는 세 가지 측면에서 명확히 비교해 드립니다.
핵심 가치: 이 글을 통해 두 도구가 정말로 "둘 중 하나를 선택해야 하는 관계"인지, 그리고 각 상황에서 어떤 도구를 선택하는 것이 최적인지 확실히 알게 되실 겁니다.

LiteLLM vs Claude Code 핵심 차이점 요약
많은 분들이 LiteLLM과 Claude Code를 경쟁 상대로 생각하지만, 사실 두 도구의 포지셔닝은 완전히 다르며 오히려 함께 사용할 때 더 큰 시너지를 냅니다. 한 문장으로 핵심 차이를 정리해 드릴게요.
- LiteLLM = LLM 게이트웨이 / API 중계 서비스, 하나의 코드로 100개 이상의 모델을 호출
- Claude Code = Anthropic 공식 에이전트형 코딩 CLI, "Claude를 활용해 코드베이스를 수정"하는 데 특화
| 비교 항목 | LiteLLM | Claude Code |
|---|---|---|
| 제품 형태 | Python SDK + Proxy 서버 | 명령줄 도구 (CLI) |
| 핵심 포지셔닝 | 범용 LLM 게이트웨이 / 모델 라우팅 | 에이전트형 코딩 어시스턴트 |
| 지원 모델 | 100개 이상 (OpenAI/Anthropic/Gemini/Bedrock/Vertex 등) | 기본적으로 Claude 시리즈만 지원 |
| 주요 사용자 | 플랫폼 엔지니어, AI 애플리케이션 개발자 | 개인 개발자, 코딩 작업자 |
| 오픈소스 여부 | ✅ 오픈소스 (BerriAI/litellm) | 비공개 CLI |
| 상호 대체 가능 여부 | ❌ 불가 | ❌ 불가 |
| 조합 사용 가능 여부 | ✅ 가능 (Claude Code 뒤에 LiteLLM 배치) | ✅ 가능 (LiteLLM으로 하위 모델 전환) |
| 최고의 파트너 | APIYI(apiyi.com)를 통한 안정적인 API 중계 | LiteLLM을 통한 모델 유연성 확보 |
💡 빠른 결론: "어떤 게 더 좋을까?"라는 고민이 든다면, 사실 둘 다 사용하는 것이 정답입니다. Claude Code를 코딩 에이전트로 활용하고, LiteLLM을 통합 입구로 삼아 APIYI(apiyi.com)를 통해 해외 모델을 연동하는 방식이 2026년 가장 주류가 되는 개발 스택입니다.
LiteLLM vs Claude Code 5가지 핵심 차이점
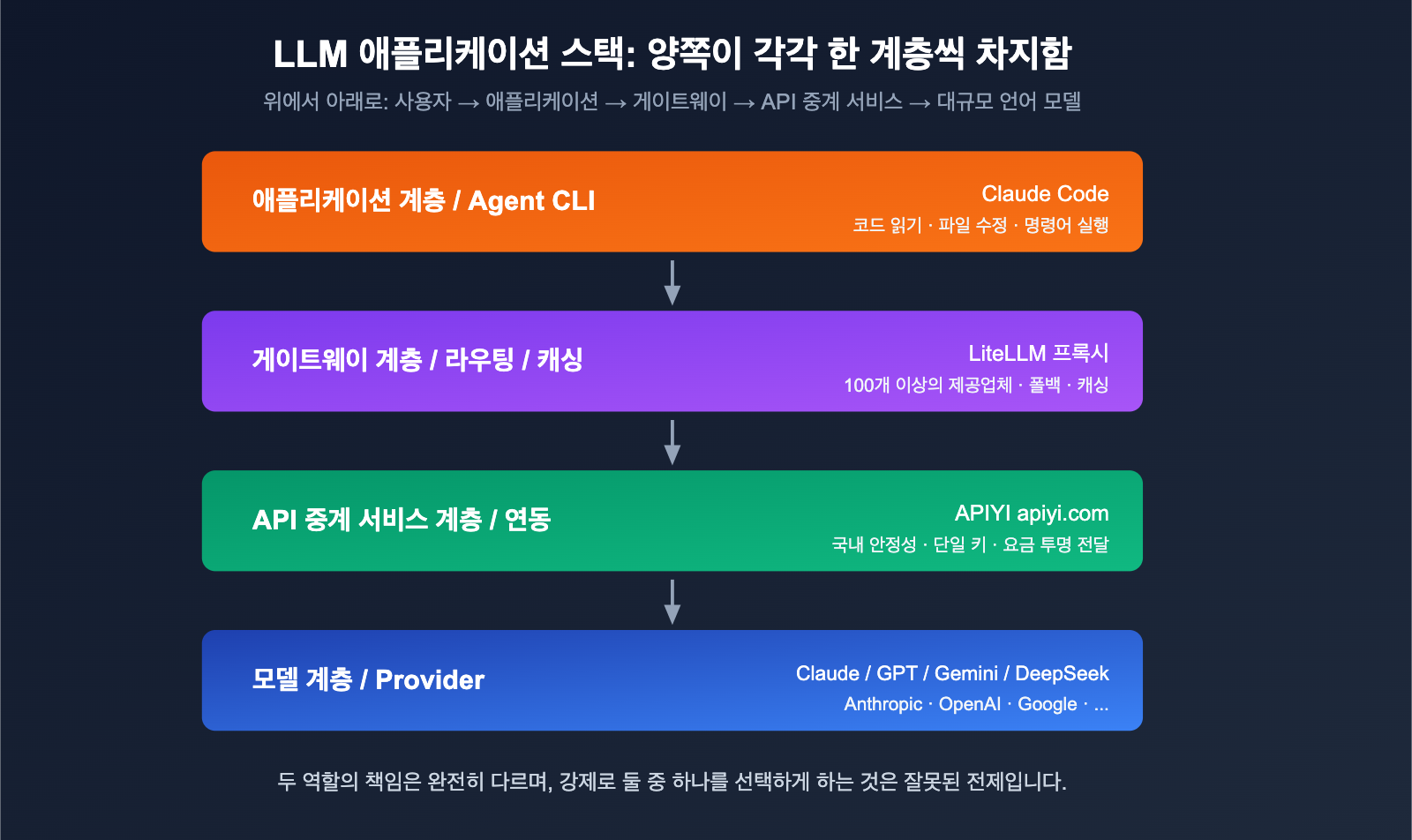
차이점 1: 포지셔닝의 차이 (게이트웨이 vs 에이전트 CLI)
LiteLLM의 포지셔닝: "OpenAI 호환 형식으로 모든 모델을 호출한다"는 목표를 가진 오픈소스 LLM 게이트웨이입니다. 두 가지 형태로 제공됩니다.
- Python SDK:
litellm.completion(model="...")형태로 개발자가 애플리케이션을 작성할 때 사용합니다. - Proxy 서버:
litellm --config config.yaml명령어로 독립적인 서비스를 실행하여 팀 단위로 공유합니다.
Claude Code의 포지셔닝: Anthropic이 공식 출시한 에이전트형 코딩 CLI입니다. "Claude가 터미널에서 직접 코드를 읽고, 수정하고, 명령어를 실행하게 한다"는 목표를 가집니다. 이는 애플리케이션 계층 제품이며, 내부적으로는 Anthropic의 Messages API를 호출합니다.
한마디로 요약하면: LiteLLM은 '수도관'이고, Claude Code는 '수도관에 연결된 수도꼭지'입니다.
차이점 2: 지원 모델 범위
| 구분 | LiteLLM | Claude Code |
|---|---|---|
| 기본 지원 | OpenAI, Anthropic, Google, Cohere, Bedrock, Azure, HuggingFace, Ollama, vLLM 등 100개 이상 | Anthropic Claude 시리즈 전용 (Opus / Sonnet / Haiku) |
| 사용자 정의 엔드포인트 | ✅ 모든 OpenAI 호환 엔드포인트 | ⚠️ ANTHROPIC_BASE_URL을 통해 LiteLLM 연결 가능 |
| 국산 모델 | ✅ DeepSeek / Qwen / Kimi / GLM 등 | ❌ 기본 지원 안 함 |
참고로 Claude Code도 ANTHROPIC_BASE_URL을 LiteLLM Proxy로 설정하면 다른 모델을 '간접적'으로 사용할 수 있지만, 이는 본질적으로 LiteLLM이 변환 작업을 수행하는 것이며, 두 도구가 상호 보완적인 관계임을 보여줍니다.
차이점 3: 사용자 인터페이스 및 개발 경험
LiteLLM의 개발 경험:
- 애플리케이션 개발자를 위한 SDK
- 모든 Python 프로젝트에 통합 가능
- 프론트엔드, Node.js, Curl 등을 위한 OpenAI 호환 HTTP 엔드포인트 제공
Claude Code의 개발 경험:
claude명령어와 유사한 독립형 CLI- 터미널에서 코드베이스와 직접 대화
- 파일 읽기/쓰기, Bash 실행, Git 등 도구 내장
- '생각하며 수정하는' 최적화된 도구 사용(Tool Use) 경험
차이점 4: 배포 및 운영 비용
| 항목 | LiteLLM | Claude Code |
|---|---|---|
| 설치 | pip install litellm |
npm i -g @anthropic-ai/claude-code |
| 서비스 필요 여부 | Proxy 모드 시 필요 | 불필요 (로컬 CLI) |
| YAML 설정 | Proxy 모드 시 필요 | 일반적으로 불필요 |
| 다수 공유 | ✅ Proxy 서비스로 팀 단위 공유 | ❌ 사용자별 CLI 설치 필요 |
| 비용 관리 | ✅ 게이트웨이 계층에서 통합 관리 | ❌ 계정별 개별 과금 |
차이점 5: 생태계 및 확장성
LiteLLM의 생태계:
- 로깅: Langfuse, Helicone, Sentry, OpenTelemetry
- 가드레일: 콘텐츠 필터링 내장
- 라우팅: 로드 밸런싱, Fallback, 속도 제한
- 비용 추적: 모델별, 사용자별, 키별 상세 관리
Claude Code의 생태계:
- 훅(Hooks): 사용자 정의 명령어 훅
- MCP: Model Context Protocol을 통한 외부 도구 연결
- IDE 통합: VS Code, JetBrains
- Anthropic의 도구 호출 능력과 긴밀한 결합
LiteLLM은 프롬프트 캐싱(Prompt Caching) 요금을 지원하나요?
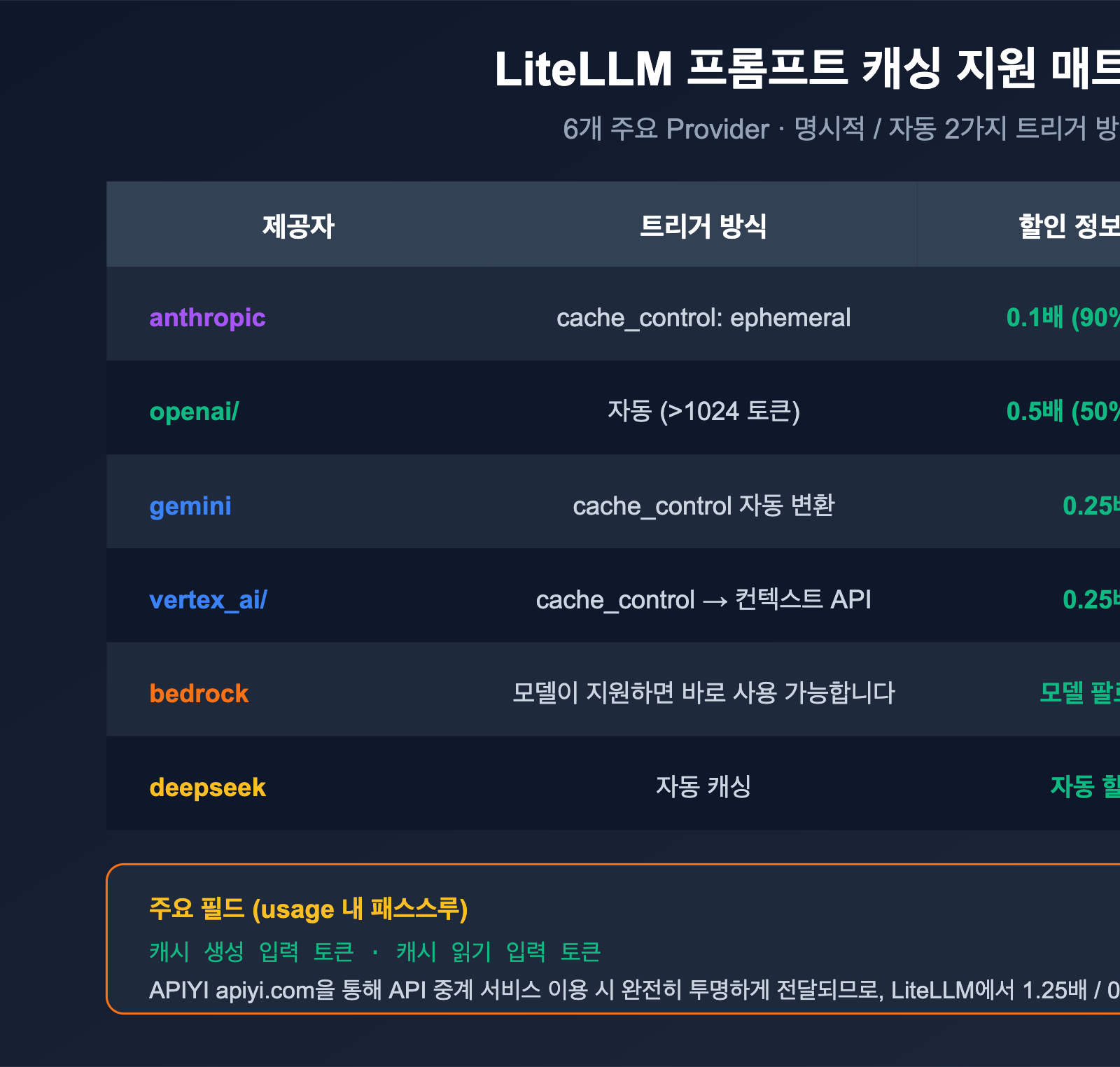
많은 개발자가 궁금해하는 부분입니다. 결론부터 말씀드리면: 지원하며, 매우 핵심적인 기능입니다.
지원 매트릭스
LiteLLM 공식 문서에 따르면, 프롬프트 캐싱은 다음 6개 공급자(Provider)에서 기본적으로 지원됩니다.
| 공급자 | LiteLLM 접두사 | 캐싱 트리거 방식 | 가격 혜택 |
|---|---|---|---|
| Anthropic | anthropic/ |
명시적 cache_control: {"type": "ephemeral"} |
쓰기 1.25배, 읽기 0.1배 (90% 할인) |
| OpenAI | openai/ |
자동 캐싱 (>1024 토큰) | 자동 50% 할인 |
| Google AI Studio | gemini/ |
명시적 cache_control |
Context Caching API로 자동 변환 |
| Vertex AI | vertex_ai/ |
명시적 cache_control |
위와 동일 |
| Bedrock | bedrock/ |
모델 지원 시 사용 가능 | 모델별 가격 정책 적용 |
| DeepSeek | deepseek/ |
자동 캐싱 | 자동 할인 |
코드 예시: Anthropic 캐싱
import litellm
response = litellm.completion(
model="anthropic/claude-opus-4-6",
messages=[
{
"role": "system",
"content": [
{
"type": "text",
"text": "당신은 숙련된 Python 엔지니어입니다... (긴 시스템 프롬프트)",
"cache_control": {"type": "ephemeral"}, # 핵심: 캐싱 대상 표시
}
],
},
{"role": "user", "content": "이 코드를 검토해주세요."},
],
)
# 캐시 사용량은 response.usage에서 확인 가능
print(response.usage)
# {
# "prompt_tokens": 1234,
# "cache_creation_input_tokens": 800, # 캐시에 기록된 토큰 수
# "cache_read_input_tokens": 0, # 두 번째 호출 시 800으로 변경됨
# "completion_tokens": 256,
# }
🎯 실전 팁: Anthropic의 프롬프트 캐싱은 긴 시스템 프롬프트나 반복되는 컨텍스트 환경에서 매우 경제적입니다. 캐시 읽기 비용이 원가의 10%에 불과하기 때문이죠. 긴 흐름의 에이전트, RAG(검색 증강 생성), 코드 리뷰 등의 시나리오에서 기본적으로 활성화하는 것을 권장합니다. 국내에서 Claude Opus 4.6 / Sonnet 4.6을 안정적으로 호출하면서 프롬프트 캐싱 할인을 누리고 싶다면, APIYI(apiyi.com)를 통해 접속하세요. 플랫폼에서 캐싱 관련 usage 필드를 완벽하게 전달합니다.
자동 캐시 제어 (Auto-Inject Cache Control)
매번 메시지에 cache_control을 수동으로 추가하기 번거롭다면, LiteLLM의 자동 주입 기능을 사용해 보세요.
response = litellm.completion(
model="anthropic/claude-opus-4-6",
messages=[...],
cache_control_injection_points=[
{"location": "message", "role": "system"} # 모든 시스템 메시지에 자동으로 캐싱 적용
],
)
기존 코드를 수정할 필요 없이 메시지 구조를 그대로 유지하면서 90% 캐싱 할인을 받을 수 있어 매우 편리합니다.
캐시 요금 관련 주의사항 및 현황
LiteLLM 초기 버전(2024년)에는 cache_creation_input_tokens와 cache_read_input_tokens를 제대로 구분하지 못해 요금 계산에 오류가 발생하는 버그(GitHub Issue #5443)가 있었으나, 2025-2026년 버전에서는 공식적으로 수정되었습니다. 현재 LiteLLM의 completion_cost() 함수는 다음 규칙에 따라 계산합니다.
| 토큰 유형 | 가격 배율 (입력 가격 대비) | 설명 |
|---|---|---|
| 캐시 쓰기 | 1.25배 | 캐시 기록 시 약간의 추가 비용 발생 |
| 캐시 읽기 | 0.1배 | 캐시 읽기 시 원가의 10%만 부과 |
| 일반 입력 | 1.0배 | 표준 입력 |
| 출력 | 모델별 상이 | 출력 토큰 |
🛡️ 중요: API 중계 서비스를 이용 중이라면, 해당 서비스가
cache_creation_input_tokens와cache_read_input_tokens필드를 누락 없이 전달하는지 확인하세요. 그렇지 않으면 LiteLLM이 일반 입력으로 간주하여 요금을 계산합니다. APIYI(apiyi.com)는 이 필드들을 완벽하게 지원하므로, LiteLLM과 함께 사용 시 실제 캐싱 할인을 온전히 누릴 수 있습니다.
시나리오별 추천: LiteLLM과 Claude Code, 언제 무엇을 써야 할까?

시나리오 1: 코딩이 주 업무인 개인 개발자
추천: Claude Code를 바로 사용하세요.
이유는 간단합니다. 코딩 영역에서 Claude의 경험은 여전히 최상위권입니다. 도구 사용(Tool Use)이 안정적이고, 파일 수정이 정확하며, 컨텍스트 관리도 훌륭하죠. 혼자 작업하면서 모델을 자주 바꿀 필요가 없다면 Claude Code가 가장 속 편한 선택입니다. 만약 국내에서 Anthropic 공식 API 접속이 어렵다면, ANTHROPIC_BASE_URL을 APIYI(apiyi.com) 중계 서비스로 설정하세요. 동일한 경험을 누릴 수 있습니다.
시나리오 2: AI 애플리케이션을 구축하는 팀
추천: LiteLLM Proxy + 애플리케이션 코드
이유: 여러분에게 필요한 것은 '통합 과금 + 멀티 모델 라우팅 + 폴백(Fallback)'이며, 이것이 바로 LiteLLM Proxy의 핵심 기능이기 때문입니다. Claude Code는 CLI 도구일 뿐, 애플리케이션 계층의 게이트웨이 역할을 수행할 수는 없습니다.
모범 사례:
- LiteLLM Proxy를 독립적인 서비스로 실행(포트 4000)
- 모든 하위 모델을 APIYI(apiyi.com)를 통해 통합 연결
- 애플리케이션 계층에서는 LiteLLM Proxy만 호출하며, 내부적으로는 의미론적 모델명을 사용
시나리오 3: Claude Code의 경험과 모델 전환의 자유를 모두 원할 때
추천: Claude Code + LiteLLM 조합
가장 강력한 조합입니다. 설정도 매우 간단하죠.
# LiteLLM Proxy 실행 (여러 모델 연결)
litellm --config litellm_config.yaml --port 4000
# Claude Code가 LiteLLM을 거치도록 설정
export ANTHROPIC_BASE_URL=http://localhost:4000
export ANTHROPIC_AUTH_TOKEN=sk-litellm-master-xxxx
# 원하는 모델로 Claude Code 실행
claude --model claude-opus-4-6
claude --model gpt-5 # 동일한 CLI, 뒷단은 GPT-5
claude --model gemini-3-pro # 동일한 CLI, 뒷단은 Gemini 3 Pro
💡 조합의 가치: Claude Code는 최고의 코딩 에이전트 경험을 제공하고, LiteLLM은 모델 선택의 자유를, APIYI(apiyi.com)는 안정적인 국내 중계 서비스를 제공합니다. 각자의 역할에 충실한 이 조합은 2026년 가장 실용적인 '풀스택 AI 코딩' 솔루션입니다.
시나리오 4: 기업용 프로덕션 배포
추천: LiteLLM Proxy + Langfuse + APIYI
기업 환경에서 Claude Code는 개발자의 로컬 도구로만 사용하고, 실제 프로덕션 트래픽에는 다음 구성이 필요합니다.
- LiteLLM Proxy: 게이트웨이 + 속도 제한 + 폴백(Fallback)
- Langfuse / Helicone: 로깅 및 비용 분석
- APIYI(apiyi.com): 하위 모델 연결 및 안정성 보장
LiteLLM vs Claude Code 결정 가이드
아래의 결정 표를 확인하시면 30초 안에 어떤 도구를 선택할지 바로 결정하실 수 있습니다.
| 요구 사항 | 추천 솔루션 |
|---|---|
| 터미널에서 AI가 코드를 수정하게 하고 싶다 | Claude Code |
| Python 앱에서 여러 모델을 호출하고 싶다 | LiteLLM SDK |
| 팀 내에서 통합 LLM 입구가 필요하다 | LiteLLM Proxy |
| Claude Code의 기본 모델을 교체하고 싶다 | Claude Code + LiteLLM |
| 운영 환경 수준의 LLM 게이트웨이를 구축하고 싶다 | LiteLLM Proxy + 모니터링 |
| 국내에서 해외 모델 접속이 불안정하다 | 어느 것이든 + APIYI apiyi.com 중계 |
| Anthropic의 토큰 비용을 절약하고 싶다 | LiteLLM + 프롬프트 캐싱 |
🚀 통합 제안: 어떤 도구를 선택하든 APIYI apiyi.com을 기본 API로 연결하는 것이 가장 안정적입니다. LiteLLM은
api_base를 통해 apiyi.com/v1으로 직접 연결할 수 있으며, Claude Code는ANTHROPIC_BASE_URL을 통해 LiteLLM을 거쳐 apiyi.com으로 연결할 수 있습니다. 두 경로 모두 수많은 개발자를 통해 안정성이 검증되었습니다.
LiteLLM vs Claude Code 자주 묻는 질문(FAQ)
Q1: LiteLLM이 Claude Code를 완전히 대체할 수 있나요?
아니요. LiteLLM은 LLM 게이트웨이일 뿐, Claude Code가 가진 "코드베이스 읽기 + 스스로 파일 수정 + Bash 실행"과 같은 에이전트 도구 체인이 없습니다. 두 도구는 해결하는 영역이 다릅니다. LiteLLM으로 Claude Code를 대체하려는 것은 "수도관 공장"으로 "커피 머신"을 대신하려는 것과 같습니다.
Q2: Claude Code가 LiteLLM을 완전히 대체할 수 있나요?
역시 불가능합니다. Claude Code는 CLI 도구이지 게이트웨이가 아닙니다. model_list, router_settings, fallbacks와 같은 게이트웨이 수준의 개념이 없으며, Python 애플리케이션이나 웹 서비스에서 직접 호출할 수도 없습니다. "애플리케이션 수준의 AI 통합"을 원하신다면 Claude Code로는 부족합니다.
Q3: LiteLLM이 Anthropic의 프롬프트 캐싱 과금을 정말 지원하나요?
네, 그렇습니다. LiteLLM은 2025년부터 cache_control: {"type": "ephemeral"}을 완벽하게 지원하며, 자동 캐시 포인트 주입(cache_control_injection_points), cache_creation_input_tokens / cache_read_input_tokens의 사용량 전달 및 completion_cost() 비용 계산까지 모두 지원합니다. 초기 Issue #5443에서 언급된 비용 계산 버그는 이미 수정되었으니 안심하고 사용하셔도 됩니다.
Q4: LiteLLM을 통해 Anthropic 캐싱을 사용하면 비용을 얼마나 절약할 수 있나요?
최대 약 90%까지 절약할 수 있습니다. Anthropic의 프롬프트 캐싱 가격 정책은 캐시 쓰기 비용이 표준 입력의 약 1.25배, 캐시 읽기 비용이 표준 입력의 약 0.1배입니다. RAG, 코드 리뷰, 긴 흐름의 에이전트와 같이 긴 시스템 프롬프트를 반복적으로 사용하는 환경에서는 보통 50~90%의 비용 절감 효과를 볼 수 있습니다. APIYI apiyi.com을 통해 접속하면 이러한 캐시 할인 혜택이 청구서에 그대로 반영됩니다.
Q5: Claude Code를 LiteLLM으로 GPT-5에 연결하면 성능이 떨어지나요?
차이는 있을 수 있지만, 반드시 성능이 떨어진다고 볼 수는 없습니다. Claude Code의 도구 사용(Tool Use) 프롬프트는 Claude에 최적화되어 있어, GPT-5로 전환 시 함수 호출 방식이나 파일 편집 동작이 약간 다를 수 있습니다. Claude 시리즈를 주력 모델로 사용하고, 다른 모델은 "영감/비교용" 보조 모델로 활용하는 것을 추천합니다. LiteLLM의 Fallback 메커니즘을 사용하면 Claude의 속도 제한 시 자동으로 GPT-5로 전환할 수 있습니다.
Q6: 국내 개발자가 Claude Code + LiteLLM + Anthropic Caching을 모두 잘 활용하려면 어떻게 해야 하나요?
가장 현실적인 방법은 3단계 구조입니다: Claude Code (CLI) → LiteLLM Proxy (로컬 4000 포트) → APIYI apiyi.com (중계). Claude Code의 ANTHROPIC_BASE_URL을 LiteLLM으로 설정하고, LiteLLM의 YAML 설정에서 모델을 anthropic/claude-opus-4-6으로, api_base를 apiyi.com/v1으로 지정하세요. 이렇게 하면 Claude Code의 코딩 경험을 누리면서 LiteLLM의 라우팅 능력을 활용할 수 있고, APIYI를 통해 네트워크 및 결제 문제를 해결하며 프롬프트 캐싱 할인까지 모두 챙길 수 있습니다.
요약
LiteLLM과 Claude Code는 경쟁 관계가 아니라, 각각 '게이트웨이 계층'과 '애플리케이션 계층'이라는 서로 다른 추상화 수준을 가진 도구입니다. 둘 중 하나를 억지로 선택해야 한다는 것은 잘못된 전제이며, 올바른 질문은 **"내 상황에 어떤 조합이 적합한가?"**입니다.
글 서두에서 던졌던 두 가지 질문으로 돌아가 보겠습니다.
- 무엇이 더 좋은가요? —— 상황에 따라 다릅니다. 개인 코딩에는 Claude Code를, 애플리케이션 개발에는 LiteLLM을 추천하며, 둘 다 필요하다면 Claude Code + LiteLLM 조합을 사용하세요.
- LiteLLM은 캐시 비용 계산을 지원하나요? —— 네, 완벽하게 지원합니다. Anthropic, OpenAI, Gemini, Vertex, Bedrock, DeepSeek 등 6대 주요 제공업체를 모두 지원하며, 입력 토큰 비용을 최대 90%까지 절감할 수 있습니다.
🚀 실행 가이드: 오늘 바로 "Claude Code + LiteLLM + Caching" 워크플로우를 구축하고 싶다면 가장 빠른 방법은 다음과 같습니다. 첫째, APIYI(apiyi.com)에 가입하여 키를 발급받으세요. 둘째, LiteLLM으로 로컬 프록시를 설정하고
api_base를apiyi.com/v1으로 지정하세요. 셋째, Claude Code에서ANTHROPIC_BASE_URL을 로컬 LiteLLM으로 설정하세요. 전체 과정을 10분 안에 완료할 수 있으며, 즉시 프롬프트 캐싱(prompt caching)을 통한 비용 절감 혜택을 누릴 수 있습니다.
저자: APIYI Team — 개발자들에게 주요 AI 대규모 언어 모델의 안정적인 연결을 제공합니다. 자세한 내용은 apiyi.com을 방문해 확인하세요.
참고 자료
-
LiteLLM 공식 문서 – 프롬프트 캐싱
- 링크:
docs.litellm.ai/docs/completion/prompt_caching - 설명: 6대 제공업체의 캐시 지원 매트릭스 및 코드 예제
- 링크:
-
LiteLLM 공식 문서 – 자동 캐시 주입(Auto-Inject Cache)
- 링크:
docs.litellm.ai/docs/tutorials/prompt_caching - 설명:
cache_control_injection_points를 통한 자동 주입
- 링크:
-
LiteLLM 공식 문서 – Claude Code 퀵스타트
- 링크:
docs.litellm.ai/docs/tutorials/claude_responses_api - 설명:
ANTHROPIC_BASE_URL설정 및 1M 컨텍스트 윈도우 지원
- 링크:
-
LiteLLM 공식 문서 – Anthropic 제공업체
- 링크:
docs.litellm.ai/docs/providers/anthropic - 설명:
cache_creation_input_tokens/cache_read_input_tokens필드 설명
- 링크:
-
GitHub Issue #5443 – 캐시 비용 계산
- 링크:
github.com/BerriAI/litellm/issues/5443 - 설명: 초기 캐시 비용 계산 버그 및 수정 이력
- 링크:
-
LiteLLM GitHub 메인 저장소
- 링크:
github.com/BerriAI/litellm - 설명: 소스 코드, 이슈 및 최신 버전 정보
- 링크: