LiteLLM 和 Claude Code 都是 2025-2026 年最熱門的 AI 開發工具,但它們經常被開發者放在一起比較:哪個更好用?能不能互相替代?LiteLLM 到底支不支持 prompt caching 緩存計費?本文對比 LiteLLM 和 Claude Code,從定位、能力邊界和緩存計費支持三個維度給出明確建議。
核心價值: 看完本文,你將明確這兩個工具是否真的"二選一",以及如何在不同場景下做出最優選擇。

LiteLLM vs Claude Code 核心差異速覽
很多人把 LiteLLM 和 Claude Code 當成競品,但其實它們的定位完全不同,甚至可以組合使用。一句話理解兩者的本質區別:
- LiteLLM = LLM 網關 / 中轉層,讓一份代碼調用 100+ 家模型
- Claude Code = Anthropic 官方的 Agentic 編碼 CLI,專注"用 Claude 改你的代碼庫"
| 對比維度 | LiteLLM | Claude Code |
|---|---|---|
| 產品形態 | Python SDK + Proxy 服務器 | 命令行工具 (CLI) |
| 核心定位 | 通用 LLM 網關 / 模型路由 | Agentic 編碼助手 |
| 支持模型 | 100+ 家 (OpenAI/Anthropic/Gemini/Bedrock/Vertex 等) | 默認僅 Claude 系列 |
| 典型用戶 | 平臺工程師、AI 應用開發者 | 個人開發者、編碼場景 |
| 是否開源 | ✅ 開源 (BerriAI/litellm) | 閉源 CLI |
| 能不能互相替代 | ❌ 不能 | ❌ 不能 |
| 能不能組合使用 | ✅ 可以 (LiteLLM 在 Claude Code 後面) | ✅ 可以 |
| 最適合的搭檔 | 配合 API易 apiyi.com 提供穩定中轉 | 配合 LiteLLM 切換底層模型 |
💡 快速結論: 如果你在問"哪個更好用",那大概率你需要的是兩個都用 —— Claude Code 當編碼 Agent,LiteLLM 當統一入口,再通過 API易 apiyi.com 接入海外模型。這纔是 2026 年最主流的棧。
LiteLLM vs Claude Code 五大核心差異

差異 1: 定位完全不同 (網關 vs Agent CLI)
LiteLLM 的定位: 一個開源的 LLM 網關,目標是"用 OpenAI 兼容格式調用任何模型"。它有兩種形態:
- Python SDK:
litellm.completion(model="..."),給開發者寫應用用 - Proxy 服務器:
litellm --config config.yaml,跑成一個獨立服務,團隊共享
Claude Code 的定位: Anthropic 官方推出的 Agentic 編碼 CLI,目標是"讓 Claude 直接在你的終端裏讀你的代碼、改你的代碼、跑你的命令"。它是一個應用層產品,下面調用的是 Anthropic 的 Messages API。
一句話:LiteLLM 是"水管",Claude Code 是"裝在水管上的水龍頭"。
差異 2: 支持的模型範圍
| 維度 | LiteLLM | Claude Code |
|---|---|---|
| 默認支持 | OpenAI, Anthropic, Google, Cohere, Bedrock, Azure, HuggingFace, Ollama, vLLM 等 100+ | 僅 Anthropic Claude 系列 (Opus / Sonnet / Haiku) |
| 自定義端點 | ✅ 任意 OpenAI 兼容端點 | ⚠️ 通過 ANTHROPIC_BASE_URL 接到 LiteLLM |
| 國產模型 | ✅ DeepSeek / Qwen / Kimi / GLM 等 | ❌ 默認不支持 |
注意 Claude Code 也可以通過設置 ANTHROPIC_BASE_URL 指向 LiteLLM Proxy 來"間接"使用其他模型,但這本質上是 LiteLLM 在做翻譯工作 —— 這恰恰證明了兩者是互補關係。
差異 3: 使用界面與開發體驗
LiteLLM 的開發體驗:
- 給應用開發者寫代碼用的 SDK
- 可以集成到任何 Python 項目裏
- 提供 OpenAI 兼容的 HTTP 端點,給前端、Node.js、Curl 用
Claude Code 的開發體驗:
- 一個獨立的 CLI,類似
claude命令 - 直接在終端裏和你的代碼庫對話
- 自帶文件讀寫、Bash 執行、Git 等工具
- 優化的 Tool Use 體驗,"邊想邊改"
差異 4: 部署與運維成本
| 項目 | LiteLLM | Claude Code |
|---|---|---|
| 安裝 | pip install litellm |
npm i -g @anthropic-ai/claude-code |
| 是否需要服務 | Proxy 模式需要 | 否,本地 CLI |
| 是否需要 YAML 配置 | Proxy 模式需要 | 一般不需要 |
| 多人共享 | ✅ 一個 Proxy 服務團隊共享 | ❌ 每人一份 CLI |
| 計費集中 | ✅ 網關層統一計費 | ❌ 各賬號各計費 |
差異 5: 生態與擴展能力
LiteLLM 的生態:
- Logging: Langfuse、Helicone、Sentry、OpenTelemetry
- Guardrails: 內置內容審覈
- Routing: 負載均衡、Fallback、限速
- Cost tracking: 多模型、多用戶、多 Key 維度
Claude Code 的生態:
- Hooks: 自定義命令鉤子
- MCP: 通過 Model Context Protocol 接入外部工具
- IDE 集成: VS Code、JetBrains
- 緊密綁定 Anthropic 的工具調用能力
LiteLLM 是否支持 Prompt Caching 緩存計費?
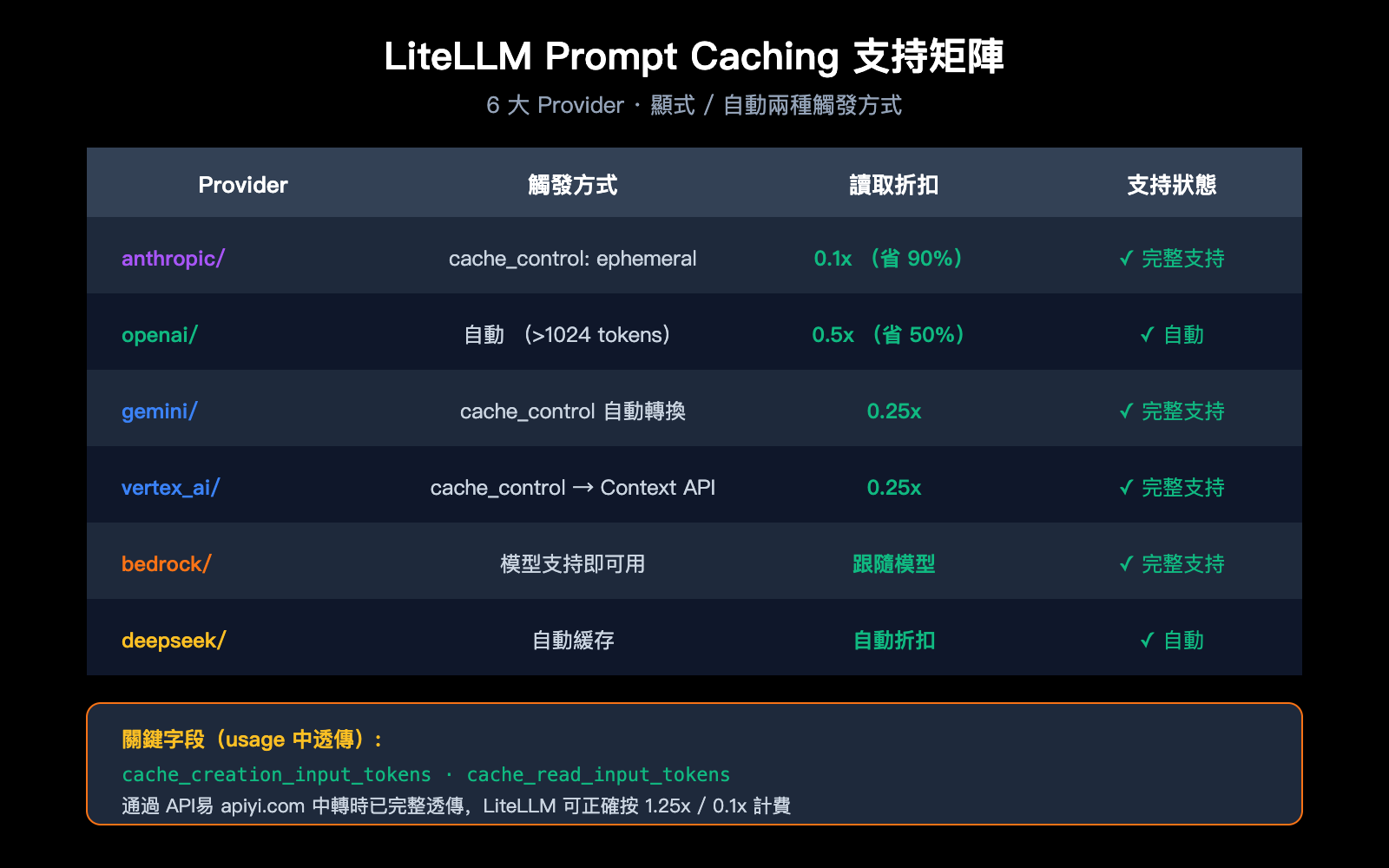
這是開發者最關心的一個問題。直接結論:支持,而且是一等公民。
支持矩陣
LiteLLM 官方文檔明確列出,prompt caching 在以下 6 大 provider 上原生支持:
| Provider | LiteLLM 前綴 | 緩存觸發方式 | 價格優勢 |
|---|---|---|---|
| Anthropic | anthropic/ |
顯式 cache_control: {"type": "ephemeral"} |
寫入 1.25x,讀取 0.1x (90% 折扣) |
| OpenAI | openai/ |
自動緩存 (>1024 tokens) | 自動 50% 折扣 |
| Google AI Studio | gemini/ |
顯式 cache_control |
自動轉換到 Context Caching API |
| Vertex AI | vertex_ai/ |
顯式 cache_control |
同上 |
| Bedrock | bedrock/ |
模型支持即可用 | 跟隨模型定價 |
| DeepSeek | deepseek/ |
自動緩存 | 自動折扣 |
代碼示例:Anthropic 緩存
import litellm
response = litellm.completion(
model="anthropic/claude-opus-4-6",
messages=[
{
"role": "system",
"content": [
{
"type": "text",
"text": "你是一個資深 Python 工程師...(長 system prompt)",
"cache_control": {"type": "ephemeral"}, # 關鍵:標記需緩存
}
],
},
{"role": "user", "content": "請審查這段代碼"},
],
)
# 緩存使用量在 response.usage 中可見
print(response.usage)
# {
# "prompt_tokens": 1234,
# "cache_creation_input_tokens": 800, # 寫入緩存的 token 數
# "cache_read_input_tokens": 0, # 第二次調用會變成 800
# "completion_tokens": 256,
# }
🎯 實戰建議: Anthropic 的 prompt caching 在長 system prompt 和重複上下文場景下極其划算 —— 緩存讀取只要原價的 10%。我們建議在長流程 Agent、RAG 檢索增強、代碼審查等場景下默認開啓。如果你希望在國內穩定調用 Claude Opus 4.6 / Sonnet 4.6 並享受 prompt caching 折扣,可以通過 API易 apiyi.com 接入,平臺完整透傳緩存相關的 usage 字段。
Auto-Inject Cache Control(自動緩存)
如果不想手動給每條消息加 cache_control,LiteLLM 還提供自動注入:
response = litellm.completion(
model="anthropic/claude-opus-4-6",
messages=[...],
cache_control_injection_points=[
{"location": "message", "role": "system"} # 自動給所有 system 消息打緩存
],
)
這對接入老代碼非常友好 —— 無需修改 messages 結構,就能享受 90% 緩存摺扣。
緩存計費的"坑"與現狀
LiteLLM 早期(2024 年)確實有過一個 bug(GitHub Issue #5443):cost tracking 沒有正確區分 cache_creation_input_tokens 和 cache_read_input_tokens,導致計費偏差。但在 2025-2026 年的版本中,官方已修復。當前 LiteLLM 在 completion_cost() 函數中按以下規則計費:
| Token 類型 | 價格倍率 (相對 input price) | 說明 |
|---|---|---|
| Cache Write | 1.25x | 寫入緩存有少量額外開銷 |
| Cache Read | 0.1x | 讀取緩存僅需 10% 價格 |
| 普通 Input | 1.0x | 標準輸入 |
| Output | 由模型自定 | 輸出 token |
🛡️ 重要提示: 如果你通過中轉站調用,請確認中轉站完整透傳了
cache_creation_input_tokens和cache_read_input_tokens字段,否則 LiteLLM 在計費時會按普通 input 計算。API易 apiyi.com 已完整支持這兩個字段的透傳,配合 LiteLLM 即可獲得真實的緩存摺扣。
場景推薦:什麼時候用 LiteLLM,什麼時候用 Claude Code

場景 1: 個人開發者,主要做編碼
推薦: 直接用 Claude Code
理由很簡單 —— Claude 在編碼場景上的體驗目前仍是第一梯隊,Tool Use 穩、文件改動準、上下文管理好。如果你是單兵作戰、不需要切換模型,Claude Code 就是最省心的選擇。如果在國內訪問 Anthropic 官方有困難,可以把 ANTHROPIC_BASE_URL 指向 API易 apiyi.com 中轉,體驗完全一致。
場景 2: 團隊搭建 AI 應用
推薦: LiteLLM Proxy + 應用代碼
理由:你需要的是"統一計費 + 多模型路由 + Fallback",這正是 LiteLLM Proxy 的核心能力。Claude Code 是 CLI 工具,無法承擔應用層網關角色。
最佳實踐:
- 用 LiteLLM Proxy 跑一個獨立服務(端口 4000)
- 所有底層模型通過 API易 apiyi.com 統一接入
- 應用層只調用 LiteLLM Proxy,看到的都是語義化模型名
場景 3: 既要 Claude Code 體驗,又要切換模型
推薦: Claude Code + LiteLLM 組合
這是最強大的組合。配置非常簡單:
# 啓動 LiteLLM Proxy(指向多家模型)
litellm --config litellm_config.yaml --port 4000
# 讓 Claude Code 走 LiteLLM
export ANTHROPIC_BASE_URL=http://localhost:4000
export ANTHROPIC_AUTH_TOKEN=sk-litellm-master-xxxx
# 用任意模型啓動 Claude Code
claude --model claude-opus-4-6
claude --model gpt-5 # 同一個 CLI,背後是 GPT-5
claude --model gemini-3-pro # 同一個 CLI,背後是 Gemini 3 Pro
💡 組合價值: Claude Code 提供頂級的編碼 Agent 體驗,LiteLLM 提供模型自由度,API易 apiyi.com 提供穩定的國內中轉。三者各司其職、互不干擾,是 2026 年最務實的"全棧 AI 編碼"方案。
場景 4: 企業級生產部署
推薦: LiteLLM Proxy + Langfuse + API易
企業場景下,Claude Code 僅作爲開發者本地工具使用,真正的生產流量需要:
- LiteLLM Proxy 做網關 + 限速 + Fallback
- Langfuse / Helicone 做 Logging 和成本分析
- API易 apiyi.com 做底層模型接入和穩定性保障
LiteLLM vs Claude Code 決策建議
下面這張決策表可以幫你 30 秒做出選擇。
| 你的需求 | 推薦方案 |
|---|---|
| 我想在終端裏讓 AI 改代碼 | Claude Code |
| 我想在 Python 應用裏調用多家模型 | LiteLLM SDK |
| 我團隊需要一個統一 LLM 入口 | LiteLLM Proxy |
| 我要給 Claude Code 切換底層模型 | Claude Code + LiteLLM |
| 我要做生產級 LLM 網關 | LiteLLM Proxy + 監控 |
| 我在國內訪問海外模型不穩定 | 任選 + API易 apiyi.com 中轉 |
| 我希望省 Anthropic 的 token 錢 | LiteLLM + prompt caching |
🚀 統一建議: 無論你選擇哪個工具,底層接入 API易 apiyi.com 都是穩定性最高的選項。LiteLLM 可以通過
api_base直接指向 apiyi.com/v1,Claude Code 可以通過ANTHROPIC_BASE_URL間接走 LiteLLM 再到 apiyi.com,兩條路徑都已被大量開發者驗證爲穩定可用。
LiteLLM vs Claude Code 常見問題
Q1: LiteLLM 能完全替代 Claude Code 嗎?
不能。LiteLLM 是 LLM 網關,沒有 Claude Code 的"讀你代碼庫 + 自主改文件 + 跑 Bash"那套 Agent 工具鏈。兩者解決的是不同層面的問題,用 LiteLLM 替代 Claude Code 就像用"水管廠"替代"咖啡機"。
Q2: Claude Code 能完全替代 LiteLLM 嗎?
也不能。Claude Code 是 CLI 工具,不是網關。它沒有 model_list、router_settings、fallbacks 這些網關層概念,也無法被你的 Python 應用或 Web 服務直接調用。如果你要做"應用層的 AI 集成",Claude Code 幫不到你。
Q3: LiteLLM 真的支持 Anthropic 的 prompt caching 計費嗎?
是的。LiteLLM 在 2025 年起完整支持 cache_control: {"type": "ephemeral"}、自動注入緩存點 cache_control_injection_points、以及 cache_creation_input_tokens / cache_read_input_tokens 的 usage 透傳和 completion_cost() 計費。早期 Issue #5443 提到的成本計算 bug 已經修復,當前版本可以放心使用。
Q4: 通過 LiteLLM 調用 Anthropic 緩存,能省多少錢?
最高可省 ~90%。Anthropic 的 prompt caching 價格規則是:cache write 價格約爲標準 input 的 1.25x,cache read 價格約爲標準 input 的 0.1x。在長 system prompt 反覆使用的場景(比如 RAG、代碼審查、長流程 Agent),實際節省通常在 50-90% 之間。如果你通過 API易 apiyi.com 接入,這部分緩存摺扣會完整體現到你的賬單上。
Q5: Claude Code 用 LiteLLM 接到 GPT-5 後,效果會變差嗎?
會有差異,但不一定變差。Claude Code 的 Tool Use 提示詞是針對 Claude 優化的,切換到 GPT-5 後函數調用風格、文件編輯動作可能略有不同。建議把 Claude 系列作爲主力模型,把其他模型作爲"靈感/對比"備用。LiteLLM 的 Fallback 機制可以讓你在 Claude 限流時自動降級到 GPT-5。
Q6: 國內開發者如何同時用好 Claude Code + LiteLLM + Anthropic Caching?
最務實的方案是三層結構: Claude Code (CLI) → LiteLLM Proxy (本地 4000 端口) → API易 apiyi.com (中轉)。Claude Code 通過 ANTHROPIC_BASE_URL 指向 LiteLLM,LiteLLM 在 YAML 裏把 model 配置成 anthropic/claude-opus-4-6,api_base 指向 apiyi.com/v1。這樣既能用 Claude Code 的編碼體驗,又能享受 LiteLLM 的路由能力,還能通過 API易 解決網絡與計費問題,並完整保留 prompt caching 折扣。
總結
LiteLLM 和 Claude Code 不是競品,而是"網關層"和"應用層"兩個不同抽象層次的工具。強行二選一是個僞命題,正確的問題應該是:你的場景適合哪種組合?
回到本文最初的兩個問題:
- 哪個更好用? —— 取決於場景。個人編碼用 Claude Code,應用開發用 LiteLLM,要兼顧兩者就用 Claude Code + LiteLLM 組合
- LiteLLM 支持緩存計費嗎? —— 完整支持,覆蓋 Anthropic、OpenAI、Gemini、Vertex、Bedrock、DeepSeek 6 大 provider,最高可省 90% 輸入 token 成本
🚀 行動建議: 如果你今天就想搭建一套"Claude Code + LiteLLM + Caching"的完整工作流,最快的路徑是: 第一步在 API易 apiyi.com 註冊並獲取一個 Key;第二步用 LiteLLM 搭建本地 Proxy,把 api_base 指向 apiyi.com/v1;第三步在 Claude Code 裏設置 ANTHROPIC_BASE_URL 指向本地 LiteLLM。整套鏈路 10 分鐘內即可跑通,並可立即享受 prompt caching 帶來的成本優勢。
作者: APIYI Team — 專注於爲開發者提供主流 AI 大模型的穩定接入,訪問 apiyi.com 瞭解更多。
參考資料
-
LiteLLM 官方文檔 – Prompt Caching
- 鏈接:
docs.litellm.ai/docs/completion/prompt_caching - 說明: 6 大 provider 的緩存支持矩陣和代碼示例
- 鏈接:
-
LiteLLM 官方文檔 – Auto-Inject Cache
- 鏈接:
docs.litellm.ai/docs/tutorials/prompt_caching - 說明: cache_control_injection_points 自動注入
- 鏈接:
-
LiteLLM 官方文檔 – Claude Code Quickstart
- 鏈接:
docs.litellm.ai/docs/tutorials/claude_responses_api - 說明: ANTHROPIC_BASE_URL 配置和 1M context 支持
- 鏈接:
-
LiteLLM 官方文檔 – Anthropic Provider
- 鏈接:
docs.litellm.ai/docs/providers/anthropic - 說明: cache_creation_input_tokens / cache_read_input_tokens 字段說明
- 鏈接:
-
GitHub Issue #5443 – Cache Cost Calculation
- 鏈接:
github.com/BerriAI/litellm/issues/5443 - 說明: 早期緩存計費 bug 與修復歷史
- 鏈接:
-
LiteLLM GitHub 主倉庫
- 鏈接:
github.com/BerriAI/litellm - 說明: 源碼、Issue 與最新版本
- 鏈接: