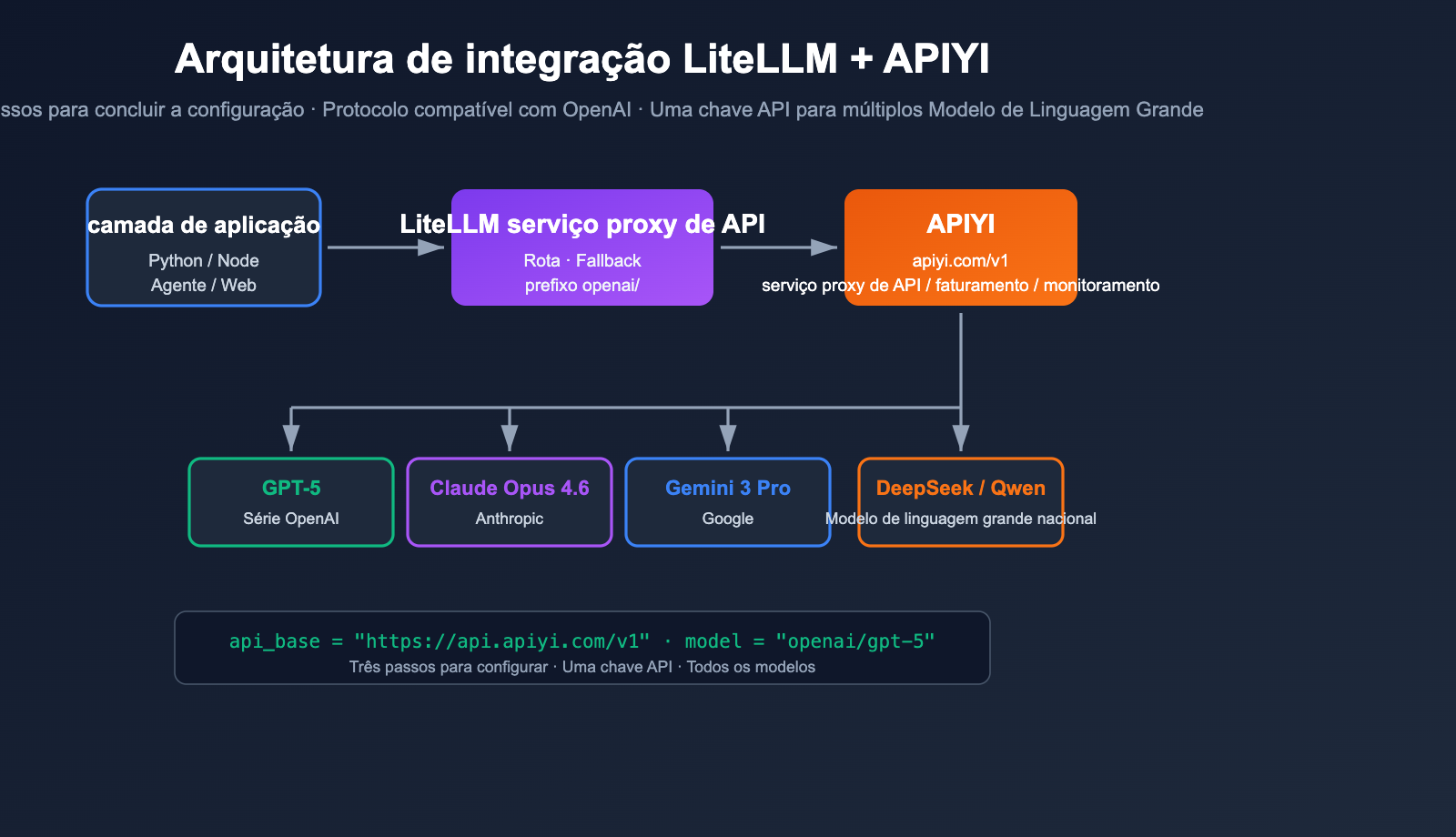
Como fazer com que o LiteLLM gerencie simultaneamente vários Modelos de Linguagem Grande, como OpenAI, Claude, Gemini e DeepSeek, sem ser bloqueado por problemas de contas estrangeiras, rede ou pagamentos? A resposta é conectar o LiteLLM a um serviço proxy de API de terceiros compatível com OpenAI. Neste artigo, usaremos o LiteLLM + APIYI apiyi.com como exemplo para guiá-lo passo a passo na configuração.
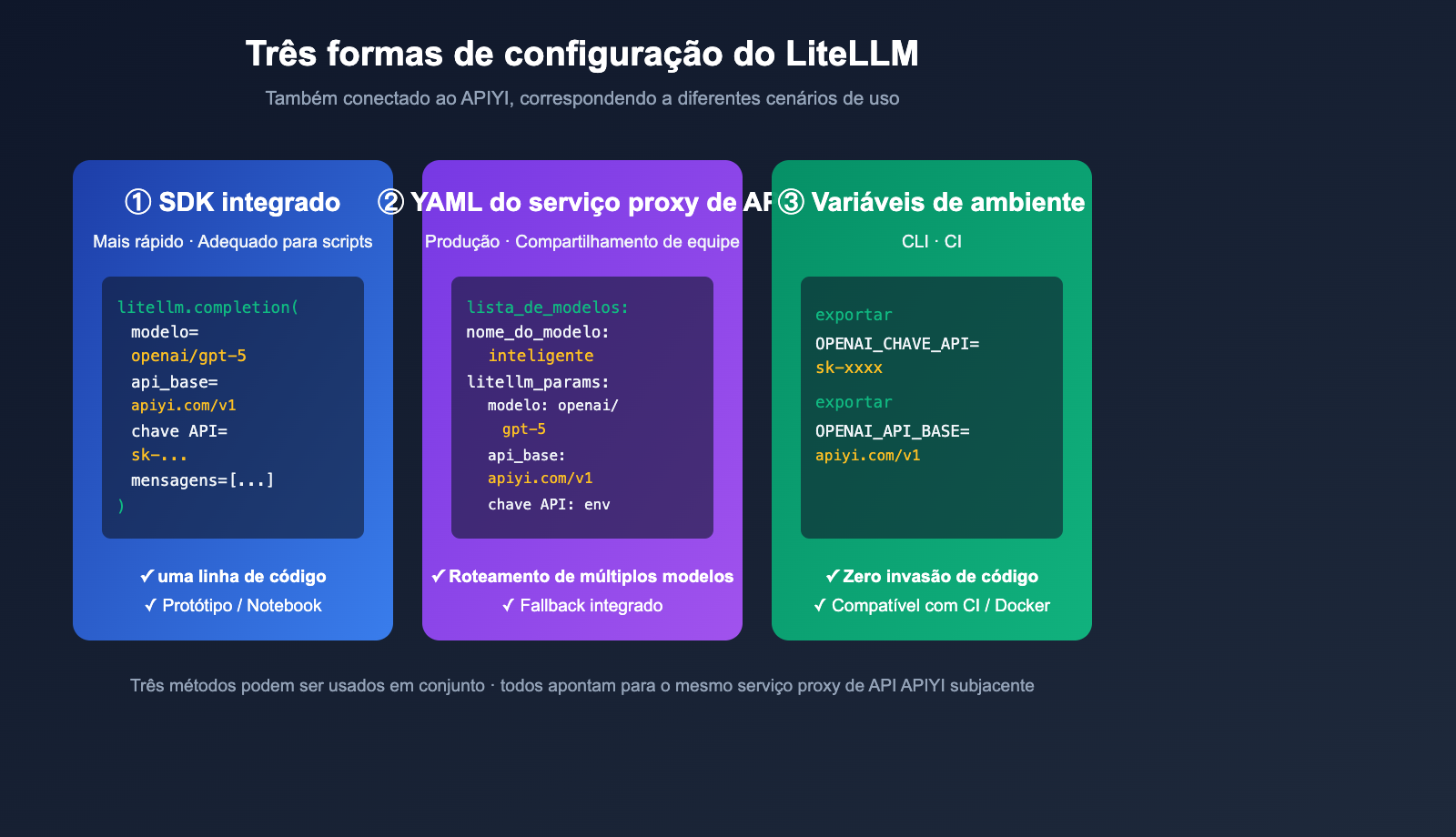
Valor central: Ao terminar este artigo, você dominará as 3 formas principais de configurar o LiteLLM com um serviço proxy de API (SDK, Proxy YAML, variáveis de ambiente) e conseguirá realizar a integração com o APIYI em 5 minutos.
Pontos principais da configuração do LiteLLM com serviço proxy de API
O LiteLLM é um gateway/SDK de LLM de código aberto que visa invocar mais de 100 modelos de linguagem grande usando o formato compatível com OpenAI. Ele suporta nativamente qualquer endpoint "compatível com OpenAI"; basta apontar o api_base para o serviço proxy e substituir a api_key pela chave emitida pelo serviço. O APIYI apiyi.com é um proxy padrão compatível com OpenAI, portanto, ambos se encaixam perfeitamente.
| Ponto | Descrição | Valor |
|---|---|---|
| Protocolo compatível com OpenAI | O LiteLLM roteia para o cliente OpenAI via prefixo openai/ |
Integração com qualquer proxy em uma linha |
| Três formas de configuração | SDK inline / Proxy YAML / Variáveis de ambiente | Adapta-se a scripts, produção e CLI |
| Nomenclatura unificada de modelos | openai/<provider-model> ou model_name personalizado |
O código superior não precisa detectar a troca subjacente |
| Chave para solução de problemas | base_url deve terminar com /v1 |
90% dos erros 404 vêm daqui |
| Fallback e balanceamento de carga | O modo YAML suporta múltiplos canais e fallback em falhas | Maximização da disponibilidade em produção |
Detalhes da configuração do LiteLLM com serviço proxy de API
A documentação oficial do LiteLLM é clara: basta adicionar o prefixo openai/ ao nome do modelo e especificar o api_base, e o LiteLLM usará o cliente OpenAI para acessar seu endpoint. Isso significa que, independentemente de o proxy estar conectado ao GPT-5, Claude Opus 4.6, Gemini 3 Pro ou DeepSeek, para o LiteLLM, tudo é "um endpoint OpenAI".
O base_url do APIYI apiyi.com é https://api.apiyi.com/v1, seguindo as especificações padrão /v1/chat/completions, /v1/embeddings e /v1/images/generations, sendo, portanto, perfeitamente compatível com o LiteLLM, sem necessidade de qualquer patch.
title: "Guia Rápido: Configurando o LiteLLM com um serviço proxy de API"
Guia Rápido: Configurando o LiteLLM com um serviço proxy de API
Preparação
Antes de começar, certifique-se de ter o seguinte:
- Chave API da APIYI: Após se registrar em apiyi.com, crie uma nova chave no painel de controle (recomendamos nomeá-la como
litellm-prod). - base_url:
https://api.apiyi.com/v1(atenção: o final deve conter/v1). - Ambiente Python: Python 3.9+.
- Instalar dependências:
pip install litellm.
Exemplo Minimalista: Configuração Inline no SDK
A maneira mais rápida de integrar é passando o api_key e o api_base diretamente no código:
import litellm
response = litellm.completion(
model="openai/gpt-5", # Chave: prefixo openai/
api_key="SUA_CHAVE_APIYI",
api_base="https://api.apiyi.com/v1", # Endereço do serviço proxy de API da APIYI
messages=[
{"role": "user", "content": "Descreva o LiteLLM em uma frase"}
],
)
print(response.choices[0].message.content)
💡 Dica: Após obter saldo de teste no painel da APIYI (apiyi.com), você pode trocar
gpt-5por nomes de modelos comoclaude-opus-4-6,gemini-3-pro, etc., sem precisar alterar mais nada no código — esse é o maior valor do protocolo compatível com OpenAI.
Ver exemplo completo e executável (incluindo tratamento de erros e streaming)
import os
import litellm
from litellm import completion
# Recomendamos gerenciar chaves via variáveis de ambiente
os.environ["OPENAI_API_KEY"] = "SUA_CHAVE_APIYI"
os.environ["OPENAI_API_BASE"] = "https://api.apiyi.com/v1"
litellm.set_verbose = False # Mude para True para depuração
def chat_with_apiyi(model: str, prompt: str, stream: bool = False):
"""Invoca qualquer modelo compatível com OpenAI via LiteLLM + APIYI"""
try:
response = completion(
model=f"openai/{model}",
messages=[{"role": "user", "content": prompt}],
stream=stream,
temperature=0.7,
max_tokens=1024,
)
if stream:
for chunk in response:
delta = chunk.choices[0].delta.content or ""
print(delta, end="", flush=True)
print()
else:
return response.choices[0].message.content
except Exception as e:
print(f"Falha na invocação: {e}")
return None
if __name__ == "__main__":
# Sem streaming
print(chat_with_apiyi("gpt-5", "Explique o que é um gateway de LLM"))
# Com streaming
chat_with_apiyi("claude-opus-4-6", "Descreva as vantagens do LiteLLM em 100 palavras", stream=True)
Configuração via YAML Proxy: Recomendado para Produção
Se você pretende rodar o LiteLLM como um serviço independente (porta 4000, para uso compartilhado na equipe), o modo YAML é o ideal. Crie um arquivo litellm_config.yaml:
model_list:
- model_name: gpt-5 # Nome do modelo exposto
litellm_params:
model: openai/gpt-5 # Prefixo openai/ para rotear ao cliente OpenAI
api_base: https://api.apiyi.com/v1 # Endereço do serviço proxy da APIYI
api_key: os.environ/APIYI_KEY # Referência à variável de ambiente
- model_name: claude-opus-4-6
litellm_params:
model: openai/claude-opus-4-6
api_base: https://api.apiyi.com/v1
api_key: os.environ/APIYI_KEY
- model_name: gemini-3-pro
litellm_params:
model: openai/gemini-3-pro
api_base: https://api.apiyi.com/v1
api_key: os.environ/APIYI_KEY
litellm_settings:
drop_params: true # Descarta automaticamente parâmetros não suportados
num_retries: 2 # Número de tentativas em caso de falha
router_settings:
fallbacks:
- gpt-5: ["claude-opus-4-6", "gemini-3-pro"]
Inicie o Proxy:
export APIYI_KEY=sk-xxxxxxxxxxxxxxxx
litellm --config ./litellm_config.yaml --port 4000
A partir daí, qualquer SDK da OpenAI pode realizar a invocação do modelo via http://localhost:4000:
from openai import OpenAI
client = OpenAI(
api_key="qualquer-string", # O LiteLLM Proxy não valida o conteúdo (a menos que configurado master_key)
base_url="http://localhost:4000",
)
resp = client.chat.completions.create(
model="gpt-5",
messages=[{"role": "user", "content": "Olá via LiteLLM Proxy"}]
)
print(resp.choices[0].message.content)
🎯 Dica de Produção: Recomendamos adicionar uma camada de
master_keyà frente do LiteLLM Proxy e conectar todos os modelos subjacentes à APIYI (apiyi.com). Assim, sua camada de aplicação enxerga apenas "nomes de modelos semânticos" comogpt-5/claude-opus-4-6, enquanto o roteamento, faturamento e limites de taxa são tratados pela combinação APIYI + LiteLLM, de forma transparente para a aplicação.
Modo de Variáveis de Ambiente: Praticidade para CLI e Scripts
Para scripts rápidos e ferramentas de linha de comando, a forma mais simples é usar variáveis de ambiente. O LiteLLM reconhece automaticamente OPENAI_API_KEY e OPENAI_API_BASE:
export OPENAI_API_KEY=sk-xxxxxxxxxxxxxxxx
export OPENAI_API_BASE=https://api.apiyi.com/v1
Depois disso, todas as invocações com o prefixo openai/ passarão pela APIYI:
import litellm
print(litellm.completion(
model="openai/gpt-5",
messages=[{"role": "user", "content": "ping"}]
).choices[0].message.content)
Comparação entre as três formas de configurar o LiteLLM com um serviço proxy
A escolha depende do seu cenário. A tabela abaixo oferece recomendações claras.

| Dimensão | SDK Inline | Proxy YAML | Variáveis de Ambiente |
|---|---|---|---|
| Dificuldade | ⭐ Mínima | ⭐⭐⭐ Média | ⭐ Mínima |
| Cenário | Scripts únicos, Notebooks | Equipes, Produção | CLI, CI |
| Processo independente | Não | Sim (porta 4000) | Não |
| Gestão de modelos | Manual | YAML centralizado | Apenas uma credencial |
| Suporte a Fallback | Requer try/except | ✅ Nativo | ❌ Não |
| Segurança | Risco de hardcode | ✅ Via env | ✅ Via env |
| Recomendação | Prototipagem | Produção | Scripts pessoais |
💡 Dica de escolha: Para desenvolvimento pessoal, variáveis de ambiente bastam. Para equipes e produção, recomendamos fortemente o modo Proxy YAML, pois ele gerencia "roteamento de modelos + Fallback + limites de taxa + estatísticas" em um único arquivo. Independentemente da escolha, a camada de canal subjacente conectada à APIYI (apiyi.com) permanece a mesma; você só precisa manter uma única chave API.
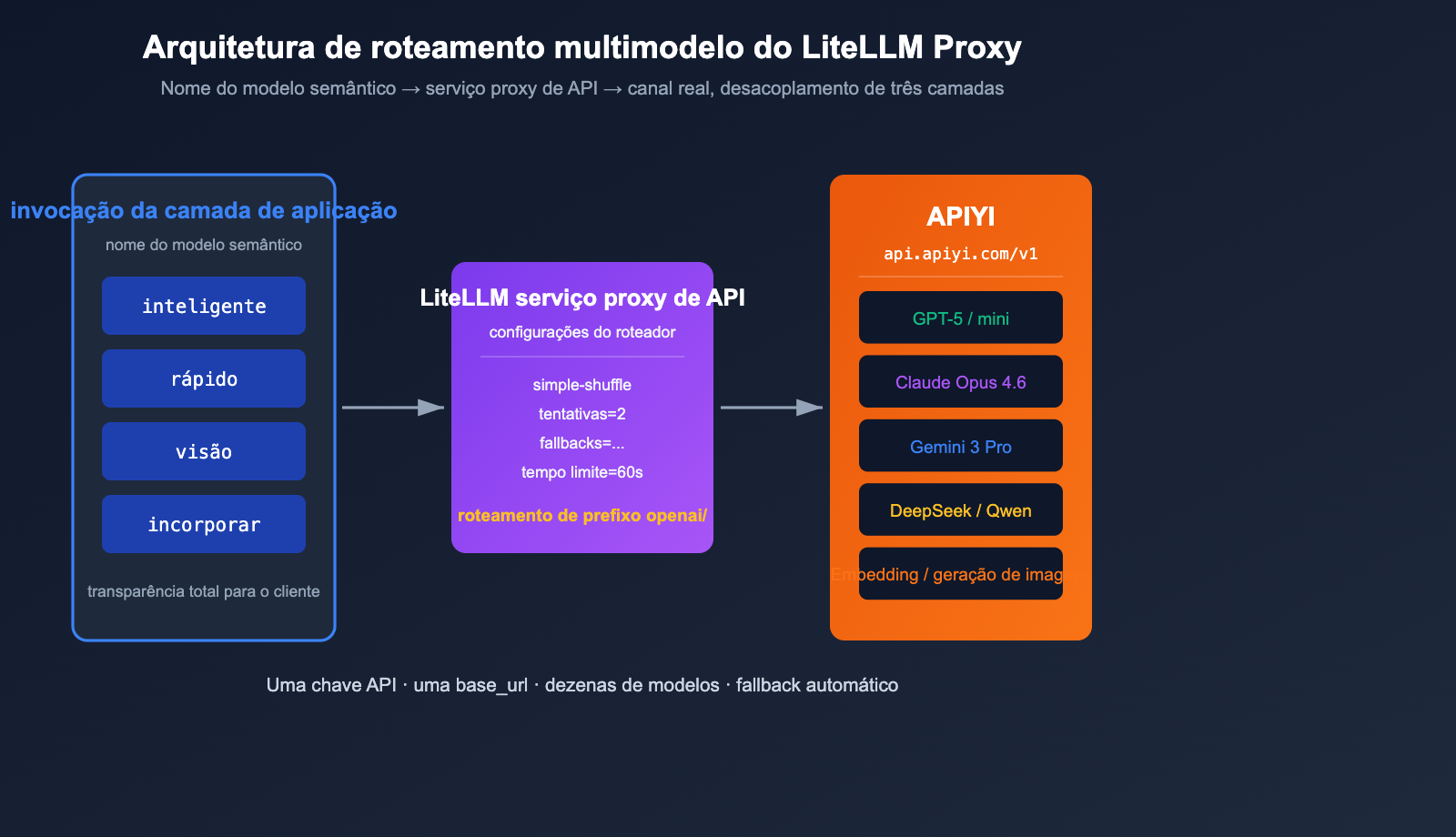
Prática de Roteamento de Múltiplos Modelos com LiteLLM + APIYI
O verdadeiro poder do modo Proxy do LiteLLM reside na capacidade de usar um único arquivo YAML para mapear "nomes de modelos semânticos → canais reais". Abaixo, apresento uma configuração de roteamento mínima pronta para produção.
# litellm_config.yaml - Exemplo de roteamento para produção
model_list:
# Modelos de inferência principais
- model_name: smart
litellm_params:
model: openai/gpt-5
api_base: https://api.apiyi.com/v1
api_key: os.environ/APIYI_KEY
timeout: 60
- model_name: smart
litellm_params:
model: openai/claude-opus-4-6
api_base: https://api.apiyi.com/v1
api_key: os.environ/APIYI_KEY
timeout: 60
# Modelos rápidos e econômicos
- model_name: fast
litellm_params:
model: openai/gpt-5-mini
api_base: https://api.apiyi.com/v1
api_key: os.environ/APIYI_KEY
# Visão/Multimodal
- model_name: vision
litellm_params:
model: openai/gemini-3-pro
api_base: https://api.apiyi.com/v1
api_key: os.environ/APIYI_KEY
# Embedding
- model_name: embed
litellm_params:
model: openai/text-embedding-3-large
api_base: https://api.apiyi.com/v1
api_key: os.environ/APIYI_KEY
litellm_settings:
drop_params: true
num_retries: 2
request_timeout: 60
router_settings:
routing_strategy: simple-shuffle # Round-robin para modelos com o mesmo nome
fallbacks:
- smart: ["fast"] # Fallback de smart para fast em caso de falha
general_settings:
master_key: sk-litellm-master-xxxx # O cliente deve obrigatoriamente enviar esta chave
A camada de aplicação enxerga apenas quatro nomes semânticos: smart, fast, vision e embed. Quando o GPT-5 sofre limitação de taxa (rate limit), o LiteLLM alterna automaticamente para o Claude Opus 4.6 (já que ambos estão registrados como smart) e, em caso de nova falha, faz o fallback para o fast. Todo o tráfego de baixo nível passa pelo serviço proxy de API da APIYI (apiyi.com) para faturamento e monitoramento unificados, isolando perfeitamente a camada de aplicação da camada de canais.
Perguntas Frequentes sobre a Configuração do LiteLLM com Serviços Proxy de Terceiros
Q1: Por que recebo um erro 404 Not Found mesmo configurando a base_url?
Em 90% dos casos, é porque falta o /v1 no final da api_base. O LiteLLM utiliza internamente o cliente OpenAI, que concatena automaticamente /chat/completions, portanto sua api_base deve ser https://api.apiyi.com/v1 e não https://api.apiyi.com. Também não escreva https://api.apiyi.com/v1/chat/completions, caso contrário, o caminho será duplicado.
Q2: Por que é obrigatório adicionar o prefixo openai/ ao modelo?
O LiteLLM mantém internamente uma tabela de roteamento de provedores. O prefixo openai/ instrui o LiteLLM a "usar o cliente OpenAI para acessar este endpoint". Se você não adicionar o prefixo, o LiteLLM pode tentar corresponder ao provedor nativo (por exemplo, o claude-opus-4-6 seria identificado como a API nativa da Anthropic), resultando em um erro de protocolo. Ao conectar a um serviço proxy, sempre adicione o prefixo openai/.
Q3: Uma única chave API da APIYI pode invocar múltiplos modelos?
Sim. Uma única chave da APIYI (apiyi.com) suporta, por padrão, todos os modelos disponíveis na plataforma, incluindo GPT-5, Claude Opus 4.6, Gemini 3 Pro, DeepSeek, Qwen, etc. Essa é a principal diferença em relação à API oficial — você só precisa gerenciar uma chave e uma base_url para carregar dezenas de modelos no seu YAML do LiteLLM.
Q4: Após iniciar o LiteLLM Proxy, como confirmar se a conexão está funcionando?
A maneira mais rápida é usar o curl diretamente no LiteLLM Proxy:
curl http://localhost:4000/v1/chat/completions \
-H "Authorization: Bearer sk-litellm-master-xxxx" \
-H "Content-Type: application/json" \
-d '{
"model": "smart",
"messages": [{"role": "user", "content": "ping"}]
}'
Se retornar 200 + JSON, a cadeia Aplicação → LiteLLM Proxy → APIYI está funcionando. Se falhar, verifique primeiro os logs do console do LiteLLM e, em seguida, teste a APIYI diretamente com a mesma base_url + chave para isolar o problema.
Q5: A saída em streaming (stream) requer configuração extra no cenário de proxy?
Não. A APIYI (apiyi.com) suporta totalmente a resposta em streaming SSE, e o LiteLLM a repassa por padrão. Basta adicionar stream=True na chamada completion() ou na chamada do SDK da OpenAI ao Proxy para receber a saída token a token.
Q6: É possível integrar também Embedding e geração de imagens?
Sim. A APIYI (apiyi.com) suporta simultaneamente /v1/embeddings, /v1/images/generations e /v1/audio/transcriptions, tudo utilizando a mesma base_url e chave. No YAML do LiteLLM, basta adicionar os modelos correspondentes à model_list, como text-embedding-3-large, gpt-image-1 ou whisper-1. O uso é idêntico ao dos modelos de chat; consulte o exemplo de roteamento de produção na seção anterior.
Resumo
Configurar um serviço proxy de API de terceiros no LiteLLM resume-se essencialmente a três pontos:
- Alinhamento de protocolo: Adicione o prefixo
openai/ao modelo para informar ao LiteLLM que ele deve utilizar o protocolo de cliente da OpenAI. - Alinhamento de entrada: Defina o
api_baseapontando para o caminho raiz do serviço proxy +/v1, por exemplo:https://api.apiyi.com/v1. - Alinhamento de credenciais: Passe a chave API fornecida pelo serviço proxy através do parâmetro
api_keyou de variáveis de ambiente.
Ao concluir esses três passos, todas as funcionalidades do LiteLLM (roteamento de múltiplos modelos, Fallback, limitação de taxa, faturamento e Logging) podem ser integradas perfeitamente sobre um serviço proxy estável.
🚀 Sugestão de ação: Se você está construindo um gateway de Modelo de Linguagem Grande unificado para sua equipe, recomendamos a arquitetura de três camadas: "Aplicação → LiteLLM Proxy → APIYI apiyi.com". O LiteLLM cuida do roteamento e do Fallback, enquanto a APIYI cuida do acesso aos modelos de base, estabilidade e faturamento por uso. Você só precisa gerenciar um arquivo YAML e uma chave. Registre-se em apiyi.com para obter créditos de teste e realizar sua primeira invocação em menos de 5 minutos.
Autor: Equipe APIYI — Focada em fornecer acesso estável aos principais Modelos de Linguagem Grande de IA para desenvolvedores. Acesse apiyi.com para saber mais.
Referências
-
Documentação oficial do LiteLLM – Endpoints compatíveis com OpenAI
- Link:
docs.litellm.ai/docs/providers/openai_compatible - Descrição: Exemplos oficiais para SDK e Proxy YAML.
- Link:
-
Visão geral da configuração do LiteLLM Proxy
- Link:
docs.litellm.ai/docs/proxy/configs - Descrição: Campos completos para model_list, router_settings e fallbacks.
- Link:
-
Repositório GitHub do LiteLLM
- Link:
github.com/BerriAI/litellm - Descrição: Código-fonte, Issues e versões mais recentes.
- Link:
-
daily_stock_analysis – LLM_CONFIG_GUIDE
- Link:
github.com/ZhuLinsen/daily_stock_analysis/blob/main/docs/LLM_CONFIG_GUIDE.md - Descrição: Três modos de configuração e referências práticas para múltiplos canais.
- Link:
-
Documentação oficial da APIYI
- Link:
apiyi.com - Descrição: Lista de modelos suportados, base_url e gerenciamento de chave API.
- Link: