LiteLLM und Claude Code zählen zu den gefragtesten KI-Entwicklungstools der Jahre 2025–2026, werden jedoch von Entwicklern oft fälschlicherweise miteinander verglichen: Welches ist besser? Können sie sich gegenseitig ersetzen? Unterstützt LiteLLM tatsächlich die Abrechnung für Prompt Caching? Dieser Artikel vergleicht LiteLLM und Claude Code und gibt klare Empfehlungen basierend auf Positionierung, Funktionsumfang und Unterstützung für Caching-Abrechnungen.
Kernnutzen: Nach diesem Artikel wissen Sie genau, ob Sie sich wirklich für eines der beiden entscheiden müssen und wie Sie in verschiedenen Szenarien die optimale Wahl treffen.

Die wesentlichen Unterschiede zwischen LiteLLM und Claude Code im Überblick
Viele betrachten LiteLLM und Claude Code als Konkurrenzprodukte, doch in Wahrheit ist ihre Positionierung grundverschieden; sie lassen sich sogar hervorragend kombinieren. Hier ist der wesentliche Unterschied in einem Satz:
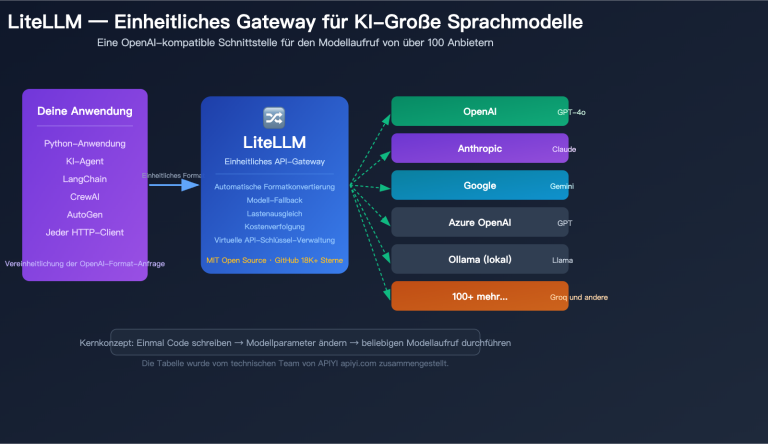
- LiteLLM = LLM-Gateway / API-Proxy-Dienst, mit dem eine Codebasis über 100+ Modelle ansteuern kann.
- Claude Code = Offizielles Agentic-Coding-CLI von Anthropic, spezialisiert darauf, "deine Codebasis mit Claude zu bearbeiten".
| Vergleichsdimension | LiteLLM | Claude Code |
|---|---|---|
| Produktform | Python SDK + Proxy-Server | Befehlszeilen-Tool (CLI) |
| Kernpositionierung | Universelles LLM-Gateway / Modell-Routing | Agentic-Coding-Assistent |
| Unterstützte Modelle | 100+ (OpenAI, Anthropic, Gemini, Bedrock, Vertex etc.) | Standardmäßig nur Claude-Serie |
| Zielgruppe | Plattform-Ingenieure, Entwickler von KI-Anwendungen | Einzelentwickler, Coding-Szenarien |
| Open Source | ✅ Ja (BerriAI/litellm) | Nein (Closed Source CLI) |
| Gegenseitig ersetzbar | ❌ Nein | ❌ Nein |
| Kombinierbar | ✅ Ja (LiteLLM hinter Claude Code) | ✅ Ja (Claude Code mit LiteLLM) |
| Ideale Ergänzung | APIYI (apiyi.com) für stabiles Proxy-Routing | LiteLLM zum Wechseln der Basismodelle |
💡 Kurzfazit: Wenn Sie sich fragen, "welches ist besser", dann benötigen Sie höchstwahrscheinlich beide. Nutzen Sie Claude Code als Coding-Agent, LiteLLM als einheitliche Schnittstelle und binden Sie internationale Modelle über APIYI (apiyi.com) an. Das ist der Standard-Stack für 2026.
Die 5 Hauptunterschiede zwischen LiteLLM und Claude Code
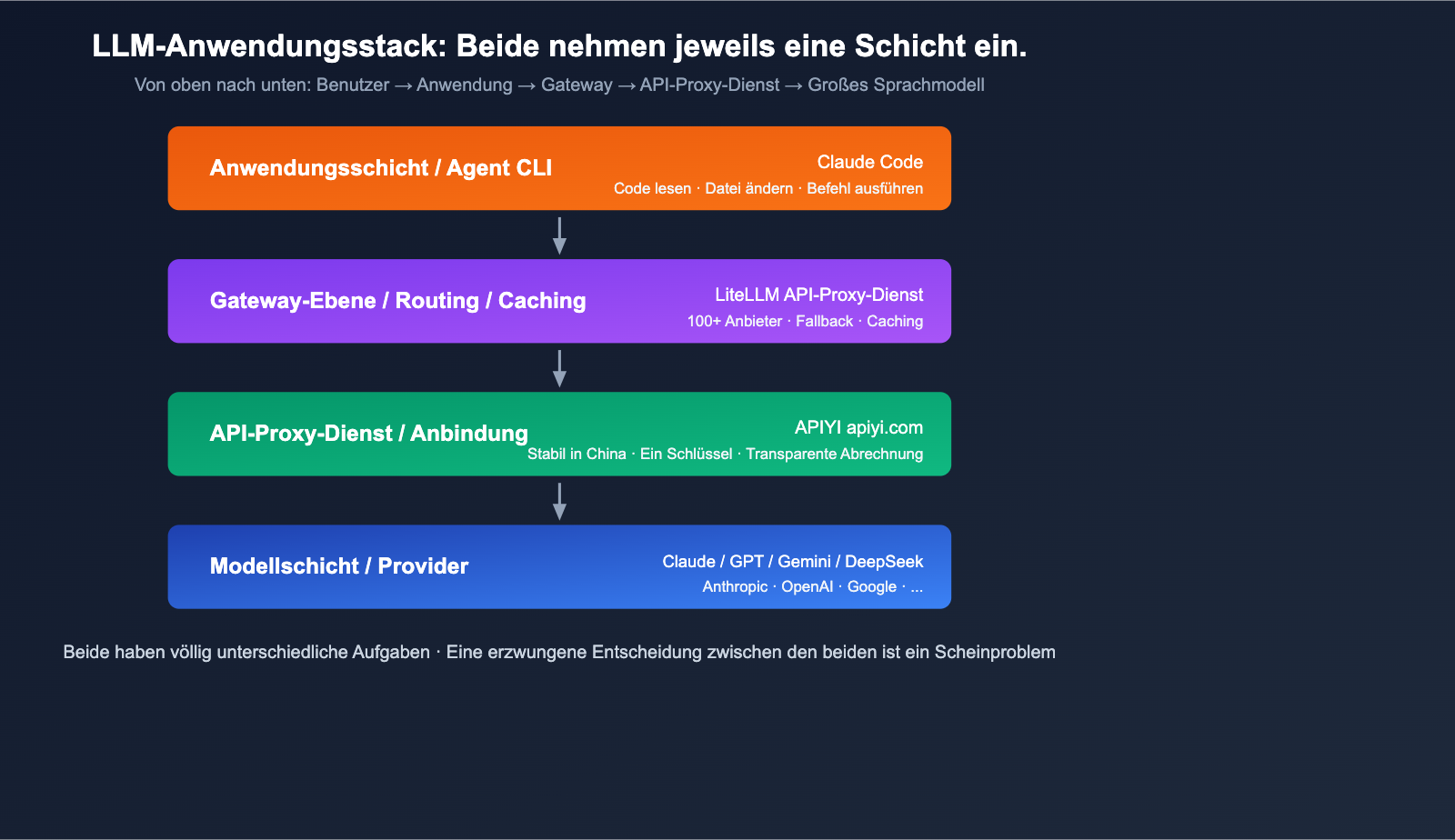
Unterschied 1: Grundlegende Ausrichtung (Gateway vs. Agent-CLI)
Positionierung von LiteLLM: Ein Open-Source-LLM-Gateway mit dem Ziel, "jedes Modell über ein OpenAI-kompatibles Format aufzurufen". Es gibt zwei Varianten:
- Python SDK:
litellm.completion(model="...")für Entwickler zur Integration in Anwendungen. - Proxy-Server:
litellm --config config.yamlals eigenständiger Dienst für die teamweite Nutzung.
Positionierung von Claude Code: Eine offizielle Agentic-Coding-CLI von Anthropic. Das Ziel: "Claude soll direkt in deinem Terminal Code lesen, bearbeiten und Befehle ausführen können". Es handelt sich um ein Anwendungsprodukt, das im Hintergrund die Messages API von Anthropic nutzt.
Kurz gesagt: LiteLLM ist die "Wasserleitung", Claude Code ist der "Wasserhahn an der Leitung".
Unterschied 2: Unterstützte Modelle
| Dimension | LiteLLM | Claude Code |
|---|---|---|
| Standard-Support | OpenAI, Anthropic, Google, Cohere, Bedrock, Azure, HuggingFace, Ollama, vLLM etc. (100+) | Nur Anthropic Claude-Serie (Opus / Sonnet / Haiku) |
| Eigene Endpunkte | ✅ Jeder OpenAI-kompatible Endpunkt | ⚠️ Über ANTHROPIC_BASE_URL an LiteLLM anbindbar |
| Lokale Modelle | ✅ DeepSeek / Qwen / Kimi / GLM etc. | ❌ Standardmäßig nicht unterstützt |
Hinweis: Claude Code kann über ANTHROPIC_BASE_URL indirekt andere Modelle via LiteLLM Proxy nutzen, was jedoch zeigt, dass sich beide Tools hervorragend ergänzen.
Unterschied 3: Benutzeroberfläche und Entwicklererfahrung
Entwicklererfahrung mit LiteLLM:
- SDK für Anwendungsentwickler.
- In jedes Python-Projekt integrierbar.
- Bietet OpenAI-kompatible HTTP-Endpunkte für Frontend, Node.js oder Curl.
Entwicklererfahrung mit Claude Code:
- Eine eigenständige CLI, ähnlich dem
claude-Befehl. - Direkte Interaktion mit dem Code-Repository im Terminal.
- Integrierte Tools für Dateizugriff, Bash-Ausführung, Git usw.
- Optimierte Tool-Nutzung: "Denken und Ändern in einem".
Unterschied 4: Bereitstellung und Betriebskosten
| Projekt | LiteLLM | Claude Code |
|---|---|---|
| Installation | pip install litellm |
npm i -g @anthropic-ai/claude-code |
| Dienst erforderlich | Ja (Proxy-Modus) | Nein, lokale CLI |
| YAML-Konfiguration | Ja (Proxy-Modus) | Meist nicht erforderlich |
| Team-Sharing | ✅ Ein Proxy-Dienst für das ganze Team | ❌ Jeder Nutzer benötigt eigene CLI |
| Zentralisierte Abrechnung | ✅ Zentrale Abrechnung am Gateway | ❌ Abrechnung pro Account |
Unterschied 5: Ökosystem und Erweiterbarkeit
Ökosystem von LiteLLM:
- Logging: Langfuse, Helicone, Sentry, OpenTelemetry.
- Guardrails: Integrierte Inhaltsprüfung.
- Routing: Lastverteilung, Fallback, Ratenbegrenzung.
- Kostenverfolgung: Nach Modell, Nutzer und API-Schlüssel.
Ökosystem von Claude Code:
- Hooks: Benutzerdefinierte Befehls-Hooks.
- MCP: Anbindung externer Tools über das Model Context Protocol.
- IDE-Integration: VS Code, JetBrains.
- Tiefe Integration der Tool-Call-Fähigkeiten von Anthropic.
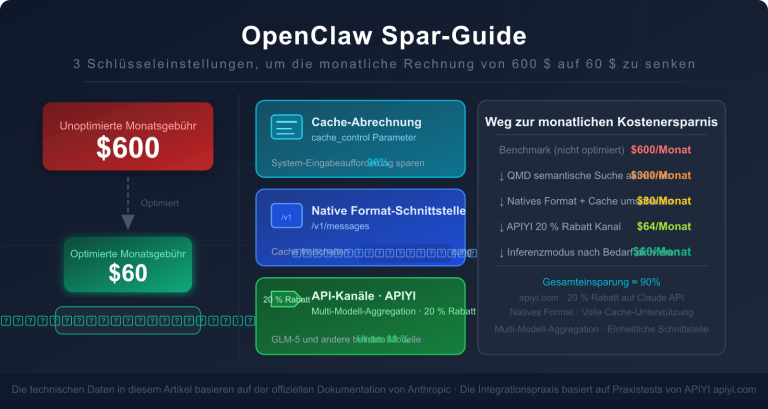
Unterstützt LiteLLM die Abrechnung für Prompt Caching?

Dies ist eine der wichtigsten Fragen für Entwickler. Die kurze Antwort: Ja, und es ist ein erstklassiges Feature.
Support-Matrix
Die offizielle LiteLLM-Dokumentation bestätigt, dass Prompt Caching bei den folgenden 6 großen Providern nativ unterstützt wird:
| Provider | LiteLLM-Präfix | Aktivierung der Zwischenspeicherung | Preisvorteil |
|---|---|---|---|
| Anthropic | anthropic/ |
Explizit cache_control: {"type": "ephemeral"} |
Schreiben 1,25x, Lesen 0,1x (90% Rabatt) |
| OpenAI | openai/ |
Automatisch (>1024 Tokens) | Automatisch 50% Rabatt |
| Google AI Studio | gemini/ |
Explizit cache_control |
Automatische Konvertierung zur Context Caching API |
| Vertex AI | vertex_ai/ |
Explizit cache_control |
Wie oben |
| Bedrock | bedrock/ |
Verfügbar, sobald Modell unterstützt | Gemäß Modellpreis |
| DeepSeek | deepseek/ |
Automatisch | Automatisch Rabatt |
Code-Beispiel: Anthropic Caching
import litellm
response = litellm.completion(
model="anthropic/claude-opus-4-6",
messages=[
{
"role": "system",
"content": [
{
"type": "text",
"text": "Du bist ein erfahrener Python-Entwickler... (langer System-Prompt)",
"cache_control": {"type": "ephemeral"}, # Wichtig: Markierung für Caching
}
],
},
{"role": "user", "content": "Bitte überprüfe diesen Code"},
],
)
# Die Cache-Nutzung ist in response.usage sichtbar
print(response.usage)
# {
# "prompt_tokens": 1234,
# "cache_creation_input_tokens": 800, # Tokens, die in den Cache geschrieben wurden
# "cache_read_input_tokens": 0, # Beim zweiten Aufruf werden dies 800
# "completion_tokens": 256,
# }
🎯 Praxistipp: Das Prompt Caching von Anthropic ist bei langen System-Prompts und wiederkehrenden Kontexten extrem effizient – das Lesen aus dem Cache kostet nur 10 % des Originalpreises. Wir empfehlen die Aktivierung für Agenten mit langen Abläufen, RAG-Systeme und Code-Reviews. Wenn Sie Claude Opus 4.6 / Sonnet 4.6 stabil nutzen und von den Rabatten profitieren möchten, können Sie dies über APIYI (apiyi.com) tun, da die Plattform die relevanten Usage-Felder vollständig durchreicht.
Auto-Inject Cache Control (Automatisches Caching)
Wenn Sie nicht manuell cache_control zu jeder Nachricht hinzufügen möchten, bietet LiteLLM eine automatische Injektion:
response = litellm.completion(
model="anthropic/claude-opus-4-6",
messages=[...],
cache_control_injection_points=[
{"location": "message", "role": "system"} # Automatische Cache-Markierung für alle System-Nachrichten
],
)
Dies ist ideal für die Anbindung an bestehenden Code – ohne die Nachrichtenstruktur zu ändern, profitieren Sie von 90 % Rabatt.
Fallstricke bei der Cache-Abrechnung
In frühen LiteLLM-Versionen (2024) gab es einen Bug (GitHub Issue #5443), bei dem die Kostenverfolgung zwischen cache_creation_input_tokens und cache_read_input_tokens nicht korrekt unterschied, was zu Abrechnungsfehlern führte. In den Versionen 2025-2026 ist dies behoben. LiteLLM berechnet die Kosten in der Funktion completion_cost() nun nach diesen Regeln:
| Token-Typ | Preis-Multiplikator (relativ zum Input-Preis) | Erläuterung |
|---|---|---|
| Cache-Schreiben | 1,25x | Geringer Mehraufwand beim Schreiben |
| Cache-Lesen | 0,1x | Nur 10 % der Kosten beim Lesen |
| Normaler Input | 1,0x | Standard-Input |
| Output | Modellabhängig | Output-Tokens |
🛡️ Wichtiger Hinweis: Wenn Sie einen API-Proxy-Dienst nutzen, stellen Sie sicher, dass dieser die Felder
cache_creation_input_tokensundcache_read_input_tokensvollständig durchreicht. Andernfalls berechnet LiteLLM die Kosten als normalen Input. APIYI (apiyi.com) unterstützt die Durchleitung dieser Felder vollständig, sodass Sie in Kombination mit LiteLLM die tatsächlichen Cache-Rabatte erhalten.
Szenario-Empfehlung: Wann LiteLLM und wann Claude Code nutzen?

Szenario 1: Einzelentwickler, Fokus auf Programmierung
Empfehlung: Verwenden Sie direkt Claude Code.
Der Grund ist simpel: Die Erfahrung von Claude bei Programmieraufgaben ist derzeit erstklassig – die Tool-Nutzung ist stabil, Dateiänderungen sind präzise und das Management des Kontextfensters ist hervorragend. Wenn Sie alleine arbeiten und nicht ständig zwischen Modellen wechseln müssen, ist Claude Code die stressfreieste Wahl. Falls der Zugriff auf die offiziellen Anthropic-Dienste aus dem Inland schwierig ist, können Sie ANTHROPIC_BASE_URL auf den API-Proxy-Dienst von APIYI (apiyi.com) umleiten, um eine identische Erfahrung zu erhalten.
Szenario 2: Teams, die KI-Anwendungen entwickeln
Empfehlung: LiteLLM Proxy + Anwendungscode.
Grund: Sie benötigen eine "einheitliche Abrechnung + Modell-Routing + Fallback-Mechanismen", was genau die Kernkompetenzen von LiteLLM Proxy sind. Claude Code ist ein CLI-Tool und kann die Rolle eines Gateways auf Anwendungsebene nicht übernehmen.
Best Practices:
- Betreiben Sie LiteLLM Proxy als eigenständigen Dienst (Port 4000).
- Binden Sie alle zugrunde liegenden Modelle einheitlich über APIYI (apiyi.com) an.
- Die Anwendungsebene ruft nur den LiteLLM Proxy auf und verwendet durchgehend semantische Modellnamen.
Szenario 3: Die Erfahrung von Claude Code mit Modellflexibilität
Empfehlung: Kombination aus Claude Code + LiteLLM.
Dies ist die leistungsstärkste Kombination. Die Konfiguration ist sehr einfach:
# Starten Sie den LiteLLM Proxy (mit Anbindung an verschiedene Modelle)
litellm --config litellm_config.yaml --port 4000
# Leiten Sie Claude Code über LiteLLM
export ANTHROPIC_BASE_URL=http://localhost:4000
export ANTHROPIC_AUTH_TOKEN=sk-litellm-master-xxxx
# Starten Sie Claude Code mit einem beliebigen Modell
claude --model claude-opus-4-6
claude --model gpt-5 # Dasselbe CLI, im Hintergrund läuft GPT-5
claude --model gemini-3-pro # Dasselbe CLI, im Hintergrund läuft Gemini 3 Pro
💡 Mehrwert der Kombination: Claude Code bietet eine erstklassige Coding-Agent-Erfahrung, LiteLLM sorgt für Modellfreiheit und APIYI (apiyi.com) garantiert eine stabile Anbindung. Alle drei Komponenten erfüllen ihre spezifische Aufgabe und bilden die pragmatischste "Full-Stack KI-Coding"-Lösung für 2026.
Szenario 4: Produktionseinsatz auf Unternehmensebene
Empfehlung: LiteLLM Proxy + Langfuse + APIYI.
In Unternehmensszenarien dient Claude Code lediglich als lokales Werkzeug für Entwickler. Der tatsächliche Produktions-Traffic erfordert:
- LiteLLM Proxy als Gateway für Ratenbegrenzung und Fallback.
- Langfuse / Helicone für Logging und Kostenanalyse.
- APIYI (apiyi.com) für die Anbindung der Basismodelle und zur Sicherstellung der Stabilität.
Entscheidungshilfe: LiteLLM vs. Claude Code
Diese Entscheidungstabelle hilft Ihnen, in 30 Sekunden die richtige Wahl zu treffen.
| Ihr Bedarf | Empfohlene Lösung |
|---|---|
| Ich möchte, dass eine KI meinen Code im Terminal bearbeitet | Claude Code |
| Ich möchte in Python-Anwendungen mehrere Modelle aufrufen | LiteLLM SDK |
| Mein Team benötigt einen einheitlichen LLM-Zugang | LiteLLM Proxy |
| Ich möchte das zugrunde liegende Modell für Claude Code wechseln | Claude Code + LiteLLM |
| Ich benötige ein LLM-Gateway für die Produktion | LiteLLM Proxy + Monitoring |
| Der Zugriff auf ausländische Modelle ist in China instabil | Beliebig + APIYI apiyi.com API-Proxy-Dienst |
| Ich möchte bei Anthropic Token-Kosten sparen | LiteLLM + Prompt Caching |
🚀 Allgemeine Empfehlung: Unabhängig davon, für welches Tool Sie sich entscheiden, ist die Anbindung an APIYI apiyi.com die stabilste Option. LiteLLM kann über
api_basedirekt auf apiyi.com/v1 verweisen, und Claude Code kann überANTHROPIC_BASE_URLindirekt über LiteLLM zu apiyi.com geleitet werden. Beide Pfade haben sich bei zahlreichen Entwicklern als stabil und zuverlässig erwiesen.
Häufig gestellte Fragen zu LiteLLM vs. Claude Code
Q1: Kann LiteLLM Claude Code vollständig ersetzen?
Nein. LiteLLM ist ein LLM-Gateway und verfügt nicht über die Agent-Toolchain von Claude Code, die "Ihre Codebasis liest + Dateien eigenständig ändert + Bash-Befehle ausführt". Beide lösen Probleme auf unterschiedlichen Ebenen; LiteLLM durch Claude Code zu ersetzen, wäre so, als würde man eine "Wasserleitung" durch eine "Kaffeemaschine" ersetzen.
Q2: Kann Claude Code LiteLLM vollständig ersetzen?
Ebenfalls nein. Claude Code ist ein CLI-Tool, kein Gateway. Es fehlen Konzepte der Gateway-Ebene wie model_list, router_settings oder Fallbacks. Zudem kann es nicht direkt von Ihrer Python-Anwendung oder Ihrem Webdienst aufgerufen werden. Wenn Sie eine "KI-Integration auf Anwendungsebene" benötigen, hilft Ihnen Claude Code nicht weiter.
Q3: Unterstützt LiteLLM wirklich die Abrechnung von Anthropic Prompt Caching?
Ja. Seit 2025 unterstützt LiteLLM vollständig cache_control: {"type": "ephemeral"}, die automatische Injektion von Cache-Punkten (cache_control_injection_points) sowie die Weitergabe der Nutzung von cache_creation_input_tokens / cache_read_input_tokens und die Kostenberechnung via completion_cost(). Der in Issue #5443 erwähnte Fehler bei der Kostenberechnung wurde behoben, sodass Sie die aktuelle Version bedenkenlos nutzen können.
Q4: Wie viel Geld lässt sich durch Anthropic Caching via LiteLLM sparen?
Bis zu ~90 %. Die Preisregeln für das Prompt Caching von Anthropic lauten: Die Kosten für das Schreiben in den Cache betragen etwa das 1,25-fache des Standard-Inputs, während das Lesen aus dem Cache nur etwa 0,1-mal so viel kostet. Bei Szenarien mit häufig wiederverwendeten langen System-Prompts (z. B. RAG, Code-Reviews, lang laufende Agenten) liegen die tatsächlichen Einsparungen meist zwischen 50 und 90 %. Wenn Sie den Dienst über APIYI apiyi.com nutzen, werden diese Cache-Rabatte vollständig auf Ihrer Rechnung berücksichtigt.
Q5: Verschlechtert sich die Leistung, wenn Claude Code über LiteLLM mit GPT-5 verbunden wird?
Es gibt Unterschiede, aber nicht unbedingt eine Verschlechterung. Die Tool-Use-Eingabeaufforderung von Claude Code ist für Claude optimiert. Beim Wechsel zu GPT-5 können sich der Stil der Funktionsaufrufe und die Dateibearbeitungsaktionen leicht unterscheiden. Es empfiehlt sich, die Claude-Serie als Hauptmodell zu verwenden und andere Modelle als "Inspiration/Vergleich" in Reserve zu halten. Der Fallback-Mechanismus von LiteLLM ermöglicht es Ihnen, bei einer Drosselung von Claude automatisch auf GPT-5 auszuweichen.
Q6: Wie können Entwickler Claude Code + LiteLLM + Anthropic Caching optimal kombinieren?
Die pragmatischste Lösung ist eine dreistufige Struktur: Claude Code (CLI) → LiteLLM Proxy (lokaler Port 4000) → APIYI apiyi.com (API-Proxy-Dienst). Claude Code verweist über ANTHROPIC_BASE_URL auf LiteLLM, LiteLLM konfiguriert das Modell in der YAML-Datei als anthropic/claude-opus-4-6 und die api_base zeigt auf apiyi.com/v1. So profitieren Sie von der Coding-Erfahrung mit Claude Code, nutzen die Routing-Fähigkeiten von LiteLLM, lösen Netzwerk- und Abrechnungsprobleme über APIYI und behalten die vollen Prompt-Caching-Rabatte bei.
Zusammenfassung
LiteLLM und Claude Code sind keine Konkurrenzprodukte, sondern Werkzeuge auf unterschiedlichen Abstraktionsebenen: der "Gateway-Ebene" und der "Anwendungsebene". Die Frage, ob man sich für eines entscheiden muss, ist ein falsches Dilemma. Die richtige Frage lautet: Welche Kombination passt zu Ihrem Szenario?
Kommen wir auf die beiden eingangs gestellten Fragen zurück:
- Was ist besser? – Das hängt vom Anwendungsfall ab. Für die individuelle Programmierung ist Claude Code ideal, für die Anwendungsentwicklung LiteLLM. Wer beides kombinieren möchte, nutzt am besten die Kombination aus Claude Code und LiteLLM.
- Unterstützt LiteLLM die Abrechnung für Caching? – Ja, vollständig. Dies deckt die sechs großen Anbieter Anthropic, OpenAI, Gemini, Vertex, Bedrock und DeepSeek ab, wodurch Sie bis zu 90 % der Kosten für Eingabe-Token einsparen können.
🚀 Handlungsempfehlung: Wenn Sie heute einen vollständigen Workflow mit "Claude Code + LiteLLM + Caching" aufbauen möchten, ist dies der schnellste Weg: Erstens bei APIYI (apiyi.com) registrieren und einen Schlüssel abrufen; zweitens einen lokalen Proxy mit LiteLLM einrichten und
api_baseaufapiyi.com/v1verweisen; drittens in Claude Code die VariableANTHROPIC_BASE_URLauf Ihren lokalen LiteLLM-Proxy setzen. Die gesamte Kette ist in weniger als 10 Minuten einsatzbereit, und Sie profitieren sofort von den Kostenvorteilen durch Prompt Caching.
Autor: APIYI Team — Wir konzentrieren uns darauf, Entwicklern einen stabilen Zugang zu führenden KI-Großsprachmodellen zu bieten. Besuchen Sie apiyi.com für weitere Informationen.
Referenzen
-
Offizielle LiteLLM-Dokumentation – Prompt Caching
- Link:
docs.litellm.ai/docs/completion/prompt_caching - Beschreibung: Cache-Support-Matrix für die 6 großen Anbieter und Code-Beispiele.
- Link:
-
Offizielle LiteLLM-Dokumentation – Auto-Inject Cache
- Link:
docs.litellm.ai/docs/tutorials/prompt_caching - Beschreibung: Automatische Injektion über
cache_control_injection_points.
- Link:
-
Offizielle LiteLLM-Dokumentation – Claude Code Quickstart
- Link:
docs.litellm.ai/docs/tutorials/claude_responses_api - Beschreibung: Konfiguration von
ANTHROPIC_BASE_URLund Unterstützung für 1M Kontextfenster.
- Link:
-
Offizielle LiteLLM-Dokumentation – Anthropic Provider
- Link:
docs.litellm.ai/docs/providers/anthropic - Beschreibung: Erläuterung der Felder
cache_creation_input_tokens/cache_read_input_tokens.
- Link:
-
GitHub Issue #5443 – Cache Cost Calculation
- Link:
github.com/BerriAI/litellm/issues/5443 - Beschreibung: Historie zur Fehlerbehebung bei der Cache-Kostenberechnung.
- Link:
-
LiteLLM GitHub-Haupt-Repository
- Link:
github.com/BerriAI/litellm - Beschreibung: Quellcode, Issues und aktuelle Versionen.
- Link: