LiteLLM dan Claude Code adalah dua alat pengembangan AI paling populer di tahun 2025-2026, namun pengembang sering membandingkan keduanya: mana yang lebih baik? Bisakah keduanya saling menggantikan? Apakah LiteLLM benar-benar mendukung penagihan prompt caching? Artikel ini membandingkan LiteLLM dan Claude Code, serta memberikan saran jelas dari tiga aspek: posisi produk, batasan kemampuan, dan dukungan penagihan caching.
Nilai Inti: Setelah membaca artikel ini, Anda akan memahami apakah kedua alat ini benar-benar harus "pilih salah satu", dan bagaimana membuat pilihan terbaik dalam skenario yang berbeda.

Sekilas Perbedaan Utama LiteLLM vs Claude Code
Banyak orang menganggap LiteLLM dan Claude Code sebagai pesaing, padahal posisi mereka sangat berbeda dan bahkan bisa digunakan bersamaan. Berikut perbedaan mendasar keduanya dalam satu kalimat:
- LiteLLM = Gateway LLM / lapisan perantara, memungkinkan satu kode memanggil 100+ model.
- Claude Code = CLI coding berbasis agen resmi dari Anthropic, fokus pada "menggunakan Claude untuk mengubah basis kode Anda".
| Dimensi Perbandingan | LiteLLM | Claude Code |
|---|---|---|
| Bentuk Produk | Python SDK + Server Proksi | Alat Baris Perintah (CLI) |
| Posisi Inti | Gateway LLM Umum / Routing Model | Asisten coding berbasis agen |
| Model yang Didukung | 100+ (OpenAI/Anthropic/Gemini/Bedrock/Vertex, dll.) | Default hanya seri Claude |
| Pengguna Tipikal | Insinyur platform, pengembang aplikasi AI | Pengembang individu, skenario coding |
| Apakah Open Source | ✅ Ya (BerriAI/litellm) | CLI closed-source |
| Bisakah saling menggantikan | ❌ Tidak | ❌ Tidak |
| Bisakah digunakan bersama | ✅ Bisa (LiteLLM di belakang Claude Code) | ✅ Bisa |
| Pasangan Terbaik | Gunakan dengan APIYI apiyi.com untuk proksi stabil | Gunakan dengan LiteLLM untuk beralih model dasar |
💡 Kesimpulan Cepat: Jika Anda bertanya "mana yang lebih baik", kemungkinan besar Anda membutuhkan keduanya — gunakan Claude Code sebagai agen coding, LiteLLM sebagai pintu masuk terpadu, lalu akses model luar negeri melalui APIYI apiyi.com. Inilah stack paling populer di tahun 2026.
5 Perbedaan Utama LiteLLM vs Claude Code
Perbedaan 1: Posisi yang Berbeda (Gateway vs Agent CLI)
Posisi LiteLLM: Gateway Model Bahasa Besar open-source yang bertujuan untuk "memanggil model apa pun dengan format yang kompatibel dengan OpenAI". Tersedia dalam dua bentuk:
- Python SDK:
litellm.completion(model="..."), digunakan oleh pengembang untuk membangun aplikasi. - Server Proksi:
litellm --config config.yaml, dijalankan sebagai layanan mandiri untuk dibagikan dalam tim.
Posisi Claude Code: CLI pengodean berbasis agen resmi dari Anthropic yang bertujuan agar "Claude dapat membaca, mengubah, dan menjalankan perintah di terminal Anda secara langsung". Ini adalah produk lapisan aplikasi yang memanggil Messages API dari Anthropic.
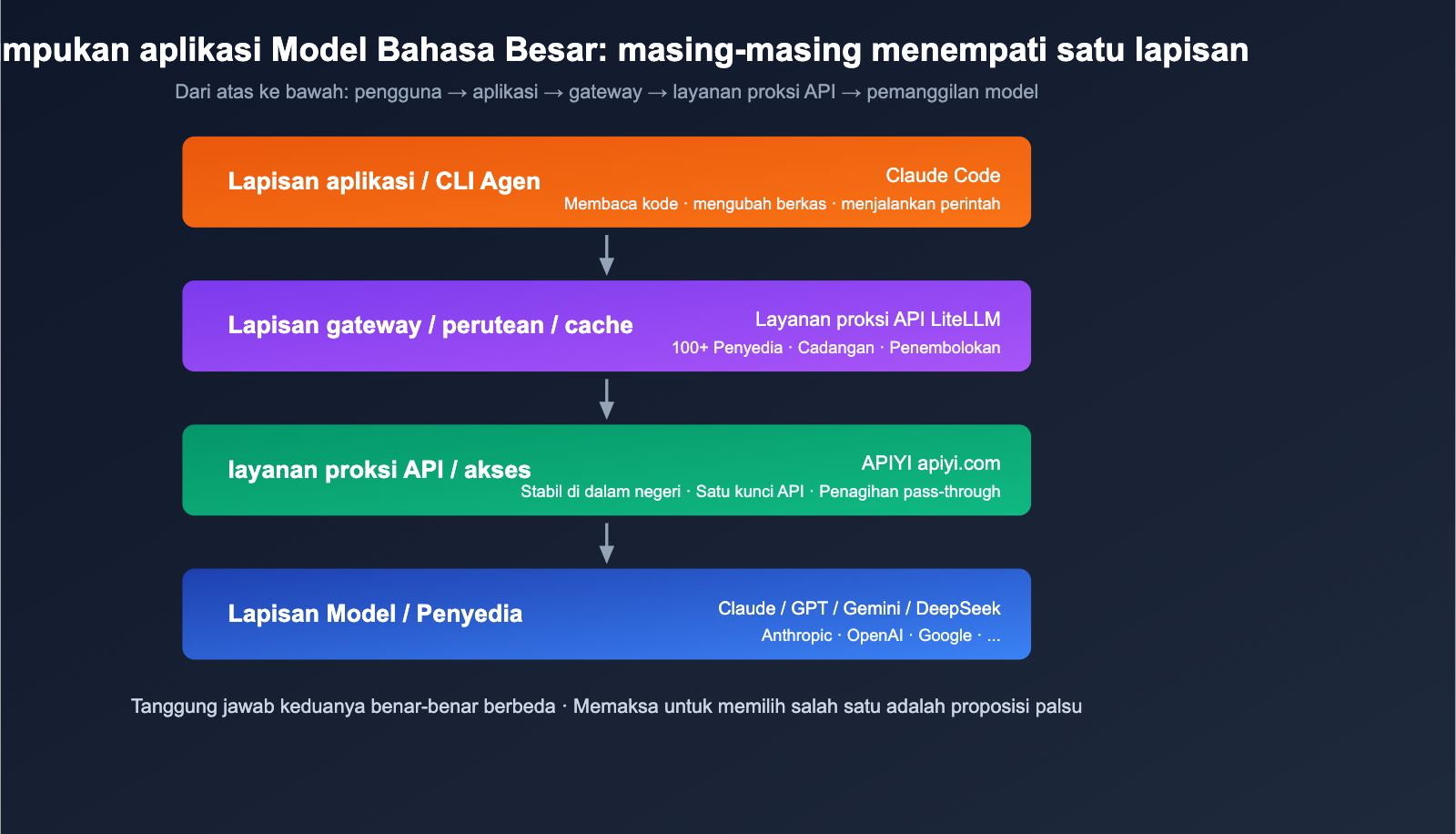
Singkatnya: LiteLLM adalah "pipa air", sedangkan Claude Code adalah "keran yang dipasang di pipa tersebut".
Perbedaan 2: Cakupan Model yang Didukung
| Dimensi | LiteLLM | Claude Code |
|---|---|---|
| Dukungan Default | OpenAI, Anthropic, Google, Cohere, Bedrock, Azure, HuggingFace, Ollama, vLLM, dll (100+) | Hanya seri Anthropic Claude (Opus / Sonnet / Haiku) |
| Endpoint Kustom | ✅ Endpoint apa pun yang kompatibel dengan OpenAI | ⚠️ Melalui ANTHROPIC_BASE_URL ke LiteLLM |
| Model Lokal | ✅ DeepSeek / Qwen / Kimi / GLM, dll | ❌ Tidak didukung secara default |
Perhatikan bahwa Claude Code juga dapat menggunakan model lain secara "tidak langsung" dengan mengarahkan ANTHROPIC_BASE_URL ke LiteLLM Proxy. Namun, pada dasarnya LiteLLM yang melakukan pekerjaan penerjemahan — ini membuktikan bahwa keduanya saling melengkapi.
Perbedaan 3: Antarmuka Pengguna dan Pengalaman Pengembangan
Pengalaman pengembangan LiteLLM:
- SDK untuk pengembang aplikasi.
- Dapat diintegrasikan ke dalam proyek Python apa pun.
- Menyediakan endpoint HTTP yang kompatibel dengan OpenAI untuk frontend, Node.js, atau Curl.
Pengalaman pengembangan Claude Code:
- CLI mandiri, mirip dengan perintah
claude. - Berdialog langsung dengan basis kode Anda di terminal.
- Dilengkapi alat baca/tulis file, eksekusi Bash, Git, dll.
- Pengalaman penggunaan alat (Tool Use) yang dioptimalkan untuk "berpikir sambil mengubah kode".
Perbedaan 4: Biaya Deployment dan Operasional
| Proyek | LiteLLM | Claude Code |
|---|---|---|
| Instalasi | pip install litellm |
npm i -g @anthropic-ai/claude-code |
| Perlu Layanan | Perlu untuk mode Proxy | Tidak, CLI lokal |
| Perlu Konfigurasi YAML | Perlu untuk mode Proxy | Umumnya tidak |
| Berbagi Tim | ✅ Satu layanan Proxy untuk tim | ❌ Satu CLI per orang |
| Penagihan Terpusat | ✅ Penagihan terpadu di lapisan gateway | ❌ Penagihan per akun |
Perbedaan 5: Ekosistem dan Kemampuan Ekspansi
Ekosistem LiteLLM:
- Logging: Langfuse, Helicone, Sentry, OpenTelemetry.
- Guardrails: Audit konten bawaan.
- Routing: Load balancing, fallback, pembatasan kecepatan (rate limiting).
- Pelacakan biaya: Berdasarkan model, pengguna, dan kunci API.
Ekosistem Claude Code:
- Hooks: Kustomisasi perintah.
- MCP: Integrasi alat eksternal melalui Model Context Protocol.
- Integrasi IDE: VS Code, JetBrains.
- Terikat erat dengan kemampuan pemanggilan alat Anthropic.
Apakah LiteLLM Mendukung Penagihan Cache Petunjuk (Prompt Caching)?

Ini adalah pertanyaan yang paling sering diajukan pengembang. Kesimpulan langsung: Mendukung, dan menjadi fitur utama.
Matriks Dukungan
Dokumentasi resmi LiteLLM dengan jelas mencantumkan bahwa prompt caching didukung secara asli pada 6 penyedia berikut:
| Penyedia | Awalan LiteLLM | Cara Pemicu Cache | Keunggulan Harga |
|---|---|---|---|
| Anthropic | anthropic/ |
Eksplisit cache_control: {"type": "ephemeral"} |
Tulis 1.25x, Baca 0.1x (Diskon 90%) |
| OpenAI | openai/ |
Cache otomatis (>1024 token) | Diskon otomatis 50% |
| Google AI Studio | gemini/ |
Eksplisit cache_control |
Konversi otomatis ke Context Caching API |
| Vertex AI | vertex_ai/ |
Eksplisit cache_control |
Sama seperti di atas |
| Bedrock | bedrock/ |
Tersedia jika model mendukung | Mengikuti harga model |
| DeepSeek | deepseek/ |
Cache otomatis | Diskon otomatis |
Contoh Kode: Cache Anthropic
import litellm
response = litellm.completion(
model="anthropic/claude-opus-4-6",
messages=[
{
"role": "system",
"content": [
{
"type": "text",
"text": "Anda adalah insinyur Python senior... (system prompt panjang)",
"cache_control": {"type": "ephemeral"}, # Kunci: Menandai untuk di-cache
}
],
},
{"role": "user", "content": "Tolong tinjau kode ini"},
],
)
# Penggunaan cache dapat dilihat di response.usage
print(response.usage)
# {
# "prompt_tokens": 1234,
# "cache_creation_input_tokens": 800, # Jumlah token yang ditulis ke cache
# "cache_read_input_tokens": 0, # Panggilan kedua akan menjadi 800
# "completion_tokens": 256,
# }
🎯 Saran Praktis: Prompt caching Anthropic sangat hemat biaya untuk system prompt yang panjang dan konteks berulang — pembacaan cache hanya 10% dari harga normal. Kami menyarankan untuk mengaktifkannya secara default pada skenario seperti Agen alur panjang, RAG (Retrieval-Augmented Generation), dan tinjauan kode. Jika Anda ingin memanggil Claude Opus 4.6 / Sonnet 4.6 secara stabil di Indonesia dan menikmati diskon prompt caching, Anda dapat mengaksesnya melalui APIYI (apiyi.com), yang meneruskan bidang penggunaan terkait cache secara utuh.
Auto-Inject Cache Control (Cache Otomatis)
Jika Anda tidak ingin menambahkan cache_control ke setiap pesan secara manual, LiteLLM menyediakan injeksi otomatis:
response = litellm.completion(
model="anthropic/claude-opus-4-6",
messages=[...],
cache_control_injection_points=[
{"location": "message", "role": "system"} # Otomatis menambahkan cache ke semua pesan system
],
)
Ini sangat ramah untuk kode lama — Anda tidak perlu mengubah struktur pesan untuk menikmati diskon cache sebesar 90%.
"Jebakan" dan Status Penagihan Cache
LiteLLM memang memiliki bug pada awal tahun 2024 (GitHub Issue #5443): pelacakan biaya tidak membedakan dengan benar antara cache_creation_input_tokens dan cache_read_input_tokens, yang menyebabkan penyimpangan penagihan. Namun, pada versi 2025-2026, masalah ini telah diperbaiki secara resmi. Saat ini, LiteLLM menghitung biaya dalam fungsi completion_cost() dengan aturan berikut:
| Tipe Token | Pengali Harga (relatif terhadap harga input) | Keterangan |
|---|---|---|
| Cache Write | 1.25x | Ada biaya tambahan kecil untuk penulisan cache |
| Cache Read | 0.1x | Membaca cache hanya 10% dari harga |
| Input Biasa | 1.0x | Input standar |
| Output | Ditentukan oleh model | Token output |
🛡️ Peringatan Penting: Jika Anda menggunakan layanan proksi API, pastikan layanan tersebut meneruskan bidang
cache_creation_input_tokensdancache_read_input_tokenssecara utuh. Jika tidak, LiteLLM akan menghitungnya sebagai input biasa. APIYI (apiyi.com) telah mendukung penerusan kedua bidang ini secara penuh, sehingga Anda bisa mendapatkan diskon cache yang nyata saat digabungkan dengan LiteLLM.
Skenario Rekomendasi: Kapan Menggunakan LiteLLM vs Claude Code

Skenario 1: Pengembang Individu, Fokus pada Coding
Rekomendasi: Gunakan langsung Claude Code.
Alasannya sederhana—pengalaman Claude dalam skenario coding saat ini masih berada di jajaran teratas; penggunaan tool yang stabil, perubahan file yang akurat, dan manajemen konteks yang baik. Jika Anda bekerja sendiri dan tidak perlu sering berganti model, Claude Code adalah pilihan yang paling praktis. Jika Anda kesulitan mengakses layanan resmi Anthropic di Indonesia, Anda bisa mengarahkan ANTHROPIC_BASE_URL ke layanan proksi API APIYI di apiyi.com, pengalamannya akan tetap sama.
Skenario 2: Tim yang Membangun Aplikasi AI
Rekomendasi: LiteLLM Proxy + Kode Aplikasi.
Alasannya: Anda membutuhkan "penagihan terpadu + perutean multi-model + fallback", yang merupakan kemampuan inti dari LiteLLM Proxy. Claude Code adalah alat CLI dan tidak dirancang untuk berperan sebagai gateway di tingkat aplikasi.
Praktik terbaik:
- Jalankan layanan mandiri LiteLLM Proxy (port 4000).
- Hubungkan semua model dasar melalui APIYI di apiyi.com.
- Tingkat aplikasi hanya memanggil LiteLLM Proxy, sehingga semua model terlihat dengan nama semantik yang konsisten.
Skenario 3: Ingin Pengalaman Claude Code, tapi Perlu Ganti Model
Rekomendasi: Kombinasi Claude Code + LiteLLM.
Ini adalah kombinasi yang paling kuat. Konfigurasinya sangat mudah:
# Jalankan LiteLLM Proxy (mengarahkan ke berbagai model)
litellm --config litellm_config.yaml --port 4000
# Arahkan Claude Code ke LiteLLM
export ANTHROPIC_BASE_URL=http://localhost:4000
export ANTHROPIC_AUTH_TOKEN=sk-litellm-master-xxxx
# Jalankan Claude Code dengan model apa pun
claude --model claude-opus-4-6
claude --model gpt-5 # CLI yang sama, di balik layar menggunakan GPT-5
claude --model gemini-3-pro # CLI yang sama, di balik layar menggunakan Gemini 3 Pro
💡 Nilai Kombinasi: Claude Code memberikan pengalaman coding agent kelas atas, LiteLLM memberikan kebebasan memilih model, dan APIYI di apiyi.com memberikan stabilitas akses di Indonesia. Ketiganya menjalankan perannya masing-masing tanpa saling mengganggu, menjadikannya solusi "Full-stack AI Coding" paling pragmatis di tahun 2026.
Skenario 4: Deployment Produksi Skala Perusahaan
Rekomendasi: LiteLLM Proxy + Langfuse + APIYI.
Dalam skenario perusahaan, Claude Code hanya digunakan sebagai alat lokal pengembang. Untuk lalu lintas produksi yang sebenarnya, Anda memerlukan:
- LiteLLM Proxy sebagai gateway + pembatasan kecepatan (rate limiting) + fallback.
- Langfuse / Helicone untuk logging dan analisis biaya.
- APIYI di apiyi.com untuk akses model dasar dan jaminan stabilitas.
Saran Keputusan: LiteLLM vs Claude Code
Tabel keputusan di bawah ini dapat membantu Anda menentukan pilihan hanya dalam 30 detik.
| Kebutuhan Anda | Solusi yang Direkomendasikan |
|---|---|
| Saya ingin AI membantu menulis kode di terminal | Claude Code |
| Saya ingin memanggil berbagai model dalam aplikasi Python | LiteLLM SDK |
| Tim saya butuh satu pintu masuk LLM yang terpadu | LiteLLM Proxy |
| Saya ingin mengganti model dasar untuk Claude Code | Claude Code + LiteLLM |
| Saya ingin membuat gateway LLM tingkat produksi | LiteLLM Proxy + Monitoring |
| Akses ke model luar negeri tidak stabil di Indonesia | Pilih salah satu + layanan proksi API APIYI apiyi.com |
| Saya ingin menghemat biaya token Anthropic | LiteLLM + prompt caching |
🚀 Saran Terpadu: Apa pun alat yang Anda pilih, menggunakan layanan proksi API APIYI apiyi.com sebagai dasar koneksi adalah opsi paling stabil. LiteLLM dapat diarahkan langsung ke apiyi.com/v1 melalui
api_base, sedangkan Claude Code dapat diarahkan secara tidak langsung melaluiANTHROPIC_BASE_URLmenuju LiteLLM lalu ke apiyi.com. Kedua jalur ini telah terbukti stabil dan andal oleh banyak pengembang.
Pertanyaan Umum (FAQ) LiteLLM vs Claude Code
Q1: Bisakah LiteLLM sepenuhnya menggantikan Claude Code?
Tidak bisa. LiteLLM adalah gateway LLM, bukan alat yang memiliki rantai alat agen seperti "membaca repositori kode + mengubah file secara mandiri + menjalankan Bash" milik Claude Code. Keduanya menyelesaikan masalah di level yang berbeda. Menggunakan LiteLLM untuk menggantikan Claude Code ibarat menggunakan "pabrik pipa air" untuk menggantikan "mesin kopi".
Q2: Bisakah Claude Code sepenuhnya menggantikan LiteLLM?
Juga tidak bisa. Claude Code adalah alat CLI, bukan gateway. Ia tidak memiliki konsep level gateway seperti model_list, router_settings, atau fallbacks, dan tidak bisa dipanggil langsung oleh aplikasi Python atau layanan Web Anda. Jika Anda ingin melakukan "integrasi AI di level aplikasi", Claude Code tidak bisa membantu Anda.
Q3: Apakah LiteLLM benar-benar mendukung penagihan prompt caching Anthropic?
Ya. Sejak tahun 2025, LiteLLM mendukung penuh cache_control: {"type": "ephemeral"}, injeksi titik cache otomatis cache_control_injection_points, serta penerusan penggunaan cache_creation_input_tokens / cache_read_input_tokens dan penagihan completion_cost(). Bug perhitungan biaya yang sempat dilaporkan di Issue #5443 sudah diperbaiki, jadi Anda bisa menggunakannya dengan tenang di versi saat ini.
Q4: Berapa banyak uang yang bisa dihemat dengan menggunakan caching Anthropic melalui LiteLLM?
Hingga ~90%. Aturan harga prompt caching Anthropic adalah: harga penulisan cache sekitar 1,25x dari input standar, dan harga pembacaan cache sekitar 0,1x dari input standar. Dalam skenario penggunaan system prompt panjang yang berulang (seperti RAG, tinjauan kode, atau agen alur panjang), penghematan aktual biasanya berkisar antara 50-90%. Jika Anda terhubung melalui APIYI apiyi.com, diskon caching ini akan tercermin sepenuhnya dalam tagihan Anda.
Q5: Apakah hasil kerja Claude Code akan menurun jika dihubungkan ke GPT-5 melalui LiteLLM?
Akan ada perbedaan, tetapi tidak selalu lebih buruk. Petunjuk (prompt) penggunaan alat (Tool Use) pada Claude Code dioptimalkan untuk Claude. Saat beralih ke GPT-5, gaya pemanggilan fungsi dan tindakan pengeditan file mungkin sedikit berbeda. Disarankan untuk menjadikan seri Claude sebagai model utama, dan model lain sebagai cadangan untuk "inspirasi/perbandingan". Mekanisme Fallback LiteLLM memungkinkan Anda untuk secara otomatis turun ke GPT-5 saat Claude mengalami limitasi (rate limit).
Q6: Bagaimana pengembang di Indonesia dapat menggunakan Claude Code + LiteLLM + Anthropic Caching secara optimal?
Solusi paling praktis adalah struktur tiga lapis: Claude Code (CLI) → LiteLLM Proxy (port lokal 4000) → APIYI apiyi.com (proksi). Claude Code diarahkan ke LiteLLM melalui ANTHROPIC_BASE_URL, LiteLLM mengonfigurasi model sebagai anthropic/claude-opus-4-6 di YAML, dan api_base diarahkan ke apiyi.com/v1. Dengan cara ini, Anda mendapatkan pengalaman coding Claude Code, kemampuan perutean LiteLLM, serta mengatasi masalah jaringan dan penagihan melalui APIYI, sekaligus tetap mendapatkan diskon prompt caching.
Kesimpulan
LiteLLM dan Claude Code bukanlah pesaing, melainkan alat di dua lapisan abstraksi yang berbeda: "lapisan gateway" dan "lapisan aplikasi". Memaksa diri untuk memilih salah satu adalah argumen yang keliru. Pertanyaan yang tepat seharusnya adalah: Kombinasi mana yang paling cocok untuk skenario Anda?
Kembali ke dua pertanyaan di awal artikel ini:
- Mana yang lebih baik? — Tergantung skenarionya. Gunakan Claude Code untuk coding personal, gunakan LiteLLM untuk pengembangan aplikasi, atau gunakan kombinasi Claude Code + LiteLLM jika Anda membutuhkan keduanya.
- Apakah LiteLLM mendukung penagihan cache? — Mendukung penuh, mencakup 6 penyedia utama: Anthropic, OpenAI, Gemini, Vertex, Bedrock, dan DeepSeek, dengan penghematan biaya token input hingga 90%.
🚀 Saran Tindakan: Jika hari ini Anda ingin membangun alur kerja lengkap "Claude Code + LiteLLM + Caching", cara tercepat adalah: Langkah pertama, daftar dan dapatkan kunci API di APIYI (apiyi.com); langkah kedua, buat proksi lokal menggunakan LiteLLM dan arahkan
api_baseke apiyi.com/v1; langkah ketiga, aturANTHROPIC_BASE_URLdi Claude Code agar mengarah ke LiteLLM lokal Anda. Seluruh alur ini dapat diselesaikan dalam waktu kurang dari 10 menit, dan Anda bisa langsung menikmati efisiensi biaya yang dihasilkan oleh prompt caching.
Penulis: Tim APIYI — Fokus menyediakan akses stabil ke Model Bahasa Besar AI arus utama bagi para pengembang. Kunjungi apiyi.com untuk informasi lebih lanjut.
Referensi
-
Dokumentasi Resmi LiteLLM – Prompt Caching
- Tautan:
docs.litellm.ai/docs/completion/prompt_caching - Penjelasan: Matriks dukungan cache dan contoh kode untuk 6 penyedia utama.
- Tautan:
-
Dokumentasi Resmi LiteLLM – Auto-Inject Cache
- Tautan:
docs.litellm.ai/docs/tutorials/prompt_caching - Penjelasan: Injeksi otomatis
cache_control_injection_points.
- Tautan:
-
Dokumentasi Resmi LiteLLM – Claude Code Quickstart
- Tautan:
docs.litellm.ai/docs/tutorials/claude_responses_api - Penjelasan: Konfigurasi
ANTHROPIC_BASE_URLdan dukungan konteks 1M.
- Tautan:
-
Dokumentasi Resmi LiteLLM – Anthropic Provider
- Tautan:
docs.litellm.ai/docs/providers/anthropic - Penjelasan: Penjelasan kolom
cache_creation_input_tokens/cache_read_input_tokens.
- Tautan:
-
GitHub Issue #5443 – Cache Cost Calculation
- Tautan:
github.com/BerriAI/litellm/issues/5443 - Penjelasan: Bug perhitungan biaya cache awal dan riwayat perbaikannya.
- Tautan:
-
Repositori Utama GitHub LiteLLM
- Tautan:
github.com/BerriAI/litellm - Penjelasan: Kode sumber, Issue, dan versi terbaru.
- Tautan: