LiteLLM et Claude Code sont deux des outils de développement IA les plus en vogue pour 2025-2026, mais les développeurs les comparent souvent : lequel est le meilleur ? Sont-ils interchangeables ? LiteLLM prend-il réellement en charge la facturation de la mise en cache des invites (prompt caching) ? Cet article compare LiteLLM et Claude Code en se penchant sur leur positionnement, leurs capacités et la gestion de la facturation du cache pour vous donner des conseils clairs.
Valeur ajoutée : Après avoir lu cet article, vous saurez si ces outils sont réellement à choisir "l'un ou l'autre" et comment faire le meilleur choix selon vos besoins.

Aperçu des différences clés : LiteLLM vs Claude Code
Beaucoup considèrent LiteLLM et Claude Code comme des concurrents, mais en réalité, leur positionnement est totalement différent, et ils peuvent même être utilisés ensemble. Voici comment distinguer leur essence en une phrase :
- LiteLLM = Passerelle LLM / couche de proxy, permettant d'appeler plus de 100 modèles avec un seul code.
- Claude Code = CLI de codage agentique officiel d'Anthropic, spécialisé dans "l'utilisation de Claude pour modifier votre base de code".
| Dimension de comparaison | LiteLLM | Claude Code |
|---|---|---|
| Format du produit | SDK Python + serveur Proxy | Outil en ligne de commande (CLI) |
| Positionnement clé | Passerelle LLM universelle / routage de modèles | Assistant de codage agentique |
| Modèles pris en charge | 100+ (OpenAI/Anthropic/Gemini/Bedrock/Vertex, etc.) | Par défaut, uniquement la gamme Claude |
| Utilisateurs types | Ingénieurs plateforme, développeurs d'applications IA | Développeurs individuels, scénarios de codage |
| Open Source | ✅ Oui (BerriAI/litellm) | CLI propriétaire |
| Interchangeables ? | ❌ Non | ❌ Non |
| Utilisables ensemble ? | ✅ Oui (LiteLLM derrière Claude Code) | ✅ Oui (LiteLLM pour changer le modèle sous-jacent) |
| Meilleur partenaire | Utilisation avec APIYI (apiyi.com) pour un proxy stable | Utilisation avec LiteLLM pour basculer entre les modèles |
💡 Conclusion rapide : Si vous vous demandez "lequel est le meilleur", il est fort probable que vous ayez besoin des deux : Claude Code comme agent de codage, LiteLLM comme point d'entrée unifié, le tout connecté via APIYI (apiyi.com) pour accéder aux modèles internationaux. C'est la stack la plus courante en 2026.
5 différences majeures entre LiteLLM et Claude Code
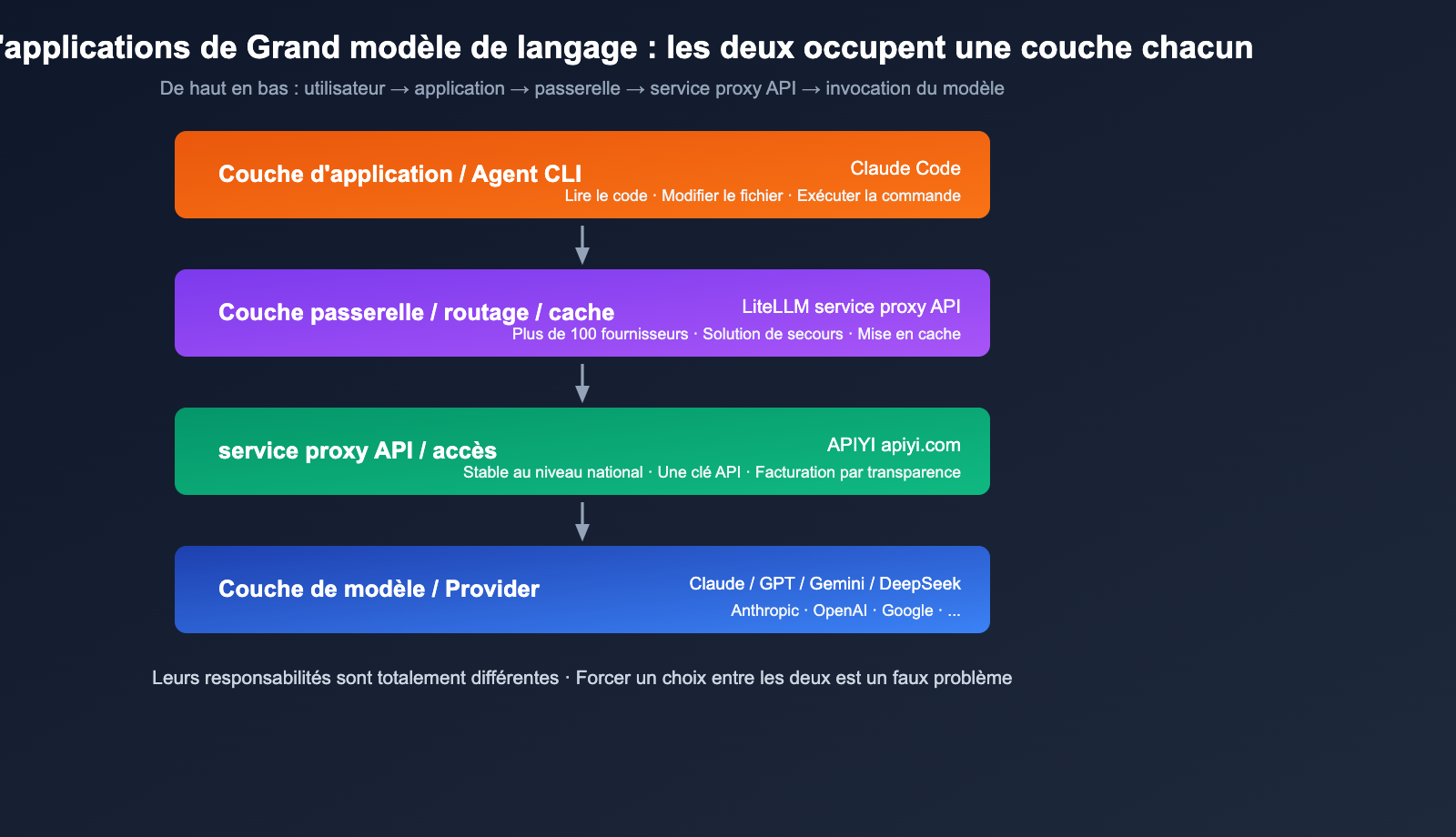
Différence 1 : Positionnement (Passerelle vs Agent CLI)
Le positionnement de LiteLLM : Une passerelle LLM open-source conçue pour "appeler n'importe quel modèle avec un format compatible OpenAI". Elle se présente sous deux formes :
- SDK Python :
litellm.completion(model="..."), pour les développeurs qui créent des applications. - Serveur Proxy :
litellm --config config.yaml, exécuté comme un service indépendant pour le partage en équipe.
Le positionnement de Claude Code : Un CLI de codage agentique lancé officiellement par Anthropic, conçu pour "laisser Claude lire, modifier et exécuter des commandes directement dans votre terminal". C'est un produit de couche applicative qui utilise l'API Messages d'Anthropic en arrière-plan.
En résumé : LiteLLM est le "tuyau", Claude Code est le "robinet installé sur le tuyau".
Différence 2 : Gamme de modèles pris en charge
| Dimension | LiteLLM | Claude Code |
|---|---|---|
| Support par défaut | OpenAI, Anthropic, Google, Cohere, Bedrock, Azure, HuggingFace, Ollama, vLLM, etc. (100+) | Uniquement la famille Anthropic Claude (Opus / Sonnet / Haiku) |
| Points de terminaison personnalisés | ✅ N'importe quel point de terminaison compatible OpenAI | ⚠️ Via ANTHROPIC_BASE_URL vers LiteLLM |
| Modèles locaux/chinois | ✅ DeepSeek / Qwen / Kimi / GLM, etc. | ❌ Non supporté par défaut |
Notez que Claude Code peut également utiliser d'autres modèles "indirectement" en configurant ANTHROPIC_BASE_URL vers un proxy LiteLLM, mais c'est essentiellement LiteLLM qui effectue le travail de traduction — ce qui prouve que les deux sont complémentaires.
Différence 3 : Interface utilisateur et expérience de développement
Expérience de développement avec LiteLLM :
- SDK destiné aux développeurs d'applications.
- Intégrable dans n'importe quel projet Python.
- Fournit des points de terminaison HTTP compatibles OpenAI pour le frontend, Node.js, Curl, etc.
Expérience de développement avec Claude Code :
- Un CLI autonome, similaire à la commande
claude. - Dialogue directement avec votre base de code dans le terminal.
- Outils intégrés pour la lecture/écriture de fichiers, exécution Bash, Git, etc.
- Expérience optimisée d'utilisation d'outils, "réfléchir tout en modifiant".
Différence 4 : Coûts de déploiement et de maintenance
| Projet | LiteLLM | Claude Code |
|---|---|---|
| Installation | pip install litellm |
npm i -g @anthropic-ai/claude-code |
| Service requis | Oui (mode Proxy) | Non, CLI local |
| Configuration YAML | Oui (mode Proxy) | Généralement non |
| Partage en équipe | ✅ Un service Proxy partagé | ❌ Un CLI par personne |
| Facturation centralisée | ✅ Facturation unifiée au niveau de la passerelle | ❌ Facturation par compte |
Différence 5 : Écosystème et capacités d'extension
Écosystème LiteLLM :
- Journalisation (Logging) : Langfuse, Helicone, Sentry, OpenTelemetry.
- Garde-fous (Guardrails) : Modération de contenu intégrée.
- Routage : Équilibrage de charge, repli (fallback), limitation de débit.
- Suivi des coûts : Par modèle, par utilisateur, par clé API.
Écosystème Claude Code :
- Hooks : Crochets de commande personnalisés.
- MCP : Accès aux outils externes via le protocole de contexte de modèle (Model Context Protocol).
- Intégration IDE : VS Code, JetBrains.
- Intégration étroite avec les capacités d'appel d'outils d'Anthropic.
LiteLLM prend-il en charge la facturation du cache (Prompt Caching) ?
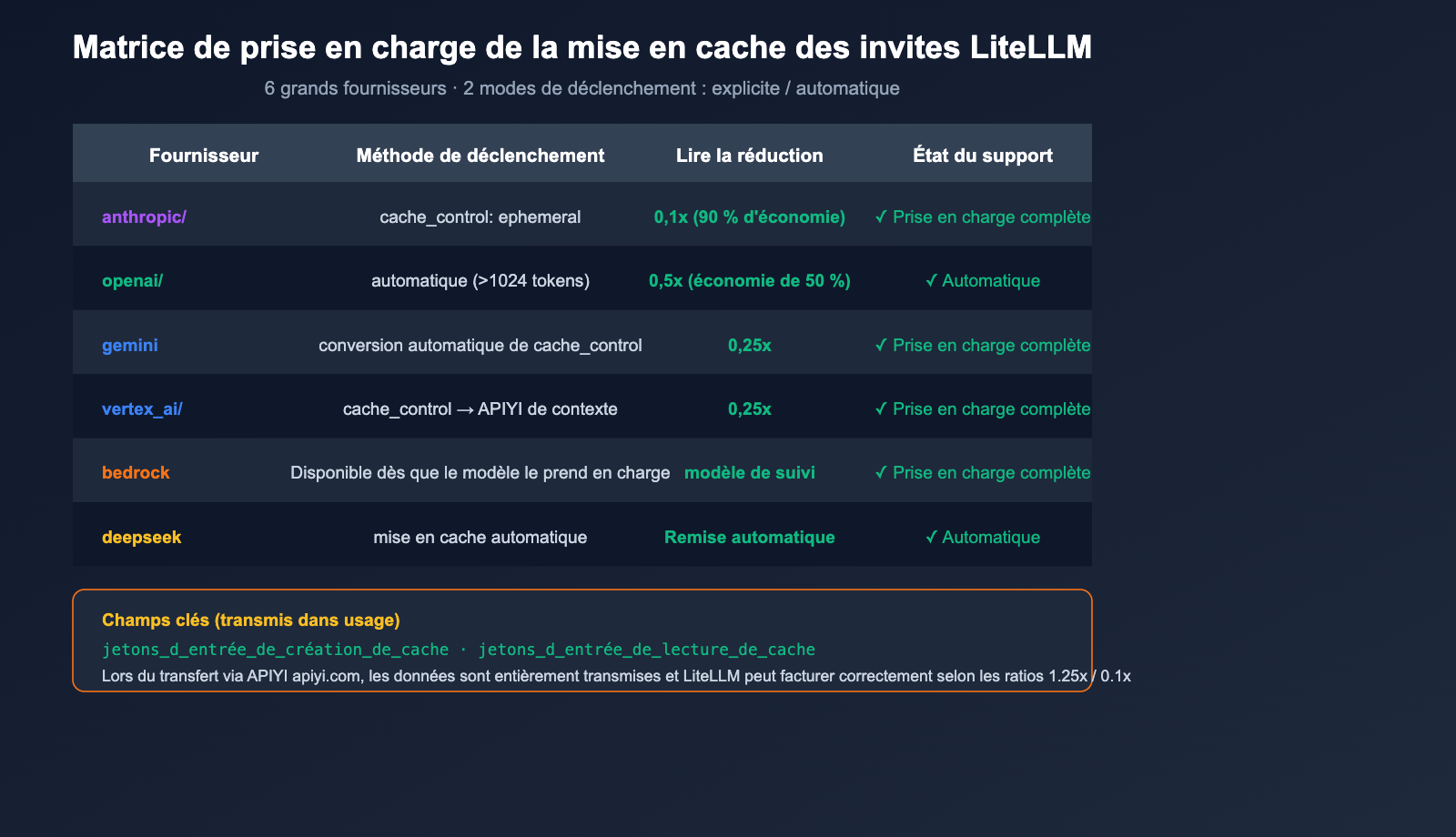
C'est une question cruciale pour les développeurs. Réponse courte : Oui, c'est une fonctionnalité de premier ordre.
Matrice de support
La documentation officielle de LiteLLM indique clairement que le prompt caching est nativement pris en charge par les 6 fournisseurs majeurs suivants :
| Fournisseur | Préfixe LiteLLM | Déclenchement du cache | Avantage tarifaire |
|---|---|---|---|
| Anthropic | anthropic/ |
Explicite cache_control: {"type": "ephemeral"} |
Écriture 1.25x, Lecture 0.1x (90% de remise) |
| OpenAI | openai/ |
Cache automatique (>1024 tokens) | 50% de remise automatique |
| Google AI Studio | gemini/ |
Explicite cache_control |
Conversion automatique vers Context Caching API |
| Vertex AI | vertex_ai/ |
Explicite cache_control |
Idem |
| Bedrock | bedrock/ |
Disponible si supporté par le modèle | Suit la tarification du modèle |
| DeepSeek | deepseek/ |
Cache automatique | Remise automatique |
Exemple de code : Cache Anthropic
import litellm
response = litellm.completion(
model="anthropic/claude-opus-4-6",
messages=[
{
"role": "system",
"content": [
{
"type": "text",
"text": "Tu es un ingénieur Python senior... (long system prompt)",
"cache_control": {"type": "ephemeral"}, # Clé : marquage pour mise en cache
}
],
},
{"role": "user", "content": "Veuillez examiner ce code"},
],
)
# L'utilisation du cache est visible dans response.usage
print(response.usage)
# {
# "prompt_tokens": 1234,
# "cache_creation_input_tokens": 800, # Tokens écrits dans le cache
# "cache_read_input_tokens": 0, # Deviendra 800 lors du second appel
# "completion_tokens": 256,
# }
🎯 Conseil pratique : Le prompt caching d'Anthropic est extrêmement rentable pour les longs prompts système et les contextes répétitifs — la lecture du cache ne coûte que 10 % du prix initial. Nous recommandons de l'activer par défaut pour les agents à long flux, la RAG (génération augmentée par récupération) et la revue de code. Si vous souhaitez appeler Claude Opus 4.6 / Sonnet 4.6 de manière stable et profiter des remises, vous pouvez passer par APIYI (apiyi.com), qui transmet intégralement les champs d'utilisation liés au cache.
Auto-Inject Cache Control (Cache automatique)
Si vous ne voulez pas ajouter manuellement cache_control à chaque message, LiteLLM propose une injection automatique :
response = litellm.completion(
model="anthropic/claude-opus-4-6",
messages=[...],
cache_control_injection_points=[
{"location": "message", "role": "system"} # Ajoute automatiquement le cache à tous les messages système
],
)
C'est très pratique pour intégrer du code existant — aucune modification de la structure des messages n'est nécessaire pour bénéficier de 90 % de remise.
Les "pièges" et l'état actuel de la facturation du cache
LiteLLM a connu un bug au début (2024, GitHub Issue #5443) où le suivi des coûts ne distinguait pas correctement cache_creation_input_tokens et cache_read_input_tokens, entraînant des erreurs de facturation. Cependant, dans les versions 2025-2026, cela a été corrigé par l'équipe officielle. Actuellement, LiteLLM calcule les coûts dans la fonction completion_cost() selon les règles suivantes :
| Type de Token | Multiplicateur de prix (relatif au prix d'entrée) | Remarque |
|---|---|---|
| Écriture Cache | 1.25x | Frais supplémentaires légers pour l'écriture |
| Lecture Cache | 0.1x | Lecture à 10% du prix seulement |
| Entrée standard | 1.0x | Entrée standard |
| Sortie | Défini par le modèle | Token de sortie |
🛡️ Note importante : Si vous utilisez un service proxy API, assurez-vous qu'il transmet correctement les champs
cache_creation_input_tokensetcache_read_input_tokens, sinon LiteLLM calculera les coûts comme une entrée standard. APIYI (apiyi.com) prend en charge la transmission complète de ces champs, vous permettant d'obtenir les remises réelles avec LiteLLM.
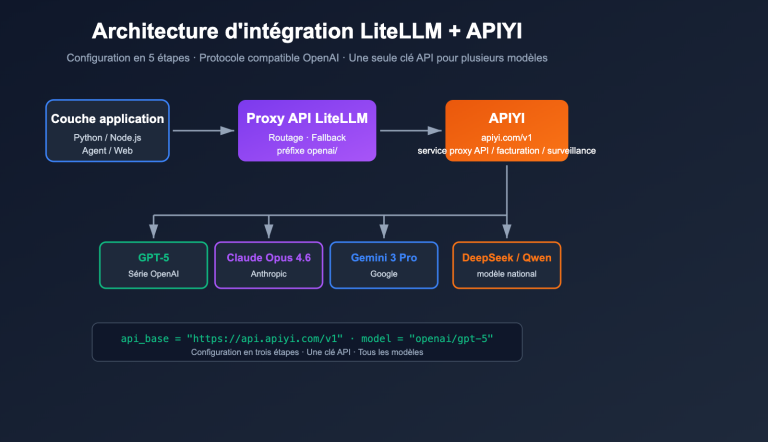
title: "Guide de scénarios : Quand choisir LiteLLM ou Claude Code"
Guide de scénarios : Quand choisir LiteLLM ou Claude Code

Scénario 1 : Développeur solo, axé sur le code
Recommandation : Utilisez directement Claude Code.
La raison est simple : l'expérience de Claude en matière de codage reste actuellement au sommet. L'utilisation des outils est stable, les modifications de fichiers sont précises et la gestion de la fenêtre de contexte est excellente. Si vous travaillez seul et que vous n'avez pas besoin de changer de modèle, Claude Code est le choix le plus serein. Si l'accès aux services officiels d'Anthropic est difficile depuis la Chine, vous pouvez rediriger ANTHROPIC_BASE_URL vers le service proxy API APIYI (apiyi.com) pour une expérience identique.
Scénario 2 : Équipes développant des applications IA
Recommandation : LiteLLM Proxy + code applicatif.
Raison : Vous avez besoin d'une "facturation unifiée + routage multi-modèles + secours (fallback)", ce qui constitue le cœur de métier de LiteLLM Proxy. Claude Code est un outil CLI et ne peut pas assumer le rôle de passerelle au niveau de l'application.
Bonnes pratiques :
- Exécutez un service indépendant LiteLLM Proxy (port 4000).
- Connectez tous les modèles sous-jacents via APIYI (apiyi.com).
- La couche applicative n'appelle que le LiteLLM Proxy, en utilisant des noms de modèles sémantiques.
Scénario 3 : Besoin de l'expérience Claude Code tout en changeant de modèle
Recommandation : Combinaison Claude Code + LiteLLM.
C'est la combinaison la plus puissante. La configuration est très simple :
# Lancer LiteLLM Proxy (pointant vers plusieurs modèles)
litellm --config litellm_config.yaml --port 4000
# Faire passer Claude Code par LiteLLM
export ANTHROPIC_BASE_URL=http://localhost:4000
export ANTHROPIC_AUTH_TOKEN=sk-litellm-master-xxxx
# Lancer Claude Code avec n'importe quel modèle
claude --model claude-opus-4-6
claude --model gpt-5 # Même CLI, avec GPT-5 en arrière-plan
claude --model gemini-3-pro # Même CLI, avec Gemini 3 Pro en arrière-plan
💡 Valeur ajoutée : Claude Code offre une expérience d'agent de codage de premier ordre, LiteLLM apporte la liberté de choix des modèles, et APIYI (apiyi.com) assure un relais stable. Chacun joue son rôle sans interférence, constituant la solution d'IA "full-stack" la plus pragmatique pour 2026.
Scénario 4 : Déploiement en production au niveau entreprise
Recommandation : LiteLLM Proxy + Langfuse + APIYI.
Dans un contexte d'entreprise, Claude Code n'est utilisé que comme outil local pour les développeurs. Le flux de production réel nécessite :
- LiteLLM Proxy pour la passerelle, la limitation de débit et le secours (fallback).
- Langfuse / Helicone pour la journalisation et l'analyse des coûts.
- APIYI (apiyi.com) pour l'accès aux modèles sous-jacents et la garantie de stabilité.
Conseils de décision : LiteLLM vs Claude Code
Ce tableau de décision vous aidera à faire votre choix en 30 secondes.
| Vos besoins | Solution recommandée |
|---|---|
| Je veux que l'IA modifie mon code dans le terminal | Claude Code |
| Je veux invoquer plusieurs modèles dans une application Python | SDK LiteLLM |
| Mon équipe a besoin d'une passerelle LLM unifiée | Proxy LiteLLM |
| Je veux changer le modèle sous-jacent de Claude Code | Claude Code + LiteLLM |
| Je veux créer une passerelle LLM de niveau production | Proxy LiteLLM + monitoring |
| L'accès aux modèles étrangers est instable depuis la Chine | N'importe lequel + service proxy API APIYI (apiyi.com) |
| Je souhaite économiser sur les jetons Anthropic | LiteLLM + mise en cache des invites |
🚀 Conseil unifié : Quel que soit l'outil choisi, l'utilisation de APIYI (apiyi.com) comme backend API est l'option la plus stable. LiteLLM peut pointer directement vers apiyi.com/v1 via
api_base, et Claude Code peut passer par LiteLLM viaANTHROPIC_BASE_URLpour atteindre apiyi.com. Ces deux chemins ont été largement validés par les développeurs pour leur stabilité.
Questions fréquentes sur LiteLLM vs Claude Code
Q1 : LiteLLM peut-il remplacer complètement Claude Code ?
Non. LiteLLM est une passerelle LLM ; il ne dispose pas de la chaîne d'outils "Agent" de Claude Code (lecture de votre base de code + modification autonome de fichiers + exécution Bash). Les deux résolvent des problèmes à des niveaux différents. Remplacer Claude Code par LiteLLM reviendrait à remplacer une "machine à café" par une "usine de tuyauterie".
Q2 : Claude Code peut-il remplacer complètement LiteLLM ?
Non plus. Claude Code est un outil CLI, pas une passerelle. Il ne possède pas les concepts de niveau passerelle tels que model_list, router_settings ou les mécanismes de secours (fallbacks), et ne peut pas être appelé directement par votre application Python ou votre service Web. Si vous devez intégrer l'IA au niveau de l'application, Claude Code ne vous aidera pas.
Q3 : LiteLLM prend-il vraiment en charge la facturation de la mise en cache des invites (prompt caching) d’Anthropic ?
Oui. Depuis 2025, LiteLLM prend entièrement en charge cache_control: {"type": "ephemeral"}, l'injection automatique de points de cache cache_control_injection_points, ainsi que la transmission des usages cache_creation_input_tokens / cache_read_input_tokens et la facturation via completion_cost(). Le bug de calcul des coûts mentionné dans l'ancien ticket #5443 a été corrigé ; vous pouvez l'utiliser en toute confiance dans la version actuelle.
Q4 : Combien peut-on économiser en utilisant la mise en cache d’Anthropic via LiteLLM ?
Jusqu'à ~90 %. Les règles tarifaires d'Anthropic pour la mise en cache des invites sont les suivantes : le prix d'écriture en cache est d'environ 1,25x le prix d'entrée standard, et le prix de lecture est d'environ 0,1x. Dans les scénarios où les invites système longues sont réutilisées (comme le RAG, la revue de code ou les agents à long flux), les économies réelles se situent généralement entre 50 et 90 %. Si vous vous connectez via APIYI (apiyi.com), cette remise sur la mise en cache sera intégralement reflétée sur votre facture.
Q5 : Les performances diminuent-elles si Claude Code utilise GPT-5 via LiteLLM ?
Il y aura des différences, mais pas nécessairement une baisse de qualité. Les invites d'utilisation des outils (Tool Use) de Claude Code sont optimisées pour Claude. Lors du passage à GPT-5, le style d'appel de fonction et les actions d'édition de fichiers peuvent varier légèrement. Il est conseillé d'utiliser la série Claude comme modèle principal et les autres modèles comme alternative pour l'inspiration ou la comparaison. Le mécanisme de secours (Fallback) de LiteLLM vous permet de basculer automatiquement vers GPT-5 en cas de limitation de débit sur Claude.
Q6 : Comment les développeurs peuvent-ils utiliser efficacement Claude Code + LiteLLM + Anthropic Caching ?
La solution la plus pragmatique est une structure à trois niveaux : Claude Code (CLI) → Proxy LiteLLM (port local 4000) → APIYI (apiyi.com) (service proxy). Claude Code pointe vers LiteLLM via ANTHROPIC_BASE_URL, LiteLLM configure le modèle dans le YAML sur anthropic/claude-opus-4-6, avec api_base pointant vers apiyi.com/v1. Vous bénéficiez ainsi de l'expérience de codage de Claude Code, de la puissance de routage de LiteLLM, et vous résolvez les problèmes de réseau et de facturation via APIYI, tout en conservant les remises liées à la mise en cache des invites.
Résumé
LiteLLM et Claude Code ne sont pas des produits concurrents, mais des outils situés à deux niveaux d'abstraction différents : la "couche passerelle" et la "couche applicative". Vouloir choisir entre les deux est un faux problème ; la vraie question est : quelle combinaison est la plus adaptée à votre cas d'usage ?
Revenons aux deux questions posées au début de cet article :
- Lequel est le meilleur ? — Cela dépend de votre scénario. Utilisez Claude Code pour le développement personnel, LiteLLM pour le développement d'applications, ou combinez les deux si vous avez besoin des deux approches.
- LiteLLM prend-il en charge la facturation du cache ? — Oui, entièrement. Il couvre les 6 principaux fournisseurs (Anthropic, OpenAI, Gemini, Vertex, Bedrock, DeepSeek), permettant d'économiser jusqu'à 90 % sur les coûts des jetons d'entrée.
🚀 Conseil pratique : Si vous souhaitez mettre en place dès aujourd'hui un flux de travail complet "Claude Code + LiteLLM + Caching", voici le chemin le plus rapide : premièrement, inscrivez-vous sur APIYI (apiyi.com) pour obtenir une clé API ; deuxièmement, configurez un proxy local avec LiteLLM en pointant
api_baseversapiyi.com/v1; troisièmement, configurezANTHROPIC_BASE_URLdans Claude Code pour pointer vers votre instance LiteLLM locale. Toute la chaîne peut être opérationnelle en moins de 10 minutes, vous permettant de profiter immédiatement des avantages tarifaires offerts par la mise en cache des invites.
Auteur : L'équipe APIYI — Spécialisée dans l'accès stable aux principaux grands modèles de langage pour les développeurs. Visitez apiyi.com pour en savoir plus.
Références
-
Documentation officielle de LiteLLM – Mise en cache des invites (Prompt Caching)
- Lien :
docs.litellm.ai/docs/completion/prompt_caching - Description : Matrice de prise en charge du cache pour les 6 principaux fournisseurs et exemples de code.
- Lien :
-
Documentation officielle de LiteLLM – Injection automatique de cache
- Lien :
docs.litellm.ai/docs/tutorials/prompt_caching - Description : Injection automatique via
cache_control_injection_points.
- Lien :
-
Documentation officielle de LiteLLM – Démarrage rapide avec Claude Code
- Lien :
docs.litellm.ai/docs/tutorials/claude_responses_api - Description : Configuration de
ANTHROPIC_BASE_URLet prise en charge d'une fenêtre de contexte de 1M.
- Lien :
-
Documentation officielle de LiteLLM – Fournisseur Anthropic
- Lien :
docs.litellm.ai/docs/providers/anthropic - Description : Explication des champs
cache_creation_input_tokens/cache_read_input_tokens.
- Lien :
-
GitHub Issue #5443 – Calcul des coûts de cache
- Lien :
github.com/BerriAI/litellm/issues/5443 - Description : Historique des bugs de facturation du cache et correctifs associés.
- Lien :
-
Dépôt GitHub principal de LiteLLM
- Lien :
github.com/BerriAI/litellm - Description : Code source, suivi des problèmes (issues) et dernières versions.
- Lien :