Muitos designers, ao terem o primeiro contato com o GPT-Image-2, costumam ter uma dúvida comum: quando envio uma foto e peço para "mudar a cor da roupa da pessoa para azul", a IA está alterando os pixels com precisão, como no Photoshop, ou ela está redesenhando a imagem inteira nos bastidores? A resposta para essa pergunta impacta diretamente como utilizamos as ferramentas de edição de imagem por IA e como interpretamos a previsibilidade dos resultados.
Na verdade, esse é um detalhe técnico frequentemente mal compreendido. Este artigo parte dos princípios de edição de imagem por IA para analisar profundamente o mecanismo de funcionamento de modelos de imagem autorregressivos de nova geração, como o GPT-Image-2 e o Nano Banana, respondendo à questão central de "modificação local versus redesenho" e revelando como eles mantêm uma consistência visual impressionante, mesmo operando sob a premissa de um redesenho completo.
| Pergunta Central | Resposta Intuitiva | Resposta Real |
|---|---|---|
| Método de edição | Cobertura local estilo PS | Redesenho de tokens da imagem inteira |
| Fonte da consistência | Manter pixels não editados | Ancoragem de atenção a características da imagem original |
| Arquitetura principal | Difusão de remoção de ruído | Transformer autorregressivo |
| Edição em múltiplas etapas | Acúmulo fácil de artefatos | GPT-Image-2 sem desvio significativo |
Ao compreender esse princípio, você perceberá que a forma de escrever o comando, o uso de máscaras e as estratégias de envio da imagem de referência ganham novas bases teóricas. Recomendamos que os leitores testem enquanto leem, utilizando a interface do GPT-Image-2 na plataforma APIYI (apiyi.com), para aplicar a teoria na prática.
Princípio de edição de imagem por IA: não é modificação local estilo PS, mas sim redesenho inteligente
Muitos usuários, baseados na experiência de interação com o ChatGPT, assumem que a edição de imagens por IA funciona como uma "modificação local" do Photoshop: o sistema identifica a área que você deseja alterar, cobre alguns pixels na imagem original e deixa o restante intacto. Esse modelo mental é intuitivo, mas está completamente errado.
Todos os modelos de edição de imagem por IA convencionais baseiam-se essencialmente na lógica de "redesenhar". Seja o GPT-Image-2, Nano Banana ou a série Stable Diffusion, todos precisam primeiro codificar a imagem original em algum tipo de representação interna (tokens ou latente), para que o modelo "imagine" a representação interna completa da nova imagem e, finalmente, a decodifique de volta em pixels. Não existe nenhuma etapa de "pintar sobre a imagem original" nesse processo.
É por isso que, às vezes, você pede à IA para mudar apenas a cor de um olho e descobre que os fios de cabelo e a textura do fundo também sofreram mudanças sutis. O modelo não está sendo preguiçoso; ele está, de fato, "redesenhando" a imagem inteira, apenas desenhando a maioria das áreas de forma muito próxima à original.
Então surge a pergunta: se é um redesenho, por que as imagens editadas pelo GPT-Image-2 parecem tão consistentes com a original, permitindo até edições repetidas sem "se perder"? A resposta está na sua arquitetura. Se você deseja verificar esse comportamento em primeira mão, pode chamar o endpoint /v1/images/edits do gpt-image-2 na APIYI (apiyi.com), usando o mesmo comando para editar a mesma imagem repetidamente e observar as mudanças nos detalhes.
Diferenças essenciais entre a modificação local do PS e o redesenho por IA
| Dimensão de comparação | Modificação local do Photoshop | Redesenho inteligente do GPT-Image-2 |
|---|---|---|
| Unidade de operação | Pixels | Tokens visuais (blocos de 8×8 ou 16×16 pixels) |
| Áreas não editadas | Fisicamente inalteradas | Teoricamente reconstruídas após codificação-decodificação |
| Garantia de consistência | 100% (cópia direta dos pixels originais) | Garantida pelo mecanismo de atenção do modelo |
| Compreensão semântica | Nenhuma, apenas valores de pixel | Compreende semântica como "roupa", "fundo", "iluminação" |
| Transição de bordas | Requer suavização manual | Transição natural automática baseada na semântica |
O PS é uma "modificação mecânica" baseada em pixels, enquanto a IA é um "redesenho após compreensão" baseada na semântica. É por isso que a IA consegue realizar edições globais que o PS nunca conseguiria, como "mudar o dia para o crepúsculo" — ela modifica a representação semântica da imagem, não apenas os valores RGB dos pixels.
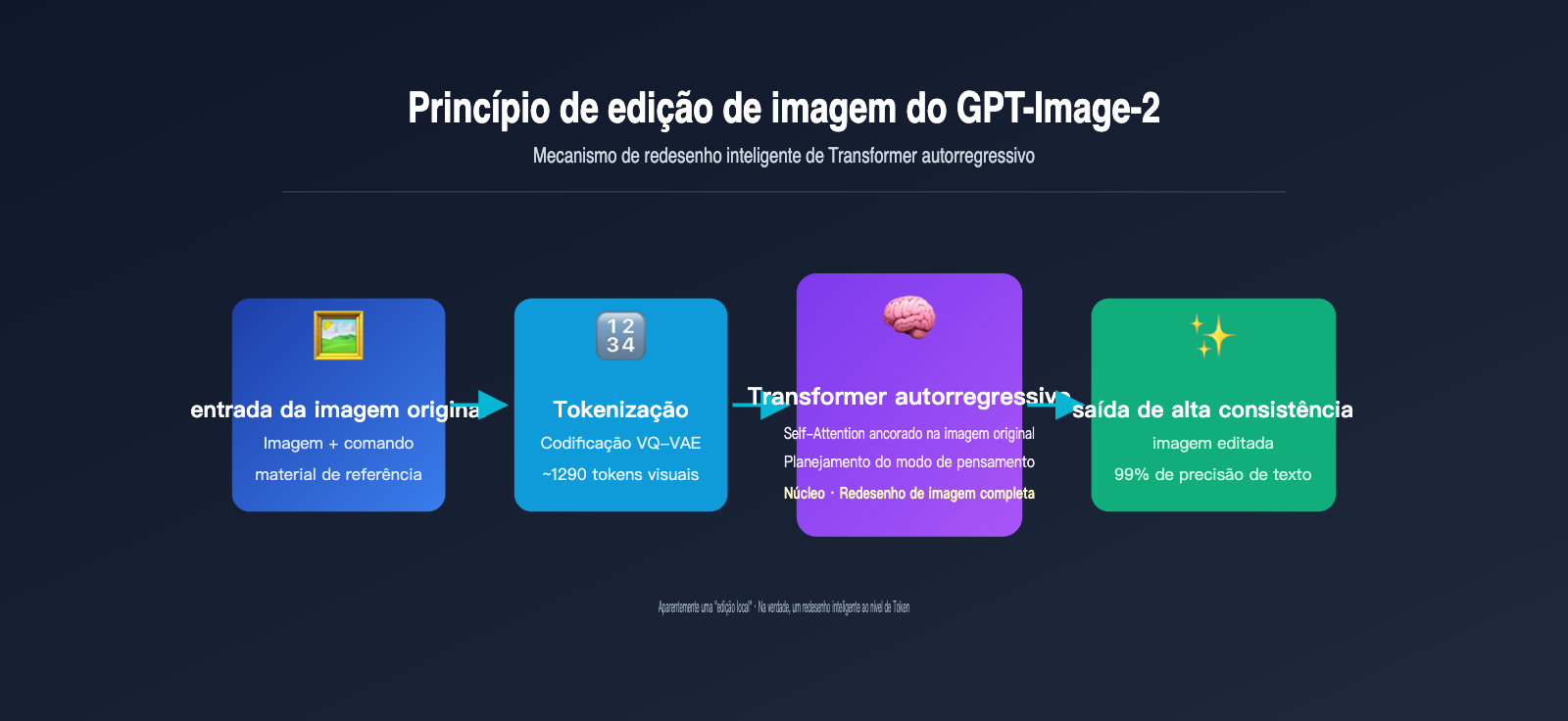
Princípio de edição do gpt-image-2: como o Transformer autorregressivo "entende" a imagem original
Para entender de verdade o princípio de edição do gpt-image-2, não podemos ignorar uma escolha arquitetural fundamental feita pela OpenAI em 21 de abril de 2026, quando lançou este modelo: abandonar os modelos de difusão usados na série DALL-E e adotar um Transformer autorregressivo. Essa decisão foi inspirada diretamente na arquitetura multimodal do GPT-4o.
A geração autorregressiva é, essencialmente, o mesmo mecanismo que o ChatGPT usa para escrever textos — prever o próximo token. A diferença é que, aqui, o "token" não é uma palavra, mas sim um token visual. O modelo faz o seguinte:
- Tokenização da imagem: Através de um mecanismo de discretização semelhante ao VQ-VAE, a imagem é dividida em cerca de 1024 a 1290 tokens visuais, onde cada token corresponde aproximadamente a um bloco de 8×8 ou 16×16 pixels da imagem original.
- Concatenação de sequência: O comando de texto do usuário e os tokens visuais da imagem original são combinados em uma longa sequência e enviados para um Transformer unificado.
- Geração token a token: O modelo prevê cada token visual da imagem de saída um por um, da esquerda para a direita (ou seguindo a ordem de varredura raster). A cada novo token gerado, o modelo consegue "ver" todas as entradas anteriores e o conteúdo já gerado.
- Decodificação para pixels: Após todos os tokens visuais serem gerados, eles são convertidos de volta em uma imagem de pixel final através de um decodificador.
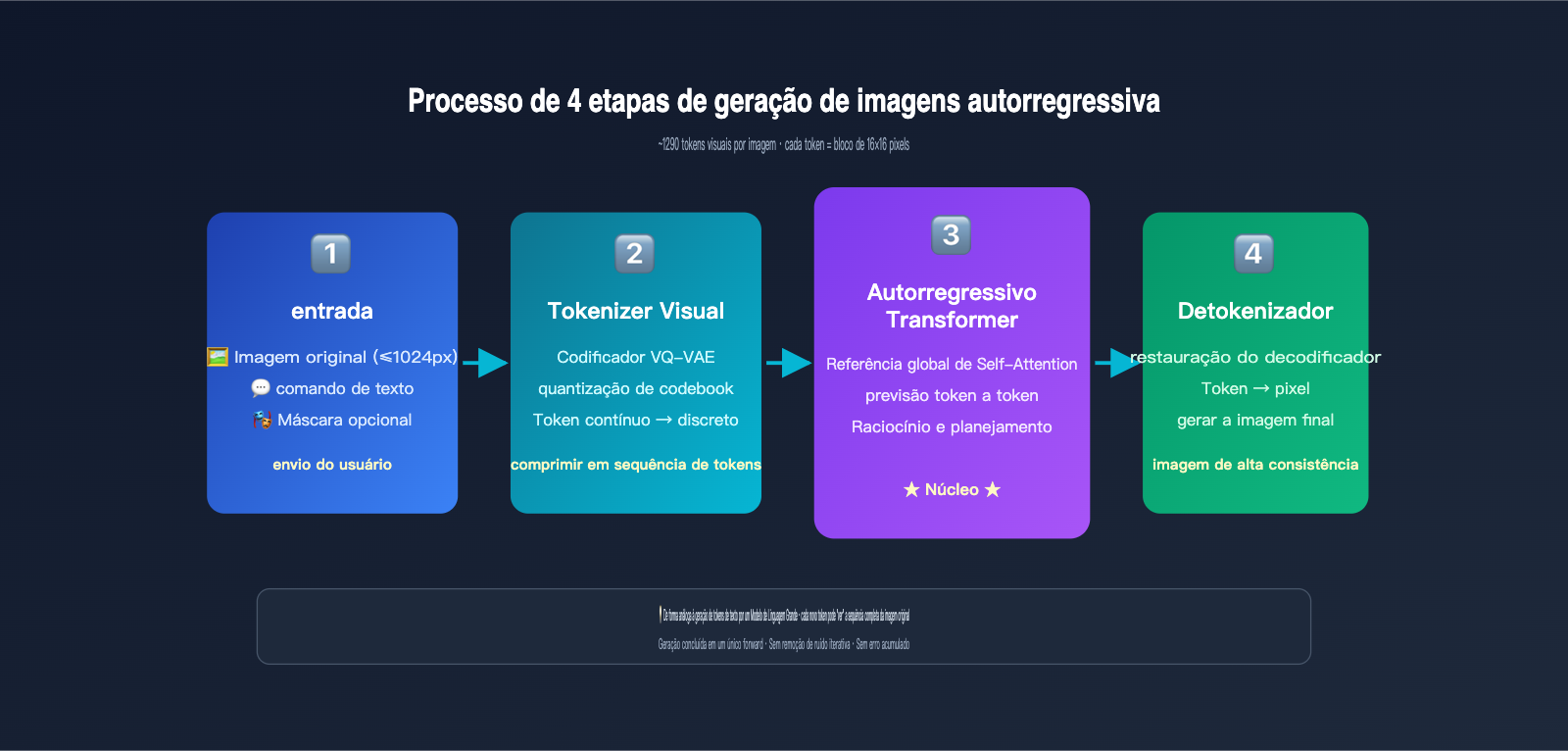
O ponto crucial aqui é: ao gerar uma nova imagem, todos os tokens da imagem original estão no "campo de visão" do GPT-Image-2. Isso é exatamente o mesmo princípio de quando você conversa com o ChatGPT e ele consegue ver todas as mensagens anteriores. O mecanismo de Self-Attention permite que cada novo token gerado "consulte" as características de qualquer parte da imagem original.
A OpenAI também introduziu no GPT-Image-2 um "modo de raciocínio" (Thinking mode), que faz com que o modelo, antes de começar a gerar os tokens visuais, faça uma análise interna para entender: o que o usuário quer mudar, quais partes devem ser mantidas e como o layout espacial deve ser organizado. Isso aumentou ainda mais a precisão na execução de comandos de edição complexos, atingindo 99% de precisão textual e layouts de múltiplos objetos precisos. Se você precisa testar essas capacidades em um ambiente de produção, pode acessar o gpt-image-2 através do APIYI (apiyi.com), que oferece especificações de interface consistentes com a oficial e uma alternância conveniente entre modelos.
Tokenizador visual: o equilíbrio entre compressão e preservação de informações
O tokenizador visual é o gargalo fundamental de todo o sistema de geração de imagens autorregressiva. Ele precisa equilibrar dois objetivos:
- Alta taxa de compressão: quanto menos tokens, mais rápido o Transformer processa e menor o custo.
- Alta qualidade de reconstrução: os pixels decodificados devem restaurar a imagem original o máximo possível, sem perder detalhes.
A abordagem principal é o VQ-VAE (Vector Quantized Variational Autoencoder): um codificador comprime a área da imagem em um vetor contínuo, que é então mapeado para um "código" limitado em um dicionário (codebook) para encontrar o índice do código mais próximo; esse índice é o token. Imagens de 1024×1024 são geralmente comprimidas em cerca de 1024 tokens, com uma densidade de informação extremamente alta.
Como essa compressão é inerentemente com perdas, nenhuma ferramenta de edição de IA consegue "preservar 100% dos valores de pixel das áreas não modificadas da imagem original". Isso nos leva à próxima questão fundamental: a consistência.
O mecanismo central da consistência de imagem em IA: Tokenização visual e ancoragem de atenção
Já que o GPT-Image-2 faz uma redesenho completo da imagem, como a consistência de imagem em IA é realmente alcançada? Por que, ao editar uma foto de retrato, seus traços faciais, tom de pele e penteado não se transformam nos de outra pessoa? A resposta possui quatro camadas.
Primeira camada: A alta abstração dos tokens visuais. Após passar por um tokenizer, a sequência de tokens gerada de um rosto já codifica as características centrais daquela "pessoa" — formato do rosto, proporções faciais, tom de pele, etc. Desde que esses "tokens de identidade" sejam preservados durante a geração da nova imagem, a pessoa não mudará.
Segunda camada: Referência global via Self-Attention. Ao gerar cada novo token, o Transformer autorregressivo calcula o peso de atenção entre ele e todos os tokens de entrada (incluindo os da imagem original). Se o usuário não especificou alterações para uma determinada área, o modelo atribui um peso alto aos tokens correspondentes da imagem original, na prática, "copiando" a fonte.
Terceira camada: Viés indutivo dos dados de treinamento. A OpenAI utilizou uma quantidade massiva de pares "imagem original-imagem editada" para treinar o GPT-Image-2. Durante o treinamento, o modelo aprendeu uma regra implícita: a menos que o comando exija explicitamente o contrário, tente manter as outras áreas inalteradas. Esse viés é consolidado nos pesos e entra em ação naturalmente durante a inferência.
Quarta camada: Planejamento explícito no modo Thinking. O GPT-Image-2 utiliza uma etapa de reflexão interna para organizar "quais áreas precisam ser alteradas e quais devem ser mantidas" antes de iniciar a geração, o que equivale a criar uma lista de preservação antes de começar o trabalho.
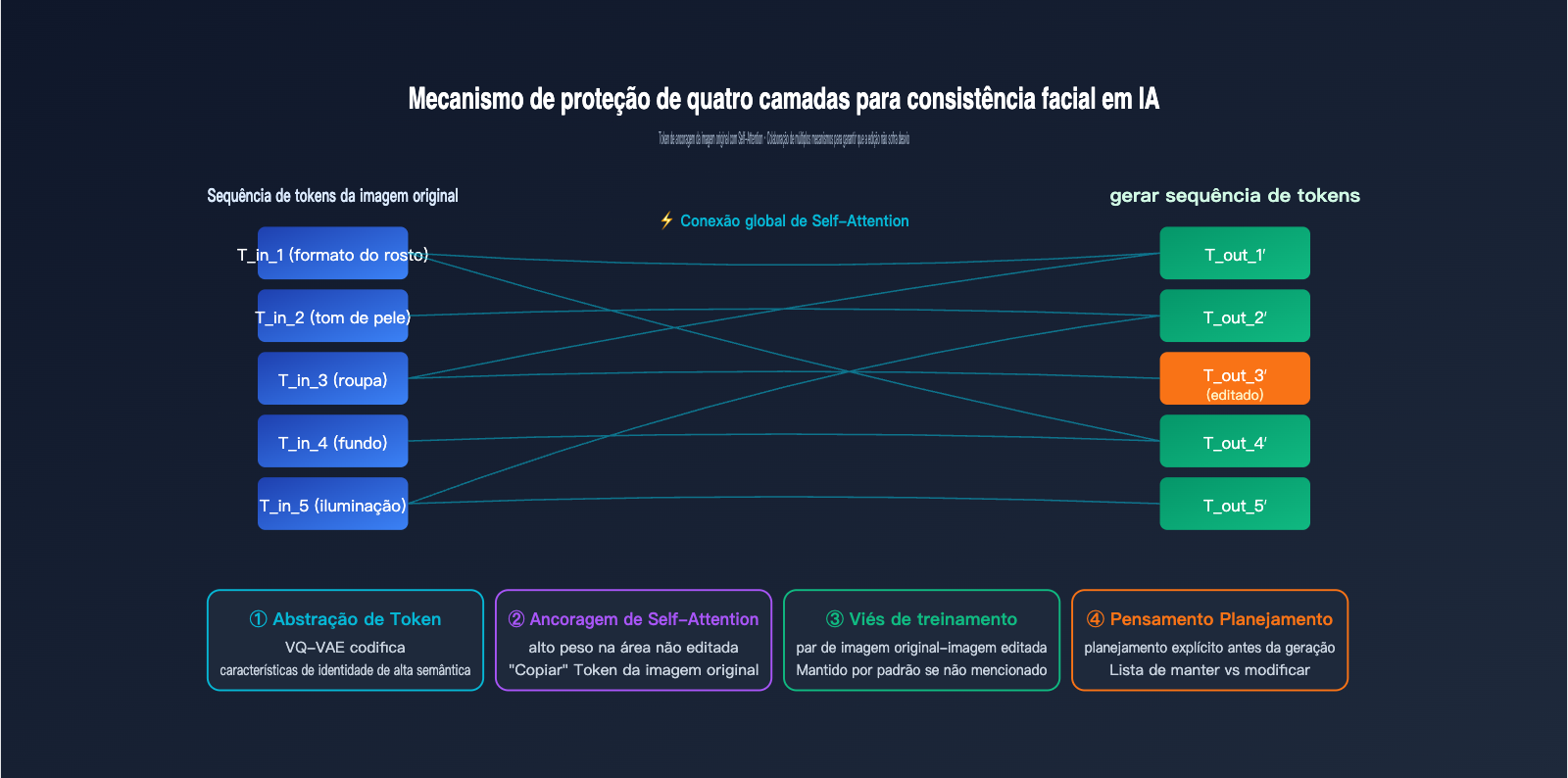
Comparativo das quatro camadas de proteção da consistência
| Camada de Mecanismo | Escopo de Ação | Cenários de Falha |
|---|---|---|
| Abstração de Token | Características de identidade global | Rosto muito distante, resultando em poucos tokens |
| Self-Attention | Ancoragem de detalhes locais | Conflito semântico entre comando e imagem original |
| Viés de Treinamento | Preservação padrão de áreas não mencionadas | Comando excessivamente agressivo |
| Planejamento Thinking | Instruções de edição complexas | Necessidade de múltiplas tentativas e ajustes |
Ao compreender essas quatro camadas de proteção, você conseguirá escrever comandos mais precisos para evitar o "desvio". Por exemplo, em vez de dizer "redesenhe a roupa desta pessoa", prefira "mantenha a identidade da pessoa inalterada, alterando apenas a cor da roupa de branco para azul". Ao testar o GPT-Image-2 na APIYI (apiyi.com), descobrimos que adicionar restrições explícitas, como "mantenha os outros elementos inalterados", faz com que o modo Thinking seja aplicado de forma mais eficaz.
Modo mask: Fazendo o redesenho "fingir" ser uma modificação local
Se o usuário deseja uma experiência de "modificação local" mais determinística, o GPT-Image-2 oferece o parâmetro mask no endpoint /v1/images/edits. O usuário pode enviar uma imagem de máscara binária: a área branca permite que a IA gere conteúdo, enquanto a área preta deve obrigatoriamente manter a imagem original.
No entanto, é importante enfatizar que o modo mask não altera a essência do redesenho. Sua função é adicionar uma restrição rígida durante a geração dos tokens: os tokens correspondentes à área preta devem ser exatamente iguais aos tokens da imagem original. Trata-se de uma "geração com restrições" dentro do framework autorregressivo, e não uma sobreposição de pixels ao estilo Photoshop.
Para entender plenamente as vantagens do GPT-Image-2, precisamos compará-lo sistematicamente com a geração anterior de modelos de difusão (Stable Diffusion, DALL-E 3, Midjourney). Esses dois sistemas possuem diferenças fundamentais em seus princípios de edição de imagem por IA.
O fluxo de trabalho dos modelos de difusão começa com uma imagem de ruído puro, passando por dezenas de iterações de remoção de ruído (denoising) até que a imagem final surja gradualmente. Ao editar, o modelo comprime a imagem original para o espaço latente, adiciona ruído parcial a esse espaço e, em seguida, usa o comando para guiar o processo de remoção de ruído, decodificando o resultado de volta para pixels. O modo de inpainting redefine o latente fora da máscara para o latente original a cada passo, "travando" assim as áreas não editadas.
O fluxo de trabalho dos modelos autorregressivos é completamente diferente: a imagem é codificada em tokens e, em seguida, o modelo prevê a saída token por token, como se estivesse escrevendo um texto. Não há iterações de remoção de ruído, não há ruído latente; a geração é concluída em uma única passagem.
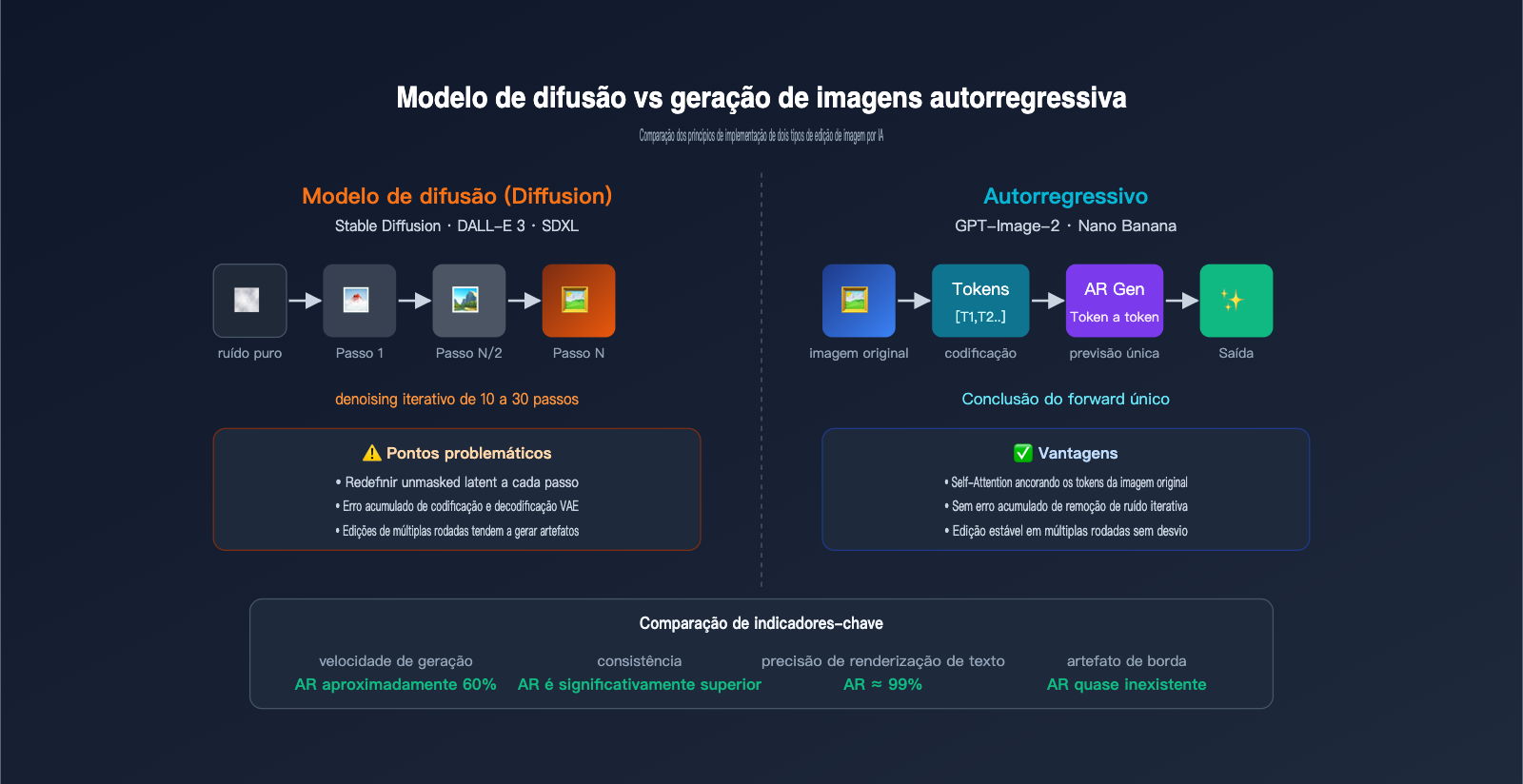
As diferenças de desempenho entre os dois paradigmas em cenários de edição de imagem são enormes, conforme detalhado na tabela abaixo:
| Comparação | Modelos de Difusão (SD/DALL-E 3) | Modelos Autorregressivos (GPT-Image-2/Nano Banana) |
|---|---|---|
| Método de geração | Iteração de remoção de ruído em várias etapas | Predição de sequência de tokens única |
| Implementação de máscara | Redefinição de latente não mascarado a cada passo | Restrição rígida em nível de token |
| Tratamento de bordas | Propensão a artefatos de junção latente | Transição natural (nível semântico) |
| Renderização de texto | Frequentemente falha | Precisão de cerca de 99% |
| Edição multietapas | Perda de recodificação acumulada | Quase sem desvio |
| Comandos complexos | Difícil de posicionar com precisão | Suporta layout de mais de 100 objetos |
| Velocidade | Geralmente 10-30 segundos | Cerca de 60% mais rápido que a difusão |
| Renderização de texto longo | Difícil | Qualquer idioma/script |
O principal problema dos modelos de difusão reside na perda de recodificação da codificação/decodificação VAE — mesmo que, teoricamente, as áreas não mascaradas sejam travadas, a conversão de ida e volta entre o latente e os pixels gera pequenas diferenças de cor. Após várias edições, a perda se acumula em artefatos visíveis a olho nu. O GPT-Image-2 contorna esse problema com uma arquitetura autorregressiva, onde a decodificação de tokens ocorre apenas uma vez.
No entanto, a abordagem autorregressiva também tem seu preço. O custo de geração é maior, principalmente porque o número de tokens é grande e cada token requer um processamento completo do Transformer. Recomendamos o uso do GPT-Image-2 para cenários que buscam consistência extrema e renderização de texto (acessível via APIYI apiyi.com), enquanto a série Stable Diffusion pode ser mantida como um complemento para cenários de alta concorrência sensíveis a custos.
Prática dos Princípios de Edição do GPT-Image-2: Chamadas de API e Otimização de Consistência
Agora que entendemos os princípios de edição do GPT-Image-2, vamos ver como aplicar esse mecanismo na prática. Abaixo, apresento um exemplo mínimo funcional para chamar a interface de edição do GPT-Image-2 através do serviço proxy de API da APIYI:
from openai import OpenAI
client = OpenAI(
api_key="your-apiyi-key",
base_url="https://vip.apiyi.com/v1"
)
with open("portrait.png", "rb") as image_file:
response = client.images.edit(
model="gpt-image-2",
image=image_file,
prompt="Mantenha a identidade da pessoa e o fundo inalterados, altere apenas a cor da camisa de branco para azul escuro",
size="1024x1024",
quality="high"
)
print(response.data[0].url)
Observe a escrita do comando: especifique claramente o que deve ser mantido e o que deve ser modificado. Isso aciona diretamente o modo de "Thinking" (raciocínio) do GPT-Image-2 para planejar a geração conforme suas expectativas. Se precisar de uma edição de área precisa, você pode adicionar o parâmetro mask:
response = client.images.edit(
model="gpt-image-2",
image=open("portrait.png", "rb"),
mask=open("mask.png", "rb"),
prompt="Altere a camisa branca para um terno azul escuro",
size="1024x1024"
)
A mask é um arquivo PNG com as mesmas dimensões; a área branca é o intervalo permitido para modificação, enquanto a área preta força a preservação dos tokens da imagem original.
5 Dicas Práticas para Otimização de Consistência
Para o ajuste fino da consistência de imagens por IA, reunimos 5 recomendações baseadas em testes reais:
- Seja explícito no comando sobre "o que manter": Não diga apenas "mude X", diga "mantenha Y inalterado e mude X".
- Resolução moderada da imagem de referência: A OpenAI recomenda que o lado mais longo da imagem de referência não exceda 1024px; tamanhos muito grandes podem diluir a atenção dos tokens.
- Use a mesma imagem base para edições em várias etapas: Não use o resultado da edição anterior como entrada para a próxima. Em vez disso, baseie-se sempre na imagem original para edições em diferentes dimensões e combine os comandos no final.
- Divida comandos em cenários complexos: Transforme "mude a pessoa para um estilo japonês com fundo de pôr do sol" em dois passos, alterando apenas uma variável por vez.
- Escolha a qualidade "high": A baixa qualidade reduz a quantidade de tokens, o que enfraquece diretamente a consistência.
Equilíbrio entre Preço e Consistência no GPT-Image-2
| Combinação de Parâmetros | Custo por Imagem | Cenário de Aplicação |
|---|---|---|
| 1024×1024 low | $0.006 | Rascunhos criativos/visualização rápida |
| 1024×1024 medium | $0.053 | Imagens para redes sociais |
| 1024×1024 high | $0.211 | Edição de nível comercial/iteração constante |
| 4K high | $0.50+ | Impressão/exibição de alta resolução |
O custo e a consistência estão correlacionados — o modo de alta qualidade aloca mais tokens para o modelo, permitindo naturalmente a preservação de mais características da imagem original. Recomendamos priorizar o modo "high" em ambientes de produção e utilizar a Batch API da APIYI (apiyi.com) para reduzir os custos em até 50%.
FAQ sobre Princípios de Edição de Imagens por IA e Tendências Futuras
Q1: O GPT-Image-2 faz modificações locais como o Photoshop ou redesenha a imagem?
R: Ele redesenha. Todos os modelos de imagem autorregressivos precisam codificar a imagem original em tokens, gerar a sequência completa de tokens de saída e, finalmente, decodificá-la em uma nova imagem. Mesmo com a mask ativada, ela apenas adiciona restrições durante o processo de redesenho, não sendo uma sobreposição real de pixels.
Q2: Já que é um redesenho, por que a imagem editada parece quase idêntica?
R: Isso ocorre devido a quatro mecanismos de consistência: abstração de características dos tokens visuais, referência global da imagem original via Self-Attention, viés indutivo dos dados de treinamento e o planejamento explícito do modo de "Thinking". Esses mecanismos fazem com que a IA "escolha ativamente" preservar as áreas não mencionadas.
Q3: O inpainting de modelos de difusão conta como uma modificação local real?
R: Não. O inpainting do Stable Diffusion também precisa passar as áreas não mascaradas pelo codificador/decodificador VAE, o que gera uma pequena perda de re-codificação. Edições em várias etapas acumulam artefatos visíveis, que é justamente uma das motivações para o GPT-Image-2 adotar a arquitetura autorregressiva. Você pode usar a APIYI (apiyi.com) para chamar ambos os modelos simultaneamente e comparar.
Q4: Por que o GPT-Image-2 pode realizar várias edições sem sofrer deriva (drift)?
R: Porque a arquitetura autorregressiva refere-se à sequência completa de tokens da imagem original a cada geração, sem o erro cumulativo da remoção de ruído iterativa. Combinado com o planejamento explícito de preservação do modo de "Thinking", a estabilidade de edições múltiplas supera em muito os modelos de difusão.
Q5: Devo usar mask ou apenas edição por comando?
R: Priorize o uso de comandos com instruções claras de preservação, o que aproveita o planejamento automático do modo de "Thinking". Use a mask apenas quando as bordas da área a ser modificada forem claras e precisarem de precisão absoluta (como partes específicas do rosto).
Q6: Como será o futuro da edição de imagens por IA?
R: Três tendências: (1) Aumento contínuo da densidade de informações do Tokenizer, reduzindo o número de tokens e custos; (2) Unificação multimodal, onde texto, imagem e vídeo compartilham o mesmo Transformer; (3) Reforço da capacidade de raciocínio (Thinking), suportando cadeias de edição de várias etapas mais longas. Recomendamos acompanhar as atualizações de novos modelos na APIYI (apiyi.com) para avaliar caminhos de atualização em primeira mão.
Conclusão: Entenda os princípios para usar bem as ferramentas
Modelos de imagem autorregressivos como o GPT-Image-2 mudaram nossa percepção sobre "edição de imagens por IA". Eles não são modificações locais ao estilo Photoshop, mas sim um redesenho inteligente baseado em geração de imagens autorregressiva. A consistência vem da colaboração de quatro mecanismos: abstração semântica tokenizada, ancoragem global via Self-Attention, viés de treinamento e o modo de "Thinking".
Ao compreender esses princípios, você conseguirá escrever comandos que realmente acionem o planejamento do "Thinking", evitar armadilhas de edições múltiplas e encontrar o equilíbrio entre custo e qualidade. Recomendamos realizar testes e comparações através da plataforma APIYI (apiyi.com), que suporta chamadas de interface unificadas para diversos modelos convencionais, facilitando a validação rápida de todas as técnicas mencionadas neste artigo.
Este artigo foi escrito pela equipe da APIYI, baseado em materiais oficiais da OpenAI, Google DeepMind e testes práticos. Para chamadas de GPT-Image-2 em ambiente de produção, visite o site oficial da APIYI: apiyi.com para obter a documentação de acesso.