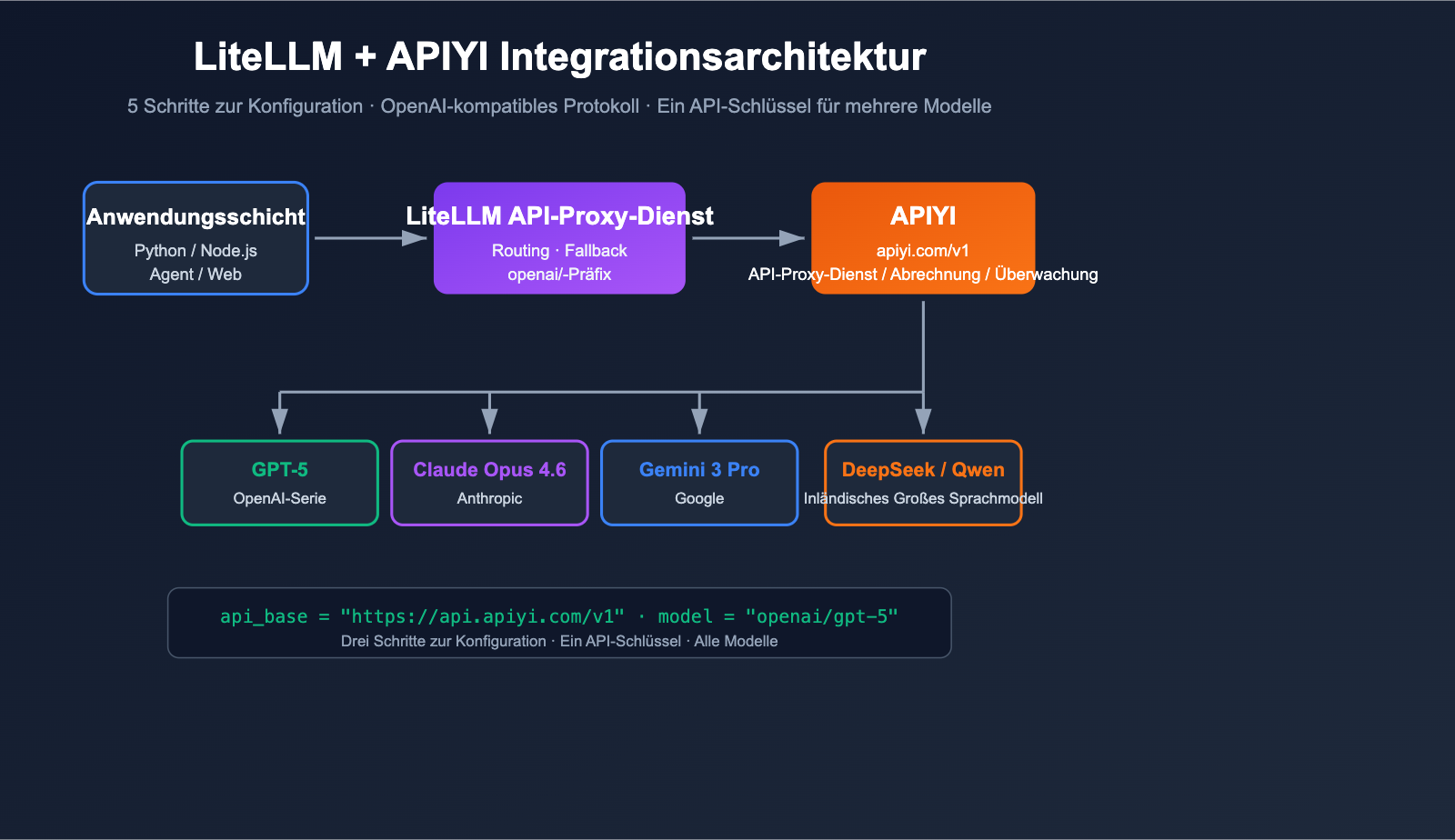
Wie lässt sich LiteLLM dazu bringen, gleichzeitig mehrere Großsprachmodelle wie OpenAI, Claude, Gemini oder DeepSeek zu steuern, ohne an Hürden wie ausländischen Konten, Netzwerkproblemen oder Zahlungsbeschränkungen zu scheitern? Die Antwort lautet: Verbinden Sie LiteLLM mit einem OpenAI-kompatiblen API-Proxy-Dienst. In diesem Artikel zeigen wir Ihnen anhand von LiteLLM + APIYI apiyi.com Schritt für Schritt, wie die Konfiguration funktioniert.
Kernnutzen: Nach dem Lesen dieses Artikels beherrschen Sie die 3 gängigen Methoden zur Konfiguration von LiteLLM mit einem API-Proxy-Dienst (SDK, Proxy YAML, Umgebungsvariablen) und können die Anbindung an APIYI in unter 5 Minuten abschließen.
Kernpunkte der LiteLLM-Konfiguration mit einem API-Proxy-Dienst
LiteLLM ist ein Open-Source-LLM-Gateway bzw. SDK, das darauf ausgelegt ist, über 100 Großsprachmodelle im OpenAI-kompatiblen Format aufzurufen. Es unterstützt von Haus aus jeden "OpenAI-kompatiblen" Endpunkt; Sie müssen lediglich api_base auf den Proxy-Dienst richten und den api_key durch den vom Dienst ausgestellten Schlüssel ersetzen. APIYI apiyi.com ist ein standardmäßiger OpenAI-kompatibler API-Proxy-Dienst, weshalb beide perfekt zusammenpassen.
| Punkt | Beschreibung | Nutzen |
|---|---|---|
| OpenAI-kompatibles Protokoll | LiteLLM routet über das openai/-Präfix zum OpenAI-Client |
Einzeilige Konfiguration für jeden Proxy |
| Drei Konfigurationsarten | SDK-Inline / Proxy YAML / Umgebungsvariablen | Anpassung an Skripte, Produktion und CLI |
| Einheitliche Modellbenennung | openai/<provider-model> oder benutzerdefinierter Name |
Keine Anpassung im Code bei Wechsel nötig |
| Fehlerbehebung | base_url muss auf /v1 enden |
90% der 404-Fehler liegen hier |
| Fallback & Lastverteilung | YAML-Modus unterstützt mehrere Kanäle & Failover | Maximale Verfügbarkeit in der Produktion |
Detaillierte Erläuterung der Konfiguration
Die offizielle LiteLLM-Dokumentation stellt klar: Solange Sie das Präfix openai/ vor den Modellnamen setzen und die api_base angeben, verwendet LiteLLM den OpenAI-Client für den Zugriff auf Ihren Endpunkt. Das bedeutet, dass es für LiteLLM keine Rolle spielt, ob dahinter GPT-5, Claude Opus 4.6, Gemini 3 Pro oder DeepSeek steckt – für LiteLLM ist es einfach "ein OpenAI-Endpunkt".
Die base_url von APIYI apiyi.com lautet https://api.apiyi.com/v1. Sie folgt den Standardspezifikationen für /v1/chat/completions, /v1/embeddings und /v1/images/generations und ist somit perfekt mit LiteLLM kompatibel, ohne dass Patches erforderlich sind.

LiteLLM: Konfiguration eines API-Proxy-Dienstes – Schnelleinstieg
Vorbereitung
Bevor wir starten, stellen Sie bitte Folgendes sicher:
- APIYI API-Schlüssel: Registrieren Sie sich auf apiyi.com und erstellen Sie einen neuen Schlüssel im Dashboard (empfohlener Name:
litellm-prod). - base_url:
https://api.apiyi.com/v1(Hinweis: Das/v1am Ende ist zwingend erforderlich). - Python-Umgebung: Python 3.9+.
- Abhängigkeiten installieren:
pip install litellm
Minimalistisches Beispiel: Inline-Konfiguration im SDK
Der schnellste Weg zur Integration ist die direkte Übergabe von api_key und api_base im Code:
import litellm
response = litellm.completion(
model="openai/gpt-5", # Wichtig: Präfix openai/
api_key="YOUR_APIYI_KEY",
api_base="https://api.apiyi.com/v1", # APIYI API-Proxy-Dienst Adresse
messages=[
{"role": "user", "content": "Erkläre LiteLLM in einem Satz."}
],
)
print(response.choices[0].message.content)
💡 Empfehlung: Sobald Sie über das APIYI-Dashboard (apiyi.com) Testguthaben erhalten haben, können Sie
gpt-5einfach durch Modellnamen wieclaude-opus-4-6odergemini-3-proersetzen, ohne den restlichen Code ändern zu müssen – das ist der größte Vorteil des OpenAI-kompatiblen Protokolls.
Vollständiges, ausführbares Beispiel anzeigen (inkl. Fehlerbehandlung und Streaming)
import os
import litellm
from litellm import completion
# Empfehlung: Verwaltung der Schlüssel über Umgebungsvariablen
os.environ["OPENAI_API_KEY"] = "YOUR_APIYI_KEY"
os.environ["OPENAI_API_BASE"] = "https://api.apiyi.com/v1"
litellm.set_verbose = False # Für Debugging auf True setzen
def chat_with_apiyi(model: str, prompt: str, stream: bool = False):
"""Aufruf beliebiger OpenAI-kompatibler Modelle über LiteLLM + APIYI"""
try:
response = completion(
model=f"openai/{model}",
messages=[{"role": "user", "content": prompt}],
stream=stream,
temperature=0.7,
max_tokens=1024,
)
if stream:
for chunk in response:
delta = chunk.choices[0].delta.content or ""
print(delta, end="", flush=True)
print()
else:
return response.choices[0].message.content
except Exception as e:
print(f"Aufruf fehlgeschlagen: {e}")
return None
if __name__ == "__main__":
# Nicht-Streaming
print(chat_with_apiyi("gpt-5", "Erkläre, was ein LLM-Gateway ist"))
# Streaming
chat_with_apiyi("claude-opus-4-6", "Beschreibe die Vorteile von LiteLLM in 100 Wörtern", stream=True)
Proxy YAML-Konfiguration: Empfehlung für die Produktion
Wenn Sie LiteLLM als eigenständigen Dienst betreiben möchten (Port 4000, zur gemeinsamen Nutzung im Team), empfiehlt sich der YAML-Modus. Erstellen Sie eine litellm_config.yaml:
model_list:
- model_name: gpt-5 # Öffentlich verfügbarer Modellname
litellm_params:
model: openai/gpt-5 # Präfix openai/, Routing zum OpenAI-Client
api_base: https://api.apiyi.com/v1 # APIYI API-Proxy-Dienst Adresse
api_key: os.environ/APIYI_KEY # Referenz auf Umgebungsvariable
- model_name: claude-opus-4-6
litellm_params:
model: openai/claude-opus-4-6
api_base: https://api.apiyi.com/v1
api_key: os.environ/APIYI_KEY
- model_name: gemini-3-pro
litellm_params:
model: openai/gemini-3-pro
api_base: https://api.apiyi.com/v1
api_key: os.environ/APIYI_KEY
litellm_settings:
drop_params: true # Automatische Entfernung nicht unterstützter Parameter
num_retries: 2 # Anzahl der Wiederholungsversuche pro Aufruf
router_settings:
fallbacks:
- gpt-5: ["claude-opus-4-6", "gemini-3-pro"]
Proxy starten:
export APIYI_KEY=sk-xxxxxxxxxxxxxxxx
litellm --config ./litellm_config.yaml --port 4000
Danach kann jedes OpenAI-SDK über http://localhost:4000 zugreifen:
from openai import OpenAI
client = OpenAI(
api_key="any-string", # LiteLLM Proxy prüft den Inhalt nicht (außer master_key ist konfiguriert)
base_url="http://localhost:4000",
)
resp = client.chat.completions.create(
model="gpt-5",
messages=[{"role": "user", "content": "Hallo via LiteLLM Proxy"}]
)
print(resp.choices[0].message.content)
🎯 Produktionstipp: Wir empfehlen, dem LiteLLM-Proxy einen
master_keyvorzuschalten und alle zugrunde liegenden Modelle zentral über APIYI (apiyi.com) anzubinden. So sieht Ihre Anwendungsebene nur "semantische Modellnamen" wiegpt-5oderclaude-opus-4-6, während Kanäle, Abrechnung und Ratenbegrenzung durch die Kombination aus APIYI und LiteLLM im Hintergrund abgewickelt werden.
Umgebungsvariablen-Modus: Ideal für CLI und Skripte
Für Einmalskripte und Befehlszeilen-Tools ist die Nutzung von Umgebungsvariablen am einfachsten. LiteLLM erkennt OPENAI_API_KEY und OPENAI_API_BASE automatisch:
export OPENAI_API_KEY=sk-xxxxxxxxxxxxxxxx
export OPENAI_API_BASE=https://api.apiyi.com/v1
Danach laufen alle Aufrufe mit dem openai/-Präfix über APIYI:
import litellm
print(litellm.completion(
model="openai/gpt-5",
messages=[{"role": "user", "content": "ping"}]
).choices[0].message.content)
Vergleich der drei Konfigurationsmethoden für LiteLLM
Die Wahl der Methode hängt vom jeweiligen Szenario ab. Die folgende Tabelle bietet eine klare Entscheidungshilfe.
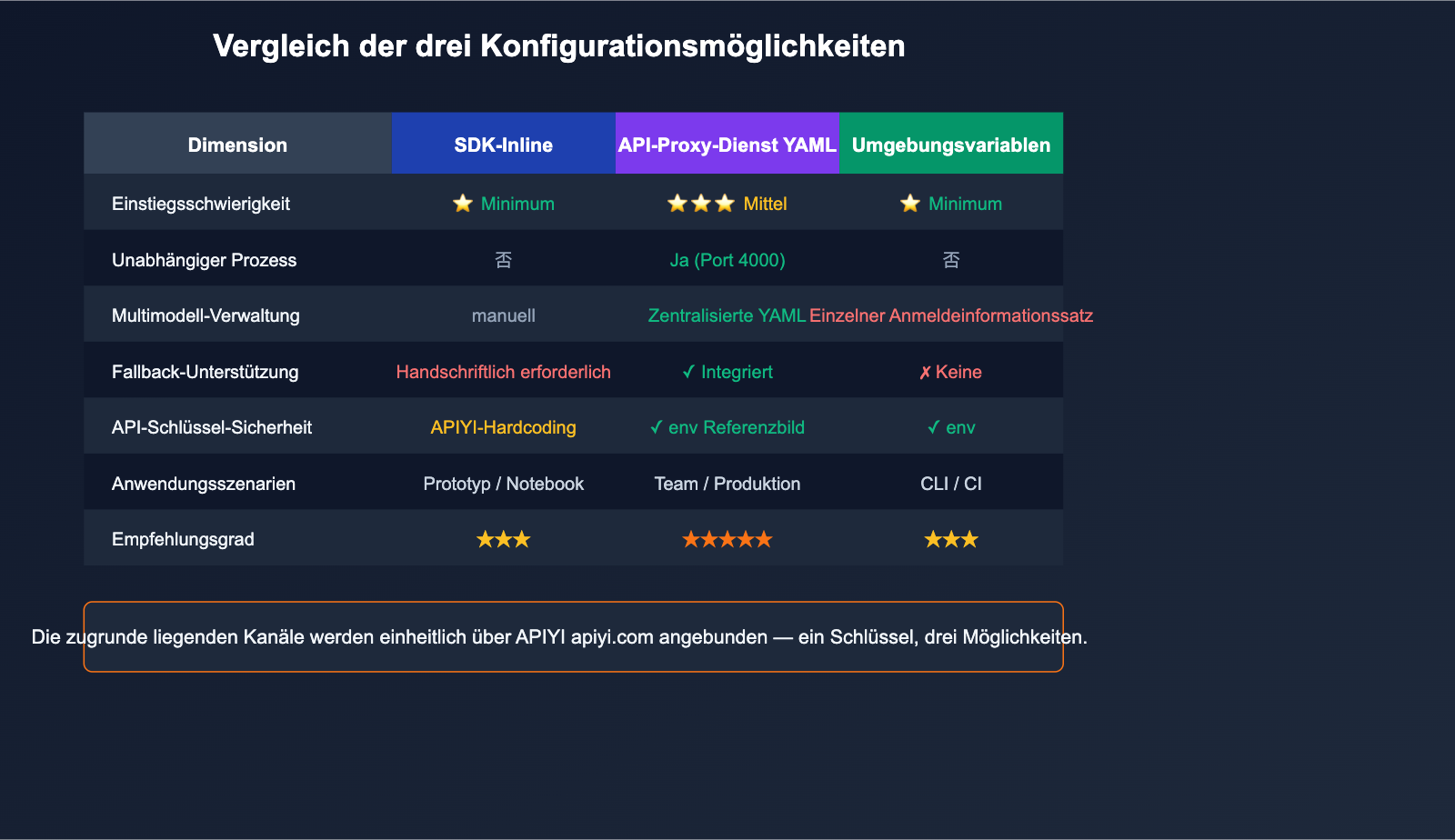
| Dimension | SDK Inline | Proxy YAML | Umgebungsvariablen |
|---|---|---|---|
| Einstiegshürde | ⭐ Sehr niedrig | ⭐⭐⭐ Mittel | ⭐ Sehr niedrig |
| Szenario | Einzelskript, Notebook | Team-Sharing, Produktion | CLI-Tools, CI |
| Separater Prozess | Nein | Ja (Port 4000) | Nein |
| Modellverwaltung | Manuell | Zentral via YAML | Nur ein Satz Anmeldedaten |
| Fallback-Support | Manuelles Try/Except | ✅ Integriert | ❌ Keiner |
| Sicherheit | Anfällig für Hardcoding | ✅ Env-Referenz | ✅ Über Env |
| Empfehlung | Prototyping | Produktion | Persönliche Skripte |
💡 Empfehlung: Für die persönliche Entwicklung reichen Umgebungsvariablen aus. Für Teams und Produktion empfehlen wir dringend den Proxy-YAML-Modus, da er "Modell-Routing + Fallback + Ratenbegrenzung + Statistik" zentral in einer Datei verwaltet. Unabhängig von der Wahl bleibt die Anbindung an APIYI (apiyi.com) identisch – Sie müssen nur einen API-Schlüssel pflegen.
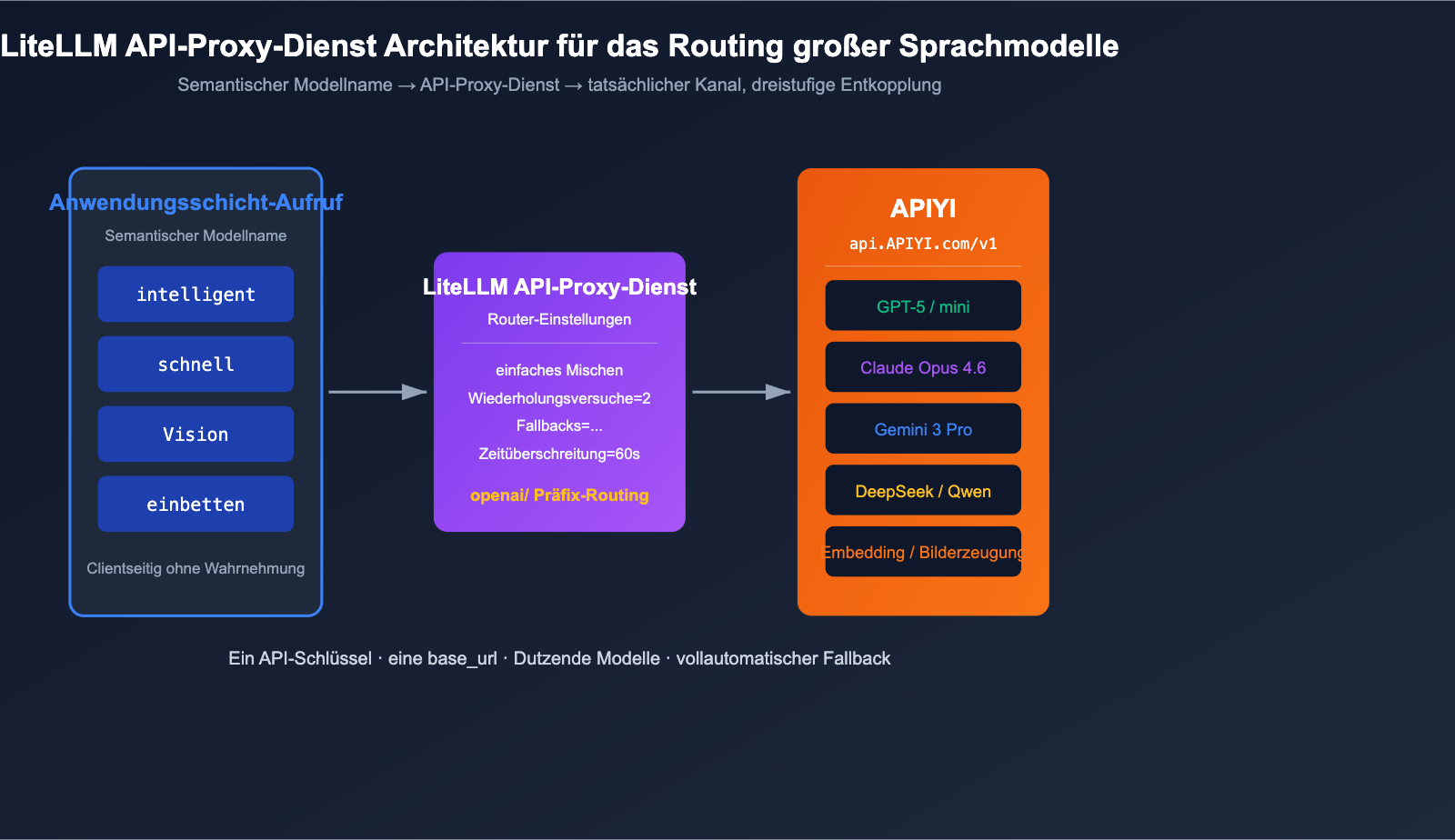
LiteLLM + APIYI: Praxis des Multi-Modell-Routings
Die wahre Stärke des LiteLLM-Proxy-Modus liegt darin, mit einer einzigen YAML-Datei eine Zuordnung von „semantischen Modellnamen“ zu „tatsächlichen Kanälen“ zu erstellen. Nachfolgend finden Sie eine produktionsreife, minimale Routing-Konfiguration.
# litellm_config.yaml - Beispiel für Produktions-Routing
model_list:
# Haupt-Inferenzmodelle
- model_name: smart
litellm_params:
model: openai/gpt-5
api_base: https://api.apiyi.com/v1
api_key: os.environ/APIYI_KEY
timeout: 60
- model_name: smart
litellm_params:
model: openai/claude-opus-4-6
api_base: https://api.apiyi.com/v1
api_key: os.environ/APIYI_KEY
timeout: 60
# Schnelle, kostengünstige Modelle
- model_name: fast
litellm_params:
model: openai/gpt-5-mini
api_base: https://api.apiyi.com/v1
api_key: os.environ/APIYI_KEY
# Vision / multimodal
- model_name: vision
litellm_params:
model: openai/gemini-3-pro
api_base: https://api.apiyi.com/v1
api_key: os.environ/APIYI_KEY
# Embedding
- model_name: embed
litellm_params:
model: openai/text-embedding-3-large
api_base: https://api.apiyi.com/v1
api_key: os.environ/APIYI_KEY
litellm_settings:
drop_params: true
num_retries: 2
request_timeout: 60
router_settings:
routing_strategy: simple-shuffle # Round-Robin für gleichnamige Modelle
fallbacks:
- smart: ["fast"] # Fallback von smart auf fast bei Fehlern
general_settings:
master_key: sk-litellm-master-xxxx # Client muss diesen Schlüssel verwenden
Die Anwendungsebene sieht nur die vier semantischen Namen smart, fast, vision und embed. Wenn GPT-5 gedrosselt wird, schaltet LiteLLM automatisch auf Claude Opus 4.6 um (da beide als smart registriert sind) und bei einem weiteren Fehler auf fast. Der gesamte Datenverkehr wird über den API-Proxy-Dienst APIYI (apiyi.com) zentral abgerechnet und überwacht, was die Anwendungsebene sauber von der Kanalebene trennt.
Häufige Fragen zur Konfiguration von LiteLLM mit einem API-Proxy-Dienst
Q1: Warum erhalte ich einen 404 Not Found Fehler, obwohl ich die base_url konfiguriert habe?
In 90 % der Fälle fehlt am Ende der api_base der Zusatz /v1. LiteLLM verwendet intern den OpenAI-Client, der automatisch /chat/completions anhängt. Daher muss Ihre api_base https://api.apiyi.com/v1 lauten und nicht https://api.apiyi.com. Schreiben Sie auch nicht https://api.apiyi.com/v1/chat/completions, da dies zu einer doppelten Pfadangabe führen würde.
Q2: Warum muss ich dem Modell das Präfix openai/ voranstellen?
LiteLLM verwaltet intern eine Provider-Routing-Tabelle. Das Präfix openai/ weist LiteLLM an: „Bitte verwende den OpenAI-Client, um diesen Endpunkt aufzurufen.“ Ohne das Präfix versucht LiteLLM möglicherweise, den internen Provider abzugleichen (z. B. würde claude-opus-4-6 als native Anthropic-API erkannt), was zu Protokollfehlern führt. Verwenden Sie bei der Anbindung an einen Proxy-Dienst immer das Präfix openai/.
Q3: Kann ein APIYI-Schlüssel mehrere Modelle gleichzeitig aufrufen?
Ja. Ein einzelner Schlüssel von APIYI (apiyi.com) unterstützt standardmäßig alle auf der Plattform verfügbaren Modelle, einschließlich GPT-5, Claude Opus 4.6, Gemini 3 Pro, DeepSeek, Qwen usw. Das ist der entscheidende Unterschied zur offiziellen API – Sie müssen nur einen Schlüssel und eine base_url verwalten, um Dutzende von Modellen in Ihrer LiteLLM-YAML-Datei einzubinden.
Q4: Wie kann ich nach dem Start des LiteLLM-Proxys prüfen, ob die Verbindung zum Proxy-Dienst steht?
Am schnellsten geht dies mit einem curl-Befehl direkt an den LiteLLM-Proxy:
curl http://localhost:4000/v1/chat/completions \
-H "Authorization: Bearer sk-litellm-master-xxxx" \
-H "Content-Type: application/json" \
-d '{
"model": "smart",
"messages": [{"role": "user", "content": "ping"}]
}'
Ein 200-Statuscode mit JSON-Antwort bestätigt, dass die gesamte Kette Anwendung → LiteLLM Proxy → APIYI funktioniert. Bei Fehlern prüfen Sie zuerst die LiteLLM-Konsolenprotokolle und testen Sie anschließend die APIYI-Verbindung direkt mit derselben base_url und dem Schlüssel, um die Fehlerquelle einzugrenzen.
Q5: Muss das Streaming (stream) bei der Nutzung eines Proxy-Dienstes besonders konfiguriert werden?
Nein. APIYI (apiyi.com) unterstützt SSE-Streaming-Antworten vollständig, und LiteLLM leitet diese standardmäßig durch. Wenn Sie beim completion()-Aufruf oder beim Aufruf des Proxys über das OpenAI-SDK stream=True setzen, erhalten Sie die Ausgabe Token für Token.
Q6: Kann ich auch Embedding und Bilderzeugung einbinden?
Ja. APIYI (apiyi.com) unterstützt gleichzeitig /v1/embeddings, /v1/images/generations und /v1/audio/transcriptions, alles über dieselbe base_url und denselben Schlüssel. Fügen Sie die entsprechenden Modelle einfach in der LiteLLM-YAML unter model_list hinzu, z. B. text-embedding-3-large, gpt-image-1 oder whisper-1. Die Verwendung ist identisch mit den Chat-Modellen; siehe dazu das Produktionsbeispiel im vorherigen Abschnitt.
Zusammenfassung
Die Konfiguration eines API-Proxy-Dienstes von Drittanbietern in LiteLLM lässt sich im Wesentlichen auf drei Punkte reduzieren:
- Protokoll-Abgleich: Fügen Sie das Präfix
openai/zum Modellnamen hinzu, um LiteLLM anzuweisen, das OpenAI-Client-Protokoll zu verwenden. - Endpunkt-Abgleich: Setzen Sie
api_baseauf den Basispfad des API-Proxy-Dienstes zuzüglich/v1, zum Beispielhttps://api.apiyi.com/v1. - Berechtigungs-Abgleich: Übergeben Sie den vom API-Proxy-Dienst ausgestellten Schlüssel über
api_keyoder eine Umgebungsvariable.
Sobald diese drei Schritte abgeschlossen sind, können alle Funktionen von LiteLLM (Modell-Routing, Fallback, Ratenbegrenzung, Abrechnung, Logging) nahtlos über einen stabilen API-Proxy-Dienst genutzt werden.
🚀 Handlungsempfehlung: Wenn Sie ein einheitliches LLM-Gateway für Ihr Team aufbauen, empfehlen wir eine Drei-Schichten-Architektur: „Anwendung → LiteLLM Proxy → APIYI apiyi.com“. LiteLLM übernimmt das Routing und Fallback, während APIYI für die Anbindung der zugrunde liegenden Modelle, die Stabilität und die nutzungsbasierte Abrechnung sorgt. Sie müssen lediglich eine YAML-Datei und einen Schlüssel verwalten. Registrieren Sie sich auf apiyi.com, um ein Testguthaben zu erhalten und Ihren ersten Modellaufruf innerhalb von 5 Minuten durchzuführen.
Autor: APIYI Team — Wir konzentrieren uns darauf, Entwicklern einen stabilen Zugang zu führenden KI-Großsprachmodellen zu bieten. Besuchen Sie apiyi.com für weitere Informationen.
Referenzen
-
Offizielle LiteLLM-Dokumentation – OpenAI-kompatible Endpunkte
- Link:
docs.litellm.ai/docs/providers/openai_compatible - Beschreibung: Offizielle Beispiele für SDK und Proxy-YAML.
- Link:
-
LiteLLM Proxy Konfigurationsübersicht
- Link:
docs.litellm.ai/docs/proxy/configs - Beschreibung: Vollständige Felder für model_list, router_settings und Fallbacks.
- Link:
-
LiteLLM GitHub-Repository
- Link:
github.com/BerriAI/litellm - Beschreibung: Quellcode, Issues und neueste Versionen.
- Link:
-
daily_stock_analysis – LLM_CONFIG_GUIDE
- Link:
github.com/ZhuLinsen/daily_stock_analysis/blob/main/docs/LLM_CONFIG_GUIDE.md - Beschreibung: Drei Konfigurationsmodi und Praxisbeispiele für Multi-Channel-Setups.
- Link:
-
APIYI Offizielle Dokumentation
- Link:
apiyi.com - Beschreibung: Liste der unterstützten Modelle, base_url und Schlüsselverwaltung.
- Link: