Как заставить LiteLLM одновременно управлять множеством больших языковых моделей (OpenAI, Claude, Gemini, DeepSeek и др.), не спотыкаясь о проблемы с зарубежными аккаунтами, доступом к сети или оплатой? Ответ прост: подключить LiteLLM к стороннему сервису-прокси API, совместимому с OpenAI. В этой статье мы на примере LiteLLM + APIYI (apiyi.com) пошагово разберем процесс настройки.
Ключевая ценность: Прочитав статью, вы освоите 3 основных способа настройки LiteLLM для работы через сторонний сервис-прокси (SDK, Proxy YAML, переменные окружения) и сможете подключить APIYI буквально за 5 минут.
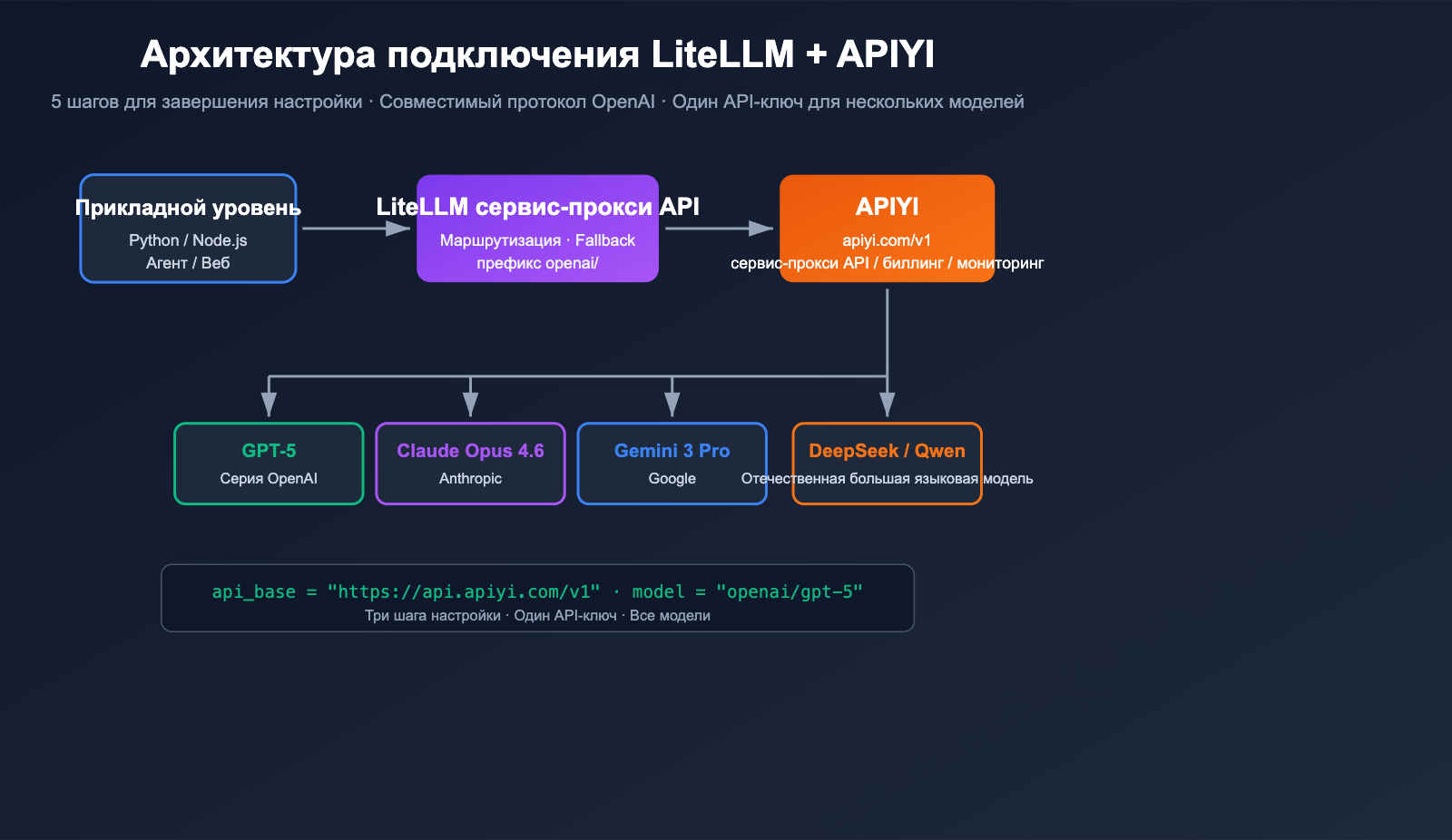
Основные аспекты настройки LiteLLM со сторонним сервисом-прокси
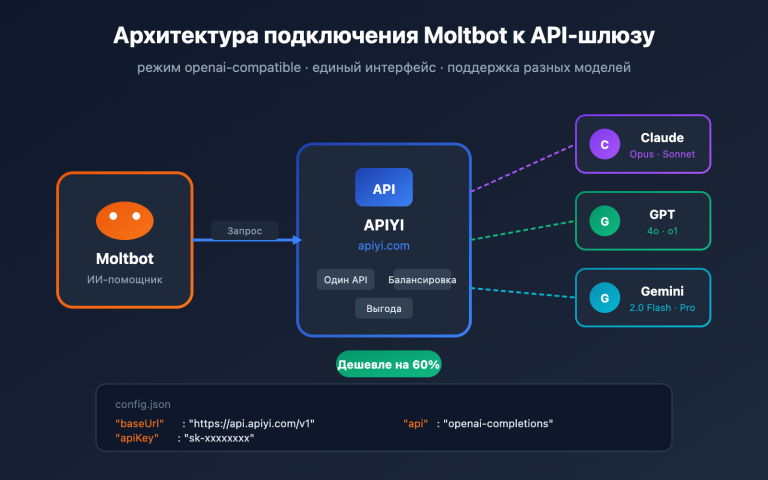
LiteLLM — это open-source шлюз/SDK для LLM, цель которого — вызывать более 100 моделей через единый интерфейс, совместимый с OpenAI. Он «из коробки» поддерживает любые эндпоинты, совместимые с OpenAI: достаточно указать api_base вашего прокси-сервиса и использовать API-ключ, выданный этим сервисом. APIYI (apiyi.com) — это стандартный прокси-сервис с поддержкой OpenAI, поэтому они идеально подходят друг другу.
| Аспект | Описание | Преимущество |
|---|---|---|
| Совместимость с OpenAI | LiteLLM использует префикс openai/ для маршрутизации |
Подключение любого прокси одной строкой |
| Три способа настройки | SDK, Proxy YAML, переменные окружения | Подходит для скриптов, продакшена и CLI |
| Единое именование моделей | openai/<provider-model> или кастомное имя |
Код не зависит от смены провайдера |
| Диагностика ошибок | base_url должен заканчиваться на /v1 |
90% ошибок 404 возникают из-за этого |
| Отказоустойчивость | YAML-режим поддерживает балансировку | Максимальная доступность в продакшене |
Подробности настройки LiteLLM
В официальной документации LiteLLM четко сказано: достаточно добавить префикс openai/ к имени модели и указать api_base, чтобы LiteLLM использовал клиент OpenAI для обращения к вашему эндпоинту. Это значит, что независимо от того, стоит ли за прокси GPT-5, Claude Opus 4.6, Gemini 3 Pro или DeepSeek, для LiteLLM это всегда «просто эндпоинт OpenAI».
Base_url сервиса APIYI (apiyi.com) — https://api.apiyi.com/v1. Он полностью соответствует стандартам /v1/chat/completions, /v1/embeddings, /v1/images/generations, поэтому идеально совместим с LiteLLM без каких-либо дополнительных патчей.

Быстрый старт: настройка LiteLLM с использованием стороннего сервис-прокси API
Подготовка
Перед началом работы убедитесь, что у вас есть:
- API-ключ APIYI: Зарегистрируйтесь на apiyi.com и создайте новый ключ в панели управления (рекомендуем назвать его
litellm-prod). - base_url:
https://api.apiyi.com/v1(обратите внимание: в конце обязательно должен быть/v1). - Python-окружение: Python 3.9+.
- Установка зависимостей:
pip install litellm.
Минималистичный пример: встроенная конфигурация SDK
Самый быстрый способ подключения — передать api_key и api_base прямо в коде:
import litellm
response = litellm.completion(
model="openai/gpt-5", # Ключевой момент: префикс openai/
api_key="YOUR_APIYI_KEY",
api_base="https://api.apiyi.com/v1", # Адрес сервис-прокси API APIYI
messages=[
{"role": "user", "content": "Опиши LiteLLM одним предложением"}
],
)
print(response.choices[0].message.content)
💡 Совет: Получив тестовый баланс в панели управления APIYI (apiyi.com), вы можете заменить
gpt-5на названия других моделей, напримерclaude-opus-4-6илиgemini-3-pro, не меняя остальной код — в этом и заключается главное преимущество совместимости с протоколом OpenAI.
Посмотреть полный рабочий пример (с обработкой ошибок и потоковым выводом)
import os
import litellm
from litellm import completion
# Рекомендуется управлять ключами через переменные окружения
os.environ["OPENAI_API_KEY"] = "YOUR_APIYI_KEY"
os.environ["OPENAI_API_BASE"] = "https://api.apiyi.com/v1"
litellm.set_verbose = False # При отладке можно сменить на True
def chat_with_apiyi(model: str, prompt: str, stream: bool = False):
"""Вызов любой модели, совместимой с OpenAI, через LiteLLM + APIYI"""
try:
response = completion(
model=f"openai/{model}",
messages=[{"role": "user", "content": prompt}],
stream=stream,
temperature=0.7,
max_tokens=1024,
)
if stream:
for chunk in response:
delta = chunk.choices[0].delta.content or ""
print(delta, end="", flush=True)
print()
else:
return response.choices[0].message.content
except Exception as e:
print(f"Ошибка вызова: {e}")
return None
if __name__ == "__main__":
# Без потока
print(chat_with_apiyi("gpt-5", "Объясни, что такое LLM-шлюз"))
# С потоком
chat_with_apiyi("claude-opus-4-6", "Опиши преимущества LiteLLM в 100 словах", stream=True)
Конфигурация через Proxy YAML: выбор для продакшена
Если вы планируете запустить LiteLLM как отдельный сервис (на порту 4000 для всей команды), рекомендуем использовать YAML-конфигурацию. Создайте файл litellm_config.yaml:
model_list:
- model_name: gpt-5 # Имя модели для внешнего доступа
litellm_params:
model: openai/gpt-5 # Префикс openai/ для маршрутизации к клиенту OpenAI
api_base: https://api.apiyi.com/v1 # Адрес прокси APIYI
api_key: os.environ/APIYI_KEY # Ссылка на переменную окружения
- model_name: claude-opus-4-6
litellm_params:
model: openai/claude-opus-4-6
api_base: https://api.apiyi.com/v1
api_key: os.environ/APIYI_KEY
- model_name: gemini-3-pro
litellm_params:
model: openai/gemini-3-pro
api_base: https://api.apiyi.com/v1
api_key: os.environ/APIYI_KEY
litellm_settings:
drop_params: true # Автоматическое удаление неподдерживаемых параметров
num_retries: 2 # Количество повторных попыток при сбое
router_settings:
fallbacks:
- gpt-5: ["claude-opus-4-6", "gemini-3-pro"]
Запуск прокси:
export APIYI_KEY=sk-xxxxxxxxxxxxxxxx
litellm --config ./litellm_config.yaml --port 4000
После этого любой SDK OpenAI сможет обращаться к моделям через http://localhost:4000:
from openai import OpenAI
client = OpenAI(
api_key="any-string", # LiteLLM Proxy не проверяет содержимое (если не настроен master_key)
base_url="http://localhost:4000",
)
resp = client.chat.completions.create(
model="gpt-5",
messages=[{"role": "user", "content": "Hello via LiteLLM Proxy"}]
)
print(resp.choices[0].message.content)
🎯 Совет для продакшена: Мы рекомендуем добавить слой
master_keyперед LiteLLM Proxy и подключить все базовые модели к APIYI (apiyi.com). Таким образом, на уровне приложения вы будете видеть только "семантические имена моделей" (например,gpt-5), а вопросы маршрутизации, биллинга и лимитов будут решаться на уровне APIYI + LiteLLM.
Режим переменных окружения: удобно для CLI и скриптов
Для разовых скриптов и инструментов командной строки проще всего использовать переменные окружения. LiteLLM автоматически распознает OPENAI_API_KEY и OPENAI_API_BASE:
export OPENAI_API_KEY=sk-xxxxxxxxxxxxxxxx
export OPENAI_API_BASE=https://api.apiyi.com/v1
После этого все вызовы с префиксом openai/ будут проходить через APIYI:
import litellm
print(litellm.completion(
model="openai/gpt-5",
messages=[{"role": "user", "content": "ping"}]
).choices[0].message.content)
Сравнение трех способов настройки LiteLLM с сервис-прокси
Выбор метода зависит от ваших задач. В таблице ниже приведены рекомендации.
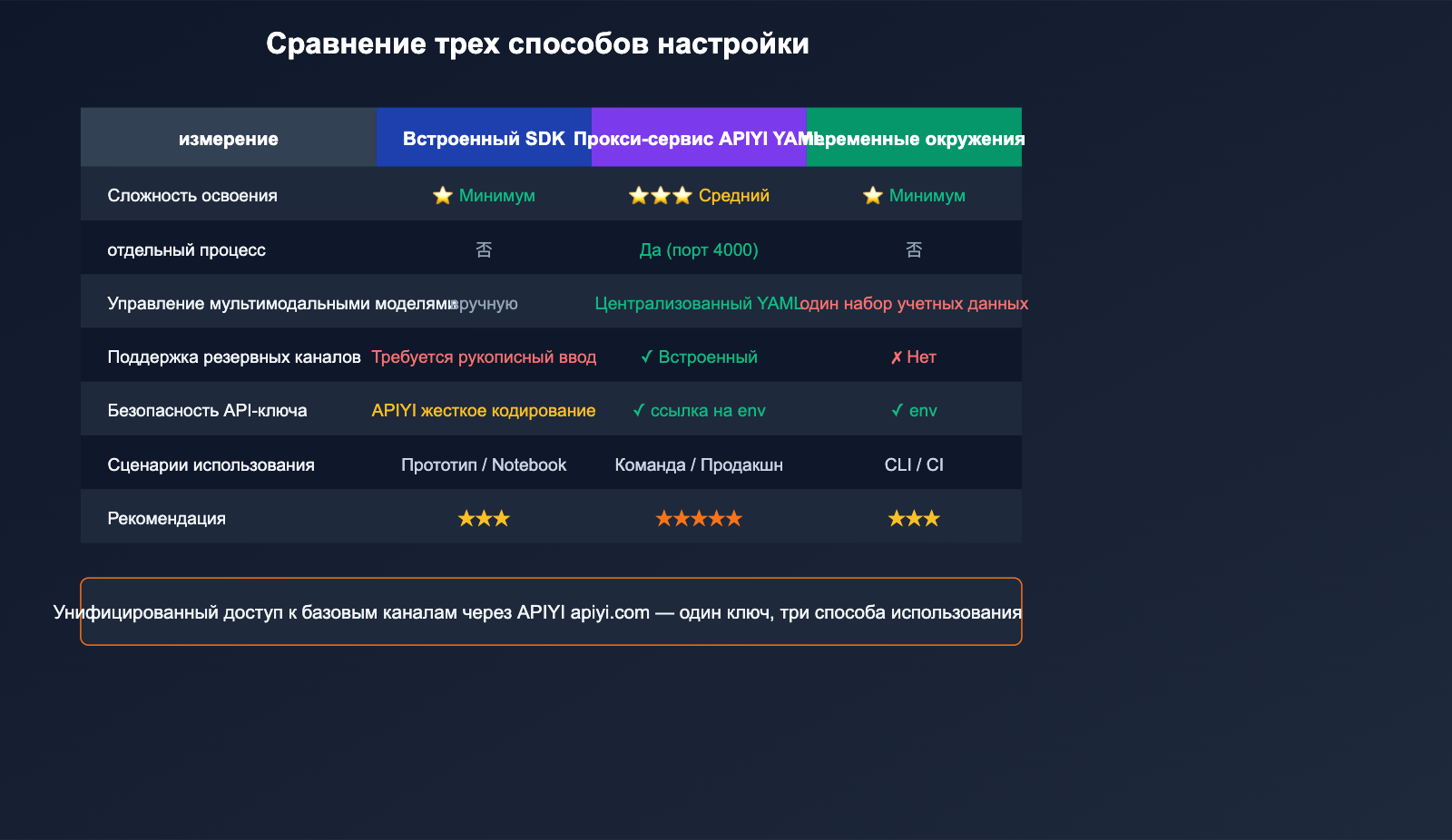
| Параметр | SDK Inline | Proxy YAML | Env Vars |
|---|---|---|---|
| Сложность | ⭐ Низкая | ⭐⭐⭐ Средняя | ⭐ Низкая |
| Сценарии | Скрипты, Notebooks | Команда, продакшен | CLI, CI |
| Отдельный процесс | Нет | Да (порт 4000) | Нет |
| Управление моделями | Вручную | Централизованно (YAML) | Только одна пара ключей |
| Поддержка Fallback | Через try/except | ✅ Встроено | ❌ Нет |
| Безопасность ключей | Риск хардкода | ✅ Через env | ✅ Через env |
| Рекомендация | Прототипирование | Продакшен | Личные скрипты |
💡 Совет: Для личной разработки достаточно переменных окружения. Для команд и продакшена настоятельно рекомендуем режим Proxy YAML, так как он позволяет управлять маршрутизацией, отказоустойчивостью (fallback), лимитами и статистикой в одном файле. Какой бы метод вы ни выбрали, подключение к APIYI (apiyi.com) остается неизменным, вам достаточно поддерживать один API-ключ.
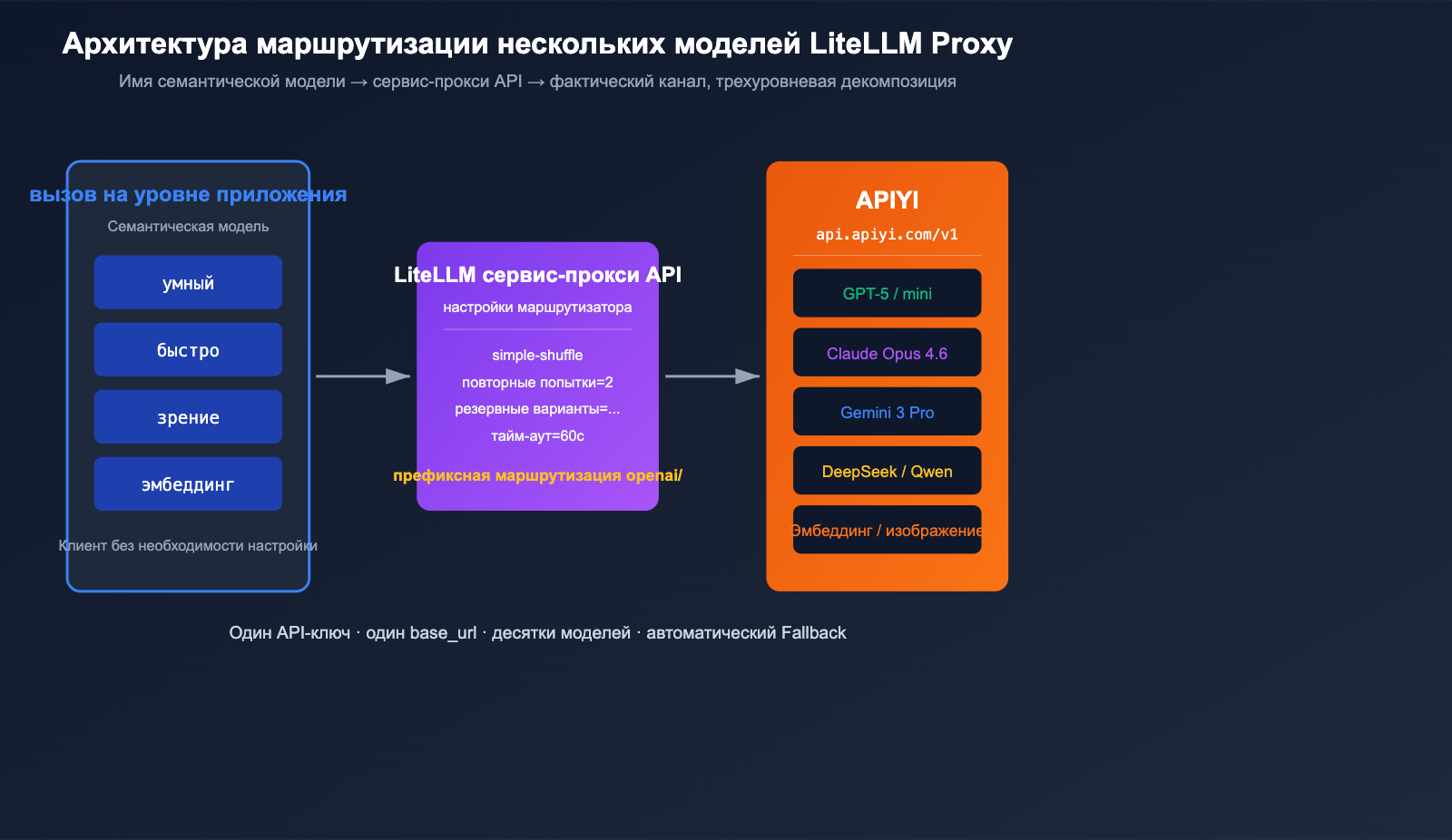
Практика маршрутизации нескольких моделей: LiteLLM + APIYI
Настоящая мощь режима LiteLLM Proxy заключается в возможности использовать один YAML-файл для сопоставления «семантического имени модели» с «реальным каналом». Ниже приведен минимальный конфиг для маршрутизации, готовый к использованию в продакшене.
# litellm_config.yaml - пример маршрутизации для продакшена
model_list:
# Основные модели для логических задач
- model_name: smart
litellm_params:
model: openai/gpt-5
api_base: https://api.apiyi.com/v1
api_key: os.environ/APIYI_KEY
timeout: 60
- model_name: smart
litellm_params:
model: openai/claude-opus-4-6
api_base: https://api.apiyi.com/v1
api_key: os.environ/APIYI_KEY
timeout: 60
# Быстрые и недорогие модели
- model_name: fast
litellm_params:
model: openai/gpt-5-mini
api_base: https://api.apiyi.com/v1
api_key: os.environ/APIYI_KEY
# Мультимодальные модели / зрение
- model_name: vision
litellm_params:
model: openai/gemini-3-pro
api_base: https://api.apiyi.com/v1
api_key: os.environ/APIYI_KEY
# Эмбеддинги
- model_name: embed
litellm_params:
model: openai/text-embedding-3-large
api_base: https://api.apiyi.com/v1
api_key: os.environ/APIYI_KEY
litellm_settings:
drop_params: true
num_retries: 2
request_timeout: 60
router_settings:
routing_strategy: simple-shuffle # Балансировка между моделями с одинаковым именем
fallbacks:
- smart: ["fast"] # При сбое smart-модели переключаемся на fast
general_settings:
master_key: sk-litellm-master-xxxx # Клиент должен использовать этот ключ
На уровне приложения вы работаете только с четырьмя семантическими именами: smart, fast, vision и embed. Если GPT-5 попадает под лимиты, LiteLLM автоматически переключится на Claude Opus 4.6 (поскольку они оба зарегистрированы как smart), а в случае дальнейших сбоев — на fast. Весь трафик проходит через сервис-прокси API APIYI (apiyi.com) для централизованного биллинга и мониторинга, что позволяет полностью отделить логику приложения от каналов доступа.
Частые вопросы по настройке сторонних сервисов-прокси API в LiteLLM
Q1: Почему я указал base_url, но все равно получаю ошибку 404 Not Found?
В 90% случаев проблема в том, что в api_base забыли добавить /v1 в конце. LiteLLM использует клиент OpenAI, который автоматически добавляет /chat/completions к пути. Поэтому ваш api_base должен выглядеть как https://api.apiyi.com/v1, а не https://api.apiyi.com. Также не пишите https://api.apiyi.com/v1/chat/completions, иначе путь будет продублирован.
Q2: Почему обязательно добавлять префикс openai/ к названию модели?
Внутри LiteLLM есть таблица маршрутизации провайдеров. Префикс openai/ говорит LiteLLM: «Пожалуйста, используй клиент OpenAI для доступа к этой конечной точке». Если префикс не добавить, LiteLLM может попытаться сопоставить модель со встроенным провайдером (например, claude-opus-4-6 будет распознана как нативный API Anthropic), из-за чего протокол будет выбран неверно. При подключении к сервису-прокси API всегда добавляйте префикс openai/.
Q3: Может ли один API-ключ APIYI использоваться для вызова нескольких моделей?
Да. Один ключ APIYI (apiyi.com) по умолчанию поддерживает все доступные на платформе модели, включая GPT-5, Claude Opus 4.6, Gemini 3 Pro, DeepSeek, Qwen и другие. В этом и заключается главное отличие от официального API — вам нужно поддерживать только один ключ и один base_url, чтобы подключить десятки моделей в YAML-конфиге LiteLLM.
Q4: Как проверить, что канал связи с прокси-сервером работает после запуска LiteLLM Proxy?
Самый быстрый способ — отправить запрос через curl напрямую к LiteLLM Proxy:
curl http://localhost:4000/v1/chat/completions \
-H "Authorization: Bearer sk-litellm-master-xxxx" \
-H "Content-Type: application/json" \
-d '{
"model": "smart",
"messages": [{"role": "user", "content": "ping"}]
}'
Если вы получили ответ 200 + JSON, значит, вся цепочка Приложение → LiteLLM Proxy → APIYI работает корректно. Если возникла ошибка, сначала проверьте логи консоли LiteLLM, а затем попробуйте отправить запрос с тем же base_url и ключом напрямую в APIYI, чтобы локализовать проблему.
Q5: Нужно ли дополнительно настраивать потоковую передачу (stream) при работе через прокси?
Нет. APIYI (apiyi.com) полностью поддерживает потоковые ответы SSE, а LiteLLM передает их по умолчанию. Вам достаточно добавить stream=True при вызове completion() или при использовании SDK OpenAI для обращения к прокси, чтобы получать ответ по токенам.
Q6: Можно ли одновременно подключить Embedding и генерацию изображений?
Да. APIYI (apiyi.com) поддерживает /v1/embeddings, /v1/images/generations и /v1/audio/transcriptions — все они работают через тот же base_url и ключ. В YAML-файле LiteLLM достаточно добавить соответствующие модели в model_list, например: text-embedding-3-large, gpt-image-1, whisper-1. Использование полностью аналогично диалоговым моделям, подробности см. в примере маршрутизации в предыдущем разделе.
Итоги
Настройка стороннего сервиса-прокси в LiteLLM сводится к трем вещам:
- Согласование протокола: добавьте префикс
openai/к модели, чтобы LiteLLM использовал протокол клиента OpenAI. - Согласование входа:
api_baseдолжен указывать на корневой путь прокси-сервиса +/v1, напримерhttps://api.apiyi.com/v1. - Согласование учетных данных: передайте ключ, выданный прокси-сервисом, через
api_keyили переменную окружения.
После выполнения этих трех шагов все функции LiteLLM (маршрутизация нескольких моделей, Fallback, ограничение скорости, биллинг, логирование) можно бесшовно использовать поверх стабильного прокси-сервиса.
🚀 Совет: Если вы создаете единый шлюз LLM для своей команды, мы рекомендуем трехуровневую архитектуру: «Приложение → LiteLLM Proxy → APIYI (apiyi.com)». LiteLLM отвечает за маршрутизацию и Fallback, а APIYI — за доступ к базовым моделям, стабильность и оплату по факту использования. Вам нужно управлять только одним YAML-файлом и одним ключом. Зарегистрируйтесь на apiyi.com, чтобы получить тестовый баланс и выполнить первый вызов за 5 минут.
Автор: Команда APIYI — специализируемся на предоставлении стабильного доступа к основным большим языковым моделям для разработчиков. Посетите apiyi.com для получения дополнительной информации.
Справочные материалы
-
Официальная документация LiteLLM — OpenAI-совместимые эндпоинты
- Ссылка:
docs.litellm.ai/docs/providers/openai_compatible - Описание: Официальные примеры для SDK и YAML-конфигурации прокси.
- Ссылка:
-
Обзор конфигурации LiteLLM Proxy
- Ссылка:
docs.litellm.ai/docs/proxy/configs - Описание: Полный список полей для
model_list,router_settingsиfallbacks.
- Ссылка:
-
Репозиторий LiteLLM на GitHub
- Ссылка:
github.com/BerriAI/litellm - Описание: Исходный код, тикеты (Issues) и информация о последних версиях.
- Ссылка:
-
daily_stock_analysis — LLM_CONFIG_GUIDE
- Ссылка:
github.com/ZhuLinsen/daily_stock_analysis/blob/main/docs/LLM_CONFIG_GUIDE.md - Описание: Практическое руководство по трем режимам конфигурации и работе с несколькими каналами.
- Ссылка:
-
Официальная документация APIYI
- Ссылка:
apiyi.com - Описание: Список поддерживаемых моделей, управление
base_urlи API-ключами.
- Ссылка: