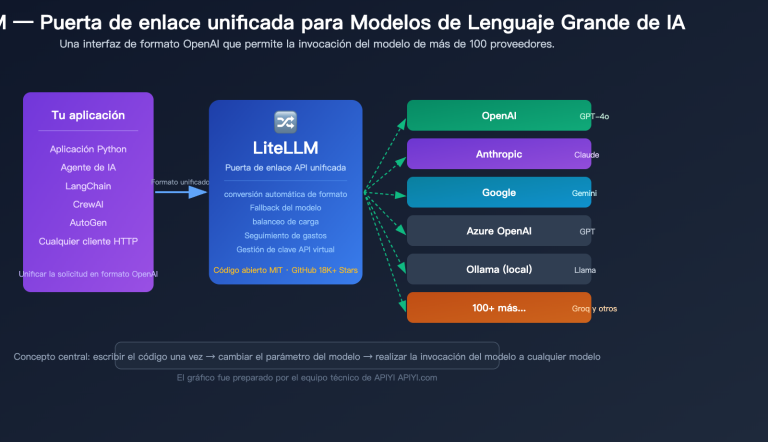
¿Cómo lograr que LiteLLM gestione simultáneamente modelos de lenguaje grandes como OpenAI, Claude, Gemini y DeepSeek sin sufrir por problemas de cuentas extranjeras, redes o pagos? La respuesta es conectar LiteLLM a un servicio proxy de API de terceros compatible con OpenAI. En este artículo, utilizaremos LiteLLM + APIYI apiyi.com como ejemplo para guiarte paso a paso en la configuración.
Valor principal: Al terminar de leer, dominarás las 3 formas principales de configurar un servicio proxy de API en LiteLLM (SDK, Proxy YAML, variables de entorno) y podrás completar la integración con APIYI en menos de 5 minutos.
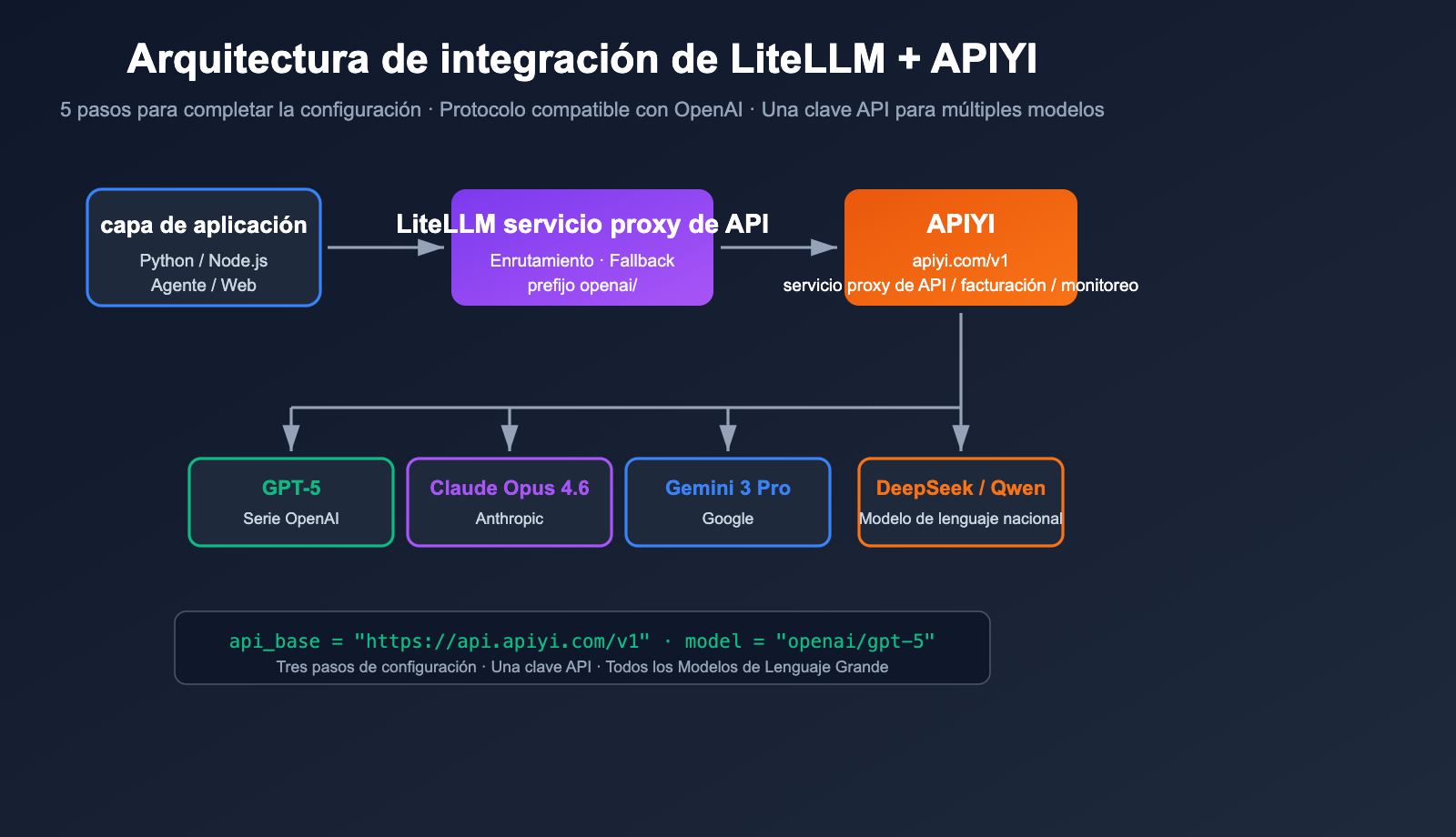
Puntos clave para configurar LiteLLM con un servicio proxy de terceros
LiteLLM es una puerta de enlace/SDK de modelos de lenguaje grandes de código abierto, cuyo objetivo es invocar más de 100 modelos utilizando un formato compatible con OpenAI. Soporta de forma nativa cualquier punto final "compatible con OpenAI"; solo necesitas apuntar api_base al servicio proxy y cambiar la api_key por la clave proporcionada por dicho servicio. APIYI apiyi.com es un proxy estándar compatible con OpenAI, por lo que ambos encajan a la perfección.
| Punto clave | Descripción | Valor |
|---|---|---|
| Protocolo compatible con OpenAI | LiteLLM enruta al cliente de OpenAI mediante el prefijo openai/ |
Conexión a cualquier proxy con una línea de configuración |
| Tres formas de configuración | SDK inline / Proxy YAML / Variables de entorno | Adaptado a scripts, producción y CLI |
| Nombres de modelo unificados | openai/<provider-model> o model_name personalizado |
El código superior no necesita detectar cambios en la capa inferior |
| Clave para resolución de errores | base_url debe terminar en /v1 |
El 90% de los errores 404 provienen de aquí |
| Fallback y balanceo de carga | El modo YAML admite múltiples canales y recuperación ante fallos | Maximiza la disponibilidad en entornos de producción |
Detalles sobre la configuración de LiteLLM con un servicio proxy de terceros
La documentación oficial de LiteLLM es clara: siempre que añadas el prefijo openai/ al nombre del modelo y especifiques api_base, LiteLLM utilizará el cliente de OpenAI para acceder a tu punto final. Esto significa que, independientemente de si el proxy conecta con GPT-5, Claude Opus 4.6, Gemini 3 Pro o DeepSeek, para LiteLLM siempre será "un punto final de OpenAI".
La base_url de APIYI apiyi.com es https://api.apiyi.com/v1, la cual sigue las especificaciones estándar de /v1/chat/completions, /v1/embeddings y /v1/images/generations, por lo que es perfectamente compatible con LiteLLM sin necesidad de parches.

Configuración de LiteLLM con un servicio proxy de API: Guía rápida
Preparativos
Antes de empezar, asegúrate de tener lo siguiente:
- Clave API de APIYI: Regístrate en apiyi.com y crea una nueva clave en el panel de control (te recomendamos llamarla
litellm-prod). - base_url:
https://api.apiyi.com/v1(ten en cuenta que debe terminar obligatoriamente en/v1). - Entorno Python: Python 3.9+.
- Instalar dependencias:
pip install litellm.
Ejemplo minimalista: Configuración en línea con el SDK
La forma más rápida de integrarlo es pasando el api_key y el api_base directamente en tu código:
import litellm
response = litellm.completion(
model="openai/gpt-5", # Clave: prefijo openai/
api_key="TU_CLAVE_APIYI",
api_base="https://api.apiyi.com/v1", # URL del servicio proxy de API de APIYI
messages=[
{"role": "user", "content": "Describe LiteLLM en una sola frase"}
],
)
print(response.choices[0].message.content)
💡 Sugerencia: Una vez que obtengas saldo de prueba en el panel de control de APIYI (apiyi.com), puedes cambiar
gpt-5por nombres de modelos comoclaude-opus-4-6,gemini-3-pro, etc., sin modificar nada más en tu código. Ese es el gran valor del protocolo compatible con OpenAI.
Ver ejemplo completo ejecutable (incluye manejo de errores y streaming)
import os
import litellm
from litellm import completion
# Se recomienda gestionar las claves mediante variables de entorno
os.environ["OPENAI_API_KEY"] = "TU_CLAVE_APIYI"
os.environ["OPENAI_API_BASE"] = "https://api.apiyi.com/v1"
litellm.set_verbose = False # Cambiar a True para depuración
def chat_with_apiyi(model: str, prompt: str, stream: bool = False):
"""Invocar cualquier modelo compatible con OpenAI mediante LiteLLM + APIYI"""
try:
response = completion(
model=f"openai/{model}",
messages=[{"role": "user", "content": prompt}],
stream=stream,
temperature=0.7,
max_tokens=1024,
)
if stream:
for chunk in response:
delta = chunk.choices[0].delta.content or ""
print(delta, end="", flush=True)
print()
else:
return response.choices[0].message.content
except Exception as e:
print(f"Error en la invocación: {e}")
return None
if __name__ == "__main__":
# Sin streaming
print(chat_with_apiyi("gpt-5", "Explica qué es una pasarela de LLM"))
# Con streaming
chat_with_apiyi("claude-opus-4-6", "Describe las ventajas de LiteLLM en 100 palabras", stream=True)
Configuración Proxy YAML: Recomendado para producción
Si planeas ejecutar LiteLLM como un servicio independiente (puerto 4000, para uso compartido en equipo), te recomendamos el modo YAML. Crea un archivo litellm_config.yaml:
model_list:
- model_name: gpt-5 # Nombre del modelo expuesto
litellm_params:
model: openai/gpt-5 # Prefijo openai/ para enrutar al cliente de OpenAI
api_base: https://api.apiyi.com/v1 # URL del servicio proxy de API de APIYI
api_key: os.environ/APIYI_KEY # Referencia a la variable de entorno
- model_name: claude-opus-4-6
litellm_params:
model: openai/claude-opus-4-6
api_base: https://api.apiyi.com/v1
api_key: os.environ/APIYI_KEY
- model_name: gemini-3-pro
litellm_params:
model: openai/gemini-3-pro
api_base: https://api.apiyi.com/v1
api_key: os.environ/APIYI_KEY
litellm_settings:
drop_params: true # Descartar automáticamente parámetros no soportados
num_retries: 2 # Número de reintentos por invocación
router_settings:
fallbacks:
- gpt-5: ["claude-opus-4-6", "gemini-3-pro"]
Inicia el Proxy:
export APIYI_KEY=sk-xxxxxxxxxxxxxxxx
litellm --config ./litellm_config.yaml --port 4000
A partir de aquí, cualquier SDK de OpenAI puede realizar la invocación a través de http://localhost:4000:
from openai import OpenAI
client = OpenAI(
api_key="any-string", # El Proxy de LiteLLM no valida el contenido (a menos que se configure una master_key)
base_url="http://localhost:4000",
)
resp = client.chat.completions.create(
model="gpt-5",
messages=[{"role": "user", "content": "Hola a través del Proxy de LiteLLM"}]
)
print(resp.choices[0].message.content)
🎯 Consejo de producción: Recomendamos añadir una capa de
master_keyfrente al Proxy de LiteLLM y conectar todos los modelos subyacentes a APIYI (apiyi.com). De esta forma, tu capa de aplicación solo verá "nombres de modelos semánticos" comogpt-5oclaude-opus-4-6, mientras que los canales, la facturación y la limitación de tasa se gestionan entre APIYI y LiteLLM, sin que la capa superior lo perciba.
Modo de variables de entorno: Ideal para CLI y scripts
Para scripts rápidos y herramientas de línea de comandos, la forma más sencilla es utilizar variables de entorno. LiteLLM reconocerá automáticamente OPENAI_API_KEY y OPENAI_API_BASE:
export OPENAI_API_KEY=sk-xxxxxxxxxxxxxxxx
export OPENAI_API_BASE=https://api.apiyi.com/v1
Después, todas las invocaciones con el prefijo openai/ pasarán por APIYI:
import litellm
print(litellm.completion(
model="openai/gpt-5",
messages=[{"role": "user", "content": "ping"}]
).choices[0].message.content)
Comparativa de las tres formas de configurar LiteLLM con un servicio proxy de API
La elección depende del escenario. La siguiente tabla ofrece recomendaciones claras.
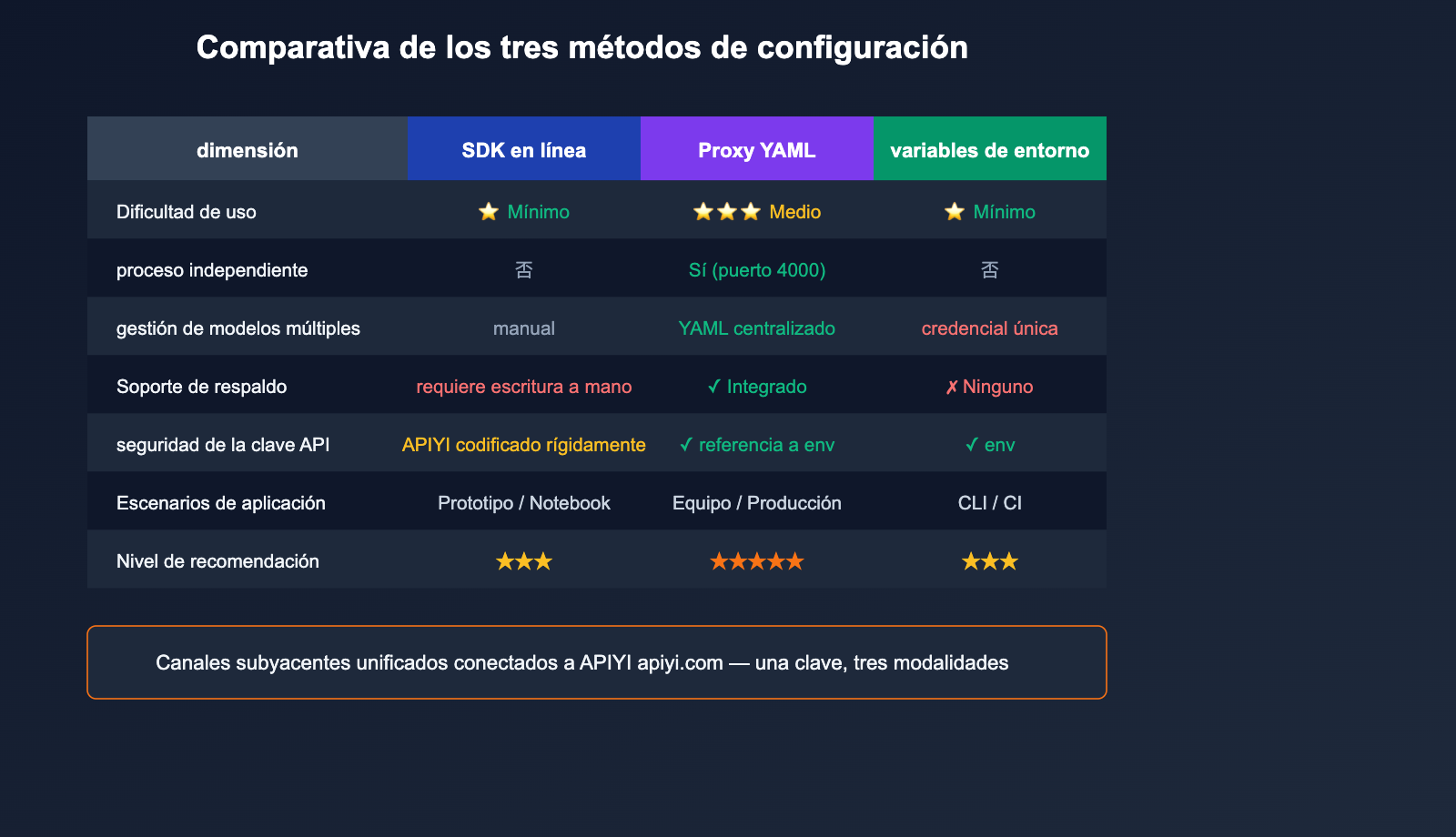
| Dimensión | SDK en línea | Proxy YAML | Variables de entorno |
|---|---|---|---|
| Dificultad | ⭐ Mínima | ⭐⭐⭐ Media | ⭐ Mínima |
| Escenario | Scripts únicos, Notebooks | Uso compartido, Producción | CLI, CI |
| Proceso independiente | No | Sí (puerto 4000) | No |
| Gestión multimodelo | Manual | Centralizada en YAML | Solo un conjunto |
| Soporte Fallback | Requiere try/except | ✅ Integrado | ❌ No |
| Seguridad de claves | Riesgo de hardcode | ✅ Referencia env | ✅ Vía env |
| Recomendación | Prototipado | Despliegue en producción | Scripts personales |
💡 Sugerencia: Para desarrollo personal, puedes usar variables de entorno; para equipos y producción, recomendamos encarecidamente el modo Proxy YAML, ya que permite gestionar el "enrutamiento de modelos + Fallback + limitación de tasa + estadísticas" en un solo archivo. Independientemente del método, la capa subyacente conectada a APIYI (apiyi.com) permanece constante; solo necesitas mantener una clave API.
Práctica de enrutamiento multimodelo con LiteLLM + APIYI
Lo realmente potente del modo Proxy de LiteLLM es que puedes usar un único archivo YAML para mapear "nombres de modelos semánticos → canales reales". A continuación, presento una configuración de enrutamiento mínima lista para producción.
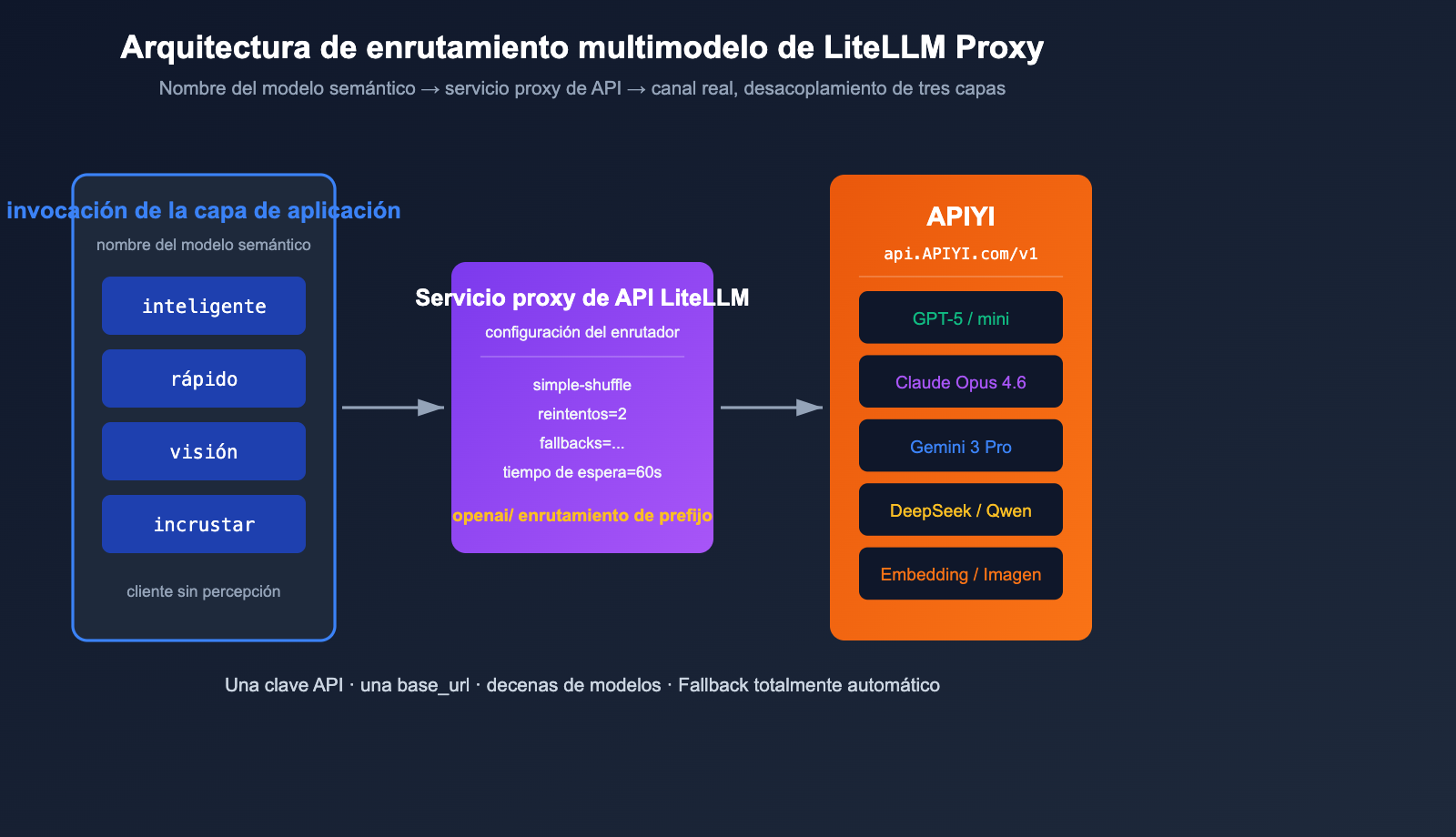
# litellm_config.yaml - Ejemplo de enrutamiento para producción
model_list:
# Modelo de inferencia principal
- model_name: smart
litellm_params:
model: openai/gpt-5
api_base: https://api.apiyi.com/v1
api_key: os.environ/APIYI_KEY
timeout: 60
- model_name: smart
litellm_params:
model: openai/claude-opus-4-6
api_base: https://api.apiyi.com/v1
api_key: os.environ/APIYI_KEY
timeout: 60
# Modelo rápido y económico
- model_name: fast
litellm_params:
model: openai/gpt-5-mini
api_base: https://api.apiyi.com/v1
api_key: os.environ/APIYI_KEY
# Visión/Multimodal
- model_name: vision
litellm_params:
model: openai/gemini-3-pro
api_base: https://api.apiyi.com/v1
api_key: os.environ/APIYI_KEY
# Embedding
- model_name: embed
litellm_params:
model: openai/text-embedding-3-large
api_base: https://api.apiyi.com/v1
api_key: os.environ/APIYI_KEY
litellm_settings:
drop_params: true
num_retries: 2
request_timeout: 60
router_settings:
routing_strategy: simple-shuffle # Round-robin para modelos con el mismo nombre
fallbacks:
- smart: ["fast"] # Degradación a 'fast' si 'smart' falla
general_settings:
master_key: sk-litellm-master-xxxx # El cliente debe incluir esta clave
La capa de aplicación solo ve cuatro nombres semánticos: smart, fast, vision y embed. Cuando GPT-5 alcanza el límite de tasa, LiteLLM cambia automáticamente a Claude Opus 4.6 (ya que ambos están registrados como smart), y si vuelve a fallar, se degrada a fast. Todo el tráfico subyacente pasa por el servicio proxy de API APIYI (apiyi.com) para una facturación y monitoreo unificados, logrando un aislamiento perfecto entre la capa superior y la capa de canales.
Preguntas frecuentes sobre la configuración de LiteLLM con un servicio proxy de terceros
Q1: ¿Por qué recibo un error 404 Not Found a pesar de haber configurado la base_url?
El 90% de las veces es porque falta /v1 al final de la api_base. LiteLLM utiliza internamente el cliente de OpenAI, que concatena automáticamente /chat/completions, por lo que tu api_base debe ser https://api.apiyi.com/v1 y no https://api.apiyi.com. Tampoco la escribas como https://api.apiyi.com/v1/chat/completions, ya que se duplicaría la ruta.
Q2: ¿Por qué es obligatorio añadir el prefijo openai/ al modelo?
LiteLLM mantiene internamente una tabla de enrutamiento de proveedores. El prefijo openai/ le indica a LiteLLM: "por favor, usa el cliente de OpenAI para acceder a este endpoint". Si no añades el prefijo, LiteLLM podría intentar coincidir con su proveedor integrado (por ejemplo, claude-opus-4-6 sería reconocido como la API nativa de Anthropic), lo que causaría un error de protocolo. Al conectar con un servicio proxy, añade siempre el prefijo openai/.
Q3: ¿Puede una clave API de APIYI llamar a varios modelos simultáneamente?
Sí. Una sola clave de APIYI (apiyi.com) admite por defecto todos los modelos disponibles en la plataforma, incluyendo GPT-5, Claude Opus 4.6, Gemini 3 Pro, DeepSeek, Qwen, etc. Esta es precisamente la diferencia clave con respecto a la API oficial: solo necesitas mantener una clave y una base_url para montar decenas de modelos en tu YAML de LiteLLM.
Q4: Una vez iniciado LiteLLM Proxy, ¿cómo verifico que el enlace del proxy funciona?
La forma más rápida es hacer un curl directamente al LiteLLM Proxy:
curl http://localhost:4000/v1/chat/completions \
-H "Authorization: Bearer sk-litellm-master-xxxx" \
-H "Content-Type: application/json" \
-d '{
"model": "smart",
"messages": [{"role": "user", "content": "ping"}]
}'
Si recibes un 200 + JSON, significa que toda la cadena Aplicación → LiteLLM Proxy → APIYI es funcional. Si falla, revisa primero los logs de la consola de LiteLLM y luego prueba la misma base_url + clave directamente contra APIYI para localizar el problema por capas.
Q5: ¿Se requiere alguna configuración adicional para la salida en streaming en escenarios de proxy?
No. APIYI (apiyi.com) admite completamente las respuestas en streaming SSE, y LiteLLM las transmite por defecto. Solo necesitas añadir stream=True en tu llamada completion() o al usar el SDK de OpenAI con el Proxy para obtener la salida token a token.
Q6: ¿Puedo conectar también Embedding y generación de imágenes?
Sí. APIYI (apiyi.com) admite simultáneamente /v1/embeddings, /v1/images/generations y /v1/audio/transcriptions, todo a través de la misma base_url y clave. En el YAML de LiteLLM, solo necesitas añadir los modelos correspondientes a la model_list, por ejemplo text-embedding-3-large, gpt-image-1 o whisper-1. Su uso es exactamente igual al de los modelos de chat, como se muestra en el ejemplo de enrutamiento de producción de la sección anterior.
Resumen
Configurar un servicio proxy de API de terceros en LiteLLM se reduce esencialmente a tres pasos:
- Alineación de protocolo: Añadir el prefijo
openai/al modelo para indicar a LiteLLM que utilice el protocolo de cliente de OpenAI. - Alineación de entrada: Configurar
api_baseapuntando a la ruta raíz del servicio proxy más/v1, por ejemplo:https://api.apiyi.com/v1. - Alineación de credenciales: Proporcionar la clave API emitida por el servicio proxy a través de
api_keyo mediante variables de entorno.
Al completar estos tres pasos, todas las funcionalidades de LiteLLM (enrutamiento de múltiples modelos, Fallback, limitación de tasa, facturación y registro) pueden integrarse sin problemas sobre un servicio proxy estable.
🚀 Sugerencia de acción: Si estás construyendo una puerta de enlace de Modelos de Lenguaje Grande unificada para tu equipo, recomendamos adoptar una arquitectura de tres capas: «Aplicación → LiteLLM Proxy → APIYI apiyi.com». LiteLLM se encarga del enrutamiento y el Fallback, mientras que APIYI gestiona el acceso a los modelos subyacentes, la estabilidad y la facturación por uso. Solo necesitas gestionar un archivo YAML y una clave. Regístrate en apiyi.com para obtener saldo de prueba y completar tu primera invocación en menos de 5 minutos.
Autor: Equipo de APIYI — Enfocados en proporcionar a los desarrolladores un acceso estable a los principales Modelos de Lenguaje Grande de IA. Visita apiyi.com para más información.
Referencias
-
Documentación oficial de LiteLLM – Endpoints compatibles con OpenAI
- Enlace:
docs.litellm.ai/docs/providers/openai_compatible - Descripción: Ejemplos oficiales para SDK y Proxy YAML.
- Enlace:
-
Resumen de configuración de LiteLLM Proxy
- Enlace:
docs.litellm.ai/docs/proxy/configs - Descripción: Campos completos para model_list, router_settings y fallbacks.
- Enlace:
-
Repositorio de GitHub de LiteLLM
- Enlace:
github.com/BerriAI/litellm - Descripción: Código fuente, problemas (Issues) y versiones más recientes.
- Enlace:
-
daily_stock_analysis – LLM_CONFIG_GUIDE
- Enlace:
github.com/ZhuLinsen/daily_stock_analysis/blob/main/docs/LLM_CONFIG_GUIDE.md - Descripción: Referencia práctica sobre tres modos de configuración y multicanalidad.
- Enlace:
-
Documentación oficial de APIYI
- Enlace:
apiyi.com - Descripción: Lista de modelos compatibles, base_url y gestión de claves.
- Enlace: