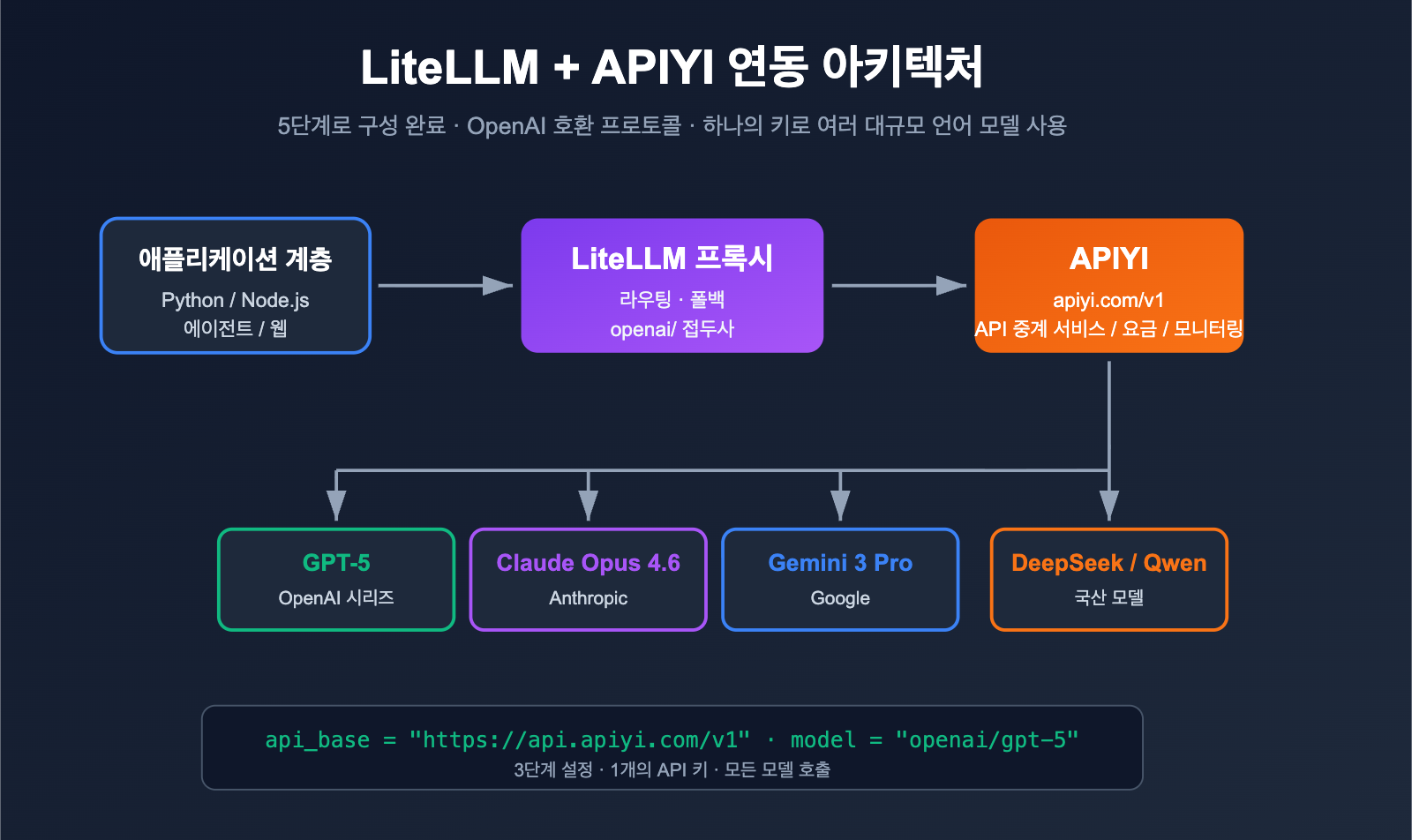
LiteLLM을 사용하여 OpenAI, Claude, Gemini, DeepSeek 등 여러 대규모 언어 모델을 동시에 관리하면서, 해외 계정, 네트워크, 결제 문제로 골머리를 앓고 계신가요? 해결책은 바로 LiteLLM을 OpenAI 호환 API 중계 서비스에 연결하는 것입니다. 이번 글에서는 LiteLLM + APIYI apiyi.com을 예로 들어, 단계별 설정 방법을 알려드릴게요.
핵심 가치: 이 글을 읽고 나면 LiteLLM에서 API 중계 서비스를 설정하는 3가지 주요 방식(SDK, Proxy YAML, 환경 변수)을 마스터하게 되며, 5분 안에 APIYI 연동을 완료할 수 있습니다.
LiteLLM 설정 핵심 요약
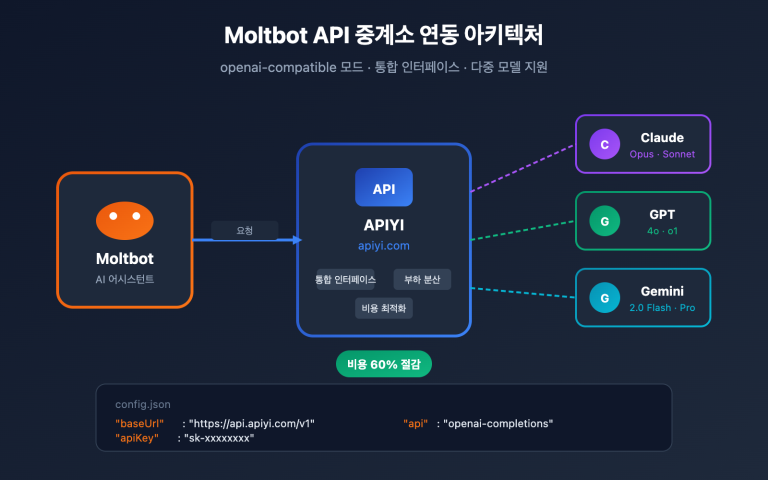
LiteLLM은 오픈 소스 LLM 게이트웨이/SDK로, OpenAI 호환 형식으로 100개 이상의 대규모 언어 모델을 호출하는 것을 목표로 합니다. 기본적으로 모든 "OpenAI 호환" 엔드포인트를 지원하므로, api_base를 중계 서비스 주소로 설정하고 api_key를 해당 서비스에서 발급받은 키로 교체하기만 하면 됩니다. APIYI apiyi.com은 표준 OpenAI 호환 중계 서비스이므로 두 서비스는 완벽하게 호환됩니다.
| 핵심 포인트 | 설명 | 가치 |
|---|---|---|
| OpenAI 호환 프로토콜 | LiteLLM은 openai/ 접두사를 통해 OpenAI 클라이언트로 라우팅 |
한 줄 설정으로 모든 중계 서비스 연동 |
| 3가지 설정 방식 | SDK 인라인 / Proxy YAML / 환경 변수 | 스크립트, 프로덕션, CLI 환경에 최적화 |
| 통합 모델 명명 | openai/<provider-model> 또는 사용자 지정 model_name |
상위 코드에서 하위 모델 변경을 감지할 필요 없음 |
| 오류 해결 핵심 | base_url은 반드시 /v1으로 끝나야 함 |
404 오류의 90%는 여기서 발생 |
| Fallback 및 로드 밸런싱 | YAML 모드에서 다중 채널 및 실패 시 대체 지원 | 프로덕션 환경의 가용성 극대화 |
LiteLLM 설정 상세 가이드
LiteLLM 공식 문서에 따르면, 모델 이름 앞에 openai/ 접두사를 붙이고 api_base를 지정하면, LiteLLM은 OpenAI 클라이언트를 사용하여 해당 엔드포인트에 접근합니다. 즉, 중계 서비스 뒤에 GPT-5, Claude Opus 4.6, Gemini 3 Pro, DeepSeek 중 무엇이 있든 LiteLLM 입장에서는 모두 "하나의 OpenAI 엔드포인트"일 뿐입니다.
APIYI apiyi.com의 base_url은 https://api.apiyi.com/v1이며, 표준 /v1/chat/completions, /v1/embeddings, /v1/images/generations 규격을 따르므로 별도의 패치 없이 LiteLLM과 완벽하게 호환됩니다.

LiteLLM 설정 및 API 중계 서비스 활용 가이드
준비 사항
시작하기 전에 다음 항목들을 준비해 주세요:
- APIYI API 키: apiyi.com에 가입한 후, 콘솔에서 새로운 키를 생성하세요 (이름은
litellm-prod를 추천해요). - base_url:
https://api.apiyi.com/v1(끝에/v1이 반드시 포함되어야 해요!) - Python 환경: Python 3.9 이상
- 의존성 설치:
pip install litellm
초간단 예제: SDK 인라인 설정
가장 빠르게 시작하는 방법은 코드 내에서 api_key와 api_base를 직접 전달하는 것입니다:
import litellm
response = litellm.completion(
model="openai/gpt-5", # 핵심: openai/ 접두사 사용
api_key="YOUR_APIYI_KEY",
api_base="https://api.apiyi.com/v1", # APIYI 중계 서비스 주소
messages=[
{"role": "user", "content": "LiteLLM을 한 문장으로 소개해줘"}
],
)
print(response.choices[0].message.content)
💡 팁: APIYI apiyi.com 콘솔에서 테스트 크레딧을 받은 후,
gpt-5를claude-opus-4-6,gemini-3-pro등 다른 모델명으로 바꿔보세요. 코드를 수정할 필요가 전혀 없습니다. 이것이 바로 OpenAI 호환 프로토콜의 가장 큰 장점이죠.
전체 실행 예제 보기 (에러 처리 및 스트리밍 출력 포함)
import os
import litellm
from litellm import completion
# 환경 변수로 키를 관리하는 것을 권장해요
os.environ["OPENAI_API_KEY"] = "YOUR_APIYI_KEY"
os.environ["OPENAI_API_BASE"] = "https://api.apiyi.com/v1"
litellm.set_verbose = False # 디버깅 시 True로 변경
def chat_with_apiyi(model: str, prompt: str, stream: bool = False):
"""LiteLLM + APIYI를 통해 OpenAI 호환 모델 호출"""
try:
response = completion(
model=f"openai/{model}",
messages=[{"role": "user", "content": prompt}],
stream=stream,
temperature=0.7,
max_tokens=1024,
)
if stream:
for chunk in response:
delta = chunk.choices[0].delta.content or ""
print(delta, end="", flush=True)
print()
else:
return response.choices[0].message.content
except Exception as e:
print(f"호출 실패: {e}")
return None
if __name__ == "__main__":
# 비스트리밍
print(chat_with_apiyi("gpt-5", "LLM 게이트웨이가 무엇인지 설명해줘"))
# 스트리밍
chat_with_apiyi("claude-opus-4-6", "LiteLLM의 장점을 100자로 소개해줘", stream=True)
Proxy YAML 설정: 운영 환경 추천
LiteLLM을 독립적인 서비스(포트 4000, 팀 공유용)로 운영하려면 YAML 모드를 추천합니다. litellm_config.yaml 파일을 새로 만드세요:
model_list:
- model_name: gpt-5 # 외부 노출 모델명
litellm_params:
model: openai/gpt-5 # openai/ 접두사, OpenAI 클라이언트로 라우팅
api_base: https://api.apiyi.com/v1 # APIYI 중계 주소
api_key: os.environ/APIYI_KEY # 환경 변수 참조
- model_name: claude-opus-4-6
litellm_params:
model: openai/claude-opus-4-6
api_base: https://api.apiyi.com/v1
api_key: os.environ/APIYI_KEY
- model_name: gemini-3-pro
litellm_params:
model: openai/gemini-3-pro
api_base: https://api.apiyi.com/v1
api_key: os.environ/APIYI_KEY
litellm_settings:
drop_params: true # 모델이 지원하지 않는 파라미터 자동 제거
num_retries: 2 # 호출 재시도 횟수
router_settings:
fallbacks:
- gpt-5: ["claude-opus-4-6", "gemini-3-pro"]
프록시 실행:
export APIYI_KEY=sk-xxxxxxxxxxxxxxxx
litellm --config ./litellm_config.yaml --port 4000
이제 모든 OpenAI SDK에서 http://localhost:4000을 통해 호출할 수 있습니다:
from openai import OpenAI
client = OpenAI(
api_key="any-string", # LiteLLM 프록시는 내용을 검증하지 않음 (master_key 설정 시 제외)
base_url="http://localhost:4000",
)
resp = client.chat.completions.create(
model="gpt-5",
messages=[{"role": "user", "content": "Hello via LiteLLM Proxy"}]
)
print(resp.choices[0].message.content)
🎯 운영 팁: LiteLLM 프록시 앞에 master_key를 추가하고, 모든 하위 모델을 APIYI apiyi.com에 통합하는 것을 권장합니다. 이렇게 하면 애플리케이션 계층에서는
gpt-5/claude-opus-4-6같은 "의미론적 모델명"만 보게 되며, 하위 채널, 과금, 속도 제한은 APIYI + LiteLLM이 처리하여 상위 계층은 신경 쓸 필요가 없습니다.
환경 변수 모드: CLI 및 스크립트에 최적
일회성 스크립트나 명령줄 도구의 경우, 환경 변수를 사용하는 것이 가장 간단합니다. LiteLLM은 OPENAI_API_KEY와 OPENAI_API_BASE를 자동으로 인식합니다:
export OPENAI_API_KEY=sk-xxxxxxxxxxxxxxxx
export OPENAI_API_BASE=https://api.apiyi.com/v1
이후 openai/ 접두사가 붙은 모든 호출은 APIYI를 거치게 됩니다:
import litellm
print(litellm.completion(
model="openai/gpt-5",
messages=[{"role": "user", "content": "ping"}]
).choices[0].message.content)
LiteLLM 설정 방식 3가지 비교
상황에 따라 적합한 설정 방식이 다릅니다. 아래 표를 참고하여 선택해 보세요.
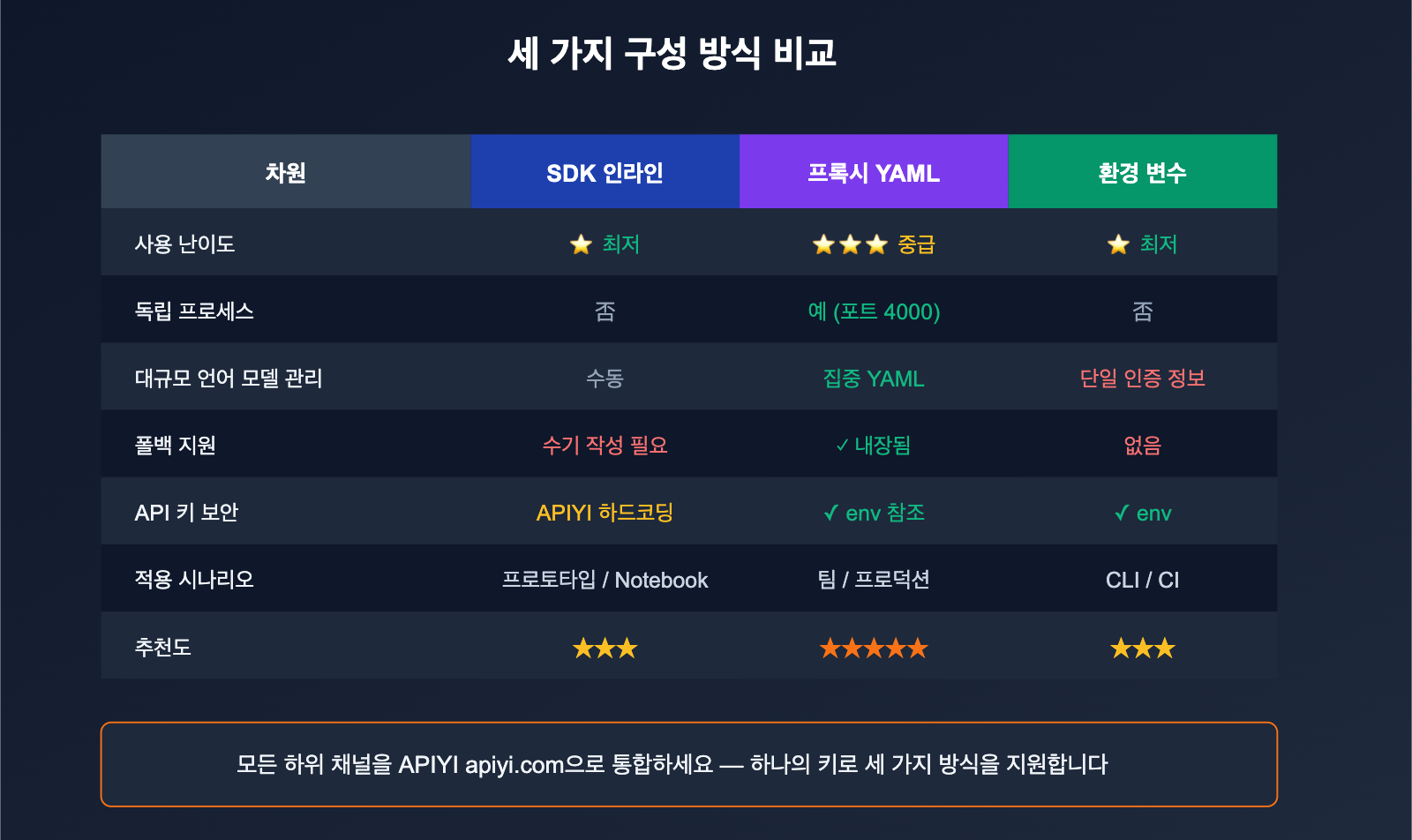
| 구분 | SDK 인라인 | Proxy YAML | 환경 변수 |
|---|---|---|---|
| 난이도 | ⭐ 최하 | ⭐⭐⭐ 보통 | ⭐ 최하 |
| 적합한 상황 | 단일 스크립트, 노트북 | 팀 공유, 운영 서비스 | CLI 도구, CI |
| 독립 프로세스 | 아니오 | 예 (포트 4000) | 아니오 |
| 다중 모델 관리 | 수동 관리 | YAML 집중 관리 | 단일 자격 증명만 |
| Fallback 지원 | 직접 구현 필요 | ✅ 내장 | ❌ 없음 |
| 키 보안성 | 하드코딩 위험 | ✅ 환경 변수 참조 | ✅ 환경 변수 사용 |
| 추천도 | 프로토타입 단계 | 운영 환경 | 개인용 스크립트 |
💡 선택 가이드: 개인 개발 시에는 환경 변수를 사용하고, 팀이나 운영 환경에서는 Proxy YAML 모드를 강력하게 추천합니다. "모델 라우팅 + Fallback + 속도 제한 + 통계"를 파일 하나로 관리할 수 있기 때문입니다. 어떤 방식을 선택하든 하위 채널을 APIYI apiyi.com으로 연결하는 것은 동일하며, API 키 하나만 유지하면 됩니다.
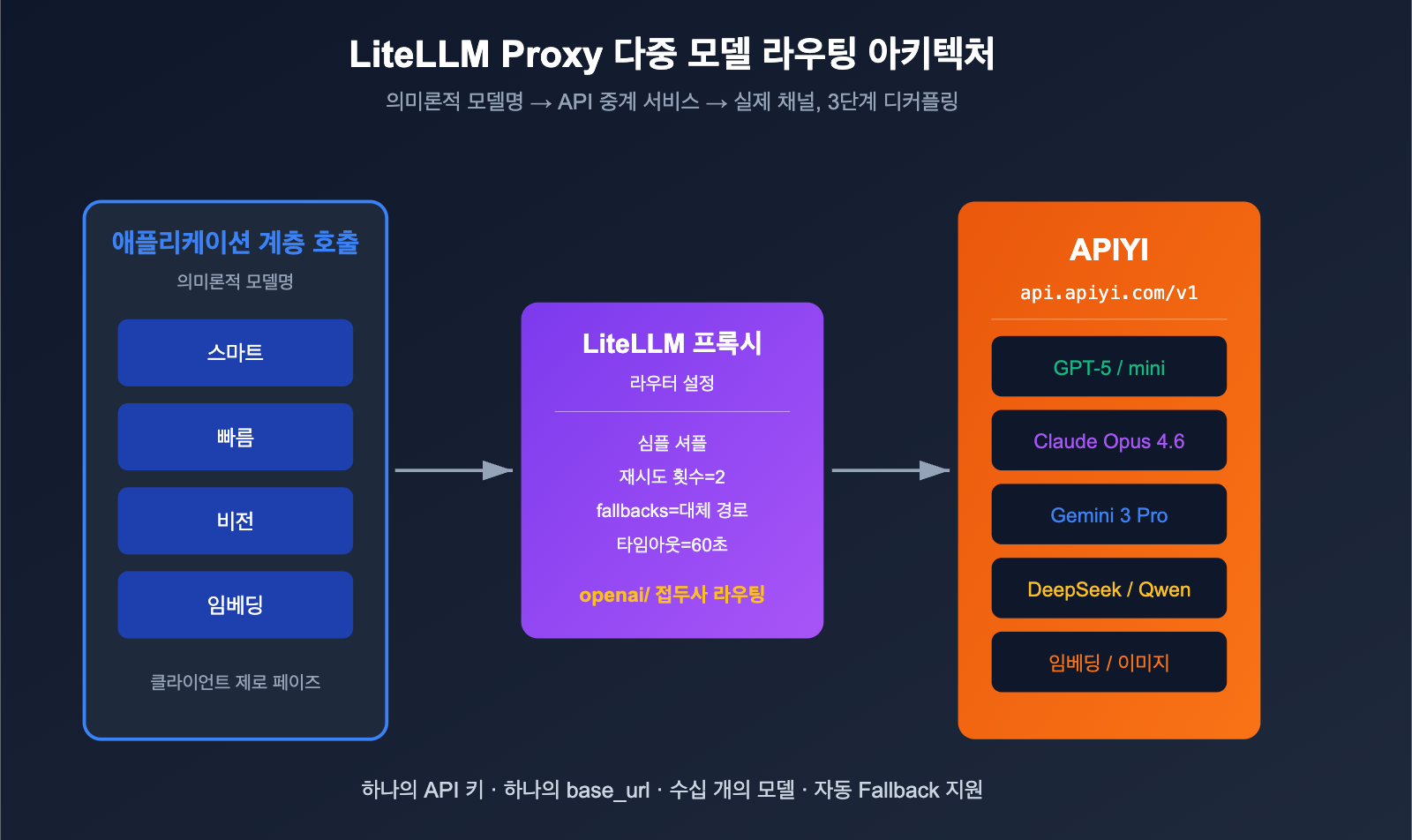
LiteLLM + APIYI 다중 모델 라우팅 실전
LiteLLM 프록시 모드의 진정한 강점은 동일한 YAML 파일 하나로 "의미론적 모델명 → 실제 채널" 매핑을 완료할 수 있다는 점입니다. 아래에 프로덕션 환경에서 바로 사용할 수 있는 최소 라우팅 설정을 소개합니다.
# litellm_config.yaml - 프로덕션 라우팅 예시
model_list:
# 메인 추론 모델
- model_name: smart
litellm_params:
model: openai/gpt-5
api_base: https://api.apiyi.com/v1
api_key: os.environ/APIYI_KEY
timeout: 60
- model_name: smart
litellm_params:
model: openai/claude-opus-4-6
api_base: https://api.apiyi.com/v1
api_key: os.environ/APIYI_KEY
timeout: 60
# 저비용 고속 모델
- model_name: fast
litellm_params:
model: openai/gpt-5-mini
api_base: https://api.apiyi.com/v1
api_key: os.environ/APIYI_KEY
# 시각/멀티모달
- model_name: vision
litellm_params:
model: openai/gemini-3-pro
api_base: https://api.apiyi.com/v1
api_key: os.environ/APIYI_KEY
# 임베딩
- model_name: embed
litellm_params:
model: openai/text-embedding-3-large
api_base: https://api.apiyi.com/v1
api_key: os.environ/APIYI_KEY
litellm_settings:
drop_params: true
num_retries: 2
request_timeout: 60
router_settings:
routing_strategy: simple-shuffle # 동일 이름 모델 라운드 로빈
fallbacks:
- smart: ["fast"] # smart 실패 시 fast로 폴백
general_settings:
master_key: sk-litellm-master-xxxx # 클라이언트는 반드시 이 키를 사용해야 함
애플리케이션 계층에서는 smart / fast / vision / embed라는 네 가지 의미론적 이름만 사용하면 됩니다. GPT-5에 속도 제한이 걸리면 LiteLLM이 자동으로 Claude Opus 4.6으로 전환하고(둘 다 smart로 등록되어 있으므로), 여기서도 실패하면 fast로 폴백합니다. 모든 하위 트래픽은 APIYI(apiyi.com)를 통해 통합 과금 및 모니터링되므로, 상위 애플리케이션과 채널 계층이 완벽하게 분리됩니다.
LiteLLM 설정 및 API 중계 서비스 관련 FAQ
Q1: base_url을 설정했는데도 404 Not Found 오류가 발생합니다. 왜 그런가요?
90%의 경우 api_base 끝에 /v1이 빠져서 발생하는 문제입니다. LiteLLM은 내부적으로 OpenAI 클라이언트를 사용하며, 자동으로 /chat/completions를 뒤에 붙입니다. 따라서 api_base는 https://api.apiyi.com/v1이어야 하며, https://api.apiyi.com으로 설정하면 안 됩니다. 또한 https://api.apiyi.com/v1/chat/completions라고 적으면 경로가 중복되니 주의하세요.
Q2: 왜 모델명 앞에 openai/ 접두사를 붙여야 하나요?
LiteLLM은 내부적으로 프로바이더 라우팅 테이블을 관리합니다. openai/ 접두사는 LiteLLM에게 "OpenAI 클라이언트를 사용하여 이 엔드포인트에 접속하라"고 알려주는 역할을 합니다. 접두사를 붙이지 않으면 LiteLLM이 내장된 프로바이더와 매칭을 시도하여(예: claude-opus-4-6을 Anthropic 네이티브 API로 인식 등) 프로토콜 오류가 발생할 수 있습니다. API 중계 서비스를 사용할 때는 항상 openai/ 접두사를 붙이세요.
Q3: APIYI 키 하나로 여러 모델을 동시에 호출할 수 있나요?
네, 가능합니다. APIYI(apiyi.com)의 단일 키는 기본적으로 플랫폼에서 제공하는 모든 모델(GPT-5, Claude Opus 4.6, Gemini 3 Pro, DeepSeek, Qwen 등)을 지원합니다. 이것이 공식 API와 차별화되는 핵심 장점입니다. 키 하나와 base_url 하나만 유지하면 LiteLLM YAML 설정에서 수십 개의 모델을 자유롭게 구성할 수 있습니다.
Q4: LiteLLM 프록시 실행 후, 중계 경로가 정상인지 어떻게 확인하나요?
가장 빠른 방법은 curl을 사용하여 LiteLLM 프록시에 직접 요청을 보내는 것입니다:
curl http://localhost:4000/v1/chat/completions \
-H "Authorization: Bearer sk-litellm-master-xxxx" \
-H "Content-Type: application/json" \
-d '{
"model": "smart",
"messages": [{"role": "user", "content": "ping"}]
}'
200 OK와 함께 JSON 응답이 오면 애플리케이션 → LiteLLM 프록시 → APIYI 전체 경로가 원활하게 작동하는 것입니다. 실패할 경우 LiteLLM 콘솔 로그를 먼저 확인하고, 동일한 base_url과 키를 사용하여 APIYI에 직접 요청을 보내 문제 지점을 파악하세요.
Q5: 스트리밍(stream) 출력 시 중계 환경에서 추가 설정이 필요한가요?
아니요, 필요 없습니다. APIYI(apiyi.com)는 SSE 스트리밍 응답을 완벽하게 지원하며, LiteLLM은 이를 기본적으로 통과시킵니다. completion() 호출 시 stream=True를 설정하거나, OpenAI SDK로 프록시를 호출할 때 stream=True를 추가하면 토큰 단위의 실시간 출력을 받을 수 있습니다.
Q6: 임베딩과 이미지 생성도 동시에 연결할 수 있나요?
네, 가능합니다. APIYI(apiyi.com)는 /v1/embeddings, /v1/images/generations, /v1/audio/transcriptions를 모두 지원하며, 동일한 base_url과 키를 사용합니다. LiteLLM YAML의 model_list에 해당 모델(예: text-embedding-3-large, gpt-image-1, whisper-1)을 추가하기만 하면 됩니다. 사용 방식은 대화형 모델과 완전히 동일합니다. 자세한 내용은 앞서 설명한 프로덕션 라우팅 예시를 참고하세요.
요약
LiteLLM에서 타사 API 중계 서비스를 설정하는 것은 본질적으로 다음 세 가지만 기억하면 됩니다.
- 프로토콜 맞춤: 모델명 앞에
openai/접두사를 붙여 LiteLLM이 OpenAI 클라이언트 프로토콜을 사용하도록 설정합니다. - 엔드포인트 맞춤:
api_base를 중계 서비스의 루트 경로 +/v1으로 지정합니다. (예:https://api.apiyi.com/v1) - 인증 맞춤: 중계 서비스에서 발급받은 키를
api_key또는 환경 변수를 통해 전달합니다.
이 세 단계만 완료하면 LiteLLM의 모든 기능(멀티 모델 라우팅, Fallback, 속도 제한, 과금, 로깅 등)을 안정적인 중계 서비스 위에서 원활하게 활용할 수 있습니다.
🚀 실행 제안: 팀을 위한 통합 LLM 게이트웨이를 구축 중이라면 「애플리케이션 → LiteLLM Proxy → APIYI apiyi.com」의 3계층 아키텍처를 권장합니다. LiteLLM은 라우팅과 Fallback을 담당하고, APIYI는 하위 모델 연결, 안정성 및 종량제 과금을 담당합니다. 여러분은 YAML 파일 하나와 키 하나만 관리하면 됩니다. apiyi.com에 가입하여 테스트 크레딧을 받고 5분 안에 첫 호출을 완료해 보세요.
작성자: APIYI Team — 개발자에게 주요 대규모 언어 모델의 안정적인 연결을 제공하는 데 집중합니다. apiyi.com에서 더 많은 정보를 확인하세요.
참고 자료
-
LiteLLM 공식 문서 – OpenAI 호환 엔드포인트
- 링크:
docs.litellm.ai/docs/providers/openai_compatible - 설명: SDK 및 Proxy YAML 공식 예제
- 링크:
-
LiteLLM Proxy 설정 개요
- 링크:
docs.litellm.ai/docs/proxy/configs - 설명: model_list, router_settings, fallbacks 전체 필드 정보
- 링크:
-
LiteLLM GitHub 저장소
- 링크:
github.com/BerriAI/litellm - 설명: 소스 코드, 이슈, 최신 버전 확인
- 링크:
-
daily_stock_analysis – LLM_CONFIG_GUIDE
- 링크:
github.com/ZhuLinsen/daily_stock_analysis/blob/main/docs/LLM_CONFIG_GUIDE.md - 설명: 3가지 설정 모드 및 다중 채널 실전 참고 자료
- 링크:
-
APIYI 공식 문서
- 링크:
apiyi.com - 설명: 지원 모델 목록, base_url 및 키 관리 안내
- 링크: