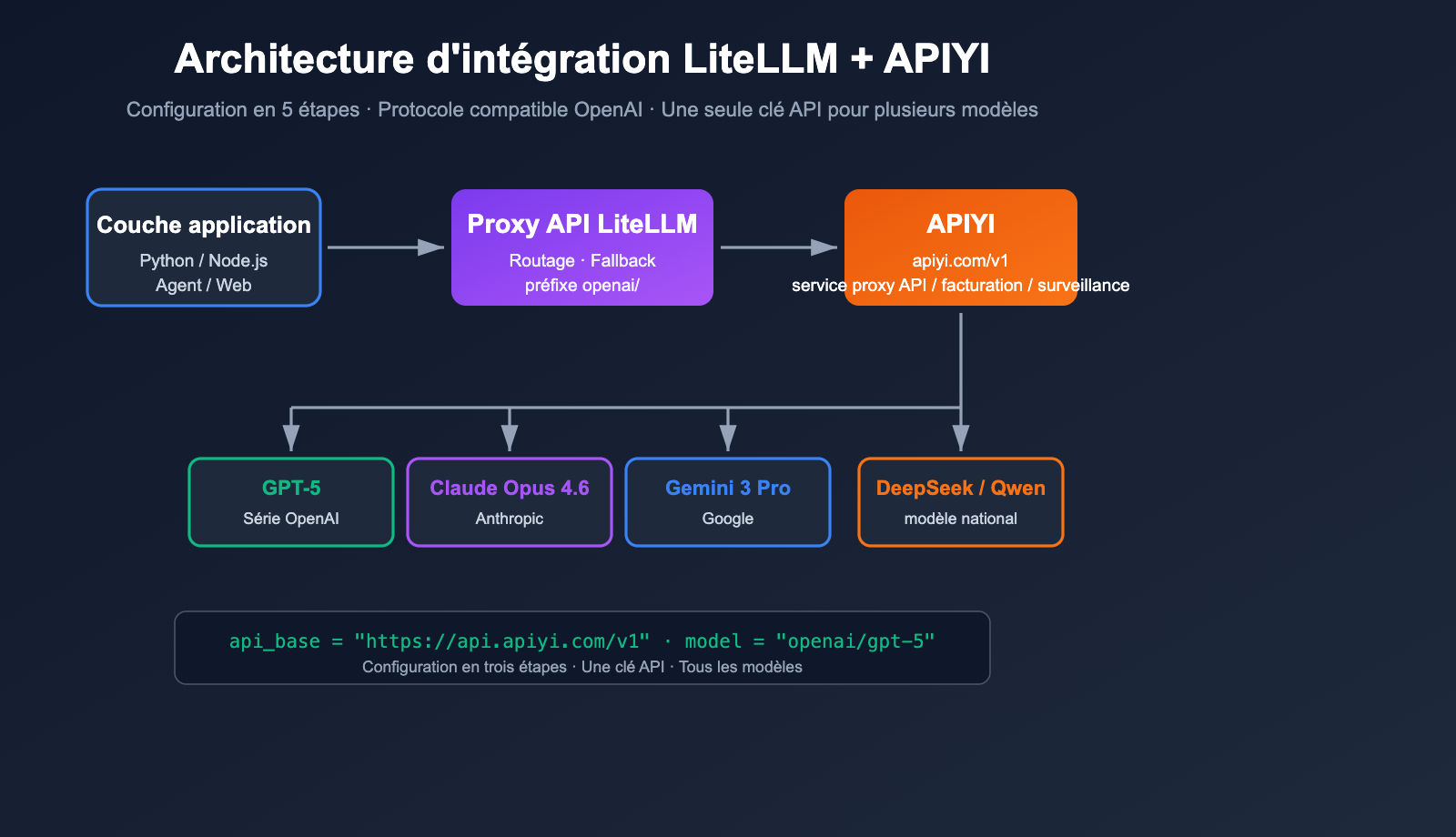
Comment faire en sorte que LiteLLM orchestre simultanément des grands modèles de langage comme OpenAI, Claude, Gemini ou DeepSeek, sans être bloqué par des problèmes de comptes étrangers, de réseau ou de paiement ? La réponse consiste à connecter LiteLLM à un service proxy API tiers compatible avec OpenAI. Dans cet article, nous allons prendre LiteLLM + APIYI apiyi.com comme exemple pour vous guider pas à pas dans la configuration.
Valeur ajoutée : En lisant cet article, vous maîtriserez les 3 méthodes principales pour configurer un service proxy API tiers dans LiteLLM (SDK, fichier YAML de proxy, variables d'environnement) et vous pourrez finaliser l'intégration d'APIYI en moins de 5 minutes.
Points clés de la configuration de LiteLLM avec un service proxy API
LiteLLM est une passerelle / SDK LLM open source dont l'objectif est d'invoquer plus de 100 grands modèles de langage en utilisant le format compatible OpenAI. Il prend nativement en charge n'importe quel point de terminaison "compatible OpenAI" ; il suffit de pointer api_base vers le service proxy et de remplacer api_key par la clé fournie par le service. APIYI apiyi.com est un service proxy standard compatible OpenAI, les deux sont donc parfaitement adaptés.
| Point clé | Description | Valeur |
|---|---|---|
| Protocole compatible OpenAI | LiteLLM utilise le préfixe openai/ pour router vers le client OpenAI |
Une ligne de configuration pour connecter n'importe quel proxy |
| Trois méthodes de configuration | SDK inline / Proxy YAML / Variables d'environnement | Adapté aux scripts, à la production et aux scénarios CLI |
| Nommage unifié des modèles | openai/<provider-model> ou nom de modèle personnalisé |
Le code de haut niveau n'a pas besoin de gérer les changements sous-jacents |
| Diagnostic d'erreurs | base_url doit se terminer par /v1 |
90 % des erreurs 404 viennent de là |
| Fallback et équilibrage de charge | Le mode YAML prend en charge plusieurs canaux et le basculement en cas d'échec | Maximise la disponibilité en environnement de production |
Détails sur la configuration de LiteLLM avec un service proxy tiers
La documentation officielle de LiteLLM est claire : il suffit d'ajouter le préfixe openai/ au nom du modèle et de spécifier api_base pour que LiteLLM utilise le client OpenAI pour accéder à votre point de terminaison. Cela signifie que peu importe que le service proxy soit connecté à GPT-5, Claude Opus 4.6, Gemini 3 Pro ou DeepSeek, pour LiteLLM, il s'agit toujours d'un "point de terminaison OpenAI".
L'URL de base (base_url) d'APIYI apiyi.com est https://api.apiyi.com/v1. Elle respecte les spécifications standard /v1/chat/completions, /v1/embeddings et /v1/images/generations, ce qui la rend parfaitement compatible avec LiteLLM, sans aucun correctif nécessaire.
Démarrage rapide avec LiteLLM et un service proxy API tiers
Prérequis
Avant de commencer, assurez-vous d'avoir :
- Clé API APIYI : Après votre inscription sur apiyi.com, créez une nouvelle clé dans la console (nous vous suggérons de la nommer
litellm-prod). - base_url :
https://api.apiyi.com/v1(attention, le/v1à la fin est obligatoire). - Environnement Python : Python 3.9+.
- Installation des dépendances :
pip install litellm.
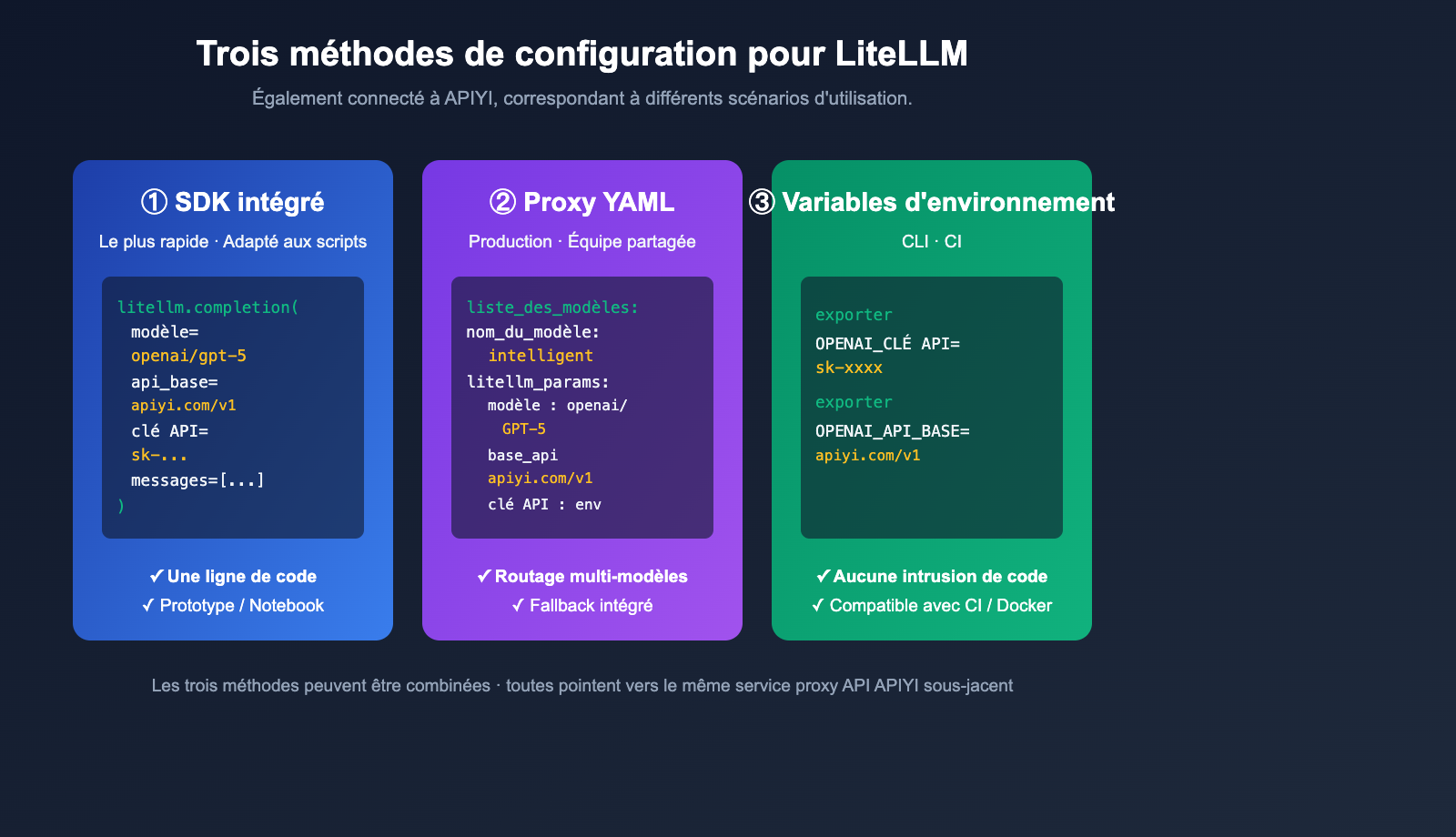
Exemple minimaliste : Configuration intégrée au SDK
La méthode la plus rapide consiste à transmettre directement api_key et api_base dans votre code :
import litellm
response = litellm.completion(
model="openai/gpt-5", # Clé : préfixe openai/
api_key="VOTRE_CLE_APIYI",
api_base="https://api.apiyi.com/v1", # URL du service proxy API APIYI
messages=[
{"role": "user", "content": "Présente LiteLLM en une phrase"}
],
)
print(response.choices[0].message.content)
💡 Conseil : Une fois que vous avez obtenu des crédits de test via la console APIYI (apiyi.com), vous pouvez remplacer
gpt-5par des noms de modèles commeclaude-opus-4-6ougemini-3-prosans modifier le reste de votre code — c'est tout l'intérêt du protocole compatible OpenAI.
Voir l’exemple complet (avec gestion d’erreurs et streaming)
import os
import litellm
from litellm import completion
# Il est recommandé de gérer les clés via des variables d'environnement
os.environ["OPENAI_API_KEY"] = "VOTRE_CLE_APIYI"
os.environ["OPENAI_API_BASE"] = "https://api.apiyi.com/v1"
litellm.set_verbose = False # Mettre à True pour le débogage
def chat_with_apiyi(model: str, prompt: str, stream: bool = False):
"""Appeler n'importe quel modèle compatible OpenAI via LiteLLM + APIYI"""
try:
response = completion(
model=f"openai/{model}",
messages=[{"role": "user", "content": prompt}],
stream=stream,
temperature=0.7,
max_tokens=1024,
)
if stream:
for chunk in response:
delta = chunk.choices[0].delta.content or ""
print(delta, end="", flush=True)
print()
else:
return response.choices[0].message.content
except Exception as e:
print(f"Échec de l'invocation : {e}")
return None
if __name__ == "__main__":
# Non-streaming
print(chat_with_apiyi("gpt-5", "Explique ce qu'est une passerelle LLM"))
# Streaming
chat_with_apiyi("claude-opus-4-6", "Présente les avantages de LiteLLM en 100 mots", stream=True)
Configuration Proxy YAML : Recommandé pour la production
Si vous souhaitez exécuter LiteLLM comme un service indépendant (port 4000, partagé par l'équipe), le mode YAML est idéal. Créez un fichier litellm_config.yaml :
model_list:
- model_name: gpt-5 # Nom du modèle exposé
litellm_params:
model: openai/gpt-5 # Préfixe openai/ pour router vers le client OpenAI
api_base: https://api.apiyi.com/v1 # URL du service proxy APIYI
api_key: os.environ/APIYI_KEY # Référence à la variable d'environnement
- model_name: claude-opus-4-6
litellm_params:
model: openai/claude-opus-4-6
api_base: https://api.apiyi.com/v1
api_key: os.environ/APIYI_KEY
- model_name: gemini-3-pro
litellm_params:
model: openai/gemini-3-pro
api_base: https://api.apiyi.com/v1
api_key: os.environ/APIYI_KEY
litellm_settings:
drop_params: true # Supprime automatiquement les paramètres non supportés
num_retries: 2 # Nombre de tentatives en cas d'échec
router_settings:
fallbacks:
- gpt-5: ["claude-opus-4-6", "gemini-3-pro"]
Lancement du proxy :
export APIYI_KEY=sk-xxxxxxxxxxxxxxxx
litellm --config ./litellm_config.yaml --port 4000
Désormais, n'importe quel SDK OpenAI peut appeler le service via http://localhost:4000 :
from openai import OpenAI
client = OpenAI(
api_key="nimporte-quoi", # LiteLLM Proxy ne vérifie pas le contenu (sauf si master_key configurée)
base_url="http://localhost:4000",
)
resp = client.chat.completions.create(
model="gpt-5",
messages=[{"role": "user", "content": "Bonjour via le proxy LiteLLM"}]
)
print(resp.choices[0].message.content)
🎯 Conseil de production : Nous recommandons d'ajouter une couche
master_keydevant le proxy LiteLLM et de connecter tous les modèles sous-jacents à APIYI. Ainsi, votre application ne voit que des "noms de modèles sémantiques" commegpt-5ouclaude-opus-4-6, tandis que les canaux, la facturation et les limites de débit sont gérés par le duo APIYI + LiteLLM.
Mode variables d'environnement : Le plus simple pour les scripts
Pour les scripts ponctuels et les outils en ligne de commande, le plus simple est d'utiliser les variables d'environnement. LiteLLM détecte automatiquement OPENAI_API_KEY et OPENAI_API_BASE :
export OPENAI_API_KEY=sk-xxxxxxxxxxxxxxxx
export OPENAI_API_BASE=https://api.apiyi.com/v1
Toutes les invocations avec le préfixe openai/ passeront alors par APIYI :
import litellm
print(litellm.completion(
model="openai/gpt-5",
messages=[{"role": "user", "content": "ping"}]
).choices[0].message.content)
Comparaison des trois méthodes de configuration pour LiteLLM
Le choix de la méthode dépend de votre cas d'usage. Le tableau ci-dessous vous aide à décider.

| Dimension | SDK intégré | Proxy YAML | Variables d'env. |
|---|---|---|---|
| Difficulté | ⭐ Très facile | ⭐⭐⭐ Moyen | ⭐ Très facile |
| Usage | Scripts, Notebooks | Équipe, Production | CLI, CI |
| Processus dédié | Non | Oui (port 4000) | Non |
| Gestion multi-modèles | Manuel | Centralisé (YAML) | Une seule clé |
| Support Fallback | Manuel (try/except) | ✅ Intégré | ❌ Aucun |
| Sécurité clé | Risque (hardcode) | ✅ Via env | ✅ Via env |
| Recommandation | Prototypage | Production | Scripts perso |
💡 Conseil : Pour le développement personnel, les variables d'environnement suffisent. Pour les équipes et la production, nous recommandons vivement le mode Proxy YAML, car il centralise le routage, le fallback, le débit et les statistiques. Quelle que soit la méthode, la connexion à APIYI reste identique : vous n'avez qu'une seule clé API à gérer.
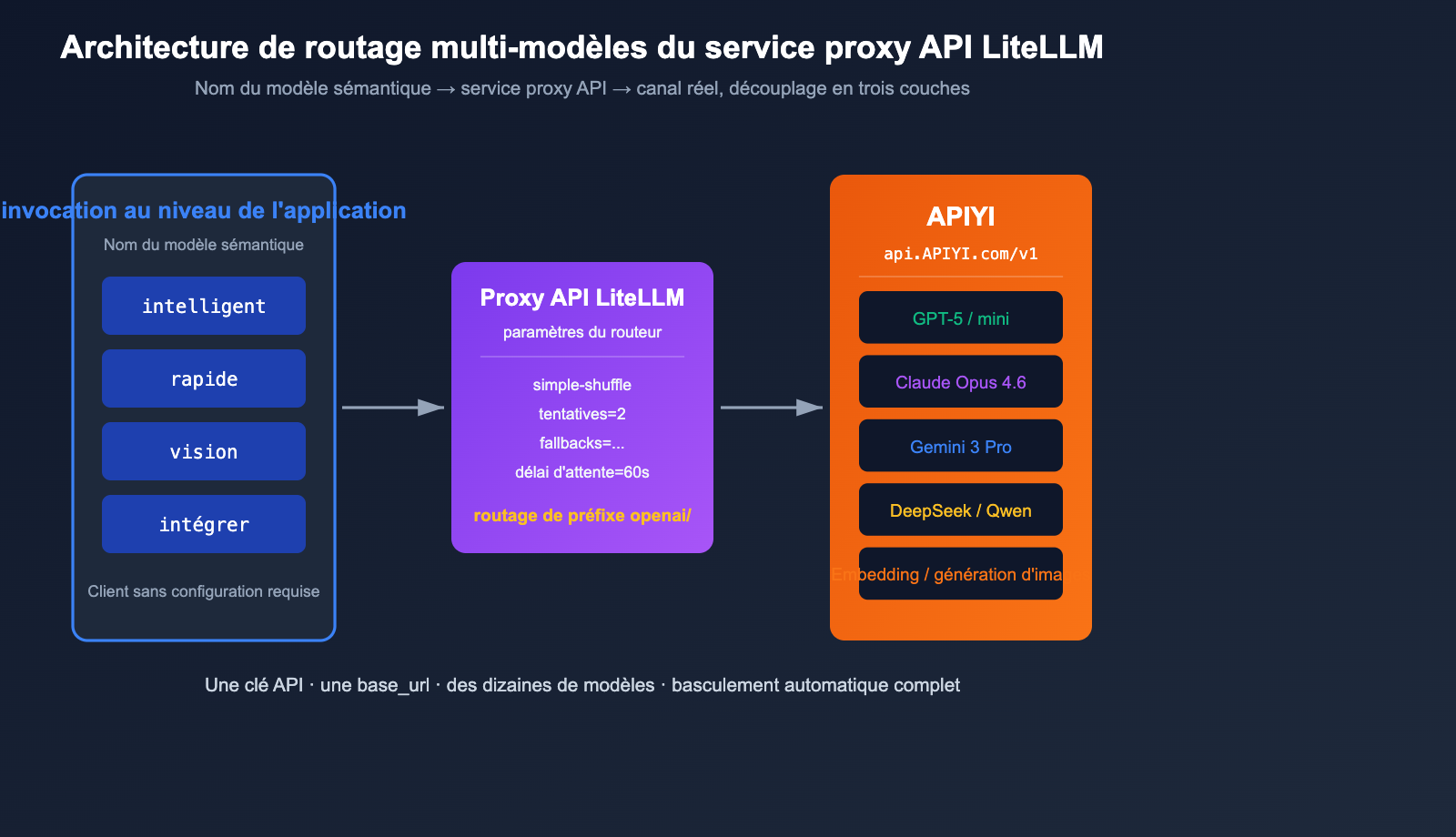
Pratique du routage multi-modèles avec LiteLLM + APIYI
La véritable puissance du mode Proxy de LiteLLM réside dans sa capacité à utiliser un seul fichier YAML pour mapper des « noms de modèles sémantiques » vers des « canaux réels ». Voici une configuration de routage minimale prête pour la production.
# litellm_config.yaml - Exemple de routage en production
model_list:
# Modèles d'inférence principaux
- model_name: smart
litellm_params:
model: openai/gpt-5
api_base: https://api.apiyi.com/v1
api_key: os.environ/APIYI_KEY
timeout: 60
- model_name: smart
litellm_params:
model: openai/claude-opus-4-6
api_base: https://api.apiyi.com/v1
api_key: os.environ/APIYI_KEY
timeout: 60
# Modèles rapides et économiques
- model_name: fast
litellm_params:
model: openai/gpt-5-mini
api_base: https://api.apiyi.com/v1
api_key: os.environ/APIYI_KEY
# Vision / Multimodal
- model_name: vision
litellm_params:
model: openai/gemini-3-pro
api_base: https://api.apiyi.com/v1
api_key: os.environ/APIYI_KEY
# Embedding
- model_name: embed
litellm_params:
model: openai/text-embedding-3-large
api_base: https://api.apiyi.com/v1
api_key: os.environ/APIYI_KEY
litellm_settings:
drop_params: true
num_retries: 2
request_timeout: 60
router_settings:
routing_strategy: simple-shuffle # Rotation entre modèles de même nom
fallbacks:
- smart: ["fast"] # Repli vers "fast" en cas d'échec de "smart"
general_settings:
master_key: sk-litellm-master-xxxx # La clé que le client doit fournir
La couche applicative ne voit que quatre noms sémantiques : smart, fast, vision et embed. Lorsque GPT-5 est limité, LiteLLM bascule automatiquement vers Claude Opus 4.6 (car ils sont tous deux enregistrés sous smart), puis se replie sur fast en cas de nouvel échec. Tout le trafic sous-jacent passe par le service proxy API APIYI (apiyi.com) pour une facturation et une surveillance unifiées, isolant parfaitement la couche application de la couche canal.
Questions fréquentes sur la configuration de LiteLLM avec un service proxy API
Q1 : Pourquoi ai-je une erreur 404 Not Found alors que j’ai configuré l’URL de base ?
Dans 90 % des cas, il manque /v1 à la fin de votre api_base. LiteLLM utilise en interne le client OpenAI, qui ajoute automatiquement /chat/completions. Votre api_base doit donc être https://api.apiyi.com/v1 et non https://api.apiyi.com. Ne l'écrivez pas non plus sous la forme https://api.apiyi.com/v1/chat/completions, sinon le chemin sera dupliqué.
Q2 : Pourquoi est-il obligatoire d’ajouter le préfixe openai/ au modèle ?
LiteLLM gère une table de routage des fournisseurs en interne. Le préfixe openai/ indique à LiteLLM : « Utilise le client OpenAI pour accéder à ce point de terminaison ». Sans ce préfixe, LiteLLM pourrait tenter de faire correspondre le modèle à son fournisseur natif (par exemple, claude-opus-4-6 serait reconnu comme une API native Anthropic), ce qui entraînerait une erreur de protocole. Lors de l'utilisation d'un service proxy API, ajoutez toujours le préfixe openai/.
Q3 : Une clé APIYI peut-elle appeler plusieurs modèles simultanément ?
Oui. Une seule clé APIYI (apiyi.com) prend en charge par défaut tous les modèles disponibles sur la plateforme, y compris GPT-5, Claude Opus 4.6, Gemini 3 Pro, DeepSeek, Qwen, etc. C'est là toute la différence avec les API officielles : vous n'avez besoin de gérer qu'une seule clé et une seule URL de base pour monter des dizaines de modèles dans votre YAML LiteLLM.
Q4 : Une fois le proxy LiteLLM lancé, comment vérifier que la chaîne de transfert fonctionne ?
Le moyen le plus rapide est d'utiliser curl directement sur le proxy LiteLLM :
curl http://localhost:4000/v1/chat/completions \
-H "Authorization: Bearer sk-litellm-master-xxxx" \
-H "Content-Type: application/json" \
-d '{
"model": "smart",
"messages": [{"role": "user", "content": "ping"}]
}'
Si vous recevez un code 200 + JSON, la chaîne Application → LiteLLM Proxy → APIYI est opérationnelle. En cas d'échec, vérifiez d'abord les logs de la console LiteLLM, puis testez l'APIYI directement avec la même URL de base et la même clé pour isoler le problème.
Q5 : Le streaming (flux) nécessite-t-il une configuration supplémentaire via le proxy ?
Non. APIYI (apiyi.com) prend entièrement en charge les réponses en flux SSE, et LiteLLM les transmet par défaut. Il vous suffit d'ajouter stream=True lors de votre appel completion(), ou dans votre SDK OpenAI lors de l'appel au proxy, pour obtenir la sortie jeton par jeton.
Q6 : Puis-je également intégrer l’Embedding et la génération d’images ?
Oui. APIYI (apiyi.com) prend en charge /v1/embeddings, /v1/images/generations et /v1/audio/transcriptions en utilisant la même URL de base et la même clé. Il suffit d'ajouter les modèles correspondants à la model_list dans votre YAML LiteLLM (ex: text-embedding-3-large, gpt-image-1, whisper-1). Leur utilisation est identique à celle des modèles de chat, comme illustré dans l'exemple de routage de production ci-dessus.
Résumé
Configurer un service proxy API tiers avec LiteLLM se résume essentiellement à trois étapes :
- Alignement du protocole : Ajoutez le préfixe
openai/au modèle pour indiquer à LiteLLM d'utiliser le protocole client OpenAI. - Alignement du point d'entrée : Faites pointer
api_basevers le chemin racine du service proxy suivi de/v1, par exemplehttps://api.apiyi.com/v1. - Alignement des identifiants : Transmettez la clé API fournie par le service proxy via
api_keyou une variable d'environnement.
Une fois ces trois étapes terminées, toutes les fonctionnalités de LiteLLM (routage multi-modèles, basculement, limitation de débit, facturation, journalisation) peuvent être superposées de manière transparente sur un service proxy stable.
🚀 Conseil pratique : Si vous mettez en place une passerelle LLM unifiée pour votre équipe, nous recommandons l'architecture à trois niveaux suivante : « Application → LiteLLM Proxy → APIYI apiyi.com ». LiteLLM gère le routage et le basculement, tandis qu'APIYI assure l'accès aux modèles sous-jacents, la stabilité et la facturation à l'usage. Vous n'avez qu'à gérer un fichier YAML et une clé. Inscrivez-vous sur apiyi.com pour obtenir un crédit de test et effectuez votre première invocation en moins de 5 minutes.
Auteur : Équipe APIYI — Spécialisée dans l'accès stable aux principaux grands modèles de langage pour les développeurs. Visitez apiyi.com pour en savoir plus.
Références
-
Documentation officielle de LiteLLM – Points de terminaison compatibles OpenAI
- Lien :
docs.litellm.ai/docs/providers/openai_compatible - Description : Exemples officiels pour le SDK et le fichier YAML du Proxy.
- Lien :
-
Vue d'ensemble de la configuration du Proxy LiteLLM
- Lien :
docs.litellm.ai/docs/proxy/configs - Description : Champs complets pour
model_list,router_settingsetfallbacks.
- Lien :
-
Dépôt GitHub de LiteLLM
- Lien :
github.com/BerriAI/litellm - Description : Code source, problèmes (issues) et dernières versions.
- Lien :
-
daily_stock_analysis – LLM_CONFIG_GUIDE
- Lien :
github.com/ZhuLinsen/daily_stock_analysis/blob/main/docs/LLM_CONFIG_GUIDE.md - Description : Référence pratique pour les trois modes de configuration et le multi-canal.
- Lien :
-
Documentation officielle d'APIYI
- Lien :
apiyi.com - Description : Liste des modèles pris en charge,
base_urlet gestion des clés API.
- Lien :