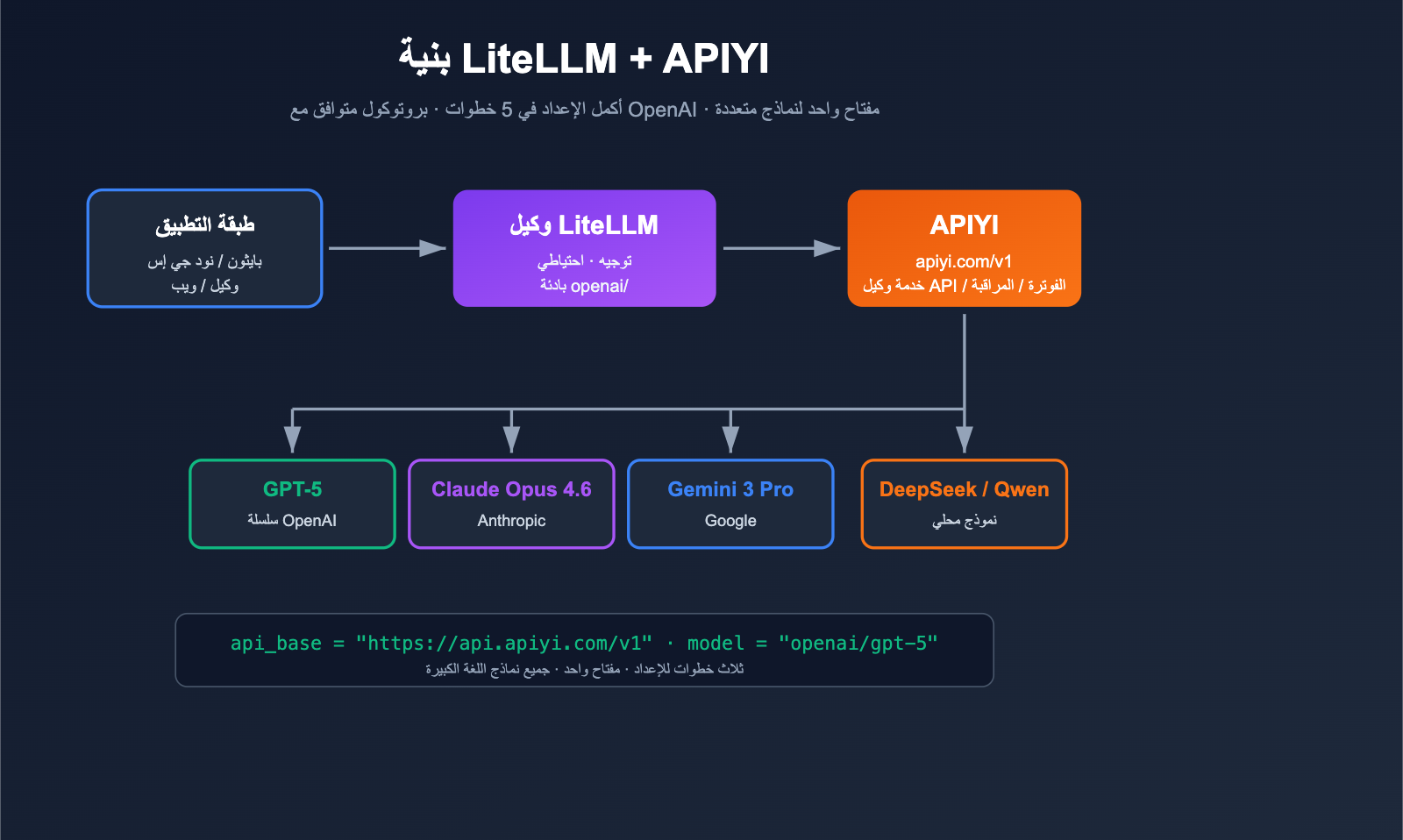
كيف يمكنك جعل LiteLLM ينسق استدعاءات نماذج لغة كبيرة متعددة مثل OpenAI وClaude وGemini وDeepSeek في وقت واحد، دون أن تعيقك مشاكل الحسابات الأجنبية، أو الشبكة، أو طرق الدفع؟ الحل يكمن في ربط LiteLLM بخدمة وكيل API طرف ثالث متوافقة مع OpenAI. في هذا المقال، سنستخدم LiteLLM + APIYI (apiyi.com) كمثال، لنشرح لك كيفية إتمام الإعداد خطوة بخطوة.
القيمة الجوهرية: بعد قراءة هذا المقال، ستتقن 3 طرق رئيسية لتهيئة LiteLLM مع خدمة وكيل API (عبر SDK، ملف YAML للوكيل، ومتغيرات البيئة)، وستتمكن من إتمام ربط APIYI في أقل من 5 دقائق.
النقاط الجوهرية لتهيئة LiteLLM مع خدمة وكيل API
LiteLLM هو بوابة/SDK مفتوح المصدر لنماذج اللغة الكبيرة، يهدف إلى استدعاء أكثر من 100 نموذج باستخدام تنسيق متوافق مع OpenAI. وهو يدعم بطبيعته أي نقطة نهاية "متوافقة مع OpenAI"، ما عليك سوى توجيه api_base إلى خدمة الوكيل، واستبدال api_key بالمفتاح الصادر عن الخدمة. وتعد APIYI (apiyi.com) خدمة وكيل قياسية متوافقة مع OpenAI، لذا فإن الربط بينهما مثالي.
| النقطة | الشرح | القيمة |
|---|---|---|
| بروتوكول توافق OpenAI | يقوم LiteLLM بالتوجيه إلى عميل OpenAI عبر البادئة openai/ |
ربط أي خدمة وكيل بإعداد واحد |
| ثلاث طرق للتهيئة | SDK داخلي / ملف Proxy YAML / متغيرات البيئة | مناسب لسيناريوهات السكربتات، الإنتاج، وCLI |
| تسمية موحدة للنماذج | openai/<provider-model> أو اسم نموذج مخصص |
لا حاجة لتعديل الكود البرمجي عند التبديل |
| مفتاح استكشاف الأخطاء | يجب أن ينتهي base_url بـ /v1 |
90% من أخطاء 404 تأتي من هنا |
| الاحتياط وتوازن الحمل | نمط YAML يدعم قنوات متعددة والرجوع عند الفشل | تعظيم التوافر في بيئة الإنتاج |
شرح مفصل لتهيئة LiteLLM مع خدمة وكيل API
توضح الوثائق الرسمية لـ LiteLLM بوضوح: طالما أضفت البادئة openai/ إلى اسم النموذج وحددت api_base، سيستخدم LiteLLM عميل OpenAI للوصول إلى نقطة النهاية الخاصة بك. هذا يعني أنه بغض النظر عما إذا كان خلف خدمة الوكيل GPT-5، أو Claude Opus 4.6، أو Gemini 3 Pro، أو DeepSeek، فبالنسبة لـ LiteLLM، هو مجرد "نقطة نهاية OpenAI".
رابط base_url الخاص بـ APIYI (apiyi.com) هو https://api.apiyi.com/v1، وهو يتبع معايير /v1/chat/completions و /v1/embeddings و /v1/images/generations القياسية، لذا فهو متوافق تماماً مع LiteLLM ولا يحتاج إلى أي تعديلات (patch).

دليل البدء السريع: إعداد خدمة وكيل API مع LiteLLM
التحضير
قبل البدء، يرجى تجهيز ما يلي:
- مفتاح API من APIYI: بعد التسجيل في apiyi.com، قم بإنشاء مفتاح جديد في لوحة التحكم (يُفضل تسميته
litellm-prod). - base_url:
https://api.apiyi.com/v1(تنبيه: يجب أن ينتهي الرابط بـ/v1). - بيئة Python: إصدار 3.9 أو أحدث.
- تثبيت المكتبات:
pip install litellm
مثال مبسط: الإعداد المضمن في SDK
أسرع طريقة للبدء هي تمرير api_key و api_base مباشرة داخل الكود:
import litellm
response = litellm.completion(
model="openai/gpt-5", # هام: بادئة openai/
api_key="YOUR_APIYI_KEY",
api_base="https://api.apiyi.com/v1", # عنوان خدمة وكيل APIYI
messages=[
{"role": "user", "content": "عرف LiteLLM في جملة واحدة"}
],
)
print(response.choices[0].message.content)
💡 نصيحة: بعد الحصول على رصيد تجريبي من لوحة تحكم APIYI، يمكنك استبدال
gpt-5بأسماء نماذج أخرى مثلclaude-opus-4-6أوgemini-3-proدون الحاجة لتعديل أي كود آخر — وهذا هو جوهر قيمة بروتوكول OpenAI المتوافق.
عرض مثال كامل قابل للتشغيل (مع معالجة الأخطاء والبث المباشر)
import os
import litellm
from litellm import completion
# يُنصح بإدارة المفاتيح عبر متغيرات البيئة
os.environ["OPENAI_API_KEY"] = "YOUR_APIYI_KEY"
os.environ["OPENAI_API_BASE"] = "https://api.apiyi.com/v1"
litellm.set_verbose = False # اجعلها True عند التصحيح
def chat_with_apiyi(model: str, prompt: str, stream: bool = False):
"""استدعاء أي نموذج متوافق مع OpenAI عبر LiteLLM + APIYI"""
try:
response = completion(
model=f"openai/{model}",
messages=[{"role": "user", "content": prompt}],
stream=stream,
temperature=0.7,
max_tokens=1024,
)
if stream:
for chunk in response:
delta = chunk.choices[0].delta.content or ""
print(delta, end="", flush=True)
print()
else:
return response.choices[0].message.content
except Exception as e:
print(f"فشل الاستدعاء: {e}")
return None
if __name__ == "__main__":
# بدون بث
print(chat_with_apiyi("gpt-5", "اشرح ما هي بوابة LLM"))
# مع بث
chat_with_apiyi("claude-opus-4-6", "عرف بمزايا LiteLLM في 100 كلمة", stream=True)
إعداد Proxy YAML: الخيار الموصى به للإنتاج
إذا كنت ترغب في تشغيل LiteLLM كخدمة مستقلة (على المنفذ 4000، للاستخدام الجماعي)، يُنصح باستخدام نمط YAML. أنشئ ملف litellm_config.yaml:
model_list:
- model_name: gpt-5 # اسم النموذج المعروض
litellm_params:
model: openai/gpt-5 # بادئة openai/ للتوجيه لعميل OpenAI
api_base: https://api.apiyi.com/v1 # عنوان خدمة وكيل APIYI
api_key: os.environ/APIYI_KEY # استدعاء متغير البيئة
- model_name: claude-opus-4-6
litellm_params:
model: openai/claude-opus-4-6
api_base: https://api.apiyi.com/v1
api_key: os.environ/APIYI_KEY
- model_name: gemini-3-pro
litellm_params:
model: openai/gemini-3-pro
api_base: https://api.apiyi.com/v1
api_key: os.environ/APIYI_KEY
litellm_settings:
drop_params: true # تجاهل المعلمات غير المدعومة تلقائياً
num_retries: 2 # عدد محاولات إعادة الاتصال
router_settings:
fallbacks:
- gpt-5: ["claude-opus-4-6", "gemini-3-pro"]
تشغيل الوكيل (Proxy):
export APIYI_KEY=sk-xxxxxxxxxxxxxxxx
litellm --config ./litellm_config.yaml --port 4000
بعد ذلك، يمكن لأي مكتبة OpenAI SDK الاتصال عبر http://localhost:4000:
from openai import OpenAI
client = OpenAI(
api_key="any-string", # LiteLLM Proxy لا يتحقق من المحتوى (إلا إذا تم إعداد master_key)
base_url="http://localhost:4000",
)
resp = client.chat.completions.create(
model="gpt-5",
messages=[{"role": "user", "content": "مرحباً عبر LiteLLM Proxy"}]
)
print(resp.choices[0].message.content)
🎯 نصيحة للإنتاج: نوصي بإضافة طبقة
master_keyأمام LiteLLM Proxy، وربط جميع النماذج الأساسية بـ APIYI، بحيث يرى تطبيقك أسماء نماذج دلالية فقط مثلgpt-5، بينما تتولى طبقة APIYI + LiteLLM إدارة القنوات، الفوترة، وتحديد السرعة.
نمط متغيرات البيئة: الأسهل للسكربتات
بالنسبة للسكربتات الفردية وأدوات سطر الأوامر، الطريقة الأسهل هي استخدام متغيرات البيئة. سيتعرف LiteLLM تلقائياً على OPENAI_API_KEY و OPENAI_API_BASE:
export OPENAI_API_KEY=sk-xxxxxxxxxxxxxxxx
export OPENAI_API_BASE=https://api.apiyi.com/v1
بعد ذلك، ستمر جميع الاستدعاءات التي تبدأ بـ openai/ عبر APIYI:
import litellm
print(litellm.completion(
model="openai/gpt-5",
messages=[{"role": "user", "content": "ping"}]
).choices[0].message.content)
مقارنة بين طرق إعداد خدمة وكيل API مع LiteLLM
تختلف طرق الإعداد حسب احتياجاتك. يوضح الجدول التالي توصيات الاختيار:
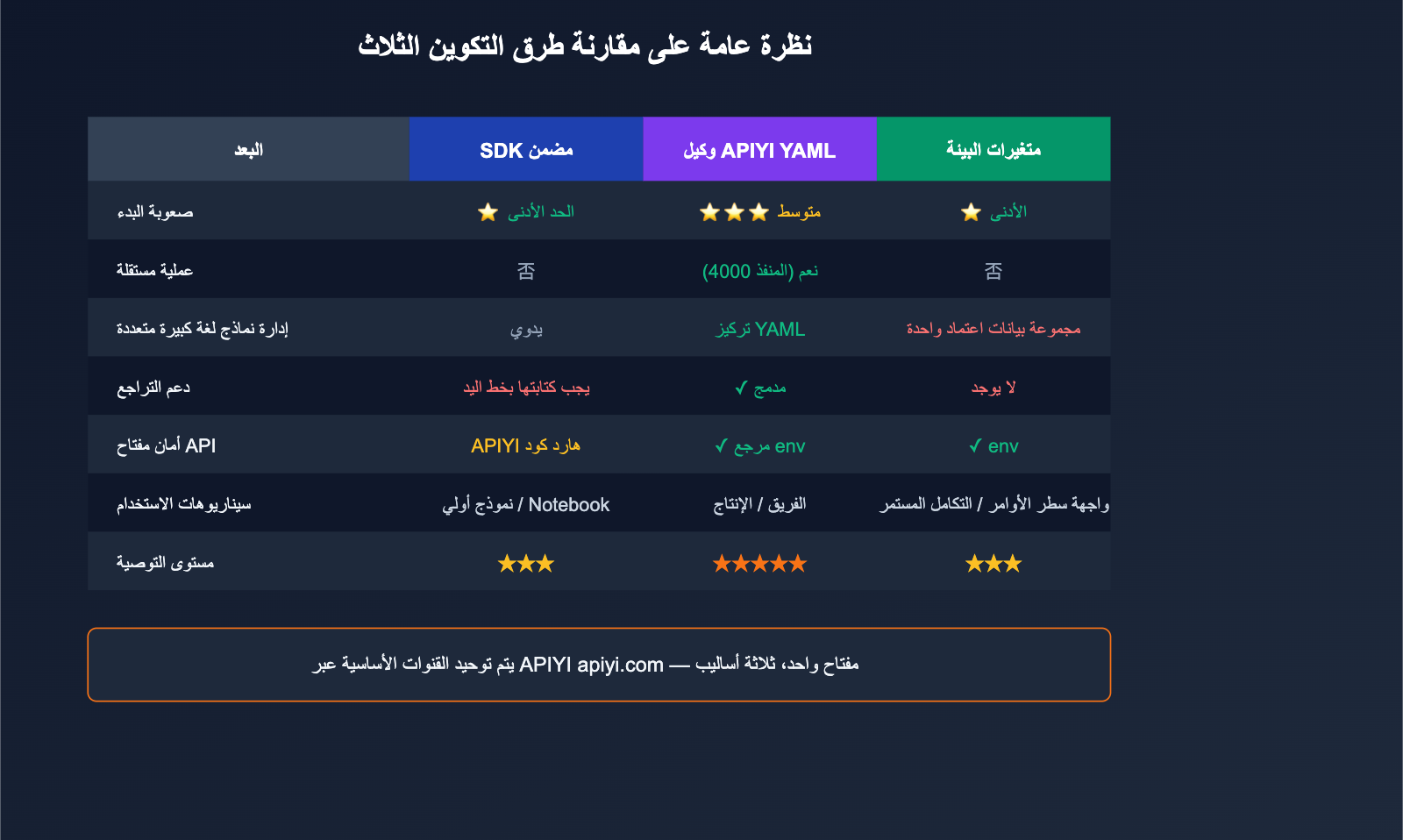
| البعد | SDK المضمن | Proxy YAML | متغيرات البيئة |
|---|---|---|---|
| سهولة البدء | ⭐ الأسهل | ⭐⭐⭐ متوسط | ⭐ الأسهل |
| الاستخدام | سكربتات، Notebook | فرق العمل، الإنتاج | أدوات CLI، CI |
| عملية مستقلة | لا | نعم (منفذ 4000) | لا |
| إدارة النماذج | يدوية | مركزية (YAML) | بيانات اعتماد واحدة |
| دعم Fallback | يتطلب كود إضافي | ✅ مدمج | ❌ لا يوجد |
| أمان المفتاح | عرضة للتسريب | ✅ عبر env | ✅ عبر env |
| التوصية | للنماذج الأولية | للإنتاج | للسكربتات الشخصية |
💡 نصيحة: للتطوير الشخصي، استخدم متغيرات البيئة. أما للفرق والإنتاج، فنوصي بشدة بنمط Proxy YAML، لأنه يجمع "توجيه النماذج + Fallback + تحديد السرعة + الإحصائيات" في ملف واحد. بغض النظر عن الطريقة، تظل القناة الأساسية هي APIYI، وكل ما تحتاجه هو مفتاح API واحد.
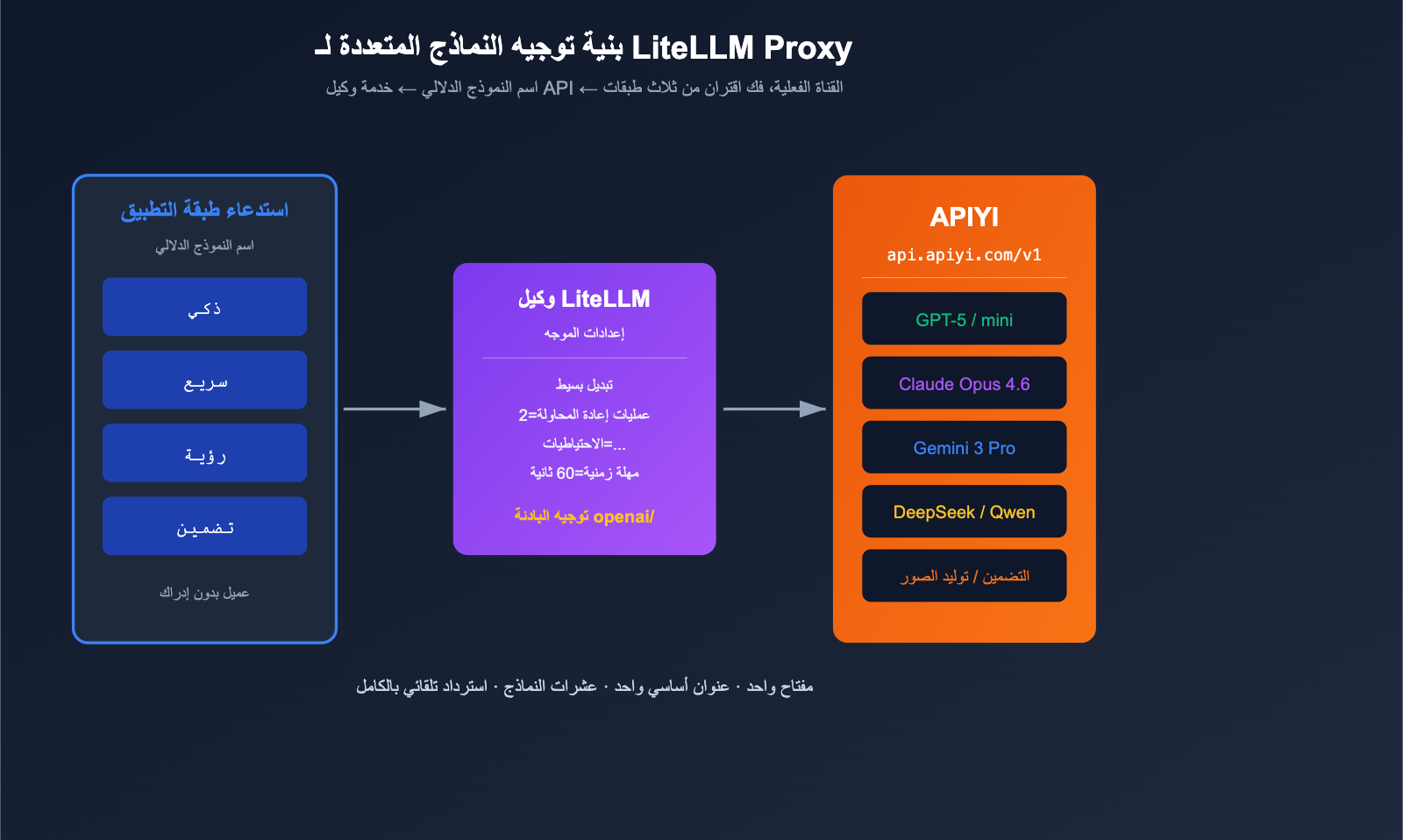
LiteLLM + APIYI 多模型路由实战
LiteLLM Proxy 模式真正强大的地方,在于能够通过同一份 YAML 文件,实现“语义模型名 → 实际渠道”的映射。下面为您提供一个生产环境可用的最小路由配置方案。
# litellm_config.yaml - 生产路由示例
model_list:
# 主力推理模型
- model_name: smart
litellm_params:
model: openai/gpt-5
api_base: https://api.apiyi.com/v1
api_key: os.environ/APIYI_KEY
timeout: 60
- model_name: smart
litellm_params:
model: openai/claude-opus-4-6
api_base: https://api.apiyi.com/v1
api_key: os.environ/APIYI_KEY
timeout: 60
# 廉价快速模型
- model_name: fast
litellm_params:
model: openai/gpt-5-mini
api_base: https://api.apiyi.com/v1
api_key: os.environ/APIYI_KEY
# 视觉/多模态
- model_name: vision
litellm_params:
model: openai/gemini-3-pro
api_base: https://api.apiyi.com/v1
api_key: os.environ/APIYI_KEY
# Embedding
- model_name: embed
litellm_params:
model: openai/text-embedding-3-large
api_base: https://api.apiyi.com/v1
api_key: os.environ/APIYI_KEY
litellm_settings:
drop_params: true
num_retries: 2
request_timeout: 60
router_settings:
routing_strategy: simple-shuffle # 同名模型轮询
fallbacks:
- smart: ["fast"] # smart 失败时降级到 fast
general_settings:
master_key: sk-litellm-master-xxxx # 客户端必须携带此 Key
应用层只需调用 smart / fast / vision / embed 这四个语义化名称。当 GPT-5 触发限流时,LiteLLM 会自动切换到 Claude Opus 4.6(因为它们都注册为 smart),若再次失败则会降级到 fast。所有底层流量均通过 APIYI (apiyi.com) 进行统一计费与监控,实现了应用层与渠道层的完美隔离。
الأسئلة الشائعة حول إعداد خدمة وكيل API لطرف ثالث في LiteLLM
س1: لماذا أحصل على خطأ 404 Not Found رغم ضبط base_url؟
في 90% من الحالات، يكون السبب هو نسيان إضافة /v1 في نهاية api_base. يستخدم LiteLLM عميل OpenAI داخلياً، والذي يقوم تلقائياً بإلحاق /chat/completions بالرابط، لذا يجب أن يكون api_base الخاص بك هو https://api.apiyi.com/v1 وليس https://api.apiyi.com. كما لا ينبغي كتابته كـ https://api.apiyi.com/v1/chat/completions لأن ذلك سيؤدي إلى تكرار المسار مرتين.
س2: لماذا يجب إضافة البادئة openai/ قبل اسم النموذج؟
يحتفظ LiteLLM بجدول توجيه داخلي لمزودي الخدمة. تخبر البادئة openai/ برنامج LiteLLM بـ "استخدام عميل OpenAI للوصول إلى نقطة النهاية هذه". إذا لم تضف البادئة، فقد يحاول LiteLLM مطابقة مزود الخدمة المدمج لديه (على سبيل المثال، سيتم التعرف على claude-opus-4-6 كـ API أصلي لـ Anthropic)، مما يؤدي إلى استخدام بروتوكول خاطئ. عند الاتصال بخدمة وكيل API، أضف دائماً البادئة openai/.
س3: هل يمكن لمفتاح API واحد من APIYI استدعاء نماذج متعددة في وقت واحد؟
نعم. يدعم مفتاح API واحد من APIYI (apiyi.com) افتراضياً جميع النماذج المتاحة على المنصة، بما في ذلك GPT-5، وClaude Opus 4.6، وGemini 3 Pro، وDeepSeek، وQwen، وغيرها. هذا هو الفرق الجوهري بينه وبين الـ API الرسمي؛ حيث تحتاج فقط إلى إدارة مفتاح واحد وbase_url واحد، ويمكنك تحميل عشرات النماذج في ملف YAML الخاص بـ LiteLLM.
س4: بعد تشغيل LiteLLM Proxy، كيف أتأكد من أن مسار الاتصال يعمل؟
أسرع طريقة هي استخدام curl للاتصال مباشرة بـ LiteLLM Proxy:
curl http://localhost:4000/v1/chat/completions \
-H "Authorization: Bearer sk-litellm-master-xxxx" \
-H "Content-Type: application/json" \
-d '{
"model": "smart",
"messages": [{"role": "user", "content": "ping"}]
}'
إذا أرجع النظام رمز 200 + JSON، فهذا يعني أن مسار الاتصال بالكامل (التطبيق ← LiteLLM Proxy ← APIYI) يعمل بشكل سليم. إذا فشل الاتصال، تحقق أولاً من سجلات وحدة تحكم LiteLLM، ثم استخدم نفس base_url والمفتاح للاتصال مباشرة بـ APIYI لتحديد مكان المشكلة.
س5: هل يتطلب البث (stream) إعدادات إضافية في سيناريوهات الوكيل؟
لا. تدعم APIYI (apiyi.com) استجابات البث SSE بالكامل، ويقوم LiteLLM بتمريرها افتراضياً. ما عليك سوى إضافة stream=True عند استدعاء completion()، أو عند استدعاء Proxy باستخدام OpenAI SDK، وستحصل على المخرجات لكل رمز (token) على حدة.
س6: هل يمكنني ربط نماذج التضمين (Embedding) وتوليد الصور أيضاً؟
نعم. تدعم APIYI (apiyi.com) كلاً من /v1/embeddings و/v1/images/generations و/v1/audio/transcriptions، وكلها تعمل عبر نفس base_url والمفتاح. في ملف YAML الخاص بـ LiteLLM، تحتاج فقط إلى إضافة النموذج المقابل إلى model_list، مثل text-embedding-3-large أو gpt-image-1 أو whisper-1. طريقة الاستخدام مطابقة تماماً لنماذج المحادثة، راجع أمثلة التوجيه في القسم السابق لمزيد من التفاصيل.
الخلاصة
إعداد خدمة وكيل API لطرف ثالث في LiteLLM يتلخص في ثلاثة أمور أساسية:
- مواءمة البروتوكول: أضف البادئة
openai/إلى اسم النموذج لإخبار LiteLLM باستخدام بروتوكول عميل OpenAI. - مواءمة المدخل: اجعل
api_baseيشير إلى المسار الجذري لخدمة الوكيل +/v1، مثلhttps://api.apiyi.com/v1. - مواءمة الاعتمادات: مرر المفتاح الصادر عن خدمة الوكيل عبر
api_keyأو متغيرات البيئة.
بإتمام هذه الخطوات الثلاث، يمكن دمج جميع ميزات LiteLLM (توجيه النماذج المتعددة، التبديل التلقائي عند الفشل، تحديد السرعة، الفوترة، والتسجيل) بسلاسة فوق خدمة وكيل مستقرة.
🚀 نصيحة عملية: إذا كنت تبني بوابة موحدة لنماذج اللغة الكبيرة (LLM) لفريقك، نوصي باستخدام بنية من ثلاث طبقات: "التطبيق ← LiteLLM Proxy ← APIYI (apiyi.com)". يتولى LiteLLM التوجيه والتبديل عند الفشل، بينما تتولى APIYI الوصول إلى النماذج الأساسية والاستقرار والفوترة حسب الاستخدام. كل ما تحتاجه هو إدارة ملف YAML واحد ومفتاح واحد. سجل في apiyi.com للحصول على رصيد تجريبي وأكمل أول استدعاء لك في غضون 5 دقائق.
المؤلف: فريق APIYI — متخصصون في توفير وصول مستقر لنماذج الذكاء الاصطناعي الرائدة للمطورين، تفضل بزيارة apiyi.com لمعرفة المزيد.
المراجع
-
وثائق LiteLLM الرسمية – نقاط النهاية المتوافقة مع OpenAI
- الرابط:
docs.litellm.ai/docs/providers/openai_compatible - الوصف: أمثلة رسمية لـ SDK وملفات YAML الخاصة بالوكيل (Proxy).
- الرابط:
-
نظرة عامة على إعدادات وكيل LiteLLM
- الرابط:
docs.litellm.ai/docs/proxy/configs - الوصف: الحقول الكاملة لـ model_list، وrouter_settings، وfallbacks.
- الرابط:
-
مستودع LiteLLM على GitHub
- الرابط:
github.com/BerriAI/litellm - الوصف: الكود المصدري، وقسم المشكلات (Issues)، وأحدث الإصدارات.
- الرابط:
-
daily_stock_analysis – دليل إعدادات نماذج اللغة (LLM_CONFIG_GUIDE)
- الرابط:
github.com/ZhuLinsen/daily_stock_analysis/blob/main/docs/LLM_CONFIG_GUIDE.md - الوصف: ثلاثة أنماط للإعدادات ومرجع عملي لاستخدام قنوات متعددة.
- الرابط:
-
وثائق APIYI الرسمية
- الرابط:
apiyi.com - الوصف: قائمة النماذج المدعومة، وإدارة base_url ومفتاح API.
- الرابط: