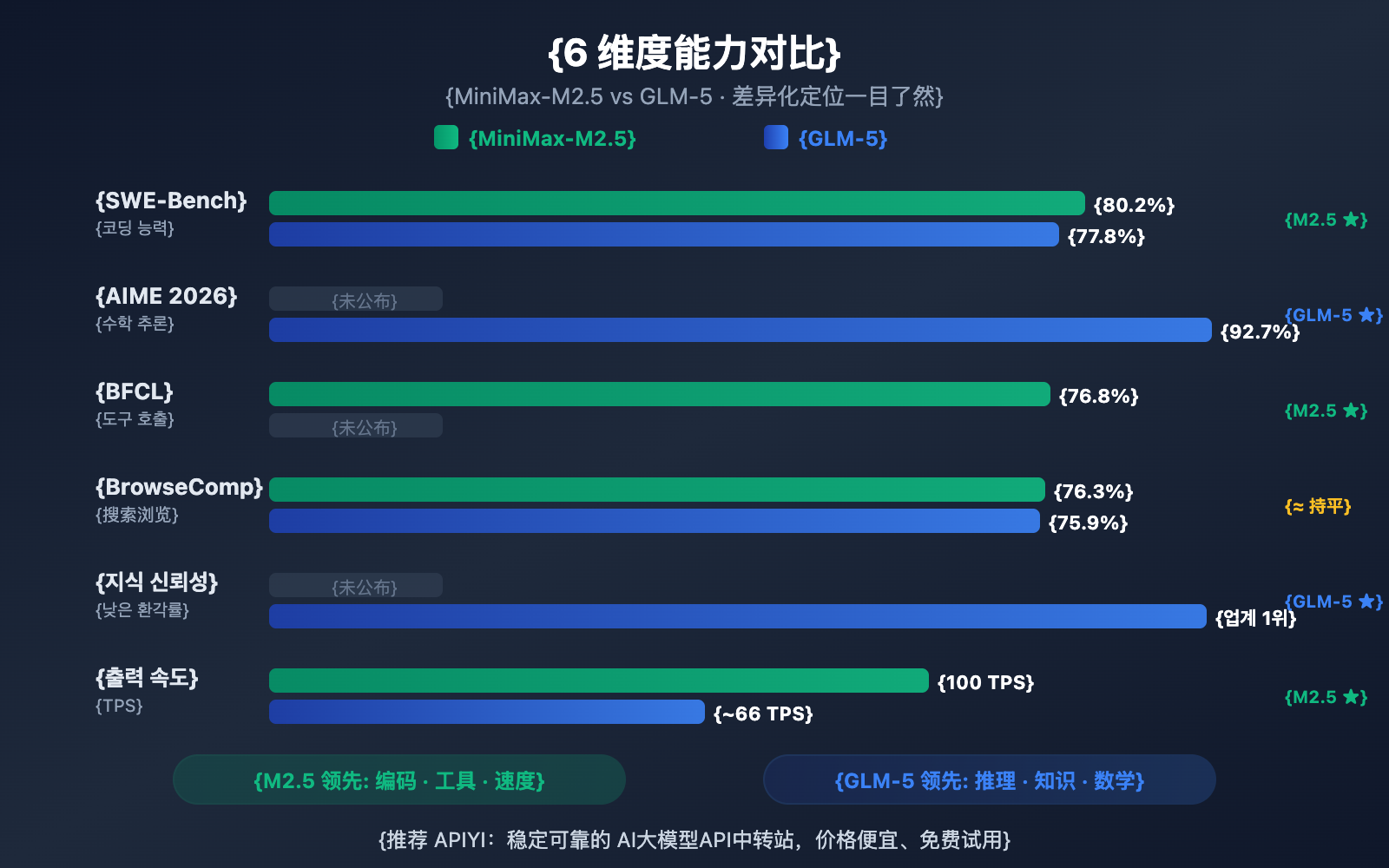
作者注:深度对比 2026 年 2 月同期发布的 MiniMax-M2.5 和 GLM-5 两大开源模型,从编码、推理、智能体、速度、价格和架构 6 个维度解析各自擅长领域
2026 年 2 月 11-12 日,两大中国 AI 公司几乎同时发布了各自的旗舰模型:智谱 GLM-5(744B 参数)和 MiniMax-M2.5(230B 参数)。两者都采用 MoE 架构、MIT 开源协议,但在能力侧重上形成了鲜明的差异化定位。
核心价值: 看完本文,你将清楚了解 GLM-5 擅长推理和知识可靠性,MiniMax-M2.5 擅长编码和智能体工具调用,从而在具体场景中做出最优选择。

MiniMax-M2.5와 GLM-5 핵심 차이점 총정리
| 비교 항목 | MiniMax-M2.5 | GLM-5 | 우세 |
|---|---|---|---|
| SWE-Bench 코딩 | 80.2% | 77.8% | M2.5 2.4% 앞섬 |
| AIME 수학적 추론 | — | 92.7% | GLM-5 우세 |
| BFCL 도구 호출 | 76.8% | — | M2.5 우세 |
| BrowseComp 검색 | 76.3% | 75.9% | 거의 대등 |
| 출력 가격/M tokens | $1.20 | $3.20 | M2.5 2.7배 저렴 |
| 출력 속도 | 50-100 TPS | ~66 TPS | M2.5 Lightning 더 빠름 |
| 총 파라미터 수 | 230B | 744B | GLM-5 더 큼 |
| 활성 파라미터 수 | 10B | 40B | M2.5 더 가벼움 |
MiniMax-M2.5의 핵심 강점: 코딩과 에이전트
MiniMax-M2.5는 코딩 벤치마크에서 특히 돋보이는 성과를 보여줍니다. SWE-Bench Verified에서 기록한 80.2%라는 점수는 GLM-5(77.8%)를 앞설 뿐만 아니라, GPT-5.2(80.0%)마저 뛰어넘는 수치예요. Claude Opus 4.6(80.8%)과도 근소한 차이밖에 나지 않죠. 여러 파일이 얽힌 협업 능력을 평가하는 Multi-SWE-Bench에서는 51.3%를, 도구 호출 능력을 보는 BFCL Multi-Turn에서는 무려 76.8%를 달성했습니다.
M2.5의 MoE(전문가 혼합) 아키텍처는 전체 230B 파라미터 중 단 10B(약 4.3%)만을 활성화합니다. 덕분에 티어 1급 모델 중 가장 '가벼운' 선택지가 되었고, 추론 효율도 극대화되었죠. 특히 라이트닝(Lightning) 버전은 최대 100 TPS의 속도를 내는데, 이는 현재 공개된 최첨단 모델 중 가장 빠른 수준입니다.
GLM-5의 핵심 강점: 추론과 지식 신뢰성
반면 GLM-5는 추론과 지식 기반 작업에서 압도적인 우위를 점하고 있습니다. AIME 2026 수학적 추론에서 92.7%, GPQA-Diamond 과학적 추론에서 86.0%를 기록했고요. 도구를 사용하는 Humanity's Last Exam에서는 50.4점을 받아 Claude Opus 4.5의 43.4점을 가볍게 제쳤습니다.
GLM-5의 가장 큰 특징은 바로 '지식의 신뢰성'입니다. AA-Omniscience 환각 평가에서 업계 최고 수준을 기록하며 전작 대비 35점이나 향상된 모습을 보여주었거든요. 기술 문서 작성, 학술 연구 보조, 지식 베이스 구축처럼 정확한 사실 정보가 중요한 상황이라면 GLM-5가 훨씬 더 믿음직한 선택이 될 거예요. 또한 744B에 달하는 거대한 파라미터와 28.5조 개의 토큰으로 학습된 데이터량은 GLM-5에게 깊이 있는 지식 창고를 제공합니다.
MiniMax-M2.5 대비 GLM-5 코딩 능력 상세 비교
코딩 능력은 현재 개발자들이 AI 모델을 선택할 때 가장 중요하게 생각하는 지표 중 하나예요. 두 모델은 이 부분에서 확연한 차이를 보입니다.
| 코딩 벤치마크 | MiniMax-M2.5 | GLM-5 | Claude Opus 4.6 (참고) |
|---|---|---|---|
| SWE-Bench Verified | 80.2% | 77.8% | 80.8% |
| Multi-SWE-Bench | 51.3% | — | 50.3% |
| SWE-Bench Multilingual | — | 73.3% | 77.5% |
| Terminal-Bench 2.0 | — | 56.2% | 65.4% |
| BFCL Multi-Turn | 76.8% | — | 63.3% |
MiniMax-M2.5는 SWE-Bench Verified에서 GLM-5를 2.4%p 앞섰어요 (80.2% vs 77.8%). 코딩 벤치마크에서 이 정도 차이는 꽤 유의미한 수준이죠. M2.5의 코딩 능력은 Opus 4.6급인 반면, GLM-5는 Gemini 3 Pro급에 더 가깝습니다.
GLM-5는 다국어 코딩(SWE-Bench Multilingual 73.3%)과 터미널 환경 코딩(Terminal-Bench 56.2%) 데이터가 있어 다양한 측면의 코딩 능력을 보여주지만, 가장 핵심인 SWE-Bench Verified에서는 M2.5의 우위가 확실해요.
M2.5는 코딩 효율성도 뛰어납니다. SWE-Bench 단일 작업을 완료하는 데 22.8분밖에 걸리지 않아 이전 세대인 M2.1보다 37%나 빨라졌어요. 이는 아키텍처를 먼저 분해한 뒤 효율적으로 구현하여 불필요한 시행착오를 줄이는 독특한 "Spec-writing" 코딩 스타일 덕분이에요.
🎯 코딩 시나리오 추천: 핵심 니즈가 AI 보조 코딩(버그 수정, 코드 리뷰, 기능 구현)이라면 MiniMax-M2.5가 더 나은 선택이에요. APIYI(apiyi.com)를 통해 두 모델을 동시에 연결해서 직접 비교 테스트해 볼 수 있습니다.
MiniMax-M2.5 대비 GLM-5 추론 능력 상세 비교
추론 능력은 GLM-5의 핵심 강점으로, 특히 수학과 과학 추론 분야에서 빛을 발합니다.
| 추론 벤치마크 | MiniMax-M2.5 | GLM-5 | 설명 |
|---|---|---|---|
| AIME 2026 | — | 92.7% | 올림피아드 수준 수학 추론 |
| GPQA-Diamond | — | 86.0% | 박사 수준 과학 추론 |
| Humanity's Last Exam (w/tools) | — | 50.4 | Opus 4.5의 43.4를 능가함 |
| HMMT Nov. 2025 | — | 96.9% | GPT-5.2의 97.1%에 근접 |
| τ²-Bench | — | 89.7% | 통신 분야 추론 |
| AA-Omniscience 지식 신뢰성 | — | 업계 최고 수준 | 환각률 최저 |
GLM-5는 SLIME(비동기 강화 학습 인프라)이라는 새로운 학습 방식을 도입해 사후 학습 효율을 대폭 높였어요. 덕분에 GLM-5는 추론 작업에서 비약적인 발전을 이뤄냈습니다.
- **AIME 2026 점수 92.7%**로 Claude Opus 4.5의 93.3%에 근접했으며, GLM-4.5 시절의 수준을 훨씬 뛰어넘었습니다.
- **GPQA-Diamond 86.0%**의 박사급 과학 추론 능력을 보여주며 Opus 4.5의 87.0%에 육박했습니다.
- Humanity's Last Exam 50.4점(도구 사용 시)으로 Opus 4.5의 43.4점과 GPT-5.2의 45.5점을 모두 제쳤습니다.
GLM-5의 가장 독보적인 능력은 지식 신뢰성이에요. AA-Omniscience 환각 평가에서 GLM-5는 이전 세대보다 35점이나 상승하며 업계 최고 수준을 달성했습니다. 이는 GLM-5가 사실 관계 질문에 대답할 때 내용을 '지어내는' 경우가 훨씬 적다는 것을 의미하며, 고정밀 정보 출력이 필요한 시나리오에서 가치가 매우 큽니다.
MiniMax-M2.5는 추론 관련 데이터가 많이 공개되지 않았어요. 핵심 강화 학습이 코딩과 에이전트 시나리오에 집중되어 있기 때문이죠. M2.5의 Forge RL 프레임워크는 순수 추론보다는 20만 개 이상의 실제 환경에서의 작업 분해와 도구 호출 최적화에 초점을 맞추고 있습니다.
비교 설명: 수학적 추론, 과학적 분석 또는 높은 신뢰성이 필요한 지식 Q&A가 주된 목적이라면 GLM-5가 더 유리해요. APIYI(apiyi.com) 플랫폼에서 여러분의 구체적인 추론 작업에 대해 두 모델의 성능 차이를 직접 테스트해 보시길 권장합니다.
MiniMax-M2.5 vs GLM-5 에이전트 및 검색 능력 비교
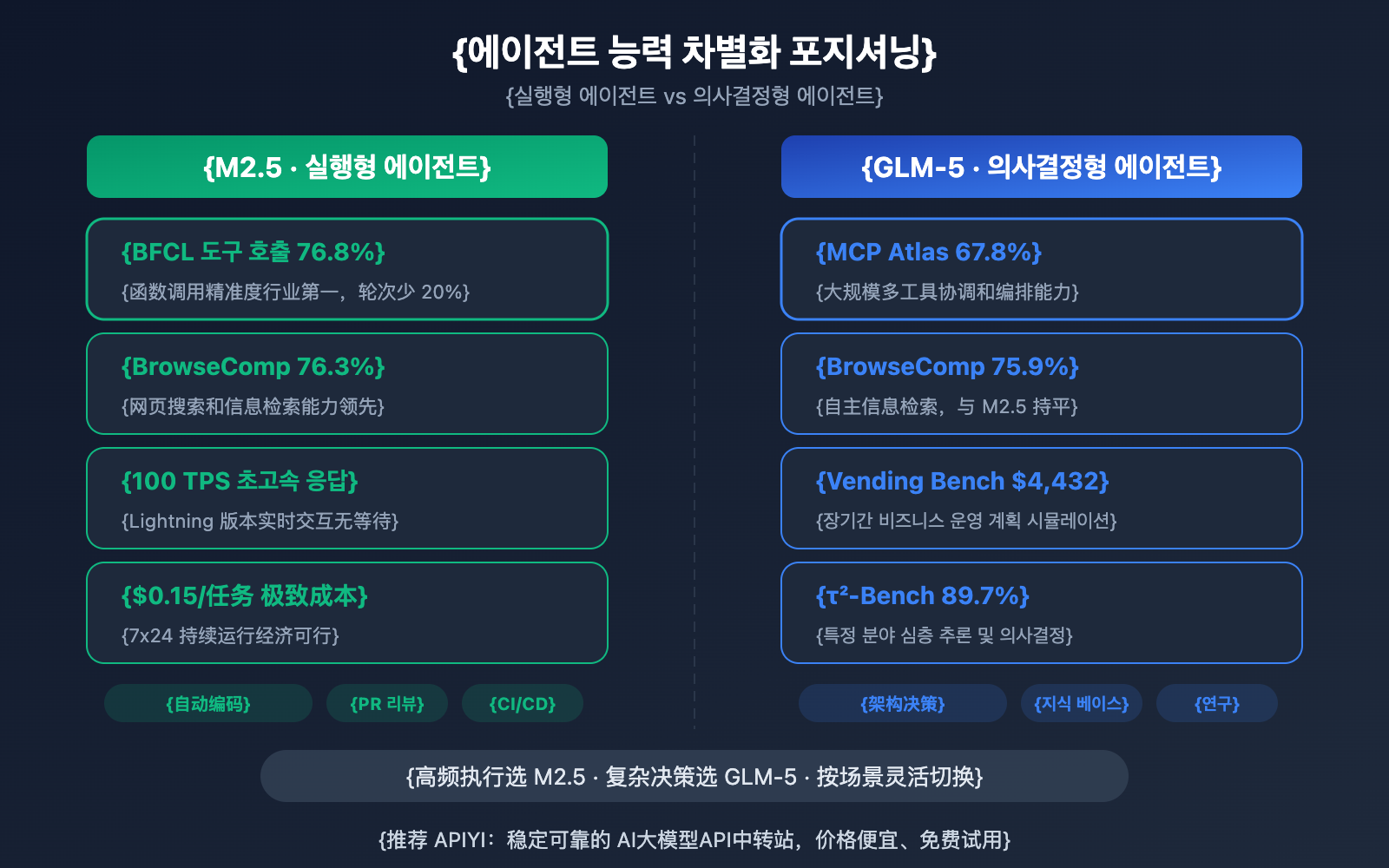
| 에이전트 벤치마크 | MiniMax-M2.5 | GLM-5 | 우세 모델 |
|---|---|---|---|
| BFCL Multi-Turn | 76.8% | — | M2.5 도구 호출 리드 |
| BrowseComp (w/context) | 76.3% | 75.9% | 거의 대등 |
| MCP Atlas | — | 67.8% | GLM-5 다중 도구 협업 |
| Vending Bench 2 | — | $4,432 | GLM-5 장기 계획 |
| τ²-Bench | — | 89.7% | GLM-5 도메인 추론 |
두 모델은 에이전트 능력 면에서 뚜렷한 차별점을 보여줍니다.
MiniMax-M2.5는 '실행형' 에이전트에 강점이 있습니다. 빈번한 도구 호출, 빠른 반복, 효율적인 실행이 필요한 시나리오에서 뛰어난 성능을 발휘해요. BFCL 76.8%라는 수치는 M2.5가 함수 호출, 파일 작업, API 상호작용 등을 정밀하게 수행할 수 있음을 의미하며, 도구 호출 횟수도 이전 세대보다 20% 줄어들었습니다. 실제로 MiniMax 내부 신규 코드의 80%가 M2.5에 의해 생성되고, 일상 업무의 30%를 스스로 처리하고 있다고 하네요.
GLM-5는 '의사결정형' 에이전트에 강점이 있습니다. 심층적인 추론, 장기적인 계획, 복잡한 의사결정이 필요한 상황에서 더 유리해요. MCP Atlas 67.8%는 대규모 도구 협업 능력을, Vending Bench 2의 $4,432 시뮬레이션 수익은 장기적인 비즈니스 계획 능력을 보여줍니다. 또한 τ²-Bench 89.7%를 통해 특정 분야에서의 깊이 있는 논리 추론 능력을 증명했습니다.
웹 검색 및 브라우징 능력에서는 두 모델 모두 BrowseComp 76.3% vs 75.9%로 거의 대등한 수준이며, 해당 분야의 선두 주자라고 할 수 있습니다.
🎯 에이전트 활용 팁: 고빈도 도구 호출이나 자동 코딩이 목적이라면 M2.5를, 복잡한 의사결정과 장기적인 계획이 필요하다면 GLM-5를 추천해요. APIYI(apiyi.com) 플랫폼에서는 두 모델을 모두 지원하므로 상황에 맞춰 유연하게 선택해 보세요!
MiniMax-M2.5 vs GLM-5 아키텍처 및 비용 비교
| 아키텍처 및 비용 | MiniMax-M2.5 | GLM-5 |
|---|---|---|
| 총 파라미터 수 | 230B | 744B |
| 활성 파라미터 수 | 10B | 40B |
| 활성 비율 | 4.3% | 5.4% |
| 학습 데이터 | — | 28.5조 토큰 |
| 컨텍스트 윈도우 | 205K | 200K |
| 최대 출력 | — | 131K |
| 입력 비용 | $0.15/M (표준 버전) | $1.00/M |
| 출력 비용 | $1.20/M (표준 버전) | $3.20/M |
| 출력 속도 | 50-100 TPS | ~66 TPS |
| 학습 칩 | — | 화웨이 어센드(Ascend) 910 |
| 학습 프레임워크 | Forge RL | SLIME 비동기 RL |
| 어텐션 메커니즘 | — | DeepSeek Sparse Attention |
| 오픈 소스 라이선스 | MIT | MIT |
MiniMax-M2.5 아키텍처 강점 분석
M2.5의 핵심 아키텍처 강점은 '극강의 경량화'에 있습니다. 단 10B의 활성 파라미터만으로 Opus 4.6에 근접하는 코딩 능력을 구현했는데요. 덕분에 다음과 같은 이점이 있습니다.
- 매우 낮은 추론 비용: 출력 비용이 $1.20/M로, GLM-5의 37% 수준에 불과합니다.
- 매우 빠른 추론 속도: Lightning 버전은 100 TPS로, GLM-5(~66 TPS)보다 52% 더 빠릅니다.
- 낮은 배포 장벽: 10B 활성 파라미터는 소비자용 GPU에서도 배포할 수 있는 가능성을 열어줍니다.
GLM-5 아키텍처 강점 분석
GLM-5는 744B의 총 파라미터와 40B의 활성 파라미터를 통해 더 강력한 지식 용량과 추론 깊이를 제공합니다.
- 더 방대한 지식 비축: 28.5조 토큰의 학습 데이터로 이전 세대를 훨씬 뛰어넘는 지식을 보유하고 있습니다.
- 더 깊은 추론 능력: 40B 활성 파라미터가 더 복잡한 추론 체인을 지원합니다.
- 국산 컴퓨팅 파워 자립: 전 과정을 화웨이 어센드 칩으로 학습하여 컴퓨팅 자원의 독립을 실현했습니다.
- DeepSeek Sparse Attention: 200K의 긴 컨텍스트를 효율적으로 처리합니다.
권장 사항: 비용에 민감한 고빈도 호출 시나리오에서는 M2.5의 가격 경쟁력이 압도적입니다(출력 비용이 GLM-5의 37% 수준). APIYI(apiyi.com) 플랫폼을 통해 실제 작업에서의 가성비를 직접 테스트해 보시는 것을 추천드려요.
MiniMax-M2.5 vs GLM-5 API 빠른 연동
APIYI 플랫폼을 사용하면 하나의 통합 인터페이스로 두 모델을 동시에 호출할 수 있어 빠르게 비교하기 편리합니다.
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
# 코딩 작업 테스트 - M2.5가 더 유리함
code_task = "Rust로 락-프리(lock-free) 동시성 큐 구현하기"
m25_result = client.chat.completions.create(
model="MiniMax-M2.5",
messages=[{"role": "user", "content": code_task}]
)
# 추론 작업 테스트 - GLM-5가 더 유리함
reason_task = "2보다 큰 모든 짝수는 두 소수의 합으로 나타낼 수 있음을 증명하라 (골드바흐의 추측 검증 아이디어)"
glm5_result = client.chat.completions.create(
model="glm-5",
messages=[{"role": "user", "content": reason_task}]
)
권장 사항: APIYI(apiyi.com)에서 무료 테스트 크레딧을 받아 여러분의 구체적인 시나리오에 맞춰 두 모델을 테스트해 보세요. 코딩 작업은 M2.5를, 추론 작업은 GLM-5를 시도해 보며 가장 적합한 솔루션을 찾아보시기 바랍니다.
자주 묻는 질문
Q1: MiniMax-M2.5와 GLM-5는 각각 어떤 분야에 가장 강점이 있나요?
MiniMax-M2.5는 코딩과 에이전트 도구 호출에 특화되어 있습니다. SWE-Bench에서 80.2%를 기록하며 Opus 4.6(4.6%)에 근접했고, BFCL에서는 76.8%로 업계 1위를 차지했습니다. 반면 GLM-5는 추론과 지식 신뢰성이 뛰어납니다. AIME 92.7%, GPQA 86.0%를 기록했으며 환각률(Hallucination)은 업계 최저 수준입니다. 간단하게 요약하자면, 코딩은 M2.5, 추론은 GLM-5를 선택하시면 됩니다.
Q2: 두 모델의 가격 차이는 어느 정도인가요?
MiniMax-M2.5 표준 버전의 출력 가격은 $1.20/M 토큰이며, GLM-5의 출력 가격은 $3.20/M 토큰으로 M2.5가 약 2.7배 더 저렴합니다. 만약 M2.5 Lightning 고속 버전($2.40/M)을 선택한다면, GLM-5와 가격은 비슷해지지만 훨씬 빠른 속도를 경험할 수 있습니다. APIYI(apiyi.com) 플랫폼을 통해 연동하면 충전 혜택도 누릴 수 있어 더욱 경제적입니다.
Q3: 두 모델의 실제 효과를 빠르게 비교해보려면 어떻게 해야 하나요?
APIYI(apiyi.com) 플랫폼을 통해 통합적으로 연동하는 것을 추천드려요:
- 계정을 등록하고 API Key와 무료 크레딧을 받습니다.
- 코딩과 추론, 두 가지 유형의 테스트 작업을 준비합니다.
- 동일한 프롬프트로 MiniMax-M2.5와 GLM-5를 각각 호출합니다.
- 출력 품질, 응답 속도, 토큰 소모량을 비교합니다.
- OpenAI 호환 인터페이스를 사용하므로,
model파라미터만 바꾸면 바로 모델을 교체할 수 있습니다.
요약
MiniMax-M2.5와 GLM-5 비교의 핵심 결론은 다음과 같습니다:
- 코딩은 M2.5가 우선: SWE-Bench 80.2% vs 77.8%로 M2.5가 2.4% 앞서며, BFCL 도구 호출 성능은 76.8%로 업계 1위입니다.
- 추론은 GLM-5가 우선: AIME 92.7%, GPQA 86.0%, Humanity's Last Exam 50.4점으로 Opus 4.5를 능가하는 성능을 보여줍니다.
- 지식 신뢰성은 GLM-5의 승리: AA-Omniscience 환각 평가에서 업계 1위를 차지하여, 사실 기반의 출력이 더 믿을만합니다.
- 가성비는 M2.5가 우수: 출력 가격이 GLM-5의 37% 수준이며, Lightning 버전은 속도 면에서도 강점이 있습니다.
두 모델 모두 MIT 라이선스로 공개된 MoE 구조를 채택하고 있지만, 지향점은 확연히 다릅니다. M2.5는 **'코딩 및 실행형 에이전트의 강자'**이고, GLM-5는 **'추론 및 지식 신뢰성의 선구자'**라고 할 수 있습니다. 실제 필요에 따라 APIYI(apiyi.com) 플랫폼에서 유연하게 전환하며 사용해 보세요. 충전 이벤트를 활용하면 더욱 합리적인 가격으로 이용할 수 있습니다.
📚 참고 자료
-
MiniMax M2.5 공식 발표: M2.5 핵심 코딩 능력과 Forge RL 학습 디테일
- 링크:
minimax.io/news/minimax-m25 - 설명: SWE-Bench 80.2%, BFCL 76.8% 등 전체 벤치마크 데이터 포함
- 링크:
-
GLM-5 공식 출시 정보: Zhipu AI GLM-5의 744B MoE 아키텍처와 SLIME 학습 기술
- 링크:
docs.z.ai/guides/llm/glm-5 - 설명: AIME 92.7%, GPQA 86.0% 등 추론 벤치마크 데이터 포함
- 링크:
-
Artificial Analysis 독립 벤치마크: 두 모델의 표준화된 벤치마크 테스트 및 순위
- 링크:
artificialanalysis.ai/models/glm-5 - 설명: Intelligence Index, 실제 속도 측정, 가격 비교 등 독립 데이터 제공
- 링크:
-
BuildFastWithAI 심층 분석: GLM-5 종합 벤치마크 테스트 및 경쟁 모델 비교
- 링크:
buildfastwithai.com/blogs/glm-5-released-open-source-model-2026 - 설명: Opus 4.5, GPT-5.2와의 상세 비교표 포함
- 링크:
-
MiniMax HuggingFace: M2.5 오픈 소스 모델 가중치(Weights)
- 링크:
huggingface.co/MiniMaxAI - 설명: MIT 라이선스, vLLM/SGLang 배포 지원
- 링크:
작성자: APIYI 팀
기술 교류: 댓글을 통해 여러분의 모델 비교 테스트 결과를 공유해 주세요! 더 많은 AI 모델 API 연동 가이드는 APIYI(apiyi.com) 기술 커뮤니티에서 만나보실 수 있습니다.