著者注:Nano Banana Pro APIが頻繁に過負荷になる根本原因を解明します。Google自社開発のTPUチップアーキテクチャからAI StudioとVertex AIの違いまで、需要過多の裏側にある技術的な真相に迫ります。
Nano Banana Proが2025年11月にリリースされて以来、開発者の間で不可解な現象が起きています。Googleが自社開発のTPUチップを保有しているにもかかわらず、この画像生成APIでは依然として「モデルの過負荷(model is overloaded)」エラーが多発しているのです。なぜ自社開発チップでも計算リソースの問題を解決できないのでしょうか?AI StudioとVertex AIという2つのプラットフォームには、どのような本質的な違いがあるのでしょうか?本記事では、Googleの計算リソースアーキテクチャの低層ロジックから、これらの問題の技術的な真相を深く解析します。
核心的な価値: 実際のデータとアーキテクチャ分析を通じて、Nano Banana Proの安定性問題の根本原因と、より信頼性の高いAPI連携プランの選び方を理解する手助けをします。
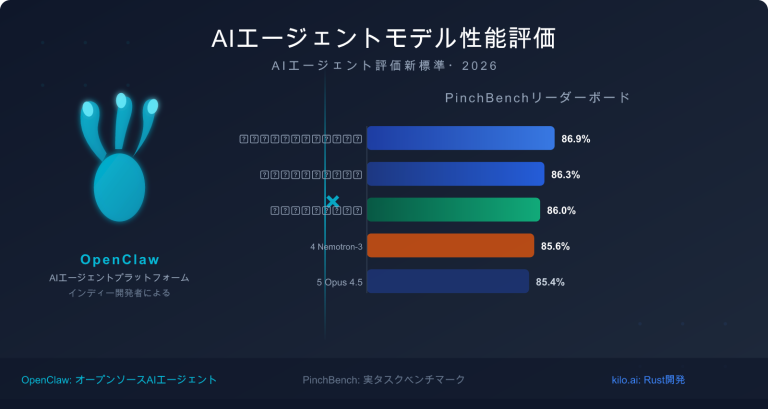
Nano Banana Pro API 安定性における核心的な課題
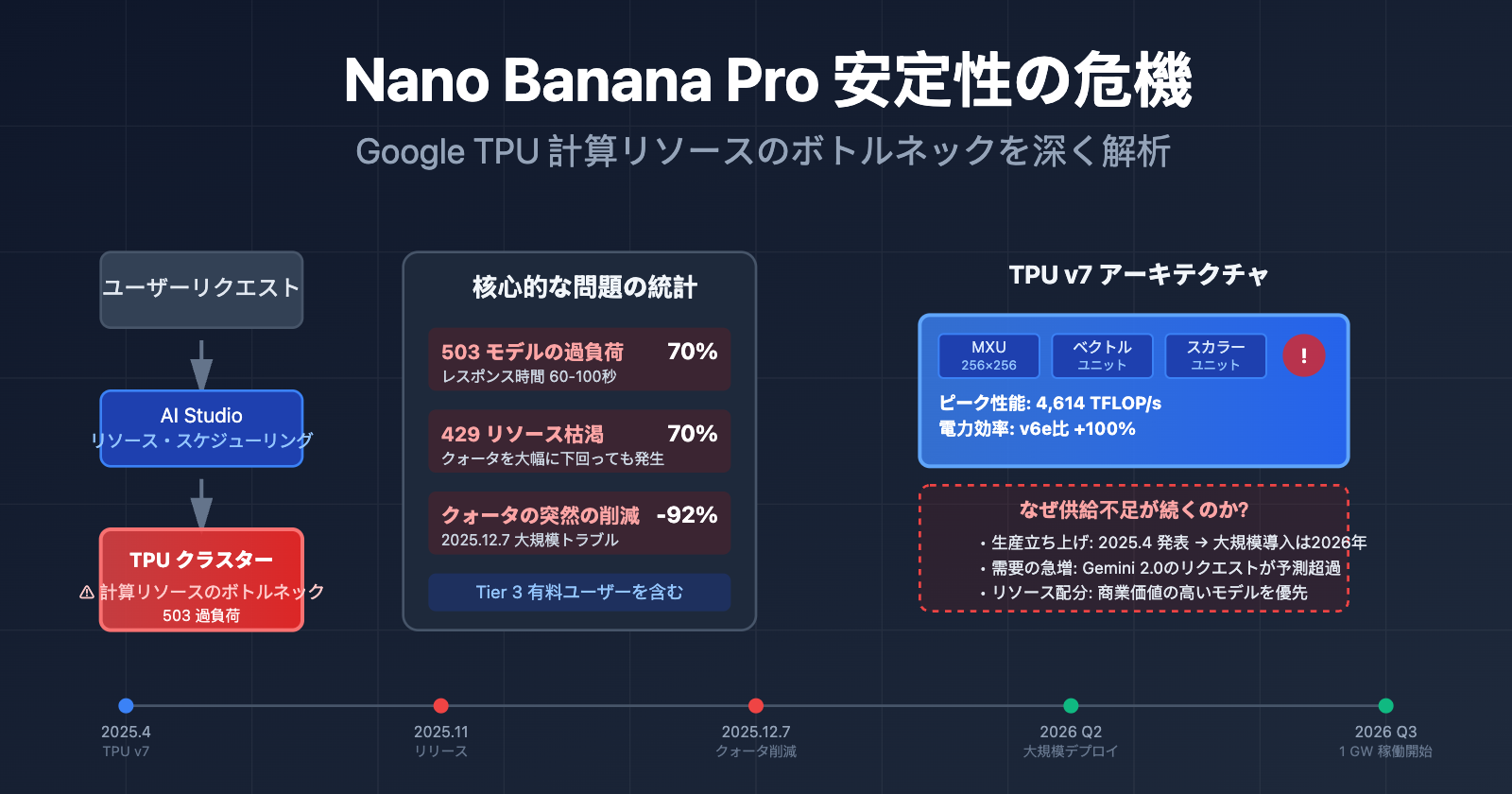
2025年11月のリリースから現在に至るまで、Nano Banana Pro (gemini-2.0-flash-preview-image-generation) は継続的な安定性の危機に直面しています。以下は、開発者コミュニティから報告された核心的な課題データです。
| 課題の種類 | 発生頻度 | 典型的な事象 | 影響範囲 |
|---|---|---|---|
| 503 モデル過負荷 | 高頻度(エラーの70%以上) | レスポンス時間が30秒から60〜100秒へ急増 | 全ての階層のユーザー(Tier 3 有料ユーザーを含む) |
| 429 リソース枯渇 | APIエラーの約70% | クォータ制限を大幅に下回っていても発生 | 無料プランおよび Tier 1 有料ユーザー |
| クォータの突然の削減 | 2025年12月7日 | 無料プランが3枚/日から2枚/日に減少、2.5 Proが無料プランから削除 | 世界中の無料プランユーザー |
| サービス利用不可 | 断続的 | 前日は高速で生成できていたが、翌日は完全に利用不可 | 無料プランに依存しているアプリ開発者 |
Nano Banana Pro 安定性問題の根本原因
これらの問題の核心はコードの欠陥ではなく、Googleサーバー側の計算リソース(算力)のキャパシティ・ボトルネックにあります。最高ランクのクォータを持つ Tier 3 有料ユーザーであっても、リクエスト頻度が公式の制限を大幅に下回っている際に過負荷エラーに遭遇しており、これは問題がユーザーのクォータ管理ではなくインフラストラクチャ層にあることを示しています。
開発者フォーラムでのGoogle公式の回答によると、計算リソースが Gemini 2.0 シリーズの新しいモデルへ再配分されており、その結果として Nano Banana Pro などの画像生成モデルで利用可能なキャパシティが制限されています。このようなリソース・スケジューリング戦略が、サービスの不安定さに直結しています。
🎯 技術的なアドバイス: 本番環境で Nano Banana Pro を使用する場合は、APIYI (apiyi.com) プラットフォーム経由での接続を検討することをお勧めします。このプラットフォームはインテリジェントな負荷分散と自動フェイルオーバー機構を提供しており、API呼び出しの成功率と安定性を大幅に向上させることができます。
<text x="20" y="25" font-family="Arial, sans-serif" font-size="18" fill="#93c5fd" font-weight="bold">
第1層:ユーザーリクエスト
</text>
<!-- 用户图标和请求 -->
<g transform="translate(50, 40)">
<circle cx="15" cy="15" r="15" fill="#3b82f6" stroke="#60a5fa" stroke-width="2"/>
<text x="15" y="21" font-family="Arial, sans-serif" font-size="16" fill="#ffffff" text-anchor="middle" font-weight="bold">👤</text>
</g>
<text x="100" y="60" font-family="Arial, sans-serif" font-size="15" fill="#e2e8f0">
開発者アプリ → APIリクエスト (プロンプト: 「猫を生成」)
</text>
<!-- 正常流量指示 -->
<rect x="700" y="35" width="260" height="35" rx="6" fill="url(#normalFlow)"/>
<text x="830" y="58" font-family="Arial, sans-serif" font-size="14" fill="#ffffff" text-anchor="middle" font-weight="bold">
✓ リクエスト受信成功(遅延 < 100ms)
</text>
<text x="20" y="25" font-family="Arial, sans-serif" font-size="18" fill="#93c5fd" font-weight="bold">
第2層:APIエントリ層 (AI Studio / Vertex AI)
</text>
<!-- AI Studio -->
<g transform="translate(100, 45)">
<rect x="0" y="0" width="350" height="60" rx="6" fill="#1e40af" stroke="#3b82f6" stroke-width="2"/>
<text x="175" y="25" font-family="Arial, sans-serif" font-size="16" fill="#ffffff" text-anchor="middle" font-weight="bold">
AI Studio(無料プラン / Tier 1-3)
</text>
<text x="175" y="45" font-family="Arial, sans-serif" font-size="13" fill="#93c5fd" text-anchor="middle">
共有リソースプール | SLA保証なし
</text>
</g>
<!-- Vertex AI -->
<g transform="translate(550, 45)">
<rect x="0" y="0" width="350" height="60" rx="6" fill="#065f46" stroke="#10b981" stroke-width="2"/>
<text x="175" y="25" font-family="Arial, sans-serif" font-size="16" fill="#ffffff" text-anchor="middle" font-weight="bold">
Vertex AI(エンタープライズ級)
</text>
<text x="175" y="45" font-family="Arial, sans-serif" font-size="13" fill="#86efac" text-anchor="middle">
優先リソース予約 | 99.9% SLA
</text>
</g>
<!-- Vertex AI 路径 (绿色 - 优先) -->
<path d="M 625,0 L 625,65" stroke="#10b981" stroke-width="4" marker-end="url(#arrow2green)"/>
<defs>
<marker id="arrow2green" markerWidth="12" markerHeight="12" refX="6" refY="6" orient="auto">
<polygon points="0 0, 12 6, 0 12" fill="#10b981" />
</marker>
</defs>
<text x="660" y="35" font-family="Arial, sans-serif" font-size="12" fill="#86efac">
✓ 優先チャネル
</text>
<text x="20" y="25" font-family="Arial, sans-serif" font-size="18" fill="#fca5a5" font-weight="bold">
第3層:グローバルリソーススケジューリング層 ⚠️ 計算リソースのボトルネックの核心
</text>
<!-- 调度逻辑 -->
<g transform="translate(50, 45)">
<rect x="0" y="0" width="900" height="80" rx="6" fill="#450a0a" stroke="#dc2626" stroke-width="2"/>
<text x="450" y="25" font-family="Arial, sans-serif" font-size="15" fill="#ffffff" text-anchor="middle">
リソース割り当て優先順位:Vertex AI (SLA予約) > AI Studio Tier 3 > Tier 2 > Tier 1 > 無料プラン
</text>
<!-- 问题说明 -->
<g transform="translate(30, 40)">
<circle cx="8" cy="0" r="5" fill="#ef4444"/>
<text x="20" y="5" font-family="Arial, sans-serif" font-size="13" fill="#fecaca">
課題1:総計算リソースの不足 → Tier 3ユーザーであっても拒否される(503エラー)
</text>
</g>
<g transform="translate(30, 60)">
<circle cx="8" cy="0" r="5" fill="#ef4444"/>
<text x="20" y="5" font-family="Arial, sans-serif" font-size="13" fill="#fecaca">
課題2:無料プラン/Tier 1がピーク時にアクティブにデグレードされる(429エラー)
</text>
</g>
</g>
<text x="20" y="25" font-family="Arial, sans-serif" font-size="18" fill="#93c5fd" font-weight="bold">
第4層:TPU v6e/v7 物理クラスタ
</text>
<!-- TPU 芯片组 -->
<g transform="translate(350, 35)">
<rect x="0" y="0" width="40" height="25" rx="3" fill="#3b82f6" stroke="#60a5fa" stroke-width="1.5"/>
<rect x="50" y="0" width="40" height="25" rx="3" fill="#3b82f6" stroke="#60a5fa" stroke-width="1.5"/>
<rect x="100" y="0" width="40" height="25" rx="3" fill="#3b82f6" stroke="#60a5fa" stroke-width="1.5"/>
<text x="150" y="17" font-family="Arial, sans-serif" font-size="12" fill="#cbd5e1">
...(256/9,216 チップクラスタ)
</text>
<rect x="330" y="0" width="40" height="25" rx="3" fill="#3b82f6" stroke="#60a5fa" stroke-width="1.5"/>
</g>
<text x="110" y="25" font-family="Arial, sans-serif" font-size="16" fill="#f1f5f9" text-anchor="middle" font-weight="bold">
エラーの種類と解析
</text>
<!-- 503 错误 -->
<g transform="translate(15, 40)">
<rect x="0" y="0" width="190" height="45" rx="4" fill="#7f1d1d" fill-opacity="0.3"/>
<text x="10" y="18" font-family="Arial, sans-serif" font-size="14" fill="#fca5a5" font-weight="bold">
503 モデル過負荷
</text>
<text x="10" y="35" font-family="Arial, sans-serif" font-size="11" fill="#cbd5e1">
第3/4層の計算リソース不足
</text>
</g>
<!-- 429 错误 -->
<g transform="translate(15, 95)">
<rect x="0" y="0" width="190" height="45" rx="4" fill="#7f1d1d" fill-opacity="0.3"/>
<text x="10" y="18" font-family="Arial, sans-serif" font-size="14" fill="#fca5a5" font-weight="bold">
429 リソース枯渇
</text>
<text x="10" y="35" font-family="Arial, sans-serif" font-size="11" fill="#cbd5e1">
第2/3層でのアクティブな制限
</text>
</g>
<!-- 成功响应 -->
<g transform="translate(15, 150)">
<rect x="0" y="0" width="190" height="20" rx="4" fill="#065f46" fill-opacity="0.3"/>
<text x="10" y="15" font-family="Arial, sans-serif" font-size="12" fill="#86efac">
✓ 200 成功(Vertex 優先)
</text>
</g>
谷歌 TPU 自研チップアーキテクチャの真実
多くの人は、Googleが自研の TPU (Tensor Processing Unit) チップを保有しているため、AI モデルの演算リソース需要を容易に支えられると考えています。しかし、事実は想像よりもはるかに複雑です。
TPU v7 (Ironwood) の最新アーキテクチャ
2025年4月、Googleは Cloud Next カンファレンスで第7世代 TPU —— Ironwood を発表しました。これはこれまでで最も強力なバージョンです。
| アーキテクチャ構成 | TPU v7 (Ironwood) | TPU v6e (Trillium) | 向上率 |
|---|---|---|---|
| ピーク演算性能 | 4,614 TFLOP/s | 約 2,300 TFLOP/s | ~100% |
| エネルギー効率 | 基準 | 参照 | ワット当たりの性能が 100% 向上 |
| クラスタ構成 | 256チップ / 9,216チップの2種類 | 単一構成 | 柔軟な拡張性 |
| 行列演算ユニット | 256×256 MXU (systolic array) | 128×128 MXU | 4倍の演算密度 |
| 活用シーン | 推論ファースト (Inference-first) | 学習・推論ハイブリッド | 推論パフォーマンスを専門に最適化 |
TPU のコアアーキテクチャ・コンポーネント
各 TPU チップは1つ以上の TensorCore を含み、各 TensorCore は以下の部分で構成されています。
- 行列乗算ユニット (MXU): TPU v6e および v7x は 256×256 の積和演算アレイを採用しており、初期バージョンは 128×128 でした。
- ベクトルユニット: 行列演算以外の処理を担当。
- スカラーユニット: 制御ロジックを実行。
このシストリック・アレイ (systolic array) アーキテクチャはニューラルネットワークの推論に非常に適していますが、限界もあります。
なぜ自研チップがあっても演算リソース不足は解消されないのか?
TPU v7 の性能は強力ですが、Nano Banana Pro の安定性の問題は依然として存在します。その理由は3つあります。
1. 生産能力の立ち上げ周期
TPU v7 は 2025年4月に発表されましたが、大規模なデプロイには時間がかかります。Googleは2025年末に Anthropic との100億ドル規模の提携を発表し、2026年に 1 GW を超える AI 演算リソースを稼働させる計画です。これは、2025年11月から2026年初頭が生産能力立ち上げの移行期であることを意味し、新旧アーキテクチャの入れ替えによって利用可能なリソースが逼迫しています。
2. 需要の爆発的増加
Gemini 2.0 シリーズのモデルが2025年末にリリースされた後、API リクエスト量は Google の当初の予測を大幅に上回りました。無料枠ユーザーの流入(特に Nano Banana Pro の画像生成需要)が、有料ユーザーのリソースプールを直接圧迫しています。
3. リソース割り当ての優先順位
Google は、Gemini 2.5 Pro (テキスト)、Gemini 2.0 Flash (マルチモーダル)、Nano Banana Pro (画像生成) など、複数の AI 製品ラインの演算需要のバランスを取る必要があります。演算リソースが限られている場合、商業的価値の高いモデルに優先的に割り当てられるため、これが Nano Banana Pro の容量制限に直結しています。
🎯 アーキテクチャの洞察: TPU チップの自研は、無限の演算リソースを意味するわけではありません。チップの生産能力、データセンターの建設、エネルギー供給はすべて制約要因となります。企業ユーザーには、APIYI (apiyi.com) プラットフォームを通じてマルチクラウドの演算リソース・スケジューリング能力を活用し、単一ベンダーの容量リスクを回避することをお勧めします。
AI Studio vs Vertex AI: 2大プラットフォームの本質的な違い
多くの開発者が、「Gemini AI Studio と Vertex AI はどちらも Gemini モデルを呼び出せるのに、なぜ安定性とクォータ(割当)にこれほど差があるのか?」と困惑しています。その答えは、両者のアーキテクチャにおける位置付けが完全に異なる点にあります。
プラットフォームのポジショニング比較
| 比較項目 | Google AI Studio (Gemini Developer API) | Vertex AI (Gemini API on GCP) |
|---|---|---|
| ターゲットユーザー | 個人開発者、学生、スタートアップ企業 | 企業レベルのチーム、本番環境アプリケーション |
| 利用のハードル | API キーを取得するだけで数分でプロトタイプ開発を開始可能 | Google Cloud アカウントと請求設定が必要 |
| 料金体系 | 無料枠 (制限あり) + Tier 1/2/3 有料プラン | 従量課金制 (無料枠なし)、GCP 請求システムに統合 |
| SLA 保障 | SLA (サービスレベル合意) なし | エンタープライズ級 SLA 提供、99.9% の可用性を保証 |
| 機能範囲 | モデル呼び出し API + 視覚的プロトタイプツール | 完全な ML ワークフロー (データアノテーション、学習、微調整、デプロイ、監視) |
| クォータの安定性 | 全体的なリソーススケジューリングの影響を受け、動的に調整される可能性あり | エンタープライズ級のクォータ予約、優先的なリソース割り当て |
AI Studio の主なメリットと限界
メリット:
- クイックスタート: 登録後すぐに API キーを取得でき、クラウドサービスの設定が不要。
- 視覚的プロトタイプツール: プロンプトテスト画面が内蔵されており、迅速な反復開発に便利。
- 無料枠の使いやすさ: 学習、実験、小規模プロジェクトに適している。
限界:
- SLA 保障なし: サービスの可用性が契約によって保護されていない。
- 不規則なクォータ調整: 2025年12月7日の突然の削減イベントのように、Gemini 2.5 Pro が無料枠から削除され、2.5 Flash の1日あたりの制限が 250回から 20回(92%削減)へ急落することがある。
- エンタープライズ機能の欠如: BigQuery や Dataflow などの GCP データサービスと統合できない。
Vertex AI のエンタープライズ級の能力
コアな利点:
- リソースの優先順位: 有料ユーザーのリクエストは Google 内部のスケジューリングシステムで高い優先順位を持つ。
- MLOps 統合: モデルの学習、バージョン管理、A/B テスト、監視アラートなど、完全なライフサイクルをサポート。
- データ主権: データの保存地域を指定でき、GDPR や CCPA などのコンプライアンス要件に適合。
- エンタープライズサポート: 専任のテクニカルサポートチームとアーキテクチャ相談サービス。
適したシーン:
- 1日のリクエスト量が 10,000回を超える本番アプリケーション。
- モデルの微調整やカスタム学習が必要なシーン。
- 可用性とレスポンスタイムに対して厳格な SLA 要件がある企業。
🎯 選択のアドバイス: アプリケーションがプロトタイプ段階を過ぎ、1日の平均呼び出し回数が 5,000回を超える場合は、Vertex AI への移行、または APIYI (apiyi.com) のような統合プラットフォームへの接続を推奨します。このプラットフォームは複数のクラウドベンダーの演算リソースを統合しており、単一のインターフェースでクロスプラットフォームのスケジューリングを実現できるため、AI Studio の使いやすさを維持しつつ、Vertex AI のような安定性も確保できます。
<!-- 定位 -->
<g transform="translate(0, 80)">
<rect x="0" y="0" width="480" height="50" rx="6" fill="#1e293b" stroke="#475569" stroke-width="2"/>
<text x="15" y="20" font-family="Arial, sans-serif" font-size="15" fill="#94a3b8" font-weight="bold">🎯 ターゲット</text>
<text x="15" y="38" font-family="Arial, sans-serif" font-size="14" fill="#e2e8f0">
個人開発者、学生、プロトタイプ開発
</text>
</g>
<!-- 资源调度 -->
<g transform="translate(0, 145)">
<rect x="0" y="0" width="480" height="120" rx="6" fill="#1e293b" stroke="#475569" stroke-width="2"/>
<text x="15" y="20" font-family="Arial, sans-serif" font-size="15" fill="#94a3b8" font-weight="bold">⚙️ リソーススケジューリング</text>
<!-- 共享资源池 -->
<g transform="translate(15, 35)">
<rect x="0" y="0" width="450" height="30" rx="4" fill="#1e40af" fill-opacity="0.3" stroke="#3b82f6" stroke-width="1.5"/>
<text x="225" y="20" font-family="Arial, sans-serif" font-size="13" fill="#93c5fd" text-anchor="middle">
グローバル共有リソースプール(動的割当、予約なし)
</text>
</g>
<!-- 优先级层级 -->
<g transform="translate(15, 70)">
<text x="0" y="0" font-family="Arial, sans-serif" font-size="12" fill="#cbd5e1">優先度: Tier 3 (有料最高) > Tier 2 > Tier 1 > 無料枠</text>
<text x="0" y="18" font-family="Arial, sans-serif" font-size="12" fill="#fca5a5">
⚠️ ピーク時はすべてのティアで制限を受ける可能性あり
</text>
</g>
</g>
<!-- 稳定性 -->
<g transform="translate(0, 280)">
<rect x="0" y="0" width="480" height="90" rx="6" fill="#1e293b" stroke="#475569" stroke-width="2"/>
<text x="15" y="20" font-family="Arial, sans-serif" font-size="15" fill="#94a3b8" font-weight="bold">📊 安定性</text>
<g transform="translate(15, 35)">
<text x="0" y="0" font-family="Arial, sans-serif" font-size="13" fill="#e2e8f0">
• SLA 保障なし (契約による可用性の保証なし)
</text>
<text x="0" y="22" font-family="Arial, sans-serif" font-size="13" fill="#e2e8f0">
• クォータは動的に調整される (例: 2025.12.7 に 92% 削減)
</text>
<text x="0" y="44" font-family="Arial, sans-serif" font-size="13" fill="#fca5a5">
• 503/429 エラー率: 70% (ピーク時)
</text>
</g>
</g>
<!-- 定价 -->
<g transform="translate(0, 385)">
<rect x="0" y="0" width="480" height="70" rx="6" fill="#1e293b" stroke="#475569" stroke-width="2"/>
<text x="15" y="20" font-family="Arial, sans-serif" font-size="15" fill="#94a3b8" font-weight="bold">💰 料金</text>
<g transform="translate(15, 35)">
<text x="0" y="0" font-family="Arial, sans-serif" font-size="13" fill="#86efac">
✓ 無料枠: 2-5 RPM (制限あり)
</text>
<text x="0" y="20" font-family="Arial, sans-serif" font-size="13" fill="#e2e8f0">
• Tier 1-3: $0.05-0.08/画像
</text>
</g>
</g>
<!-- 适用场景 -->
<g transform="translate(0, 470)">
<rect x="0" y="0" width="480" height="110" rx="6" fill="#1e293b" stroke="#475569" stroke-width="2"/>
<text x="15" y="20" font-family="Arial, sans-serif" font-size="15" fill="#94a3b8" font-weight="bold">✅ 活用シーン</text>
<g transform="translate(15, 35)">
<text x="0" y="0" font-family="Arial, sans-serif" font-size="13" fill="#e2e8f0">
• 迅速なプロトタイプ開発と技術検証
</text>
<text x="0" y="20" font-family="Arial, sans-serif" font-size="13" fill="#e2e8f0">
• 学習と実験 (クレジットカード不要)
</text>
<text x="0" y="40" font-family="Arial, sans-serif" font-size="13" fill="#e2e8f0">
• 1日の呼び出し量 < 1,000 回の小規模アプリ
</text>
<text x="0" y="60" font-family="Arial, sans-serif" font-size="13" fill="#e2e8f0">
• 遅延や可用性の許容度が高いケース
</text>
</g>
</g>
<!-- 风险标注 -->
<g transform="translate(0, 595)">
<rect x="0" y="0" width="480" height="50" rx="6" fill="#7f1d1d" fill-opacity="0.3" stroke="#ef4444" stroke-width="2"/>
<text x="240" y="30" font-family="Arial, sans-serif" font-size="14" fill="#fca5a5" text-anchor="middle" font-weight="bold">
⚠️ リスク: クォータが不安定 + サービス保障なし
</text>
</g>
<!-- 定位 -->
<g transform="translate(0, 80)">
<rect x="0" y="0" width="480" height="50" rx="6" fill="#1e293b" stroke="#475569" stroke-width="2"/>
<text x="15" y="20" font-family="Arial, sans-serif" font-size="15" fill="#94a3b8" font-weight="bold">🎯 ターゲット</text>
<text x="15" y="38" font-family="Arial, sans-serif" font-size="14" fill="#e2e8f0">
企業チーム、本番環境アプリケーション
</text>
</g>
<!-- 资源调度 -->
<g transform="translate(0, 145)">
<rect x="0" y="0" width="480" height="120" rx="6" fill="#1e293b" stroke="#475569" stroke-width="2"/>
<text x="15" y="20" font-family="Arial, sans-serif" font-size="15" fill="#94a3b8" font-weight="bold">⚙️ リソーススケジューリング</text>
<!-- 企业级资源池 -->
<g transform="translate(15, 35)">
<rect x="0" y="0" width="450" height="30" rx="4" fill="#065f46" fill-opacity="0.4" stroke="#10b981" stroke-width="1.5"/>
<text x="225" y="20" font-family="Arial, sans-serif" font-size="13" fill="#86efac" text-anchor="middle">
企業向け計算リソースプール (SLA 予約リソース、優先割り当て)
</text>
</g>
<!-- 优先级说明 -->
<g transform="translate(15, 70)">
<text x="0" y="0" font-family="Arial, sans-serif" font-size="12" fill="#cbd5e1">優先度: すべての AI Studio ティアよりも高い</text>
<text x="0" y="18" font-family="Arial, sans-serif" font-size="12" fill="#86efac">
✓ リソース予約メカニズムにより、ピーク時でも可用性を確保
</text>
</g>
</g>
<!-- 稳定性 -->
<g transform="translate(0, 280)">
<rect x="0" y="0" width="480" height="90" rx="6" fill="#1e293b" stroke="#475569" stroke-width="2"/>
<text x="15" y="20" font-family="Arial, sans-serif" font-size="15" fill="#94a3b8" font-weight="bold">📊 安定性</text>
<g transform="translate(15, 35)">
<text x="0" y="0" font-family="Arial, sans-serif" font-size="13" fill="#86efac">
✓ 99.9% 可用性 SLA (サービスレベル合意による保証)
</text>
<text x="0" y="22" font-family="Arial, sans-serif" font-size="13" fill="#86efac">
✓ 安定したクォータ (契約に基づき、突然削減されない)
</text>
<text x="0" y="44" font-family="Arial, sans-serif" font-size="13" fill="#86efac">
✓ 503/429 エラー率: <5% (低)
</text>
</g>
</g>
<!-- 定价 -->
<g transform="translate(0, 385)">
<rect x="0" y="0" width="480" height="70" rx="6" fill="#1e293b" stroke="#475569" stroke-width="2"/>
<text x="15" y="20" font-family="Arial, sans-serif" font-size="15" fill="#94a3b8" font-weight="bold">💰 料金</text>
<g transform="translate(15, 35)">
<text x="0" y="0" font-family="Arial, sans-serif" font-size="13" fill="#fca5a5">
✗ 無料枠なし
</text>
<text x="0" y="20" font-family="Arial, sans-serif" font-size="13" fill="#e2e8f0">
• 従量課金: $0.08-0.12/画像
</text>
</g>
</g>
<!-- 适用场景 -->
<g transform="translate(0, 470)">
<rect x="0" y="0" width="480" height="110" rx="6" fill="#1e293b" stroke="#475569" stroke-width="2"/>
<text x="15" y="20" font-family="Arial, sans-serif" font-size="15" fill="#94a3b8" font-weight="bold">✅ 活用シーン</text>
<g transform="translate(15, 35)">
<text x="0" y="0" font-family="Arial, sans-serif" font-size="13" fill="#e2e8f0">
• 1日の呼び出し量 > 5,000 回の本番アプリ
</text>
<text x="0" y="20" font-family="Arial, sans-serif" font-size="13" fill="#e2e8f0">
• SLA 保障が必要なエンタープライズサービス
</text>
<text x="0" y="40" font-family="Arial, sans-serif" font-size="13" fill="#e2e8f0">
• GCP データサービス (BigQuery/Dataflow) との統合が必要
</text>
<text x="0" y="60" font-family="Arial, sans-serif" font-size="13" fill="#e2e8f0">
• モデルの微調整や MLOps 能力が必要
</text>
</g>
</g>
<!-- 优势标注 -->
<g transform="translate(0, 595)">
<rect x="0" y="0" width="480" height="50" rx="6" fill="#065f46" fill-opacity="0.3" stroke="#10b981" stroke-width="2"/>
<text x="240" y="30" font-family="Arial, sans-serif" font-size="14" fill="#86efac" text-anchor="middle" font-weight="bold">
✓ 利点: 企業向け SLA + リソース予約 + 高い安定性
</text>
</g>
<text x="520" y="25" font-family="Arial, sans-serif" font-size="18" fill="#f1f5f9" text-anchor="middle" font-weight="bold">
核心的な違い: リソーススケジューリングの優先度とサービス保障
</text>
<g transform="translate(30, 40)">
<text x="0" y="0" font-family="Arial, sans-serif" font-size="14" fill="#cbd5e1">
• <tspan fill="#93c5fd" font-weight="bold">AI Studio</tspan>: 共有リソース、SLAなし、クォータ変動あり。プロトタイプ開発向け | 低コストだが不安定
</text>
<text x="0" y="24" font-family="Arial, sans-serif" font-size="14" fill="#cbd5e1">
• <tspan fill="#86efac" font-weight="bold">Vertex AI</tspan>: 企業向けリソース予約、99.9% SLA、安定したクォータ。本番環境向け | 高コストだが高信頼
</text>
<text x="0" y="48" font-family="Arial, sans-serif" font-size="14" fill="#fbbf24">
• <tspan font-weight="bold">推奨</tspan>: APIYI (apiyi.com) の統合プラットフォーム経由でマルチクラウド・スケジューリングを行い、コストと安定性を両立
</text>
</g>
Nano Banana Pro の供給不足が続く深層的な理由
前述の分析を総合すると、Nano Banana Pro の供給不足が続いている理由は、以下の 3 つの大きな側面に集約されます。
1. 技術的側面:チップの生産能力と需要の不均衡
- TPU v7 の生産拡大: 2025 年 4 月に発表されましたが、大規模なデプロイが完了するのは 2026 年になる見込みです。
- 推論よりも学習を優先: Gemini 3.0 シリーズの学習タスクが、大量の TPU v6e および v7 リソースを占有しています。
- 画像生成の計算負荷: Nano Banana Pro の拡散モデル (Diffusion Model) の推論には、テキストモデルの 5 〜 10 倍の計算リソースが必要です。
2. 商業的側面:無料枠戦略の調整
| タイムライン | ポリシーの変更 | 背景・理由 |
|---|---|---|
| 2025 年 11 月 | Nano Banana Pro リリース、無料枠は 3 枚/日 | ユーザーフィードバックを迅速に取得し、市場での地位を確立するため |
| 2025 年 12 月 7 日 | 無料枠を 2 枚/日に削減、Gemini 2.5 Pro の無料枠を撤廃 | 計算コストが予算を超過したため、無料ユーザーの増加を抑制する必要性 |
| 2026 年 1 月 | 無料枠の RPM(1分あたりのリクエスト数)を 10 から 5 に制限 | Gemini 2.0 Flash の企業顧客向けにリソースを確保するため |
Google は公式フォーラムで、これらの調整は 「持続可能なサービス品質を確保するため」 であると明言しています。実際には、無料枠ユーザーの急増(特に自動化ツールや一括呼び出し)によってコストが制御不能になり、ポリシーを厳格化せざるを得なくなったのが実情です。
3. アーキテクチャ的側面:AI Studio と Vertex AI のリソース分離
2 つのプラットフォームは同じ基盤モデルを呼び出していますが、Google 内部でのリソーススケジューリングの優先順位が異なります。
- Vertex AI: GCP のエンタープライズ級演算リソースプールに直接接続されており、SLA 保証付きのリソース予約が可能です。
- AI Studio: グローバルな共有リソースプールを使用しており、ピーク時には優先順位が下げられます。
このアーキテクチャ設計により、AI Studio の無料枠および Tier 1 ユーザーは 429(リクエスト過多)や 503(サービス利用不可)エラーに遭遇しやすく、一方で Vertex AI の有料ユーザーへの影響は比較的小さくなっています。
4. プロダクト戦略:「市場シェアの獲得」から「収益性の最適化」へ
Nano Banana Pro のリリース初期、Google は DALL-E 3 や Midjourney などの競合に対抗するため、積極的な無料戦略を採用しました。しかし、ユーザー数が爆発的に増加するにつれ、無料枠中心のビジネスモデルは持続不可能であると判断し、「高価値な有料ユーザー」へリソースを傾斜させ始めました。
この転換を象徴する出来事が 2025 年 12 月のクォータ削減と 2.5 Pro 無料枠の撤廃 であり、開発者コミュニティでは「無料枠の惨事 (Free Tier Fiasco)」と呼ばれています。
🎯 対応策: Nano Banana Pro に依存する商用アプリケーションについては、マルチクラウド・バックアップ戦略の採用を検討してください。APIYI (apiyi.com) プラットフォームを利用すれば、単一のインターフェースで Nano Banana Pro、DALL-E 3、Stable Diffusion など複数のモデルの自動切り替えルールを設定できます。特定のサービスが過負荷になった際、自動的に代替案へフォールバックし、ビジネスの継続性を確保することが可能です。
開発者は Nano Banana Pro の不安定さにどう対処すべきか
前述の分析に基づき、検証済みの 4 つの技術的な解決策を提案します。
解決策 1: 指数バックオフによるリトライ・メカニズムの実装
import time
import random
def call_nano_banana_with_retry(prompt, max_retries=5):
"""指数バックオフ戦略を使用して Nano Banana Pro API を呼び出す"""
for attempt in range(max_retries):
try:
response = call_api(prompt) # 実際の API 呼び出し関数
return response
except Exception as e:
if "503" in str(e) or "429" in str(e):
# 待ち時間を指数関数的に増加させ、ジッター(ゆらぎ)を加える
wait_time = (2 ** attempt) + random.uniform(0, 1)
print(f"過負荷エラーが発生しました。{wait_time:.2f} 秒後に再試行します...")
time.sleep(wait_time)
else:
raise e
raise Exception("最大再試行回数に達しました")
核心となる考え方: 503 や 429 エラーに遭遇した際、待ち時間を指数関数的に増加(1秒 → 2秒 → 4秒 → 8秒)させることで、リクエストの集中による雪崩現象を回避します。
本番環境向けの完全な実装例 (クリックで展開)
import time
import random
import logging
from typing import Optional, Dict, Any
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
class NanoBananaClient:
def __init__(self, api_key: str, base_delay: float = 1.0, max_retries: int = 5):
self.api_key = api_key
self.base_delay = base_delay
self.max_retries = max_retries
def generate_image(self, prompt: str, **kwargs) -> Optional[Dict[str, Any]]:
"""エラー処理とモニタリングを含む、本番環境向けの画像生成メソッド"""
for attempt in range(self.max_retries):
try:
# 実際の API 呼び出しロジック
response = self._call_api(prompt, **kwargs)
logger.info(f"リクエスト成功 (試行 {attempt + 1}/{self.max_retries})")
return response
except Exception as e:
error_code = self._parse_error_code(e)
if error_code in [429, 503]:
if attempt < self.max_retries - 1:
wait_time = self._calculate_backoff(attempt)
logger.warning(
f"エラー {error_code}: {str(e)[:100]} | "
f"{wait_time:.2f}秒待機中 (試行 {attempt + 1}/{self.max_retries})"
)
time.sleep(wait_time)
else:
logger.error(f"最大再試行回数に達しました。最終エラー: {str(e)}")
raise
else:
logger.error(f"再試行不可能なエラー: {str(e)}")
raise
return None
def _calculate_backoff(self, attempt: int) -> float:
"""ジッターを加えた指数バックオフ時間の計算。同期的な再試行を回避。"""
exponential_delay = self.base_delay * (2 ** attempt)
jitter = random.uniform(0, self.base_delay)
return min(exponential_delay + jitter, 60.0) # 最大待機時間は 60 秒
def _parse_error_code(self, error: Exception) -> int:
"""例外から HTTP ステータスコードを抽出"""
error_str = str(error)
if "429" in error_str or "RESOURCE_EXHAUSTED" in error_str:
return 429
elif "503" in error_str or "overloaded" in error_str:
return 503
return 500
def _call_api(self, prompt: str, **kwargs) -> Dict[str, Any]:
"""実際の API 呼び出しロジック (実際の環境に合わせて実装が必要)"""
# ここに実際の API 呼び出しコードを記述します
pass
# 使用例
client = NanoBananaClient(api_key="your_api_key")
result = client.generate_image("a cute cat playing piano")
解決策 2: リクエスト間隔の制御
開発者コミュニティのフィードバックによると、リクエスト間に 5 〜 10 秒の固定遅延 を追加することで、503 エラーの発生率を大幅に下げることができます。
import time
def batch_generate_images(prompts):
"""リクエスト頻度を厳密に制御して画像をバッチ生成する"""
results = []
for i, prompt in enumerate(prompts):
result = call_api(prompt)
results.append(result)
if i < len(prompts) - 1: # 最後の回は待機不要
time.sleep(7) # 固定で 7 秒の間隔を空ける
return results
推奨シーン: バッチコンテンツ生成やオフラインデータ処理など、リアルタイム性が求められないアプリケーション。
解決策 3: マルチクラウド・バックアップ戦略
統合 API プラットフォームを介して、自動フェイルオーバー(故障時の切り替え)を実現します。
| ステップ | 技術的実装 | 期待される効果 |
|---|---|---|
| 1. メイン・サブモデルの設定 | Nano Banana Pro (主) + DALL-E 3 (従) | 単一障害点の回避 |
| 2. 切り替えルールの設定 | 503 エラーが 3 回連続 → 自動でサブに切り替え | ユーザーが感じる遅延の低減 |
| 3. 復旧状態の監視 | 5 分ごとにメインサービスの正常性を確認 | メインサービスへの自動復帰 |
🎯 推奨される実装: APIYI (apiyi.com) プラットフォームは、このようなマルチクラウド・スケジューリング戦略をネイティブでサポートしています。コンソールで切り替えルールを設定するだけで、システムが自動的に障害検知、トラフィックの切り替え、コストの最適化を処理するため、業務コードを修正する必要はありません。
解決策 4: Vertex AI またはエンタープライズ級プラットフォームへのアップグレード
以下のいずれかに該当する場合は、アップグレードを検討することをお勧めします。
- 1 日あたりの API 呼び出し数が 5,000 回を超える
- 応答時間に対して厳格な SLA がある (例: 95 パーセンタイルが 10 秒未満)
- サービスの切断が許容されない (例: EC サイトの画像生成、リアルタイム・コンテンツ監査)
コスト比較:
AI Studio Tier 1: $0.05/画像 (ただし頻繁に過負荷)
Vertex AI: $0.08/画像 (安定、SLA あり)
APIYI プラットフォーム: $0.06/画像 (マルチクラウド制御、自動フォールバック)
Vertex AI は単価こそ高いものの、再試行のコスト、開発工数、およびビジネス機会の損失を考慮すると、実際の TCO (総保有コスト) は低くなる可能性があります。
よくある質問 (FAQ)
Q1: なぜ有料ユーザーでも「モデル過負荷」エラーが発生するのですか?
A: Nano Banana Pro の容量不足は、ユーザーごとの割当(クォータ)レイヤーではなく、Googleのグローバル計算リソース・スケジューリング・レイヤーで発生しています。たとえ Tier 3 の有料ユーザーであっても、全体の計算リソースプールが飽和状態になると、503エラーが返されます。これは、従来の 429(クォータ制限超過)エラーとは性質が異なります。
違いは以下の通りです:
- 429 エラー: 個人の割当(RPM制限など)を使い果たした状態
- 503 エラー: Googleサーバー側の計算リソース不足。ユーザーの割当設定とは無関係
Q2: AI Studio と Vertex AI で呼び出されるのは同じモデルですか?
A: はい、両者が呼び出している基盤となる Nano Banana Pro モデル (gemini-2.0-flash-preview-image-generation) は全く同じものです。しかし、リソースのスケジューリング優先順位が異なります:
- Vertex AI: エンタープライズ級の SLA(サービス品質保証)があり、計算リソースが優先的に割り当てられます。
- AI Studio: 共有リソースプールを使用するため、ピーク時にはパフォーマンスが低下したり制限されたりする可能性があります。
これは、クラウドサーバーにおける「従量課金(オンデマンド)」と「年間・月間予約インスタンス」の違いに似ています。
Q3: Google は今後も無料枠の割当を削減し続けるのでしょうか?
A: これまでの傾向から、Google は無料枠のポリシーを調整し続ける可能性があります:
- 2025年11月:無料枠 3枚/日
- 2025年12月7日:2枚/日に減少、2.5 Pro の削除
- 2026年1月:RPM が 10 から 5 に低下
Google の公式発表では「持続可能なサービス品質の確保」とされていますが、実際には コスト管理とユーザー増加のバランスを模索している 状態です。商用アプリケーションでは無料枠に依存せず、有料プランへの移行やマルチクラウドによるバックアップを事前に計画することをお勧めします。
Q4: Nano Banana Pro の安定性はいつ頃改善されますか?
A: Google の公開情報に基づくと、重要なマイルストーンは 2026年中期 とされています:
- 2026年 Q2: TPU v7 (Ironwood) の大規模展開が完了
- 2026年 Q3: Anthropic との提携による 1 GW 規模の計算リソースが稼働開始
この時期には計算リソースの供給が大幅に増加しますが、同時に需要も増加すると予想されます。控えめに見積もって、安定性が実質的に改善されるのは 2026年後半 になるでしょう。
Q5: Nano Banana Pro の最適な導入方法は?
A: アプリケーションの開発フェーズに合わせて選択してください:
| フェーズ | 推奨プラン | 理由 |
|---|---|---|
| プロトタイプ開発 | AI Studio 無料枠 | コストを最小限に抑え、迅速にアイデアを検証 |
| 小規模リリース | AI Studio Tier 1 + リトライメカニズム | コストと安定性のバランスを維持 |
| 本番環境 | Vertex AI または APIYI プラットフォーム | SLA 保証とエンタープライズ級のサポート |
| ミッションクリティカル | マルチクラウド・バックアップ戦略 (例: APIYI プラットフォーム) | 最高の可用性と自動フェイルオーバー |
🎯 意思決定のアドバイス: 選択に迷う場合は、APIYI (apiyi.com) プラットフォームを通じた A/B テストを推奨します。このプラットフォームでは、同じリクエストで Nano Banana Pro (AI Studio)、Nano Banana Pro (Vertex AI)、DALL-E 3 などの実際のパフォーマンスを比較でき、リアルなデータに基づいた意思決定が可能になります。
まとめ:Nano Banana Pro の計算リソース問題にどう向き合うか
Nano Banana Pro の安定性の問題は孤立した事象ではなく、AI 業界全体が直面している 計算リソースの需要と供給の矛盾 を象徴しています。
核心となる矛盾:
- 需要側: 生成AIアプリケーションの爆発的増加(特に画像生成分野)
- 供給側: チップ生産の立ち上がりの遅れ、データセンター建設の長期サイクル(12〜18ヶ月)
- 経済モデル: 無料枠戦略の持続可能性の低さと、有料転換率の課題
3つの技術的真実:
-
自社製TPU ≠ 無限の計算リソース: Google は TPU v7 のような先進的なチップを保有していますが、生産能力の向上、電力供給、データセンター建設には時間が必要です。2026年が大きな転換点となります。
-
AI Studio vs Vertex AI の本質: 両者は単なる「無料版」と「有料版」の関係ではなく、リソースのスケジューリング優先順位 の違いです。Vertex AI のエンタープライズ SLA の裏側には、独立した計算リソースの予約メカニズムが存在します。
-
供給不足は長期化する: Gemini 3.0 や GPT-5 といった次世代モデルの発表に伴い、計算リソースへの需要は増え続けます。短期的(2026〜2027年)には、需給の逼迫状態が根本的に解消されることはないでしょう。
実践的なアドバイス:
- 短期: リトライメカニズムやリクエスト間隔の制御といったエンジニアリング手法で問題を緩和する
- 中期: Vertex AI やマルチクラウドプラットフォームへアップグレードした際の投資対効果(ROI)を評価する
- 長期: 2026年中期の Google の計算リソース拡張の進捗に注目し、適宜戦略を調整する
企業向けアプリケーションにおいては、単一ベンダーのリソースリスクを避けるために、マルチクラウド・バックアップ戦略 を採用することを強く推奨します。APIYI (apiyi.com) のような統合プラットフォームを利用することで、コードの複雑さを増すことなく、クラウドをまたいだスケーリング、自動フェイルオーバー、コスト最適化を実現できます。
最後に: Nano Banana Pro が直面している課題は、AI アプリケーションの安定性がモデルの能力だけでなく、基盤となるインフラの成熟度に依存していることを改めて教えてくれています。計算リソースが鍵を握るこの時代において、堅牢なアーキテクチャ設計とプロバイダーの多様化 こそが、製品競争力の源泉となるでしょう。
関連情報:
- Nano Banana Pro API 利用ガイド
- Google TPU v7 アーキテクチャ徹底解説
- AI 画像生成 API の選び方:Nano Banana Pro vs DALL-E 3 vs Stable Diffusion
- 本番環境における AI API 呼び出しのベストプラクティス10選