Note de l'auteur : Analyse approfondie des 5 percées majeures du modèle unifié de génération et d'édition d'images Qwen-Image-2.0, incluant l'architecture légère de 7B, la résolution 2K native, les invites de 1000 tokens, ainsi qu'un guide d'accès API et d'utilisation pratique.
L'équipe Tongyi d'Alibaba a publié le 10 février 2026 Qwen-Image-2.0, une mise à jour majeure qui unifie la génération et l'édition d'images au sein d'un seul et même modèle. Ce qui est impressionnant, c'est qu'il a réduit le nombre de paramètres de 20B (version précédente) à seulement 7B, tout en améliorant globalement les performances. APIYI, en tant que partenaire autorisé d'Alibaba Cloud, est actuellement en phase d'intégration ; nous prévoyons une mise en ligne rapide avec des tarifs avantageux.
Valeur ajoutée : Grâce à cette analyse approfondie, vous découvrirez les 5 percées majeures de Qwen-Image-2.0, ses différences réelles par rapport à la concurrence, et comment l'intégrer rapidement via API.
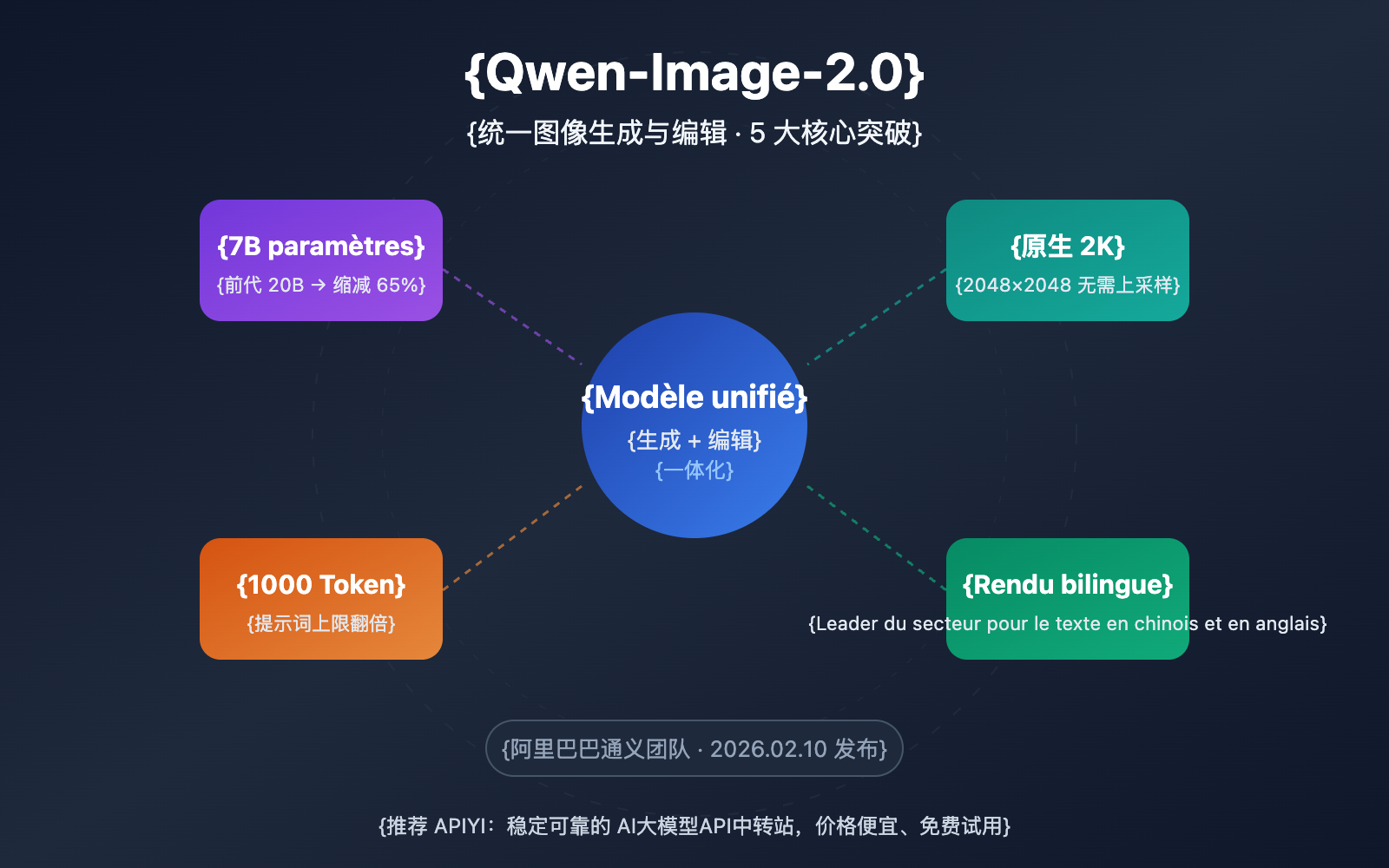
Aperçu des points clés de Qwen-Image-2.0
| Point clé | Description | Valeur |
|---|---|---|
| Génération + Édition unifiées | Texte-vers-image et édition d'image combinés dans un seul modèle 7B | Plus besoin de charger deux modèles séparés, réduction drastique des coûts de déploiement |
| Réduction de 65 % des paramètres | Passage de 20B à 7B (décodeur de diffusion) | Inférence plus rapide, besoins en VRAM nettement diminués |
| Résolution 2K native | Supporte une sortie native jusqu'à 2048×2048 | Pas besoin d'upscaling, clarté des détails supérieure |
| Invite de 1000 Tokens | Limite d'invite doublée (contre ~500 tokens auparavant) | Supporte des descriptions de scènes complexes et un contrôle précis |
| Rendu de texte bilingue | Génération de texte en chinois et anglais leader du secteur | Résultats exceptionnels pour les affiches, infographies et visuels textuels |
Analyse technique de Qwen-Image-2.0
Qwen-Image-2.0 adopte une toute nouvelle architecture à double composant : le modèle vision-langage Qwen3-VL de 8B paramètres sert d'encodeur de conditions, tandis que le MMDiT (Multimodal Diffusion Transformer) de 7B paramètres fait office de décodeur de diffusion. Cette conception permet au modèle de comprendre en profondeur les informations sémantiques des modalités textuelles et visuelles, puis de générer des images de haute qualité via le processus de diffusion.
La différence majeure avec la génération précédente Qwen-Image-2512 réside dans la stratégie d'entraînement unifiée : le texte-vers-image (T2I) et l'édition d'image (I2I/TI2I) sont fusionnés dans une seule propagation avant. Cela signifie qu'un seul modèle peut accomplir ce qui nécessitait auparavant deux modèles distincts, Qwen-Image (génération) et Qwen-Image-Edit (édition), simplifiant ainsi grandement le déploiement et la complexité.
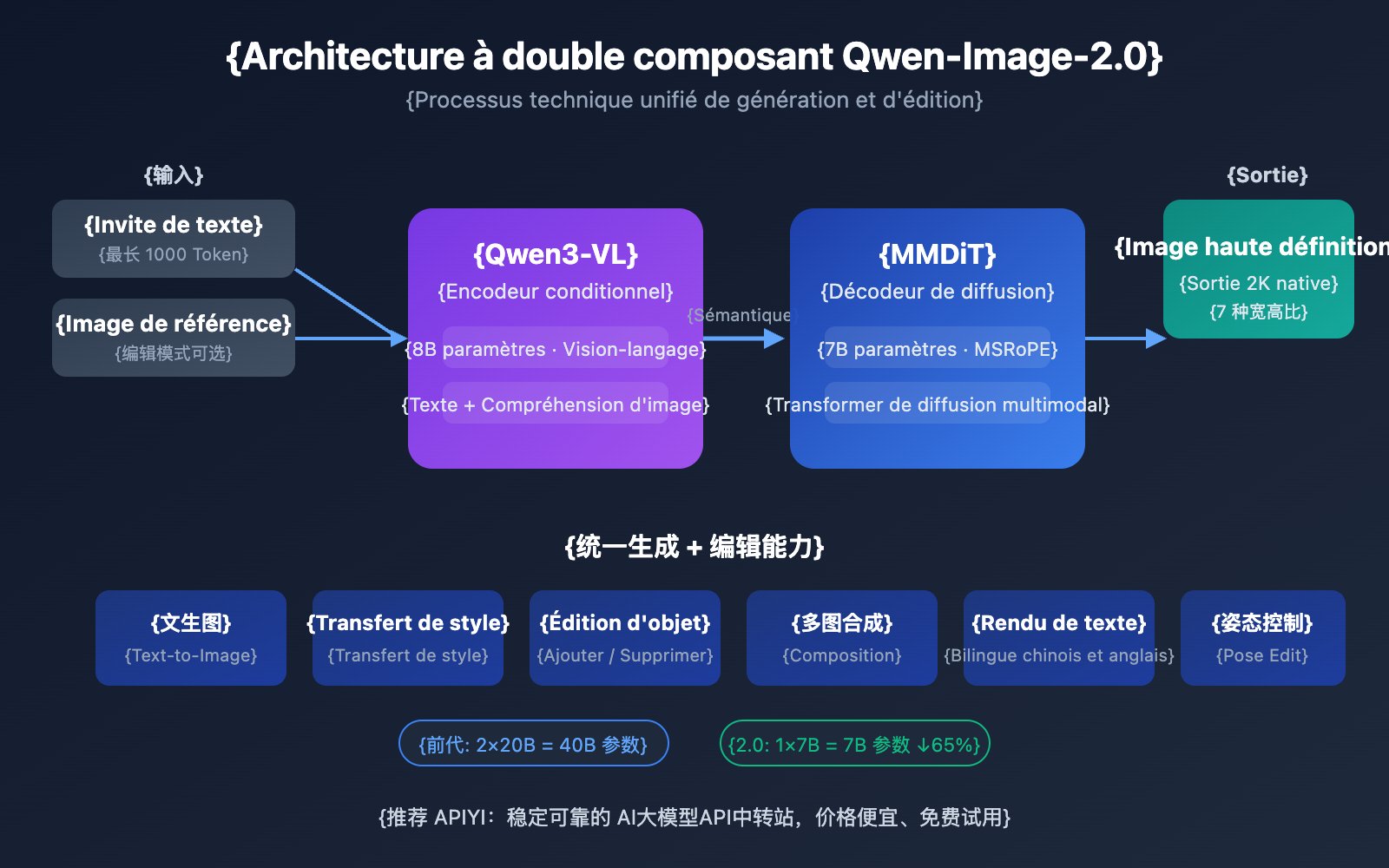
Analyse détaillée des 5 percées majeures de Qwen-Image-2.0
Percée n°1 : Architecture unifiée de génération et d'édition
C'est l'innovation la plus emblématique de Qwen-Image-2.0. Alors que la génération précédente nécessitait de maintenir séparément un modèle de texte-vers-image et un modèle d'édition d'image, la version 2.0 fusionne les deux :
| Capacité | Solution précédente | Qwen-Image-2.0 |
|---|---|---|
| Texte-vers-image | Qwen-Image-2512 (20B) | Modèle unifié (7B) |
| Édition d'image | Qwen-Image-Edit-2511 (20B) | Modèle unifié (7B) |
| Transfert de style | Géré par le modèle d'édition | Support direct par le modèle unifié |
| Synthèse multi-images | Géré par le modèle d'édition | Support direct par le modèle unifié |
| VRAM totale du modèle | Nécessite 2 modèles de 20B | Un seul modèle de 7B suffit |
En pratique, vous pouvez d'abord générer une image à partir d'un texte, puis effectuer directement des opérations d'édition sur cette même image — transfert de style, ajout/suppression d'objets, ajustement de pose, etc. — le tout sans jamais changer de modèle.
Percée n°2 : Des performances supérieures avec seulement 7B de paramètres
Passer de 20B à 7B (pour le décodeur de diffusion) représente une réduction de 65 % du nombre de paramètres, et pourtant, la qualité d'image s'est améliorée. La clé réside dans la capacité de compréhension sémantique profonde de l'encodeur Qwen3-VL. Ce grand modèle de langage visuel de 8B de paramètres assume une plus grande part de travail dans la phase de "compréhension du besoin", permettant au décodeur de diffusion de se concentrer plus efficacement sur la "génération de l'image".
Pour les développeurs, cela signifie :
- Vitesse d'inférence accrue : Appel API d'environ 5 à 8 secondes par image.
- Besoins en VRAM réduits : On estime qu'une VRAM de 24 Go suffira (contre plus de 48 Go pour la génération précédente).
- Coûts de déploiement réduits : Possibilité de faire tourner le modèle sur un seul GPU grand public.
Percée n°3 : Haute résolution 2K native
Qwen-Image-2.0 supporte nativement une sortie en résolution 2048×2048, sans étape supplémentaire d'upscaling (suréchantillonnage). Il prend en charge 7 ratios d'aspect standards :
| Ratio | Résolution | Usage recommandé |
|---|---|---|
| 16:9 | 1664×928 | Couvertures vidéo, illustrations de blog (par défaut) |
| 1:1 | 1328×1328 | Avatars de réseaux sociaux, images produits |
| 9:16 | 928×1664 | Fonds d'écran mobile, couvertures de vidéos courtes |
| 4:3 | 1472×1104 | Affichage paysage traditionnel |
| 3:4 | 1104×1472 | Affichage portrait traditionnel |
| 3:2 | 1584×1056 | Photos style paysage |
| 2:3 | 1056×1584 | Photos style portrait |
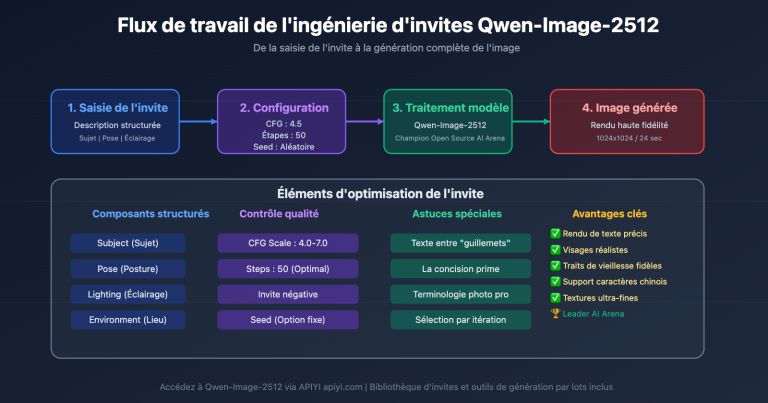
Percée n°4 : Longues invites de 1000 tokens
La limite des invites est passée d'environ 500 tokens à 1000 tokens. Cet espace doublé vous permet de décrire des scènes beaucoup plus complexes. Lors des tests réels, cela s'est avéré particulièrement précieux pour :
- Infographies professionnelles : Contrôle précis de la mise en page, du contenu textuel et de la palette de couleurs.
- Scènes multi-sujets : Description simultanée des relations spatiales et des interactions entre plusieurs objets.
- Fusion de styles : Description détaillée du style artistique souhaité et des exigences de texture.
Percée n°5 : Leader du rendu de texte bilingue
La capacité de Qwen-Image-2.0 à générer du texte à l'intérieur des images est à la pointe de l'industrie, particulièrement pour le rendu du chinois — supportant divers styles de polices comme le Kaishu, le Shoujin ou le Xiaozhuan. Cela lui donne un avantage net dans les scénarios suivants :
- Conception d'affiches marketing et promotionnelles.
- Graphiques techniques avec annotations en chinois.
- Contenu texte-image pour les réseaux sociaux.
- Génération de supports visuels de marque.
🎯 Conseil pratique : Qwen-Image-2.0 est actuellement en phase de test bêta sur invitation via API. APIYI (apiyi.com) est en train de l'intégrer activement et proposera prochainement des tarifs 20 % inférieurs à ceux du site officiel, avec un support d'appel unifié au format compatible OpenAI. Restez à l'écoute.
Prise en main rapide de Qwen-Image-2.0
Exemple minimaliste
Voici la méthode de base pour générer une image via l'appel API de Qwen-Image-2.0 (basé sur le format API DashScope) :
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="qwen-image-2.0",
messages=[{
"role": "user",
"content": "一只戴墨镜的柴犬在沙滩冲浪,阳光明媚,高清摄影风格"
}]
)
print(response.choices[0].message.content)
Voir l’exemple d’appel API natif DashScope
from dashscope import MultiModalConversation
import os
response = MultiModalConversation.call(
api_key=os.getenv("DASHSCOPE_API_KEY"),
model="qwen-image-max",
messages=[{
"role": "user",
"content": [{
"text": "现代简约办公桌,桌上有笔记本和绿植,柔和自然光"
}]
}],
size="1328*1328",
prompt_extend=True,
watermark=False
)
image_url = response.output.choices[0].message.content[0]["image"]
print(f"图像URL: {image_url}")
# Note: L'URL est valide 24 heures, veuillez la télécharger rapidement.
Suggestion : APIYI (apiyi.com) intègre actuellement Qwen-Image-2.0. Une fois disponible, vous pourrez utiliser un format compatible OpenAI pour tester et comparer avec une seule clé API plusieurs modèles comme GPT Image 1.5, Gemini 3 Pro Image ou FLUX.2.
Qwen-Image-2.0 vs la concurrence

| Critère de comparaison | Qwen-Image-2.0 | GPT Image 1.5 | Gemini 3 Pro Image | FLUX.2 Max |
|---|---|---|---|---|
| Développeur | Alibaba | OpenAI | Black Forest Labs | |
| Génération + Édition unifiées | ✅ | ✅ | ✅ | ❌ |
| Résolution max | 2K | 2K+ | 2K | 2K |
| Rendu de texte chinois | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐ |
| Vitesse d'inférence | 5-8 secondes | 10-15 secondes | 5-10 secondes | 10-20 secondes |
| Écosystème Open Source | Précédent open source | Propriétaire | Propriétaire | Partiellement open source |
| Réf. prix API | -20% via APIYI | 0,04 $ – 0,08 $ / image | Facturation par token | 0,04 $ / image |
Les avantages distinctifs de Qwen-Image-2.0 :
- Le plus performant pour le chinois : Sa capacité de rendu de texte bilingue est leader du secteur. Le rendu des affiches et infographies en chinois est nettement supérieur à celui des concurrents.
- Architecture la plus légère : Avec seulement 7B de paramètres, il atteint une qualité équivalente à GPT Image 1.5, tout en offrant des coûts d'inférence plus bas.
- Potentiel Open Source : Toute la série précédente est sous licence Apache-2.0 ; on peut donc s'attendre à une ouverture prochaine de la version 2.0.
- Écosystème riche : Plus de 2 380 likes sur HuggingFace, plus de 484 adaptateurs LoRA et une communauté très active.
Note comparative : Les données ci-dessus proviennent de documentations techniques publiques et du classement AI Arena. Nous vous recommandons de tester et comparer les performances de chaque modèle selon vos besoins spécifiques via la plateforme APIYI (apiyi.com).
Scénarios d'utilisation recommandés pour Qwen-Image-2.0
Ce modèle est particulièrement adapté aux contextes suivants :
- Images de produits e-commerce : Un modèle unique pour générer des photos de produits et remplacer les arrière-plans, simplifiant considérablement le flux de travail. Idéal pour les équipes d'exploitation e-commerce et de design.
- Conception de supports marketing : Affiches, visuels pour les réseaux sociaux, ressources publicitaires ; le rendu puissant du texte chinois est un avantage concurrentiel majeur. Idéal pour les équipes marketing.
- Design créatif : Supporte divers styles artistiques comme le réalisme, l'anime, l'aquarelle ou le dessin à la main. Les invites (prompts) longues de 1000 tokens permettent un contrôle précis de la direction créative. Idéal pour les designers et les créateurs de contenu.
- Génération de diagrammes techniques : Pages PPT, infographies, organigrammes et autres contenus professionnels avec une mise en page précise au pixel près. Idéal pour les équipes de documentation technique.
🎯 Conseil : Si votre activité implique la génération massive de contenus texte-image en chinois, Qwen-Image-2.0 est actuellement l'option la plus pertinente. Nous vous suggérons d'effectuer des tests comparatifs via la plateforme APIYI (apiyi.com) pour trouver la solution la mieux adaptée à vos besoins métier.
Évolution des versions et tarifs de Qwen-Image-2.0
Chronologie de l'évolution des versions
Depuis le lancement de la première version en août 2025, la série Qwen-Image a maintenu un rythme d'itération soutenu :
| Version | Date | Améliorations clés |
|---|---|---|
| Qwen-Image v1 | 08.2025 | Lancement initial 20B MMDiT, open-source Apache-2.0 |
| Qwen-Image-Edit | 08.2025 | Ajout d'un modèle d'édition dédié |
| Qwen-Image-2512 | 12.2025 | Amélioration des textures réalistes et du rendu de texte |
| Qwen-Image-2.0 | 02.2026 | Architecture unifiée, version légère 7B, 2K natif |
Références de prix
| Canal | Modèle | Prix de référence |
|---|---|---|
| Alibaba Cloud DashScope | qwen-image-max | 0,50 ¥ / image |
| Alibaba Cloud DashScope | qwen-image-plus | 0,20 ¥ / image |
| Replicate | Qwen Image | 0,030 $ / image |
| Fal.ai | Qwen Image Edit | 0,021 $ / image |
| APIYI (Bientôt disponible) | Qwen-Image-2.0 | 20 % de réduction par rapport au prix officiel |
💡 Le prix de la version finale de Qwen-Image-2.0 n'a pas encore été annoncé. APIYI (apiyi.com) travaille activement sur son intégration et proposera des tarifs inférieurs de 20 % à ceux du site officiel. Inscrivez-vous dès maintenant pour obtenir des crédits de test gratuits. Restez à l'écoute !
FAQ
Q1 : Quelle est la différence entre Qwen-Image-2.0 et Qwen-Image-2512 ?
La plus grande différence est que la version 2.0 unifie la génération et l'édition dans un modèle unique de 7B paramètres, alors que la génération précédente (2512) était un modèle de 20B purement dédié au texte-vers-image, nécessitant le chargement séparé de Qwen-Image-Edit pour les modifications. La version 2.0 prend également en charge une résolution native 2K et des invites allant jusqu'à 1000 tokens, avec des améliorations notables de la qualité d'image et du rendu de texte.
Q2 : Qwen-Image-2.0 est-il disponible via API ?
Il est actuellement en phase de test bêta sur invitation pour l'API, mais vous pouvez l'essayer gratuitement en ligne sur chat.qwen.ai. APIYI (apiyi.com) est en cours d'intégration et proposera, dès son lancement, des tarifs 20 % inférieurs à ceux du site officiel. Le service sera compatible avec le format OpenAI, permettant de comparer plusieurs modèles de génération d'images avec une seule clé API.
Q3 : Qwen-Image-2.0 est-il adapté à un déploiement local ?
Les poids de Qwen-Image-2.0 ne sont pas encore open-source. Cependant, compte tenu du fait que la série précédente était sous licence Apache-2.0, la communauté s'attend généralement à ce que la version 2.0 le devienne aussi. Sa taille de 7B paramètres signifie qu'un GPU grand public (avec 24 Go de VRAM) devrait pouvoir le faire tourner. En attendant l'ouverture du code, il est recommandé de passer par APIYI (apiyi.com) pour tester rapidement ses performances via API.
Résumé
Points clés de Qwen-Image-2.0 :
- L'architecture unifiée est l'atout majeur : Un seul modèle de 7B gère la génération + l'édition, là où la génération précédente nécessitait deux modèles de 20B.
- Plus léger sans sacrifier la qualité : Une réduction de 65 % des paramètres tout en améliorant globalement la qualité d'image et l'éventail des fonctionnalités.
- Indispensable pour le contexte chinois : Rendu de texte bilingue, support de multiples polices ; c'est le choix numéro un pour la création de contenus texte-image en chinois.
- Accès API imminent : Actuellement en test sur invitation, la version officielle est très attendue.
Qwen-Image-2.0 représente une avancée majeure pour les grands modèles de langage visuels produits en Chine. Pour les équipes ayant besoin de contenus texte-image de haute qualité, c'est l'un des modèles les plus intéressants à suivre actuellement.
Nous vous recommandons de suivre les actualités d'intégration et les tarifs préférentiels (20 % de réduction par rapport au site officiel) sur APIYI (apiyi.com). La plateforme propose des crédits gratuits et une interface unifiée multi-modèles pour faciliter vos tests comparatifs.
📚 Ressources de référence
-
Blog officiel de Qwen : Annonce de la sortie de Qwen-Image-2.0
- Lien :
qwen.ai/blog?id=qwen-image-2.0 - Description : Analyse technique officielle et présentation des fonctionnalités.
- Lien :
-
Dépôt GitHub : Page d'accueil du projet Qwen-Image
- Lien :
github.com/QwenLM/Qwen-Image - Description : Code source ouvert, documentation technique et guides d'utilisation.
- Lien :
-
Classement AI Arena : Classements pour la génération de texte-vers-image et l'édition d'images
- Lien :
arena.ai/leaderboard/text-to-image - Description : Classements d'évaluation indépendants tiers, avec des données mises à jour en temps réel.
- Lien :
-
Documentation API Alibaba Cloud : API de génération d'images DashScope
- Lien :
help.aliyun.com/zh/model-studio/qwen-image-api - Description : Documentation officielle d'accès à l'API et description des paramètres.
- Lien :
Auteur : Équipe technique
Échanges techniques : N'hésitez pas à discuter dans la section des commentaires. Pour plus de ressources, vous pouvez visiter la communauté technique APIYI sur apiyi.com.