Gemini 3.1 Pro Preview a ajouté le niveau de réflexion medium, ce qui constitue l'une des différences majeures avec la génération précédente Gemini 3 Pro. Vous pouvez désormais contrôler précisément la profondeur de raisonnement du modèle entre trois niveaux : low, medium et high. Le mode high active même les capacités de Deep Think Mini.
Valeur ajoutée : En lisant cet article, vous maîtriserez la méthode de configuration complète du paramètre thinkingLevel et apprendrez à trouver l'équilibre optimal entre qualité, vitesse et coût.

Matrice de support complète des niveaux de réflexion Gemini 3.1 Pro
Commençons par une vue d'ensemble : les différents modèles Gemini supportent des niveaux de réflexion différents.
| Niveau de réflexion | Gemini 3.1 Pro | Gemini 3 Pro | Gemini 3 Flash | Description |
|---|---|---|---|---|
| minimal | ❌ Non supporté | ❌ Non supporté | ✅ Supporté | Proche de la désactivation, uniquement Flash |
| low | ✅ Supporté | ✅ Supporté | ✅ Supporté | Réponse rapide, coût minimal |
| medium | ✅ Nouveau support | ❌ Non supporté | ✅ Supporté | Raisonnement équilibré, mise à jour clé de 3.1 Pro |
| high | ✅ Supporté (par défaut) | ✅ Supporté (par défaut) | ✅ Supporté (par défaut) | Raisonnement profond, active Deep Think Mini |
Changements clés : Évolution des niveaux de réflexion de 3 Pro → 3.1 Pro
| Comparaison | Gemini 3 Pro | Gemini 3.1 Pro |
|---|---|---|
| Niveaux disponibles | low, high (2 niveaux) | low, medium, high (3 niveaux) |
| Niveau par défaut | high | high |
| Signification du mode high | Raisonnement profond | Deep Think Mini (plus puissant) |
| Désactivation possible ? | Non | Non |
Point essentiel à retenir : La profondeur de raisonnement du mode high de Gemini 3 Pro est approximativement équivalente au niveau medium de Gemini 3.1 Pro. Le mode high de la version 3.1 Pro est le tout nouveau Deep Think Mini, dont la profondeur de raisonnement dépasse de loin celle de la génération précédente.
🎯 Conseil de migration : Si vous utilisiez auparavant le mode high de Gemini 3 Pro, nous vous suggérons de passer d'abord au niveau medium avec Gemini 3.1 Pro (pour conserver une qualité et un coût similaires), et d'activer le mode high uniquement lorsque vous avez besoin d'un raisonnement très approfondi. APIYI (apiyi.com) supporte simultanément tous les modèles Gemini et leurs niveaux de réflexion.
Gemini 3.1 Pro 思考等级 API 设置方法
通过 APIYI 调用 (OpenAI 兼容格式)
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # APIYI 统一接口
)
# LOW 模式: 快速响应
response_low = client.chat.completions.create(
model="gemini-3.1-pro-preview",
messages=[{"role": "user", "content": "把这段英文翻译成中文: Hello World"}],
extra_body={
"thinking": {"type": "enabled", "budget_tokens": 1024}
}
)
# MEDIUM 模式: 平衡推理 (新增!)
response_med = client.chat.completions.create(
model="gemini-3.1-pro-preview",
messages=[{"role": "user", "content": "审查这段代码有没有内存泄漏风险"}],
extra_body={
"thinking": {"type": "enabled", "budget_tokens": 8192}
}
)
# HIGH 模式: Deep Think Mini
response_high = client.chat.completions.create(
model="gemini-3.1-pro-preview",
messages=[{"role": "user", "content": "证明: 对所有正整数n, n^3-n能被6整除"}],
extra_body={
"thinking": {"type": "enabled", "budget_tokens": 32768}
}
)
通过 Google SDK 原生调用
from google import genai
from google.genai import types
client = genai.Client()
# 使用 thinkingLevel 参数
response = client.models.generate_content(
model="gemini-3.1-pro-preview",
contents="你的提示词",
config=types.GenerateContentConfig(
thinking_config=types.ThinkingConfig(
thinking_level="MEDIUM" # "LOW" / "MEDIUM" / "HIGH"
)
),
)
# 查看思考 token 消耗
print(f"思考 token: {response.usage_metadata.thoughts_token_count}")
print(f"输出 token: {response.usage_metadata.candidates_token_count}")
REST API 调用
POST https://generativelanguage.googleapis.com/v1beta/models/gemini-3.1-pro-preview:generateContent
{
"contents": [{"parts": [{"text": "你的提示词"}]}],
"generationConfig": {
"thinkingConfig": {
"thinkingLevel": "MEDIUM"
}
}
}
⚠️ 重要提醒:
thinkingLevel和thinkingBudget不能同时使用,否则会返回 400 错误。Gemini 3+ 模型推荐使用thinkingLevel,Gemini 2.5 模型使用thinkingBudget。
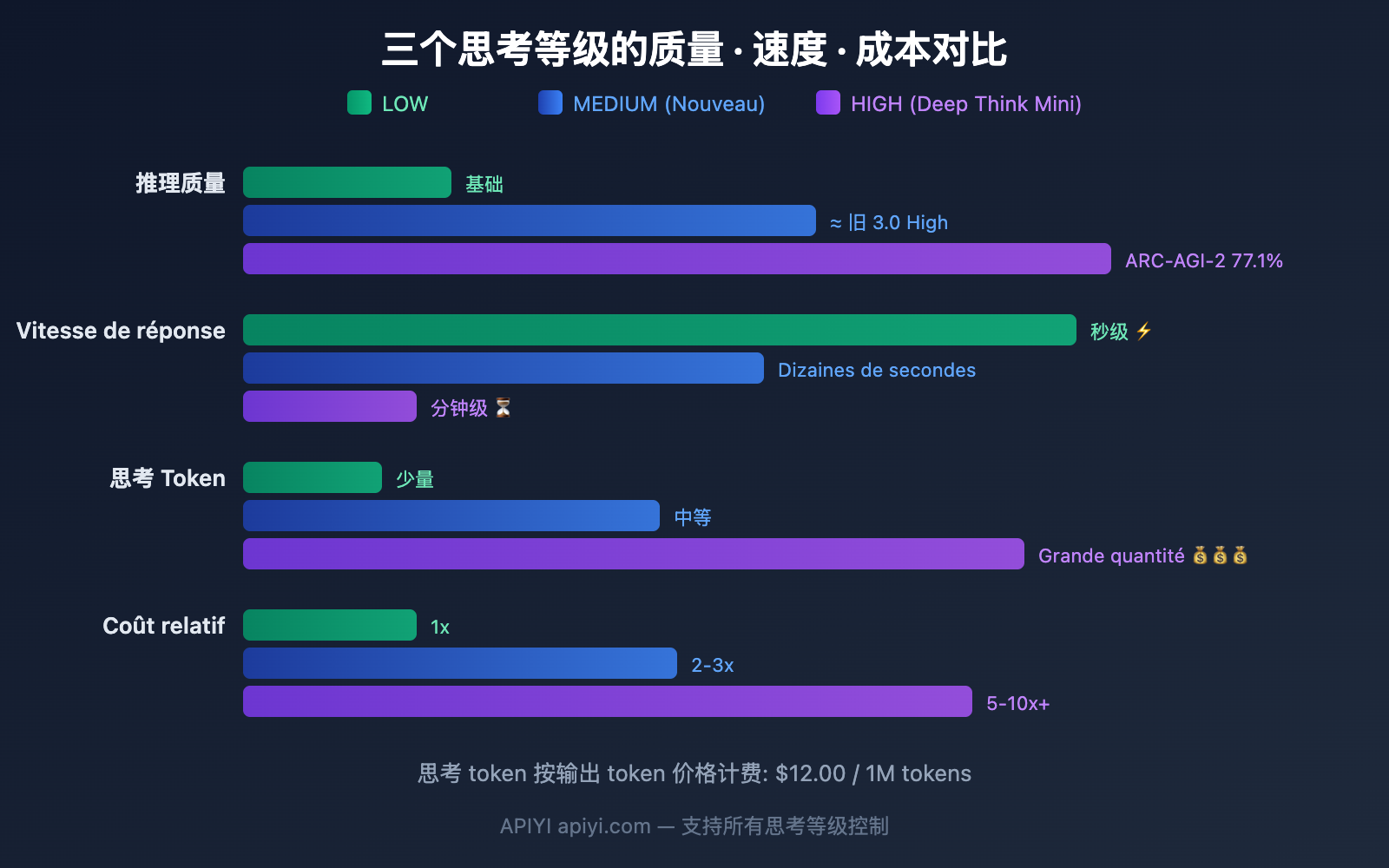
3 个思考等级的 Gemini 3.1 Pro 详细对比
LOW: 最快最便宜
| 维度 | 详情 |
|---|---|
| 推理深度 | 最少的思考 token,仍优于不思考的模型 |
| 响应速度 | 秒级 (最快) |
| 成本 | 最低 (思考 token 少 → 输出 token 少 → 费用低) |
| 适用场景 | 自动补全、分类、结构化数据提取、简单翻译、摘要 |
| 不适合 | 复杂推理、数学证明、多步调试 |
MEDIUM: 平衡首选 (新增)
| 维度 | 详情 |
|---|---|
| 推理深度 | 中等思考 token,≈ 旧版 3.0 Pro 的 high 水平 |
| 响应速度 | 中等延迟 |
| 成本 | 中等 |
| 适用场景 | 代码审查、文档分析、日常编码、标准 API 调用、问答 |
| 不适合 | IMO 级数学、极复杂的多步推理 |
HIGH: Deep Think Mini (默认)
| 维度 | 详情 |
|---|---|
| 推理深度 | 最大化推理,激活 Deep Think Mini 能力 |
| 响应速度 | 可能需要数分钟 (IMO 题 ~8 分钟) |
| 成本 | 最高 (大量思考 token 按输出价格计费) |
| 适用场景 | 复杂调试、算法设计、数学证明、研究任务、Agent 工作流 |
| 特殊能力 | 思考签名 (thought signatures) 保持跨 API 调用的推理连续性 |
Règles de facturation des tokens de réflexion de Gemini 3.1 Pro
Comprendre la facturation est essentiel pour choisir le bon niveau de réflexion.
Principes fondamentaux de facturation
| Élément de facturation | Description |
|---|---|
| Les tokens de réflexion sont-ils facturés ? | Oui, ils sont facturés au même prix que les tokens de sortie. |
| Prix des tokens de sortie | 12,00 $ / 1M de tokens (incluant les tokens de réflexion). |
| Base de facturation | Facturé sur la chaîne de raisonnement interne complète, et pas seulement sur le résumé. |
| Résumé de la réflexion | L'API ne renvoie que le résumé de la réflexion, mais facture le nombre total de tokens de réflexion générés. |
Explication officielle de Google :
"Les modèles de réflexion génèrent des pensées complètes pour améliorer la qualité de la réponse finale, puis produisent des résumés pour donner un aperçu du processus de réflexion. La tarification est basée sur l'ensemble des tokens de réflexion que le modèle doit générer pour créer un résumé, même si seul le résumé est renvoyé par l'API."
Estimation des coûts pour les trois niveaux
| Niveau | Estimation des tokens de réflexion | Pour 1 000 appels | Tendance du coût mensuel |
|---|---|---|---|
| LOW | ~500-2K / appel | 6 – 24 $ | Le plus bas |
| MEDIUM | ~2K-8K / appel | 24 – 96 $ | Modéré |
| HIGH | ~8K-32K+ / appel | 96 – 384 $+ | Élevé, plus pour les tâches complexes |
💰 Optimisation des coûts : Toutes les requêtes n'ont pas besoin du niveau HIGH. En réglant 80 % des tâches quotidiennes sur LOW ou MEDIUM et seulement 20 % des tâches complexes sur HIGH, vous pouvez réduire vos dépenses API de 50 à 70 %. La plateforme APIYI (apiyi.com) permet de configurer cela de manière flexible.
Guide de correspondance entre types de tâches et niveaux de réflexion Gemini 3.1 Pro
Recommandations par scénarios détaillés
| Type de tâche | Niveau recommandé | Raison | Latence attendue |
|---|---|---|---|
| Traduction simple | LOW | Pas de raisonnement requis | < 5 s |
| Classification de texte | LOW | Tâche de reconnaissance de formes | < 5 s |
| Extraction de résumé | LOW | Compression d'information, pas de raisonnement | < 10 s |
| Saisie automatique | LOW | Sensible à la latence | < 3 s |
| Revue de code | MEDIUM | Nécessite une analyse modérée | 10-30 s |
| Questions-réponses sur documents | MEDIUM | Compréhension + Réponse | 10-30 s |
| Codage quotidien | MEDIUM | Génération de code classique | 15-40 s |
| Analyse de bugs | MEDIUM | Raisonnement de complexité moyenne | 20-40 s |
| Débogage complexe | HIGH | Chaîne de raisonnement multi-étapes | 1-5 min |
| Preuve mathématique | HIGH | Deep Think Mini | 3-8 min |
| Conception d'algorithmes | HIGH | Raisonnement approfondi | 2-5 min |
| Analyse de recherche | HIGH | Analyse approfondie multidimensionnelle | 2-5 min |
| Workflow d'agent | HIGH | Maintien de la continuité de la réflexion | Selon la tâche |
Sélection dynamique du niveau : Code de bonnes pratiques
import openai
client = openai.OpenAI(
api_key="VOTRE_CLE_API",
base_url="https://api.apiyi.com/v1" # Interface unifiée APIYI
)
# Sélection automatique du niveau de réflexion selon le type de tâche
THINKING_CONFIG = {
"simple": {"type": "enabled", "budget_tokens": 1024}, # LOW
"medium": {"type": "enabled", "budget_tokens": 8192}, # MEDIUM
"complex": {"type": "enabled", "budget_tokens": 32768}, # HIGH
}
def smart_think(prompt, complexity="medium"):
"""Définit automatiquement le niveau de réflexion selon la complexité de la tâche"""
return client.chat.completions.create(
model="gemini-3.1-pro-preview",
messages=[{"role": "user", "content": prompt}],
extra_body={"thinking": THINKING_CONFIG[complexity]}
)
# Traduction simple → LOW
resp1 = smart_think("Traduire : Good morning", "simple")
# Revue de code → MEDIUM
resp2 = smart_think("Vérifier la sécurité de ce code : ...", "medium")
# Preuve mathématique → HIGH (Deep Think Mini)
resp3 = smart_think("Prouver un cas particulier de l'hypothèse de Riemann", "complex")
Gemini 3.1 Pro vs 3 Pro : Évolution des niveaux de réflexion

Pourquoi Deep Think Mini est-il si puissant ?
L'activation de Deep Think Mini via le mode HIGH de Gemini 3.1 Pro est le point fort de cette mise à jour.
Qu'est-ce que Deep Think Mini ?
Deep Think Mini n'est pas un modèle indépendant, mais un mode de raisonnement spécial activé par Gemini 3.1 Pro au niveau de réflexion HIGH. Google le décrit comme une « version mini de Gemini Deep Think » — Deep Think étant le modèle de raisonnement lourd dédié de Google (avec un score de 84,6 % sur ARC-AGI-2).
Performances réelles de Deep Think Mini
| Test | Deep Think Mini (3.1 Pro HIGH) | Gemini 3 Pro HIGH | Amélioration |
|---|---|---|---|
| ARC-AGI-2 | 77,1 % | 31,1 % | +148 % |
| Problèmes de maths IMO | Résolu en ~8 min | Impossible à résoudre | Passage de l'échec au succès |
| Tâches de planification complexes | Hausse de 40-60 % | Comparé à Gemini 2.5 Pro | Amélioration significative |
Signatures de pensée (Thought Signatures)
Deep Think Mini introduit une technologie unique : les signatures de pensée (thought signatures). Il s'agit de représentations chiffrées et inviolables des états de raisonnement intermédiaires.
Dans les flux de travail des Agents, le raisonnement du modèle s'étend souvent sur plusieurs appels d'API. Les signatures de pensée permettent de transmettre le contexte de raisonnement d'un appel au suivant, garantissant ainsi la continuité du raisonnement. C'est crucial pour les tâches d'Agent multi-étapes.
Quelles tâches méritent d'utiliser Deep Think Mini ?
| Mérite le mode HIGH (Deep Think Mini) | Le mode HIGH n'est pas nécessaire |
|---|---|
| Raisonnement de niveau compétition mathématique | Opérations arithmétiques simples |
| Débogage complexe sur plusieurs fichiers | Correction d'erreurs de syntaxe |
| Conception et optimisation d'algorithmes | Génération de code CRUD |
| Analyse méthodologique de thèses académiques | Résumé d'article |
| Tâches d'Agent longues à étapes multiples | Questions-réponses en un seul tour |
| Analyse approfondie de failles de sécurité | Conversion de format |
💡 Conseil pratique : La puissance de Deep Think Mini a un prix — la latence et le coût sont plus élevés. Il est recommandé d'utiliser le mode HIGH uniquement pour les tâches nécessitant une « réflexion profonde », le mode MEDIUM suffisant pour les tâches quotidiennes. Via APIYI (apiyi.com), vous pouvez basculer de manière flexible à chaque requête.
thinkingLevel vs thinkingBudget : Ne les confondez pas
Google propose deux paramètres pour contrôler la réflexion, applicables à différentes séries de modèles :
| Paramètre | Modèles compatibles | Type de valeur | Description |
|---|---|---|---|
| thinkingLevel | Gemini 3+ (3 Flash, 3 Pro, 3.1 Pro) | Énumération : MINIMAL/LOW/MEDIUM/HIGH | Recommandé pour la série Gemini 3 |
| thinkingBudget | Gemini 2.5 (Pro, Flash, Flash Lite) | Entier : 0-32768 | Applicable à la série 2.5 |
⚠️ Les deux paramètres ne peuvent pas être utilisés simultanément ! Envoyer les deux en même temps retournera une erreur 400.
| Scénario | Bonne pratique | Mauvaise pratique |
|---|---|---|
| Appeler Gemini 3.1 Pro | Utiliser thinkingLevel: "MEDIUM" |
Utiliser thinkingBudget: 8192 |
| Appeler Gemini 2.5 Pro | Utiliser thinkingBudget: 8192 |
Utiliser thinkingLevel: "MEDIUM" |
| Envoyer les deux paramètres | — | Erreur 400 ❌ |
🎯 Astuce pour mémoriser : Série Gemini 3 → thinkingLevel (niveaux sous forme de chaînes de caractères), Série Gemini 2.5 → thinkingBudget (nombre de tokens sous forme d'entier). APIYI (apiyi.com) prend en charge les deux formats de paramètres.
Questions fréquentes
Q1 : Quel est le niveau par défaut si thinkingLevel n’est pas défini ?
Par défaut, c'est le niveau HIGH. Cela signifie que si vous ne le définissez pas activement, chaque appel utilisera toute la capacité de raisonnement de Deep Think Mini, consommant ainsi le maximum de tokens de réflexion. Il est conseillé de choisir un niveau adapté à vos besoins réels pour réduire les coûts. Via APIYI (apiyi.com), vous pouvez contrôler cela de manière flexible au niveau de chaque requête.
Q2 : Comment sont facturés les tokens de réflexion ? Est-ce cher ?
Les tokens de réflexion sont facturés au même prix que les tokens de sortie (12,00 $ / 1M tokens). En mode HIGH, une requête complexe peut consommer plus de 30 000 tokens de réflexion, soit environ 0,36 $. En mode LOW, la même requête pourrait n'en consommer que 1 000, soit environ 0,012 $. L'écart de coût peut donc être multiplié par 30.
Q3 : Le niveau MEDIUM de 3.1 Pro est-il équivalent au HIGH de 3.0 Pro ?
C'est pratiquement équivalent. Selon la description de Google, le niveau MEDIUM de 3.1 Pro offre une « réflexion équilibrée, adaptée à la plupart des tâches », ce qui correspond au positionnement du niveau HIGH de 3.0 Pro. Si vous migrez de 3.0 Pro vers 3.1 Pro, passer de HIGH à MEDIUM vous permettra de conserver une qualité et un coût similaires. Vous pouvez utiliser APIYI (apiyi.com) pour appeler les deux versions et comparer les résultats.
Q4 : Peut-on désactiver la fonction de réflexion ?
Sur Gemini 3.1 Pro, il est impossible de désactiver complètement la réflexion. Le niveau minimum est LOW, ce qui implique toujours un raisonnement de base. Si vous avez besoin d'une réponse sans aucune réflexion, vous pouvez envisager le mode MINIMAL de Gemini 3 Flash.
Idées reçues courantes sur les niveaux de réflexion de Gemini 3.1 Pro
| Idée reçue | Réalité |
|---|---|
| « Le niveau HIGH offre la meilleure qualité, il faut l'utiliser tout le temps » | Pour les tâches simples, la qualité de HIGH est proche de MEDIUM, mais le coût est 5 à 10 fois plus élevé. |
| « Le niveau LOW a une faible capacité de raisonnement » | LOW reste supérieur aux modèles sans réflexion, il utilise simplement moins de tokens de pensée. |
| « MEDIUM est une nouvelle fonctionnalité, elle pourrait être instable » | La profondeur de raisonnement de MEDIUM est environ égale au niveau HIGH de l'ancienne version 3.0 Pro, elle est déjà bien éprouvée. |
| « Les tokens de réflexion ne sont pas facturés » | Si, ils le sont ! Ils sont facturés au même prix que les tokens de sortie (12 $/MTok). |
| « On peut désactiver la réflexion de 3.1 Pro » | Impossible, le minimum est LOW, qui conserve un raisonnement de base. |
| « On peut utiliser thinkingLevel et thinkingBudget ensemble » | Non ! Les utiliser simultanément renverra une erreur 400. |
| « En choisissant un niveau élevé, le délai sera plus long mais le résultat sera instantané » | Le mode HIGH peut mettre plusieurs minutes avant de commencer à répondre, ce n'est pas juste un petit délai. |
Résumé : Aide-mémoire pour choisir le niveau de réflexion de Gemini 3.1 Pro
| Niveau | En résumé | Cas d'utilisation | Coût relatif |
|---|---|---|---|
| LOW | Le plus rapide et le moins cher | Traduction, classification, résumé, complétion | 1x |
| MEDIUM | Le meilleur compromis (nouveau) | Codage, révision, analyse, Q&A | 2-3x |
| HIGH | Deep Think Mini | Mathématiques, débogage, recherche, Agents | 5-10x+ |
Conseils clés :
- Utilisez MEDIUM pour le développement quotidien — Bonne qualité, coût raisonnable, équivalent à l'ancien niveau HIGH.
- Utilisez LOW pour les tâches simples — Économisez plus de 70 % sur les frais de tokens de réflexion.
- Utilisez HIGH pour le raisonnement profond — Les capacités de Deep Think Mini sont uniques, mais attention au coût.
- Le mode par défaut est HIGH — Si vous ne configurez rien, c'est le mode le plus cher qui s'applique, pensez à l'ajuster manuellement.
Nous vous recommandons d'utiliser la plateforme APIYI (apiyi.com) pour basculer dynamiquement entre les niveaux de réflexion selon le type de tâche, afin d'obtenir le meilleur équilibre entre qualité et coût.
Références
-
Documentation Google AI : Guide de configuration de la réflexion Gemini
- Lien :
ai.google.dev/gemini-api/docs/thinking - Description : Documentation complète du paramètre
thinkingLevel.
- Lien :
-
Documentation Google AI : Page du modèle Gemini 3.1 Pro
- Lien :
ai.google.dev/gemini-api/docs/models/gemini-3.1-pro-preview - Description : Matrice de support des niveaux de réflexion et remarques importantes.
- Lien :
-
Page de tarification de l'API Gemini : Explications sur la facturation des tokens de réflexion
- Lien :
ai.google.dev/gemini-api/docs/pricing - Description : Les tokens de réflexion sont facturés au même tarif que les tokens de sortie.
- Lien :
-
VentureBeat : Test approfondi de Deep Think Mini
- Lien :
venturebeat.com/technology/google-gemini-3-1-pro-first-impressions - Description : Données de tests réels montrant la résolution d'un problème d'IMO (Olympiades Internationales de Mathématiques) en 8 minutes.
- Lien :
-
Blog officiel de Google : Annonce du lancement de Gemini 3.1 Pro
- Lien :
blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-3-1-pro - Description : Présentation officielle du système de réflexion à trois niveaux et de Deep Think Mini.
- Lien :
📝 Auteur : Équipe APIYI | Pour les échanges techniques, visitez APIYI apiyi.com
📅 Date de mise à jour : 20 février 2026
🏷️ Mots-clés : Niveaux de réflexion Gemini 3.1 Pro, thinkingLevel, Deep Think Mini, LOW MEDIUM HIGH, appel API, contrôle du raisonnement