Vous avez déjà rencontré l'erreur "You've reached your rate limit. Please try again later." ? C'est frustrant, n'est-ce pas ? Surtout quand tout fonctionnait bien quelques minutes auparavant, que vous n'avez pas dépassé votre limite de tokens, et que soudainement, plus rien ne marche.
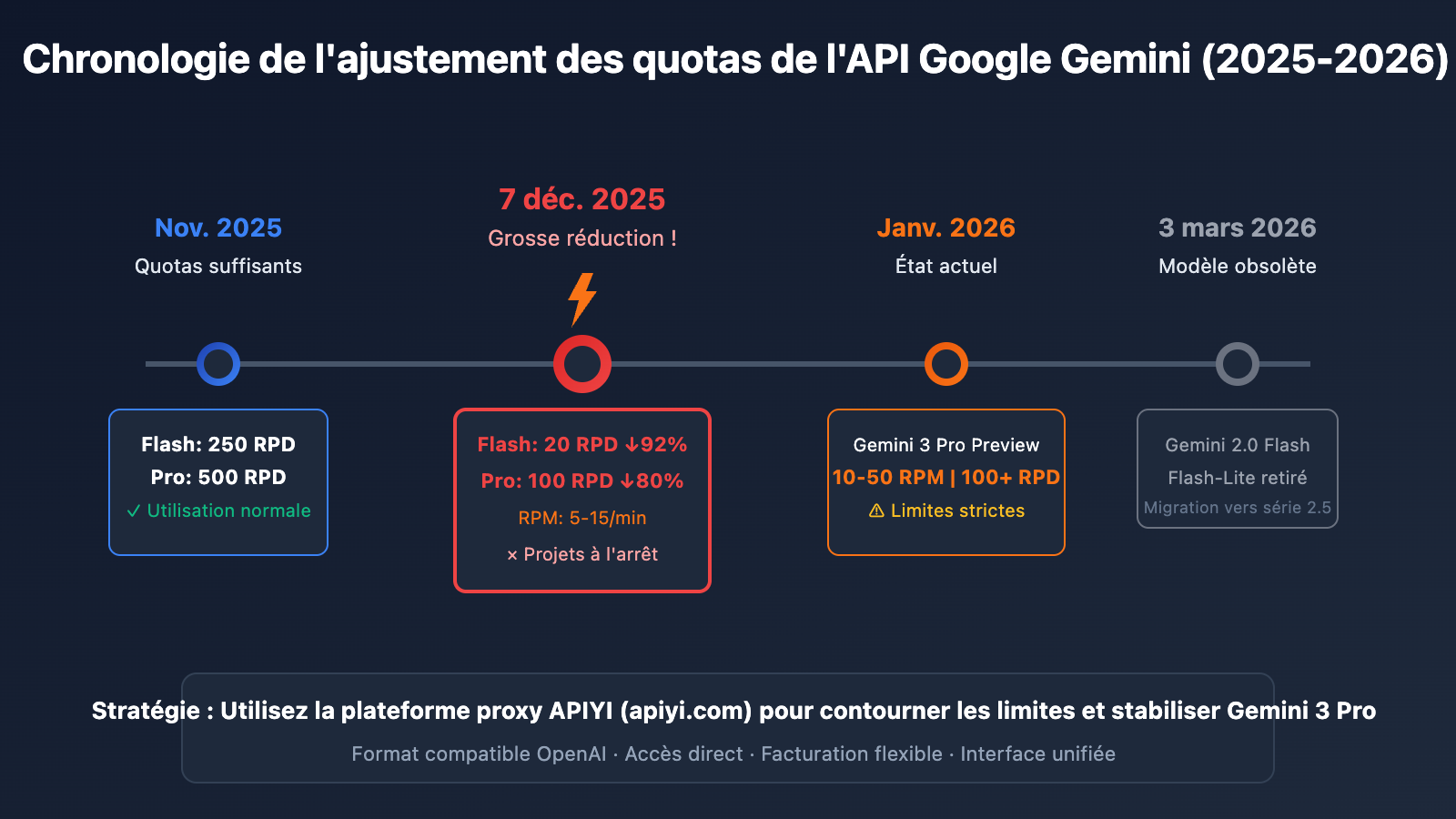
Si vous êtes un utilisateur individuel utilisant Gemini 3 Pro sur AI Studio pour de la génération de texte, vous n'êtes pas seul. Le 7 décembre 2025, Google a discrètement réduit les quotas gratuits de l'API Gemini de 50 % à 92 %. Ce changement a mis à l'arrêt les projets de dizaines de milliers de développeurs dans le monde du jour au lendemain.
Valeur ajoutée de cet article : En lisant ce qui suit, vous comprendrez les raisons réelles de cette réduction de quota, vous découvrirez 5 méthodes pour contourner ces limites de débit, et vous apprendrez comment utiliser Gemini 3 Pro de manière stable via une plateforme de proxy API.

Points clés sur les limites de débit de Gemini 3 Pro
Avant de résoudre le problème, nous devons comprendre les ajustements effectués par Google.
| Élément ajusté | Avant (Nov. 2025) | Après (7 déc. 2025) | Baisse |
|---|---|---|---|
| Modèle Flash RPD | 250 requêtes/jour | 20 requêtes/jour | -92% |
| Modèle Pro RPD | 500 requêtes/jour | 100 requêtes/jour | -80% |
| Modèle Pro RPM | 15 requêtes/minute | 5 requêtes/minute | -67% |
| Gemini 3 Pro Preview | Illimité | 10-50 RPM, 100+ RPD | Nouvelle limite |
Les 4 dimensions des limites de débit de Gemini 3 Pro
Le système de limitation de Google contrôle l'utilisation selon 4 dimensions :
| Dimension de limite | Nom complet | Description | Valeur actuelle (Free Tier) |
|---|---|---|---|
| RPM | Requests Per Minute | Requêtes par minute | 5-15 fois |
| TPM | Tokens Per Minute | Tokens par minute | 250 000 |
| RPD | Requests Per Day | Requêtes par jour | 20-100 fois |
| IPM | Images Per Minute | Images par minute | Pour le multimodal |
🔑 Information clé : En tant que version Preview, Gemini 3 Pro a actuellement des limites d'environ 10-50 RPM et 100+ RPD pour le niveau gratuit, mais en pratique, de nombreux utilisateurs rapportent des restrictions bien plus strictes que ce qui est indiqué dans la documentation.
Pourquoi Google a-t-il réduit les quotas si massivement ?
Selon les annonces officielles de Google, ces ajustements sont dus aux raisons suivantes :
- Explosion de la demande : L'essor des applications IA en 2025 a entraîné un volume d'appels API bien au-delà des prévisions.
- Pression sur l'infrastructure : Les modèles Gemini 2.0/3.0 sont extrêmement gourmands en ressources de calcul.
- Protection de l'expérience utilisateur payante : Priorité donnée à la qualité de service pour les clients payants.
- Ajustement de stratégie commerciale : Inciter les développeurs à migrer vers des forfaits payants.
5 solutions pour les limites de débit de Gemini 3 Pro
Pour résoudre les problèmes de limites de débit (rate limit) sur AI Studio, voici 5 solutions éprouvées :
Solution 1 : Passer à d'autres modèles Gemini
C'est la solution temporaire la plus simple. Différents modèles ont des quotas différents :
| Modèle | RPM | RPD | Scénario recommandé |
|---|---|---|---|
| Gemini 2.5 Flash-Lite | 15 | 1 000 | Premier choix pour les tâches légères |
| Gemini 2.5 Flash | 10 | 500 | Performance équilibrée |
| Gemini 2.5 Pro | 5 | 100 | Raisonnement complexe |
| Gemini 3 Pro Preview | 10-50 | 100+ | Capacités maximales, limites plus strictes |
💡 Astuce pratique : Si votre tâche ne nécessite pas toute la puissance de Gemini 3 Pro, passer à Gemini 2.5 Flash-Lite vous permet de bénéficier d'un quota allant jusqu'à 1 000 RPD (requêtes par jour), ce qui est amplement suffisant pour un usage quotidien.
Solution 2 : Attendre la réinitialisation du quota
Le quota RPD de l'API Gemini est réinitialisé à minuit, heure du Pacifique (PST).
Tableau de correspondance pour la réinitialisation :
- Heure de Paris : 09:00 (été) / 10:00 (hiver)
- Heure de Pékin : 16:00 (été) / 17:00 (hiver)
- Heure de Tokyo : 17:00 (été) / 18:00 (hiver)
Solution 3 : Passer au forfait payant
Si vous avez besoin d'utiliser Gemini 3 Pro de manière stable, passer au forfait payant est la solution recommandée officiellement :
| Niveau | Exigences | RPM | RPD | Coût mensuel moyen |
|---|---|---|---|---|
| Forfait Gratuit | Aucune | 5-15 | 20-100 | 0 $ |
| Tier 1 | Carte de crédit liée | 150-300 | Illimité | Facturation à l'usage |
| Tier 2 | Consommation cumulée > 250 $ + 30 jours | 1 000+ | Illimité | Facturation à l'usage |
Tarification de Gemini 3 Pro :
- Entrée : 2,00 $ / million de tokens (contexte ≤ 200K)
- Sortie : 12,00 $ / million de tokens (contexte ≤ 200K)
- Contexte long (> 200K) : le prix est doublé
Solution 4 : Utiliser une plateforme de relais API (Recommandé)
Pour les utilisateurs individuels et les petites/moyennes équipes, l'utilisation d'une plateforme de relais API est le choix le plus rentable :
# Appel de Gemini 3 Pro via APIYI - Exemple minimaliste
import openai
client = openai.OpenAI(
api_key="votre-cle-apiyi",
base_url="https://api.apiyi.com/v1" # Interface unifiée APIYI
)
response = client.chat.completions.create(
model="gemini-3-pro-preview",
messages=[
{"role": "user", "content": "Veuillez expliquer l'architecture Transformer"}
],
max_tokens=2000
)
print(response.choices[0].message.content)
🚀 Démarrage rapide : Nous recommandons d'utiliser la plateforme APIYI (apiyi.com) pour un accès rapide à Gemini 3 Pro. Cette plateforme propose une interface compatible OpenAI, éliminant les soucis de limites de quota, avec une intégration possible en moins de 5 minutes.
Voir l’exemple de code complet (avec gestion des erreurs)
# Exemple complet d'appel Gemini 3 Pro via APIYI
import openai
from openai import OpenAI
import time
def call_gemini_3_pro(prompt: str, max_retries: int = 3) -> str:
"""
Appelle le modèle Gemini 3 Pro
Args:
prompt: Entrée de l'utilisateur
max_retries: Nombre maximum de tentatives
Returns:
Contenu de la réponse du modèle
"""
client = OpenAI(
api_key="votre-cle-apiyi",
base_url="https://api.apiyi.com/v1" # Interface unifiée APIYI
)
for attempt in range(max_retries):
try:
response = client.chat.completions.create(
model="gemini-3-pro-preview",
messages=[
{
"role": "system",
"content": "Tu es un assistant IA professionnel, réponds en français s'il te plaît."
},
{
"role": "user",
"content": prompt
}
],
max_tokens=4000,
temperature=0.7
)
return response.choices[0].message.content
except openai.RateLimitError as e:
print(f"Requêtes trop fréquentes, attente avant nouvel essai... ({attempt + 1}/{max_retries})")
time.sleep(2 ** attempt) # Backoff exponentiel
except openai.APIError as e:
print(f"Erreur API : {e}")
raise
raise Exception("Nombre de tentatives épuisé")
# Exemple d'utilisation
if __name__ == "__main__":
result = call_gemini_3_pro("Explique le fonctionnement des grands modèles de langage en 100 mots")
print(result)
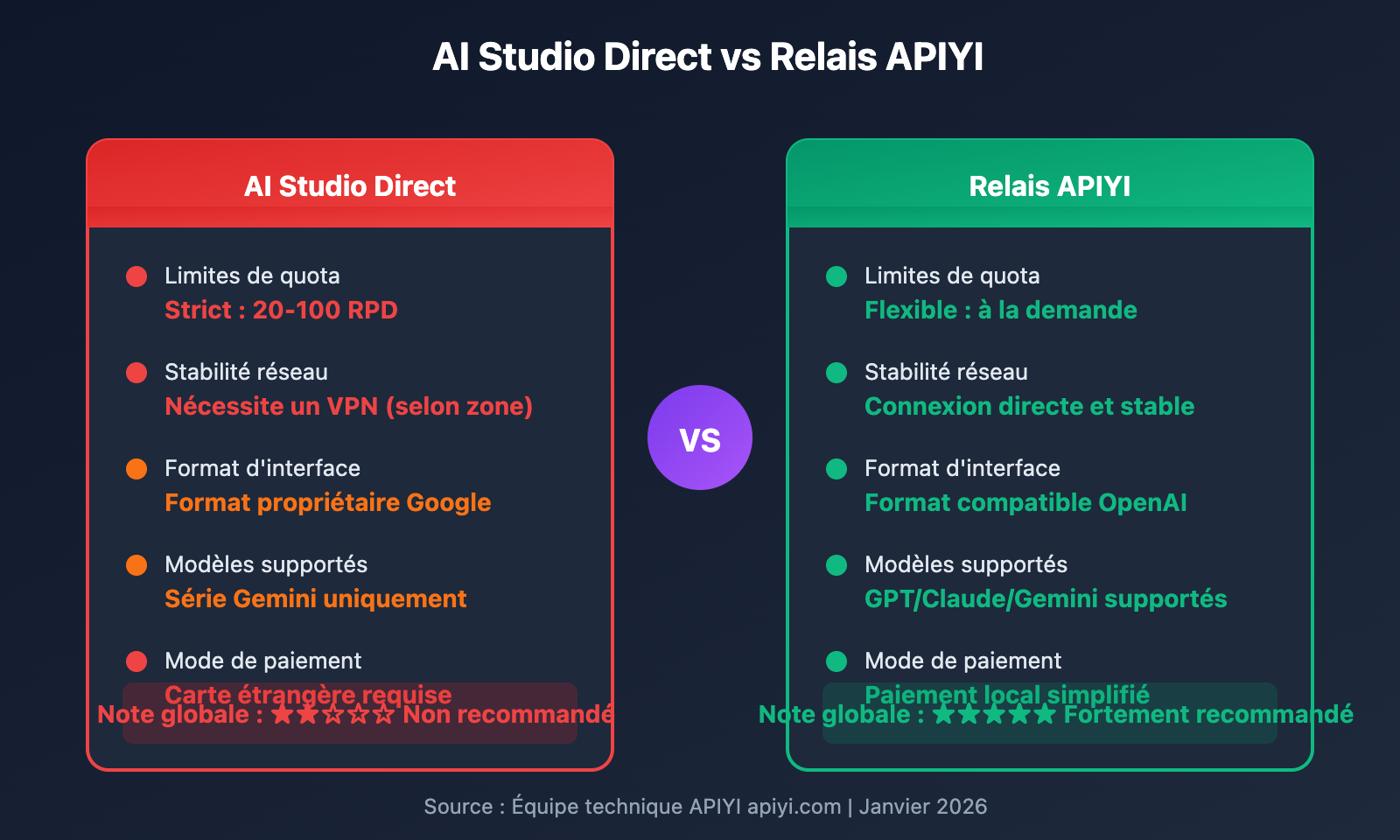
Avantages de l'utilisation d'une plateforme de relais API :
| Élément de comparaison | AI Studio Direct | Relais APIYI |
|---|---|---|
| Limites de quota | Strictes (20-100 RPD) | Flexibles, selon l'usage |
| Stabilité réseau | Accès spécial parfois requis | Connexion directe et rapide |
| Format d'interface | Format propriétaire Google | Format compatible OpenAI |
| Changement de modèle | Série Gemini uniquement | Support de GPT / Claude / Gemini, etc. |
| Mode de paiement | Carte de crédit étrangère | Options de paiement locales simplifiées |
Solution 5 : Planifier rationnellement votre stratégie de requêtes
Si vous devez impérativement utiliser le forfait gratuit, les stratégies suivantes peuvent maximiser l'utilisation de votre quota :
1. Traitement par lots (Batching)
# Combiner plusieurs petites questions en une seule requête
combined_prompt = """
Veuillez répondre aux questions suivantes dans l'ordre :
1. Quelle est la différence entre une liste et un tuple en Python ?
2. Qu'est-ce qu'un décorateur ?
3. Comment implémenter le pattern Singleton ?
"""
2. Utilisation d'un mécanisme de cache
import hashlib
import json
# Cache local simple
cache = {}
def cached_query(prompt: str) -> str:
cache_key = hashlib.md5(prompt.encode()).hexdigest()
if cache_key in cache:
return cache[cache_key]
result = call_gemini_3_pro(prompt) # Appel réel à l'API
cache[cache_key] = result
return result
3. Utilisation en heures creuses
- Évitez les heures de pointe (heures de bureau aux États-Unis).
- Profitez de la réinitialisation du quota juste après minuit, heure du Pacifique.
FAQ sur les limites de débit de Gemini 3 Pro
Q1 : Pourquoi ai-je déclenché une limite de débit après seulement quelques messages ?
C'est un problème courant suite à l'ajustement des quotas de décembre 2025. Actuellement, les limites de la version gratuite (Free Tier) de Gemini 3 Pro Preview sont très strictes, parfois même inférieures aux valeurs indiquées dans la documentation officielle. Certains utilisateurs signalent un RPM (requêtes par minute) réel correspondant à la moitié de ce qui est annoncé.
Solution : Si vous avez besoin d'une utilisation continue, il est conseillé de passer par une plateforme intermédiaire comme APIYI (apiyi.com). Cela permet d'éviter de buter directement sur les restrictions du forfait gratuit de Google.
Q2 : Le forfait payant résout-il totalement le problème des limites ?
En passant au forfait payant (Tier 1), le RPM augmente pour atteindre 150-300, et les limites RPD (requêtes par jour) sont pratiquement supprimées. Cependant, notez que :
- Cela nécessite une carte de crédit internationale.
- La facturation se fait à l'usage (par Token).
- Les tarifs de Gemini 3 Pro sont assez élevés (entre 2 et 12 $ par million de Tokens).
Pour un usage personnel ou d'apprentissage, utiliser une plateforme comme APIYI (apiyi.com) peut s'avérer plus économique, tout en supportant les méthodes de paiement locales.
Q3 : L’utilisation d’un proxy API est-elle sûre ?
Choisir une plateforme de proxy API reconnue est tout à fait sûr. En prenant APIYI comme exemple :
- Le contenu des conversations n'est pas stocké.
- Les transferts sont sécurisés via HTTPS.
- Des journaux d'appels API complets sont fournis.
Il est recommandé de privilégier des plateformes ayant une bonne réputation et une certaine ancienneté.
Q4 : Quelle est la différence entre Gemini 3 Pro et 2.5 Pro ?
| Comparaison | Gemini 3 Pro | Gemini 2.5 Pro |
|---|---|---|
| Capacité de raisonnement | Maximale | Élevée |
| Longueur de contexte | 200K+ | 1M |
| Capacités multimodales | Renforcées | Standards |
| Quota gratuit | Très strict | 100 RPD |
| Tarification | 2-12 $/M | 1,25-5 $/M |
Si votre tâche ne nécessite pas les toutes dernières capacités de pointe, Gemini 2.5 Pro offre un meilleur rapport qualité-prix.
Q5 : Les quotas vont-ils encore changer en 2026 ?
Selon les annonces de Google, les modèles Gemini 2.0 Flash et Flash-Lite seront abandonnés le 3 mars 2026. Conseils :
- Migrez dès que possible vers la série Gemini 2.5.
- Suivez les actualités sur le forum des développeurs Google AI.
- Envisagez d'utiliser des plateformes multi-modèles comme APIYI (apiyi.com) pour basculer rapidement d'un modèle à l'autre.
Comparaison des solutions aux limites de débit de Gemini 3 Pro
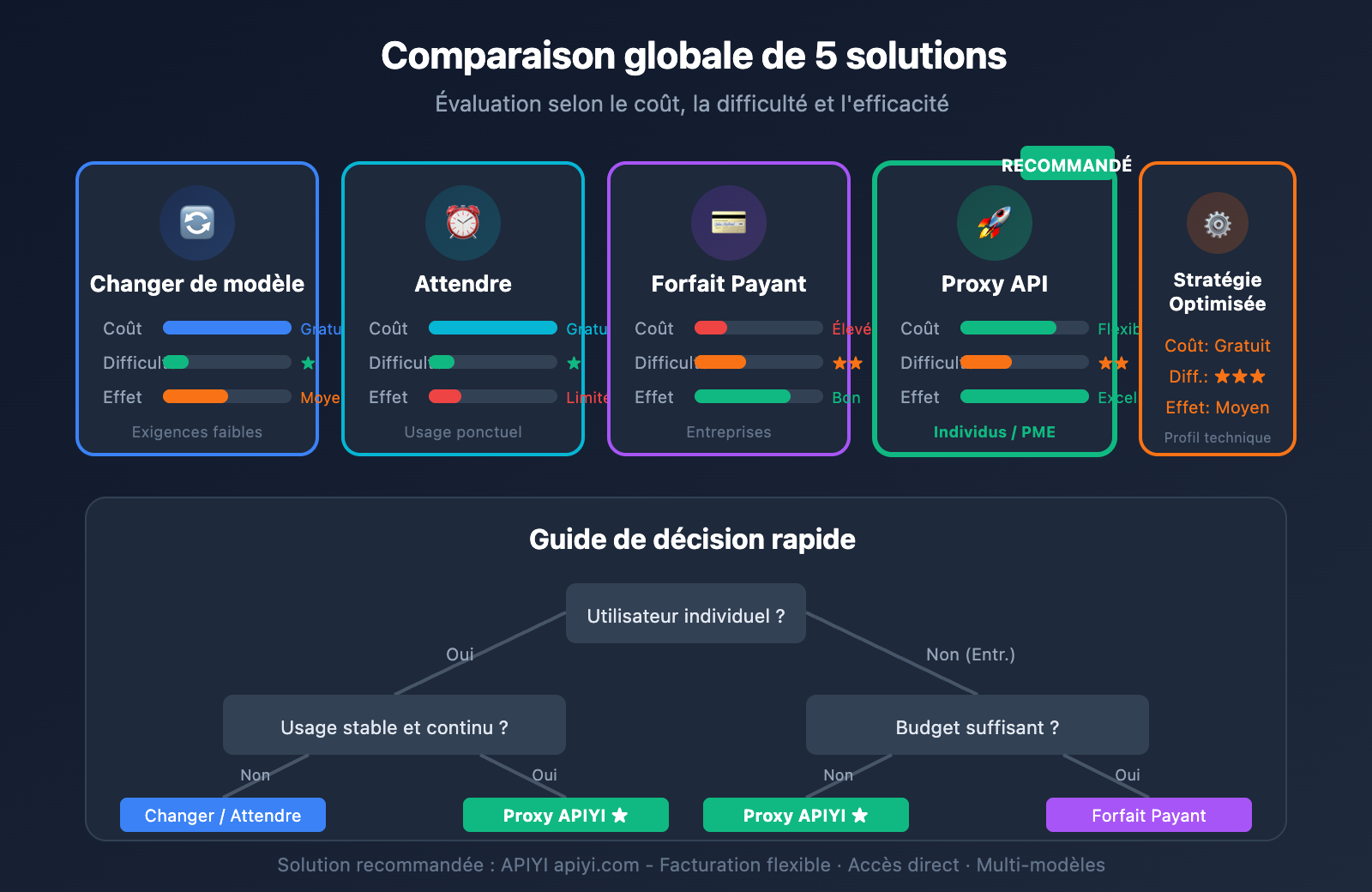
| Solution | Coût | Difficulté | Effet | Scénario recommandé |
|---|---|---|---|---|
| Changer de modèle | Gratuit | ⭐ | Moyen | Exigences faibles |
| Attendre | Gratuit | ⭐ | Limité | Usage ponctuel |
| Forfait Payant | Élevé | ⭐⭐ | Bon | Entreprises |
| Proxy API | Flexible | ⭐⭐ | Très bon | Individus / PME |
| Optimiser les requêtes | Gratuit | ⭐⭐⭐ | Moyen | Profil technique |
💡 Conseil de choix : Pour les utilisateurs individuels ou étudiants, nous recommandons de tester en priorité le changement de modèle ou l'utilisation d'une plateforme de proxy API. APIYI (apiyi.com) propose une facturation flexible à la demande, vous permettant de ne plus vous soucier des limites de quotas de manière efficace.
Résumé
L'erreur « You've reached your rate limit » sur AI Studio provient de la réduction massive des quotas du niveau gratuit effectuée par Google en décembre 2025. Les 5 solutions présentées dans cet article ont chacune leurs avantages et leurs inconvénients :
- Changer de modèle – Le plus simple, idéal pour les besoins temporaires.
- Attendre la réinitialisation – Gratuit, mais peu efficace.
- Passer au forfait payant – Très efficace, mais le coût est élevé.
- Relais API (Proxy) – Excellent rapport qualité-prix, recommandé pour les utilisateurs individuels.
- Optimiser les stratégies – Nécessite des compétences techniques.
Pour la plupart des utilisateurs individuels et étudiants, nous recommandons d'utiliser APIYI (apiyi.com) pour résoudre rapidement les problèmes de limite de débit. Cette plateforme prend en charge l'appel unifié des principaux modèles tels que Gemini 3 Pro, GPT-4 et Claude 3.5, tout en offrant un accès stable et des options de paiement flexibles.
Références
-
Google AI – Documentation officielle sur les limites de débit (Rate Limits)
- Lien :
ai.google.dev/gemini-api/docs/rate-limits - Description : Explications officielles sur les limites de débit de l'API Gemini.
- Lien :
-
Google AI Developers Forum – Discussions sur les limites de débit
- Lien :
discuss.ai.google.dev/t/youve-reached-your-rate-limit/35201 - Description : Discussions de la communauté concernant les limites de débit.
- Lien :
-
Tarification officielle de l'API Gemini
- Lien :
ai.google.dev/gemini-api/docs/pricing - Description : Informations sur les tarifs et les quotas pour chaque modèle.
- Lien :
📝 Auteur : Équipe APIYI
🔗 Support technique : APIYI (apiyi.com) – Votre plateforme relais tout-en-un pour les API de grands modèles de langage.
📅 Date de mise à jour : 24 janvier 2026