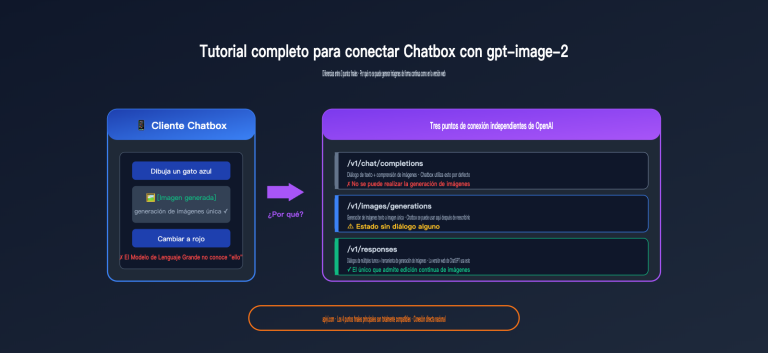
Si invocas la interfaz de Gemini 3 Pro Image para generar imágenes y muestras directamente la primera imagen que recibes, el resultado suele verse "extraño": composición desordenada, detalles toscos o incluso partes de la imagen cortadas. No es que el modelo haya perdido calidad, es que estás tomando la imagen incorrecta. Lo más probable es que la primera sea el "borrador de pensamiento" del modelo, y la versión final sea la última de la respuesta.
Este artículo, basado en la documentación oficial de Google AI, desglosa sistemáticamente la estructura de respuesta del mecanismo de pensamiento de imágenes de Gemini 3. Explicamos por qué una invocación puede devolver de 2 a 3 imágenes, cómo identificar la imagen final con precisión mediante el campo part.thought y la firma thought_signature, y proporcionamos el código de extracción correcto en Python, Node.js y cURL. Todos los ejemplos se basan en el proxy transparente de APIYI (apiyi.com): la capa de servicio proxy preserva intacta la estructura de respuesta nativa de Gemini; los desarrolladores solo necesitan procesarla siguiendo las especificaciones oficiales.
Principio fundamental del mecanismo de pensamiento de imágenes de Gemini 3
Antes de ponernos a programar, aclaremos el problema fundamental: "¿Por qué una sola llamada devuelve varias imágenes?".
Por qué el pensamiento de imágenes de Gemini 3 no se puede desactivar por defecto
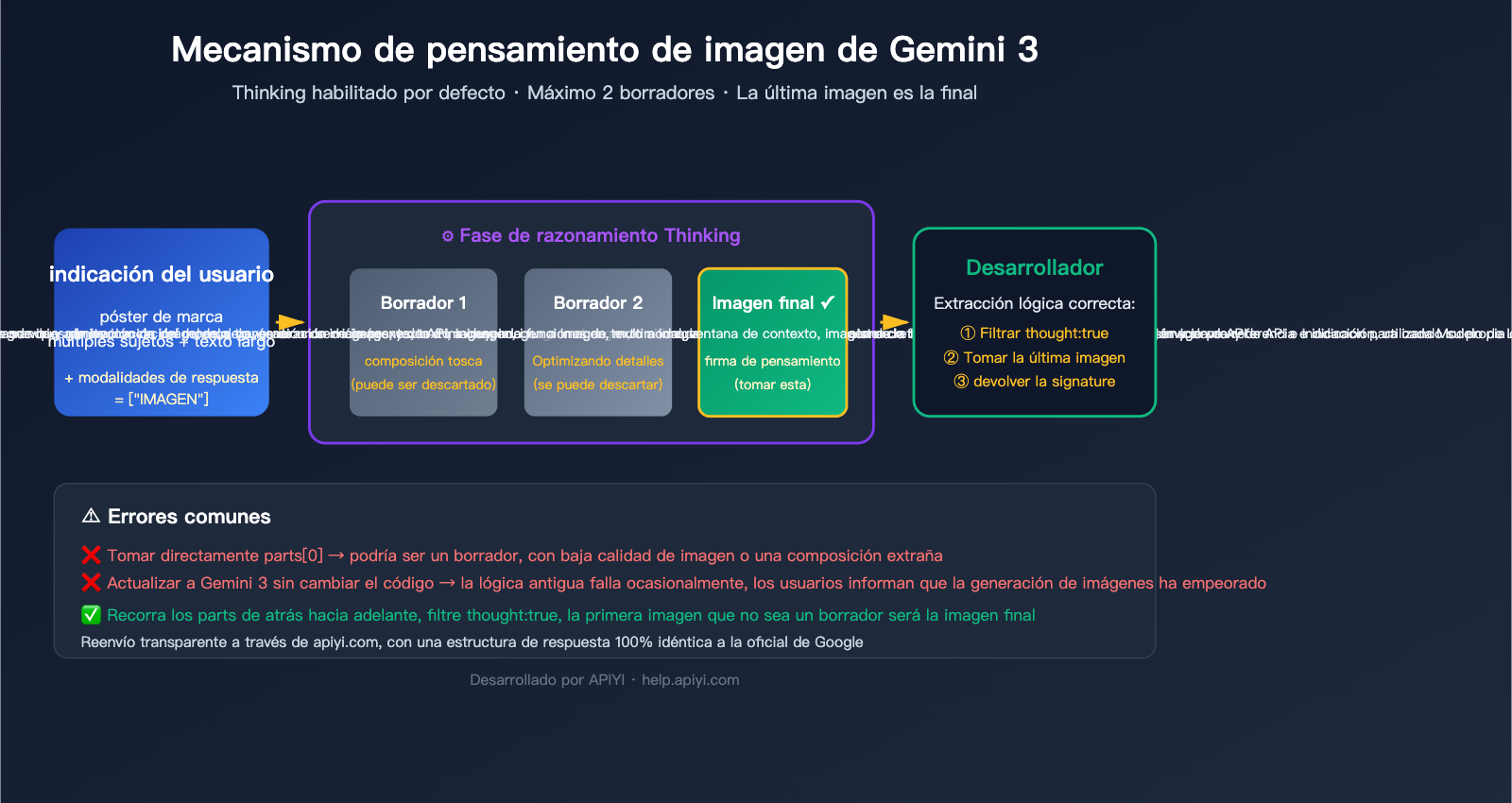
Google ha introducido en gemini-3-pro-image-preview (nombre comercial Nano Banana Pro) un mecanismo de "Thinking" (pensamiento) que proviene de la misma raíz que los modelos de texto de Gemini. Antes de generar la imagen final, el modelo utiliza hasta 2 imágenes temporales para experimentar con la composición, el diseño y el renderizado de texto, similar a como un diseñador humano hace bocetos antes de entregar el trabajo final.
La documentación oficial confirma 3 hechos clave:
| Hecho | Explicación |
|---|---|
| Activado por defecto, imposible desactivar | La función Thinking se aplica a nivel de API, no existen parámetros para desactivarla |
| Hasta 2 imágenes temporales | El modelo puede generar hasta 2 borradores de pensamiento, no siempre ocurre en cada llamada |
| La última es la imagen final | La última imagen de la fase de Thinking es la que constituye el resultado de renderizado final |
| Los Tokens de pensamiento se cobran | Aunque no solicites devolver el contenido del pensamiento, los tokens de pensamiento se consumen y se facturan |
En otras palabras, recibir múltiples imágenes es el comportamiento nativo de la respuesta; no es un bug, es el diseño. La clave no es "cómo desactivarlo", sino "cómo elegir correctamente solo la imagen final".
🎯 Entendimiento de la arquitectura: El mecanismo de pensamiento de imágenes de Gemini 3 comparte el mismo motor de razonamiento subyacente que el modelo de texto Gemini 3 Pro. Esto explica por qué Nano Banana Pro supera significativamente a las versiones anteriores en renderizado de texto largo y consistencia entre múltiples sujetos. Al realizar la llamada a través de APIYI (apiyi.com), todos los comportamientos de thinking son idénticos a los de conectarse directamente a Google; la capa de servicio proxy no elimina ningún dato de pensamiento.
Repaso de los errores más comunes de los clientes
El escenario más típico donde los usuarios fallan es el siguiente:
Llamada API → Recibir respuesta → Encontrar array 'parts' → Tomar directamente la imagen de 'parts[0]' → Mostrar al usuario
Este pseudocódigo funcionaba perfectamente en la era del Nano Banana antiguo (Gemini 2.5 Flash Image), ya que esa versión devolvía por defecto una sola imagen. Al actualizar a Gemini 3 Pro Image, el mismo código tomará el "borrador de pensamiento" como el producto final, provocando que el usuario vea un "producto a medio terminar" con una composición extraña que no cumple con la indicación (prompt).
Este error es especialmente difícil de detectar porque:
- No siempre ocurre: Con indicaciones simples, el modelo puede no activar el proceso de pensamiento y devolver solo una imagen.
- No se producen errores: La estructura de la respuesta es válida, por lo que acceder a
parts[0]no lanza excepciones. - Hay imagen, pero de mala calidad: El usuario cree que el modelo "no es bueno", cuando en realidad el problema está en la selección de la imagen.
title: Detalle de la estructura de respuesta de razonamiento de imagen de Gemini 3
Entender qué puede devolver una llamada a la API es la premisa básica para manejarla correctamente.
El array de partes en una respuesta completa
Cuando se activa el razonamiento (thinking) de Gemini 3 Pro Image, response.candidates[0].content.parts puede verse así:
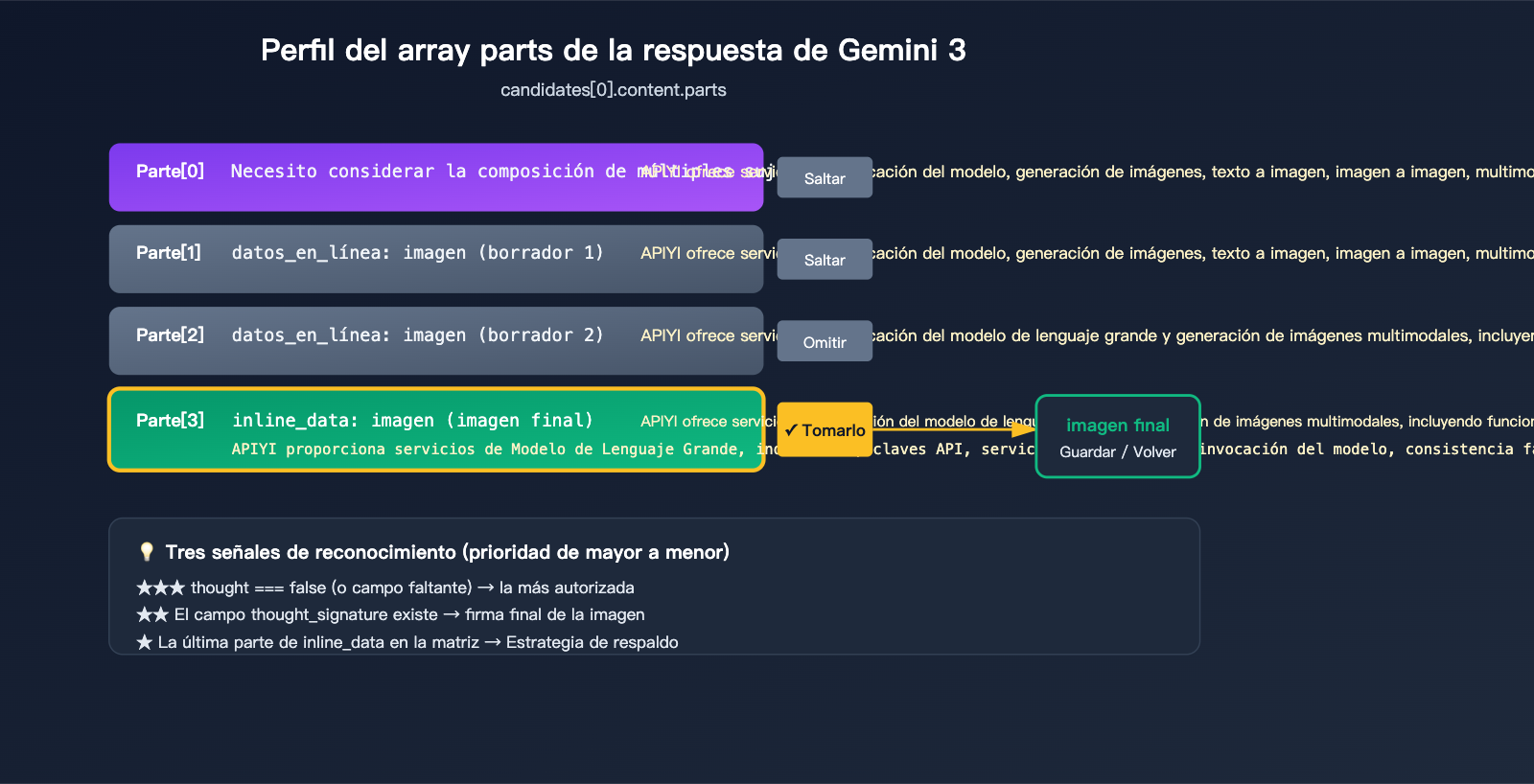
candidates[0].content.parts = [
{ text: "Necesito considerar la composición...", thought: true },
{ inline_data: { mime_type: "image/png", data: "..." }, thought: true }, // Borrador 1
{ inline_data: { mime_type: "image/png", data: "..." }, thought: true }, // Borrador 2
{ inline_data: { mime_type: "image/png", data: "..." }, thought_signature: "..." } // Imagen final
]
Malinterpretar este array es la fuente de la mayoría de los errores. Sigue estas 3 reglas y escribirás código robusto.
3 señales oficiales para identificar la imagen final
Google proporciona 3 señales para identificar la imagen definitiva, úsalas según su prioridad:
| Prioridad | Señal de identificación | Explicación | Confiabilidad |
|---|---|---|---|
| ★★★ | part.thought === false (o campo ausente) |
Etiquetado explícito como contenido que no es razonamiento | Máxima |
| ★★ | Presencia del campo thought_signature |
Solo la imagen final lleva la firma, los borradores no | Alta |
| ★ | El último inline_data del array |
Documentación oficial confirma "la última imagen es la final" | Último recurso |
La forma más segura es combinar estos métodos: prioriza el campo thought, si no existe, usa thought_signature como respaldo, y si nada funciona, toma el último inline_data.
Diferencias en thinking_level de Gemini 3.1 Flash
Ten en cuenta que el comportamiento de los modelos de imagen de Gemini no siempre es consistente:
| Modelo | Razonamiento (Thinking) predeterminado | thinking_level configurable |
Caso de uso |
|---|---|---|---|
gemini-3-pro-image-preview |
Siempre activado | ❌ No ajustable | Alta fidelidad, activos profesionales |
gemini-3-flash-image |
minimal por defecto | ✅ minimal / high | Interacción en tiempo real, generación masiva |
gemini-2.5-flash-image |
Sin razonamiento | – | Compatibilidad con versiones antiguas |
Gemini 3.1 Flash permite ajustar manualmente el thinking_level para obtener una composición más detallada o reducirlo a "minimal" para obtener una respuesta más rápida; esta flexibilidad no existe en la versión Pro.
🎯 Sugerencia de selección: Para funciones de generación de imágenes en productos orientados al consumidor (C-end), recomendamos usar
gemini-3-flash-image+thinking_level=minimal(más rápido y económico) por defecto, y cambiar agemini-3-pro-image-previewcuando el usuario seleccione "modo de alta calidad". En la plataforma APIYI (apiyi.com), puedes alternar entre ambos modelos sin problemas usando la misma clave API ybase_url.
Código para manejar correctamente el razonamiento de imagen de Gemini 3
Teoría clara, vamos al código. Los siguientes ejemplos se basan en el reenvío transparente de APIYI (apiyi.com): tu código que originalmente se conectaba a Google AI Studio solo necesita cambiar la base_url por la dirección de APIYI y tu api_key por la de APIYI; la lógica de procesamiento de la respuesta se mantiene intacta.
Escritura correcta con SDK oficial de Python
from google import genai
client = genai.Client(
api_key="sk-your-apiyi-key",
http_options={"base_url": "https://vip.apiyi.com/v1beta"}
)
response = client.models.generate_content(
model="gemini-3-pro-image-preview",
contents="Un Shiba Inu estilo cyberpunk, bajo un letrero de neón, alta definición 4K",
config={"response_modalities": ["IMAGE"]}
)
# ✅ Correcto: filtra todas las partes de pensamiento (thought), guardando solo la imagen final
for part in response.parts:
if getattr(part, "thought", False):
continue # Saltar borradores de pensamiento
if hasattr(part, "as_image"):
image = part.as_image()
if image:
image.save("final_output.png")
break # La primera imagen que no es de pensamiento es la definitiva
Mal ejemplo (código típico donde los usuarios fallan):
# ❌ Error: tomar la primera imagen directamente puede devolver un borrador de pensamiento
image_part = response.parts[0]
image_bytes = image_part.inline_data.data
# La imagen generada podría ser un trabajo incompleto
Escritura correcta en Node.js / TypeScript
import { GoogleGenAI } from "@google/genai";
const ai = new GoogleGenAI({
apiKey: process.env.APIYI_KEY,
httpOptions: { baseUrl: "https://vip.apiyi.com/v1beta" }
});
const response = await ai.models.generateContent({
model: "gemini-3-pro-image-preview",
contents: "Un Shiba Inu estilo cyberpunk, bajo un letrero de neón, alta definición 4K",
config: { responseModalities: ["IMAGE"] }
});
const parts = response.candidates?.[0]?.content?.parts ?? [];
// ✅ Recorre desde el final, la primera imagen que no es 'thought' es la final
let finalImage: string | null = null;
for (let i = parts.length - 1; i >= 0; i--) {
const p = parts[i];
if (p.thought === true) continue;
if (p.inlineData?.mimeType?.startsWith("image/")) {
finalImage = p.inlineData.data;
break;
}
}
if (finalImage) {
fs.writeFileSync("final.png", Buffer.from(finalImage, "base64"));
}
Versión de línea de comandos (cURL + jq)
Si realizas la llamada en un script de shell, puedes usar jq para filtrar:
curl -sS https://vip.apiyi.com/v1beta/models/gemini-3-pro-image-preview:generateContent \
-H "x-goog-api-key: $APIYI_KEY" \
-H "content-type: application/json" \
-d '{
"contents": [{
"parts": [{"text": "Un Shiba Inu estilo cyberpunk"}]
}],
"generationConfig": {"responseModalities": ["IMAGE"]}
}' | jq -r '
.candidates[0].content.parts
| map(select(.thought != true))
| map(select(.inlineData.mimeType | startswith("image/")))
| last.inlineData.data
' | base64 -d > final.png
Esta expresión jq hace tres cosas: filtra thought: true, conserva solo el tipo MIME de imagen y toma la last (última), cumpliendo perfectamente con las 3 reglas oficiales.
🎯 Puntos de revisión de código: Durante el code review, al ver código que recorre respuestas de imagen de Gemini, asegúrate de que exista el filtro de
thought. Recomendamos encapsular una función de utilidad llamadaextractFinalImage()dentro de tu equipo; así, todo el código de negocio solo llamará a esta función, evitando errores dispersos. Si accedes a través de APIYI (apiyi.com), puedes probar este código localmente y reutilizarlo directamente en producción.
Temas avanzados sobre el razonamiento visual de Gemini 3
La edición en múltiples pasos requiere devolver thought_signature
Nano Banana Pro admite la "edición continua" (por ejemplo, el usuario dice "cambia el fondo a una playa" y luego "haz que la expresión del perro sea feliz"), pero la documentación oficial exige explícitamente devolver el thought_signature de la ronda anterior en cada paso. De lo contrario, el modelo no podrá continuar con el contexto de razonamiento previo y la calidad caerá drásticamente.
La forma correcta de escribir el código para múltiples rondas:
# Primera ronda
response1 = client.models.generate_content(
model="gemini-3-pro-image-preview",
contents="Un perro Shiba Inu corriendo en un parque"
)
# Extraer el objeto part de la imagen final (incluyendo thought_signature)
final_part = next(
p for p in response1.parts
if not getattr(p, "thought", False) and hasattr(p, "inline_data")
)
# Segunda ronda: añadir todo el final_part de vuelta al historial
response2 = client.models.generate_content(
model="gemini-3-pro-image-preview",
contents=[
{"role": "user", "parts": [{"text": "Un perro Shiba Inu corriendo en un parque"}]},
{"role": "model", "parts": [final_part]}, # Incluye thought_signature
{"role": "user", "parts": [{"text": "Cambia el fondo a un atardecer en la playa"}]}
]
)
Visualización del proceso de razonamiento (para depuración)
Si quieres ver qué es lo que el modelo "está pensando", puedes activar include_thoughts:
from google.genai import types
response = client.models.generate_content(
model="gemini-3-pro-image-preview",
contents="Prompt complejo para póster publicitario de marca...",
config=types.GenerateContentConfig(
response_modalities=["IMAGE"],
thinking_config=types.ThinkingConfig(
include_thoughts=True
)
)
)
# Imprimir el proceso de pensamiento
for part in response.parts:
if getattr(part, "thought", False):
if part.text:
print(f"[Razonamiento] {part.text}")
elif hasattr(part, "as_image"):
img = part.as_image()
img.save(f"borrador_{id(part)}.png") # Guardar borrador
Esto es extremadamente útil al depurar por qué un resultado no es el esperado: observar los borradores permite deducir qué parte del prompt malinterpretó el modelo.

Lógica de facturación de los tokens de razonamiento (thinking tokens)
La facturación de Gemini 3 Pro Image requiere que los desarrolladores presten especial atención:
| Tipo de Token | Precio (por millón) | ¿Se genera obligatoriamente? |
|---|---|---|
| Prompt de entrada | $2 | ✅ Sí |
| Salida de imagen/texto | $12 | ✅ Sí |
| Razonamiento (Thinking) | Incluido en tokens de salida | ✅ Obligatorio, no desactivable |
Esto significa que, incluso si solo quieres la imagen final y no te importa el proceso de razonamiento, los tokens de pensamiento se generarán y se cobrarán. Lo único que puedes ahorrar es el envío de la información de pensamiento hacia ti (a través del parámetro include_thoughts), pero no puedes evitar que el modelo ejecute el razonamiento.
🎯 Sugerencia de optimización de costes: Para escenarios sencillos (como generar imágenes de productos o ilustraciones), utiliza
gemini-3-flash-image+thinking_level=minimal; el coste es significativamente menor que la versión Pro. Para escenarios complejos (consistencia entre múltiples sujetos, renderizado de texto de alta fidelidad), opta por el modelo Pro. Recomendamos activar el monitoreo de uso a través de APIYI (apiyi.com) para comparar la relación calidad/precio de ambos modelos en tu escenario de negocio antes de decidir tu configuración de producción.
Solución de problemas en el razonamiento visual de Gemini 3
Problema 1: Obtener constantemente imágenes de baja calidad
Pasos de diagnóstico:
# Imprimir el campo thought de todos los parts
for i, part in enumerate(response.parts):
is_thought = getattr(part, "thought", False)
has_image = hasattr(part, "inline_data")
has_sig = hasattr(part, "thought_signature")
print(f"Part {i}: thought={is_thought}, image={has_image}, signature={has_sig}")
Si en la salida hay varios parts con image=True, es el caso típico de "devolución de múltiples imágenes". Verifica si tu código está tomando el part con el índice incorrecto.
Problema 2: El campo 'thought' no aparece en la estructura de respuesta
Posible causa: Si utilizas el JSON original de la REST API, la nomenclatura está en camelCase (thought), pero en algunas versiones del SDK el campo podría convertirse a snake_case. Debes asegurar compatibilidad con ambos:
def is_thought(part):
return getattr(part, "thought", None) or \
getattr(part, "is_thought", None) or \
(isinstance(part, dict) and part.get("thought", False))
Problema 3: Guardar todas las imágenes (para depuración)
La forma completa recomendada por el equipo oficial para recorrer la respuesta:
for i, part in enumerate(response.parts):
if not hasattr(part, "inline_data"):
continue
is_draft = getattr(part, "thought", False)
suffix = "draft" if is_draft else "final"
filename = f"gemini_output_{suffix}_{i}.png"
with open(filename, "wb") as f:
f.write(part.inline_data.data)
print(f"Guardado: {filename}")
Adaptación a escenarios empresariales reales con el razonamiento visual de Gemini 3
Más allá de la teoría y el código base, existen detalles importantes que considerar según el escenario empresarial.
Escenario 1: Visualización directa de imágenes generadas en el frontend web
Cuando el frontend recibe la imagen en base64, debe convertirla al formato data:image/png;base64,xxx para mostrarla. Evita filtrar el proceso de pensamiento (thought) en el frontend: deja que el backend devuelva un resultado limpio, de lo contrario, el frontend tendría que gestionar la estructura de respuesta de Gemini:
// ❌ No recomendado: el frontend procesa la respuesta bruta de Gemini
const parts = await apiCall();
parts.forEach(p => {
if (!p.thought) showImage(p.inlineData.data);
});
// ✅ Recomendado: el backend filtra los datos y el frontend solo consume la imagen final
// El backend de la API devuelve: { "image": "base64-string" }
const { image } = await fetch("/api/generate").then(r => r.json());
imgEl.src = `data:image/png;base64,${image}`;
Escenario 2: Generación + Almacenamiento en OSS / CDN
Al guardar imágenes generadas por lotes en un almacenamiento de objetos, utiliza un hash para evitar escrituras duplicadas:
import hashlib, base64
def save_to_oss(bucket, base64_data):
binary = base64.b64decode(base64_data)
fname = f"gemini3/{hashlib.md5(binary).hexdigest()}.png"
bucket.put_object(fname, binary)
return fname
final_b64 = extract_final_image(response)
if final_b64:
url = save_to_oss(my_bucket, final_b64)
Asegúrate de subir solo la imagen final; los borradores de razonamiento solo contaminarán tu OSS y desperdiciarán espacio de almacenamiento.
Escenario 3: Manejo correcto de la respuesta en streaming
Gemini 3 admite streaming para imágenes; los borradores de pensamiento llegan primero y la imagen final después. En escenarios de flujo, se recomienda la técnica de "sobrescritura progresiva":
stream = client.models.generate_content_stream(
model="gemini-3-pro-image-preview",
contents="..."
)
current_image = None
for chunk in stream:
for part in chunk.parts:
if getattr(part, "thought", False):
continue # Saltar el borrador
if hasattr(part, "inline_data") and part.inline_data:
current_image = part.inline_data.data # Sobrescribir continuamente, mantener la última
# Al finalizar el stream, current_image contiene la imagen final
🎯 Optimización del streaming: Para mejorar la experiencia de usuario, puedes mostrar los borradores de pensamiento en el frontend como una "vista previa de carga" y reemplazarlos cuando llegue la imagen final. Esta "presentación progresiva" es muy popular en productos para el consumidor final. APIYI (apiyi.com) es totalmente compatible con el protocolo de streaming SSE de Gemini, ofreciendo una experiencia idéntica a la conexión directa.
Relación entre el razonamiento visual de Gemini 3 y los indicadores de negocio
Datos cuantitativos de mejora de calidad
Según la información oficial de Google y las pruebas de la comunidad, la calidad de las imágenes mejora significativamente al activar el razonamiento (thinking):
| Indicador | Gemini 2.5 Flash Image | Gemini 3 Pro Image (thinking) | Mejora |
|---|---|---|---|
| Precisión de renderizado de texto largo | ~70% | ~95% | +35% |
| Consistencia de múltiples sujetos (5 personas) | ~60% | ~90% | +50% |
| Seguimiento de composición compleja | ~75% | ~92% | +22% |
| Tasa de utilidad de la primera imagen | ~80% | ~95% | +18% |
El costo a pagar es un aumento del 40-80% en el tiempo de respuesta y un incremento del 20-40% en el consumo de tokens. ¿Vale la pena? Depende de tu caso de uso:
- Material de diseño profesional, publicidad: La mejora en la calidad compensa el costo adicional; recomendado encarecidamente.
- Generación de imágenes por usuarios (UGC), contenido masivo: Se sugiere usar Flash con
thinking_level=minimalpara un buen equilibrio. - Interacción en tiempo real, chatbots: Prioriza la velocidad de respuesta, Flash es más adecuado.
🎯 Sugerencia para pruebas A/B: No elijas el modelo basándote en la intuición. Te sugerimos crear claves API independientes para ambos modelos en APIYI (apiyi.com), distribuir el tráfico al 50/50 y comparar los indicadores de satisfacción del usuario (tasa de likes, tasa de regeneración, tasa de conversión) tras 7 días. Los datos te dirán qué modelo es el que realmente vale la inversión.
FAQ sobre el pensamiento en imágenes de Gemini 3
P1: ¿Por qué mi código de generación de imágenes empezó a dar "resultados a medio terminar" ocasionalmente tras actualizar a Gemini 3?
Porque Gemini 3 Pro Image tiene activado el "pensamiento" (thinking) por defecto, por lo que la respuesta puede contener de 1 a 3 imágenes. Es muy probable que tu código anterior estuviera tomando parts[0], y esa primera parte puede ser un borrador. Solución: modifica el código para filtrar thought: true y tomar siempre la última imagen que no sea de pensamiento.
P2: ¿La plataforma APIYI también tiene este comportamiento de "pensamiento" en la interfaz de imágenes de Gemini 3?
Es exactamente igual. APIYI (apiyi.com) utiliza una arquitectura de reenvío transparente; el thought, thought_signature e inline_data de la respuesta nativa de Gemini se transmiten tal cual, sin eliminar ni reescribir nada. Puedes apuntar tu código que antes conectaba directamente con Google AI Studio a APIYI sin cambiar ni una sola línea, la estructura de la respuesta es totalmente compatible.
P3: ¿Existe algún parámetro para forzar que solo devuelva la imagen final?
No. La documentación oficial es clara: "This feature is enabled by default and cannot be disabled in the API" (esta función está activada por defecto y no se puede desactivar en la API). Sin embargo, puedes establecer include_thoughts: false para que la respuesta no contenga el texto del pensamiento, pero los borradores de imágenes aún podrían existir, por lo que el filtrado a nivel de código sigue siendo obligatorio.
P4: El "pensamiento" ha aumentado la latencia de la respuesta, ¿cómo puedo optimizarlo?
Hay tres caminos:
- En escenarios sencillos, cambia a
gemini-3-flash-image+thinking_level=minimal. - Si la necesidad no es compleja, escribe una indicación más precisa para evitar que el modelo "piense en exceso".
- Utiliza la respuesta en flujo (streaming) para que el usuario pueda ver el borrador del proceso de pensamiento mientras la imagen final llega al final.
P5: ¿Cómo puedo saber si realmente ocurrió un proceso de "pensamiento" en la respuesta?
Comprueba el campo response.usage_metadata.thoughts_token_count. Si es mayor que 0, significa que el proceso de pensamiento se activó efectivamente. Este valor también te ayudará a estimar el coste de inferencia real.
P6: ¿Puedo construir o modificar thought_signature por mi cuenta?
No. thought_signature es una credencial cifrada emitida por el servidor de Google que sirve para verificar la continuidad del contexto en conversaciones de varias vueltas. Una firma construida manualmente será rechazada por el servidor. Para ediciones multivuelta, simplemente reenvía la parte que contiene la firma.
P7: ¿Cómo manejar la incertidumbre que genera el "pensamiento" al generar 100 imágenes por lote?
Se recomienda procesar la respuesta de forma independiente para cada solicitud y registrar el thoughts_token_count. Puedes consultar el consumo de tokens por solicitud en el panel de control de APIYI (apiyi.com) y filtrar aquellas con un consumo de pensamiento anormalmente alto para revisarlas. Para escenarios masivos, también considera usar la API Batch (compatible con Gemini 3 Pro Image), que reduce los costes a la mitad y permite procesar las respuestas de forma asíncrona.
Resumen y lista de verificación para Gemini 3
Repasando todo, el pensamiento en imágenes de Gemini 3 no solo ha mejorado la calidad, sino que ha cambiado radicalmente la estructura de respuesta. En una frase:
✅ Principio fundamental: Nunca tomes
parts[0]a ciegas, filtra siemprethought: truey selecciona siempre la últimainline_datacomo la imagen final.

Lista de verificación para la migración
Si tu proyecto migra de Gemini 2.5 a Gemini 3, revisa los siguientes puntos:
- Reemplaza el ID del modelo:
gemini-2.5-flash-image→gemini-3-pro-image-previewogemini-3-flash-image. - Reescribe el análisis de respuesta: Cambia todos los
parts[0]por la lógica de "filtrar thought + tomar la última". - Nueva gestión de signature: Conserva la parte que contiene
thought_signatureen las conversaciones de varias vueltas. - Valida la previsión de costes: Ten en cuenta que los tokens de pensamiento cuentan como salida, por lo que el coste puede aumentar entre un 20% y un 40%.
- Pruebas de regresión: Prepara 20+ indicadores de muestra y compara la salida de Gemini 2.5 con Gemini 3 para evitar errores inesperados.
Plantilla de integración rápida
Utiliza este código como la "plantilla de oro" de tu equipo para todas las llamadas de la API:
def extract_final_image(response):
"""Extrae de forma segura la imagen final de una respuesta de Gemini 3 Image"""
parts = response.candidates[0].content.parts if response.candidates else []
# Buscar de atrás hacia adelante la primera imagen que no sea un 'thought'
for part in reversed(parts):
if getattr(part, "thought", False):
continue
if hasattr(part, "inline_data") and part.inline_data:
mime = part.inline_data.mime_type or ""
if mime.startswith("image/"):
return part.inline_data.data # base64 bytes
return None # No se encontró la imagen final, requiere reintento
🎯 Consejo final: El mecanismo de pensamiento en imágenes de Gemini 3 es un arma de doble filo: si se usa bien, obtienes una calidad de imagen de primer nivel; si se usa mal, obtienes resultados aleatorios a medio terminar. Recomendamos que, tras conectar mediante APIYI (apiyi.com), realices una prueba de regresión con 10-20 indicadores reales de tu negocio para confirmar que el código extrae correctamente la imagen final en diversos estados de activación del pensamiento antes de pasar a producción. Esta plataforma es compatible con toda la gama de modelos Gemini 3 y las respuestas de la API son idénticas a las oficiales de Google.
Autor: Equipo técnico de APIYI | Para más tutoriales de generación de imágenes con IA, visita help.apiyi.com