Muchos equipos que integran la API de Gemini para tareas de reconocimiento de imágenes se han topado con la misma confusión: al enviar la misma imagen y la misma indicación en la versión web de gemini.google.com, el modelo identifica detalles con precisión y ofrece respuestas estructuradas; sin embargo, al hacer lo mismo mediante la API de gemini-3.5-flash, los resultados son notablemente más pobres e incluso omiten información clave. Esta sensación de que "la web es potente y la API es débil" no significa que el modelo haya sido degradado, sino que estás viendo la brecha de ingeniería que existe entre la versión web y la API.
Este artículo se centra en una conclusión fundamental: la versión web de Gemini es un agente integral que optimiza automáticamente las indicaciones, realiza razonamientos en múltiples pasos, invoca herramientas y valida los resultados; mientras que la llamada a la API utiliza el modelo "desnudo", donde obtienes exactamente lo que envías. Al comprender esta diferencia, 6 técnicas de mejora de API que van más allá de simplemente "ajustar la indicación" te permitirán estabilizar tus resultados de reconocimiento de imágenes para que alcancen el nivel de la versión web.
Por qué el reconocimiento de imágenes de la API de Gemini es inferior a la versión web: la brecha entre el Agente y el modelo desnudo
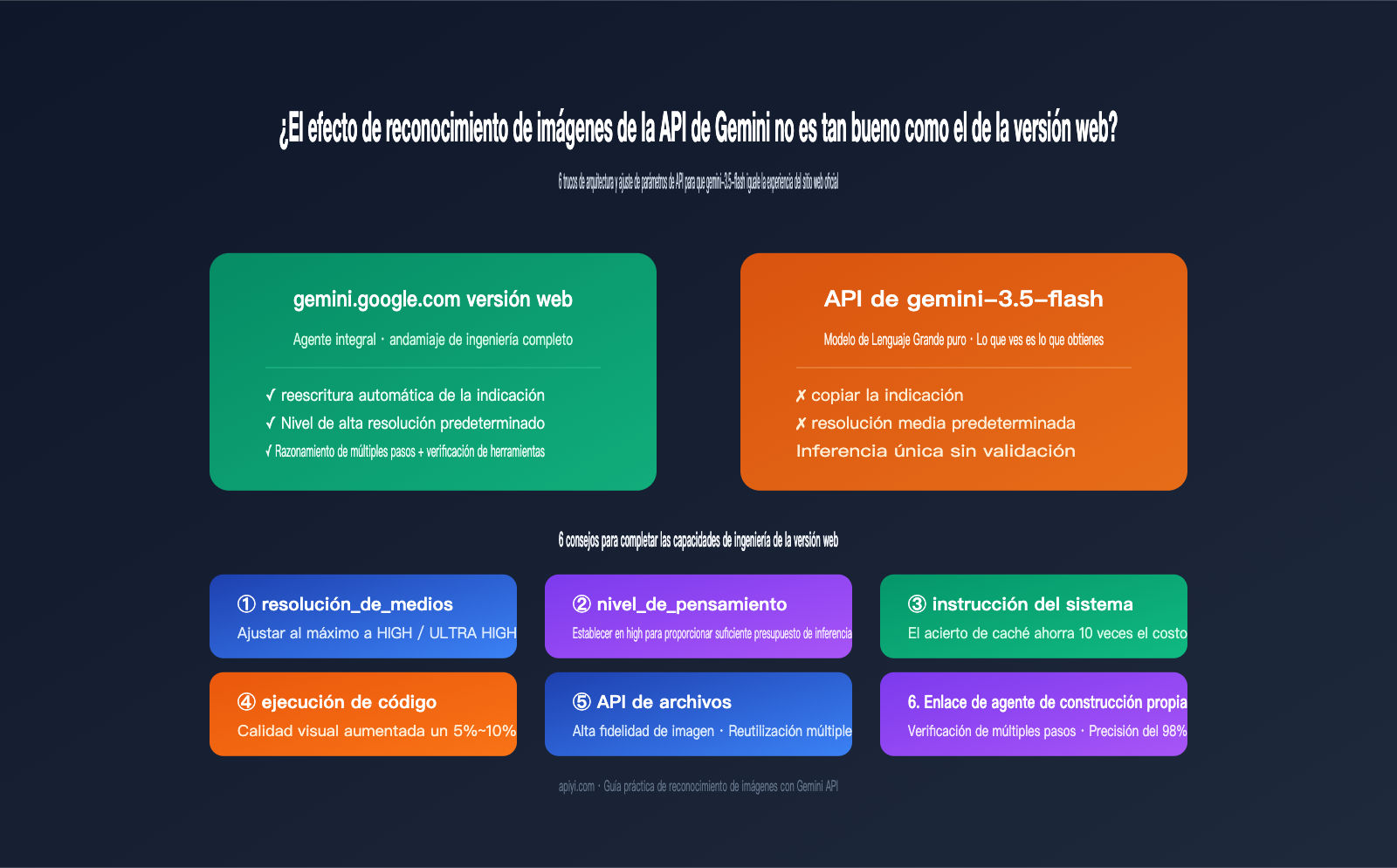
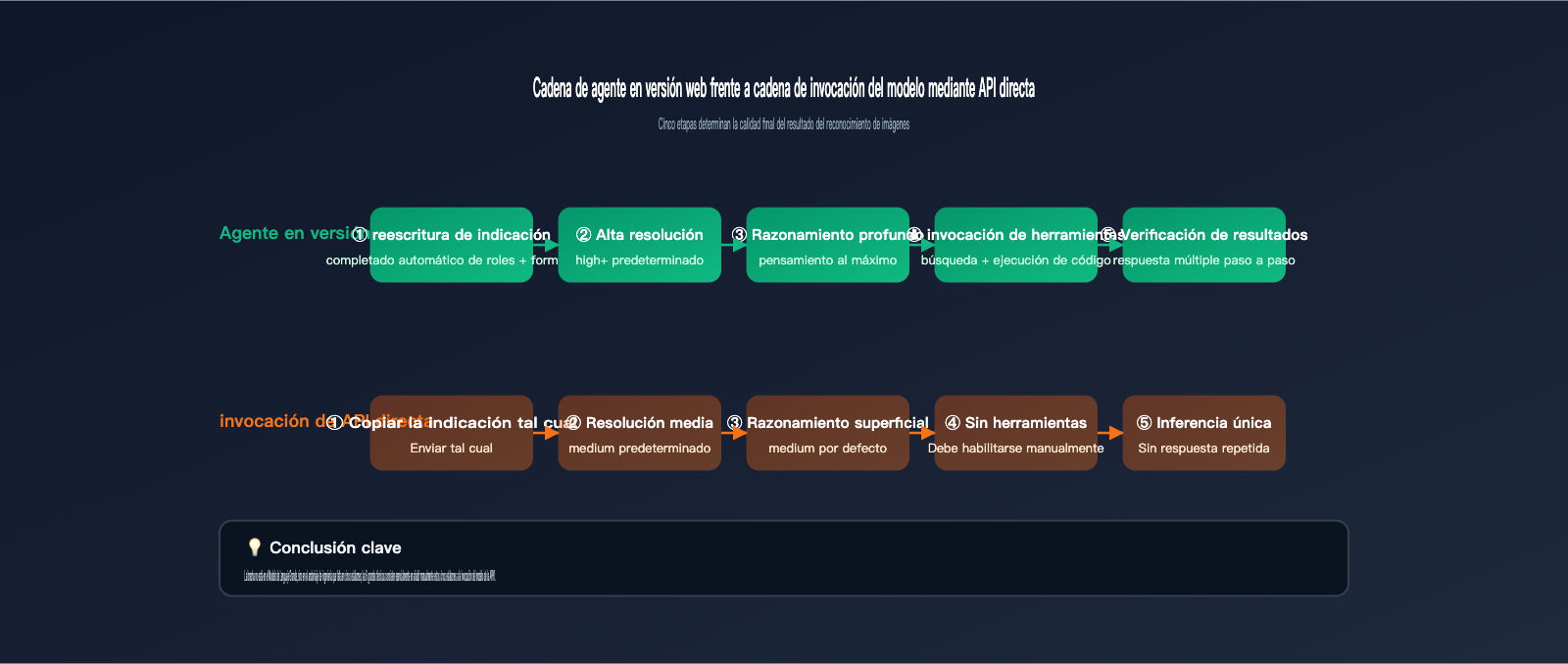
Para explicar esta diferencia, primero debemos entender cuánto trabajo realiza gemini.google.com por ti desde que envías una imagen hasta que obtienes la respuesta final. Basándonos en la documentación de Agentic Vision de Google y en las diferencias de respuesta que observamos en APIYI (apiyi.com) entre la web oficial y la API, la versión web es esencialmente un agente de nivel de producto construido alrededor del modelo base. Al menos realiza 5 tareas que no has solicitado explícitamente:
- Reescribe automáticamente tu indicación, complementándola con un rol, una tarea y un formato de salida completo.
- Procesa la imagen internamente con una resolución más alta para asegurar que los detalles no se compriman en píxeles borrosos.
- Activa por defecto un presupuesto de razonamiento de alta intensidad (similar a
thinking_level=high), dando tiempo al modelo para "pensar". - Invoca herramientas integradas como ejecución de código o búsqueda web cuando es necesario para realizar una validación cruzada y confirmar que los detalles son veraces.
- Evalúa el formato y la necesidad de una "re-respuesta" del resultado; si encuentra una respuesta ambigua, le vuelve a preguntar al modelo.
Cuando llamas directamente a la API, ninguna de estas 5 cosas ocurre automáticamente. En otras palabras, estás utilizando un "modelo" con capacidades completas, pero sin todo el "andamio de ingeniería". La siguiente tabla detalla las diferencias en los eslabones clave entre ambas formas de uso:
| Dimensión de comparación | Versión web gemini.google.com | API gemini-3.5-flash |
|---|---|---|
| Procesamiento de indicación | Reescribe y completa rol/formato | Copia exacta de la entrada del usuario |
| Resolución de imagen | Nivel alto por defecto | Nivel medio por defecto, requiere ajuste manual |
| Presupuesto de razonamiento | Alta intensidad, sin límite explícito | Medio por defecto, se puede configurar thinking_level |
| Invocación de herramientas | Acceso a búsqueda y código por defecto | Desactivado por defecto, requiere activación explícita |
| Validación de resultados | Verificación en múltiples pasos del Agente | Razonamiento único, sin validación |
| Transparencia de facturación | Cubierto por plan mensual | Facturación por Token |
Recomendamos ejecutar la misma imagen e indicación en una pasarela de agregación como APIYI (apiyi.com) para comparar los resultados de reconocimiento de imágenes entre la API de gemini-3.5-flash, Claude Opus y GPT-5.5. Esto te permitirá determinar rápidamente si la tarea actual está limitada por la capacidad del modelo o por el flujo de ingeniería.
Truco 1 para la visión de Gemini API: aumenta el parámetro media_resolution
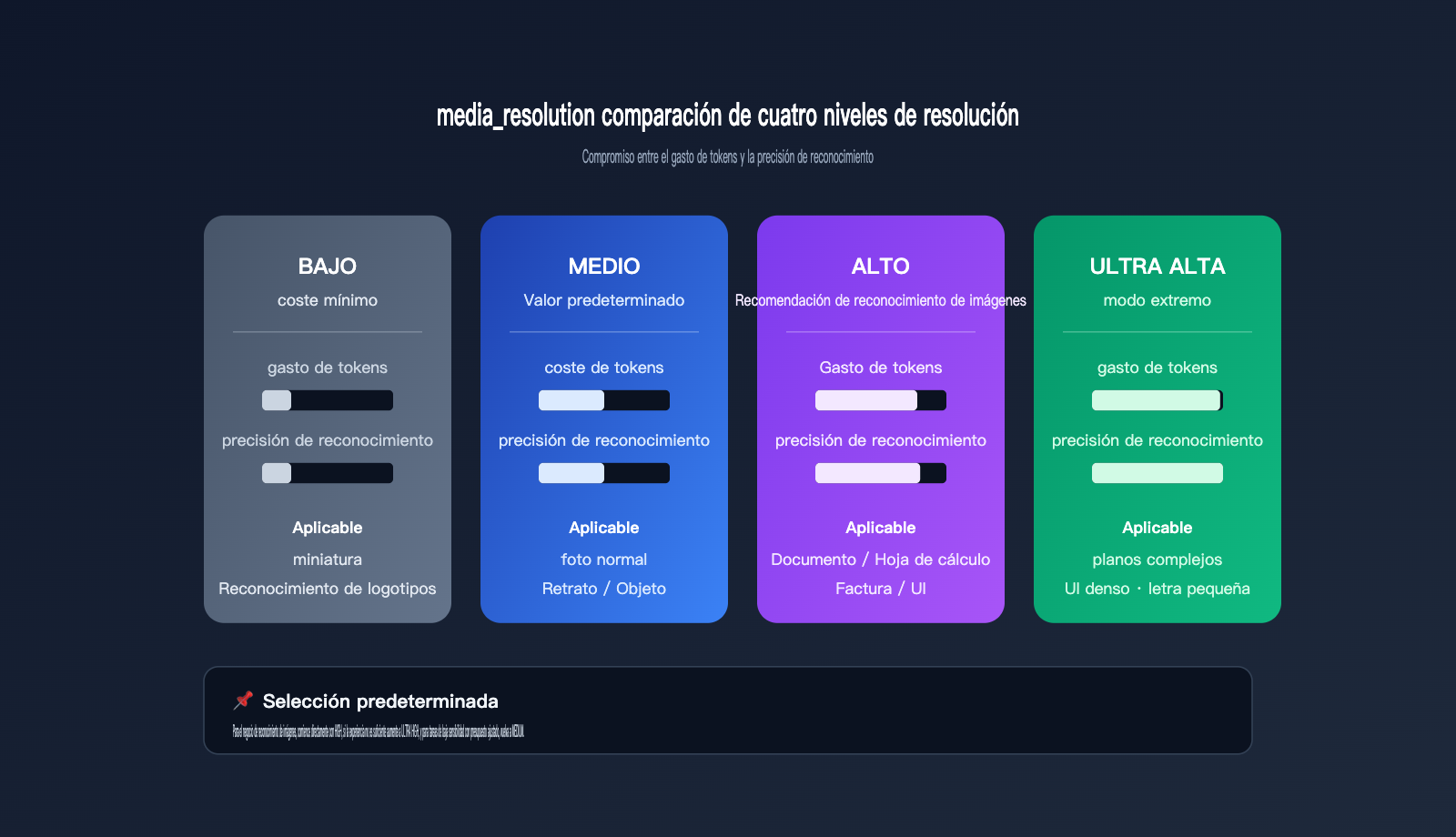
A partir de la serie Gemini 3, se introdujo el parámetro media_resolution, que controla directamente cuántos tokens asigna la API para "ver" una imagen. Este parámetro tiene cuatro niveles: low, medium, high y ultra high, siendo medium el valor predeterminado. Para tareas que requieren identificar texto pequeño, facturas, diagramas de circuitos o capturas de pantalla de interfaces (UI) con muchos detalles, medium suele quedarse corto, ya que el modelo comprime la imagen en un mapa de características demasiado tosco, provocando la pérdida de información.
La siguiente tabla muestra las diferencias reales entre los cuatro niveles para que elijas según tu caso de uso:
| Nivel de resolución | Consumo de tokens | Escenario de uso | Problema típico |
|---|---|---|---|
| low | Mínimo | Miniaturas, reconocimiento de logos | Se pierde casi todo el texto pequeño |
| medium (predeterminado) | Medio | Fotos normales, retratos | Detalles borrosos |
| high | Alto | Documentos, tablas, facturas | Información generalmente legible |
| ultra high | Muy alto | Planos complejos, UI densa | Calidad cercana a la web oficial |
Para tareas de visión, cambiar este parámetro de medium a high suele mejorar la precisión de inmediato. Si tu presupuesto lo permite y la tarea realmente implica texto pequeño o tablas densas, elegir ultra high es una opción razonable.
# Invocación de gemini-3.5-flash a través de APIYI, especificando resolución media 'high'
from google import genai
from google.genai import types
client = genai.Client(
api_key="YOUR_APIYI_KEY",
http_options={"base_url": "https://api.apiyi.com"}
)
resp = client.models.generate_content(
model="gemini-3.5-flash",
contents=[image_part, "Extrae todo el texto visible de la imagen y preséntalo en formato de tabla"],
config=types.GenerateContentConfig(
media_resolution="MEDIA_RESOLUTION_HIGH"
)
)
print(resp.text)
Al realizar la llamada a través de APIYI (apiyi.com), los parámetros se transmiten directamente al backend sin que la pasarela los reempaquete, por lo que puedes configurar los valores siguiendo la documentación oficial con total confianza.
Truco 2 para la visión de Gemini API: activa explícitamente thinking_level=high
Gemini 3.5 Flash introdujo el parámetro thinking_level, que controla la profundidad de razonamiento interno del modelo antes de generar una respuesta. En tareas de visión, la diferencia entre "pensar lo suficiente" y "pensar con cuidado" suele ser la clave para distinguir detalles o cometer errores. El nivel predeterminado de la API prioriza la velocidad sobre la calidad; para tareas de visión, se recomienda establecerlo en high para que el modelo tenga tiempo suficiente para realizar razonamientos espaciales y conteos, tal como lo hace en la versión web.
| thinking_level | Escenario recomendado | Diferencia percibida |
|---|---|---|
| low | Conversaciones simples, juicios de estilo | Rápido, reconocimiento tosco |
| medium | Preguntas y respuestas generales | Nivel estándar |
| high (recomendado para visión) | Documentos, facturas, conteo, razonamiento espacial | Calidad similar a la web oficial |
La documentación oficial destaca un punto contraintuitivo: al usar thinking_level=high, es mejor escribir indicaciones más directas y concisas, evitando las antiguas técnicas de "cadena de pensamiento" (chain-of-thought) como "por favor, razona paso a paso" o "considera todas las situaciones". Esas tácticas son para modelos antiguos; en la serie Gemini 3, pueden llevar al modelo a un "análisis excesivo".
🎯 Consejo de configuración: Establece
media_resolution=HIGHythinking_level=highcomo la combinación predeterminada para tus tareas de visión y guárdala en tus plantillas de llamada en APIYI (apiyi.com). Ajusta posteriormente haciaultra higholowsegún la experiencia real de tu negocio, evitando probar parámetros repetidamente en cada solicitud.
Truco 3 de la API de Gemini para reconocimiento de imágenes: coloca las instrucciones en system_instruction en lugar del user prompt
Otro error común al usar la API es meter todo en el user prompt: la configuración del rol, la descripción de la tarea, el formato de salida y la pregunta del usuario, todo mezclado en un solo bloque de texto. Esta forma de trabajar obliga al modelo a releer todo el contexto cada vez, mientras que las "instrucciones del sistema" en la versión web se almacenan en caché y se reutilizan.
La forma correcta es colocar tus "instrucciones estables" dentro de system_instruction:
config = types.GenerateContentConfig(
media_resolution="MEDIA_RESOLUTION_HIGH",
thinking_level="high",
system_instruction=(
"Eres un asistente de análisis de imágenes riguroso."
"Al responder, cita solo los detalles claramente visibles en la imagen, no infieras nada sin pruebas."
"Genera una salida en JSON estructurado con los campos fijos: entities/attributes/text."
)
)
Hacerlo así aporta dos beneficios: el modelo responde siempre bajo reglas uniformes, lo que hace que los resultados sean más estables; además, una vez que se activa el System Prompt Caching, el costo de entrada puede reducirse hasta 10 veces, algo muy valioso para tareas de reconocimiento de imágenes que se ejecutan por lotes a largo plazo. En el panel de control de APIYI (apiyi.com), puedes ver la tasa de aciertos de caché por ID de modelo, lo que facilita observar el efecto de tus optimizaciones.
Truco 4 de la API de Gemini para reconocimiento de imágenes: activa la ejecución de código para que el modelo "haga zoom" en la imagen
Google proporcionó un dato claro en el anuncio de Agentic Vision para Gemini 1.5 Flash: al activar herramientas de ejecución de código sobre el modelo base, las tareas de reconocimiento de imágenes obtienen una mejora de calidad promedio del 5% al 10%. El principio es que el modelo puede generar internamente código Python para recortar, ampliar, rotar o leer píxeles de la imagen, y luego volver a analizar la subimagen procesada. Esto es exactamente lo que hace la versión web por defecto.
La API no activa la ejecución de código por defecto, por lo que debes declararlo explícitamente:
config = types.GenerateContentConfig(
media_resolution="MEDIA_RESOLUTION_HIGH",
thinking_level="high",
tools=[types.Tool(code_execution=types.ToolCodeExecution())]
)
resp = client.models.generate_content(
model="gemini-1.5-flash",
contents=[image_part, "Cuenta el número de botones rojos en la imagen y enumera sus posiciones"],
config=config
)
Para tareas de conteo, razonamiento espacial y análisis denso de interfaces de usuario (UI), que son los casos donde la ejecución de código aporta valor según el fabricante, esta es la optimización con mejor relación costo-beneficio. En APIYI (apiyi.com) hemos observado que la latencia general aumenta ligeramente al activar la ejecución de código, por lo que recomendamos activarla por defecto en procesos asíncronos y usarla bajo demanda en procesos síncronos.
Truco de visión para la API de Gemini 5: Usa File API para imágenes grandes en lugar de base64
Para imágenes que superan los pocos MB, muchos equipos optan por incrustarlas directamente en el cuerpo de la solicitud mediante base64. Si bien esto funciona bien con imágenes pequeñas, cuando el tamaño total de la solicitud supera los 20 MB, se activan las restricciones de Gemini: algunas imágenes se comprimen silenciosamente, lo que inevitablemente reduce la calidad del reconocimiento.
La guía oficial establece límites muy claros:
| Tamaño de imagen | Método de transferencia recomendado | Motivo |
|---|---|---|
| Menos de 5 MB | base64 en línea | Solicitud ligera, invocación sencilla |
| 5~20 MB | Carga mediante File API | Evita la expansión del volumen de la solicitud |
| Más de 20 MB | Obligatorio File API | La codificación base64 corrompe la solicitud |
| Reutilización múltiple | Recomendado File API | Sube una vez y referencia varias veces, ahorra tokens |
Otra ventaja de File API es que la misma imagen puede reutilizarse en múltiples solicitudes, ahorrando los costes de carga repetida. Con la pasarela de APIYI (apiyi.com), el endpoint de File API utiliza el mismo conjunto de credenciales, por lo que no necesitas abrir una cuenta de Google Cloud por separado para la carga de imágenes.
Truco 6 para la API de Gemini: Construye tu propia cadena de Agentes para una verificación de varios pasos
Después de aplicar los 5 trucos anteriores, tu invocación del modelo mediante API ya debería sentirse muy similar a la versión web. Sin embargo, la interfaz web tiene un as bajo la manga: la verificación de varios pasos. Tras generar una respuesta, el sistema realiza un segundo razonamiento para validar los hechos clave y, si encuentra algo incierto, vuelve a generar la respuesta. Esta capacidad no tiene un interruptor directo en la API, por lo que tendrás que montar una cadena de Agentes sencilla.
Una cadena mínima de dos pasos sería:
- Primera invocación: Haz que
gemini-3.5-flashgenere un resultado de reconocimiento estructurado (salida JSON). - Segunda invocación: Envía el resultado anterior junto con la imagen original y pregunta al modelo: "¿Basado en esta imagen, son ciertas todas las conclusiones siguientes?".
Si la segunda invocación detecta algún campo "falso", dispara una tercera "re-generación". Esta cadena puede ejecutarse directamente en APIYI (apiyi.com) usando la misma base_url y clave API, sin necesidad de servicios adicionales. Para tareas que exigen alta precisión (procesamiento de contratos, asistencia en imágenes médicas, cumplimiento normativo), la verificación de varios pasos es el paso clave para elevar la precisión del 90% al 98%.
| Tipo de tarea | Cadena sugerida | Parámetros de un solo paso |
|---|---|---|
| Preguntas y respuestas generales | Un paso | high + thinking_high |
| Extracción de documentos | Un paso + validación JSON | ultra high + thinking_high |
| Conteo complejo | Dos pasos + ejecución de código | high + thinking_high + tools |
| Negocios de alta precisión | Cadena de tres pasos (reconocimiento → validación → re-generación) | ultra high + thinking_high + tools |
Plantilla de parámetros para producción: encadena los 6 trucos en una llamada reutilizable
Para que puedas aplicarlo fácilmente, aquí tienes una "plantilla predeterminada para tareas de reconocimiento de imágenes" que integra los 6 trucos anteriores, ideal como punto de partida para la mayoría de los casos de uso:
from google import genai
from google.genai import types
client = genai.Client(
api_key="YOUR_APIYI_KEY",
http_options={"base_url": "https://api.apiyi.com"}
)
SYSTEM = (
"Eres un asistente de análisis de imágenes riguroso. Cita solo lo que sea claramente visible en la imagen, "
"no infieras nada. Genera un JSON estricto con los campos entities/attributes/text."
)
config = types.GenerateContentConfig(
media_resolution="MEDIA_RESOLUTION_HIGH",
thinking_level="high",
system_instruction=SYSTEM,
tools=[types.Tool(code_execution=types.ToolCodeExecution())],
response_mime_type="application/json"
)
resp = client.models.generate_content(
model="gemini-3.5-flash",
contents=[image_part, "Reconoce esta imagen siguiendo las instrucciones del SYSTEM"],
config=config
)
print(resp.text)
Al desplegar, te recomiendo extraer esta plantilla en una capa de invocación SDK unificada en APIYI (apiyi.com). De este modo, los equipos de negocio solo envían la imagen y la pregunta, mientras que los parámetros se inyectan de forma centralizada desde la pasarela, evitando que cada proyecto tenga que aprender de sus propios errores.

Preguntas frecuentes (FAQ): Diferencias entre la API de Gemini y la versión web en reconocimiento de imágenes
P1: Si activo todos estos parámetros, ¿la API seguirá siendo inferior a la versión web?
La gran mayoría de las tareas de negocio pueden igualar el rendimiento de la web, pero en casos de alta dificultad (texto muy pequeño, baja iluminación, estilos artísticos especiales), aún podría haber una ligera diferencia, ya que la versión web utiliza procesos internos de mejora (Pipeline) no públicos. Para este tipo de escenarios, puedes realizar comparaciones horizontales con otros modelos visuales en APIYI (apiyi.com) para encontrar el modelo de trabajo más adecuado.
P2: ¿thinking_level=high duplicará los costos?
Aumentará el consumo de tokens de razonamiento interno, pero solo afecta a la etapa de salida, y en las tareas de reconocimiento de imágenes, los tokens de imagen suelen representar la mayor parte del costo total. La mejora en la precisión que aporta ajustar el thinking a high es mucho mayor que el incremento en el costo, especialmente en tareas que sustituyen la revisión humana.
P3: ¿Cómo cambio la base_url? Estoy usando el SDK oficial de Google.
El SDK google-genai permite redirigir las solicitudes a la pasarela de APIYI (apiyi.com) mediante http_options={"base_url": "https://api.apiyi.com"}. Solo necesitas usar la clave API generada en el panel de control de APIYI; no es necesario tener un proyecto de Google Cloud independiente.
P4: ¿Se puede solucionar el problema optimizando solo la indicación?
El límite de ajustar solo la indicación es evidente; no puede cubrir capacidades "fuera del modelo" como la resolución, la profundidad de razonamiento o la invocación de herramientas. De los 6 consejos de este artículo, solo el tercero está relacionado con la indicación; los otros 5 son palancas a nivel de ingeniería.
P5: ¿Qué hago si la versión web puede reconocer "marcas de agua en chino" en las imágenes, pero la API siempre las pasa por alto?
Los detalles como las marcas de agua suelen depender de una combinación de alta resolución y recorte mediante ejecución de código. Ajusta media_resolution a ultra high, habilita code execution y utiliza una cadena de verificación de dos pasos; esto suele estabilizar el reconocimiento.
Conclusión: Lleva las capacidades de ingeniería de la web a tus llamadas de API
Volviendo a la pregunta inicial: ¿por qué el reconocimiento de imágenes de la API de Gemini no es tan bueno como el de la versión web? La respuesta no es que el modelo sea más débil, sino que la versión web viene con un "andamio" de ingeniería muy robusto. Cuando llamas directamente a la API de gemini-3.5-flash, la reescritura de la indicación, los niveles de resolución, el presupuesto de razonamiento, la invocación de herramientas y la validación de resultados son tareas que debes completar explícitamente tú mismo. Al entender esto, la esencia de los 6 consejos es "trasladar lo que la versión web hace por ti a tu propia cadena de llamadas de API".
La ruta de implementación es clara: primero, maximiza media_resolution y thinking_level, luego traslada las instrucciones a system_instruction y habilita el caché. Para tareas complejas de reconocimiento, activa code execution, procesa las imágenes grandes a través de la File API y, finalmente, utiliza una cadena de agentes de dos o tres pasos para asegurar la precisión en tareas críticas. Con esta combinación, al volver al panel de control de APIYI (apiyi.com) para comparar la tasa de aciertos y la latencia, la mayoría de los equipos podrán reducir la brecha entre la "web y la API" hasta que sea prácticamente imperceptible.
📌 Autoría: Este artículo ha sido preparado por el equipo técnico de APIYI (apiyi.com). Para más guías prácticas de acceso y ajuste de parámetros de los modelos de las series Gemini, Claude y GPT, consulta el Centro de Ayuda de APIYI.