Claude Opus 4.7 se lanzó oficialmente el 16 de abril de 2026, y al segundo día de su debut, la comunidad ya estaba dividida. Aunque los benchmarks oficiales aseguran que supera al 4.6 en 12 de las 14 pruebas, un gran número de desarrolladores en GitHub y X se quejan de que su rendimiento es inferior al de la versión 4.6, e incluso algunos lo han calificado como una "versión 4.6 pre-ajustada disfrazada de nueva versión".
Basado en datos oficiales de Anthropic, pruebas independientes de terceros y comentarios de primera mano de la comunidad, este artículo analiza a fondo Claude Opus 4.7 a través de 8 dimensiones, incluyendo capacidades de codificación, reconocimiento visual, contexto largo, cambios en el Tokenizer y Task Budgets, para ayudarte a decidir si vale la pena migrar de inmediato.
Valor clave: Tras leer este artículo, sabrás si Claude Opus 4.7 es una actualización o una degradación para tus casos de negocio, y cómo mitigar los riesgos de la migración.

Antecedentes y detalles clave del lanzamiento de Claude Opus 4.7
Claude Opus 4.7 es el Modelo de Lenguaje Grande insignia lanzado por Anthropic el 16 de abril de 2026. Hereda el precio de $5/$25 por millón de tokens de Opus 4.6 y establece nuevos récords en múltiples benchmarks. Sin embargo, viene acompañado de cambios sistémicos como una reestructuración del Tokenizer, una caída significativa en el benchmark de contexto largo MRCR y un nuevo nivel de inferencia "xhigh", factores que afectan directamente el rendimiento en entornos reales.
Resumen rápido del lanzamiento de Claude Opus 4.7
| Ítem de información | Detalles |
|---|---|
| Fecha de lanzamiento | 16 de abril de 2026 |
| Lanzado por | Anthropic |
| Precio de entrada | $5 / millón de tokens (igual que 4.6) |
| Precio de salida | $25 / millón de tokens (igual que 4.6) |
| Ventana de contexto | 1M de tokens (precio estándar) |
| Resolución máxima de imagen | 2576px lado largo / 3.75 millones de píxeles |
| Nuevo nivel de inferencia | xhigh (entre high y max) |
| Nueva función experimental | Task Budgets (en versión beta pública) |
| Canales disponibles | Claude API, Amazon Bedrock, Google Vertex AI, Microsoft Foundry |
🎯 Sugerencia técnica: Antes de migrar formalmente a Claude Opus 4.7, te recomendamos realizar pruebas comparativas paralelas llamando tanto al 4.6 como al 4.7 a través de la plataforma APIYI (apiyi.com). Esta plataforma ofrece una interfaz unificada donde cambiar de modelo solo requiere ajustar parámetros, permitiéndote identificar rápidamente las diferencias de rendimiento.
Puntos clave de actualización de Claude Opus 4.7
Las mejoras promocionadas oficialmente por Anthropic se centran principalmente en las siguientes cuatro áreas:
- Capacidades de ingeniería de software significativamente mejoradas: SWE-bench Verified aumentó del 80.8% al 87.6%, y SWE-bench Pro saltó del 53.4% al 64.3%.
- Mejora drástica en la comprensión visual: Soporte para imágenes de alta resolución de 3.75 millones de píxeles; el benchmark visual aumentó del 54.5% al 98.5%.
- Refuerzo en el uso de herramientas Agentic: El benchmark MCP-Atlas obtuvo la mayor mejora individual, con un incremento de 13 puntos en condiciones sin herramientas.
- Seguimiento de indicaciones más preciso: El procesamiento de indicaciones ambiguas es más robusto y la ejecución más exhaustiva.
Sin embargo, la retroalimentación real de la comunidad muestra otra cara de la moneda.
Análisis detallado de las funciones principales de Claude Opus 4.7
Los cambios en las funciones principales de Claude Opus 4.7 no solo se reflejan en las capacidades del modelo, sino también en ajustes importantes a nivel de entrega. Comprender estos cambios es fundamental para evaluar correctamente el rendimiento del modelo.
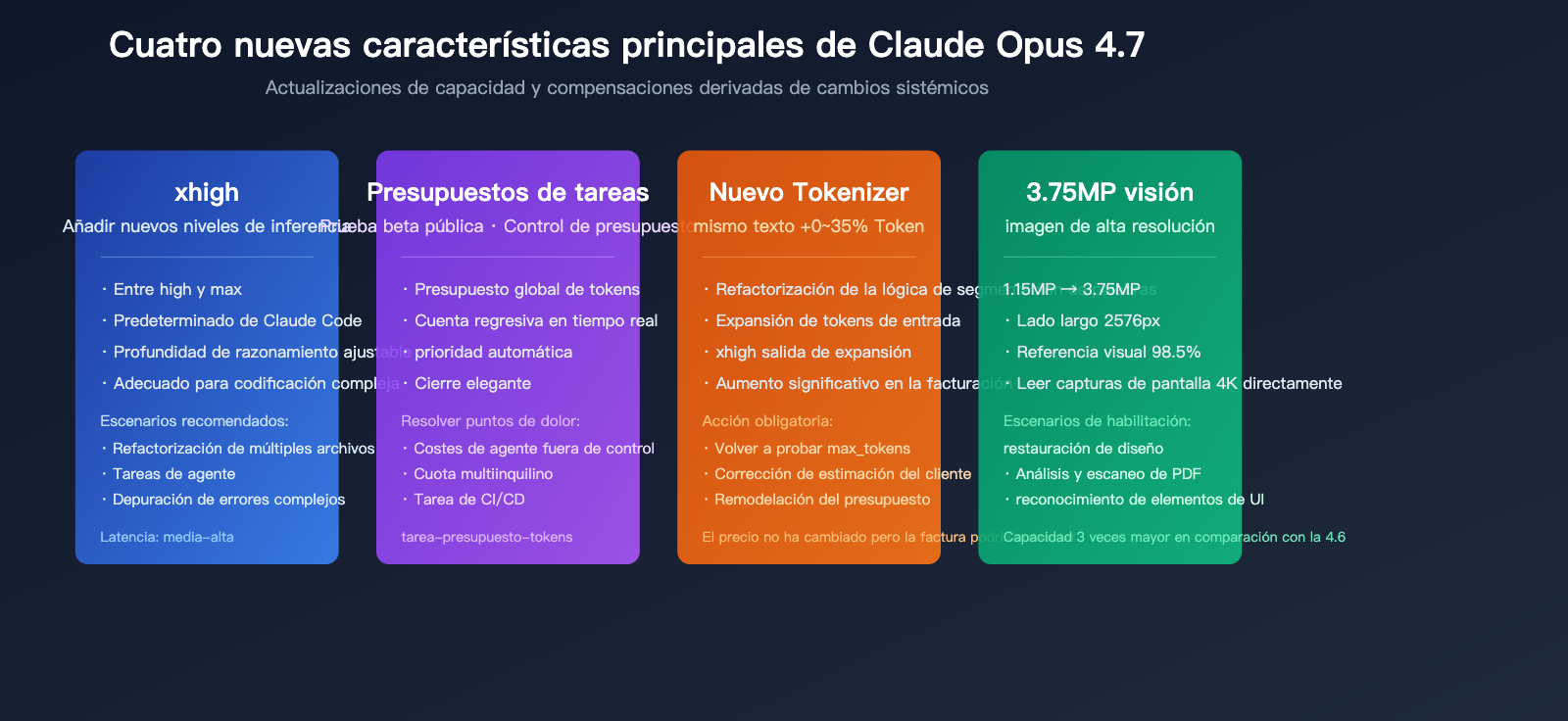
Los cuatro cambios sistémicos de Claude Opus 4.7
| Módulo funcional | Rendimiento 4.6 | Cambio en 4.7 | Impacto empresarial |
|---|---|---|---|
| Tokenizer | Tokenización original | 1.0–1.35× tokens por el mismo texto | La factura real podría subir un 35% |
| Nivel de inferencia | low / medium / high / max | Nuevo xhigh (predeterminado en Claude Code) | Profundidad y latencia más precisas |
| Presupuestos de tarea | N/A | Versión beta, control global de presupuesto de tokens | Costos de bucle de agentes controlables |
| Entrada visual | ~1.15 megapíxeles | ~3.75 megapíxeles (3×) | Capaz de procesar capturas y planos HD |
| Contexto largo MRCR | 78.3% | 32.2% | Caída significativa en la recuperación de documentos largos |
| SWE-bench Verified | 80.8% | 87.6% | Mejora sustancial en tareas de código reales |
Los costos ocultos de los cambios en el Tokenizer
El cambio más importante, pero también el más pasado por alto, en Claude Opus 4.7 es la reestructuración del Tokenizer. La documentación oficial es clara: el mismo texto de entrada se mapea en 4.7 a una cantidad de tokens entre 1.0 y 1.35 veces mayor que en la versión 4.6. Esto significa que:
- La longitud de tu indicación no cambia, pero la facturación de tokens de entrada podría ser un 35% mayor.
- En los niveles de inferencia xhigh o max, los tokens de salida también podrían aumentar significativamente.
- Los límites de
max_tokensestablecidos anteriormente para la versión 4.6 deben volver a probarse por completo. - La lógica del cliente para estimar tokens basada en el número de caracteres debe reescribirse.
💰 Optimización de costos: Para entornos de producción sensibles a los costos de tokens, antes de migrar a Claude Opus 4.7, recomendamos encarecidamente realizar una comparación de facturación con tráfico real en la plataforma APIYI (apiyi.com). Esta plataforma admite consultas de facturación flexibles y monitoreo en tiempo real, lo que facilita cuantificar el incremento de costos real derivado de la migración.
Estrategia de uso del nivel de inferencia xhigh
xhigh es un nuevo nivel de inferencia introducido en Opus 4.7, situado entre high y max. Anthropic recomienda usar xhigh por defecto en tareas de codificación y agentes, y es el nivel predeterminado para todos los planes de Claude Code.
Escenarios de uso para los diferentes niveles de inferencia:
| Nivel de inferencia | Tareas aplicables | Latencia | Escenario de uso recomendado |
|---|---|---|---|
low |
Preguntas simples, conversión de formato | Muy baja | Alta concurrencia, tareas de baja complejidad |
medium |
Generación de código estándar | Baja | Asistencia de desarrollo convencional |
high |
Código complejo, diseño técnico | Media | Tareas de agentes convencionales |
xhigh |
Depuración difícil, refactorización a gran escala | Media-alta | Recomendado: Escenarios de codificación como Claude Code |
max |
Inferencia extremadamente compleja | Alta | Tareas de investigación, no sensibles a la latencia |
Presupuestos de tarea: El fin de los costos descontrolados en bucles de agentes
Los presupuestos de tarea (Task Budgets) son una función beta introducida en Opus 4.7 que resuelve el problema persistente de la dificultad para controlar el consumo total de tokens en los bucles de agentes. Mecanismo de funcionamiento:
- Los desarrolladores establecen un presupuesto global de tokens antes de iniciar el bucle del agente.
- El modelo puede ver la cuenta regresiva del presupuesto en cada respuesta.
- El modelo ajusta automáticamente la profundidad de pensamiento y el número de llamadas a herramientas según el presupuesto restante.
- Antes de que se agote el presupuesto, el modelo prioriza completar la tarea principal y finalizar de manera elegante.
Esta función, junto con la nueva cabecera de interfaz redact-thinking-2026-02-12, representa una mejora sustancial en la gestión de costos de agentes.
Panorama de datos de pruebas reales de Claude Opus 4.7
Esta sección es el núcleo del artículo. Hemos recopilado los benchmarks oficiales de Anthropic, evaluaciones independientes de terceros y datos de pruebas de la comunidad para presentar la diferencia real entre Claude Opus 4.7 y 4.6.
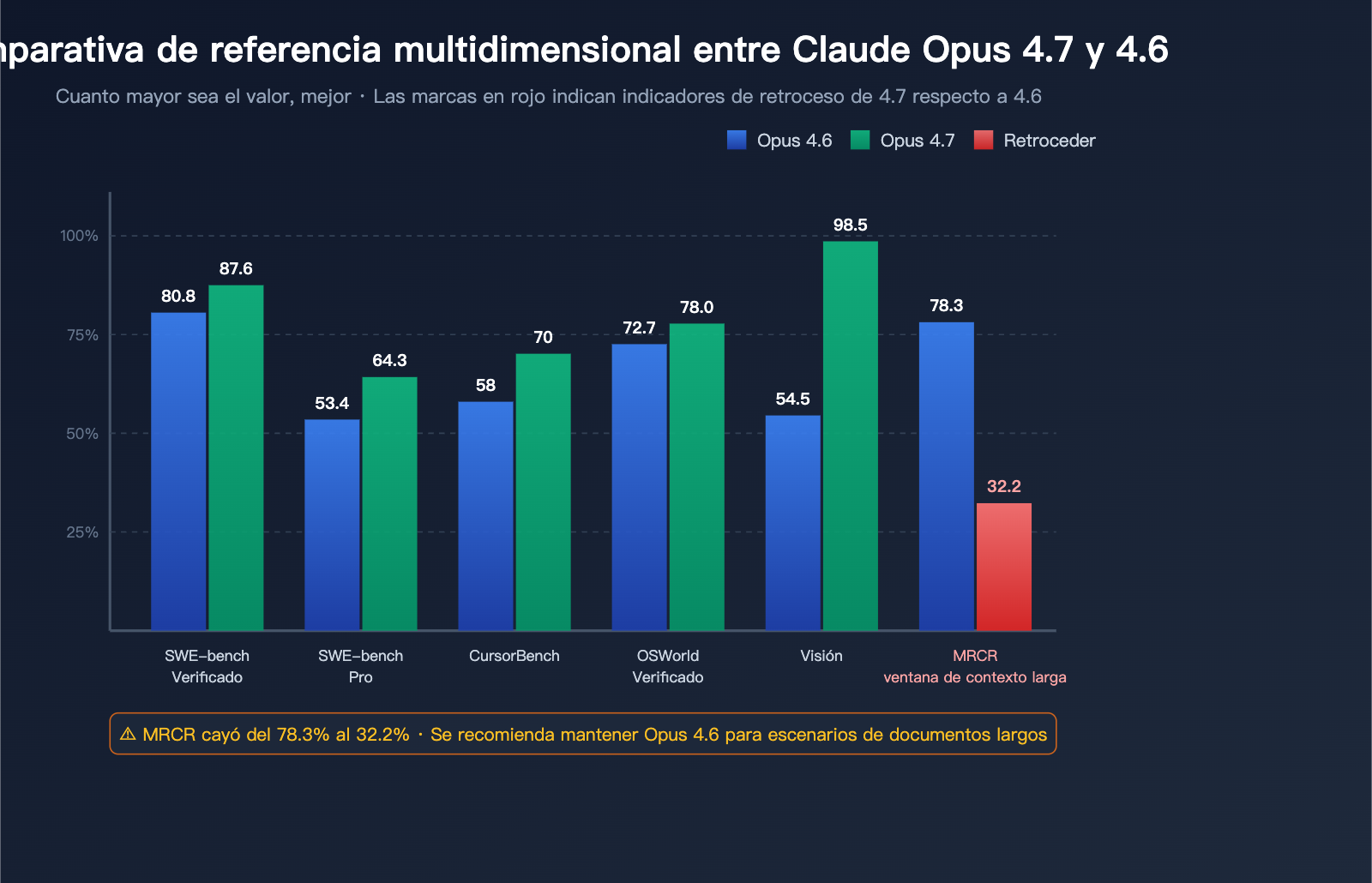
Benchmarks de capacidad de codificación: 4.7 lidera en todos los aspectos
| Benchmark de codificación | Opus 4.6 | Opus 4.7 | Mejora | Descripción |
|---|---|---|---|---|
| SWE-bench Verified | 80.8% | 87.6% | +6.8pt | Tareas reales de corrección de GitHub Issues |
| SWE-bench Pro | 53.4% | 64.3% | +10.9pt | Variante multilingüe de mayor dificultad |
| CursorBench | 58% | 70% | +12pt | Tareas de codificación reales dentro del IDE |
| OSWorld-Verified | 72.7% | 78.0% | +5.3pt | Operaciones de escritorio y uso de computadora |
| MCP-Atlas (sin herramientas) | — | +13pt | Mayor mejora en un ítem | Tareas de cadena de herramientas Agentic |
| MCP-Atlas (con herramientas) | — | +6pt | Mejora significativa | Precisión de invocación del modelo |
En el campo de la codificación, Claude Opus 4.7 es, sin duda, el Modelo de Lenguaje Grande público más potente del segundo trimestre de 2026; su resultado del 64.3% en SWE-bench Pro le permite recuperar el primer lugar en codificación Agentic.
🚀 Inicio rápido: Si deseas experimentar inmediatamente la capacidad de codificación de Claude Opus 4.7, puedes utilizarlo directamente a través de la plataforma APIYI (apiyi.com). Esta plataforma ofrece interfaces totalmente compatibles con la API oficial de Claude, admite el formato estándar de SDK de OpenAI y tiene un costo de migración extremadamente bajo.
Benchmarks visuales y de contexto largo: polarización
| Benchmark | Opus 4.6 | Opus 4.7 | Cambio | Evaluación |
|---|---|---|---|---|
| Reconocimiento visual (general) | 54.5% | 98.5% | +44pt | Cerca de un cambio cualitativo |
| Resolución máxima de imagen | ~1.15 MP | ~3.75 MP | 3× | Puede procesar capturas en 4K |
| Recuperación de contexto largo MRCR | 78.3% | 32.2% | -46.1pt | Retroceso grave |
MRCR (Recuperación de contexto de múltiples rondas) es el benchmark estándar para evaluar la capacidad de recuperación en contextos largos. En este indicador, Opus 4.7 ha caído abruptamente del 78.3% al 32.2%; esto no es una fluctuación normal, sino un retroceso estructural.
Esta cifra explica por qué muchos desarrolladores se quejan de que "al darle al modelo 800 líneas de documentación de flujo de trabajo, este dice haberlas leído, pero el contenido de salida no tiene nada que ver con el documento".
Benchmarks vs. experiencia real: ¿Por qué la evaluación está polarizada?
Que los benchmarks sean líderes no significa que el rendimiento empresarial real sea superior. Opus 4.7 ha recibido muchos comentarios negativos en la comunidad por varias razones:
- Expansión de Tokenizer: El consumo de tokens aumenta para la misma tarea, pero la mejora en capacidad no siempre compensa el costo.
- Seguimiento de indicaciones demasiado literal: La versión 4.6 solía "entender la intención", mientras que la 4.7 ejecuta estrictamente al pie de la letra, lo que puede invalidar las indicaciones (prompts) anteriores.
- Colapso de MRCR: La capacidad de recuperación en documentos largos ha disminuido, lo que genera problemas evidentes al procesar grandes bases de código o documentos contractuales.
- Falsos positivos en Claude Code: Algunos desarrolladores informan que la versión 4.7 clasifica erróneamente código legítimo como código malicioso y rechaza editarlo.
💡 Consejo de elección: Elegir entre Claude Opus 4.7 o seguir usando la versión 4.6 depende principalmente de tus escenarios de negocio principales. Recomendamos realizar pruebas de carga en paralelo con ambos modelos a través de la plataforma APIYI (apiyi.com) antes de tomar una decisión. La plataforma admite la invocación mediante una interfaz unificada para múltiples modelos, facilitando la comparación y el cambio rápido.
Experiencia real con Claude Opus 4.7
Más allá de los datos de referencia, Anthropic y la comunidad de desarrolladores han ofrecido opiniones muy dispares sobre el rendimiento de Opus 4.7 en flujos de trabajo reales.
Postura oficial de Anthropic
En su anuncio de lanzamiento, Anthropic destacó cuatro mejoras clave de Opus 4.7 frente a la versión 4.6:
- Mejor rendimiento en tuberías de ingeniería: los usuarios pueden delegar con confianza tareas "difíciles" que antes requerían una supervisión estricta.
- Mayor capacidad para manejar problemas ambiguos: más robustez ante requisitos mal definidos.
- Resolución de problemas más exhaustiva: no abandona las tareas a mitad de camino.
- Seguimiento de instrucciones más preciso: mayor rigor en los detalles.
Boris Cherny, responsable de Claude Code, declaró tras el lanzamiento que Opus 4.7 es "más inteligente, más capaz como agente y más preciso" que la 4.6, aunque admitió que se requieren unos días de adaptación para aprovechar al máximo sus nuevas capacidades.
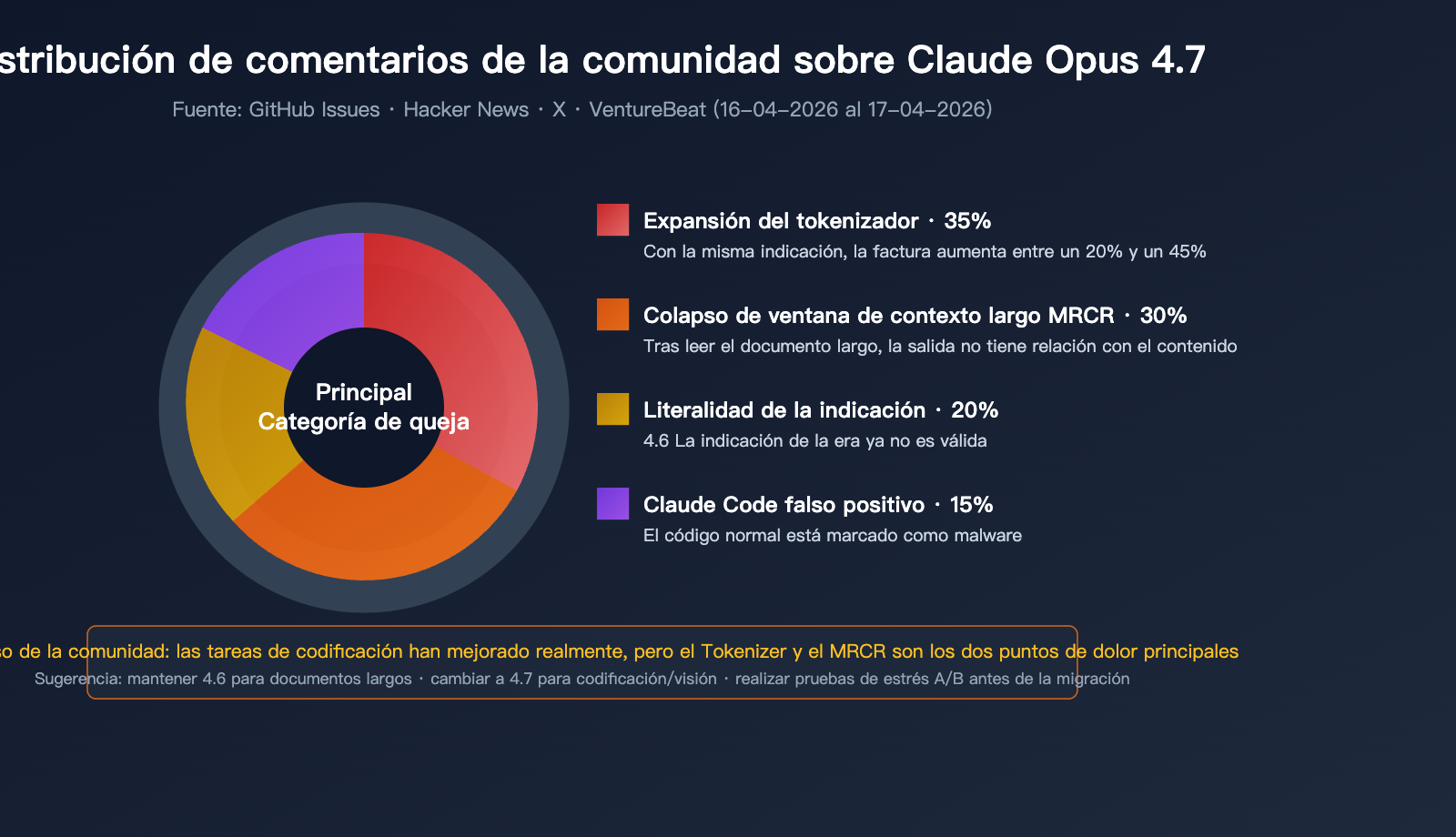
Opiniones reales de la comunidad de desarrolladores
En plataformas como GitHub, Hacker News y X, las reacciones de los desarrolladores han sido notablemente negativas:
Queja 1: El consumo de tokens se dispara
Debido al nuevo tokenizador, la misma entrada se descompone en más tokens en Opus 4.7. Sumado al aumento de tokens de salida en el nivel xhigh, algunos usuarios reportan incrementos en su factura de hasta un 40%. Esto ha sido bautizado irónicamente como "inflación por reducción de IA" (AI Shrinkflation).
Queja 2: Desastre en el procesamiento de documentos largos
Varios desarrolladores informan que, tras introducir documentos extensos en Opus 4.7, el modelo afirma haberlos leído, pero el contenido generado no tiene relación sustancial con el documento. Esto coincide con la caída del MRCR del 78,3% al 32,2%.
Queja 3: Claude Code clasifica erróneamente código como malicioso
En el Issue #47483, varios ingenieros informan que Claude Opus 4.7 marca fragmentos de código normal de lectura/escritura de archivos como malware, negándose a completar tareas básicas de edición.
Queja 4: Disminución de la compatibilidad de las indicaciones (prompts)
Las indicaciones que funcionaban bien en la 4.6 ofrecen una calidad de salida inferior al migrar a la 4.7. La razón es que la 4.7 ejecuta las instrucciones estrictamente al pie de la letra, mientras que la 4.6 solía "leer entre líneas" automáticamente.
Puntuación por escenarios de Claude Opus 4.7
Basado en datos de pruebas y comentarios de la comunidad, aquí tienes la puntuación de Opus 4.7 en diferentes escenarios:
| Escenario de uso | Puntuación Opus 4.6 | Puntuación Opus 4.7 | Cambio | Recomendación |
|---|---|---|---|---|
| Refactorización de código corto/medio | 8/10 | 9/10 | ↑ | Migrar de inmediato |
| Flujos de trabajo de agentes complejos | 7.5/10 | 9/10 | ↑ | Migrar de inmediato |
| Revisión de código en repositorios grandes | 8/10 | 6.5/10 | ↓ | Seguir usando 4.6 |
| Resumen y preguntas sobre documentos largos | 8.5/10 | 5/10 | ↓↓ | Seguir usando 4.6 |
| Comprensión de imágenes de alta resolución | 6.5/10 | 9.5/10 | ↑↑ | Migrar de inmediato |
| Conversación y escritura convencional | 9/10 | 9/10 | → | Cualquiera |
| Producción sensible a costes | 9/10 | 7/10 | ↓ | Seguir usando 4.6 |
| Desarrollo de prototipos y experimentos | 8/10 | 8.5/10 | ↑ | Migrar |
Análisis profundo de pros y contras de Claude Opus 4.7
Tras comparar los datos y la experiencia, podemos ofrecer un resumen más claro de sus ventajas y limitaciones.
Las cuatro ventajas principales de Claude Opus 4.7
Ventaja 1: Mejora significativa en la capacidad de codificación real
Los resultados de 87,6% en SWE-bench Verified y 64,3% en SWE-bench Pro no son solo juegos de números, sino tareas reales de resolución de Issues en GitHub. Esto significa que Opus 4.7 realmente puede sustituir más mano de obra en tareas de codificación pequeñas y medianas.
Ventaja 2: Salto cualitativo en la comprensión visual
La entrada de imágenes de alta resolución (3,75 megapíxeles) permite a Opus 4.7 procesar directamente capturas de pantalla 4K, planos de diseño, escaneos PDF y otros contenidos visuales de alta densidad. Este es un avance importante para la serie Claude.
Ventaja 3: Task Budgets para la gestión de costes de agentes
Durante mucho tiempo, el consumo descontrolado de tokens en los bucles de agentes ha sido el principal obstáculo para la implementación empresarial. Los Task Budgets ofrecen a los desarrolladores, por primera vez, una capacidad de control presupuestario global y detallado.
Ventaja 4: El nivel xhigh ofrece un equilibrio más preciso entre razonamiento y latencia
Tener una opción adicional entre high y max significa que los desarrolladores pueden ajustar el rendimiento de forma flexible según los requisitos de SLA en el mismo escenario.
Las cuatro limitaciones principales de Claude Opus 4.7
Limitación 1: La inflación del tokenizador aumenta los costes reales
Incluso manteniendo el precio unitario, una inflación del 35% en los tokens, sumada a la expansión de salida del nivel xhigh, puede hacer que la factura real sea entre un 20% y un 45% más alta que con la 4.6.
Solución: Volver a probar todas las rutas de código con la interfaz de conteo de tokens antes de migrar.
Limitación 2: Colapso en la capacidad de recuperación (recall) de contexto largo MRCR
Este es el problema más crítico. Al procesar documentos largos, grandes bases de código o conversaciones extensas, la precisión de recuperación de Opus 4.7 cae drásticamente.
Solución: Seguir usando Opus 4.6 para escenarios de documentos largos o cambiar a una estrategia de RAG + fragmentación.
Limitación 3: Seguimiento de instrucciones demasiado literal
Las indicaciones originales pueden producir cambios de salida inesperados.
Solución: Reescribir las indicaciones de forma sistemática, eliminando intenciones implícitas y utilizando restricciones explícitas.
Limitación 4: Aumento de juicios erróneos y alucinaciones en algunos escenarios
La comunidad ha reportado ampliamente problemas como la clasificación errónea de código en Claude Code y alucinaciones en documentos largos.
Solución: Combinar tareas críticas con revisión humana y utilizar validación cruzada con múltiples modelos para la lógica clave.
🎯 Recomendación de migración: Si tu negocio implica tanto tareas de codificación cortas como el procesamiento de documentos largos, te recomendamos utilizar la plataforma APIYI (apiyi.com) para enrutar diferentes versiones de Claude según el escenario. Esta plataforma admite la invocación unificada de múltiples modelos, permitiéndote combinar de forma flexible Opus 4.6 (para contexto largo) y 4.7 (para codificación/visual) en el mismo proyecto, evitando la degradación del rendimiento que supone una migración "drástica".
Práctica de invocación de la API de Claude Opus 4.7
Más allá del análisis teórico, presentamos ejemplos de código ejecutables para ayudarte a empezar rápidamente con Claude Opus 4.7.
Ejemplo minimalista (compatible con el SDK de OpenAI)
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="claude-opus-4-7",
messages=[
{"role": "user", "content": "Por favor, escribe un ejemplo de un crawler concurrente en Python"}
],
temperature=0.7,
max_tokens=4096
)
print(response.choices[0].message.content)
Ver código completo (incluye nivel de razonamiento xhigh, presupuestos de tareas y manejo de errores)
import openai
import time
from typing import Optional
class ClaudeOpusClient:
"""Envoltorio completo para la invocación de Claude Opus 4.7"""
def __init__(self, api_key: str, base_url: str = "https://api.apiyi.com/v1"):
self.client = openai.OpenAI(
api_key=api_key,
base_url=base_url
)
def generate(
self,
prompt: str,
model: str = "claude-opus-4-7",
effort: str = "xhigh",
task_budget: Optional[int] = None,
max_retries: int = 3
) -> str:
"""Invoca a Claude Opus 4.7 con soporte para nuevas características"""
extra_headers = {}
if task_budget:
extra_headers["task-budget-tokens"] = str(task_budget)
if effort:
extra_headers["reasoning-effort"] = effort
for attempt in range(max_retries):
try:
response = self.client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": prompt}],
max_tokens=8192,
extra_headers=extra_headers,
timeout=120
)
return response.choices[0].message.content
except openai.RateLimitError:
wait = 2 ** attempt
print(f"Límite de tasa alcanzado, esperando {wait}s...")
time.sleep(wait)
except openai.APIError as e:
print(f"Error de API: {e}")
if attempt == max_retries - 1:
raise
time.sleep(1)
raise RuntimeError("Se ha excedido el número máximo de reintentos")
def compare_versions(self, prompt: str) -> dict:
"""Invoca simultáneamente las versiones 4.6 y 4.7 para comparar"""
results = {}
for model in ["claude-opus-4-6", "claude-opus-4-7"]:
start = time.time()
results[model] = {
"output": self.generate(prompt, model=model),
"latency": time.time() - start
}
return results
if __name__ == "__main__":
client = ClaudeOpusClient(api_key="YOUR_API_KEY")
result = client.generate(
prompt="Refactoriza este código Python para que soporte concurrencia asíncrona",
effort="xhigh",
task_budget=50000
)
print(result)
🚀 Inicio rápido: El
base_urlen el código anterior apunta a la plataforma APIYI (apiyi.com). Esta plataforma ofrece un formato de interfaz totalmente compatible con el oficial de Claude, y permite la invocación paralela de Claude Opus 4.7 y 4.6, facilitando las pruebas A/B durante el periodo de migración.
Lista de verificación para la migración
Pasos obligatorios al migrar de Opus 4.6 a 4.7:
# 1. Reevaluar el límite de max_tokens (cambios en el Tokenizer)
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
# Invocar el Prompt principal con ambos modelos y registrar el consumo real de tokens
for model in ["claude-opus-4-6", "claude-opus-4-7"]:
resp = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": YOUR_PROMPT}],
max_tokens=4096
)
print(f"{model}: entrada={resp.usage.prompt_tokens}, salida={resp.usage.completion_tokens}")
# 2. Reevaluar escenarios de documentos largos (colapso de MRCR)
# Se recomienda mantener las tareas de documentos largos en 4.6 o usar fragmentación RAG
# 3. Auditar la intención implícita de los Prompts
# 4.7 ejecuta de forma estrictamente literal; es necesario cambiar la "lectura de intenciones" por restricciones explícitas
Preguntas frecuentes sobre Claude Opus 4.7
Q1: ¿Es realmente mejor Claude Opus 4.7 que la 4.6?
Depende del escenario:
- Tareas de codificación cortas/medias: 4.7 es notablemente mejor (SWE-bench Verified +6.8pt, CursorBench +12pt).
- Tareas visuales de alta definición: 4.7 supera ampliamente a la 4.6 (referencia visual del 54.5% al 98.5%).
- Cadenas de herramientas Agentic: 4.7 es más potente (MCP-Atlas mejora 13pt).
- Recuperación de contexto largo: 4.6 es claramente mejor (MRCR 78.3% vs 32.2%).
- Sensibilidad al costo: 4.6 es superior (la inflación de tokens en 4.7 puede llegar al 35%).
Si necesitas invocar ambas versiones en paralelo según el escenario, te recomendamos usar la plataforma APIYI (apiyi.com) para enrutar las versiones según el negocio; esta plataforma permite invocar toda la serie de modelos Claude con una sola clave API.
Q2: ¿Por qué algunos dicen que Claude Opus 4.7 es peor que la 4.6?
Existen cuatro razones principales:
- Refactorización del Tokenizer: El consumo de tokens para la misma tarea aumenta hasta un 35%, pero la mejora en capacidad no siempre compensa el costo.
- Caída en contexto largo (MRCR): Desciende del 78.3% al 32.2%, lo que supone un retroceso grave en el procesamiento de documentos extensos.
- Seguimiento de instrucciones demasiado literal: Los Prompts que "leían la intención" en la era 4.6 suelen fallar en la 4.7.
- Falsos positivos ocasionales en Claude Code: Algunos desarrolladores reportan que código legítimo es marcado como malicioso.
No son alucinaciones, sino diferencias de experiencia reales derivadas de cambios estructurales.
Q3: ¿Cómo migrar de forma segura de Opus 4.6 a 4.7?
Método de migración en tres pasos:
- Pruebas de carga paralelas: Invoca 4.6 y 4.7 simultáneamente en el 5–10% del tráfico de producción, comparando la calidad de salida, latencia y costo.
- Enrutamiento por escenario: Continúa usando 4.6 para documentos largos y bases de código grandes; cambia a 4.7 para codificación corta/media y tareas visuales.
- Aumento gradual: Del 10% → 30% → 50% → 100%, observando cada etapa durante 3–7 días.
Se recomienda utilizar la plataforma APIYI (apiyi.com) para estas pruebas de migración, ya que permite un enrutamiento flexible de modelos y asignación de tráfico.
Q4: ¿Cuándo debería usar el nivel xhigh de Claude Opus 4.7?
Anthropic recomienda usar xhigh por defecto en tareas de codificación y Agentic. Escenarios aplicables:
- Refactorización de código complejo.
- Depuración de errores en múltiples archivos.
- Generación de pruebas unitarias a gran escala.
- Tareas de cadenas de herramientas Agentic de múltiples pasos.
Escenarios no recomendables:
- Preguntas y respuestas simples (basta con medium).
- Solicitudes de alta concurrencia (xhigh tiene mayor latencia).
- Tareas sensibles al costo (xhigh aumenta significativamente los tokens de salida).
Q5: ¿Cómo usar los presupuestos de tareas (Task Budgets) y para qué sirven?
Los Task Budgets son una función en fase beta que se transmite a través de un encabezado HTTP:
task-budget-tokens: 50000
Escenarios aplicables:
- Ciclos de agentes de larga duración (necesidad de controlar el costo total).
- SaaS multi-inquilino (limitar el presupuesto por usuario).
- Tareas de automatización CI/CD (establecer un límite de tokens por trabajo).
El modelo ajustará automáticamente su profundidad de razonamiento según el presupuesto restante, finalizando con elegancia antes de agotarlo para evitar fallos a mitad de proceso.
Q6: ¿Es realmente tan potente la capacidad visual de Claude Opus 4.7?
Sí, y es una de las mejoras más significativas de la 4.7:
- Resolución máxima: Aumenta de 1.15 megapíxeles a 3.75 megapíxeles (3×).
- Referencia visual: Salta del 54.5% al 98.5%.
- Capacidad práctica: Puede leer directamente capturas de pantalla en 4K, diagramas de arquitectura, borradores de diseño de UI y documentos PDF escaneados.
Para equipos dedicados al desarrollo frontend, restauración de diseños o digitalización de documentos, esta es una actualización que puede transformar el flujo de trabajo.
¿Para quién es Claude Opus 4.7? Recomendaciones de decisión
Basándonos en el análisis completo, ofrecemos recomendaciones claras de uso:
Escenarios para migrar inmediatamente a Claude Opus 4.7
- ✅ Codificación y refactorización de archivos cortos y medianos: Los datos de SWE-bench y CursorBench lo dicen todo.
- ✅ Flujos de trabajo de agentes complejos: El respaldo doble de MCP-Atlas y Task Budgets.
- ✅ Procesamiento de imágenes de alta resolución: La capacidad visual de 3.75 MP supone un cambio cualitativo.
- ✅ Desarrollo rápido de prototipos: El nivel "xhigh" ofrece un rendimiento excelente en tareas de complejidad media.
Escenarios para seguir usando Claude Opus 4.6
- 🔒 Resumen y preguntas sobre documentos largos: El colapso de MRCR es inevitable.
- 🔒 Revisión de código a nivel de repositorio grande: La capacidad de recuperación en contextos largos es más estable.
- 🔒 Sensibilidad extrema a los costos de tokens: El tokenizador de la versión 4.6 es más económico.
- 🔒 Producción estable ya operativa: No se recomienda introducir riesgos de regresión solo por seguir la novedad.
Estrategia recomendada de uso mixto
Para la mayoría de los equipos, enrutar según el escenario es más práctico que una "migración total":
- Relacionado con documentos largos → Opus 4.6
- Codificación/Visión/Agentes → Opus 4.7
- Gestionar ambas versiones a través de una pasarela unificada para reducir los riesgos de migración.
💡 Recomendación final: Elegir entre Claude Opus 4.7 o seguir con la 4.6 depende principalmente de sus casos de uso específicos. Recomendamos realizar pruebas comparativas reales a través de la plataforma APIYI apiyi.com. Esta plataforma admite llamadas de interfaz unificadas para varios modelos principales, lo que facilita la comparación y el cambio rápido, permitiéndole mantener la flexibilidad del negocio durante el proceso de migración.
Resumen
Claude Opus 4.7 es una "actualización de compensaciones" típica: logra un verdadero salto en codificación, visión y capacidades de agentes, pero paga un precio evidente en la recuperación de contextos largos, eficiencia de tokens y compatibilidad de indicaciones.
Las discusiones en la comunidad durante el primer día de lanzamiento no son infundadas: Opus 4.7 es un modelo nuevo y potente, pero también un ajuste arquitectónico con costos asociados. Para los desarrolladores, la clave no es "¿migrar o no?", sino "¿en qué escenarios migrar?".
- Si trabaja en tareas de código complejas o análisis visual de alta resolución, la 4.7 es la mejor opción para el segundo trimestre de 2026.
- Si su negocio principal es el procesamiento de documentos largos o la inferencia sensible a los costos, mantenga la 4.6 por el momento.
- Durante el proceso de migración, recomendamos encarecidamente realizar pruebas de estrés en paralelo para evitar regresiones ocultas causadas por un enfoque de "talla única".
Le recomendamos experimentar rápidamente con Claude Opus 4.7 y 4.6 a través de la plataforma APIYI apiyi.com, la cual ofrece una interfaz unificada, monitoreo de facturación en tiempo real y capacidades de enrutamiento de múltiples modelos, siendo la opción ideal para pruebas de migración y despliegue en producción.
Referencias
-
Anuncio oficial de Anthropic: Presentación oficial de Claude Opus 4.7
- Enlace:
anthropic.com/news/claude-opus-4-7 - Descripción: Detalles sobre las capacidades principales y precios oficiales.
- Enlace:
-
Documentación oficial de la API de Claude: Guía de migración a Claude Opus 4.7
- Enlace:
platform.claude.com/docs/en/about-claude/models/migration-guide - Descripción: Recomendaciones oficiales de migración y cambios en el tokenizador.
- Enlace:
-
Blog de lanzamiento de AWS Bedrock: Claude Opus 4.7 disponible en Amazon Bedrock
- Enlace:
aws.amazon.com/blogs/aws/introducing-anthropics-claude-opus-4-7-model-in-amazon-bedrock - Descripción: Instrucciones de despliegue en plataformas de nube de terceros.
- Enlace:
-
Análisis de referencia de Vellum AI: Interpretación profunda de los benchmarks de Claude Opus 4.7
- Enlace:
vellum.ai/blog/claude-opus-4-7-benchmarks-explained - Descripción: Evaluación de referencia independiente realizada por terceros.
- Enlace:
-
GitHub Issue #47483: Comentarios de la comunidad sobre Claude Opus
- Enlace:
github.com/anthropics/claude-code/issues/47483 - Descripción: Experiencias de primera mano compartidas por desarrolladores.
- Enlace:
Autor: Equipo técnico de APIYI
Fecha de publicación: 17-04-2026
Modelos aplicables: Claude Opus 4.7 / Claude Opus 4.6
Intercambio técnico: Te invitamos a obtener cuotas de prueba a través de APIYI (apiyi.com) para comparar personalmente las diferencias entre las distintas versiones de Claude.