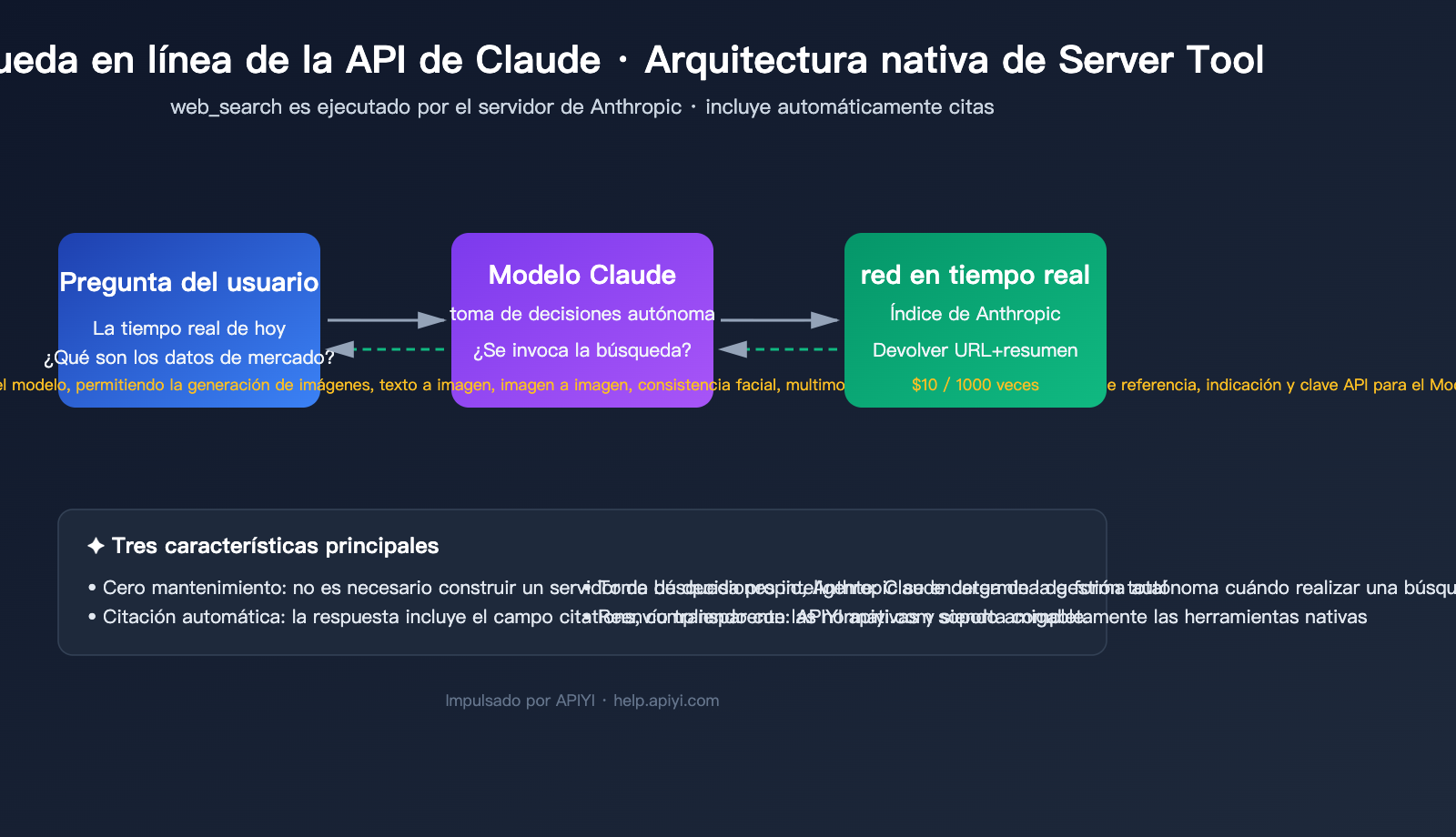
El conocimiento de los modelos tiene una fecha de corte, pero los problemas de negocio reales suelen requerir datos "actuales". En 2025, Claude lanzó oficialmente la herramienta nativa web_search, y en 2026 la actualizó a la versión web_search_20260209 con soporte para filtrado dinámico, transformando la búsqueda en internet de la API de Claude de un "proceso complejo de autoconstrucción" a "un simple parámetro".
Este artículo analiza sistemáticamente la implementación más reciente de la búsqueda en internet de la API de Claude en 2026, centrándose en los parámetros, facturación, limitaciones y plantillas de código de las herramientas oficiales web_search / web_fetch. También comparamos las ventajas y desventajas de tres rutas: MCP de terceros, RAG autoconstruido y la solución oficial. Al final, presentamos un ejemplo de integración mediante el servicio proxy de API APIYI (apiyi.com); solo necesitas reemplazar base_url y api_key para ejecutar todo el flujo desde entornos locales.
Puntos clave de la búsqueda en internet de la API de Claude
Antes de escribir código, aclaremos los conceptos. La búsqueda en internet de la API de Claude es, en esencia, una herramienta de servidor (Server Tool) proporcionada oficialmente por Anthropic. Esto significa que la búsqueda se ejecuta en la nube de Anthropic; no necesitas conectar una API de Google/Bing ni desplegar rastreadores.
Resumen de las tres soluciones principales
| Solución | Complejidad de integración | Costo | Tiempo real | Citas y cumplimiento |
|---|---|---|---|---|
Nativa oficial web_search |
★☆☆ (un campo tool) | $10 / 1000 solicitudes + token | Alta (índice en tiempo real de Anthropic) | Citas automáticas |
| MCP de terceros (ej. Brave/Tavily) | ★★☆ (requiere servidor MCP) | Facturación de API de búsqueda externa | Media-Alta | Gestión propia |
| Autoconstruido (Google CSE + invocación) | ★★★ (herramienta personalizada + parsing) | Cuota de API de Google | Media | Gestión total |
🎯 Recomendación: Si tu objetivo principal es "permitir que Claude responda sobre eventos recientes y obtenga datos en tiempo real", la herramienta nativa
web_searches la mejor opción actual: cero mantenimiento, cumplimiento de citas y cobertura para modelos principales como Sonnet 4.6 / Opus 4.7. Recomendamos integrarla directamente a través del servicio proxy de API APIYI (apiyi.com) para acceder a todas las capacidades de la interfaz oficial de Anthropic sin necesidad de VPN.
Matriz de modelos compatibles con la búsqueda en internet de Claude
No todos los modelos de Claude admiten web_search. La nueva versión web_search_20260209 tiene requisitos específicos para los modelos:
| Modelo | Versión base web_search_20250305 |
Versión filtrado dinámico web_search_20260209 |
|---|---|---|
| Claude Opus 4.7 | ✅ | ✅ |
| Claude Opus 4.6 | ✅ | ✅ |
| Claude Sonnet 4.6 | ✅ | ✅ |
| Claude Sonnet 4.5 | ✅ | ❌ |
| Claude Haiku 4.5 | ✅ | ❌ |
El filtrado dinámico (Dynamic Filtering) es la actualización central de la versión 2026: Claude utiliza una herramienta de ejecución de código para filtrar los resultados de búsqueda antes de que entren en la ventana de contexto, conservando solo los fragmentos relevantes. Para la recuperación de documentos largos y revisiones de literatura técnica, esto reduce significativamente el consumo de tokens.
Guía detallada de las herramientas nativas para la búsqueda web en la API de Claude
Anthropic ofrece dos herramientas nativas complementarias. Entender sus límites es el requisito fundamental para aprovechar al máximo la búsqueda web en la API de Claude.
División de tareas entre web_search y web_fetch
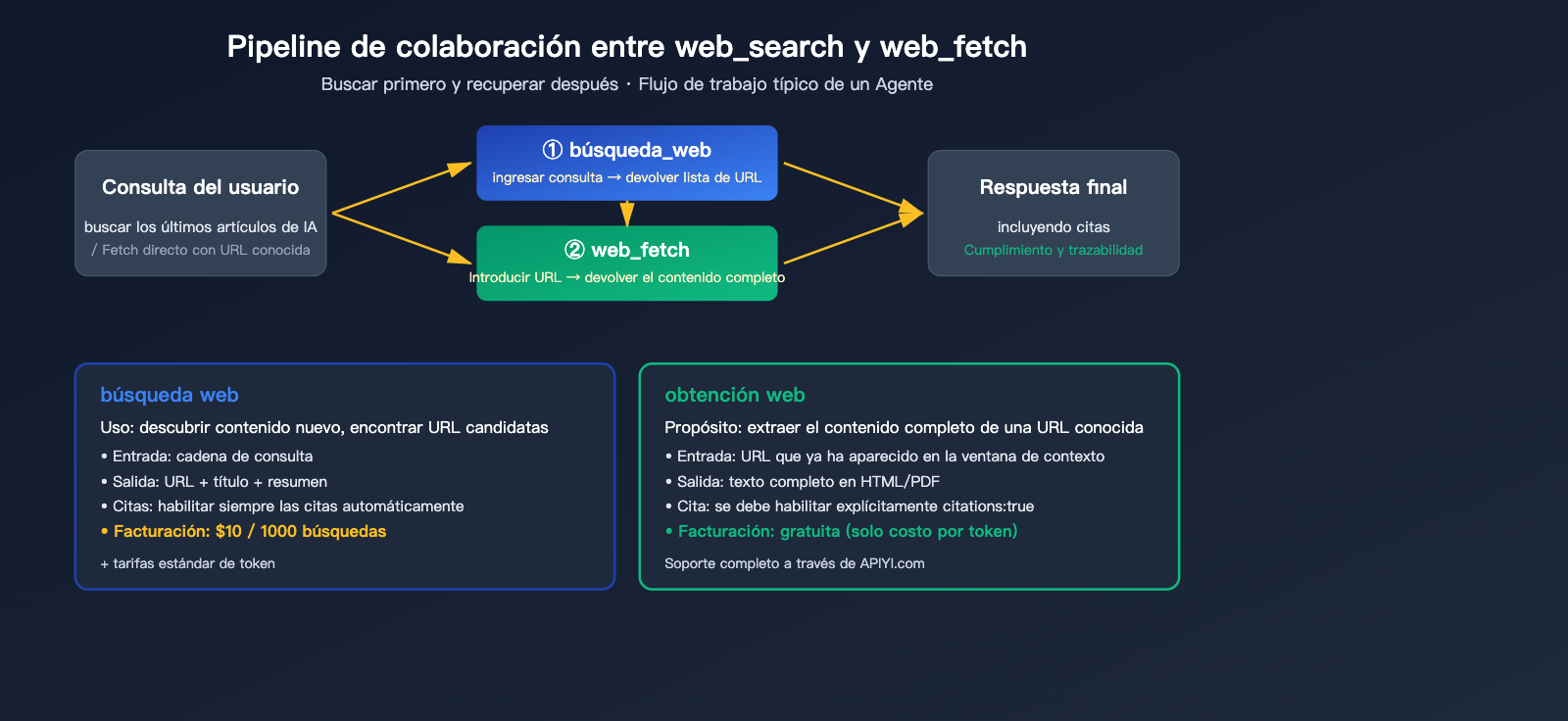
| Herramienta | Uso | Entrada | Salida | Facturación |
|---|---|---|---|---|
web_search |
Descubrir contenido nuevo | Cadena de consulta | URL + Título + Resumen | $10 / 1000 usos |
web_fetch |
Extraer texto completo de una URL conocida | Cadena de URL | HTML completo / Texto PDF | Gratis (solo se cobra por tokens) |
🎯 Consejo de arquitectura: El flujo de trabajo típico de un agente es "primero buscar, luego extraer":
web_searchidentifica las páginas candidatas yweb_fetchobtiene el texto completo de las más relevantes. Si el usuario ya proporcionó una URL (por ejemplo, "analiza este artículo en example.com/articulo"), usa directamenteweb_fetchy así no consumirás cuota de búsqueda. En APIYI (apiyi.com), ambas herramientas son compatibles de forma transparente, sin necesidad de configuración adicional.
Definición completa de parámetros de la herramienta web_search
La siguiente tabla detalla los parámetros JSON oficiales; combínalos según tus necesidades:
| Parámetro | Tipo | Obligatorio | Por defecto | Descripción |
|---|---|---|---|---|
type |
string | ✅ | – | Fijo como web_search_20250305 o web_search_20260209 |
name |
string | ✅ | – | Fijo como web_search |
max_uses |
integer | ❌ | Sin límite | Número máximo de búsquedas permitidas por solicitud |
allowed_domains |
string[] | ❌ | – | Solo permite resultados de estos dominios (excluyente con blocked) |
blocked_domains |
string[] | ❌ | – | Prohíbe resultados de estos dominios |
user_location |
object | ❌ | – | Ubicación aproximada del usuario para búsquedas locales |
Estructura de campos de user_location:
{
"type": "approximate",
"city": "Shanghai",
"region": "Shanghai",
"country": "CN",
"timezone": "Asia/Shanghai"
}
Manejo de errores en la búsqueda web de la API de Claude
Cuando una búsqueda falla, la API de Anthropic sigue devolviendo un HTTP 200, y la información del error se encuentra dentro del cuerpo de la respuesta en web_search_tool_result. Asegúrate de identificar estos códigos de error en tu código cliente:
| Código de error | Significado | Sugerencia de manejo |
|---|---|---|
too_many_requests |
Límite de tasa alcanzado | Realiza un reintento con retroceso, reduce la concurrencia |
max_uses_exceeded |
Límite de max_uses superado |
Aumenta el límite o divide la solicitud |
query_too_long |
Cadena de consulta demasiado larga | Recorta o reescribe la consulta |
invalid_input |
Formato de parámetro incorrecto | Verifica la estructura JSON |
unavailable |
Error interno de Anthropic | Reintenta tras un breve periodo |
⚠️ Nota sobre facturación: Las solicitudes fallidas de
web_searchno se facturan. Sin embargo, si una búsqueda tuvo éxito antes de que ocurriera un fallo posterior, la llamada exitosa sí se contabilizará a $10 / 1000 usos. Te recomendamos revisar el detalle de facturación en el panel de control de APIYI (apiyi.com) para detectar consumos inusuales.
Primeros pasos con la búsqueda web de la API de Claude
A continuación, te mostramos cómo ejecutar el flujo completo con el mínimo código posible. Todos los ejemplos utilizan la interfaz de reenvío transparente de APIYI (apiyi.com); no necesitas modificar ninguna lógica de negocio, solo apunta la base_url al nodo de proxy y reemplaza ANTHROPIC_API_KEY con tu clave API de APIYI.
Ejemplo minimalista con cURL
Solicitud mínima ejecutable para la búsqueda web de la API de Claude:
curl https://vip.apiyi.com/v1/messages \
-H "x-api-key: $APIYI_API_KEY" \
-H "anthropic-version: 2023-06-01" \
-H "content-type: application/json" \
-d '{
"model": "claude-sonnet-4-6",
"max_tokens": 1024,
"messages": [
{"role": "user", "content": "Resume en español cuáles son los modelos más recientes lanzados por OpenAI en abril de 2026"}
],
"tools": [{
"type": "web_search_20250305",
"name": "web_search",
"max_uses": 5
}]
}'
La estructura de respuesta incluirá tres bloques: el texto de decisión de Claude, server_tool_use (la consulta ejecutada), web_search_tool_result (lista de URLs) y la respuesta final con citations.
Ejemplo completo con el SDK de Python (incluyendo web_fetch)
import anthropic
client = anthropic.Anthropic(
base_url="https://vip.apiyi.com",
api_key="sk-tu-clave-apiyi",
)
response = client.messages.create(
model="claude-opus-4-7",
max_tokens=4096,
messages=[{
"role": "user",
"content": "Busca artículos sobre evaluación de agentes de IA del último mes y haz un resumen detallado del más relevante"
}],
tools=[
{
"type": "web_search_20260209",
"name": "web_search"
},
{
"type": "web_fetch_20260209",
"name": "web_fetch",
"max_uses": 3,
"citations": {"enabled": True}
}
]
)
for block in response.content:
if block.type == "text":
print(block.text)
elif block.type == "server_tool_use":
print(f"[Llamada a herramienta] {block.name}: {block.input}")
🎯 Consejo de código: Hemos utilizado una combinación dinámica de
web_search_20260209+web_fetch_20260209. Junto con Claude Opus 4.7, esto reduce significativamente el consumo de tokens en escenarios de documentos largos. Si solo necesitas respuestas rápidas, cambia el modelo aclaude-sonnet-4-6y usa la versión básicaweb_search_20250305para reducir costos. Todas las llamadas se reenvían a través de APIYI (apiyi.com) con la misma estabilidad que la oficial.
Ejemplo con TypeScript / Node.js
import Anthropic from "@anthropic-ai/sdk";
const client = new Anthropic({
baseURL: "https://vip.apiyi.com",
apiKey: process.env.APIYI_API_KEY,
});
const response = await client.messages.create({
model: "claude-sonnet-4-6",
max_tokens: 2048,
messages: [
{ role: "user", content: "¿Qué tiempo hace hoy en Shanghái?" }
],
tools: [{
type: "web_search_20250305",
name: "web_search",
max_uses: 3,
user_location: {
type: "approximate",
city: "Shanghai",
region: "Shanghai",
country: "CN",
timezone: "Asia/Shanghai"
}
}]
});
console.log(response.content);
Manejo de respuestas en streaming
Al activar stream: true, el proceso de búsqueda se enviará en tiempo real mediante eventos SSE. Notarás una "pausa" durante la ejecución de la búsqueda, ya que Claude está esperando a que el servidor de Anthropic complete la tarea:
with client.messages.stream(
model="claude-sonnet-4-6",
max_tokens=2048,
messages=[{"role": "user", "content": "Consulta el precio más reciente de Claude 4.7"}],
tools=[{"type": "web_search_20250305", "name": "web_search", "max_uses": 2}]
) as stream:
for event in stream:
if event.type == "content_block_start":
block = event.content_block
if block.type == "server_tool_use":
print(f"\n[Buscando] La consulta comenzará a fluir...")
elif block.type == "web_search_tool_result":
print(f"[Búsqueda completada] {len(block.content)} resultados encontrados")
elif event.type == "content_block_delta":
if hasattr(event.delta, "text"):
print(event.delta.text, end="", flush=True)
Comparativa y selección de soluciones para búsqueda web con la API de Claude
Tras conocer las interfaces oficiales, pasemos a la toma de decisiones. Existen tres caminos para implementar la búsqueda web con la API de Claude, cada uno con sus escenarios de uso ideales.

Opción A: web_search nativo oficial (Recomendado)
Ventajas:
- Cero mantenimiento: Sin necesidad de servidores propios, todo gestionado por Anthropic.
- Citas automáticas: Cada respuesta incluye
citationsautomáticamente, ideal para el cumplimiento normativo. - Integración total: Claude decide por sí mismo cuándo buscar y qué buscar.
- Facturación transparente: $10 por cada 1000 solicitudes, consolidado en la factura de Anthropic.
Desventajas:
- Limitado a las fuentes indexadas por Anthropic (no se puede cambiar el motor de búsqueda).
- Restricciones en algunas versiones de modelos (Haiku/Sonnet antiguo solo soportan la versión básica).
Escenarios de uso: 90% de los agentes conversacionales generales, asistentes de preguntas y respuestas y tareas de investigación.
Opción B: Servicio MCP de terceros (Brave/Tavily/Serper, etc.)
A través del Model Context Protocol, puedes iniciar un servidor MCP local o remoto para inyectar capacidades de búsqueda en Claude:
# Ejemplo con Tavily MCP, requiere ejecutar primero: npm install -g @tavily/mcp-server
claude mcp add tavily-search npx -- @tavily/mcp-server
Ventajas:
- Libertad para elegir el motor de búsqueda (Brave para privacidad, Tavily para optimización con LLM).
- Personalizable: Puedes limpiar los resultados o añadir metadatos.
- Soporte nativo en clientes como Claude Code o Cursor.
Desventajas:
- Requiere mantener un proceso de servidor MCP adicional.
- Los resultados de búsqueda no generan automáticamente
citationsbajo el estándar de Anthropic. - Debes gestionar por tu cuenta las cuotas y facturación de la API de búsqueda de terceros.
Escenarios de uso: Si ya tienes cuentas empresariales en Brave/Tavily o necesitas una personalización profunda del motor de búsqueda.
Opción C: Invocación de herramientas personalizada (Google CSE + Custom Tool)
El enfoque más tradicional: defines una tool propia, realizas la llamada a Google Custom Search / Bing API desde tu código backend e insertas los resultados en los messages:
tools = [{
"name": "google_search",
"description": "Busca en Google y devuelve los N mejores resultados",
"input_schema": {
"type": "object",
"properties": {
"query": {"type": "string"}
},
"required": ["query"]
}
}]
Ventajas: Control total, permite integrar búsquedas en intranets corporativas o bases de conocimiento privadas.
Desventajas: Debes encargarte del diseño de la indicación, el orden de los resultados, la generación de citas y la gestión de reintentos. Además, Claude no llamará a la herramienta "automáticamente"; requiere una guía explícita en el system prompt.
Escenarios de uso: Escenarios empresariales que requieren un cumplimiento estricto, alta personalización o conexión con fuentes de datos privadas.
Árbol de decisiones para las tres opciones
| Tu necesidad | Solución recomendada |
|---|---|
| Quieres rapidez y funcionalidad estándar | Opción A web_search nativo |
| Necesitas cambiar el motor de búsqueda (privacidad/cumplimiento) | Opción B MCP de terceros |
| Debes conectar fuentes de datos privadas | Opción C Herramienta personalizada + RAG |
| El acceso a Anthropic es inestable en tu región | Opción A + APIYI apiyi.com (proxy transparente) |
🎯 Nota especial para desarrolladores: El acceso a la API oficial de Anthropic puede ser inestable en ciertas regiones y requiere un número de teléfono extranjero para el registro. Recomendamos utilizar el servicio proxy de API de APIYI (apiyi.com), que transmite de forma transparente todas las Server Tools de Anthropic (incluyendo
web_search,web_fetchycode_execution). Tu código no requiere modificaciones: simplemente cambia labase_urlahttps://vip.apiyi.comy utiliza tu clave API de APIYI.
Uso avanzado de la búsqueda web con la API de Claude
Lista blanca de dominios: para una "búsqueda vertical"
¿Necesitas que Claude busque únicamente en dominios específicos? Usa allowed_domains:
tools=[{
"type": "web_search_20250305",
"name": "web_search",
"max_uses": 5,
"allowed_domains": [
"docs.python.org",
"pypi.org",
"github.com"
]
}]
Ten en cuenta algunas limitaciones:
allowed_domainsyblocked_domainsno pueden usarse al mismo tiempo.- Los subdominios son coincidencias exactas:
docs.example.comno incluiráapi.example.com. - Las restricciones de dominio a nivel de solicitud deben ser compatibles con la configuración a nivel de organización; no pueden ampliar el alcance definido por los administradores de la organización.
Habilitar citas con web_fetch
web_search tiene las citas activadas por defecto, pero web_fetch requiere que se habiliten explícitamente:
{
"type": "web_fetch_20250910",
"name": "web_fetch",
"max_uses": 5,
"citations": {"enabled": True},
"max_content_tokens": 50000
}
max_content_tokens se utiliza para truncar documentos extremadamente grandes y evitar que una sola extracción sature la ventana de contexto. Valores de referencia:
| Tipo de contenido | Tamaño | Tokens aprox. |
|---|---|---|
| Página web normal | 10 KB | ~2,500 |
| Página de documento grande | 100 KB | ~25,000 |
| PDF de investigación | 500 KB | ~125,000 |
encrypted_content en conversaciones multironda
Cada resultado devuelto por web_search incluye un campo encrypted_content. Si quieres que Claude siga citando resultados de búsqueda anteriores en una conversación multironda, debes devolver este campo tal cual; de lo contrario, se perderá el contexto de las citas en las siguientes rondas.
messages.append({
"role": "assistant",
"content": previous_response.content # Conservar íntegramente, incluyendo encrypted_content
})
messages.append({
"user",
"content": "Analiza detalladamente el segundo artículo que encontraste hace un momento"
})
🎯 Consejo técnico: Al integrar con marcos de trabajo de agentes (como LangChain o LlamaIndex), asegúrate de que el marco transmita completamente todos los bloques de contenido de la respuesta de Claude. Muchos marcos "limpian" campos como
server_tool_use, lo que invalida las citas. Recomendamos construir directamente sobre el SDK de Anthropic y realizar la invocación del modelo a través de APIYI (apiyi.com) para garantizar un comportamiento idéntico al oficial.
Casos de uso prácticos de la búsqueda web con la API de Claude
Ahora que conocemos la teoría, veamos algunas combinaciones de mejores prácticas para la búsqueda web con la API de Claude en escenarios de negocio reales.
Escenario 1: Asistente de noticias en tiempo real
Si un usuario pregunta "¿Cómo va la bolsa hoy?", obviamente se necesitan datos en tiempo real. Estrategia de configuración:
response = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=1024,
system="Eres un asistente financiero. Cuando se trate de cotizaciones o noticias en tiempo real, utiliza siempre web_search. Las respuestas deben incluir citas.",
messages=[{"role": "user", "content": "¿A cuánto cerró hoy el índice SSE y cómo fue la variación?"}],
tools=[{
"type": "web_search_20250305",
"name": "web_search",
"max_uses": 3,
"allowed_domains": ["sina.com.cn", "eastmoney.com", "163.com"],
"user_location": {
"type": "approximate",
"country": "CN",
"timezone": "Asia/Shanghai"
}
}]
)
Puntos clave: Usa allowed_domains para fijar sitios financieros autorizados y user_location para que Claude priorice resultados en chino.
Escenario 2: Mejora de RAG para documentación técnica
Permite que Claude priorice la búsqueda en la documentación oficial al responder preguntas técnicas:
response = client.messages.create(
model="claude-opus-4-7",
max_tokens=4096,
messages=[{
"role": "user",
"content": "¿Cómo implementar el mantenimiento de conexión (heartbeat) de WebSocket en FastAPI? Dame un ejemplo completo"
}],
tools=[
{
"type": "web_search_20260209",
"name": "web_search",
"max_uses": 5,
"allowed_domains": [
"fastapi.tiangolo.com",
"docs.python.org",
"github.com",
"stackoverflow.com"
]
},
{
"type": "web_fetch_20260209",
"name": "web_fetch",
"max_uses": 3,
"citations": {"enabled": True}
}
]
)
Puntos clave: Usa el filtrado dinámico de web_search_20260209 para eliminar HTML irrelevante y luego utiliza web_fetch para extraer el texto completo de la documentación oficial más relevante.
Escenario 3: Asistente de investigación académica
Para escenarios que requieren citas estrictas y análisis de contexto largo, recomendamos Opus 4.7 + doble herramienta:
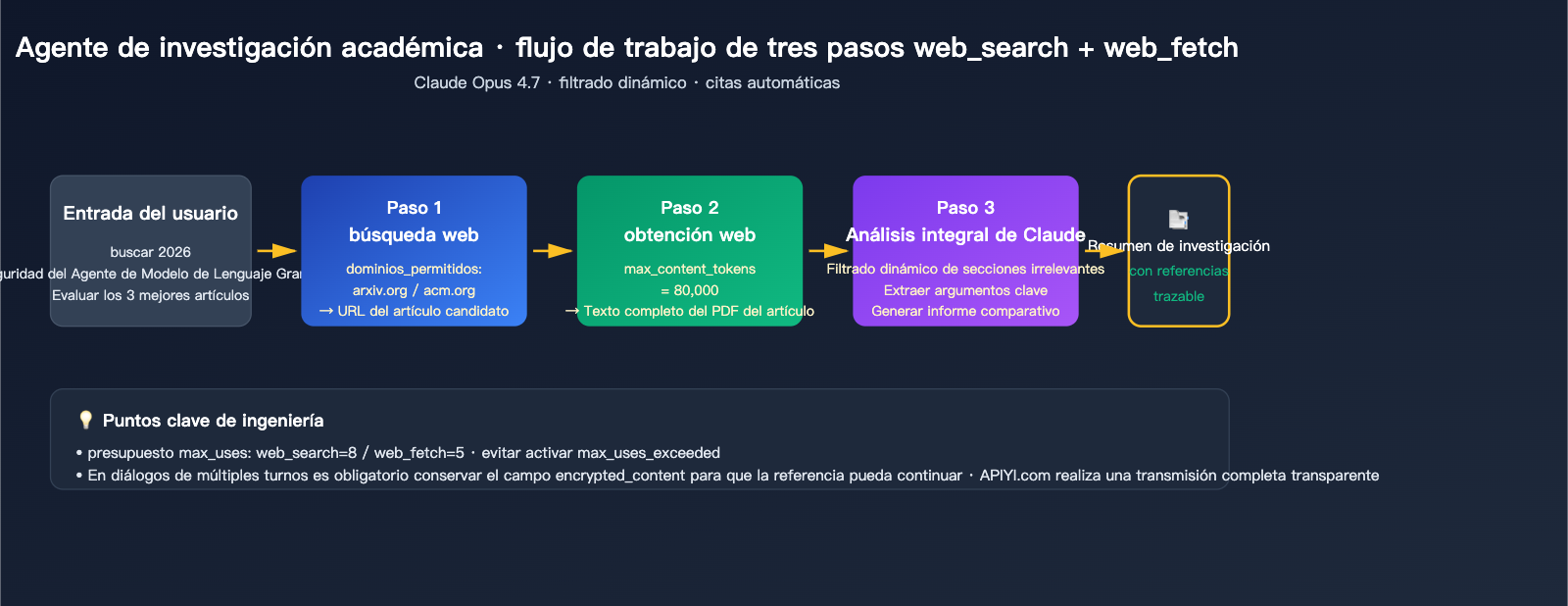
response = client.messages.create(
model="claude-opus-4-7",
max_tokens=8192,
messages=[{
"role": "user",
"content": "Busca artículos de 2026 sobre la evaluación de seguridad de agentes LLM, selecciona los 3 mejores y haz una comparativa integral"
}],
tools=[
{
"type": "web_search_20260209",
"name": "web_search",
"max_uses": 8,
"allowed_domains": ["arxiv.org", "openreview.net", "acm.org"]
},
{
"type": "web_fetch_20260209",
"name": "web_fetch",
"max_uses": 5,
"citations": {"enabled": True},
"max_content_tokens": 80000
}
]
)
🎯 Sugerencia por escenario: Cada negocio tiene prioridades distintas respecto a la calidad de búsqueda, cumplimiento de citas y costos. Recomendamos crear una clave API independiente para cada caso de uso en APIYI (apiyi.com), lo que facilita desglosar los datos de facturación y monitorear el uso real de búsquedas y el consumo de tokens por escenario, en lugar de mezclar todas las invocaciones.
Mejores prácticas de ingeniería para la búsqueda web con la API de Claude
Hacer funcionar una demo no es difícil, pero llevar la búsqueda web de la API de Claude a un entorno de producción real requiere superar algunos obstáculos.
Práctica 1: Optimización de costes con prompt caching
Aunque la definición de la herramienta de servidor (Server Tool) es breve, supone un coste fijo considerable cuando se combina con un system prompt. Activa el prompt caching:
response = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=2048,
system=[{
"type": "text",
"text": "Eres un asistente de investigación profesional...(se omiten 500 palabras del system prompt)",
"cache_control": {"type": "ephemeral"}
}],
messages=[...],
tools=[
{
"type": "web_search_20250305",
"name": "web_search",
"max_uses": 5,
"cache_control": {"type": "ephemeral"}
}
]
)
Prueba real: en solicitudes repetidas dentro de un margen de 5 minutos, el coste de tokens de la parte de system + tools puede reducirse hasta en un 90%.
Práctica 2: Respuestas en streaming para evitar tiempos de espera
Una ejecución única de web_search puede tardar entre 5 y 15 segundos. Si tus servicios intermedios (puerta de enlace, cliente) tienen un límite de tiempo de espera de 30 segundos, asegúrate de habilitar stream=True para mantener la conexión activa mediante un "latido" (heartbeat) de streaming.
Práctica 3: Consistencia en múltiples turnos con encrypted_content
En conversaciones de varios turnos, Claude puede citar resultados de búsquedas anteriores. Es obligatorio conservar el array completo de content de todos los mensajes del asistente anteriores en cada solicitud, no te limites a guardar solo la parte de texto:
# ❌ Práctica incorrecta
messages.append({"role": "assistant", "content": response.content[-1].text})
# ✅ Práctica correcta
messages.append({"role": "assistant", "content": response.content})
Práctica 4: Límites de tasa y estrategias de reintento
El límite de tasa de web_search es independiente de la interfaz de mensajes estándar. Se recomienda implementar una lógica de reintento con retroceso exponencial (exponential backoff) a nivel de SDK:
| Código de error | Estrategia de reintento | Máx. reintentos |
|---|---|---|
too_many_requests |
Retroceso exponencial (2s/4s/8s) | 3 |
unavailable |
Retraso fijo (5s) | 2 |
max_uses_exceeded |
No reintentar, aumentar max_uses | – |
query_too_long |
No reintentar, truncar query | – |
🎯 Consejo para producción: Registra todas las respuestas de error de
web_searchen tu sistema de monitoreo y analiza periódicamente la proporción detoo_many_requests; este es el indicador clave para evaluar si necesitas escalar la concurrencia. Al realizar la invocación del modelo a través de la plataforma APIYI (apiyi.com), puedes consultar directamente en el panel de control la tasa de éxito de las solicitudes, el tiempo medio de respuesta y otras métricas críticas para facilitar las operaciones.
Preguntas frecuentes (FAQ) sobre la búsqueda web de la API de Claude
P1: ¿El servicio proxy de API de APIYI admite web_search nativo? ¿Debo modificar el código?
Sí, lo admite y no necesitas cambiar el código. APIYI (apiyi.com) utiliza una arquitectura de reenvío transparente, transmitiendo íntegramente todas las herramientas de servidor oficiales de Anthropic. Solo tienes que cambiar la base_url a https://vip.apiyi.com y sustituir la clave API por la de APIYI. Tu código original funcionará sin tocar una sola línea, incluyendo todas las herramientas nativas como web_search, web_fetch o code_execution.
P2: ¿Cómo se factura web_search? ¿Es caro $10 por cada 1000 búsquedas?
Cada búsqueda cuesta $0.01, independientemente de cuántos resultados devuelva. Las búsquedas fallidas no se cobran. Comparativa: Tavily cuesta $0.005/búsqueda, Brave $0.006/búsqueda y Google CSE $0.005/consulta (tras superar la cuota gratuita). La búsqueda web nativa es ligeramente más cara, pero ahorra los costes de ingeniería de mantenimiento del servidor MCP y el cumplimiento de las normativas de citas, lo que suele ser más rentable para equipos pequeños y medianos.
P3: ¿Por qué recibo el error max_uses_exceeded?
Claude puede invocar web_search varias veces en una sola conversación (toma sus propias decisiones sobre cuántas veces buscar). Si estableces "max_uses": 1 y la pregunta requiere 3 búsquedas para ser respondida, se activará este error. Se recomienda asignar un presupuesto de 5 a 10 usos para preguntas complejas, y dejar 1 o 2 para preguntas sencillas.
P4: ¿Puede web_search buscar en páginas web en español?
Sí. web_search utiliza el índice en tiempo real de Anthropic, que tiene una excelente cobertura de contenido en español. Si deseas limitar la búsqueda a sitios en español, puedes combinarlo con la lista blanca allowed_domains.
P5: El consumo de tokens es muy alto al investigar artículos largos con web_search, ¿cómo optimizarlo?
Tres direcciones de optimización:
- Utiliza la versión de filtrado dinámico
web_search_20260209(requiere Claude Opus/Sonnet 4.6+), que descarta automáticamente los fragmentos irrelevantes. - Utiliza el parámetro
max_content_tokensdeweb_fetchpara limitar el límite de extracción por página. - Activa el prompt caching para almacenar la definición de la herramienta y el system prompt, reduciendo el coste de las solicitudes repetidas.
P6: ¿Se pueden mezclar las soluciones de búsqueda MCP de terceros con web_search nativo?
Sí. Claude permite definir varias herramientas a la vez, pero ten cuidado de escribir descripciones claras para diferenciar las herramientas; por ejemplo, describe tavily_search de MCP como "búsqueda de artículos académicos" y web_search nativo como "búsqueda web general". Claude elegirá basándose en la descripción. Sin embargo, para reducir ambigüedades, recomendamos usar una única herramienta de búsqueda por escenario.
P7: ¿Qué hago si la búsqueda web de la API de Claude falla al invocarla desde China?
Hay dos razones principales: la inestabilidad de la red al conectar directamente con la API de Anthropic y el hecho de que el backend de Anthropic puede bloquear IPs de China continental al ejecutar web_search. La solución más directa es utilizar el servicio proxy de API de APIYI (apiyi.com): todas las solicitudes de web_search se reenvían a través de los nodos extranjeros de APIYI hacia Anthropic, y la respuesta se devuelve al origen, manteniendo la misma estabilidad que una conexión directa desde el extranjero.
Resumen de soluciones y recomendaciones para la búsqueda web con la API de Claude
Repasando todo el contenido, la búsqueda web con la API de Claude ha alcanzado en 2026 un nivel de madurez "listo para usar". Una decisión rápida:
✅ Para el 80% de los proyectos, la función nativa
web_searchoficial es suficiente: configuración sencilla, citas conformes a las normas y mantenimiento por parte de Anthropic. Solo considera MCP de terceros o herramientas personalizadas para el 20% restante que requiera una personalización profunda.
Lista de acciones para la implementación
Si estás listo para integrar la búsqueda web con la API de Claude en tu proyecto hoy mismo:
- Elige el modelo: Usa
claude-sonnet-4-6para escenarios generales (mejor relación calidad-precio) yclaude-opus-4-7para investigaciones complejas. - Elige la versión de la herramienta: Prioriza
web_search_20260209(filtrado dinámico) y recurre aweb_search_20250305para modelos antiguos. - Diseña
max_uses: De 1 a 3 veces para preguntas y respuestas simples, y de 5 a 10 veces para investigaciones complejas. - Combínalo con
web_fetch: Cuando necesites un análisis de texto completo, úsalo junto conweb_fetchpara extraer las páginas candidatas. - Configura el acceso: Desde China, utiliza el servicio proxy de API de APIYI (apiyi.com) para una retransmisión transparente, sin necesidad de VPN y sin modificar el código.
🎯 Recomendación final: La clave de la búsqueda web con la API de Claude no es "si se puede usar", sino "cómo equilibrar la calidad de los resultados de búsqueda, el costo de los tokens y la latencia de respuesta". Te sugerimos probar primero con algunos casos de uso reales en la plataforma APIYI (apiyi.com), contabilizar el número real de búsquedas y el consumo de tokens por conversación, y luego decidir si implementar optimizaciones avanzadas como el almacenamiento en caché de indicaciones (prompt caching) o el filtrado dinámico. La plataforma es compatible con toda la gama de modelos de Claude y herramientas de servidor nativas, lo que facilita una iteración rápida.
Autor: Equipo técnico de APIYI | Para más tutoriales prácticos sobre la API de Claude, visita help.apiyi.com