Nota del autor: Análisis profundo de los errores "overloaded" (sobrecargado) y "service unavailable" (servicio no disponible) de la API Gemini Nano Banana Pro, incluyendo causas, patrones temporales, soluciones prácticas y mejores prácticas para entornos de producción.
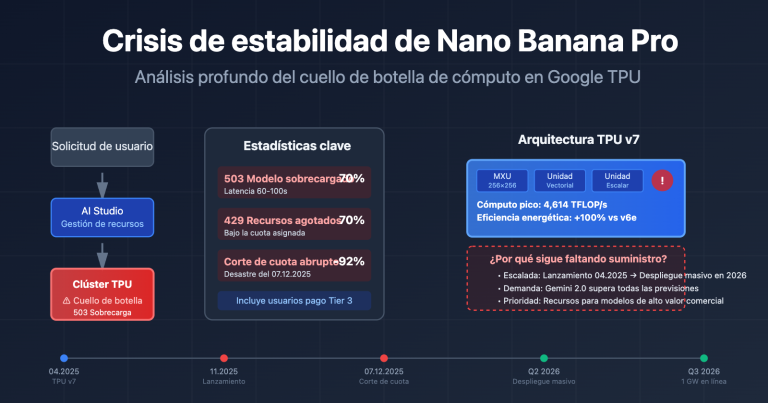
El 16 de enero de 2026 a las 00:18 (hora local), una gran cantidad de desarrolladores informaron errores de «The model is overloaded. Please try again later.» e incluso «The service is currently unavailable.» en la API Gemini Nano Banana Pro (nombre del modelo gemini-3-pro-image-preview). Esto no es un problema de código, sino un fallo sistémico provocado por cuellos de botella en la capacidad de cómputo de los servidores de Google.
Valor principal: Al terminar de leer este artículo, entenderás las causas fundamentales, los patrones temporales y los mecanismos técnicos de estos dos tipos de errores. Dominarás 5 soluciones prácticas y aprenderás a construir estrategias de tolerancia a fallos de nivel de producción.

Puntos clave de los errores de la API Gemini Nano Banana Pro
| Punto clave | Descripción | Impacto |
|---|---|---|
| Error 503 Overloaded | Recursos de cómputo insuficientes en el servidor, no es un problema de código | El 45% de las llamadas a la API fallan en horas pico |
| Error 503 vs 429 | El 503 es un problema de capacidad; el 429 es un límite de velocidad | El 503 tarda 30-120 min en recuperarse; el 429 solo 1-5 min |
| Limitación del modelo Preview | La serie Gemini 3 aún está en fase de vista previa (preview) | Recursos limitados y gestión de capacidad inestable |
| Patrones temporales | Tasa de fallos máxima en la madrugada y horas pico nocturnas | Requiere evitar horas pico o implementar degradación |
| Aumento del tiempo de respuesta | 20-40 segundos normalmente; 60-100+ segundos en fallos | Se requiere configurar un timeout más largo (120s+) |
Análisis detallado de los errores de Gemini Nano Banana Pro
¿Qué es Nano Banana Pro?
Gemini Nano Banana Pro es el modelo de generación de imágenes de máxima calidad de Google. El nombre del modelo correspondiente en la API es gemini-2.0-flash-preview-image-generation o gemini-3-pro-image-preview. Como modelo insignia de generación de imágenes de la serie Gemini 3, supera significativamente a Gemini 2.5 Flash Image en calidad de imagen, detalle y renderizado de texto, pero esto también lo hace enfrentar cuellos de botella de recursos de cómputo más severos.
¿Por qué ocurren errores con tanta frecuencia?
Según los datos de discusión de los foros de desarrolladores de Google AI, los problemas de error de Nano Banana Pro comenzaron a aparecer con frecuencia en la segunda mitad de 2025 y aún no se han resuelto por completo a principios de 2026. Las razones fundamentales incluyen:
- Restricciones de recursos en fase Preview: Los modelos de la serie Gemini 3 todavía se encuentran en la fase Pre-GA (antes de la disponibilidad general), por lo que Google asigna recursos de cómputo limitados.
- Gestión dinámica de capacidad: Incluso si no has alcanzado tu límite de velocidad (Rate Limit), el sistema puede devolver un error 503 si la carga global es demasiado alta.
- Competencia global de usuarios: Todos los desarrolladores comparten el mismo grupo de recursos de cómputo; en horas pico, la demanda supera con creces la oferta.
- Cómputo intensivo del modelo: La generación de imágenes de alta calidad requiere una enorme potencia de GPU. Una sola solicitud tarda entre 20 y 40 segundos, mucho más que los modelos de texto.
Diferencia entre errores 503 y 429
| Tipo de error | Código HTTP | Mensaje de error | Causa raíz | Tiempo de recuperación | Proporción |
|---|---|---|---|---|---|
| Sobrecargado | 503 | The model is overloaded |
Capacidad de cómputo insuficiente en el servidor | 30-120 minutos | ~25% |
| Límite de velocidad | 429 | RESOURCE_EXHAUSTED |
Superación de cuota de usuario (RPM/TPM/RPD) | 1-5 minutos | ~70% |
| No disponible | 503 | Service unavailable |
Fallo sistémico o mantenimiento | Incierto (posiblemente horas) | ~5% |
Análisis de los patrones de error en Gemini Nano Banana Pro
Horarios pico de fallos
Según los datos reportados por diversos desarrolladores, los fallos en la API de Nano Banana Pro presentan un patrón temporal bastante claro:
Horarios de alto riesgo (Hora de Beijing):
- 00:00 – 02:00: Horario laboral de la costa oeste de EE. UU. (08:00-10:00 PST), pico de desarrolladores en América y Europa.
- 09:00 – 11:00: Inicio de la jornada laboral en China continental, pico de desarrolladores en Asia.
- 20:00 – 23:00: Pico nocturno en China continental coincidiendo con la tarde en Europa.
Periodos relativamente estables:
- 03:00 – 08:00: Periodo con menor cantidad de usuarios a nivel global.
- 14:00 – 17:00: Tarde en China y madrugada en EE. UU., carga de trabajo reducida.
Validación de casos: El fallo masivo ocurrido el 16 de enero de 2026 a las 00:18 (hora de Beijing) coincidió exactamente con el inicio de la jornada laboral en la costa oeste de EE. UU. (15 de enero, 08:18 PST), lo que confirma la precisión de estos patrones temporales.

5 formas de solucionar errores en Gemini Nano Banana Pro
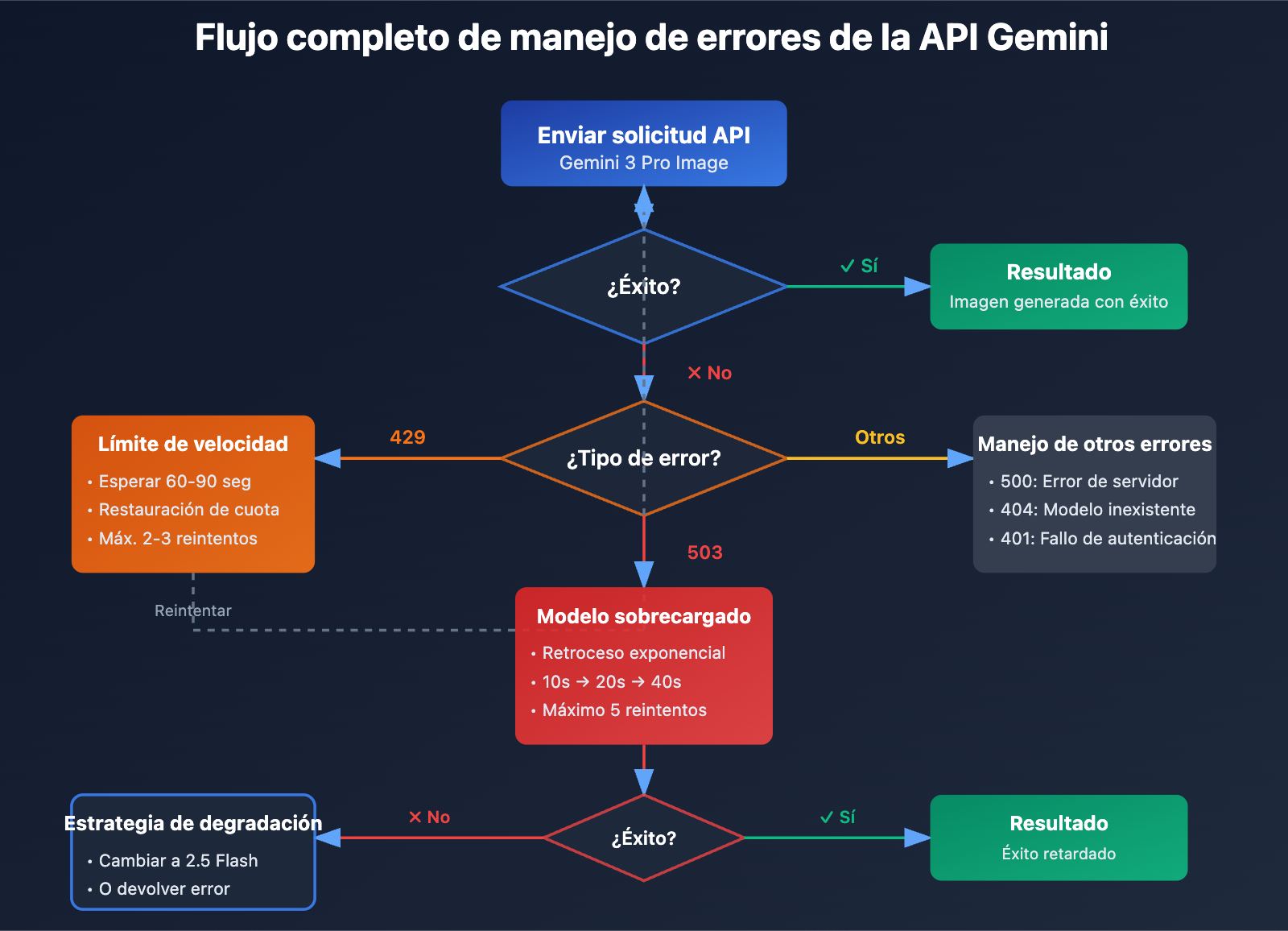
Método 1: Implementar una estrategia de reintentos con retroceso exponencial
Esta es la solución fundamental para lidiar con los errores 503. A continuación, te presento la lógica de reintento recomendada:
import time
import random
from openai import OpenAI
client = OpenAI(
api_key="TU_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
def generate_image_with_retry(
prompt: str,
model: str = "gemini-3-pro-image-preview",
max_retries: int = 5,
initial_delay: int = 10
):
"""
Función de generación de imagen con retroceso exponencial
"""
for attempt in range(max_retries):
try:
response = client.images.generate(
model=model,
prompt=prompt,
timeout=120 # Aumentar tiempo de espera
)
return response
except Exception as e:
error_msg = str(e)
# Error 503: Reintento con retroceso exponencial
if "overloaded" in error_msg.lower() or "503" in error_msg:
if attempt < max_retries - 1:
delay = initial_delay * (2 ** attempt) + random.uniform(0, 5)
print(f"⚠️ Modelo sobrecargado, reintentando en {delay:.1f} segundos (intento {attempt + 1}/{max_retries})")
time.sleep(delay)
continue
else:
raise Exception("❌ Se alcanzó el máximo de reintentos, el modelo sigue sobrecargado")
# Error 429: Espera breve y reintento
elif "429" in error_msg or "RESOURCE_EXHAUSTED" in error_msg:
print("⚠️ Límite de tasa alcanzado, reintentando en 60 segundos")
time.sleep(60)
continue
# Otros errores: Lanzar excepción directamente
else:
raise e
raise Exception("❌ Todos los reintentos fallaron")
# Ejemplo de uso
result = generate_image_with_retry(
prompt="A futuristic city at sunset, cyberpunk style",
max_retries=5
)
Ver código completo de nivel producción
import time
import random
from typing import Optional, Dict
from openai import OpenAI
from datetime import datetime, timedelta
class GeminiImageClient:
"""
Cliente de generación de imágenes Gemini de nivel producción
Soporta reintentos, degradación y monitoreo
"""
def __init__(self, api_key: str, base_url: str = "https://vip.apiyi.com/v1"):
self.client = OpenAI(api_key=api_key, base_url=base_url)
self.error_log = []
self.success_count = 0
self.failure_count = 0
def generate_with_fallback(
self,
prompt: str,
primary_model: str = "gemini-3-pro-image-preview",
fallback_model: str = "gemini-2.5-flash-image",
max_retries: int = 3
) -> Dict:
"""
Generación de imagen con estrategia de degradación (fallback)
"""
# Intentar con el modelo principal
try:
result = self._generate_with_retry(prompt, primary_model, max_retries)
self.success_count += 1
return {
"success": True,
"model_used": primary_model,
"data": result
}
except Exception as e:
print(f"⚠️ El modelo principal {primary_model} falló: {str(e)}")
# Degradación automática al modelo de respaldo
try:
print(f"🔄 Degradando al modelo de respaldo {fallback_model}")
result = self._generate_with_retry(prompt, fallback_model, max_retries)
self.success_count += 1
return {
"success": True,
"model_used": fallback_model,
"fallback": True,
"data": result
}
except Exception as fallback_error:
self.failure_count += 1
self.error_log.append({
"timestamp": datetime.now(),
"primary_error": str(e),
"fallback_error": str(fallback_error)
})
return {
"success": False,
"error": str(fallback_error)
}
def _generate_with_retry(self, prompt: str, model: str, max_retries: int):
"""Lógica interna de reintentos"""
for attempt in range(max_retries):
try:
response = self.client.images.generate(
model=model,
prompt=prompt,
timeout=120
)
return response
except Exception as e:
if attempt < max_retries - 1:
delay = 10 * (2 ** attempt) + random.uniform(0, 5)
time.sleep(delay)
else:
raise e
def get_stats(self) -> Dict:
"""Obtener datos estadísticos"""
total = self.success_count + self.failure_count
success_rate = (self.success_count / total * 100) if total > 0 else 0
return {
"total_requests": total,
"success_count": self.success_count,
"failure_count": self.failure_count,
"success_rate": f"{success_rate:.2f}%",
"recent_errors": self.error_log[-5:]
}
# Ejemplo de uso
client = GeminiImageClient(api_key="TU_API_KEY")
result = client.generate_with_fallback(
prompt="A magical forest with glowing mushrooms",
primary_model="gemini-3-pro-image-preview",
fallback_model="gemini-2.5-flash-image"
)
if result["success"]:
print(f"✅ Generación exitosa, modelo usado: {result['model_used']}")
else:
print(f"❌ Fallo en la generación: {result['error']}")
# Ver estadísticas
print(client.get_stats())
Sugerencia técnica: En entornos de producción reales, te sugiero realizar las llamadas a través de la plataforma APIYI (apiyi.com). Esta plataforma ofrece una interfaz unificada que soporta Gemini 3 Pro y diversos modelos de generación de imágenes. Cuando Nano Banana Pro se sobrecarga, puedes cambiar rápidamente a Gemini 2.5 Flash u otros modelos de respaldo, garantizando la continuidad de tu servicio.
Método 2: Aumentar el tiempo de espera y configurar la solicitud
El tiempo de respuesta normal de Nano Banana Pro es de 20 a 40 segundos, pero bajo sobrecarga puede alcanzar los 60-100 segundos o más. Un ajuste de tiempo de espera (timeout) predeterminado de 30 segundos provocará muchos errores falsos.
Configuración recomendada:
from openai import OpenAI
client = OpenAI(
api_key="TU_API_KEY",
base_url="https://vip.apiyi.com/v1",
timeout=120, # Aumentar tiempo de espera global a 120 segundos
max_retries=3 # El SDK reintenta automáticamente 3 veces
)
# O especificar en una solicitud individual
response = client.images.generate(
model="gemini-3-pro-image-preview",
prompt="Tu indicación aquí",
timeout=150 # Tiempo de espera de 150 segundos para esta solicitud
)
Explicación de parámetros clave:
timeout: Tiempo máximo de espera para una sola solicitud; se recomienda ajustarlo entre 120 y 180 segundos.max_retries: Número de reintentos automáticos a nivel de SDK; se recomiendan de 2 a 3 veces.keep_alive: Mantiene la conexión activa para evitar interrupciones en solicitudes largas.
Método 3: Evitar las horas pico
Si tu negocio permite el procesamiento asíncrono, programar las tareas basándote en los patrones temporales puede mejorar significativamente la tasa de éxito:
Estrategia de programación recomendada:
- Tareas de alta prioridad: Ejecutarlas entre las 03:00-08:00 o 14:00-17:00 (hora de Beijing).
- Tareas de generación por lotes: Usar colas de tareas para ejecución automática en horas de baja carga.
- Tareas en tiempo real: Es obligatorio implementar una estrategia de degradación; no se puede depender de un único modelo.
Ejemplo de programación de tareas en Python:
from datetime import datetime
def is_peak_hour() -> bool:
"""Determina si es hora pico actualmente (Hora de Beijing)"""
current_hour = datetime.now().hour
# Horas pico: 0-2, 9-11, 20-23
peak_hours = list(range(0, 3)) + list(range(9, 12)) + list(range(20, 24))
return current_hour in peak_hours
def smart_generate(prompt: str):
"""Generación inteligente: degradación automática en horas pico"""
if is_peak_hour():
print("⚠️ Estamos en hora pico, usando modelo de respaldo")
model = "gemini-2.5-flash-image"
else:
model = "gemini-3-pro-image-preview"
return generate_image(prompt, model)
Método 4: Implementar una estrategia de degradación de modelo
Google recomienda oficialmente cambiar a Gemini 2.5 Flash cuando se detecta una sobrecarga. Aquí tienes los datos comparativos:
| Métrica | Gemini 3 Pro (Nano Banana Pro) | Gemini 2.5 Flash Image |
|---|---|---|
| Calidad de imagen | Máxima (9/10) | Excelente (7.5/10) |
| Velocidad de generación | 20-40 segundos | 10-20 segundos |
| Estabilidad | 45% de fallos en horas pico | <10% de fallos en horas pico |
| Tiempo recuperación 503 | 30-120 minutos | 5-15 minutos |
| Costo de API | Más alto | Más bajo |
Propuesta de solución: Para escenarios sensibles a la calidad (pósteres de marketing, fotos de productos, etc.), utiliza prioritariamente Gemini 3 Pro y degrada a 2.5 Flash si falla. Para escenarios de alta concurrencia (contenido UGC, prototipos rápidos), usa directamente 2.5 Flash para mayor estabilidad. Te recomiendo usar la plataforma APIYI (apiyi.com) para realizar pruebas comparativas, ya que permite cambiar de modelo con un clic y ofrece datos comparativos de costo y calidad.
Método 5: Sistema de monitoreo y alertas
En entornos de producción es indispensable contar con un monitoreo robusto para detectar y responder a fallos a tiempo:
Métricas clave de monitoreo:
- Tasa de éxito: En los últimos 5 min / 1 hora / 24 horas.
- Tiempo de respuesta: Tiempos P50 / P95 / P99.
- Distribución de errores: Proporción de errores 503 / 429 / 500, etc.
- Frecuencia de degradación: Cuántas veces se activó el respaldo por fallo del modelo principal.
Implementación básica de monitoreo:
from collections import deque
from datetime import datetime
class APIMonitor:
"""Monitor de llamadas a la API"""
def __init__(self, window_size: int = 100):
self.recent_calls = deque(maxlen=window_size)
self.error_counts = {"503": 0, "429": 0, "500": 0, "other": 0}
def log_call(self, success: bool, response_time: float, error_code: str = None):
"""Registrar una llamada a la API"""
self.recent_calls.append({
"timestamp": datetime.now(),
"success": success,
"response_time": response_time,
"error_code": error_code
})
if not success and error_code:
if error_code in self.error_counts:
self.error_counts[error_code] += 1
else:
self.error_counts["other"] += 1
def get_success_rate(self) -> float:
"""Calcular la tasa de éxito"""
if not self.recent_calls:
return 0.0
success_count = sum(1 for call in self.recent_calls if call["success"])
return success_count / len(self.recent_calls) * 100
def should_alert(self) -> bool:
"""Determinar si se debe disparar una alerta"""
success_rate = self.get_success_rate()
# Alerta si la tasa de éxito baja del 70%
if success_rate < 70:
return True
# Alerta si los errores 503 superan el 30% del total de errores
total_errors = sum(self.error_counts.values())
if total_errors > 0 and self.error_counts["503"] / total_errors > 0.3:
return True
return False
# Ejemplo de uso
monitor = APIMonitor(window_size=100)
# Registrar después de cada llamada
start_time = time.time()
try:
result = client.images.generate(...)
response_time = time.time() - start_time
monitor.log_call(success=True, response_time=response_time)
except Exception as e:
response_time = time.time() - start_time
error_code = "503" if "overload" in str(e) else "other"
monitor.log_call(success=False, response_time=response_time, error_code=error_code)
# Verificación periódica de alertas
if monitor.should_alert():
print(f"🚨 ALERTA: La tasa de éxito de la API bajó al {monitor.get_success_rate():.2f}%")
Detalles sobre las cuotas y límites de velocidad de la Gemini API
Ajuste de cuotas de diciembre de 2025
El 7 de diciembre de 2025, Google ajustó los límites de cuota de la Gemini API, lo que provocó que muchos desarrolladores se encontraran con errores 429 inesperados.
Estándares de cuota actuales (enero de 2026):
| Dimensión de la cuota | Versión gratuita (Free Tier) | Versión de pago Tier 1 | Descripción |
|---|---|---|---|
| RPM (Solicitudes por minuto) | 5-15 (según el modelo) | 150-300 | Gemini 3 Pro tiene límites más estrictos |
| TPM (Tokens por minuto) | 32,000 | 4,000,000 | Aplicable a modelos de texto |
| RPD (Solicitudes por día) | 1,500 | 10,000+ | Pool de cuotas compartido |
| IPM (Imágenes por minuto) | 5-10 | 50-100 | Exclusivo para modelos de generación de imágenes |
Notas clave:
- Los límites de cuota se basan en el nivel del Proyecto de Google Cloud, no en cada API Key individual.
- Crear varias API Keys bajo el mismo proyecto no aumentará la cuota.
- Superar el límite de cualquiera de las dimensiones activará un error 429.
- Se aplica mediante el algoritmo Token Bucket, por lo que los picos repentinos de tráfico serán limitados.
Optimización de costos: Para proyectos con presupuesto ajustado, puedes considerar llamar a la API de Gemini a través de la plataforma APIYI (apiyi.com). Esta plataforma ofrece un sistema flexible de pago por uso sin necesidad de una suscripción a Google Cloud, ideal para equipos pequeños y desarrolladores individuales que buscan realizar pruebas rápidas o despliegues a pequeña escala.
Preguntas frecuentes
Q1: ¿Cómo diferenciar los errores 503 (overloaded) y 429 (rate limit)?
La diferencia radica en la causa raíz y el tiempo de recuperación:
503 Overloaded:
- Mensaje de error:
The model is overloaded. Please try again later. - Código de estado HTTP: 503 Service Unavailable
- Causa raíz: Insuficiencia de recursos de computación en los servidores de Google, no tiene que ver con tu cuota.
- Tiempo de recuperación: 30-120 minutos (Gemini 3 Pro), 5-15 minutos (Gemini 2.5 Flash).
- Estrategia: Reintentos con retroceso exponencial (exponential backoff), cambiar a un modelo de respaldo o evitar las horas pico.
429 Rate Limit:
- Mensaje de error:
RESOURCE_EXHAUSTEDoRate limit exceeded - Código de estado HTTP: 429 Too Many Requests
- Causa raíz: Tus llamadas a la API han superado los límites de cuota (RPM/TPM/RPD/IPM).
- Tiempo de recuperación: 1-5 minutos (el pool de cuotas se recupera automáticamente).
- Estrategia: Reducir la frecuencia de las solicitudes, subir a la versión de pago o solicitar un aumento de cuota.
Método rápido de diagnóstico: Revisa el uso de cuota en Google AI Studio; si estás cerca o has llegado al límite, es un 429. De lo contrario, es un 503.
Q2: ¿Por qué hubo un fallo masivo a las 00:18 de la madrugada?
El fallo masivo del 16 de enero de 2026 a las 00:18 (hora de Pekín) coincide con las 08:18 PST del 15 de enero en la costa oeste de EE. UU., justo al inicio de la jornada laboral estadounidense.
Análisis de patrones horarios:
- Los desarrolladores de la costa oeste de EE. UU. (Silicon Valley) comienzan a trabajar entre las 08:00 y 10:00 PST (00:00-02:00 hora de Pekín).
- Los desarrolladores europeos están en su pico de trabajo entre las 14:00 y 18:00 CET (21:00-01:00 hora de Pekín).
- Los desarrolladores en China tienen sus picos de 09:00-11:00 CST y 20:00-23:00 CST.
La superposición de estos tres periodos provocó que la carga de la API Nano Banana Pro superara con creces su capacidad, activando errores 503 masivos.
Sugerencia: Si tu negocio se dirige principalmente a usuarios en China, puedes programar tareas por lotes entre las 03:00 y 08:00 (hora de Pekín), cuando la carga global es mínima (noche profunda en EE. UU. y madrugada en Europa).
Q3: ¿Cómo elegir el modelo adecuado para entornos de producción?
Elige tu estrategia de modelo según las necesidades de tu negocio:
Estrategia 1: Prioridad a la calidad (marketing, imágenes de producto)
- Modelo principal: Gemini 3 Pro Image Preview (Nano Banana Pro)
- Modelo de respaldo: Gemini 2.5 Flash Image
- Implementación: Degradación automática al modelo de respaldo tras 3 fallos del principal.
- Tasa de éxito esperada: 92-95% (incluyendo degradación).
Estrategia 2: Prioridad a la estabilidad (UGC, alta concurrencia)
- Modelo principal: Gemini 2.5 Flash Image
- Modelo de respaldo: Otros modelos de generación de imágenes (DALL-E 3, Stable Diffusion XL)
- Implementación: Uso directo de 2.5 Flash, cambiando a modelos de terceros en caso de fallo.
- Tasa de éxito esperada: 95-98%.
Estrategia 3: Prioridad al costo (pruebas, prototipos)
- Uso de la versión gratuita de Gemini 2.5 Flash.
- Aceptar errores ocasionales 429 y 503.
- Sin implementar lógica compleja de tolerancia a fallos.
Solución recomendada: Utiliza la plataforma APIYI (apiyi.com) para probar rápidamente el efecto y el costo de diferentes modelos. Ofrece una interfaz unificada para llamar a múltiples modelos de generación de imágenes, facilitando la comparación y el cambio entre ellos.
Resumen
Puntos clave sobre los errores de la API de Gemini Nano Banana Pro:
- El error 503 Overloaded es un problema sistémico: No tiene nada que ver con tu código; se debe a la falta de recursos de cómputo en los servidores de Google. En horas pico, hasta el 45% de las llamadas pueden fallar.
- Patrones temporales claros: Las franjas horarias de 00:00-02:00, 09:00-11:00 y 20:00-23:00 (hora de Beijing) son de alto riesgo. Es fundamental evitarlas o implementar estrategias de degradación.
- La tolerancia a fallos es vital: Es imprescindible implementar tres capas de protección: reintentos con retroceso exponencial (exponential backoff), aumentar el tiempo de espera (timeout a 120s+) y degradación de modelo (usar 2.5 Flash como respaldo).
- Monitorización y alertas: En entornos de producción, es obligatorio monitorizar la tasa de éxito, los tiempos de respuesta y la distribución de errores para detectar y reaccionar rápidamente ante los fallos.
- Entender los límites de cuota: El error 429 está relacionado con tu cuota de API, mientras que el 503 depende de la carga global de Google. Las estrategias para enfrentar cada uno son distintas.
Como modelo en fase de vista previa (preview), los problemas de estabilidad de Nano Banana Pro difícilmente se resolverán a corto plazo. Te recomendamos usar APIYI (apiyi.com) para validar rápidamente tus necesidades de generación de imágenes. La plataforma ofrece cuotas gratuitas y una interfaz unificada para múltiples modelos, incluyendo Gemini 3 Pro, Gemini 2.5 Flash y DALL-E 3, garantizando así la continuidad de tu negocio.
📚 Referencias
⚠️ Nota sobre el formato de los enlaces: Todos los enlaces externos utilizan el formato
Nombre del recurso: dominio.com. Esto facilita la copia pero evita clics directos para proteger el SEO.
-
Nano Banana Errors & Troubleshooting Guide: Manual completo de referencia de errores.
- Enlace:
www.aifreeapi.com/en/posts/nano-banana-errors-troubleshooting-guide - Descripción: Cubre soluciones completas para todos los códigos de error de Nano Banana Pro, como 429, 502, 403, 500, etc.
- Enlace:
-
Foro de desarrolladores de Google AI: Discusión sobre el error "overloaded" en Gemini 3 Pro.
- Enlace:
discuss.ai.google.dev/t/gemini-3-pro-nano-banana-tier-1-4k-image-503-unavailable-error-the-model-is-overloaded/110232 - Descripción: Discusión en tiempo real y experiencias compartidas por la comunidad de desarrolladores sobre el error 503.
- Enlace:
-
Documentación oficial de Gemini API Rate Limits: Explicación de cuotas y límites de velocidad.
- Enlace:
ai.google.dev/gemini-api/docs/rate-limits - Descripción: Documentación oficial de Google sobre cuotas de API, con detalles sobre RPM/TPM/RPD/IPM.
- Enlace:
-
Gemini 3 Pro Image Preview Error Codes: Guía completa de códigos de error.
- Enlace:
www.aifreeapi.com/en/posts/gemini-3-pro-image-preview-error-codes - Descripción: Guía de resolución de todos los códigos de error de Gemini 3 Pro para los años 2025-2026.
- Enlace:
Autor: Equipo técnico
Intercambio técnico: Te invitamos a discutir tu experiencia con la API de Gemini en la sección de comentarios. Para más material de resolución de problemas, visita la comunidad técnica de APIYI (apiyi.com).