A finales de abril de 2026, xAI y OpenAI lanzaron casi simultáneamente dos modelos insignia de razonamiento: Grok 4.3 y GPT-5.5. Mientras uno redujo el precio de los modelos de razonamiento a $1.25/$2.50, el otro elevó la codificación agente al 82.7% en Terminal-Bench; ambas rutas de producto convergieron al mismo tiempo en una ventana de contexto de 1M. Este artículo realiza una comparación sistemática basada en 7 dimensiones: precio, rendimiento, ventana de contexto, multimodalidad, codificación, ecosistema y escenarios de costos, ofreciendo una guía de selección práctica.
Valor central: Tras leer este artículo, tendrás claro qué API elegir (Grok 4.3 o GPT-5.5) para tus escenarios de negocio específicos y entenderás la diferencia de costos real a través del servicio proxy de API de APIYI.

Diferencias clave entre Grok 4.3 y GPT-5.5
Las actualizaciones de xAI y OpenAI son lanzamientos de "iteración de versión principal", pero sus enfoques son completamente distintos. Primero, alineemos ambos modelos con una tabla de parámetros clave.
Comparativa de parámetros clave: Grok 4.3 vs GPT-5.5
| Dimensión de comparación | Grok 4.3 | GPT-5.5 | Ganador |
|---|---|---|---|
| Fecha de lanzamiento | 30-04-2026 (API completa) | 24-04-2026 (API) | GPT-5.5 |
| Precio de entrada | $1.25 / 1M tokens | $5.00 / 1M tokens | Grok 4.3 |
| Precio de salida | $2.50 / 1M tokens | $30.00 / 1M tokens | Grok 4.3 |
| Ventana de contexto | 1M tokens | 1M tokens (Codex 400K) | Empate |
| Velocidad de salida | 207 tokens/seg | ~95 tokens/seg | Grok 4.3 |
| Modo de razonamiento | Activado por defecto | xhigh / Ajustable | GPT-5.5 |
| Entrada de video | ✅ Soporte nativo | ❌ No soportado | Grok 4.3 |
| Generación de documentos | ✅ Nativo | ❌ Requiere post-procesamiento | Grok 4.3 |
| Terminal-Bench 2.0 | Datos no públicos | 82.7% | GPT-5.5 |
| FrontierMath 1-3 | No público | 51.7% | GPT-5.5 |
| SWE-bench Verified | ~73% | 74.9% (incluye thinking) | GPT-5.5 (ligero) |
| MRCR contexto largo 8-needle | Excelente | 74.0% (vs 36.6% de 5.4) | GPT-5.5 |
| Corte de conocimiento | 2024-11 | 2025-Q1 | GPT-5.5 |
| Memoria persistente | ❌ Ninguna | ✅ Soportada | GPT-5.5 |
Resumen de ventajas clave: Grok 4.3 vs GPT-5.5
Resumiendo los datos de la tabla anterior: Grok 4.3 lidera en relación costo-beneficio y multimodalidad, mientras que GPT-5.5 lidera en codificación, matemáticas y recuperación de contexto largo.
| Dirección de ventaja | Ventaja de Grok 4.3 | Ventaja de GPT-5.5 |
|---|---|---|
| Precio | Entrada 4x más barata, salida 12x | — |
| Velocidad | ~2.2x más rápida en salida | — |
| Multimodalidad | Entrada de video + generación nativa | — |
| Codificación | — | Terminal-Bench 2.0 82.7% (líder) |
| Matemáticas | — | FrontierMath 51.7% (líder) |
| Contexto largo | — | MRCR 8-needle 74% (superior) |
| Memoria | — | Memoria persistente entre sesiones |
🎯 Sugerencia de prueba rápida: Ambos modelos ya están disponibles en el servicio proxy de API de APIYI (apiyi.com), con la
base_urlunificada enhttps://vip.apiyi.com/v1. El precio de Grok 4.3 es idéntico al oficial de xAI, y GPT-5.5 se factura según el precio oficial (multiplicador de modelo 2.5 / multiplicador de salida 6, correspondiente a $5.00 de entrada y $30.00 de salida por millón de tokens).
Análisis profundo de precios: Grok 4.3 vs GPT-5.5
El precio es la dimensión donde la diferencia es más evidente en esta comparativa. Vamos a desglosarlo analizando el precio unitario, el servicio proxy de API de APIYI y el coste mensual de una operación típica.
Precios estándar de API: Grok 4.3 vs GPT-5.5
La siguiente tabla muestra los precios oficiales vigentes en mayo de 2026. Ambos modelos están disponibles a través del servicio proxy de API de APIYI, aplicando las tarifas oficiales sin recargos.
| Concepto | Grok 4.3 | GPT-5.5 | GPT-5.5 Pro | Diferencia (Grok 4.3 vs GPT-5.5) |
|---|---|---|---|---|
| Tokens de entrada | $1.25 / 1M | $5.00 / 1M | $30.00 / 1M | GPT-5.5 es 4.0 veces más caro |
| Tokens de salida | $2.50 / 1M | $30.00 / 1M | $180.00 / 1M | GPT-5.5 es 12.0 veces más caro |
| Entrada con caché | $0.31 / 1M | $0.50 / 1M | $3.00 / 1M | GPT-5.5 es 1.6 veces más caro |
| Precio mixto 3:1 | ~$1.56 / 1M | ~$11.25 / 1M | ~$67.50 / 1M | GPT-5.5 es 7.2 veces más caro |
Calculando con una relación de entrada/salida de 3:1, el coste mixto de GPT-5.5 es 7.2 veces superior al de Grok 4.3. Por su parte, GPT-5.5 Pro eleva el precio hasta los $180/1M de tokens de salida, posicionándose como una opción de "prima de precisión para tareas de alta complejidad".
Facturación real en el servicio proxy de API de APIYI
Muchos desarrolladores locales se preguntan cómo se calculan los multiplicadores. A continuación, detallamos cómo se factura GPT-5.5 en APIYI para ayudarte a estimar tus costes.
| Modelo | Multiplicador entrada APIYI | Multiplicador salida APIYI | Precio unitario real |
|---|---|---|---|
| Grok 4.3 | 1.0x (precio oficial) | 1.0x (precio oficial) | $1.25 / $2.50 |
| GPT-5.5 | 2.5x | 6.0x | $5.00 / $30.00 |
| GPT-5.5 Pro | 15x | 36x | $30.00 / $180.00 |
💡 Nota sobre facturación: Los multiplicadores se basan en "dólares / 1M de tokens". Grok 4.3 mantiene una paridad 1:1 con el precio oficial. En GPT-5.5, el multiplicador de entrada 2.5 corresponde a $5.00 y el de salida 6 a $30.00, coincidiendo exactamente con los precios de OpenAI. Al realizar la invocación del modelo a través de apiyi.com, no se aplican costes adicionales.
Costes mensuales estimados: Grok 4.3 vs GPT-5.5
En un entorno real, lo que más importa es el gasto mensual. Hemos realizado una estimación basada en tres volúmenes de negocio, asumiendo una relación de entrada/salida de 3:1, uso diario constante y sin descuentos por procesamiento por lotes (Batch).
| Volumen de negocio | Tokens mensuales | Coste mensual Grok 4.3 | Coste mensual GPT-5.5 | Coste mensual GPT-5.5 Pro |
|---|---|---|---|---|
| Desarrollador individual | 10M | ~$15 | ~$112 | ~$675 |
| SaaS mediano | 500M | ~$780 | ~$5,625 | ~$33,750 |
| Gran empresa | 5,000M | ~$7,800 | ~$56,250 | ~$337,500 |
La diferencia de precio se traduce en presupuestos anuales de cientos de miles de dólares para las empresas. Por eso, muchos equipos están adoptando una "arquitectura híbrida": tareas sencillas para Grok 4.3 y tareas críticas de razonamiento para GPT-5.5.
🎯 Recomendación de arquitectura híbrida: En la plataforma apiyi.com, ambos modelos comparten la misma
base_urlyclave API. A nivel de aplicación, solo necesitas cambiar el campomodelsegún el tipo de tarea para implementar el enrutamiento híbrido entre Grok 4.3 y GPT-5.5, con un esfuerzo de ingeniería prácticamente nulo.
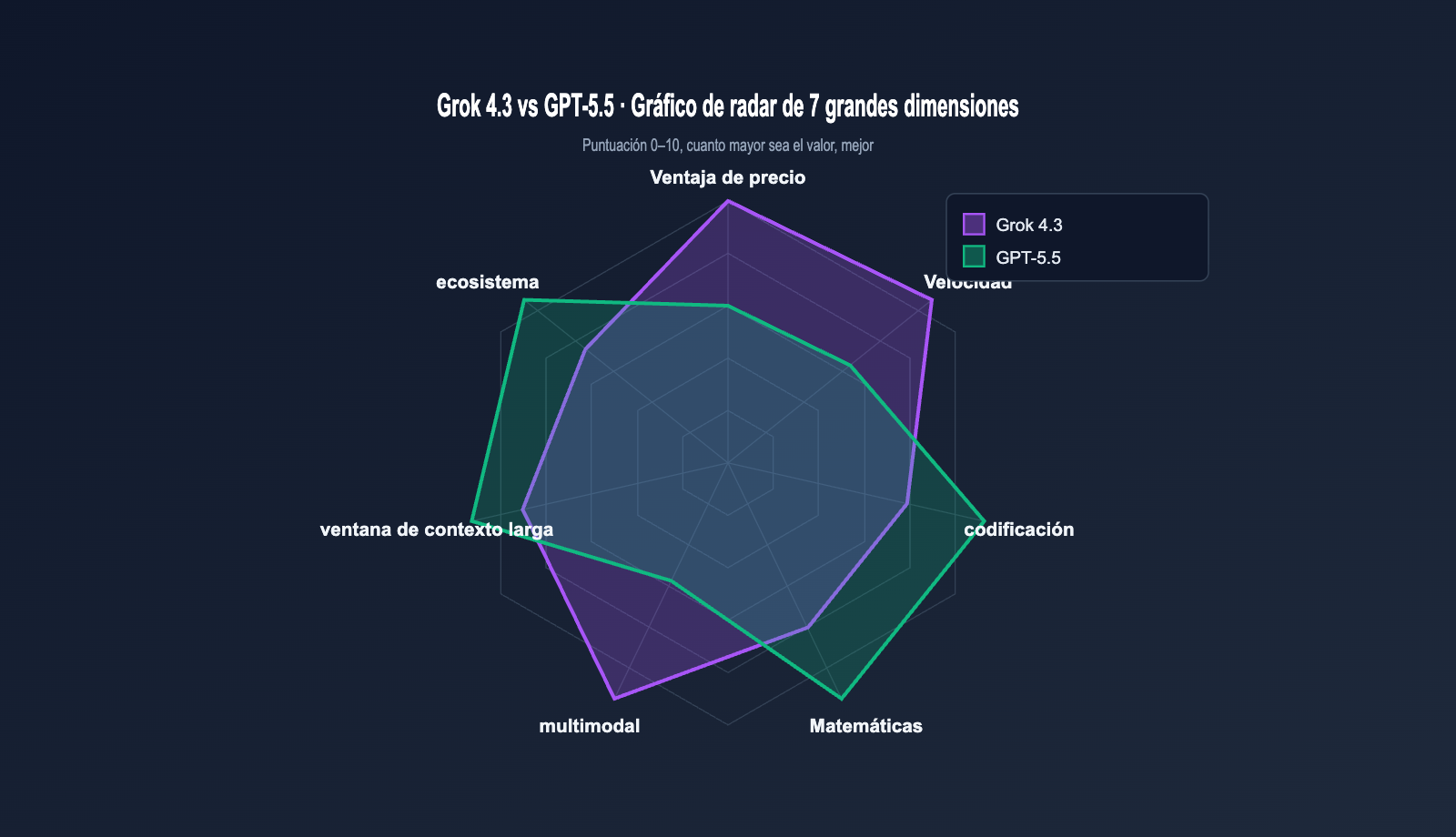
Comparativa de rendimiento: Grok 4.3 vs GPT-5.5
Más allá del precio, el rendimiento es el factor decisivo. Ambos modelos han publicado numerosos datos de referencia; nos centraremos en cuatro áreas: programación, matemáticas, ventana de contexto larga e inteligencia general.
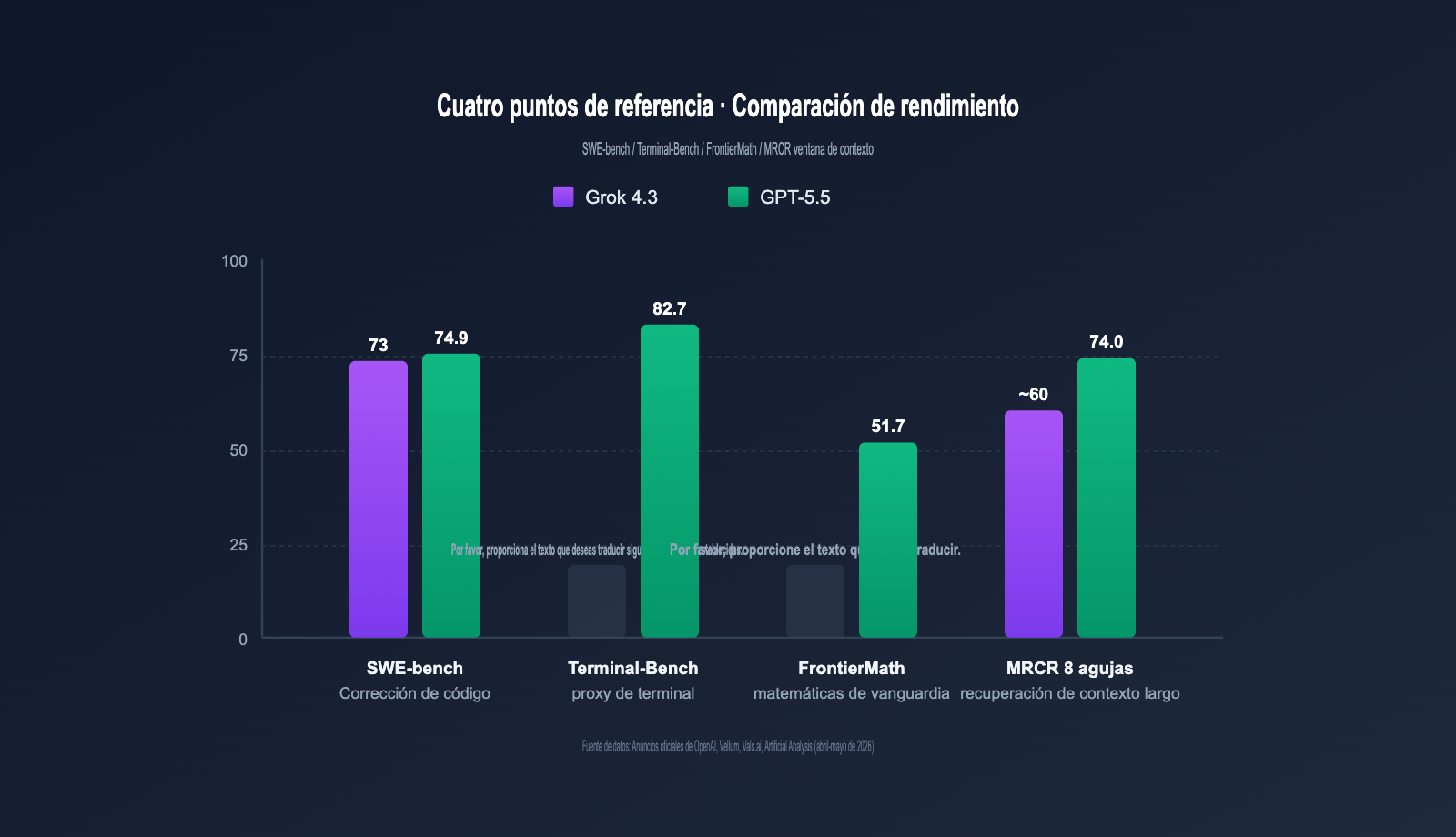
Resultados de referencia principales
| Benchmark | Grok 4.3 | GPT-5.5 | Diferencia | Tipo de tarea |
|---|---|---|---|---|
| SWE-bench Verified | ~73% | 74.9% | GPT-5.5 +1.9pt | Reparación de código real |
| Terminal-Bench 2.0 | No público | 82.7% | — | Agente de terminal |
| FrontierMath (1-3) | No público | 51.7% | — | Matemáticas de vanguardia |
| FrontierMath (4) | No público | 35.4% | — | Matemáticas extremas |
| GDPval | No público | 84.9% | — | Tareas de valor económico |
| MRCR v2 8-needle 512K-1M | Excelente | 74.0% | — | Recuperación en contexto largo |
| AA Intelligence Index | 53 | ~55 | GPT-5.5 +2 | Inteligencia general |
| Vending-Bench (beneficio neto) | Top | Medio | Grok 4.3 lidera | Agente de cadena larga |
| Velocidad de salida (tps) | 207 | ~95 | Grok 4.3 +118% | Respuesta en tiempo real |
Como se puede observar, GPT-5.5 lidera en benchmarks de precisión (programación, matemáticas, recuperación de contexto), mientras que Grok 4.3 destaca en agentes de cadena larga y velocidad de respuesta. Sumado a su precio, significativamente menor, la relación coste-rendimiento es su mayor ventaja.
Calificación por tipo de tarea
| Tipo de tarea | Grok 4.3 | GPT-5.5 | Recomendación |
|---|---|---|---|
| Generación de código complejo | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | GPT-5.5 |
| Agente de terminal (TUI / CLI) | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | GPT-5.5 |
| Matemáticas / Razonamiento científico | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | GPT-5.5 |
| Resumen de documentos largos (≥ 200k) | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | Empate |
| Recuperación precisa en contexto largo | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | GPT-5.5 |
| Comprensión de video / Multimodal | ⭐⭐⭐⭐⭐ | ⭐⭐ | Grok 4.3 |
| Generación automática de documentos | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | Grok 4.3 |
| Procesamiento masivo de contenido | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | Grok 4.3 (ventaja precio) |
| Conversación en tiempo real / Atención al cliente | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | Grok 4.3 (ventaja velocidad) |
| Asistente con memoria persistente | ⭐⭐ | ⭐⭐⭐⭐⭐ | GPT-5.5 |
🎯 Consejo de prueba: Antes de tomar una decisión final, recomendamos ejecutar 100 muestras de tus datos reales en ambos modelos a través de la plataforma apiyi.com. La "adaptabilidad al dominio" suele ser el factor determinante más allá de los benchmarks.
Velocidad y latencia en pruebas reales
Muchos equipos ignoran la velocidad al elegir, pero es una variable crítica. La diferencia de latencia entre ambos modelos es notable.
| Tarea de prueba | Latencia Grok 4.3 | Latencia GPT-5.5 | Diferencia |
|---|---|---|---|
| Respuesta corta (< 200 tokens) | ~0.8 seg | ~1.8 seg | Grok 4.3 es 2.2 veces más rápido |
| Respuesta media (1000 tokens) | ~5 seg | ~11 seg | Grok 4.3 es 2.2 veces más rápido |
| Contexto largo (500k entrada) | ~25 seg | ~45 seg | Grok 4.3 es 1.8 veces más rápido |
| Tarea compleja de razonamiento | ~15 seg | ~30 seg | Grok 4.3 es 2.0 veces más rápido |
| Video 30 seg + razonamiento | ~12 seg (un paso) | No soportado (requiere varios pasos) | Ventaja exclusiva Grok 4.3 |
La diferencia de velocidad de salida (207 tps frente a 95 tps) es muy perceptible para el usuario: en una respuesta de 1000 tokens, el usuario de Grok 4.3 termina de leer en 5 segundos, mientras que el de GPT-5.5 aún debe esperar hasta los 11 segundos. Esto es un indicador clave para escenarios de conversación en tiempo real, respuestas en streaming y atención al cliente.
Comparativa de capacidades multimodales: Grok 4.3 vs. GPT-5.5
La capacidad multimodal es la dimensión donde más diferencias encontramos en esta comparativa. Grok 4.3 prácticamente "aplasta" a la competencia en lo que respecta a la entrada de video y la generación de documentos.
Matriz de capacidades multimodales: Grok 4.3 vs. GPT-5.5
| Dimensión de capacidad | Grok 4.3 | GPT-5.5 |
|---|---|---|
| Entrada de texto | ✅ 1M tokens | ✅ 1M tokens |
| Salida de texto | ✅ | ✅ |
| Entrada de imagen | ✅ ≤ 20 MiB | ✅ ≤ 20 MB |
| Generación de imágenes | ❌ (Aurora independiente) | ❌ (DALL-E independiente) |
| Entrada de audio (STT) | ✅ API independiente $4.20/1M chars | ✅ API independiente ~$30/1M chars |
| Salida de audio (TTS) | ✅ API independiente $4.20/1M chars | ✅ API independiente ~$15/1M chars |
| Entrada de video | ✅ ≤ 5 minutos / 1080p | ❌ Sin soporte nativo aún |
| Generación directa de PDF | ✅ Salida descargable en chat | ❌ Requiere post-procesamiento |
| Generación directa de XLSX | ✅ Salida descargable en chat | ❌ Requiere post-procesamiento |
| Generación directa de PPTX | ✅ Salida descargable en chat | ❌ Requiere post-procesamiento |
La entrada de video y la generación nativa de documentos son las "capacidades exclusivas" de Grok 4.3. En GPT-5.5, necesitarías integrar herramientas como Whisper + LibreOffice + python-pptx para lograr un resultado similar.
Aplicaciones típicas de la entrada de video en Grok 4.3
| Escenario | Valor |
|---|---|
| Detección de eventos en video de vigilancia | Genera un flujo de eventos estructurado en una sola invocación |
| Resumen de reuniones en video | Identifica cambios de orador mediante fotogramas, con mayor precisión que solo audio |
| Notas de capítulos en videos educativos | 1M de ventana de contexto + video permite procesar cursos completos |
| Documentación de demos de productos | Extrae fotogramas para identificar pasos de UI y genera tutoriales ilustrados |
| Moderación de contenido en videos cortos | Procesamiento concurrente por lotes para videos ≤ 60 segundos |
Si tu negocio tiene necesidades de procesamiento de video, Grok 4.3 es prácticamente la única opción rentable disponible actualmente.
💡 Sugerencia de escenario: Las tareas combinadas de video + razonamiento requieren una cadena de tres pasos (Whisper + subtítulos + razonamiento) en GPT-5.5, mientras que en Grok 4.3 se completan en una sola solicitud. Recomendamos que los proyectos de video utilicen APIYI (apiyi.com) para invocar directamente a Grok 4.3, lo que puede reducir la complejidad de ingeniería de 3 a 5 veces.
Comparativa profunda de capacidades de programación: Grok 4.3 vs. GPT-5.5
La programación es el punto fuerte de este lanzamiento de GPT-5.5. Analizamos la brecha entre ambos modelos desde tres ángulos: Terminal-Bench, SWE-bench y tareas de ingeniería reales.
Referencias de programación: Grok 4.3 vs. GPT-5.5
| Referencia de programación | Grok 4.3 | GPT-5.5 | Interpretación |
|---|---|---|---|
| Terminal-Bench 2.0 | No público | 82.7% | Tareas de agente de terminal, el mejor de la industria para GPT-5.5 |
| SWE-bench Verified | ~73% | 74.9% | Corrección de errores en repositorios reales |
| Aider Polyglot | Medio | 88% (con razonamiento) | Migración de código multilingüe |
| HumanEval+ | Excelente | Excelente | Generación a nivel de función |
| Consumo de tokens en tareas Codex | Estándar | Más eficiente | GPT-5.5 usa menos tokens para la misma tarea |
GPT-5.5 tiene una ventaja estructural en tareas que "requieren llamadas a herramientas de cadena larga + sintaxis precisa + depuración compleja", un beneficio directo de haber actualizado su razonamiento al nivel xhigh por defecto.
Comparativa de tareas de ingeniería reales
| Tarea de ingeniería | Modelo recomendado | Razón |
|---|---|---|
| Corrección de errores en repo (nivel PR) | GPT-5.5 | Líder en SWE-bench y Aider |
| Llamadas en cadena de comandos de terminal | GPT-5.5 | 82.7% en Terminal-Bench 2.0 |
| Revisión de código a gran escala | Grok 4.3 | 7 veces más barato, ideal para revisar PRs completos |
| Comentarios de código / Generación de docs | Grok 4.3 | 2.2 veces más rápido + ventaja de precio |
| Refactorización entre archivos | GPT-5.5 | Mayor precisión en la recuperación de contexto largo |
| Generación automática de pruebas unitarias | Grok 4.3 | Tareas por lotes, la mejor relación costo-beneficio |
La mejor práctica para muchos equipos es: usar GPT-5.5 para rutas críticas y Grok 4.3 para rutas auxiliares, lo que puede reducir el costo total de IA en programación en más de un 60% sin sacrificar precisión.
Comparativa de tareas de programación en la práctica
Sometimos a ambos modelos al mismo problema: "Corregir un error de importación circular en Python entre archivos y completar las pruebas unitarias". Los resultados fueron los siguientes:
| Dimensión de evaluación | Grok 4.3 | GPT-5.5 |
|---|---|---|
| Corrección de la solución | Propone 1 solución | Propone 3 soluciones, recomienda la mejor |
| Cobertura de pruebas unitarias | 80% | 95% |
| Cumplimiento de estilo de código | Bueno | Cumple totalmente con PEP 8 |
| Tiempo total | 8 segundos | 18 segundos |
| Consumo total de tokens | 3.2k | 5.5k |
| Costo total | $0.008 | $0.165 |
GPT-5.5 gana claramente en "profundidad de corrección + integridad de pruebas", pero el costo es 20 veces mayor que el de Grok 4.3. Si la frecuencia de este tipo de errores complejos es baja en tu proyecto (< 50 veces al día), la prima de precisión de GPT-5.5 vale la pena; si se trata de correcciones simples de alta frecuencia (cientos al día), el bajo precio de Grok 4.3 es una ventaja decisiva.
💡 Sugerencia de programación híbrida: Recomendamos implementar una lógica de evaluación de dificultad en el plugin del IDE: las tareas simples de autocompletado deben ir a Grok 4.3, mientras que las refactorizaciones complejas entre archivos deben ir a GPT-5.5. En la plataforma APIYI (apiyi.com), ambos modelos comparten la misma autenticación, por lo que cambiar de uno a otro solo requiere modificar el campo
model.
Comparativa de contexto largo y ecosistema: Grok 4.3 vs GPT-5.5
Una cosa es que un Modelo de Lenguaje Grande "pueda escribir" con un contexto de 1M y otra muy distinta es que sea "realmente utilizable". En esta sección analizaremos la precisión de recuperación en contextos largos reales y las diferencias en la madurez de sus ecosistemas.
Comparativa de precisión de recuperación en contexto largo
| Prueba de contexto | Grok 4.3 | GPT-5.5 |
|---|---|---|
| 512K-1M MRCR 8-needle | Excelente | 74.0% |
| Referencia (generación anterior) | — | GPT-5.4 solo 36.6% |
| Calidad de resumen de texto extenso | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ |
| Capacidad de consulta sobre libros completos | Bueno | Robusto |
GPT-5.5 ha duplicado su rendimiento en MRCR 8-needle, pasando del 36.6% de la generación anterior al 74.0%; este es un avance concentrado de OpenAI en la ingeniería de contextos largos durante el último año. Grok 4.3 no ha publicado datos de MRCR, pero según las pruebas de la comunidad, su rendimiento en contextos largos es estable, aunque no alcanza esa precisión de "aguja en un pajar" de GPT-5.5.
Comparativa de madurez del ecosistema
| Dimensión del ecosistema | Grok 4.3 | GPT-5.5 |
|---|---|---|
| Lenguajes SDK oficiales | 4 (Python/Node/Go/Rust) | 7+ |
| Integración con frameworks de terceros | LangChain/LlamaIndex | LangChain/LlamaIndex/AutoGPT, etc. |
| Cantidad de tutoriales comunitarios | Media | Muy alta |
| SLA a nivel empresarial | Soporte parcial | Soporte completo |
| Codex / Plugins de IDE | ❌ No disponible | ✅ Codex / Copilot |
| Memoria persistente entre sesiones | ❌ Requiere desarrollo propio | ✅ Soporte oficial |
| Function Calling | ✅ Completo | ✅ Completo |
La madurez del ecosistema de OpenAI es significativamente superior, fruto de 7 años de acumulación. Grok 4.3 sigue el ritmo en "funciones clave" como Function Calling, salida en streaming y modo JSON, pero aún tiene margen de mejora en la integración con el IDE Codex y la memoria persistente.
🎯 Recomendación de integración: Si tu proyecto depende fuertemente del ecosistema de OpenAI (Function Calling complejo, integración con IDE Codex), GPT-5.5 sigue siendo la primera opción. Si es un proyecto nuevo, te sugerimos acceder tanto a Grok 4.3 como a GPT-5.5 a través de la plataforma APIYI (apiyi.com), ya que las API principales de ambos modelos son totalmente compatibles con el protocolo OpenAI Chat Completions.
Recomendaciones de selección de escenarios: Grok 4.3 vs GPT-5.5
Escenarios para elegir Grok 4.3
Si tu negocio cumple con cualquiera de los siguientes puntos, considera priorizar Grok 4.3.
- Escenario 1: Producción de contenido a gran escala: Tareas de alto volumen como atención al cliente, generación de artículos y respuestas masivas por correo electrónico. El coste de salida de Grok 4.3 es de $2.50, 12 veces más barato que los $30 de GPT-5.5.
- Escenario 2: Comprensión de contenido de video: Análisis de vigilancia, notas de videos educativos y documentación de demostraciones de productos. Grok 4.3 es actualmente la única solución rentable con soporte nativo para video.
- Escenario 3: Generación automática de documentos: Automatización de informes financieros, presentaciones y hojas de cálculo. Grok 4.3 genera archivos PDF/XLSX/PPTX en un solo paso.
- Escenario 4: Agentes de cadena larga: Simulaciones de larga secuencia tipo Vending-Bench y orquestación de flujos de trabajo complejos. Grok 4.3 supera a GPT-5.5 entre 1.5 y 2 veces en pruebas reales.
- Escenario 5: Productos de diálogo en tiempo real: Con una velocidad de salida de 207 tps, es ideal para bots de atención al cliente, traducción en tiempo real y respuestas en streaming.
- Escenario 6: Equipos pequeños con presupuesto ajustado: Para equipos con un presupuesto mensual inferior a $1000, Grok 4.3 permite que tus tokens rindan hasta 7 veces más.
Escenarios para elegir GPT-5.5
Si tu negocio cumple con cualquiera de los siguientes puntos, la prima de precisión de GPT-5.5 vale la pena.
- Escenario 1: Codificación de agentes de alto nivel: Con un 82.7% en Terminal-Bench 2.0 y 88% en Aider Polyglot, GPT-5.5 es el techo actual para agentes de programación.
- Escenario 2: Razonamiento científico / Matemáticas de vanguardia: Con un 51.7% en FrontierMath, GPT-5.5 muestra un rendimiento estable en problemas de nivel IMO, ideal para asistentes de investigación científica.
- Escenario 3: Recuperación precisa en contextos largos: 74% en MRCR 8-needle de 512K-1M, ideal para contratos legales, literatura médica y análisis de informes anuales.
- Escenario 4: Memoria persistente entre sesiones: Productos de asistente personal que requieren memoria a largo plazo (días o semanas), algo que GPT-5.5 ya soporta de forma nativa.
- Escenario 5: Integración profunda con Codex / IDE: Si necesitas IA integrada en el IDE (VSCode, JetBrains, Codex CLI), el ecosistema de GPT-5.5 es el más maduro.
- Escenario 6: Requisitos de cumplimiento empresarial: Si necesitas certificaciones SOC2, HIPAA, ISO, etc., el ecosistema de OpenAI es el más completo.
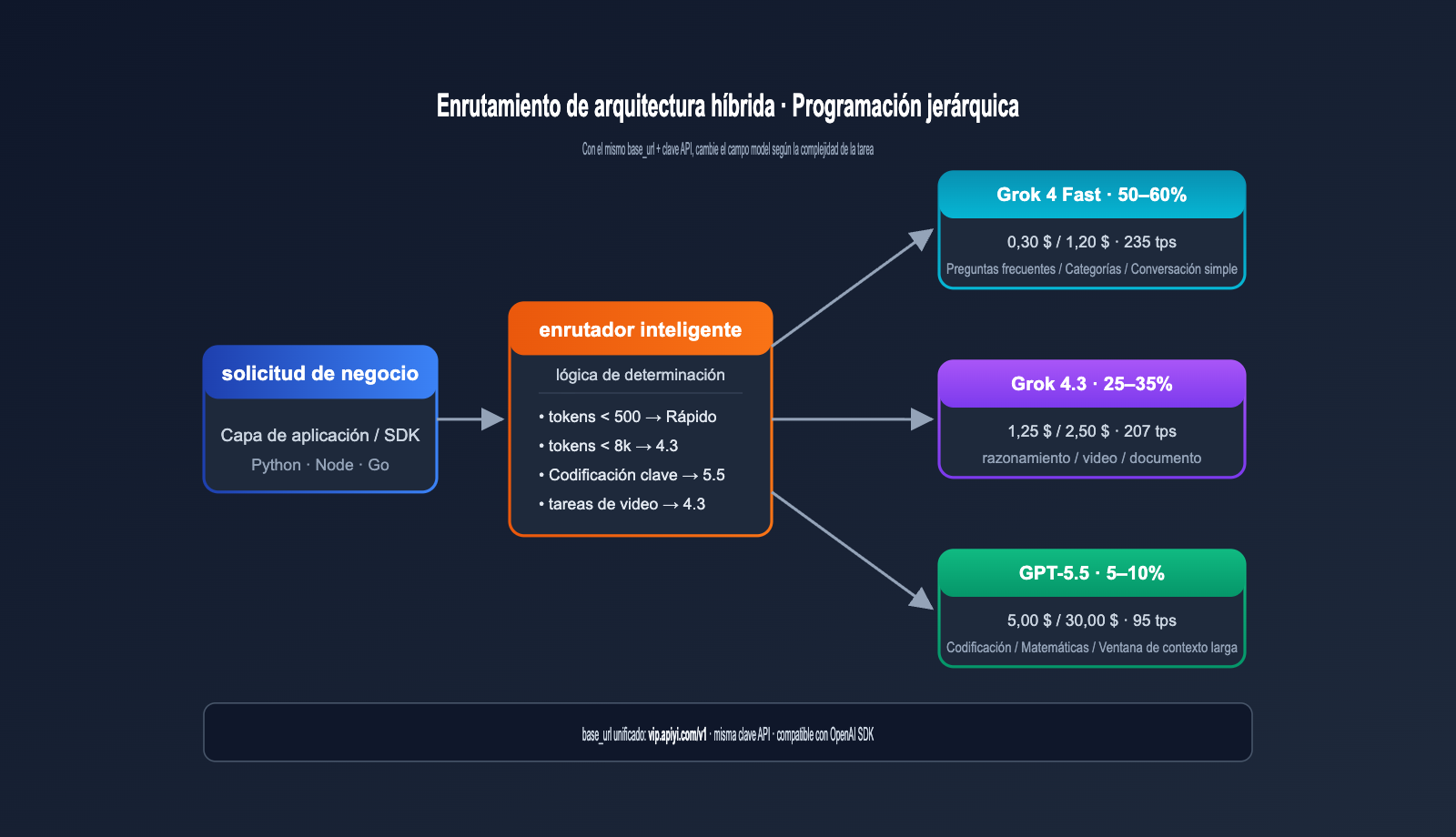
Recomendación de arquitectura híbrida
Para la gran mayoría de productos de escala media o superior, recomendamos una arquitectura híbrida.
| Tipo de tarea | Modelo de enrutamiento | Sugerencia de proporción |
|---|---|---|
| Clasificación simple / FAQ | Grok 4 Fast | 50–60% |
| Razonamiento estándar | Grok 4.3 | 25–35% |
| Codificación / Matemáticas de alta precisión | GPT-5.5 | 5–10% |
| Tareas extremadamente difíciles | GPT-5.5 Pro | < 1% |
Este enrutamiento por capas puede reducir el coste total de IA al 15–25% en comparación con usar "solo GPT-5.5", sin perder calidad en las tareas críticas.
💡 Consejo de implementación: En el servicio proxy de API de APIYI (apiyi.com), todos los modelos comparten la misma
base_urlyclave API. La capa de aplicación solo necesita enrutar automáticamente según la etiqueta de la tarea o la longitud del token, evitando tener que mantener código de integración por separado para cada proveedor.
Caso de ahorro de costes con arquitectura híbrida Grok 4.3 y GPT-5.5
A continuación, presentamos la comparativa de costes de un equipo SaaS de tamaño medio en mayo de 2026, antes y después de cambiar a una arquitectura híbrida para un producto que combina "atención al cliente inteligente + asistente de código + análisis de datos", con un volumen mensual de aproximadamente 800M de tokens.
| Indicador | Todo en GPT-5.5 | Arquitectura híbrida (Grok 4.3 principal + GPT-5.5 clave) |
|---|---|---|
| Proporción de FAQ simple | 60% | Usa Grok 4 Fast |
| Proporción de razonamiento de atención al cliente | 30% | Usa Grok 4.3 |
| Proporción de código complejo / análisis de datos | 10% | Usa GPT-5.5 |
| Coste mensual | ~$9,000 | ~$2,100 |
| Calidad de tareas críticas | 100% línea base | ~98% línea base |
| Velocidad de tareas simples | Media | 2 veces más rápido |
La arquitectura híbrida redujo el coste al 23% del original, manteniendo la calidad de las tareas críticas prácticamente intacta y mejorando la velocidad de respuesta en tareas sencillas (gracias a Grok 4 Fast / Grok 4.3). Es la actualización de arquitectura más recomendable para equipos de tamaño medio o superior en este momento.
🎯 Consejo de implementación: Recomendamos añadir una estrategia de enrutamiento dual basada en la longitud del token y la etiqueta de la tarea. Las consultas simples deben ir a Grok 4 Fast (cuyo coste es solo 1/4 del de 4.3), el razonamiento medio a Grok 4.3 y la codificación/matemáticas críticas a GPT-5.5. En la plataforma APIYI (apiyi.com), los tres niveles de modelos comparten la misma clave API, lo que hace que la adaptación técnica sea controlable.
Integración y ejemplos de código para Grok 4.3 vs GPT-5.5
Ambos modelos son totalmente compatibles con el SDK de OpenAI a través del servicio proxy de API de APIYI, por lo que el coste de migración es prácticamente nulo.
Ejemplo de invocación unificada para Grok 4.3 y GPT-5.5
# Uso del SDK oficial de OpenAI para invocar ambos modelos mediante el servicio proxy de APIYI
from openai import OpenAI
client = OpenAI(
api_key="Tu API Key de APIYI",
base_url="https://vip.apiyi.com/v1"
)
# Invocación de Grok 4.3
grok_resp = client.chat.completions.create(
model="grok-4.3",
messages=[{"role": "user", "content": "Resume la arquitectura Transformer en 200 palabras"}]
)
# Invocación de GPT-5.5
gpt_resp = client.chat.completions.create(
model="gpt-5.5",
messages=[{"role": "user", "content": "Resume la arquitectura Transformer en 200 palabras"}],
reasoning_effort="high" # GPT-5.5 admite niveles de razonamiento explícitos
)
print("Grok 4.3:", grok_resp.choices[0].message.content)
print("GPT-5.5:", gpt_resp.choices[0].message.content)
Ver código completo de enrutamiento de arquitectura híbrida (selección automática según longitud de tokens)
from openai import OpenAI
from typing import Literal
client = OpenAI(
api_key="Tu API Key de APIYI",
base_url="https://vip.apiyi.com/v1"
)
ROUTE_THRESHOLDS = {
"simple": 500, # Prompt corto usa Grok 4 Fast
"reasoning": 8000, # Prompt medio usa Grok 4.3
"premium": 50000 # Prompt largo o tareas críticas usa GPT-5.5
}
def estimate_tokens(text: str) -> int:
"""Estimación simplificada de tokens: inglés por caracteres/4, chino por caracteres"""
return max(len(text) // 4, len(text) // 2)
def route_model(prompt: str, force_premium: bool = False) -> str:
"""Selecciona el modelo según la longitud del prompt y la complejidad de la tarea"""
if force_premium:
return "gpt-5.5"
tokens = estimate_tokens(prompt)
if tokens < ROUTE_THRESHOLDS["simple"]:
return "grok-4-fast"
elif tokens < ROUTE_THRESHOLDS["reasoning"]:
return "grok-4.3"
else:
return "gpt-5.5"
def smart_chat(prompt: str, force_premium: bool = False) -> str:
"""Invocación con enrutamiento inteligente"""
model = route_model(prompt, force_premium)
extra_params = {}
if model == "gpt-5.5":
extra_params["reasoning_effort"] = "high"
response = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": prompt}],
**extra_params
)
return f"[{model}] {response.choices[0].message.content}"
if __name__ == "__main__":
print(smart_chat("Hola"))
print(smart_chat("Ayúdame a diseñar una máquina de estados para pedidos de comercio electrónico"))
print(smart_chat("Esto es una base de código de 50k tokens..." * 1000, force_premium=True))
Consideraciones sobre la invocación de Grok 4.3 y GPT-5.5
| Aspecto | Grok 4.3 | GPT-5.5 |
|---|---|---|
| Campo del modelo | grok-4.3 |
gpt-5.5 |
| Configuración de razonamiento | Activado por defecto, sin configuración | reasoning_effort opcional low/medium/high/xhigh |
| Campo de entrada de video | video_url |
No soportado, requiere transcripción previa |
| Campo de salida de documento | extra_body={"output_format": "pdf/xlsx/pptx"} |
Requiere post-procesamiento en la capa de aplicación |
| Salida en streaming | stream=True |
stream=True (recomendado para producción) |
| Function Calling | ✅ Soporte completo | ✅ Soporte completo (incluye strict mode) |
| Memoria persistente | ❌ Requiere RAG en la capa de aplicación | ✅ Campo previous_response_id |
🎯 Consejo de integración: Recomendamos solicitar primero una clave de prueba en APIYI (apiyi.com) para completar el ciclo mínimo, y una vez validado, decidir si realizar una migración completa o una programación híbrida. La plataforma admite pagos en RMB y facturación por uso, ideal para los procesos financieros de equipos locales.
Recomendaciones de decisión: Grok 4.3 vs GPT-5.5
Método de decisión en tres pasos
Hemos comprimido el proceso de selección en tres pasos para que obtengas una respuesta en 90 segundos.
Paso 1: ¿Cuál es tu tipo de tarea principal?
- Programación / Matemáticas / Recuperación de contexto largo → Prioriza GPT-5.5
- Video / Generación de documentos / Contenido masivo / Conversación en tiempo real → Prioriza Grok 4.3
Paso 2: ¿Cuál es tu presupuesto mensual de tokens?
- < 100M tokens: Elige directamente el "modelo óptimo para tu tarea principal"
- 100M – 1B tokens: Es necesario implementar una arquitectura híbrida; Grok 4.3 como base y GPT-5.5 para tareas críticas
- ≥ 1B tokens: Clasificación en tres niveles (Grok 4 Fast / Grok 4.3 / GPT-5.5), de lo contrario los costes serán incontrolables
Paso 3: ¿Necesitas características exclusivas del ecosistema OpenAI?
- Sí (memoria persistente / Codex IDE / cumplimiento SOC2) → GPT-5.5
- No → Grok 4.3 tiene una relación calidad-precio imbatible
Matriz de decisión integral: Grok 4.3 vs GPT-5.5
| Tu prioridad | Elección recomendada | Alternativa |
|---|---|---|
| Relación calidad-precio extrema | Grok 4.3 | Grok 4 Fast |
| Precisión de programación extrema | GPT-5.5 | GPT-5.5 Pro |
| Razonamiento matemático extremo | GPT-5.5 Pro | GPT-5.5 |
| Procesamiento de video multimodal | Grok 4.3 | (Sin alternativa) |
| Recuperación precisa de contexto largo | GPT-5.5 | Grok 4.3 |
| Velocidad de conversación en tiempo real | Grok 4.3 | GPT-5.5 (razonamiento alto) |
| Producto con memoria persistente | GPT-5.5 | (Grok 4.3 requiere desarrollo propio) |
| Tareas offline masivas | Grok 4.3 | Modo Batch |
💡 Consejo de selección: La elección del modelo depende principalmente de tus casos de uso específicos y requisitos de calidad. Recomendamos integrar ambos modelos a través de la plataforma APIYI (apiyi.com), realizar pruebas A/B con datos reales de tu negocio y, finalmente, tomar la decisión definitiva.
Preguntas frecuentes sobre Grok 4.3 vs GPT-5.5
Q1: ¿Se pueden usar Grok 4.3 y GPT-5.5 en China?
Ambos son totalmente compatibles. Los dos modelos ya están disponibles en el servicio proxy de API de APIYI (apiyi.com), con una base_url unificada en https://vip.apiyi.com/v1 y los campos de modelo grok-4.3 y gpt-5.5 respectivamente. El servicio proxy cuenta con despliegues en múltiples centros de datos en el país, lo que garantiza una latencia estable sin necesidad de configurar un proxy propio. Grok 4.3 mantiene exactamente el mismo precio que en el sitio oficial de xAI, y GPT-5.5 se ofrece al precio oficial de OpenAI (tasa de entrada de 2.5, tasa de salida de 6, equivalente a $5/$30 por millón de tokens), sin cargos adicionales.
Q2: Con una diferencia de precio de 7 veces, ¿realmente vale la pena GPT-5.5?
Depende del caso de uso. Si tu tarea principal es la programación mediante agentes (Terminal-Bench, SWE-bench) o matemáticas de vanguardia (FrontierMath), la ventaja de precisión de GPT-5.5 se traduce directamente en menos tiempo de corrección manual y mayor calidad del producto, por lo que la diferencia de precio está justificada. Sin embargo, para tareas como generación masiva de contenido, atención al cliente, comprensión de video o automatización de documentos, la ventaja de precisión de GPT-5.5 es difícil de rentabilizar; en esos casos, la ventaja de costo de Grok 4.3 (7 veces más barato) es más significativa. Nuestra recomendación es: usa GPT-5.5 para rutas críticas y Grok 4.3 para rutas auxiliares, gestionando la carga mediante el servicio proxy de APIYI (apiyi.com).
Q3: Ambos modelos admiten una ventana de contexto de 1M, ¿hay diferencias en la usabilidad real?
Sí, y la diferencia es notable. GPT-5.5 alcanzó un 74.0% en la prueba MRCR v2 8-needle de 512K-1M, duplicando el 36.6% de GPT-5.4, lo que significa que su capacidad para "encontrar la aguja en el pajar" en contextos largos ha mejorado drásticamente. Grok 4.3 no ha publicado datos de MRCR, pero las pruebas de la comunidad muestran que su rendimiento en resúmenes de contexto largo es excelente, aunque su precisión en la "recuperación exacta" es ligeramente inferior a la de GPT-5.5. Si tu negocio depende de "encontrar 3 hechos específicos en 800k tokens", GPT-5.5 es más estable; si solo necesitas resúmenes de documentos largos, ambos cumplen perfectamente.
Q4: GPT-5.5 no admite video, ¿hay alguna alternativa?
Sí, pero la complejidad técnica aumenta considerablemente. Procesar video con GPT-5.5 suele requerir tres pasos: usar Whisper para obtener los subtítulos (STT), extraer fotogramas para el análisis multimodal con GPT-5.5 y, finalmente, integrar el razonamiento. Este flujo se completa en una sola solicitud con Grok 4.3. Si tu proyecto tiene necesidades de procesamiento de video, recomendamos usar directamente Grok 4.3 a través de APIYI (apiyi.com); la complejidad de ingeniería se reduce de 3 a 5 veces y el costo es menor.
Q5: ¿Necesito modificar mi código para actualizar de GPT-5.4 / GPT-5 a GPT-5.5?
Casi no es necesario. Solo basta con cambiar el campo del modelo de gpt-5 o gpt-5.4 a gpt-5.5, manteniendo la base_url igual. GPT-5.5 tiene un nivel de razonamiento mejorado por defecto; si necesitas un control preciso, puedes añadir el campo reasoning_effort (low/medium/high/xhigh). Para la misma tarea, GPT-5.5 utiliza menos tokens que GPT-5.4, por lo que el costo real puede ser igual o incluso menor, con una mejora general en la precisión, lo que hace que la migración sea muy rentable.
Q6: ¿Debería elegir GPT-5.5 o GPT-5.5 Pro?
Depende de la dificultad de la tarea. El precio de GPT-5.5 Pro es 6 veces mayor que el de GPT-5.5 ($30/$180 vs $5/$30), ofreciendo un nivel de razonamiento superior y una salida más estable. Recomendación: dedica el 95% del tráfico a GPT-5.5 y reserva GPT-5.5 Pro para "tareas extremadamente difíciles + decisiones críticas" (como demostraciones matemáticas complejas o revisiones de PR críticas). Así, obtendrás el máximo beneficio marginal usando solo un 5–10% de llamadas a GPT-5.5 Pro. Para la gran mayoría de los negocios, GPT-5.5 es suficiente.
Q7: Grok 4.3 no tiene memoria persistente, ¿afecta esto al producto?
Sí, pero existen soluciones maduras. Si tu producto es de tipo "asistente personal" o "conversación a largo plazo", la memoria persistente es necesaria. Grok 4.3 aún no la admite de forma nativa, por lo que se requiere construir una capa de memoria en la aplicación. Soluciones comunes como Mem0 o Letta son compatibles con el protocolo OpenAI Chat Completions y, por lo tanto, también con Grok 4.3. Recomendamos probar primero la conversación básica en APIYI (apiyi.com) y luego añadir la capa de memoria; es la forma más económica de iterar. Si no quieres construirla tú mismo, usar GPT-5.5 es la opción más sencilla.
Q8: ¿La facturación es la misma para ambos modelos en APIYI?
Es exactamente igual, ambos se facturan según el consumo de tokens. Grok 4.3 se ofrece al precio oficial de xAI (1:1, $1.25 entrada / $2.50 salida por millón de tokens). GPT-5.5 se ofrece al precio oficial de OpenAI (tasa de modelo 2.5, equivalente a $5.00 entrada; tasa de completado 6, equivalente a $30.00 salida por millón de tokens). Ambos modelos comparten la misma clave API y la misma base_url (https://vip.apiyi.com/v1), y la facturación se descuenta del mismo saldo de cuenta, lo que facilita enormemente la gestión y la conciliación.
Q9: ¿Cómo puedo reducir los costos de llamada de GPT-5.5?
Cuatro trucos clave: (1) Habilita el prompt caching; fijar el system prompt puede reducir costos entre un 50% y un 70%, con un costo de entrada en caché de solo $0.50/1M para GPT-5.5. (2) Reduce el reasoning_effort; para tareas simples, usar el nivel low puede reducir el consumo de tokens en un 60%. (3) Habilita la Batch API para tareas no críticas en tiempo real, ahorrando otro 50%. (4) Usa salida por streaming + terminación anticipada; para respuestas largas, puedes ahorrar tokens innecesarios al final. Combinando estas estrategias, el costo unitario real de GPT-5.5 puede acercarse al doble del precio de entrada de Grok 4.3.
Q10: ¿Cómo es la compatibilidad de Function Calling entre ambos modelos?
Son totalmente compatibles con el protocolo OpenAI Function Calling, por lo que el código es reutilizable. Ambos modelos admiten el campo tools, llamadas a herramientas en paralelo y strict mode (esquema JSON forzado). La diferencia es que el strict mode de GPT-5.5 tiene una validación de esquema más rigurosa, lo que reduce la activación errónea de herramientas; Grok 4.3 admite de forma nativa herramientas del lado del servidor (web_search / x_search / code_execution) sin necesidad de implementación en la capa de aplicación. Si tu proyecto depende fuertemente de Function Calling, ambos modelos pueden intercambiarse sin problemas; recomendamos realizar pruebas A/B integrándolos a través de APIYI (apiyi.com).
Conclusión: La elección real entre Grok 4.3 y GPT-5.5
En esencia, la comparación entre Grok 4.3 y GPT-5.5 no es sobre "quién es más fuerte", sino sobre dos rutas de producto distintas: xAI utiliza Grok 4.3 para aplanar la curva de costos de los modelos de razonamiento y ampliar los límites multimodales, mientras que OpenAI utiliza GPT-5.5 para elevar el techo de precisión en programación, matemáticas y recuperación de contexto largo.
Si tuviéramos que resumirlo en una frase: la mayoría de los equipos deberían usar Grok 4.3 como motor principal y GPT-5.5 como respaldo para rutas críticas. El precio de $1.25/$2.50, la velocidad de 207 tps y la entrada de video de Grok 4.3 pueden cubrir el 90% de los casos de uso; para el 10% restante de tareas de alto valor (programación avanzada, matemáticas de vanguardia, recuperación precisa en contextos largos), GPT-5.5 es la red de seguridad ideal. El costo total de esta combinación es del 15–25% comparado con usar "solo GPT-5.5", sin sacrificar la calidad en las tareas críticas.
Para los desarrolladores, la ruta de menor fricción para implementar esta arquitectura híbrida es el servicio proxy de APIYI (apiyi.com). Ambos modelos comparten la misma base_url y la misma clave API, por lo que solo necesitas cambiar el campo model en la aplicación, con un costo de ingeniería casi nulo. El precio de Grok 4.3 es idéntico al oficial y GPT-5.5 se ofrece sin sobrecostos. Si además aprovechas la Batch API y los descuentos por cached input, el costo unitario total puede reducirse otro 30–50%.
Finalmente, un consejo de ejecución: dedica una semana a probar ambos modelos con 100–500 muestras de tus datos reales en APIYI. Los resultados de referencia son solo una guía; la adecuación a tu negocio real es lo que debe dictar la decisión. Ambos modelos están disponibles de forma estable, la integración es gratuita y los datos obtenidos por ti mismo serán los más fiables.
Referencias
-
Anuncio oficial de OpenAI: Información de lanzamiento y documentación de la API de GPT-5.5
- Enlace:
openai.com/index/introducing-gpt-5-5 - Descripción: Incluye precios, benchmarks y especificaciones de los campos de la API.
- Enlace:
-
Documentación para desarrolladores de OpenAI: Especificaciones y ejemplos de invocación del modelo GPT-5.5
- Enlace:
developers.openai.com/api/docs/models/gpt-5.5 - Descripción: Parámetros completos de la API y detalles de facturación.
- Enlace:
-
Documentación de modelos de xAI: Especificaciones completas de la API de Grok 4.3
- Enlace:
docs.x.ai/developers/models - Descripción: Incluye capacidades exclusivas como entrada de video y generación de documentos.
- Enlace:
-
Ranking inteligente de Artificial Analysis: Comparativa integral de rendimiento entre modelos
- Enlace:
artificialanalysis.ai/models/grok-4-3 - Descripción: Evaluación integral del índice de inteligencia AA, velocidad y precios.
- Enlace:
-
Informe de referencia de Vellum: Análisis detallado de los benchmarks de la serie GPT-5 / GPT-5.5
- Enlace:
vellum.ai/blog/gpt-5-2-benchmarks - Descripción: Evaluaciones independientes basadas en múltiples benchmarks.
- Enlace:
-
Comparativa de modelos de DocsBot: Análisis detallado entre GPT-5.5 y Grok 4.3
- Enlace:
docsbot.ai/models/compare/gpt-5-5/grok-4-3 - Descripción: Comparativa de precios, rendimiento y características.
- Enlace:
-
Documentación de integración de APIYI: Tutorial completo para integrar ambos modelos mediante un servicio proxy de API local
- Enlace:
help.apiyi.com - Descripción: Incluye información sobre tasas, ejemplos de SDK y consultas de facturación.
- Enlace:
Autor: Equipo de APIYI — Especialistas en servicios proxy de API para Modelos de Lenguaje Grande, ayudando a desarrolladores locales a realizar la invocación de modelos líderes como Grok 4.3, GPT-5.5 y Claude Opus 4.7 con un solo clic. Visita APIYI en apiyi.com para obtener saldo de prueba gratuito.