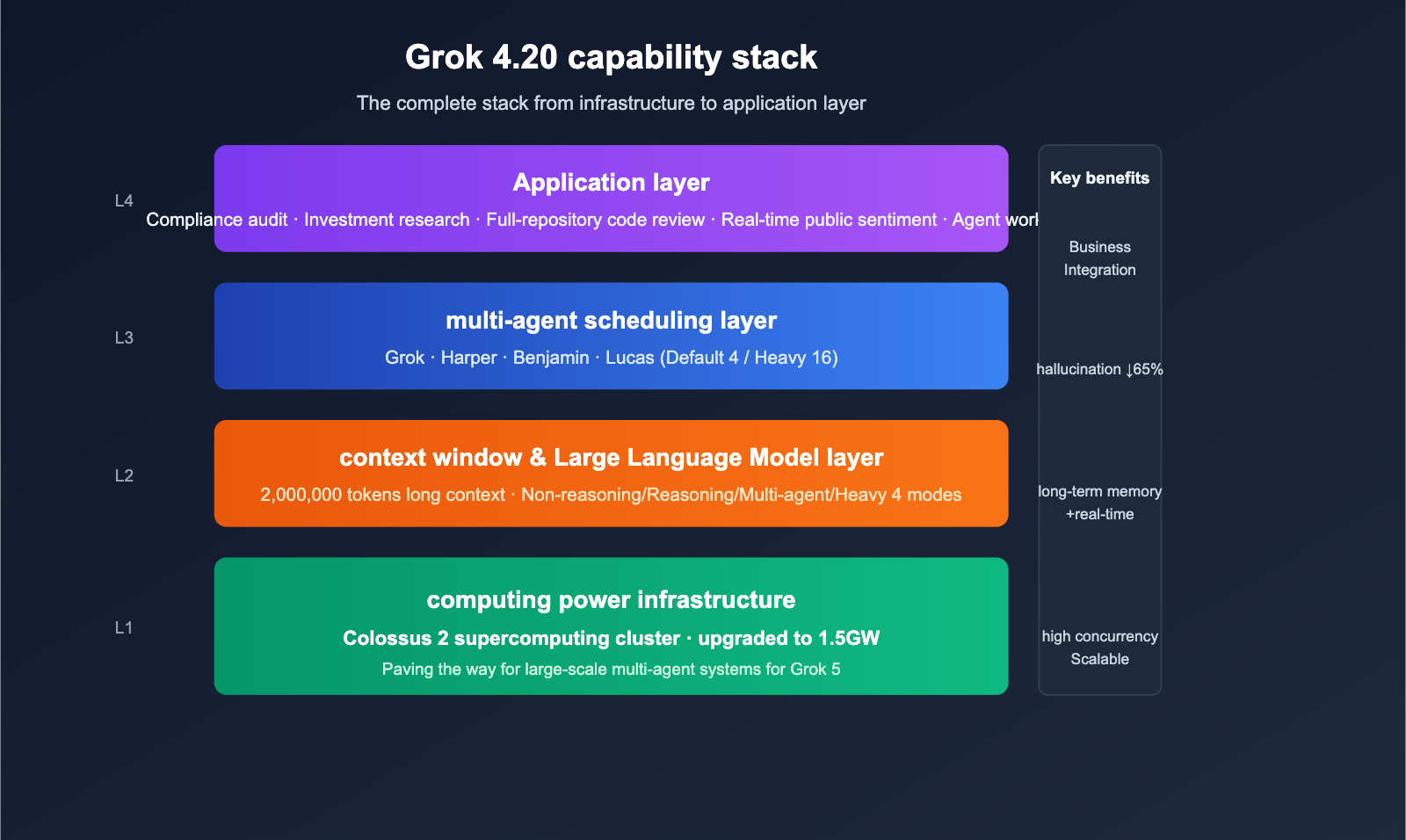
On February 17, 2026, xAI officially released Grok 4.20 Beta. It takes a highly unconventional approach to outperform the competition on the "non-hallucination rate" leaderboard—a space long dominated by the Claude and GPT series. Instead of simply stacking parameters or increasing inference steps, it employs four specialized agents (Grok / Harper / Benjamin / Lucas) that work in parallel on every complex query, debate with each other, and synthesize the final answer. Independent third-party evaluator Artificial Analysis Omniscience rated it at a 78% non-hallucination rate, while xAI claims it reaches 83% in comprehensive tests, surpassing Claude Opus 4.6 and GPT-5.4 in public benchmarks. Simultaneously, Grok 4.20 has pushed its context window to 2M tokens, offering a significant edge for ultra-long documents and long-cycle agentic tasks.
The underlying compute power is also scaling up: xAI’s Colossus 2 supercomputing cluster is gradually expanding to the 1.5GW level, preparing for the scaling of Grok 5 and future multi-agent systems. This article synthesizes primary English-language sources to break down Grok 4.20’s architecture, key benchmarks, "Heavy" mode, API availability, and typical use cases, helping you decide within 10 minutes whether it's worth the switch.
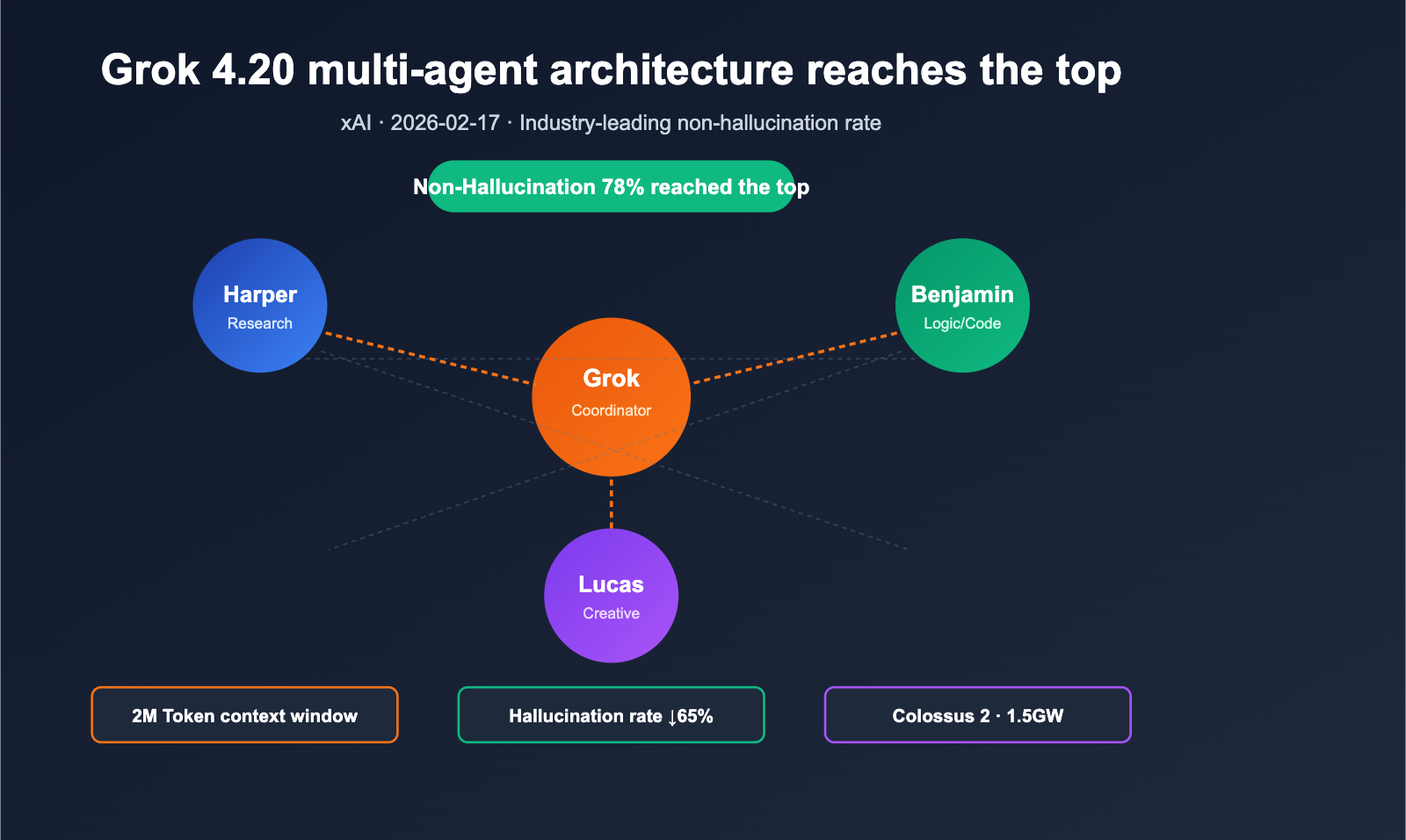
The Core Breakthrough of Grok 4.20's Multi-Agent Architecture
Compared to the mainstream approach of "a single larger model + deeper reasoning chains," Grok 4.20 has chosen a Swarm-style Reasoning path.
The Roles of the 4 Agents
| Role | Name | Responsibility | Key Capability |
|---|---|---|---|
| Orchestrator | Grok | Task decomposition, debate arbitration, final synthesis | Orchestration / Arbiter |
| Researcher | Harper | Real-time Web search + X Firehose data retrieval | Fact completion, timeliness verification |
| Logician | Benjamin | Math, code, structured reasoning and verification | Code execution validation, formal reasoning |
| Divergent Thinker | Lucas | Creative output, solution expansion, language polishing | Multi-candidate generation, answer optimization |
Whenever a complex query enters the model, Harper pulls real-time context, Benjamin performs logic and code reasoning in parallel, and Lucas generates multiple candidate answers. Finally, Grok coordinates the debate and synthesizes the final draft. This mechanism upgrades "one model, one forward pass" into "multi-round internal negotiation between four professional roles."
Why It Reduces Hallucinations
Traditional LLM hallucinations mainly stem from the model lacking self-verification for things it "doesn't know." Grok 4.20 forms a natural fact-checking mechanism through cross-agent verification:
- Harper detects that Benjamin's inference contradicts the latest web/X real-time data → Rejects it.
- Benjamin finds that Lucas's creative solution is mathematically unsound → Vetoes it.
- As the orchestrator, Grok only outputs conclusions that all three parties agree on.
Official disclosures indicate that this mechanism reduces the single-model hallucination rate from approximately 12% to about 4.2%, representing a 65% reduction in hallucinations.
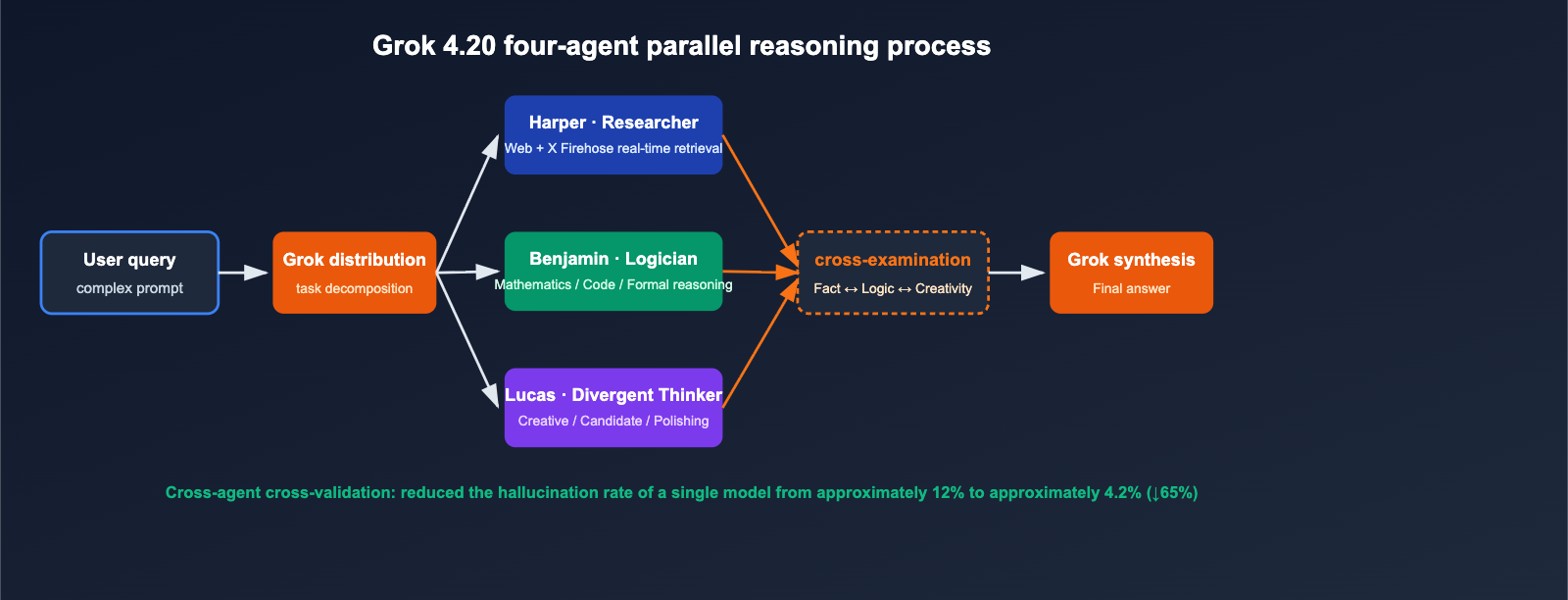
🎯 Architecture Insight: Multi-agent isn't "4 serial single-model passes," but rather 4-way parallel processing + debate within a single forward pass. Teams wanting to experience the difference quickly can use the APIYI (apiyi.com) API proxy service to call Grok 4.20 directly, run the same batch of prompts alongside other models, and compare the hallucination rates.
Grok 4.20 Key Metrics and Industry Comparison
The value of benchmark scores depends heavily on the evaluation set used, so I've separated the self-reported data from independent evaluations below.
Public Benchmark Overview
| Metric | Grok 4.20 | Claude Opus 4.6 | GPT-5.4 |
|---|---|---|---|
| Artificial Analysis Omniscience (Non-hallucination rate) | 78% (Top) | Runner-up | Third |
| xAI Self-reported Non-hallucination rate | ~83% | — | — |
| Hallucination rate (vs. Grok 4.1 baseline) | 4.22% (↓65%) | — | — |
| LMArena Thinking Elo | 1483 | — | — |
| Context window | 2,000,000 tokens | 200K (1M extended) | 400K class |
| Architecture | 4-agent parallel (Heavy mode 16) | Single model | Single model |
Heavy Mode: 4 → 16 Agent Scaling
Beyond the default 4-agent configuration, Grok 4.20 offers a Heavy mode: when deeper reasoning is required, the agent count scales from 4 to 16, covering a broader debate space and higher-dimensional cross-verification of evidence chains. The trade-off is increased cost and latency per request, making it ideal for "accuracy-critical, cost-insensitive" scenarios (investment research, compliance auditing, security analysis, etc.).
Mode and Scenario Quick Reference
| Mode | Agent Count | Use Case | Characteristics |
|---|---|---|---|
| Grok 4.20 Non-reasoning | 1 | Chat, Q&A | Low latency, low cost |
| Grok 4.20 Reasoning | 1 + CoT | Math, Coding | Moderate cost |
| Grok 4.20 Multi-agent (Default) | 4 | Complex queries, fact-checking | Significantly lower hallucinations |
| Grok 4.20 Heavy | 16 | Professional research, compliance | Highest accuracy |
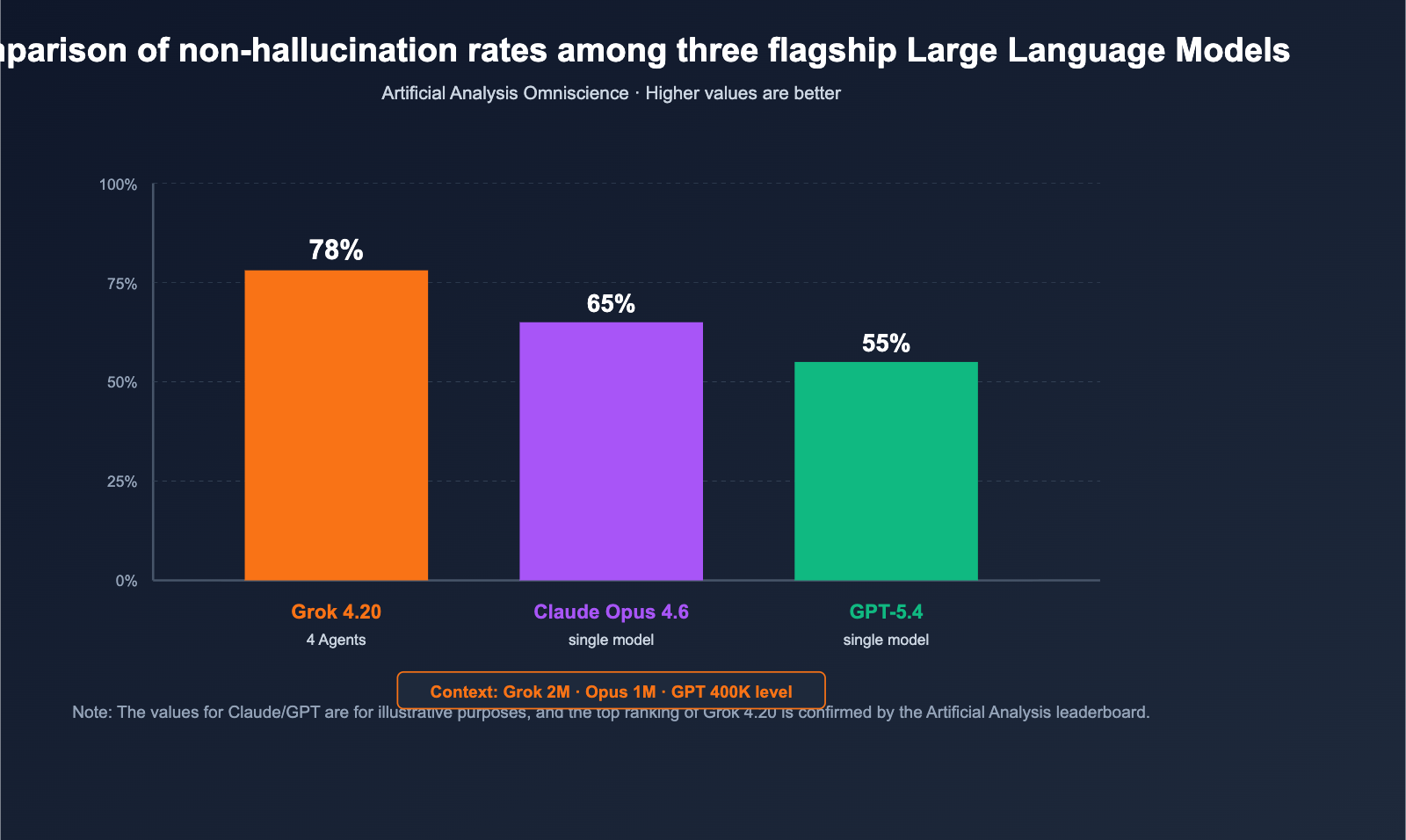
🎯 Benchmark Reading Tip: There can be a 5–10% gap between a model's self-reported scores and third-party evaluations. When selecting a model, prioritize independent benchmarks like Artificial Analysis. By using the APIYI (apiyi.com) API proxy service to compare Grok 4.20, Opus 4.6, and GPT-5.4 using the same prompt, you'll get a much clearer picture of how they perform in your specific business context.
Grok 4.20's 2M Context and Colossus 2 Compute Foundation
Architectural innovation requires hardware support, and two underlying upgrades in Grok 4.20 are worth noting.
The Value of a 2M Token Context Window
Grok 4.20 pushes the context window to 2,000,000 tokens, which means:
- Full-length books can be fed into a prompt at once without manual splitting;
- Long conversations / long-running agent sessions can maintain complete history;
- Multi-file code reviews can cover mid-sized monorepos;
- When combined with Harper's real-time retrieval, it creates a "long memory + real-time facts" advantage.
Colossus 2 Supercomputer Cluster Upgraded to 1.5GW
The Colossus 2 supercomputer cluster built by xAI for the Grok series is being upgraded to a 1.5GW-class scale. This infrastructure is aimed at supporting Grok 5 and even larger multi-agent swarms. The direct impact for developers:
- Higher inference availability and concurrency limits;
- Faster model iteration cycles;
- Grok 4.20 is already capable of running the "16 agents × 2M context" Heavy mode, with the compute baseline provided by this cluster.
Quick Start: Grok 4.20 API Invocation and APIYI Integration
Basic Invocation Example (OpenAI Compatible)
from openai import OpenAI
client = OpenAI(
base_url="https://api.apiyi.com/v1",
api_key="YOUR_API_KEY",
)
# Default 4-agent multi-agent mode
resp = client.chat.completions.create(
model="grok-4-20",
messages=[
{"role": "system", "content": "You are a factual research assistant."},
{"role": "user", "content": "Summarize the global AI chip shipment data for Q1 2026 and list the key sources."},
],
temperature=0.3,
max_tokens=4096,
)
print(resp.choices[0].message.content)
Invoking Heavy Mode (16 Agents)
# Heavy mode is suitable for high-accuracy scenarios, though it has higher latency and costs
resp = client.chat.completions.create(
model="grok-4-20-heavy",
messages=[
{"role": "user", "content": "Perform a risk summary and cross-reference verification for this 800-page compliance document."},
],
max_tokens=16384,
)
📎 Click to expand: 2M Ultra-long Context Invocation Example
# 2M context allows you to process an entire book or repository at once
with open("large_repo_dump.txt", "r") as f:
repo_text = f.read() # Can handle millions of tokens
resp = client.chat.completions.create(
model="grok-4-20",
messages=[
{"role": "system", "content": "You are a senior code reviewer."},
{"role": "user", "content": f"Here is the entire repository code. Please identify the 5 most critical issues:\n\n{repo_text}"},
],
max_tokens=8192,
)
Advantages of Integrating via APIYI
The Grok 4.20 API is now officially live on APIYI (apiyi.com). Pricing is identical to the official site, with the following added benefits:
- Discounts up to 15% off on top-ups, making long-term usage cheaper than direct connections;
- No concurrency limits, perfect for batch processing in Heavy mode;
- OpenAI-compatible interface, no need to refactor existing code—just swap the
base_urlandmodelfields; - Unified billing with other models like Claude and GPT, making it easy to run A/B tests across multiple models.
🎯 Integration Tip: Heavy mode consumes significantly more tokens per request than the standard mode, so the lack of concurrency limits is a huge advantage here. For new teams, we recommend testing your basic logic on APIYI (apiyi.com) using non-reasoning modes first, then switching your critical paths to multi-agent or Heavy mode.
Typical Use Cases for Grok 4.20
5 Workloads Best Suited for Grok 4.20
| Scenario | Recommended Mode | Key Benefit |
|---|---|---|
| News/Research Fact-Checking | Multi-agent (Default) | Harper real-time retrieval + cross-agent verification |
| Investment Research & Compliance | Heavy | 16-agent setup reduces errors in key facts |
| Full Book / Repo-level Analysis | Multi-agent + 2M | Process everything at once, no need for chunking |
| Multi-step Agent Workflows | Multi-agent | Built-in coordinator reduces external engineering |
| Real-time Sentiment / Social Monitoring | Multi-agent | Native integration with Harper and X Firehose |
Scenarios Not Recommended
- Millisecond-level IDE Completion: The latency introduced by multi-agent parallelism isn't suitable for tab-level interactions;
- Ultra-low-cost Batch Processing: Heavy mode is expensive; consider using non-reasoning modes or Haiku-level models instead;
- Strict Local Deployment Requirements: Grok 4.20 is currently provided as an API; there are no self-hosted weights available.
🎯 Migration Path Suggestion: Prioritize moving "hallucination-sensitive" workflows (compliance, medical, financial research, etc.) to the Grok 4.20 multi-agent mode. Use the billing dashboard on APIYI (apiyi.com) to track costs by path, allowing you to quantify the business gains from reduced hallucinations.
FAQ
Q1: Which is more reliable: a 78% non-hallucination rate or 83%?
The 78% figure comes from the independent third-party Artificial Analysis Omniscience benchmark, which is currently the most credible data available. The 83% figure is xAI's internal test result based on a broader dataset. When selecting a model, we recommend prioritizing independent benchmarks while using official data as a secondary reference. Both sources agree on one thing: Grok 4.20 has surpassed Claude Opus 4.6 and GPT-5.4 in terms of non-hallucination performance.
Q2: Does using 4 agents mean I have to perform 4 model invocations?
No. Multi-agent orchestration is handled internally on the xAI server side, exposing only a single API call to the user. While token billing is higher than in single-agent mode, it's significantly cheaper than chaining 4 requests on your own client side, and the latency is much lower.
Q3: What's the difference between Heavy mode and the standard multi-agent setup?
Heavy mode scales the parallel agents from 4 to 16. This further improves accuracy for complex reasoning and long evidence-chain tasks, but at the cost of significantly higher per-request expenses and latency. We recommend using it only in scenarios where "every error is costly," such as compliance, medicine, or investment research. By using APIYI (apiyi.com) to route requests to different modes, you can effectively "allocate compute based on value."
Q4: Can the 2M context window really be fully utilized?
Yes. Grok 4.20 claims an actual usable context window, not just a theoretical limit. However, keep in mind that as the context grows, the cost per token and latency increase linearly. For ultra-large contexts, we recommend combining context compression with multi-agent Harper retrieval.
Q5: What is the difference between using APIYI and the official website?
Pricing is identical to the official website, with recharge promotions offering up to 15% off. The key advantage is that there are no concurrency limits, making it ideal for batch calls in Heavy mode. The interface remains compatible with the OpenAI schema; you only need to point your base_url to apiyi.com in your code.
Q6: Will Grok 4.20 replace Grok 5?
No. Grok 5 remains xAI's next-generation flagship, supported by the Colossus 2 1.5GW cluster. Grok 4.20 is positioned more as a way to "validate the multi-agent paradigm on the 4th-gen architecture," providing engineering verification for the large-scale multi-agent systems expected in Grok 5.
Summary: The Multi-Agent Paradigm is Reshaping the Flagship Model Landscape
Grok 4.20 brings more than just a version update; it marks a shift in how flagship models compete: moving from "larger single models with deeper reasoning chains" to "multi-role group reasoning + real-time evidence verification." The combination of a 78% independent non-hallucination rate and a 2M context window means that high-stakes industries (compliance, investment research, medicine, law) finally have a "low-hallucination" option available via a general-purpose API.
For developers, the first step isn't to replace all your models, but to prioritize migrating your most error-sensitive workflows to the Grok 4.20 multi-agent mode, while keeping routine tasks on lower-cost models as part of a hybrid orchestration strategy. As an industry trend, Grok 5 and the Colossus 2 1.5GW cluster will continue to amplify this advantage, so getting started early means building up your multi-agent integration experience sooner.
🎯 Actionable Advice: The Grok 4.20 API is now live on APIYI (apiyi.com). Pricing is the same as the official site, with 15% off on recharges. Most importantly, there are no concurrency limits, making it perfect for high-throughput needs like multi-agent setups, Heavy mode, and 2M context windows. You can integrate it using standard OpenAI-compatible code—try switching over your "hallucination-sensitive" workflows today.
— APIYI Team (apiyi.com Technical Team)