description: 2026年2月17日,xAI发布Grok 4.20 Beta,通过4个智能体并行辩论架构,在非幻觉率榜单上实现反超,并支持2M上下文窗口。
2026 年 2 月 17 日,xAI 正式发布 Grok 4.20 Beta,以一种非常反常规的思路在"非幻觉率"这个长期被 Claude 与 GPT 系列霸占的榜单上实现反超:它并没有单纯堆参数或堆推理步数,而是让 4 个专业化智能体(Grok / Harper / Benjamin / Lucas)在每次复杂查询中并行工作、互相辩论、最后合成答案。独立第三方 Artificial Analysis Omniscience 测评给出 78% 非幻觉率,xAI 官方称综合测试可达 83%,在公开测评中超过 Claude Opus 4.6 与 GPT-5.4。同时 Grok 4.20 将上下文窗口推进到 2M token,在超长文档与长周期代理任务上取得显著优势。
背后的算力支撑也在升级:xAI 的 Colossus 2 超算集群 正逐步扩容至 1.5GW 级别,为 Grok 5 及后续多智能体规模化做准备。本文基于英文一手资料系统梳理 Grok 4.20 的架构设计、关键跑分、Heavy 模式、API 上线情况以及典型落地场景,帮助你在 10 分钟内判断是否值得切换。
Grok 4.20 多智能体架构的核心突破
相比"单个更大模型 + 更深推理链"的主流思路,Grok 4.20 选择了一条**群体智能(Swarm-style Reasoning)**路线。
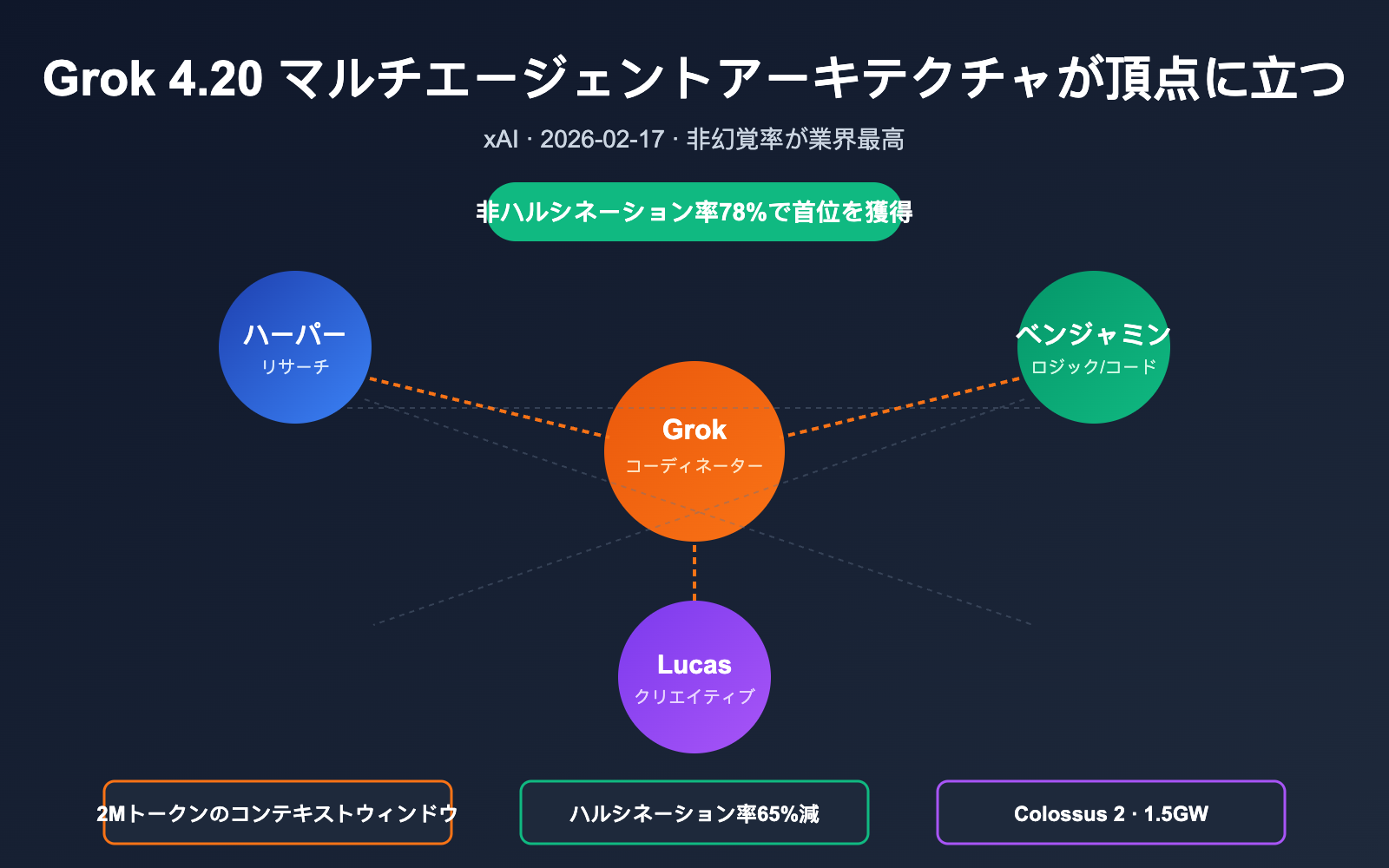
4 个智能体的分工
| 角色 | 名字 | 职责 | 关键能力 |
|---|---|---|---|
| 协调者 | Grok | 任务分解、辩论裁决、最终合成 | Orchestration / Arbiter |
| 研究员 | Harper | 实时 Web 搜索 + X Firehose 数据检索 | 事实补全、时效校验 |
| 逻辑员 | Benjamin | 数学、代码、结构化推理与验证 | 代码执行校验、形式化推理 |
| 发散员 | Lucas | 创意输出、方案扩展、语言润色 | 多候选生成、答案优化 |
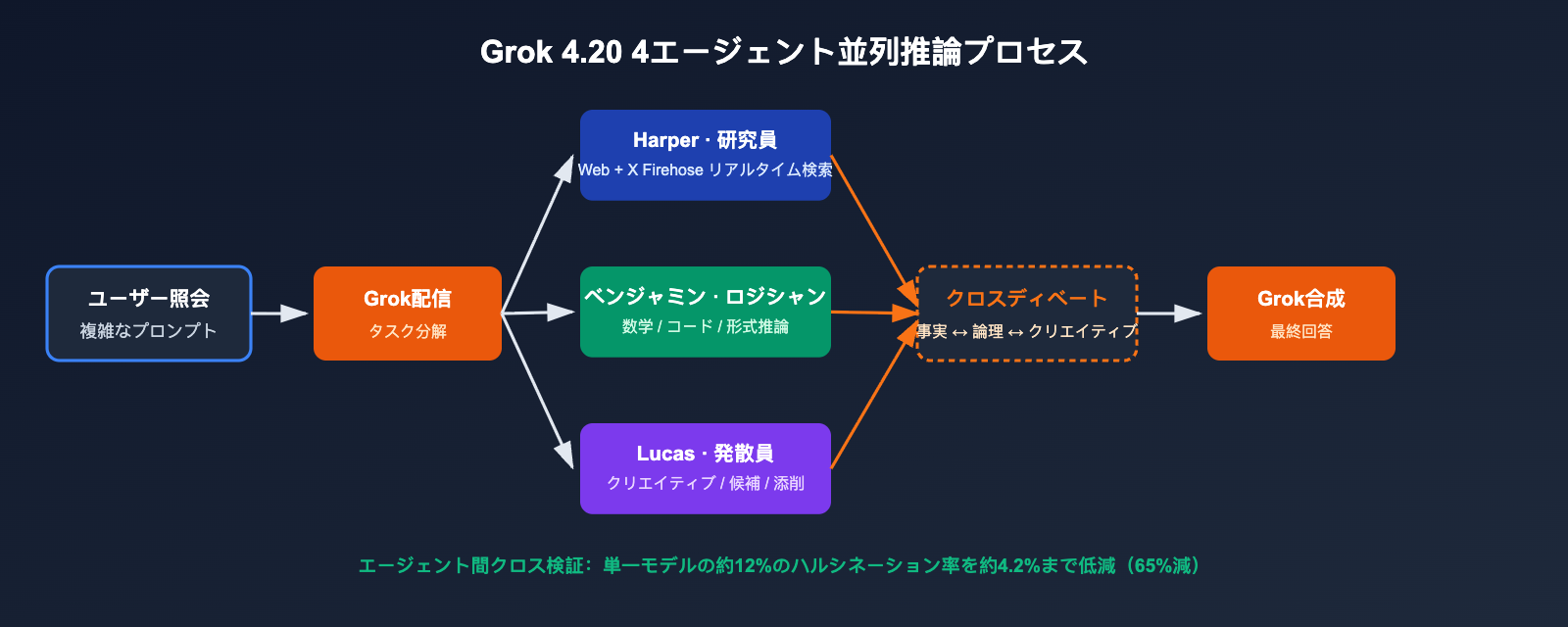
每次复杂查询进入模型后,Harper 先拉取实时上下文,Benjamin 同步进行逻辑与代码推理,Lucas 输出多组候选答案,最后由 Grok 协调辩论并合成终稿。这套机制把"一个模型一次前向推理"升级为"四个专业角色的内部多轮协商"。
为什么能降低幻觉
传统 LLM 的幻觉主要来自:模型对自己"不知道的事情"缺乏自我校验;Grok 4.20 通过 跨智能体交叉验证 形成自然的事实校对机制:
- Harper 发现 Benjamin 的推断与最新网页/X 实时数据相矛盾 → 打回;
- Benjamin 发现 Lucas 的创意方案数学不成立 → 否决;
- Grok 作为协调者只会输出三方都无反对的结论。
官方披露:这种机制把原本约 12% 的单模型幻觉率压到约 4.2%,相当于 65% 的幻觉下降。
🎯 架构理解提示:多智能体不是"4 次单模型串联",而是一次前向中 4 路并行+辩论。想快速体验差异的团队,可以通过 APIYI apiyi.com 直接调用 Grok 4.20,与其他模型并列跑同一批プロンプト,对比幻觉率差异。
Grok 4.20 の主要指標と業界比較
ベンチマークの結果は、どの評価セットを使用するかによって大きく左右されます。そのため、以下では自社レポートと独立した評価結果を分けて記載します。
公開ベンチマーク概要
| 指標 | Grok 4.20 | Claude Opus 4.6 | GPT-5.4 |
|---|---|---|---|
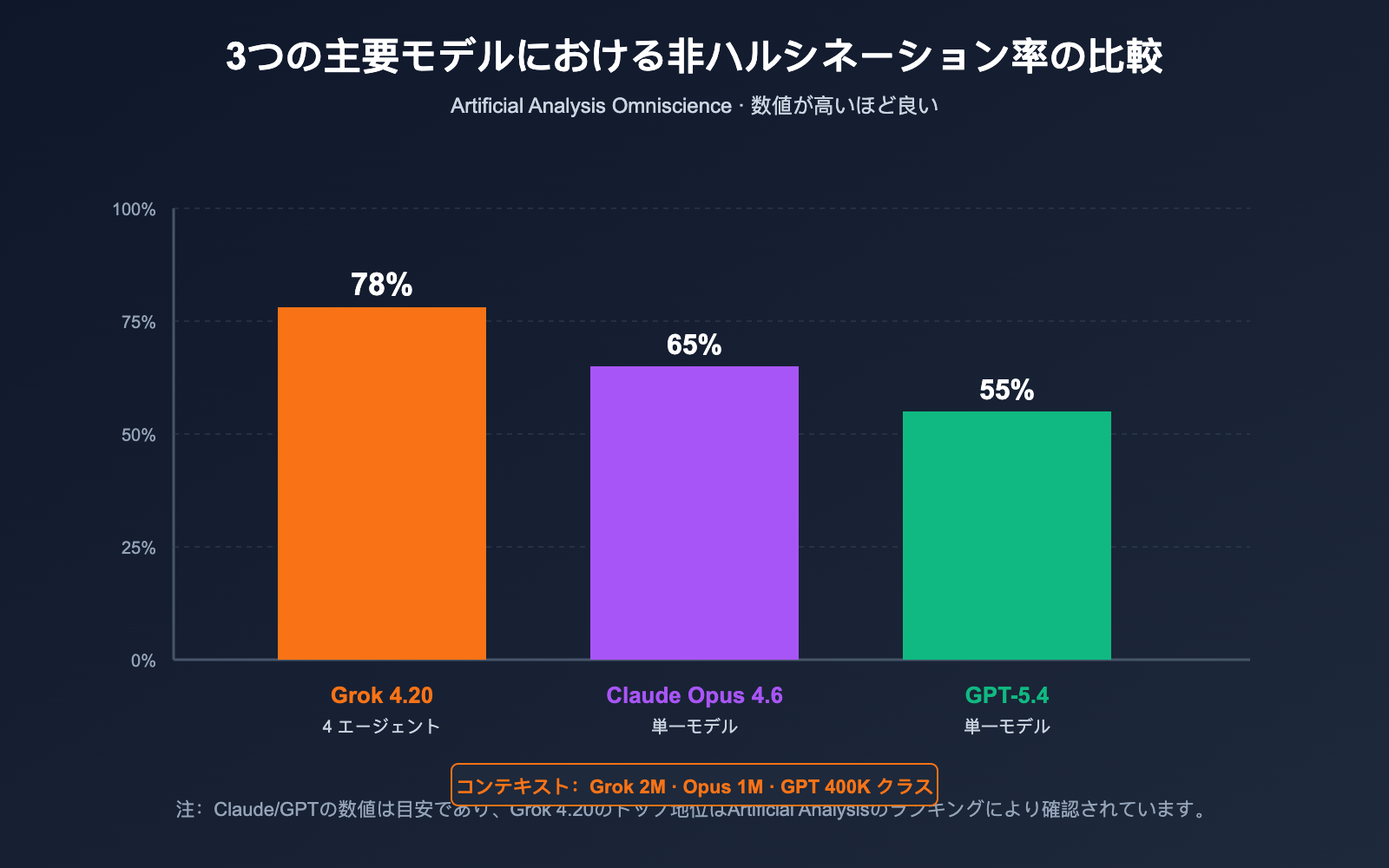
| Artificial Analysis Omniscience(非ハルシネーション率) | 78%(トップ) | 次点 | 第3位 |
| xAI 自社評価 総合非ハルシネーション率 | 約 83% | — | — |
| ハルシネーション率(Grok 4.1 ベースライン比) | 4.22%(↓65%) | — | — |
| LMArena Thinking Elo | 1483 | — | — |
| コンテキストウィンドウ | 2,000,000 トークン | 200K(1M 拡張) | 400K クラス |
| アーキテクチャ | 4 エージェント並列(Heavy モード 16) | 単一モデル | 単一モデル |
Heavy モード:4 → 16 エージェントへの拡張
デフォルトの 4 エージェント構成に加え、Grok 4.20 には Heavy モードが用意されています。より深い推論が必要な場合、エージェント数を 4 から 16 に拡張し、より広範な議論空間と高次元の証拠連鎖によるクロス検証を行います。代償としてリクエストごとのコストと遅延が増加するため、「正確性が極めて重要で、コストを問わない」シナリオ(投資調査、コンプライアンス監査、セキュリティ分析など)に適しています。
モードと用途のクイックリファレンス
| モード | エージェント数 | 適用シナリオ | 特徴 |
|---|---|---|---|
| Grok 4.20 非推論モード | 1 | チャット、Q&A | 低遅延、低コスト |
| Grok 4.20 推論モード | 1 + CoT | 数学、コード | 中程度のコスト |
| Grok 4.20 マルチエージェント(デフォルト) | 4 | 複雑なクエリ、事実確認 | ハルシネーションが大幅に減少 |
| Grok 4.20 Heavy | 16 | 専門調査、コンプライアンス監査 | 最高レベルの正確性 |
🎯 ベンチマーク読解のアドバイス:同一モデルでも、自社テストと第三者によるテストでは 5〜10% 程度の乖離が生じることがあります。選定時には Artificial Analysis などの独立したベンチマークを優先的に参照してください。APIYI (apiyi.com) を通じて同一のプロンプトで Grok 4.20 / Opus 4.6 / GPT-5.4 を比較することで、実際の業務環境におけるパフォーマンスをより正確に把握できます。
Grok 4.20 の 2M コンテキストと Colossus 2 計算基盤
アーキテクチャの革新にはハードウェアの裏付けが不可欠です。今回の Grok 4.20 における 2 つの基盤的なアップグレードにも注目です。
2M トークンコンテキストの価値
Grok 4.20 はコンテキストウィンドウを 2,000,000 トークンまで拡張しました。これは以下のことを意味します:
- 書籍レベルのドキュメントを一度にプロンプトへ入力可能(手動での分割不要)。
- 長時間の対話や長期間のエージェントセッションで完全な履歴を保持可能。
- 複数ファイルにわたるコードレビューで中規模のモノレポをカバー可能。
- Harper のリアルタイム検索能力と組み合わせることで、「長い記憶 + リアルタイムの事実」という強力な組み合わせを実現。
Colossus 2 スーパーコンピュータ・クラスタが 1.5GW へ
xAI が Grok シリーズのために構築した Colossus 2 スーパーコンピュータ・クラスタは、1.5GW クラスの計算規模へと拡張中です。このインフラは Grok 5 および、より大規模なマルチエージェント群を見据えたものです。開発者への直接的なメリットは以下の通りです:
- 推論の可用性と同時実行数の上限向上。
- 新モデルの反復速度の高速化。
- Grok 4.20 はすでに「16 エージェント × 2M コンテキスト」の Heavy モードを運用可能であり、その計算基盤はこのクラスタによって支えられています。

クイックスタート:Grok 4.20 API呼び出しとAPIYIへの接続
基本的な呼び出し例(OpenAI互換)
from openai import OpenAI
# APIYI経由でクライアントを初期化
client = OpenAI(
base_url="https://api.apiyi.com/v1",
api_key="YOUR_API_KEY",
)
# デフォルトの「4エージェント・マルチエージェントモード」を使用
resp = client.chat.completions.create(
model="grok-4-20",
messages=[
{"role": "system", "content": "あなたは事実に基づいたリサーチアシスタントです。"},
{"role": "user", "content": "2026年第1四半期のグローバルAIチップ出荷データをまとめ、主要なソースをリストアップしてください。"},
],
temperature=0.3,
max_tokens=4096,
)
print(resp.choices[0].message.content)
Heavyモードの呼び出し(16エージェント)
# Heavyモードは高精度が求められるシナリオに適していますが、遅延とコストが増加します
resp = client.chat.completions.create(
model="grok-4-20-heavy",
messages=[
{"role": "user", "content": "この800ページのコンプライアンス文書について、リスク要点のまとめとクロスリファレンスの検証を行ってください。"},
],
max_tokens=16384,
)
📎 2M超長コンテキスト呼び出しの例を展開する
# 2Mのコンテキストウィンドウにより、書籍1冊分やリポジトリ全体を一度に読み込めます
with open("large_repo_dump.txt", "r") as f:
repo_text = f.read() # 百万単位のトークンも処理可能
resp = client.chat.completions.create(
model="grok-4-20",
messages=[
{"role": "system", "content": "あなたはシニアコードレビュアーです。"},
{"role": "user", "content": f"以下はリポジトリ全体のコードです。最も深刻な問題を5つ指摘してください:\n\n{repo_text}"},
],
max_tokens=8192,
)
APIYIプラットフォーム接続のメリット
Grok 4.20のAPIは APIYI (apiyi.com) で正式に提供開始されました。価格は公式サイトと同等でありながら、以下の付加価値を提供します:
- チャージキャンペーンで最大15%OFF:長期利用時のコストを直販より抑えられます。
- 同時接続数無制限:Heavyモードでのバッチ処理タスクに最適です。
- OpenAI互換インターフェース:既存のコードを書き換える必要はなく、
base_urlとmodelフィールドを置き換えるだけで利用可能です。 - Claude / GPT等の他モデルと同一アカウントで課金:複数モデルを並行してA/Bテストする際に便利です。
🎯 接続のアドバイス:Heavyモードは1回のトークン消費量が通常モードの数倍になるため、同時接続数無制限のメリットがこのシナリオで最も発揮されます。新規導入チームは、まずAPIYI (apiyi.com) で推論モード以外の設定で基本ロジックをテストし、その後、重要なワークフローをマルチエージェントやHeavyモードに切り替えることをお勧めします。
Grok 4.20の典型的な活用シーン
Grok 4.20に最適な5つのワークロード
| シナリオ | 推奨モード | 主なメリット |
|---|---|---|
| ニュース/調査レポートの事実確認 | マルチエージェント(デフォルト) | Harperのリアルタイム検索 + エージェント間のクロス検証 |
| 投資調査とコンプライアンス審査 | Heavy | 16エージェントによる主要事実の誤り率低減 |
| 書籍/リポジトリ単位の長文分析 | マルチエージェント + 2M | 分割不要で一度に読み込み可能 |
| 多段階エージェントワークフロー | マルチエージェント | コーディネーター機能内蔵で外部エンジニアリングを削減 |
| リアルタイム世論/SNS監視 | マルチエージェント | HarperによるX Firehoseのネイティブ連携 |
推奨されないシナリオ
- ミリ秒単位のIDE補完:マルチエージェントの並列処理による遅延が発生するため、タブ補完のようなインタラクションには向きません。
- 極端な低コストバッチ処理:Heavyモードはコストが高いため、推論モードやHaikuクラスのモデルの方が経済的です。
- 厳格なローカルデプロイメントが必要な場合:Grok 4.20は現在API形式での提供であり、セルフホスト用のウェイトは公開されていません。
🎯 移行のヒント:「ハルシネーション(幻覚)への感度が高い」ワークフロー(コンプライアンス、医療、金融調査など)を優先的にGrok 4.20のマルチエージェントモードへ移行してください。APIYI (apiyi.com) の課金ダッシュボードでワークフローごとに統計を取ることで、ハルシネーションの低減がもたらすビジネス上の利益を定量化できます。
よくある質問(FAQ)
Q1:非ハルシネーション率 78% と 83%、どちらを信頼すべきですか?
78% は独立した第三者機関である Artificial Analysis Omniscience のテストセットによるもので、現在最も信頼性の高いデータです。一方、83% は xAI がより広範なテストセットで行った自社テストの結果です。モデル選定の際は、独立したベンチマークを主とし、公式データを補助として参照することをお勧めします。両者に共通している結論は、Grok 4.20 が非ハルシネーションの観点において、Claude Opus 4.6 や GPT-5.4 をすでに凌駕しているという点です。
Q2:4つのエージェントを使うということは、APIを4回呼び出すということですか?
いいえ、違います。マルチエージェントのスケジューリングは xAI のサーバー内部で完結するため、ユーザー側からは1回の API 呼び出しとして扱われます。トークン料金はシングルエージェントモードよりも高くなりますが、ユーザーがクライアント側で4回リクエストを繋ぐ手法に比べれば大幅に安く、遅延も抑えられます。
Q3:Heavyモードと通常モードのマルチエージェントにはどれくらいの差がありますか?
Heavyモードは並列エージェントの数を4から16に拡張します。複雑な推論や長い証拠チェーンを伴うタスクにおいて正解率がさらに向上しますが、その代償としてリクエストあたりのコストと遅延が大幅に増加します。「1つのミスが大きな損失につながる」コンプライアンス、医学、投資調査などのシナリオでのみ有効化することをお勧めします。APIYI (apiyi.com) を通じてリクエストごとにモードをルーティングすることで、「価値に応じた計算リソースの活用」が可能です。
Q4:2Mのコンテキストウィンドウは本当に使い切れますか?
はい、可能です。Grok 4.20 が公表しているのは理論上の上限ではなく、実際に利用可能なコンテキストサイズです。ただし、コンテキストが長くなるほどトークンあたりのコストと遅延が線形に増加することには注意が必要です。超大規模なコンテキストを利用する場合は、「コンテキスト圧縮」と「マルチエージェントによる Harper 検索」を併用することをお勧めします。
Q5:APIYIでの提供と公式サイトでの利用に違いはありますか?
価格は公式サイトと同等ですが、チャージキャンペーンを利用すれば最大15%オフ(85折)で利用可能です。最大のメリットは同時接続数(コンカレンシー)に制限がないことで、Heavyモードでのバッチ処理に最適です。インターフェースは OpenAI のスキーマと互換性があるため、コード側で base_url を apiyi.com に向けるだけで簡単に利用を開始できます。
Q6:Grok 4.20 は Grok 5 に取って代わられますか?
いいえ。Grok 5 は依然として xAI の次世代主力モデルであり、Colossus 2 1.5GW クラスターによって支えられています。Grok 4.20 の位置付けは、むしろ「マルチエージェントのパラダイムを第4世代アーキテクチャで先に確立し、Grok 5 の大規模マルチエージェント化に向けたエンジニアリング上の検証を行う」という役割が強いと言えます。
まとめ:マルチエージェント・パラダイムがフラッグシップモデルの勢力図を塗り替える
Grok 4.20 がもたらしたのは単なるバージョンアップではなく、フラッグシップモデルの競争軸の変化です。それは「単一モデルの巨大化や推論チェーンの深化」から、「マルチエージェントによる集団推論 + リアルタイムの証拠検証」への転換です。78% という独立した非ハルシネーション率と 2M コンテキストの組み合わせは、リスクの高い業務(コンプライアンス、投資調査、医学、法律)において、汎用 API で利用可能な「ハルシネーションの少ない最優先の選択肢」が初めて登場したことを意味します。
開発者にとっての第一歩は、すべてのモデルを置き換えることではなく、最もミスが許されないワークフローを優先的に Grok 4.20 のマルチエージェントモードへ移行し、通常のワークフローはコストの低いモデルに任せるというハイブリッドな構成にすることです。業界のトレンドとして、Grok 5 と Colossus 2 の 1.5GW クラスターがこの優位性をさらに拡大していくことは間違いありません。早期に導入することで、マルチエージェント活用のノウハウをいち早く蓄積できるでしょう。
🎯 アクションプラン:Grok 4.20 API は APIYI (apiyi.com) にて正式に提供を開始しました。価格は公式サイトと同等で、チャージキャンペーンで 15% オフ(85折)が適用されます。何より同時接続数が無制限であるため、マルチエージェントや Heavy モード、2M コンテキストといった高負荷なニーズに最適です。OpenAI 互換のコードで簡単に接続できるため、今日から「ハルシネーションを最も避けたい」ワークフローを切り替えてみてください。
— APIYI Team(APIYI apiyi.com 技術チーム)