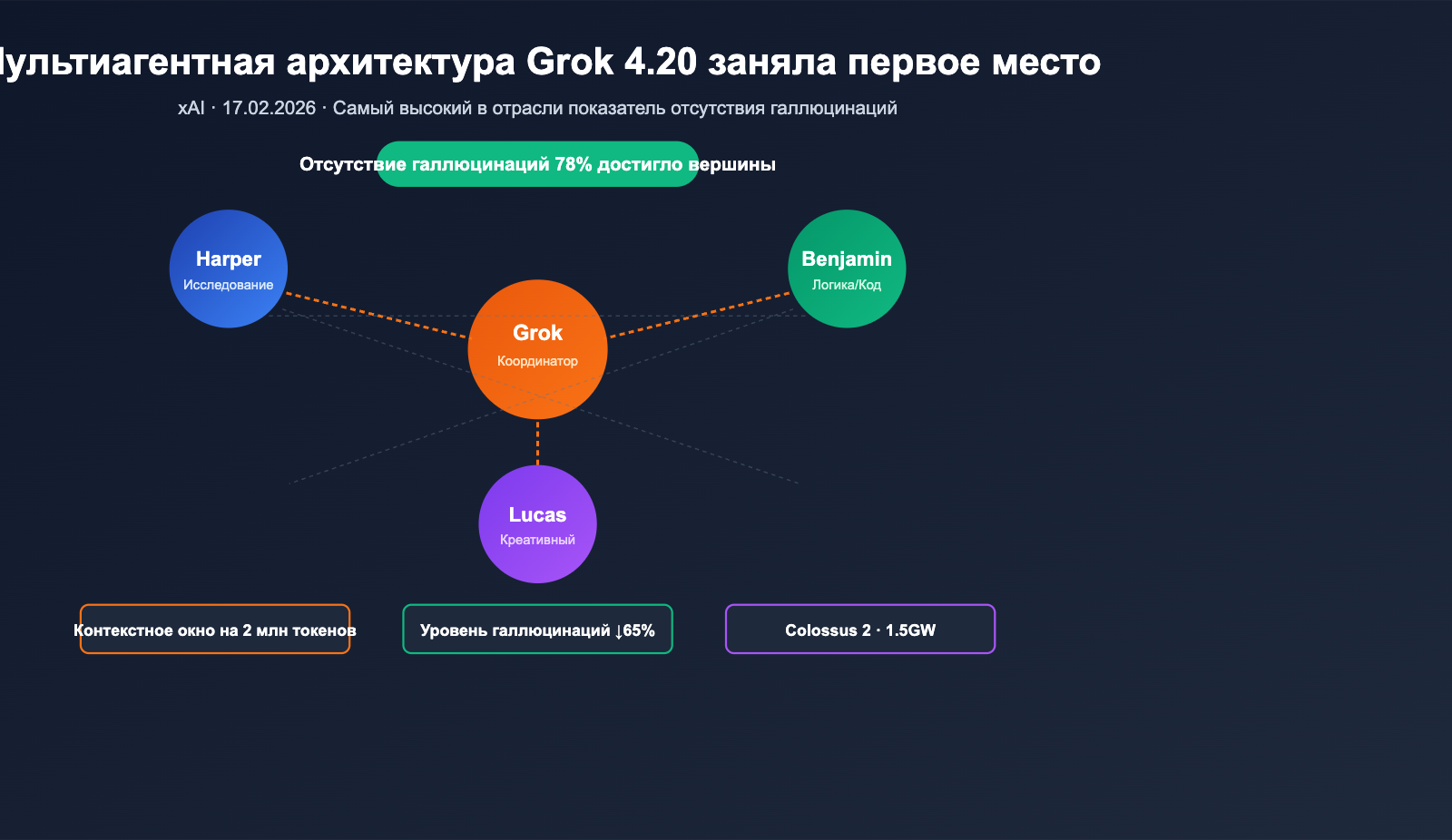
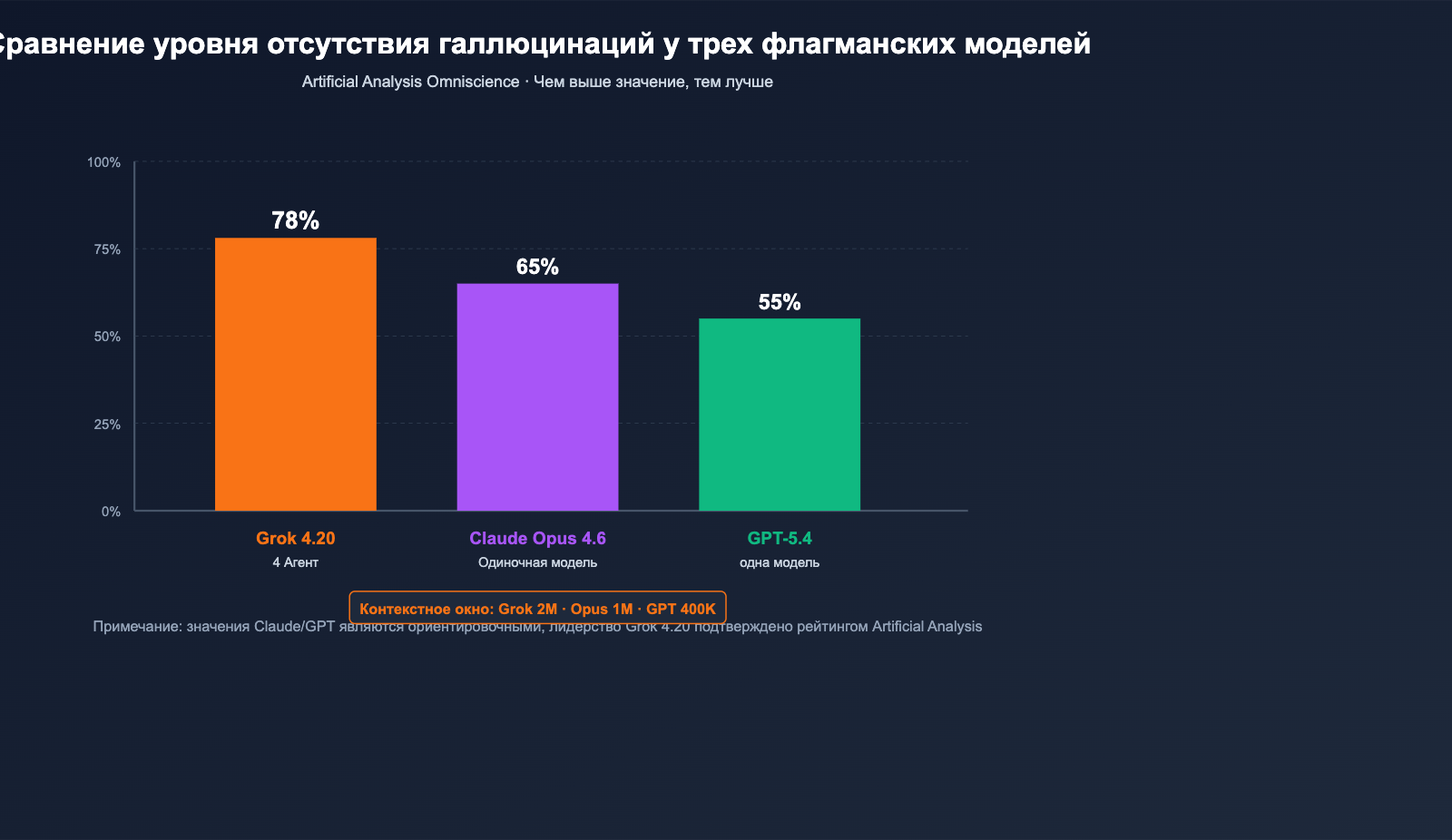
17 февраля 2026 года компания xAI официально представила Grok 4.20 Beta. Она выбрала весьма нестандартный путь, чтобы обойти конкурентов в рейтинге «отсутствия галлюцинаций», где долгое время доминировали серии Claude и GPT. Вместо простого наращивания параметров или глубины рассуждений, разработчики заставили 4 специализированных агента (Grok / Harper / Benjamin / Lucas) работать параллельно над каждым сложным запросом, дискутировать друг с другом и в итоге синтезировать единый ответ. Независимая площадка Artificial Analysis Omniscience оценила «отсутствие галлюцинаций» в 78%, а по официальным данным xAI, в комплексных тестах показатель достигает 83%, что превосходит Claude Opus 4.6 и GPT-5.4 в публичных бенчмарках. Кроме того, Grok 4.20 расширил контекстное окно до 2 млн токенов, что дает значительное преимущество при работе с огромными документами и долгосрочными агентскими задачами.
Техническая база также обновляется: суперкомпьютерный кластер xAI Colossus 2 постепенно расширяется до уровня 1,5 ГВт, подготавливая почву для Grok 5 и последующего масштабирования мультиагентных систем. В этой статье, основанной на первоисточниках, мы систематизируем архитектуру Grok 4.20, ключевые результаты тестов, режим Heavy, доступность API и типичные сценарии использования, чтобы вы могли за 10 минут решить, стоит ли переходить на новую модель.
Ключевой прорыв мультиагентной архитектуры Grok 4.20
В отличие от мейнстримного подхода «одна большая модель + более глубокая цепочка рассуждений», Grok 4.20 выбрал путь роевого интеллекта (Swarm-style Reasoning).
Распределение ролей между 4 агентами
| Роль | Имя | Обязанности | Ключевые навыки |
|---|---|---|---|
| Координатор | Grok | Декомпозиция задач, арбитраж дискуссий, синтез | Оркестрация / Арбитраж |
| Исследователь | Harper | Поиск в реальном времени + данные X Firehose | Проверка фактов, актуализация |
| Логик | Benjamin | Математика, код, структурированные рассуждения | Проверка кода, формальная логика |
| Генератор | Lucas | Креатив, расширение идей, стилистика | Генерация вариантов, оптимизация ответов |
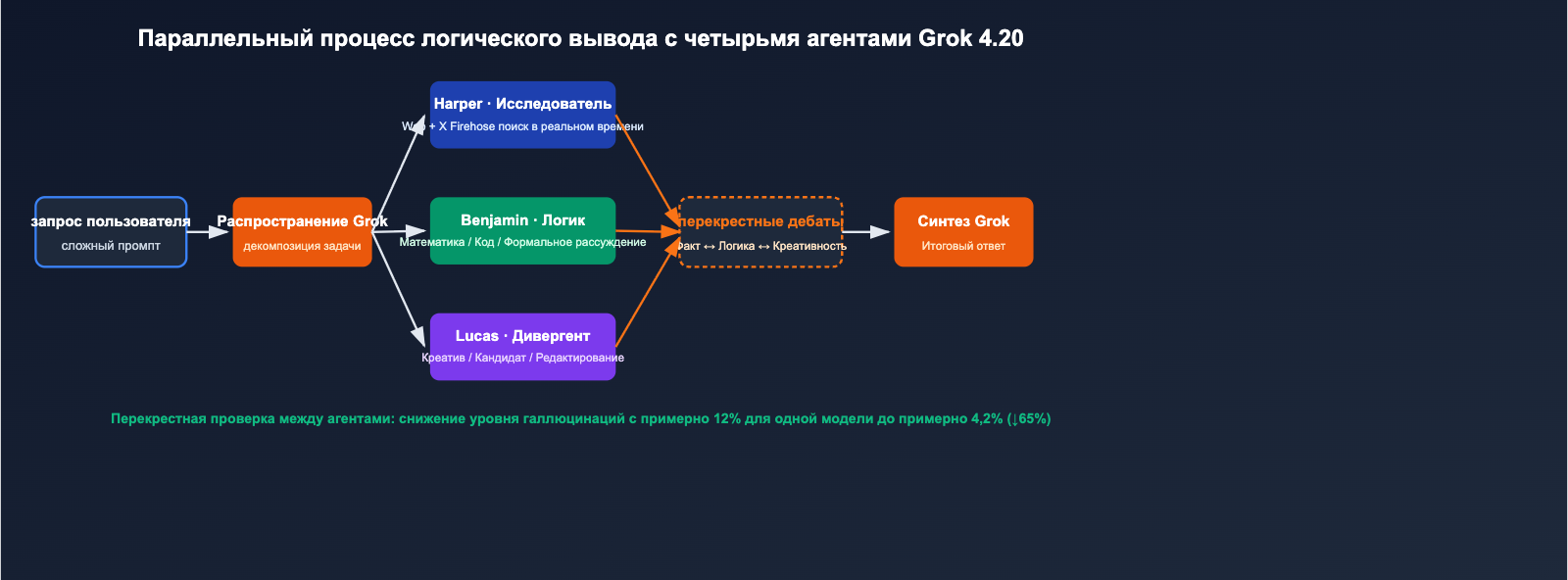
После поступления сложного запроса Harper извлекает актуальный контекст, Benjamin параллельно занимается логическими и программными вычислениями, Lucas создает несколько вариантов ответов, а Grok координирует дискуссию и формирует итоговый текст. Этот механизм превращает «один проход модели» в «многораундовое внутреннее обсуждение четырех профессиональных ролей».
Почему это снижает количество галлюцинаций
Галлюцинации традиционных LLM часто возникают из-за того, что модель не умеет проверять себя в том, чего «не знает». Grok 4.20 использует перекрестную проверку между агентами, создавая естественный механизм контроля фактов:
- Harper видит, что выводы Benjamin противоречат последним данным из сети или X → отправляет на доработку;
- Benjamin видит, что математика в креативном решении Lucas неверна → накладывает вето;
- Grok как координатор выдает только те выводы, против которых нет возражений у остальных сторон.
Официально заявлено: такой механизм снижает уровень галлюцинаций с 12% до примерно 4,2%, что эквивалентно снижению на 65%.
🎯 Совет по пониманию архитектуры: мультиагентность — это не «последовательное соединение 4 моделей», а параллельная работа 4 агентов с дискуссией в рамках одного прохода. Команды, желающие быстро оценить разницу, могут воспользоваться сервисом-прокси API APIYI (apiyi.com) для вызова Grok 4.20 и сравнения его работы с другими моделями на одном и том же промпте, чтобы увидеть разницу в уровне галлюцинаций.
Ключевые показатели и отраслевое сравнение Grok 4.20
Ценность бенчмарков во многом зависит от набора тестов, поэтому ниже мы разделили собственные отчеты компании и независимые оценки.
Обзор публичных бенчмарков
| Показатель | Grok 4.20 | Claude Opus 4.6 | GPT-5.4 |
|---|---|---|---|
| Artificial Analysis Omniscience (отсутствие галлюцинаций) | 78% (лидер) | Второе место | Третье место |
| Комплексный показатель xAI (без галлюцинаций) | ~83% | — | — |
| Уровень галлюцинаций (относительно базы Grok 4.1) | 4.22% (↓65%) | — | — |
| LMArena Thinking Elo | 1483 | — | — |
| Контекстное окно | 2 000 000 токенов | 200K (расширяется до 1M) | Уровень 400K |
| Архитектура | 4 агента параллельно (16 в режиме Heavy) | Одиночная модель | Одиночная модель |
Режим Heavy: расширение с 4 до 16 агентов
Помимо стандартной конфигурации из 4 агентов, Grok 4.20 предлагает режим Heavy: когда требуется более глубокий анализ, количество агентов увеличивается до 16, что обеспечивает более широкое поле для дискуссий и многоуровневую перекрестную проверку цепочек доказательств. Плата за это — рост стоимости одного запроса и задержки, поэтому режим подходит для задач, где "точность критически важна, а стоимость вторична" (инвестиционные исследования, комплаенс-аудит, анализ безопасности и т.д.).
Быстрый справочник режимов и сценариев
| Режим | Кол-во агентов | Сценарии использования | Характеристики |
|---|---|---|---|
| Grok 4.20 (обычный) | 1 | Чат, ответы на вопросы | Низкая задержка, низкая стоимость |
| Grok 4.20 (режим рассуждения) | 1 + CoT | Математика, код | Средняя стоимость |
| Grok 4.20 (мультиагентный, по умолчанию) | 4 | Сложные запросы, проверка фактов | Значительное снижение галлюцинаций |
| Grok 4.20 (Heavy) | 16 | Профессиональные исследования, аудит | Максимальная точность |
🎯 Совет по чтению бенчмарков: Самостоятельные тесты моделей и независимые оценки могут различаться на 5–10 процентных пунктов, поэтому при выборе модели лучше ориентироваться на независимые бенчмарки, такие как Artificial Analysis. Используя сервис-прокси API APIYI (apiyi.com), вы можете сравнить Grok 4.20, Opus 4.6 и GPT-5.4 на одном и том же промпте, чтобы увидеть реальную производительность в контексте ваших бизнес-задач.
Контекстное окно 2M и вычислительная база Colossus 2
Архитектурные инновации требуют аппаратной поддержки, и два фундаментальных обновления Grok 4.20 заслуживают особого внимания.
Ценность контекстного окна в 2 млн токенов
Увеличение контекстного окна Grok 4.20 до 2 000 000 токенов означает, что:
- Документы размером с целую книгу можно загрузить в промпт целиком без ручного разбиения;
- Длинные диалоги / сессии агентов сохраняют полную историю;
- Анализ кода в нескольких файлах может охватывать средние по размеру монорепозитории;
- В сочетании с возможностями поиска в реальном времени от Harper это создает преимущество "длинной памяти + актуальных фактов".
Обновление суперкомпьютера Colossus 2 до 1.5 ГВт
Суперкомпьютерный кластер Colossus 2, созданный xAI для серии Grok, обновляется до уровня мощности 1.5 ГВт. Эта инфраструктура нацелена на будущий Grok 5 и еще более масштабные мультиагентные системы. Что это дает разработчикам:
- Более высокая доступность вычислений и лимиты параллелизма;
- Ускорение темпов итерации новых версий моделей;
- Grok 4.20 уже способен поддерживать режим Heavy ("16 агентов × 2M контекста"), вычислительная база для которого обеспечивается именно этим кластером.

Быстрый старт: вызов API Grok 4.20 и подключение через APIYI
Базовый пример вызова (совместимость с OpenAI)
from openai import OpenAI
client = OpenAI(
base_url="https://api.apiyi.com/v1",
api_key="YOUR_API_KEY",
)
# Режим мультиагентности по умолчанию (4 агента)
resp = client.chat.completions.create(
model="grok-4-20",
messages=[
{"role": "system", "content": "You are a factual research assistant."},
{"role": "user", "content": "Подведи итоги по мировым поставкам AI-чипов в первом квартале 2026 года и укажи ключевые источники."},
],
temperature=0.3,
max_tokens=4096,
)
print(resp.choices[0].message.content)
Вызов в режиме Heavy (16 агентов)
# Режим Heavy подходит для задач с высокими требованиями к точности,
# но имеет более высокую задержку и стоимость
resp = client.chat.completions.create(
model="grok-4-20-heavy",
messages=[
{"role": "user", "content": "Проведи анализ рисков и перекрестную проверку фактов в этом документе на 800 страниц."},
],
max_tokens=16384,
)
📎 Развернуть, чтобы увидеть пример вызова с контекстным окном 2M
# Контекстное окно 2M позволяет загрузить целую книгу или весь репозиторий за раз
with open("large_repo_dump.txt", "r") as f:
repo_text = f.read() # Может достигать миллионов токенов
resp = client.chat.completions.create(
model="grok-4-20",
messages=[
{"role": "system", "content": "You are a senior code reviewer."},
{"role": "user", "content": f"Ниже представлен код всего репозитория. Найди 5 самых критических проблем:\n\n{repo_text}"},
],
max_tokens=8192,
)
Преимущества подключения через платформу APIYI
API для Grok 4.20 уже официально доступно на APIYI apiyi.com. Цены соответствуют официальным, но мы предлагаем дополнительные преимущества:
- Скидки до 15% при пополнении баланса, что делает долгосрочное использование выгоднее прямого подключения;
- Безлимитный параллелизм, что идеально подходит для массового запуска задач в режиме Heavy;
- Совместимость с интерфейсом OpenAI: не нужно переписывать код, достаточно просто заменить
base_urlи полеmodel; - Единый биллинг с другими моделями (Claude, GPT и др.), что упрощает проведение A/B тестов между моделями.
🎯 Совет по подключению: В режиме Heavy расход токенов за один запрос в несколько раз выше, чем в обычном режиме, поэтому преимущество безлимитного параллелизма здесь проявляется наиболее ярко. Новым командам рекомендуем сначала отладить логику в APIYI apiyi.com без использования режима рассуждений, а затем переключать критически важные цепочки на мультиагентный или Heavy-режим.
Типичные сценарии использования Grok 4.20
5 типов рабочих нагрузок, идеально подходящих для Grok 4.20
| Сценарий | Рекомендуемый режим | Ключевая выгода |
|---|---|---|
| Проверка фактов в новостях/отчетах | Мультиагентный (по умолчанию) | Поиск в реальном времени через Harper + перекрестная проверка между агентами |
| Инвестиционный анализ и комплаенс | Heavy | 16 агентов снижают вероятность ошибки в ключевых фактах |
| Анализ длинных документов (книги/репозитории) | Мультиагентный + 2M | Загрузка целиком без необходимости разбиения |
| Многошаговые рабочие процессы агентов | Мультиагентный | Встроенный координатор, упрощающий внешнюю инженерию |
| Мониторинг соцсетей и новостей | Мультиагентный | Нативная интеграция Harper с X Firehose |
Сценарии, в которых использование не рекомендуется
- IDE-автодополнение с задержкой в миллисекунды: задержка из-за параллельной работы агентов не подходит для интерактивных подсказок уровня Tab;
- Пакетная обработка с экстремально низкой стоимостью: режим Heavy стоит дорого, лучше использовать модели уровня Haiku или режимы без рассуждений;
- Необходимость строго локального развертывания: Grok 4.20 доступен только через API, веса для self-hosting не предоставляются.
🎯 Рекомендация по миграции: Переводите цепочки с высокой чувствительностью к галлюцинациям (комплаенс, медицина, финансовые исследования) на мультиагентный режим Grok 4.20 в первую очередь. Используя панель биллинга APIYI apiyi.com для раздельной статистики по цепочкам, вы сможете количественно оценить бизнес-выгоду от снижения количества галлюцинаций.
Часто задаваемые вопросы (FAQ)
Q1: Чему верить больше: показателю отсутствия галлюцинаций 78% или 83%?
78% — это данные из независимого стороннего набора тестов Artificial Analysis Omniscience, который на данный момент считается наиболее авторитетным. 83% — это результат внутренних тестов xAI на более широкой выборке. При выборе модели рекомендуем ориентироваться на независимые бенчмарки, используя официальные данные как вспомогательные. Оба источника сходятся в одном: Grok 4.20 по показателю отсутствия галлюцинаций уже превзошел Claude Opus 4.6 и GPT-5.4.
Q2: Означает ли использование 4 агентов, что нужно делать 4 вызова модели через API?
Нет. Оркестрация мультиагентной системы происходит внутри серверов xAI, поэтому для пользователя это выглядит как один вызов API. Расход токенов будет выше, чем в одноагентном режиме, но значительно ниже, чем при попытке «склеить» 4 запроса самостоятельно на стороне клиента, к тому же задержка будет гораздо меньше.
Q3: В чем разница между режимом Heavy и обычным мультиагентным режимом?
В режиме Heavy количество параллельных агентов увеличивается с 4 до 16. Это повышает точность в задачах со сложными цепочками рассуждений и длинными доказательствами, но ценой значительного роста стоимости одного запроса и задержки. Рекомендуем включать этот режим только там, где цена ошибки критически высока: в комплаенсе, медицине или инвестиционном анализе. Через APIYI (apiyi.com) вы можете маршрутизировать запросы в разные режимы, чтобы «использовать вычислительную мощность пропорционально ценности задачи».
Q4: Можно ли реально «забить» контекстное окно в 2 млн токенов?
Да. Grok 4.20 заявляет именно реально доступный объем контекста, а не теоретический предел. Однако помните: чем длиннее контекст, тем линейно выше стоимость каждого токена и задержка. Для работы с огромными объемами данных рекомендуем сочетать сжатие контекста + поиск Harper с использованием мультиагентов.
Q5: В чем разница между подключением через APIYI и официальный сайт?
Цена такая же, как на официальном сайте, а с учетом акций при пополнении можно получить скидку 15%. Главное преимущество — отсутствие ограничений по количеству параллельных запросов, что идеально подходит для пакетных вызовов в режиме Heavy. Интерфейс полностью совместим со схемой OpenAI, поэтому в коде достаточно просто изменить base_url на apiyi.com.
Q6: Заменит ли Grok 4.20 модель Grok 5?
Нет. Grok 5 остается флагманской моделью следующего поколения от xAI, работающей на кластере Colossus 2 1.5GW. Позиционирование Grok 4.20 скорее напоминает «обкатку мультиагентной парадигмы на архитектуре 4-го поколения», что служит инженерной проверкой перед масштабированием мультиагентов в Grok 5.
Итог: мультиагентная парадигма меняет ландшафт флагманских моделей
Grok 4.20 — это не просто очередное обновление, это смена вектора конкуренции среди флагманских моделей: переход от «увеличения размера и глубины рассуждений одной модели» к «групповому мышлению нескольких ролей + проверке доказательств в реальном времени». Сочетание 78% независимого показателя отсутствия галлюцинаций и 2 млн токенов контекста означает, что для высокорисковых отраслей (комплаенс, инвестиции, медицина, право) впервые появилось решение, которое можно считать «выбором №1 для минимизации галлюцинаций» через универсальный API.
Для разработчиков первый шаг — это не полная замена всех моделей, а приоритетный перенос самых критичных к ошибкам цепочек на мультиагентный режим Grok 4.20, при этом оставляя стандартные задачи на более дешевых моделях. В долгосрочной перспективе кластер Colossus 2 1.5GW для Grok 5 только усилит это преимущество, поэтому раннее подключение означает накопление опыта работы с мультиагентами уже сейчас.
🎯 Рекомендация: API Grok 4.20 уже доступен на APIYI (apiyi.com). Цены соответствуют официальным, действуют скидки 15% при пополнении, а главное — нет ограничений по параллельным запросам, что идеально для мультиагентных систем, режима Heavy и работы с контекстом 2M. Подключайтесь с помощью стандартного кода OpenAI и переводите свои «самые ответственные» задачи на новую модель уже сегодня.
— Команда APIYI (техническая команда APIYI apiyi.com)