title: "Grok 4.20 Beta 发布:多智能体辩论架构如何实现 83% 非幻觉率?"
description: "深度解析 xAI 的 Grok 4.20 Beta:通过 4 个智能体并行辩论的架构,实现 83% 非幻觉率,并支持 2M token 上下文。"
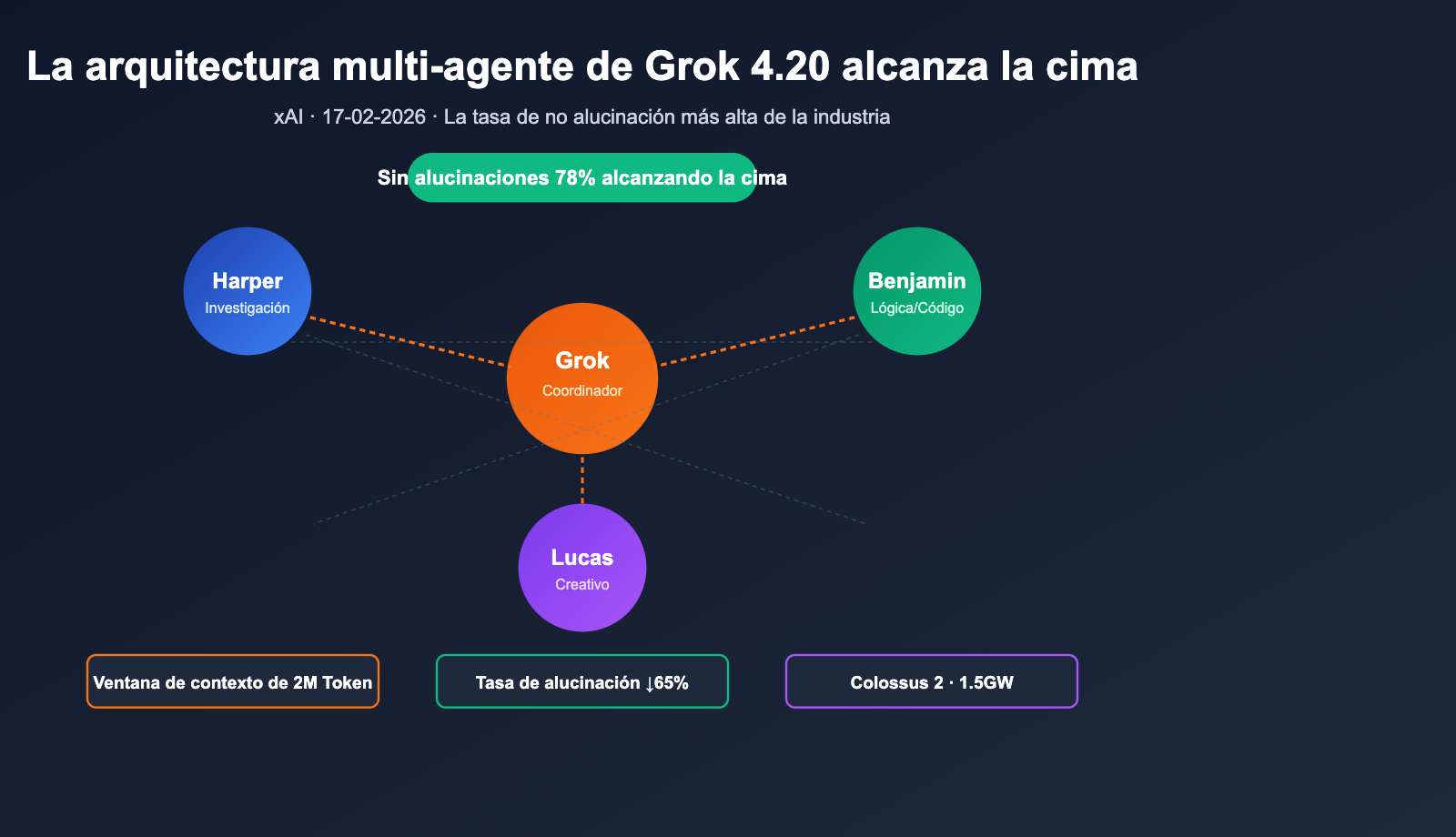
El 17 de febrero de 2026, xAI lanzó oficialmente Grok 4.20 Beta, utilizando un enfoque poco convencional para superar a las series Claude y GPT en el ranking de "tasa de no alucinación", un terreno dominado durante mucho tiempo por estos modelos. En lugar de simplemente aumentar los parámetros o los pasos de razonamiento, permite que 4 agentes especializados (Grok / Harper / Benjamin / Lucas) trabajen en paralelo en cada consulta compleja, debatan entre sí y finalmente sinteticen la respuesta. La evaluación independiente de terceros, Artificial Analysis Omniscience, le otorga una tasa de no alucinación del 78%, mientras que xAI afirma que en pruebas integrales puede alcanzar el 83%, superando a Claude Opus 4.6 y GPT-5.4 en evaluaciones públicas. Al mismo tiempo, Grok 4.20 amplía la ventana de contexto a 2M de tokens, logrando una ventaja significativa en documentos ultralargos y tareas de agentes de ciclo largo.
El soporte de potencia de cómputo subyacente también se está actualizando: el clúster de supercomputación Colossus 2 de xAI se está expandiendo gradualmente al nivel de 1.5GW, preparándose para Grok 5 y la futura escalabilidad de múltiples agentes. Este artículo, basado en fuentes primarias en inglés, sistematiza la arquitectura, las puntuaciones clave, el modo Heavy, la disponibilidad de la API y los escenarios de aplicación típicos de Grok 4.20, ayudándote a decidir en 10 minutos si vale la pena cambiar.
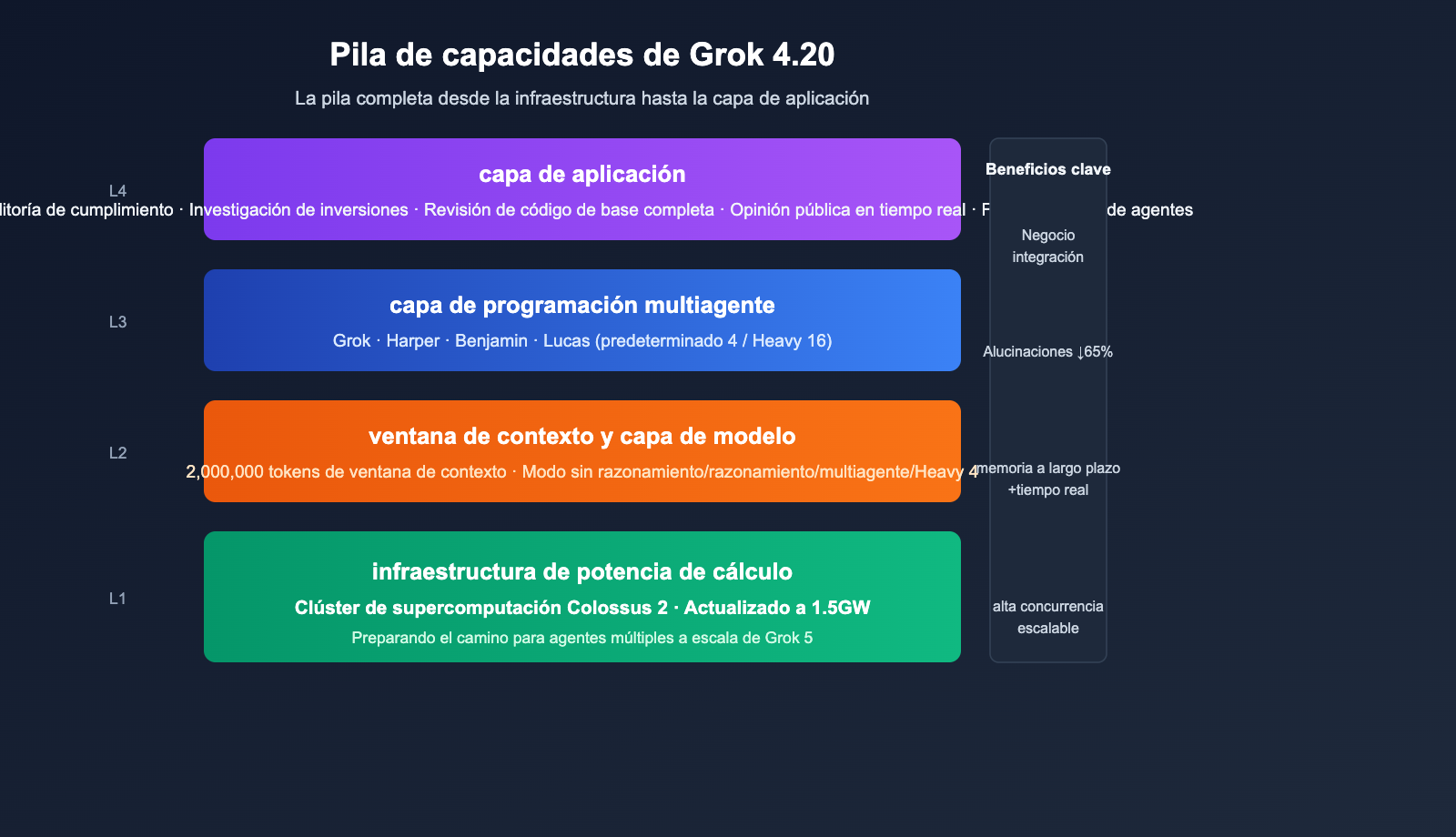
Avances clave en la arquitectura multiagente de Grok 4.20
En comparación con el enfoque convencional de "un modelo más grande + cadena de razonamiento más profunda", Grok 4.20 ha optado por una ruta de inteligencia de enjambre (razonamiento estilo Swarm).
División de tareas de los 4 agentes
| Rol | Nombre | Responsabilidad | Capacidad clave |
|---|---|---|---|
| Coordinador | Grok | Descomposición de tareas, arbitraje de debates, síntesis final | Orquestación / Árbitro |
| Investigador | Harper | Búsqueda web en tiempo real + recuperación de datos de X Firehose | Completado de hechos, verificación de actualidad |
| Lógico | Benjamin | Matemáticas, código, razonamiento estructurado y validación | Verificación de ejecución de código, razonamiento formal |
| Divergente | Lucas | Salida creativa, expansión de soluciones, pulido de lenguaje | Generación de múltiples candidatos, optimización de respuestas |
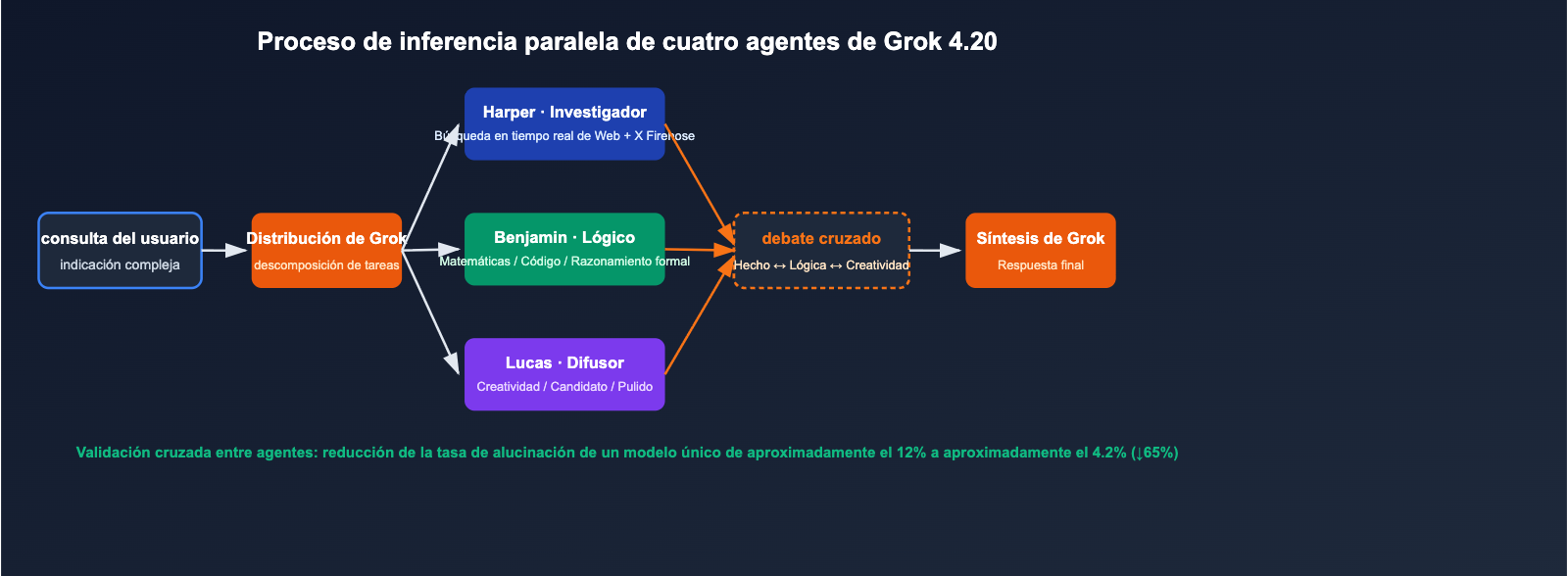
Cada vez que una consulta compleja ingresa al modelo, Harper primero extrae el contexto en tiempo real, Benjamin realiza razonamiento lógico y de código simultáneamente, Lucas genera múltiples grupos de respuestas candidatas y, finalmente, Grok coordina el debate y sintetiza la versión final. Este mecanismo actualiza el "razonamiento de avance único de un modelo" a una "negociación interna de múltiples rondas entre cuatro roles profesionales".
¿Por qué puede reducir las alucinaciones?
Las alucinaciones de los LLM tradicionales provienen principalmente de la falta de autoverificación del modelo sobre "cosas que no sabe". Grok 4.20 forma un mecanismo natural de verificación de hechos a través de la validación cruzada entre agentes:
- Harper descubre que la inferencia de Benjamin contradice los datos en tiempo real de la web/X → rechaza.
- Benjamin descubre que la solución creativa de Lucas no es matemáticamente válida → veta.
- Grok, como coordinador, solo emitirá conclusiones a las que ninguna de las partes se oponga.
Divulgación oficial: este mecanismo reduce la tasa de alucinación del modelo único, que era de aproximadamente el 12%, a alrededor del 4.2%, lo que equivale a una reducción del 65% en alucinaciones.
🎯 Consejo para entender la arquitectura: El sistema multiagente no es "4 veces la conexión en serie de un solo modelo", sino 4 rutas paralelas + debate en una sola inferencia de avance. Los equipos que deseen experimentar rápidamente las diferencias pueden invocar Grok 4.20 directamente a través de APIYI apiyi.com, ejecutar el mismo lote de indicaciones (prompt) junto con otros modelos y comparar las diferencias en la tasa de alucinación.
Métricas clave y comparativa industrial de Grok 4.20
El valor de los resultados de los benchmarks depende en gran medida del conjunto de pruebas utilizado, por lo que a continuación separamos los datos autoinformados de las evaluaciones independientes.
Resumen de benchmarks públicos
| Métrica | Grok 4.20 | Claude Opus 4.6 | GPT-5.4 |
|---|---|---|---|
| Artificial Analysis Omniscience (tasa de no alucinación) | 78% (líder) | Segundo lugar | Tercer lugar |
| Tasa de no alucinación (autoevaluación xAI) | ~83% | — | — |
| Tasa de alucinación (relativa a la base Grok 4.1) | 4.22% (↓65%) | — | — |
| LMArena Thinking Elo | 1483 | — | — |
| Ventana de contexto | 2,000,000 tokens | 200K (extensible a 1M) | Nivel 400K |
| Arquitectura | 4 agentes en paralelo (modo Heavy 16) | Modelo único | Modelo único |
Modo Heavy: expansión de 4 a 16 agentes
Además de la configuración predeterminada de 4 agentes, Grok 4.20 ofrece el modo Heavy: cuando se requiere una mayor profundidad de razonamiento, el número de agentes se expande de 4 a 16, lo que permite un espacio de debate más amplio y una validación cruzada de cadenas de evidencia de mayor dimensión. El costo es un aumento en la latencia y el precio por solicitud, ideal para escenarios donde la precisión es crítica y el costo no es la prioridad (investigación de inversiones, auditorías de cumplimiento, análisis de seguridad, etc.).
Guía rápida de modos y escenarios
| Modo | N.º de agentes | Escenario de uso | Características |
|---|---|---|---|
| Grok 4.20 sin razonamiento | 1 | Chat, preguntas y respuestas | Baja latencia, bajo costo |
| Grok 4.20 con razonamiento | 1 + CoT | Matemáticas, código | Costo medio |
| Grok 4.20 multi-agente (predeterminado) | 4 | Consultas complejas, verificación de hechos | Reducción significativa de alucinaciones |
| Grok 4.20 Heavy | 16 | Investigación profesional, auditoría | Máxima precisión |
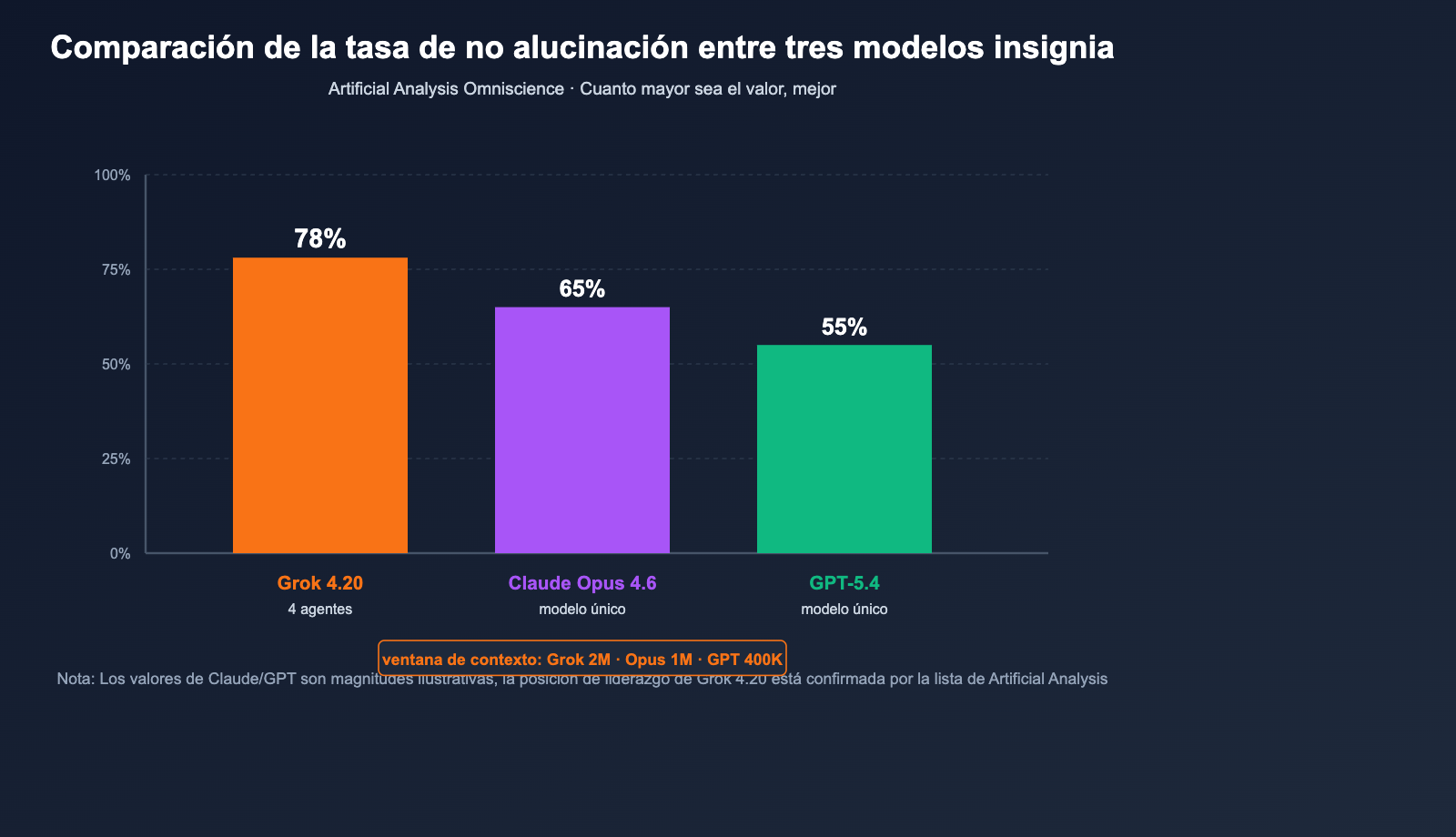
🎯 Consejo de lectura de benchmarks: Las autoevaluaciones y las de terceros pueden tener una diferencia de 5 a 10 puntos porcentuales. Al elegir un modelo, prioriza referencias independientes como Artificial Analysis. Al comparar Grok 4.20 / Opus 4.6 / GPT-5.4 con la misma indicación a través de APIYI (apiyi.com), podrás observar su rendimiento real en tu contexto de negocio.
Los 2M de contexto de Grok 4.20 y la base de cómputo Colossus 2
La innovación arquitectónica requiere soporte de hardware; estas dos actualizaciones subyacentes de Grok 4.20 también merecen atención.
El valor de los 2M de tokens de contexto
Grok 4.20 amplía la ventana de contexto a 2,000,000 tokens, lo que significa que:
- Documentos del tamaño de libros enteros pueden incluirse en una sola indicación sin necesidad de fragmentación manual;
- Conversaciones largas / sesiones de agentes prolongadas pueden mantener un historial completo;
- Revisiones de código de múltiples archivos pueden cubrir repositorios de tamaño mediano;
- Al combinarse con la capacidad de recuperación en tiempo real de Harper, se crea una ventaja combinada de "memoria larga + hechos en tiempo real".
El superclúster de supercomputación Colossus 2 se actualiza a 1.5GW
El superclúster de supercomputación Colossus 2, creado por xAI para la serie Grok, se está actualizando a una escala de 1.5GW, un objetivo de infraestructura orientado a Grok 5 y a grupos de multi-agentes de mayor escala. El impacto directo para los desarrolladores es:
- Mayor disponibilidad de inferencia y límites de concurrencia más altos;
- Velocidad de iteración de nuevos modelos más rápida;
- Grok 4.20 ya es capaz de soportar el modo Heavy de "16 agentes × 2M de contexto", cuya base de cómputo proviene de este clúster.
Guía rápida: Invocación de la API de Grok 4.20 e integración con APIYI
Ejemplo de invocación básica (compatible con OpenAI)
from openai import OpenAI
client = OpenAI(
base_url="https://api.apiyi.com/v1",
api_key="YOUR_API_KEY",
)
# Modo multi-agente predeterminado de 4 agentes
resp = client.chat.completions.create(
model="grok-4-20",
messages=[
{"role": "system", "content": "Eres un asistente de investigación basado en hechos."},
{"role": "user", "content": "Resume los datos de envíos globales de chips de IA del primer trimestre de 2026 y enumera las fuentes clave."},
],
temperature=0.3,
max_tokens=4096,
)
print(resp.choices[0].message.content)
Invocación en modo Heavy (16 agentes)
# El modo Heavy es ideal para escenarios de alta precisión, aunque tiene mayor latencia y costo
resp = client.chat.completions.create(
model="grok-4-20-heavy",
messages=[
{"role": "user", "content": "Realiza un resumen de los puntos de riesgo y una verificación de referencias cruzadas para este documento de cumplimiento de 800 páginas."},
],
max_tokens=16384,
)
📎 Desplegar para ver el ejemplo de invocación con ventana de contexto extendida de 2M
# La ventana de contexto de 2M permite procesar un libro completo o un repositorio entero de una sola vez
with open("large_repo_dump.txt", "r") as f:
repo_text = f.read() # Puede alcanzar millones de tokens
resp = client.chat.completions.create(
model="grok-4-20",
messages=[
{"role": "system", "content": "Eres un revisor de código senior."},
{"role": "user", "content": f"A continuación se muestra el código de todo el repositorio, por favor identifica los 5 problemas más graves:\n\n{repo_text}"},
],
max_tokens=8192,
)
Ventajas de la integración con la plataforma APIYI
La API de Grok 4.20 ya está disponible oficialmente en APIYI apiyi.com. El precio es idéntico al del sitio web oficial, pero con las siguientes ventajas adicionales:
- Promociones de recarga con hasta un 15% de descuento, lo que reduce el costo de uso a largo plazo en comparación con la conexión directa;
- Concurrencia ilimitada, ideal para ejecutar tareas por lotes en modo Heavy;
- Interfaz compatible con OpenAI, sin necesidad de modificar el código existente, solo basta con reemplazar los campos
base_urlymodel; - Facturación unificada con otros modelos como Claude o GPT, facilitando las pruebas A/B entre múltiples modelos desde una misma cuenta.
🎯 Sugerencia de integración: El consumo de tokens por invocación en modo Heavy es varias veces mayor que en el modo normal; la ventaja de la concurrencia ilimitada es más evidente en este escenario. Se recomienda a los equipos que recién comienzan que prueben primero la lógica básica en APIYI apiyi.com utilizando un modo que no sea de razonamiento, y luego migren los flujos críticos al modo multi-agente o Heavy.
Escenarios de aplicación típicos de Grok 4.20
Los 5 tipos de cargas de trabajo más adecuadas para Grok 4.20
| Escenario | Modo recomendado | Beneficio clave |
|---|---|---|
| Verificación de hechos en noticias/informes | Multi-agente (predeterminado) | Búsqueda en tiempo real de Harper + validación cruzada entre agentes |
| Investigación de inversiones y cumplimiento | Heavy | 16 agentes reducen la tasa de error en hechos críticos |
| Análisis de documentos largos (libros/repositorios) | Multi-agente + 2M | Procesamiento completo de una sola vez, sin necesidad de fragmentación |
| Flujos de trabajo de agentes de varios pasos | Multi-agente | Coordinador integrado, reduce la complejidad de la ingeniería externa |
| Monitoreo de opinión pública/redes sociales | Multi-agente | Integración nativa de Harper con X Firehose |
Escenarios no recomendados
- Autocompletado de IDE en milisegundos: La latencia generada por el procesamiento paralelo de múltiples agentes no es adecuada para interacciones tipo Tab;
- Procesamiento por lotes de costo extremadamente bajo: El precio del modo Heavy es elevado; es mejor usar modelos sin razonamiento o de nivel Haiku;
- Necesidad de despliegue local estricto: Grok 4.20 se ofrece actualmente como API, no cuenta con pesos para autohospedaje.
🎯 Sugerencia de ruta de migración: Priorice la migración de flujos de trabajo "sensibles a las alucinaciones" (cumplimiento, medicina, investigación financiera, etc.) al modo multi-agente de Grok 4.20. Utilice el panel de facturación de APIYI apiyi.com para desglosar las estadísticas por flujo, lo que le permitirá cuantificar el beneficio comercial derivado de la reducción de alucinaciones.
Preguntas frecuentes (FAQ)
Q1: ¿Es más fiable una tasa de no alucinación del 78% o del 83%?
El 78% proviene del conjunto de pruebas independiente de terceros Artificial Analysis Omniscience, que es actualmente el dato con mayor credibilidad; el 83% es el resultado de las pruebas internas de xAI en un conjunto de datos más amplio. Nuestra recomendación para la selección de modelos es priorizar los puntos de referencia independientes y usar los datos oficiales como referencia secundaria. La conclusión compartida por ambos es que Grok 4.20 ha superado a Claude Opus 4.6 y GPT-5.4 en la dimensión de no alucinación.
Q2: ¿Cuatro agentes significan realizar cuatro llamadas a la API?
No. La programación de múltiples agentes se realiza internamente en el servidor de xAI, exponiendo solo una única llamada a la API al usuario. La facturación por tokens será mayor que en el modo de agente único, pero mucho menor que en un esquema donde tú mismo encadenas cuatro solicitudes desde el cliente, además de ofrecer una latencia menor.
Q3: ¿Qué diferencia hay entre el modo Heavy y el modo multi-agente normal?
El modo Heavy amplía el número de agentes paralelos de 4 a 16, lo que mejora aún más la precisión en tareas de razonamiento complejo y cadenas de evidencia largas, a costa de un aumento significativo en el costo y la latencia por solicitud. Recomendamos activarlo solo en escenarios donde "cada error tiene un costo elevado", como en cumplimiento normativo, medicina o investigación de inversiones. A través de APIYI (apiyi.com), puedes enrutar las solicitudes a diferentes modos para lograr un "uso de potencia de cómputo según el valor".
Q4: ¿Realmente se puede aprovechar una ventana de contexto de 2M?
Sí. Grok 4.20 declara una ventana de contexto utilizable en la práctica, no un límite teórico. Sin embargo, ten en cuenta que, a mayor contexto, el costo por token y la latencia aumentan linealmente; para contextos muy grandes, recomendamos combinar la compresión de contexto + la recuperación Harper de múltiples agentes.
Q5: ¿Qué diferencia hay entre usar APIYI y el sitio web oficial?
El precio es el mismo que en el sitio oficial, con promociones de recarga que pueden alcanzar un 15% de descuento. La ventaja clave es que no hay límite de concurrencia, lo que lo hace ideal para llamadas masivas en modo Heavy. La interfaz mantiene la compatibilidad con el esquema de OpenAI, por lo que a nivel de código solo necesitas apuntar la base_url a apiyi.com.
Q6: ¿Reemplazará Grok 4.20 a Grok 5?
No. Grok 5 sigue siendo el objetivo principal de la próxima generación de xAI, respaldado por el clúster Colossus 2 de 1.5GW. El posicionamiento de Grok 4.20 es más bien el de "validar el paradigma multi-agente en la arquitectura de cuarta generación", proporcionando una verificación de ingeniería para el escalado de agentes múltiples en Grok 5.
Conclusión: El paradigma multi-agente comienza a cambiar el panorama de los modelos insignia
Lo que trae Grok 4.20 no es solo una actualización de versión, sino un cambio en las dimensiones de competencia de los modelos insignia: pasando de "modelos individuales más grandes con cadenas de razonamiento más profundas" a "razonamiento grupal de múltiples roles + verificación de evidencia en tiempo real". La combinación de una tasa de no alucinación independiente del 78% y una ventana de contexto de 2M significa que, por primera vez, las operaciones de alto riesgo (cumplimiento, investigación de inversiones, medicina, legal) tienen una opción "preferente de baja alucinación" disponible a través de una API general.
Para los desarrolladores, el primer paso no es reemplazar todos los modelos, sino migrar primero las cadenas de procesos donde más se temen los errores al modo multi-agente de Grok 4.20, manteniendo los procesos convencionales en modelos de menor costo mediante una orquestación híbrida. En cuanto a la tendencia de la industria, el clúster de 1.5GW de Grok 5 y Colossus 2 seguirá amplificando esta ventaja; integrarse pronto significa acumular experiencia en invocación multi-agente antes que los demás.
🎯 Recomendación de acción: La API de Grok 4.20 ya está disponible oficialmente en APIYI (apiyi.com). El precio es igual al del sitio oficial, con un 15% de descuento en recargas y, lo más importante, sin límites de concurrencia, ideal para necesidades de alto rendimiento en modo multi-agente, modo Heavy y contextos de 2M. Puedes integrarlo con el código compatible de OpenAI; migra hoy mismo tus procesos "más sensibles a las alucinaciones".
— Equipo de APIYI (Equipo técnico de APIYI apiyi.com)