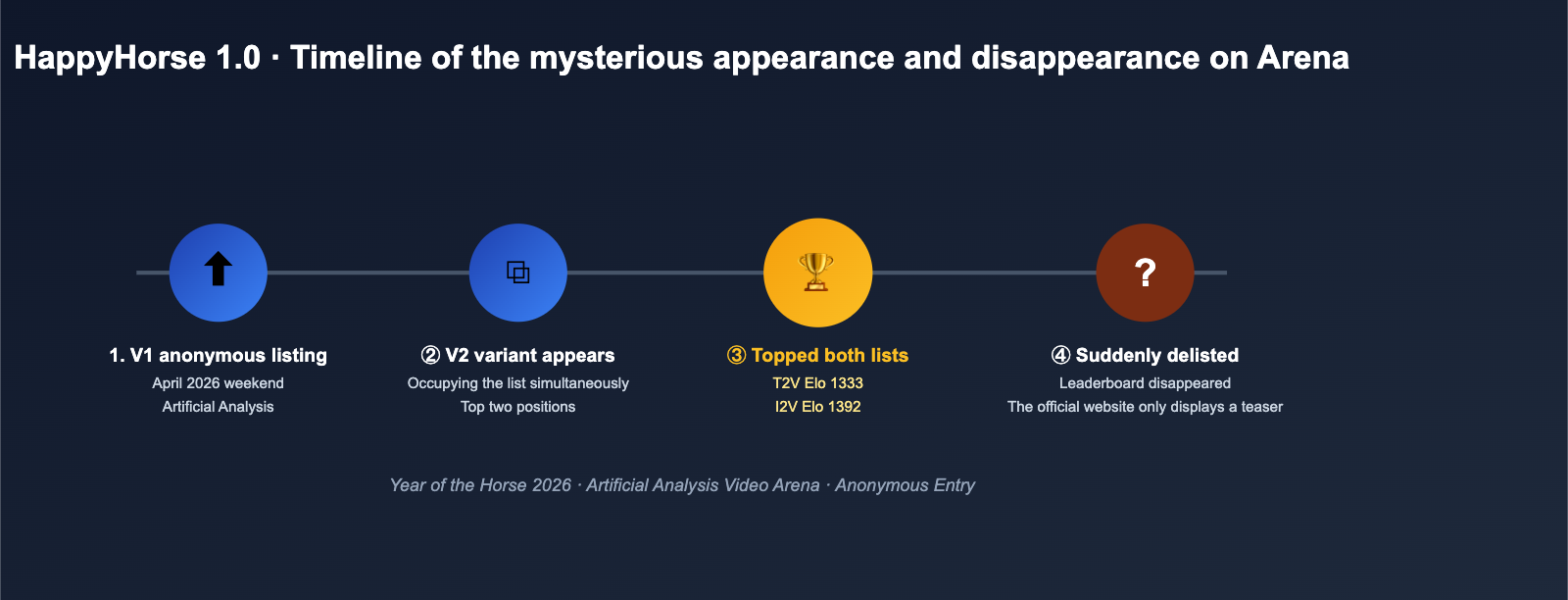
In early April 2026, a mysterious AI video model named HappyHorse quietly appeared on the Artificial Analysis Video Arena blind test leaderboard. Both its V1 and V2 versions simultaneously climbed to the top of the Text-to-Video and Image-to-Video rankings, shattering Elo scores and leaving industry heavyweights like Seedance 2.0, Kling 3.0, and PixVerse V6 in the dust. However, just a few days later, HappyHorse 1.0 suddenly vanished from the leaderboard, leaving behind only a few screenshots and a cryptic official landing page.
Speculation surrounding the HappyHorse model exploded across the English-speaking AI community: Is it a rebrand of Wan 2.7? Is it the next-gen experiment from the ByteDance Seedance team? Or did an undisclosed Asian lab suddenly reveal its hand? Based on publicly verifiable data, this article provides a comprehensive breakdown of the architecture, performance, open-source status, and potential origins of HappyHorse 1.0 to help you decide if this dark horse is worth adding to your video generation stack.

Quick Overview of HappyHorse Model Core Information
Before we dive into the technical weeds, let's condense the known information into a single table to help you get up to speed quickly.
| Dimension | Known Info for HappyHorse 1.0 |
|---|---|
| Model Type | Text/Image-to-Video generation model (joint generation of visuals and audio) |
| Architecture | 40-layer single-stream Self-Attention Transformer, no Cross-Attention |
| Inference Steps | Only 8 denoising steps, no CFG (Classifier-Free Guidance) required |
| Language Support | Chinese, English, Japanese, Korean, German, French |
| Release Assets | Base model / Distilled model / Upscaling model / Inference code (officially claimed to be fully open-source) |
| Appearance | Artificial Analysis Video Arena (some sources also mention the LMArena video track) |
| Current Status | V1/V2 removed from public leaderboards; website still online, but GitHub/Model Hub marked as "Coming Soon" |
| Suspected Origin | Asian team; community guesses link it to the Wan 2.7 / Seedance ecosystem, but not officially confirmed |
🎯 Quick Testing Tip: Since the official weights for the HappyHorse model aren't available on major inference platforms yet, if you want to compare it against top-tier video models (like Seedance 2.0, Kling 3.0, or Veo 3.1) in your production environment, we recommend using a unified API proxy service like APIYI (apiyi.com) to call multiple video models in parallel. This way, you can seamlessly switch over once HappyHorse is officially released, saving you from repetitive engineering work.
The Timeline of the HappyHorse Model's Emergence
To understand why this "Happy Horse" has sent shockwaves through the global AI community, we need to take a clear look at the timeline.
The "Year of the Horse" and Naming Coincidence
2026 happens to be the Year of the Horse in the Chinese zodiac. Since the Lunar New Year in February, international media and columns like UX Tigers have repeatedly mentioned that the Chinese AI scene is focusing on a wave of "Horse"-themed releases. The name "HappyHorse" not only echoes the zodiac but also forms a series of associations with another model appearing around the same time, simply referred to as "The Horse." This was one of the key clues that led the community to immediately identify it as coming from an Asian team.
Explosion and Disappearance on the Arena
According to screenshots and subsequent reports from AI video reviewers like Brent Lynch on X (formerly Twitter) in early April, the emergence of HappyHorse 1.0 followed this general rhythm:
- First Appearance: The V1 version landed on the Artificial Analysis Video Arena as an anonymous entry, surging into the top three in text-to-video blind tests within a few hours.
- V2 Launch: Almost simultaneously, a V2 variant appeared, with both versions occupying the first and second spots on the image-to-video leaderboard at one point.
- Taking the Top Spot: In the non-audio category, HappyHorse 1.0 outperformed top-tier models like Seedance 2.0 720p, Kling 3.0, and PixVerse V6.
- Disappearance: Within a few days, both V1 and V2 were removed from the public leaderboard, leaving only screenshots and third-party records behind. The official page only later added a note stating that the "base model will be open-sourced soon."
This rhythm of "sudden appearance → dominating the leaderboard → quiet removal" usually means one of two things: either a lab is conducting anonymous A/B testing, or the company behind the model is still preparing for an official launch and pulled it back after receiving unexpected traffic exposure. Both explanations have only added to the mystique of the HappyHorse model.
Decoding the HappyHorse Model Architecture: How the 40-Layer Single-Stream Transformer Tops the Charts
Although the official paper hasn't been released yet, we can piece together several key design choices for HappyHorse 1.0 based on descriptions from happyhorse-ai.com and the mirror site happy-horse.net.
Single-Stream Self-Attention Replacing Complex Multi-Stream Structures
Traditional video generation models (especially multimodal models that handle audio, text, and video simultaneously) usually adopt a multi-stream architecture, where text, video, and audio each have their own encoders, interacting through Cross-Attention. This structure is flexible but wastes parameters, requiring tensors to be moved back and forth between branches during inference.
HappyHorse 1.0 simplifies all of this into a single pipeline: a 40-layer Self-Attention Transformer that processes text, video, and audio tokens simultaneously, without any Cross-Attention in between, and without any sub-networks specifically designed for a single modality. All modalities are encoded into a unified token sequence and modeled directly within the same attention space. This design has several theoretical advantages:
- High Parameter Efficiency: No redundant parameters needed for modality isolation.
- Short Inference Path: No extra cross-modal movement, resulting in more continuous kernels.
- Unified Training Objective: Text, video, and audio share the same loss, making end-to-end optimization easier.
- Native Audio-Video Synchronization: Sound and video are tokens within the same sequence, inherently enforcing synchronization.
8-Step Denoising + CFG-Free Extreme Inference
For developers who have used models like Stable Video Diffusion, Sora, or Kling, "dozens of denoising steps + Classifier-Free Guidance (CFG)" is almost muscle memory. The official description for HappyHorse 1.0 is quite aggressive: it only requires 8 denoising steps and uses no CFG to produce the image quality currently ranked first on the Arena.
This usually implies that the model underwent processes like Consistency Distillation, Rectified Flow, or Progressive Distillation during training, compressing multi-step sampling into a few direct prediction steps. Combined with the "distilled model" and "upscaling model" released alongside it, the entire inference stack is well-aligned with the dual goals of "edge-friendly" and "high-throughput server-side" performance.
Potential Parameter Scale and VRAM Requirements
Since the weights haven't been made public, we can't directly verify the parameter count of the HappyHorse model. However, considering the 40-layer, single-stream architecture, support for 6 languages, and its performance on the Arena, it's reasonable to assume its scale is in the same league as public models like Wan 2.x, Seedance 1.x, and Hunyuan Video, likely falling into the 10B–30B parameter range. This means that true local deployment will require at least one professional GPU with high VRAM, and users with standard consumer GPUs will still need to wait for INT8/FP8 quantized versions.
🎯 Architecture Selection Advice: If you are evaluating "next-generation video generation infrastructure" for your team, we recommend keeping a close eye on the "Single-Stream Transformer + Minimal Step Inference" paradigm used by HappyHorse 1.0. Before it is fully open-sourced, you can use models like Seedance, Kling, or Veo on APIYI (apiyi.com) for engineering integration to polish your prompts, shot scripts, and post-production pipelines, then switch over once the HappyHorse weights are ready.
HappyHorse Model Performance: How It Topped the Arena Leaderboards
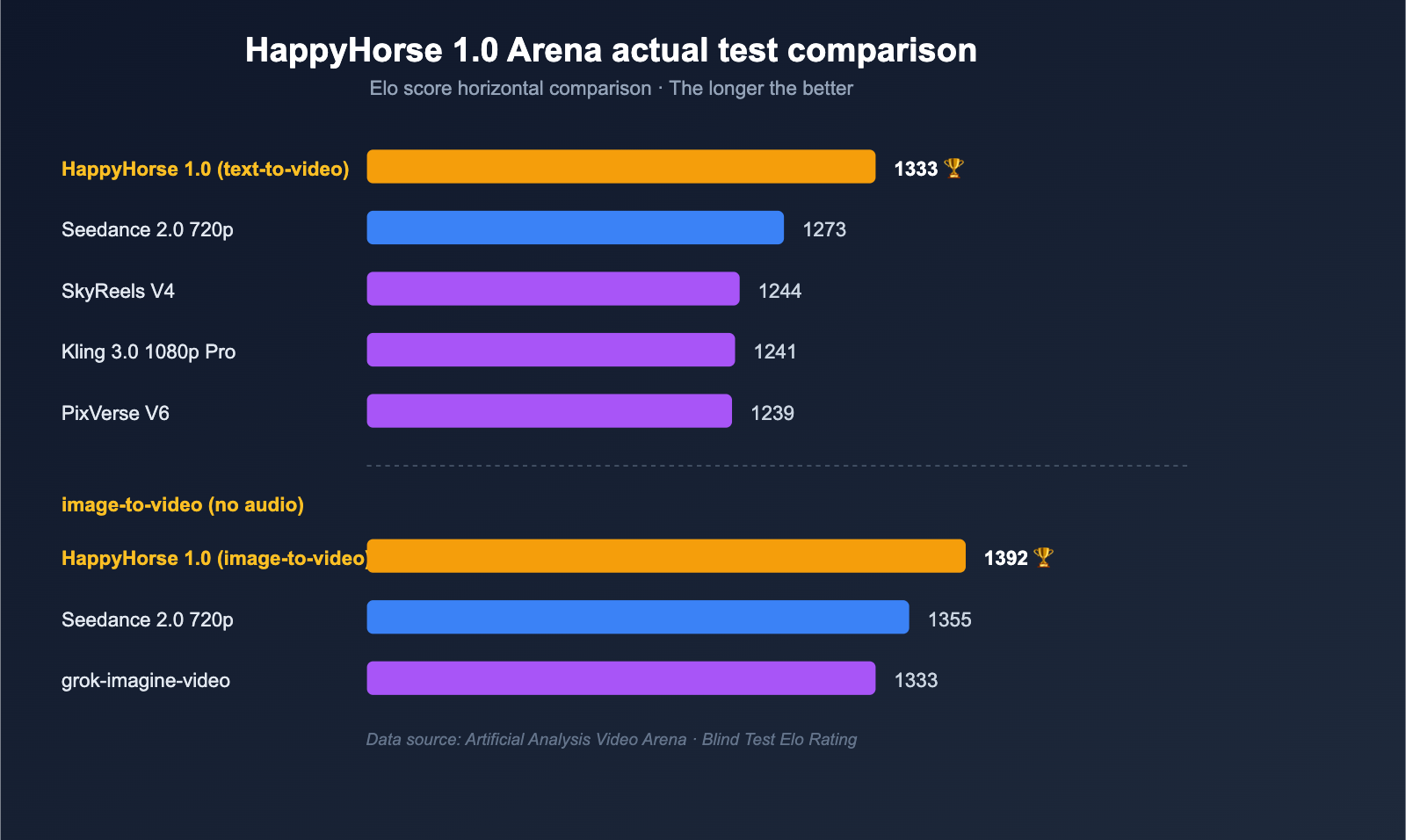
Beyond the architecture, what really convinces frontline teams are the numbers. The table below summarizes the blind-test Elo scores for HappyHorse 1.0 from public third-party records on the Artificial Analysis Video Arena, along with the positions of its main competitors.
Text-to-Video / Image-to-Video Elo Comparison
| Category | Rank | Model | Elo Score |
|---|---|---|---|
| Text-to-Video (No Audio) | 1 | HappyHorse-1.0 | 1333 |
| Text-to-Video (No Audio) | 2 | Dreamina Seedance 2.0 720p | 1273 |
| Text-to-Video (No Audio) | 3 | SkyReels V4 | 1244 |
| Text-to-Video (No Audio) | 4 | Kling 3.0 1080p (Pro) | 1241 |
| Text-to-Video (No Audio) | 5 | PixVerse V6 | 1239 |
| Text-to-Video (With Audio) | 1 | Dreamina Seedance 2.0 720p | 1219 |
| Text-to-Video (With Audio) | 2 | HappyHorse-1.0 | 1205 |
| Image-to-Video (No Audio) | 1 | HappyHorse-1.0 | 1392 |
| Image-to-Video (No Audio) | 2 | Dreamina Seedance 2.0 720p | 1355 |
| Image-to-Video (No Audio) | 3 | PixVerse V6 | 1338 |
| Image-to-Video (No Audio) | 4 | grok-imagine-video | 1333 |
| Image-to-Video (No Audio) | 5 | Kling 3.0 Omni 1080p (Pro) | 1297 |
A few key observations:
- Strongest Lead in Image-to-Video: With a score of 1392 vs. 1355, the Elo gap is nearly 40 points—a level where users can consistently perceive a difference in blind tests.
- Top Spot in Text-to-Video: Leading by 60 points (1333 vs. 1273), the HappyHorse model has surpassed Seedance 2.0 in fundamental capabilities like shot composition and character movement, even without a reference image.
- Second Place in Audio: Seedance 2.0 still leads in audio-visual synchronization, likely due to the engineering polish applied for "AI director" long-form storytelling.
- V2 Variant: While V2 briefly appeared in some screenshots, the official release only mentions 1.0, and it remains unconfirmed whether V2 is the version that later "disappeared."
Multilingual Support and Human-Centric Scenarios
The official documentation explicitly states that HappyHorse 1.0 natively supports 6 languages: Chinese, English, Japanese, Korean, German, and French. It also emphasizes that the model excels in "human-centric" scenarios, including:
- Delicate facial performance;
- Natural speech coordination;
- Realistic body motion;
- Accurate lip sync.
This positioning clearly targets the "virtual human / digital content / short drama" market, rather than just "scenic promotional videos." This explains why it holds such a significant lead in the image-to-video category (animating a character photo)—which is the core requirement for digital humans.
Speculating on the Origins of HappyHorse: WAN 2.7? Seedance? Or a Dark Horse?
As screenshots of HappyHorse 1.0 began circulating in the English-speaking AI community, the hottest topic was "who is behind this?" Based on community clues, we've organized the speculations into the table below.
Comparison of Three Main Theories
| Speculated Origin | Core Argument | Counter-Argument |
|---|---|---|
| Alibaba Wan 2.7 Alias | Released around the same time as Wan 2.7; Alibaba Tongyi Lab is aggressive in video; "Horse" in the name echoes the Year of the Horse | Official Wan 2.7 descriptions focus on image/reasoning, which doesn't align with the single-stream 40-layer architecture emphasized by HappyHorse |
| ByteDance Seedance Team Experimental Version | Seedance 2.0 is a top-tier Chinese contender on the Arena; ByteDance has clear motives for anonymous testing | Seedance 2.0 still leads in the audio category; ByteDance has no reason to upload a "stronger version" under a different name |
| Undisclosed Lab / Academic Consortium | The "full open source + distilled model + super-resolution model" bundle feels more like research; odd naming and minimalist website | The model quality has reached commercial levels; it's difficult for a purely academic team to train a model of this scale independently |
We personally lean toward the third hypothesis: HappyHorse 1.0 is likely from a new team hoping to break out overnight through an open-source strategy, choosing to upload anonymously to the Arena to build credibility with blind-test data before an official launch. This "rank first, open source later, product launch last" playbook has been validated by several Asian labs over the past 18 months.
However, this is just speculation. Until the GitHub repository and Model Hub are officially live, any claims that "it is X" should not be taken as fact. The most pragmatic approach for developers is: focus on its capability curve, not its pedigree.
🎯 Cautionary Advice: Until the HappyHorse model weights are open and the source is officially confirmed, we do not recommend betting your production business on it. You can first use mature platforms like APIYI (apiyi.com) to invoke commercially available video models like Seedance 2.0, Kling 3.0, or Veo 3.1 to complete your projects, while evaluating HappyHorse's open-source progress in parallel.
The Three-Layer Impact of the HappyHorse Model on the Industry
Even if HappyHorse 1.0 ultimately turns out to be nothing more than a well-orchestrated teaser campaign, it has already left three significant marks on the AI video generation landscape.
Layer 1: A Signal for Architectural Paradigms
Over the past two years, mainstream video models have continued to refine the path of multi-stream Diffusion + Cross-Attention. The HappyHorse model proved, by hitting the #1 spot on the Arena, that the "single-stream Self-Attention + minimal inference steps" approach can reach SOTA (State-of-the-Art) levels while being cleaner from an engineering perspective. This will push more teams to reconsider: Is it time to ditch the "complexity tax" of Cross-Attention?
Layer 2: The Evolution of Open Source Strategy
HappyHorse opted for a rhythm of "anonymous leaderboard entry → public promise of open source → release of weights," rather than the traditional "publish paper first → release weights later." This is a strategy closer to consumer product launches, prioritizing "user-perceived data" over academic papers. If it follows through with its open-source promise, HappyHorse 1.0 could become another foundational video model widely adopted for secondary development, joining the ranks of Wan, Hunyuan Video, and Open-Sora.
Layer 3: The Credibility of Blind Test Leaderboards
From another perspective, the "sudden rise and disappearance" of HappyHorse has served as a wake-up call for blind test platforms like Artificial Analysis and LMArena. As anonymous entries become more frequent, distinguishing between a "truly new model" and a "checkpoint of an existing model" will become a major challenge for leaderboard maintainers. For developers, this means that when we read Elo rankings, we need to look beyond the numbers and incorporate "model cards, inference samples, and real-world business data."

How Developers Should Handle "Surprise" Events Like the HappyHorse Model
For frontline engineering teams and content creators, instead of getting caught up in guessing "who they are" or "when they'll open source," it's better to establish a standard operating procedure for these types of surprise events.
Recommended Four-Step Response Process
| Step | Action | Objective |
|---|---|---|
| 1 | Streamline existing video generation workflows with a unified interface | Ensure seamless switching when any new model appears |
| 2 | Collect typical business prompts and reference materials | Build an internal "benchmark set" independent of public Arenas |
| 3 | Run internal benchmarks as soon as a new model is available | Verify if Arena scores hold up with your own data |
| 4 | Evaluate total costs (API pricing / inference latency / compliance) | Decide whether to replace your primary model |
The core of this process is: Don't be held hostage by the release cadence of any single model; instead, make "rapid integration of new models" a core capability. HappyHorse 1.0 is just the beginning; we can expect more anonymous models to appear on various video Arenas throughout the second half of 2026.
🎯 Engineering Tip: For teams looking to track HappyHorse model alongside competitors like Seedance, Kling, and Veo, we recommend using an API proxy service like APIYI (apiyi.com) that supports multi-model parallel invocation. This way, no matter who hits the leaderboard next, your business side only needs to switch a single
modelparameter to complete comparisons and canary releases.
title: HappyHorse Model FAQ
description: Frequently asked questions about the HappyHorse model, covering availability, performance, and integration strategies for developers.
tags: [AI, HappyHorse, Video Generation, APIYI]
HappyHorse Model FAQ
Q1: Is HappyHorse 1.0 available for download yet?
As of early April 2026, the official page for HappyHorse 1.0 still lists its GitHub repository and Model Hub links as "Coming Soon." In other words, the weights and inference code have not been released to the public. Be very cautious of any sources claiming that the model is already available for download or deployment. We recommend keeping an eye on the official website and, in the meantime, using platforms like APIYI (apiyi.com) to access commercially available models like Seedance 2.0 or Kling 3.0 for your projects.
Q2: Why did the HappyHorse model disappear from the Arena leaderboard?
There is no official explanation for its disappearance. Based on community discussions, there are two main theories: first, the authors may have voluntarily withdrawn it to reorganize results before an official release; second, the platform might have temporarily delisted it due to the anonymous nature of the entry. Regardless of the reason, it shouldn't be interpreted as the model "not being good"—the Elo score it achieved before disappearing was based on real, blind-test data.
Q3: Are HappyHorse 1.0 and Wan 2.7 the same model?
There is no official information confirming this. Wan 2.7 is an image/video model officially released by Alibaba's Tongyi Lab in April 2026, focusing on "thinking modes" and long-text rendering. In contrast, the HappyHorse model emphasizes a 40-layer single-stream Transformer and 8-step denoising inference. Their technical descriptions don't align. While some in the community speculate they might share a common origin, they currently appear to be two separate products competing in the same space rather than different versions of the same model.
Q4: Can the HappyHorse model perform joint audio-video generation?
Yes. The official documentation explicitly states that HappyHorse 1.0 processes text, video, and audio tokens within the same 40-layer Transformer, naturally supporting "text-to-video with audio" workflows. It currently ranks second in the audio-enabled category on the Arena, trailing only Seedance 2.0, but it remains firmly in the top tier.
Q5: As a developer, how should I prepare?
The most cost-effective approach is to keep your toolchain neutral. Integrate your video generation workflows into a unified platform like APIYI (apiyi.com) that supports parallel model invocation. This allows you to finalize your prompts, camera scripts, and review processes ahead of time. Once the HappyHorse model is officially open-sourced or available via API, you'll only need to switch the model parameter to integrate this new contender without rewriting your code.
Q6: Which business scenarios is HappyHorse 1.0 best suited for?
Given the official emphasis on "human-centric scenarios, facial performance, lip-syncing, and multilingual support," the HappyHorse model is best suited for: virtual streamers/digital human short videos, AI micro-dramas, cross-lingual promotional videos, and character-focused segments in advertisements. If your business primarily focuses on landscapes or product shots, established options like Seedance 2.0, Veo 3.1, or Kling 3.0 remain more reliable choices.
Summary: What HappyHorse Teaches Us
Putting all the clues together, HappyHorse 1.0 is worth a deep dive not just because of its impressive Elo score on the Artificial Analysis Video Arena, but because it represents a shift in the release paradigm for 2026 video generation models: single-stream Transformers replacing complex multi-stream architectures, low-step inference replacing multi-step denoising, anonymous leaderboard entries replacing paper-first releases, and open-source commitments replacing closed-source APIs. While none of these changes are revolutionary on their own, their convergence signals a new pace for video model iteration.
Our advice to frontline teams is simple: Don't get caught up in the guessing game of "who it is." Instead, treat it as an engineering stress test. Can your video generation pipeline integrate and evaluate a new model the day it drops? If the answer is yes, you'll benefit regardless of whether HappyHorse is truly open-sourced, revealed to be a rebrand from a major player, or fades into silence.
🎯 Final Recommendation: If you want to experience all mainstream AI video models (Seedance 2.0 / Kling 3.0 / Veo 3.1 / PixVerse V6, etc.) immediately while keeping the ability to switch to HappyHorse with one click, we recommend using a unified API proxy service like APIYI (apiyi.com). This avoids the hassle of integrating individual SDKs for every vendor and minimizes migration costs when new models launch.
Author: APIYI Team | Focusing on the deployment and engineering practice of AI Large Language Models. For more video and multimodal model evaluations, please visit APIYI at apiyi.com.