2026 年 4 月初,一個名爲 HappyHorse 的神祕 AI 視頻模型悄無聲息地出現在 Artificial Analysis Video Arena 的盲測榜單上,V1 與 V2 兩個版本幾乎同時刷新了文本到視頻(Text-to-Video)與圖像到視頻(Image-to-Video)雙榜的 Elo 分數,把 Seedance 2.0、Kling 3.0、PixVerse V6 等一線選手全部甩在身後。然而僅僅幾天之後,HappyHorse 1.0 又突然從榜單上消失,只留下少量截圖和一份語焉不詳的官方頁面。
圍繞 HappyHorse 模型 的猜測瞬間在英文 AI 圈炸開:它是 Wan 2.7 的僞裝馬甲?是 ByteDance Seedance 團隊的下一代實驗?還是某家未公開的亞洲實驗室突然亮劍?本文基於公開可驗證的資料,對 HappyHorse 1.0 的架構、性能、開源狀態和潛在出身做一次完整梳理,幫助你判斷這匹黑馬值不值得納入你的視頻生成工具棧。

HappyHorse 模型核心信息一覽
在拆解技術細節之前,我們先用一張表把已知信息濃縮到一屏之內,方便快速建立認知。
| 維度 | HappyHorse 1.0 已知信息 |
|---|---|
| 模型類型 | 文本+圖像到視頻生成模型(聯合生成畫面與音頻) |
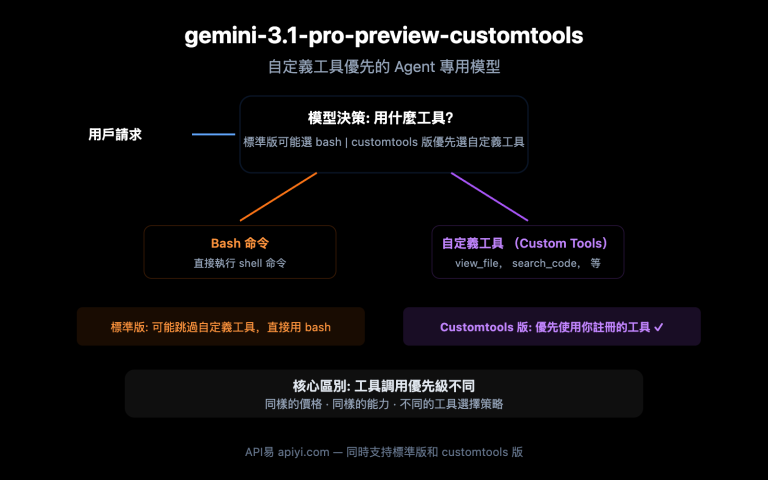
| 架構 | 40 層單流 Self-Attention Transformer,無 Cross-Attention |
| 推理步數 | 僅需 8 步去噪,無需 CFG(Classifier-Free Guidance) |
| 多語言支持 | 中文、英文、日文、韓文、德文、法文 |
| 發佈物 | 基礎模型 / 蒸餾模型 / 超分模型 / 推理代碼(官方聲稱全部開源) |
| 出現位置 | Artificial Analysis Video Arena(部分資料也提到 LMArena 視頻賽道) |
| 當前狀態 | V1/V2 已從公開榜單消失,官網仍在線但 GitHub/Model Hub 標註爲 "Coming Soon" |
| 疑似出身 | 來自亞洲團隊,社區猜測與 Wan 2.7 / Seedance 體系有關,但未被官方確認 |
🎯 快速測試建議:由於 HappyHorse 模型 的官方權重尚未在主流推理平臺開放,如果你想第一時間在生產環境對比同檔位的視頻模型(如 Seedance 2.0、Kling 3.0、Veo 3.1),我們建議先通過 API易 apiyi.com 這樣的統一中轉平臺並行調用多家視頻模型,等待 HappyHorse 正式發佈後再無縫切換,避免重複改造工程。
HappyHorse 模型橫空出世的時間線
爲了理解這匹"快樂的馬"爲什麼能讓海外 AI 圈集體震動,我們需要把時間線拉直看一遍。
Year of the Horse 與命名巧合
2026 年正好是中國農曆的馬年(Year of the Horse),從 2 月春節開始,海外媒體、UX Tigers 等專欄就反覆提到中國 AI 圈正在圍繞"馬"做一波集中發佈。"HappyHorse"這一命名既呼應了生肖,又與同期出現的另一款被簡稱爲 "The Horse" 的模型形成系列聯想,這是社區第一時間認定它來自亞洲團隊的核心線索之一。
Arena 上的爆發與消失
根據 X(原 Twitter)上 Brent Lynch 等 AI 視頻測評人在 4 月初發布的截圖與後續報道,HappyHorse 1.0 的出現節奏大致如下:
- 首次出現:V1 版本以匿名條目形式登陸 Artificial Analysis Video Arena,幾個小時內在文本到視頻盲測中衝上前三;
- V2 版本上線:幾乎同時出現 V2 變體,兩個版本一度同時佔據圖像到視頻榜單的第一與第二;
- 登頂:在不開啓音頻的賽道,HappyHorse 1.0 把 Seedance 2.0 720p、Kling 3.0、PixVerse V6 等一線模型全部壓在身後;
- 消失:幾天之內,V1/V2 同時從公開榜單移除,只留下截圖與第三方記錄,官方頁面隨後才上線"基礎模型即將開源"的說明。
這種"突然上榜→霸榜→悄然下架"的節奏,在過去通常意味着兩件事:要麼是某家實驗室在做匿名 A/B 測試,要麼是模型背後的廠商還在準備正式發佈,提前被流量曝光後主動撤下。兩種解釋都讓 HappyHorse 模型 的神祕感再上一個臺階。

HappyHorse 模型架構解析:40 層單流 Transformer 是怎麼打榜的
雖然官方尚未公開論文,但通過 happyhorse-ai.com 與鏡像站 happy-horse.net 的描述,可以拼出 HappyHorse 1.0 在架構層面的幾個關鍵設計選擇。
單流 Self-Attention 替代多流複雜結構
傳統的視頻生成模型(尤其是同時處理音頻、文本、畫面的多模態模型)通常採用多流(multi-stream)架構,文本、視頻、音頻各自有自己的 Encoder,再通過 Cross-Attention 互相交互。這種結構靈活但參數浪費嚴重,推理時需要在多個分支之間來回搬運張量。
HappyHorse 1.0 把這一切簡化成一條流水線:一顆 40 層 Self-Attention Transformer 同時處理文本、視頻與音頻 Token,中間沒有任何 Cross-Attention,也沒有爲某個模態專門設計的子網絡。所有模態被統一編碼成 Token 序列,直接在同一個注意力空間裏相互建模。這種設計在理論上有幾個好處:
- 參數利用率高:不再需要爲模態隔離而準備的冗餘參數;
- 推理路徑短:沒有跨模態的額外搬運,Kernel 更連續;
- 訓練目標統一:文本、畫面、音頻共享同一套損失,容易做端到端優化;
- 天然支持音視頻聯合:聲音和畫面是同一個序列裏的 Token,自帶同步約束。
8 步去噪 + 無 CFG 的極致推理
對於使用過 Stable Video Diffusion、Sora、Kling 等模型的開發者而言,"幾十步去噪 + Classifier-Free Guidance"幾乎是肌肉記憶。HappyHorse 1.0 的官方描述則寫得相當激進:僅需 8 步去噪,且不使用 CFG,就能產出當前 Arena 排名第一的畫質。
這背後通常意味着模型在訓練階段做了類似 Consistency Distillation / Rectified Flow / Progressive Distillation 的工作,把多步採樣壓縮成幾步直接預測。配合官方同時放出的"蒸餾模型"和"超分模型",整套推理棧非常貼近"端側友好 + 服務端高吞吐"的雙重目標。
可能的參數規模與顯存需求
由於權重尚未公開,無法直接驗證 HappyHorse 模型 的參數量。但結合 40 層、單流、支持 6 種語言的描述,以及它在 Arena 上的表現,合理推測它的體量與 Wan 2.x、Seedance 1.x、Hunyuan Video 等公開模型屬於同一量級,大概率落在 10B~30B 參數區間。這意味着真正本地部署需要至少一張高顯存的專業卡,普通消費級 GPU 仍要等待 INT8/FP8 量化版本。
🎯 架構選型建議:如果你正在爲團隊評估"下一代視頻生成基礎設施",我們建議把 HappyHorse 1.0 這種"單流 Transformer + 極少步推理"的範式作爲重點觀察對象;在它完全開源之前,可以先用 API易 apiyi.com 上的 Seedance、Kling、Veo 等模型做工程聯調,把 Prompt、鏡頭腳本、後期流水線打磨到位,等 HappyHorse 權重就緒後再切換。
HappyHorse 模型實測數據:Arena 雙榜怎麼打下來的
把架構講完,真正能說服一線團隊的還是數字。下面這張表彙總了第三方公開記錄中 HappyHorse 1.0 在 Artificial Analysis Video Arena 上的盲測 Elo 分數,以及主要競爭對手的位置。
文本到視頻 / 圖像到視頻 Elo 對比
| 賽道 | 排名 | 模型 | Elo 分數 |
|---|---|---|---|
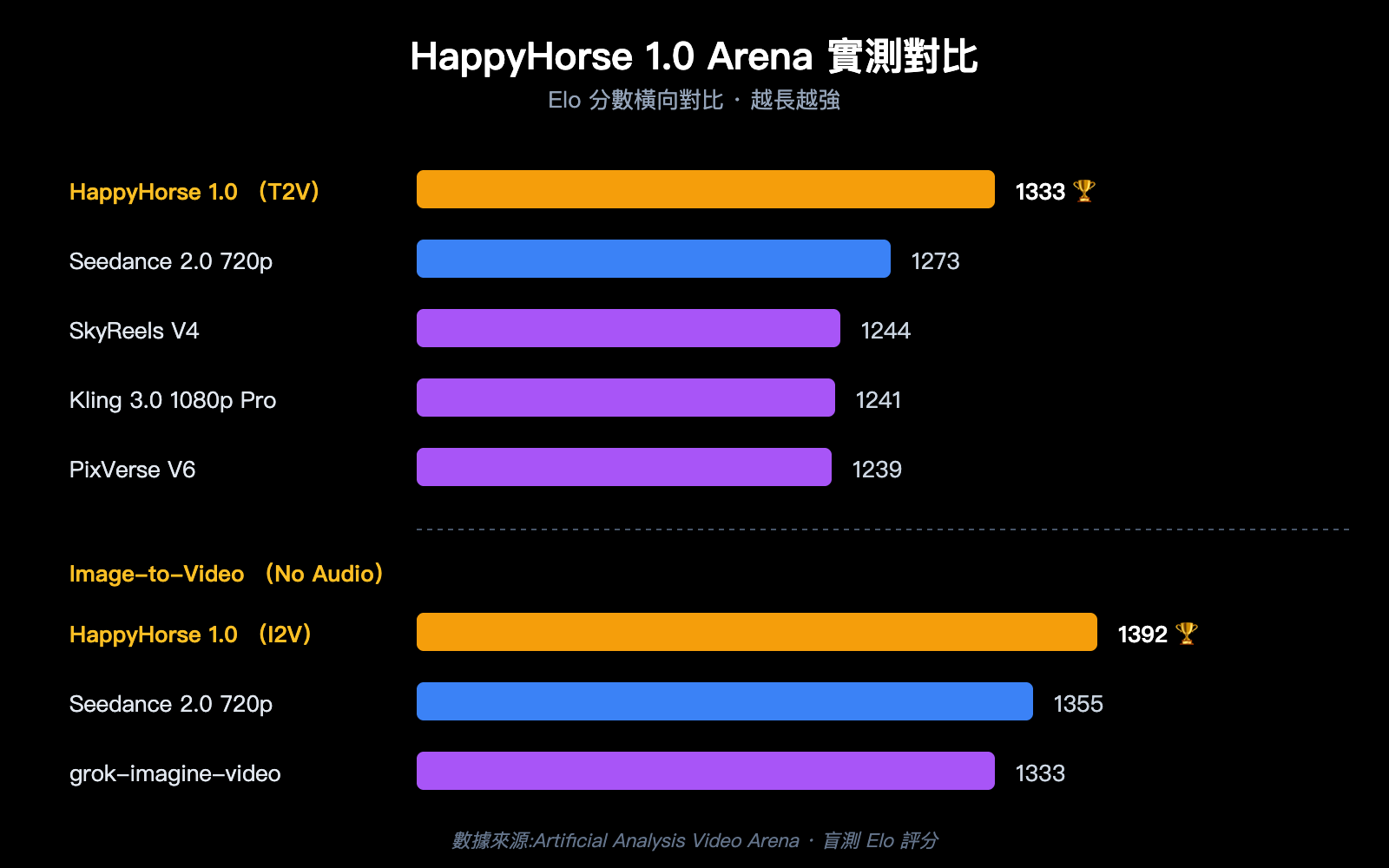
| 文本到視頻(無音頻) | 1 | HappyHorse-1.0 | 1333 |
| 文本到視頻(無音頻) | 2 | Dreamina Seedance 2.0 720p | 1273 |
| 文本到視頻(無音頻) | 3 | SkyReels V4 | 1244 |
| 文本到視頻(無音頻) | 4 | Kling 3.0 1080p (Pro) | 1241 |
| 文本到視頻(無音頻) | 5 | PixVerse V6 | 1239 |
| 文本到視頻(含音頻) | 1 | Dreamina Seedance 2.0 720p | 1219 |
| 文本到視頻(含音頻) | 2 | HappyHorse-1.0 | 1205 |
| 圖像到視頻(無音頻) | 1 | HappyHorse-1.0 | 1392 |
| 圖像到視頻(無音頻) | 2 | Dreamina Seedance 2.0 720p | 1355 |
| 圖像到視頻(無音頻) | 3 | PixVerse V6 | 1338 |
| 圖像到視頻(無音頻) | 4 | grok-imagine-video | 1333 |
| 圖像到視頻(無音頻) | 5 | Kling 3.0 Omni 1080p (Pro) | 1297 |
幾個關鍵觀察:
- 圖像到視頻賽道領先優勢最大:1392 vs 1355,Elo 差距接近 40 分,在盲測體系裏屬於"用戶能穩定感覺到差異"的級別;
- 純文本到視頻也是第一:1333 vs 1273,領先 60 分,意味着即使沒有參考圖,HappyHorse 模型 在鏡頭構圖、人物動作等基礎能力上已經超過 Seedance 2.0;
- 音頻賽道暫時第二:Seedance 2.0 在音畫同步上仍然領先,這與它針對"AI 導演"長敘事所做的工程化打磨有關;
- V2 變體:V2 在部分截圖中也出現過短暫領跑,但官方目前只對外釋出 1.0 的描述,V2 是否就是後來"消失"的版本仍未確認。
多語言支持與人本場景
官方明確寫出 HappyHorse 1.0 原生支持 6 種語言:中文、英文、日文、韓文、德文、法文,並且強調模型在"人本(human-centric)"場景下表現尤爲突出,包括:
- 細膩的面部表演(facial performance);
- 自然的語音協調(speech coordination);
- 真實的肢體動作(body motion);
- 準確的口型同步(lip sync)。
這套描述非常明顯地把 HappyHorse 模型 定位在"虛擬人 / 數字內容 / 短劇"賽道,而不僅僅是"風景宣傳片"。這也解釋了爲什麼它在圖像到視頻(給一張人物照片做動起來)的賽道上領先優勢最大——這是數字人的核心需求。
HappyHorse 模型出身猜想:WAN 2.7?Seedance?還是黑馬新軍?
當 HappyHorse 1.0 的截圖開始在英文 AI 圈傳播,最熱鬧的討論就是"它到底是誰家的"。綜合社區線索,我們可以把猜測整理成下面這張表。
三種主流猜測對比
| 猜測出處 | 核心論據 | 反駁論據 |
|---|---|---|
| Alibaba Wan 2.7 馬甲 | Wan 2.7 同期發佈,Alibaba Tongyi Lab 在視頻賽道一貫激進;命名帶"Horse"呼應馬年 | Wan 2.7 的官方描述更偏圖像 / 思考模式,與 HappyHorse 強調的單流 40 層架構對不上 |
| ByteDance Seedance 團隊實驗版 | Seedance 2.0 是當前盤踞 Arena 前列的中國選手,字節有充足匿名測試動機 | Seedance 2.0 官方在音頻賽道仍領先 HappyHorse,字節沒有理由把"更強的版本"換名上傳 |
| 未公開實驗室 / 學術聯合體 | "全部開源 + 蒸餾模型 + 超分模型"打包發佈更像研究風格;命名古怪、官網極簡 | 模型質量已經達到一線商用水平,純學術團隊很難獨立訓練出如此規模 |
我們個人傾向於第三種假設的概率正在上升:HappyHorse 1.0 更可能來自一支希望通過開源策略一夜出圈的新團隊,選擇匿名上 Arena 是爲了先用盲測數據建立信譽,再正式發佈。 這種"先打榜、再開源、後發產品"的玩法,在過去 18 個月裏已經被多家亞洲實驗室驗證有效。
不過這只是猜測。在 GitHub 倉庫與 Model Hub 正式上線之前,任何"它就是 X"的說法都不應被當成事實。對開發者更務實的態度是:先關注它的能力曲線,而不是它的姓氏。
🎯 謹慎建議:在 HappyHorse 模型 權重尚未對外開放、來源未被官方確認之前,不建議把生產業務直接押注在它身上。可以先通過 API易 apiyi.com 等成熟平臺調用 Seedance 2.0、Kling 3.0、Veo 3.1 等已商用化的視頻模型完成項目交付,再在內部並行評估 HappyHorse 的開源進度。
HappyHorse 模型對行業的三層影響
即使 HappyHorse 1.0 最終被證明只是一次精心策劃的預熱活動,它已經對整個 AI 視頻生成賽道留下了三個值得記錄的影響。
第一層:架構範式的信號
過去兩年,主流視頻模型仍然在多流 Diffusion + Cross-Attention 的路徑上做精細化打磨。HappyHorse 模型 用 Arena 第一名直接證明了"單流 Self-Attention + 極少步推理"這條路同樣可以走到 SOTA,而且工程上更乾淨。這會促使更多團隊重新審視:是不是該把 Cross-Attention 這層"複雜性稅"省下來?
第二層:開源策略的演變
HappyHorse 選擇"匿名上榜 → 公開宣告將開源 → 發佈權重"的節奏,而不是傳統的"先發論文 → 再發權重"。這是一種更接近消費級產品發佈的玩法,把"用戶感知數據"放在論文之前。如果它最終如約開源,HappyHorse 1.0 可能成爲繼 Wan、Hunyuan Video、Open-Sora 之後又一個被大量二次開發的視頻基礎模型。
第三層:盲測榜單的可信度
從另一個角度看,HappyHorse 的"瞬間登頂又消失"也給 Artificial Analysis、LMArena 這些盲測平臺敲了一記警鐘。匿名條目越來越多,如何區分"真新模型"與"已有模型的某個 Checkpoint"將成爲榜單維護方必須面對的難題。 對開發者而言,這意味着我們在閱讀 Elo 排行時,需要更多結合"模型卡 + 推理示例 + 真實業務數據",而不是隻看一個數字。

開發者如何應對 HappyHorse 模型這類"突襲"事件
對於一線工程團隊和內容創作者,與其陷入"它是誰、它什麼時候開源"的猜測,不如建立一套面對此類突襲事件的標準應對動作。
推薦的四步應對流程
| 步驟 | 動作 | 目的 |
|---|---|---|
| 1 | 用統一接口先把現有視頻生成業務跑順 | 確保任何新模型出現時都能無縫切換 |
| 2 | 收集典型業務 Prompt 與參考素材 | 形成內部"基準測試集",獨立於公開 Arena |
| 3 | 在新模型可用的第一時間跑內部基準 | 用自己的數據驗證 Arena 分數是否能復現 |
| 4 | 評估總成本(API 價格 / 推理延遲 / 合規) | 決定是否替換主力模型 |
這個流程的核心是:不要被任何單一模型的發佈節奏綁架,而是把"快速接入新模型"本身做成一種基礎能力。HappyHorse 1.0 這次只是開了個頭,可以預見 2026 年下半年還會有更多類似的匿名模型出現在各類視頻 Arena 上。
🎯 工程化建議:對於希望長期跟進 HappyHorse 模型 與 Seedance、Kling、Veo 等競品的團隊,我們建議把視頻生成統一接入 API易 apiyi.com 這樣支持多模型並行調用的中轉平臺;這樣無論後續上榜的是誰,業務側只需切換一個 model 參數,就能完成對比與灰度發佈。
HappyHorse 模型常見問題 FAQ
Q1:HappyHorse 1.0 已經可以下載使用了嗎?
目前(2026 年 4 月初)HappyHorse 1.0 的官方頁面仍然把 GitHub 倉庫與 Model Hub 鏈接標註爲 "Coming Soon"。也就是說,權重和推理代碼尚未對外公開,任何宣稱"已經能下載部署"的渠道都需要非常謹慎。建議持續關注官方網站,在權重正式釋出前,先在 API易 apiyi.com 等平臺調用 Seedance 2.0、Kling 3.0 等已商用化的模型完成項目。
Q2:HappyHorse 模型爲什麼會從 Arena 榜單上消失?
公開資料裏並沒有對消失原因給出確切解釋。結合社區討論,主流解釋有兩種:其一,模型作者主動撤回,準備重新整理結果後正式發佈;其二,平臺方因匿名條目身份未明而暫時下架。無論哪種,都不能簡單解讀爲"模型不行"——它在消失前的 Elo 分數是真實存在的盲測數據。
Q3:HappyHorse 1.0 和 Wan 2.7 是同一個模型嗎?
沒有任何官方信息確認這一點。Wan 2.7 是阿里通義實驗室在 2026 年 4 月正式發佈的圖像/視頻模型,主打"思考模式"和長文本渲染;而 HappyHorse 模型 強調的是 40 層單流 Transformer 和 8 步去噪推理,兩者的技術敘述並不一致。社區有人猜測兩者同源,但目前更像是"同期同賽道的兩個產品",而非同一個模型的不同包裝。
Q4:HappyHorse 模型能做音視頻聯合生成嗎?
可以。官方明確指出 HappyHorse 1.0 在同一顆 40 層 Transformer 內聯合處理文本、視頻和音頻 Token,因此天然支持"輸入文本 → 輸出有聲短片"。在 Arena 含音頻賽道上它目前排名第二,落後於 Seedance 2.0,但仍屬於第一梯隊。
Q5:作爲開發者,我現在應該怎麼準備?
最划算的做法是保持工具鏈中立:把視頻生成業務接入像 API易 apiyi.com 這樣支持多模型並行調用的統一平臺,提前把 Prompt、鏡頭腳本、審覈流程跑通;一旦 HappyHorse 模型 正式開源或上線 API,你只需要切換 model 參數,就能在不重寫代碼的前提下接入這匹新黑馬。
Q6:HappyHorse 1.0 適合哪些業務場景?
從官方對"人本場景、面部表演、口型同步、多語言"的強調來看,HappyHorse 模型 最合適的方向包括:虛擬主播 / 數字人短視頻、AI 短劇、跨語種宣傳片、廣告中的人物片段。如果你的業務以風景、產品鏡頭爲主,Seedance 2.0、Veo 3.1、Kling 3.0 等仍然是更穩妥的現成選擇。
總結:HappyHorse 模型留給我們的啓示
把所有線索拼在一起,HappyHorse 1.0 之所以值得寫一篇完整的解析,不只是因爲它在 Artificial Analysis Video Arena 上的 Elo 分數足夠漂亮,更是因爲它代表了 2026 年視頻生成模型發佈範式的一次集中體現:單流 Transformer 替代多流複雜結構、極少步推理替代幾十步去噪、匿名上榜替代論文先行、開源承諾替代閉源 API。這四個變化任何一個單獨出現都不算顛覆,但疊加在一起,就意味着我們正在迎來一波新的視頻模型迭代節奏。
對一線團隊的建議是簡單而直接的:不要陷在"它是誰"的猜謎裏,而是把它當成一次工程化壓力測試——你的視頻生成流水線,能不能在新模型出現的當天就完成接入和評估?如果答案是肯定的,那麼無論 HappyHorse 模型 接下來是真正開源、被證實是某家廠商的馬甲,還是悄無聲息地永遠沉默,你都能從中獲益。
🎯 最終建議:想要第一時間體驗 HappyHorse 1.0 之外的所有主流 AI 視頻模型(Seedance 2.0 / Kling 3.0 / Veo 3.1 / PixVerse V6 等),並保留未來一鍵切換到 HappyHorse 的能力,我們建議通過 API易 apiyi.com 這樣的統一中轉平臺進行接入,既能避免重複對接每一家廠商的 SDK,也能在新模型上線時把遷移成本降到最低。
作者:APIYI Team | 關注 AI 大模型落地與工程實踐,更多視頻與多模態模型評測請訪問 API易 apiyi.com。