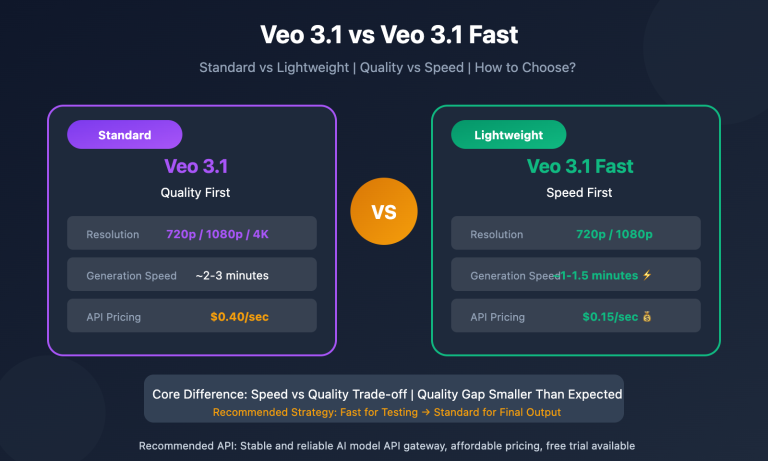
Following the launch of Gemini 3.5 Flash on May 19, 2026, the developer community isn't asking "does it work?" but rather "can it directly replace the Gemini 3.1 Pro Preview models we've been running since late last year?" Google has repeatedly emphasized that 3.5 Flash "outperforms 3.1 Pro" in coding, tool calling, and Agent tasks. With pricing at $1.50 / $9 compared to Pro's $2 / $12—a 25% discount—it certainly sounds like you're getting more for less. However, BenchLM's aggregate leaderboard shows 3.1 Pro with a score of 92, five points higher than 3.5 Flash's 87. Which side should you trust? This article provides a comprehensive 8-dimension comparison, drawing on primary English-language sources including Google, LLM-Stats, Artificial Analysis, Engadget, and DataCamp.
To start with the conclusion: for teams running Agent workflows, coding Copilots, or processing long documents, Gemini 3.5 Flash is a "more for less" upgrade—offering lower costs and stronger Agent intelligence. However, for teams focused on academic reasoning, abstract logic, or ultra-long 200K+ context windows, Gemini 3.1 Pro Preview still holds an irreplaceable high-performance niche. We recommend running both models through APIYI (apiyi.com) using their free credits on your actual business use cases before deciding how to route your production traffic.
Quick Overview: Gemini 3.5 Flash vs. Gemini 3.1 Pro Preview
Both models belong to the Gemini 3.x family, but they serve completely different purposes. Gemini 3.5 Flash is Google's "Agentic Flash" model, which reached GA (General Availability) on May 19, 2026. It was released as a stable production version with the model ID gemini-3.5-flash (no preview suffix). Gemini 3.1 Pro Preview, on the other hand, is the flagship reasoning model launched in late 2025 as a preview. Its model ID is gemini-3.1-pro-preview, and it remains in preview status, meaning its SLA isn't as stable as a GA release.
The table below summarizes the core specifications of both models, with all data sourced from Google AI for Developers and LLM-Stats.
| Comparison Dimension | Gemini 3.5 Flash | Gemini 3.1 Pro Preview | Winner |
|---|---|---|---|
| Release Status | GA (General Availability) | Preview | 3.5 Flash |
| Model ID | gemini-3.5-flash |
gemini-3.1-pro-preview |
— |
| Context Window | 1,048,576 input / 65,536 output | 1,048,576 input / 65,536 output | Tie |
| Input Modalities | Text + Image + Audio + Video | Text + Image + Audio + Video + Code | 3.1 Pro |
| Knowledge Cutoff | January 2026 | Late 2025 | 3.5 Flash |
| Dynamic Thinking | Enabled by default, no config needed | Manual thinking budget config required | 3.5 Flash |
| Tool Capability | function calling / Search-as-Tool / Code Exec | function calling / Search-as-Tool / Code Exec | Tie |
| Output Speed | ~289 tokens/s (4x faster than peers) | Slower, typically 60-90 tokens/s | 3.5 Flash |
| APIYI Access | Available, $0.05 credit for new users | Available, $0.05 credit for new users | Tie |
🎯 Integration Tip: Both Gemini 3.5 Flash and Gemini 3.1 Pro Preview are available on the APIYI (apiyi.com) platform. You can switch between these models at zero cost using the OpenAI-compatible interface; simply swap the
modelfield betweengemini-3.5-flashandgemini-3.1-pro-previewwithout needing to rewrite your authentication or routing logic.
The Truth Behind "More Value, Same Price": A Practical Cost Analysis
Let's get to the core question of this article: Is Gemini 3.5 Flash truly "more value for the same price"? To answer this, we need to look at the official pricing, cache hit rates, tiered pricing for extra-long context windows, and overall intelligence scores all in one place.
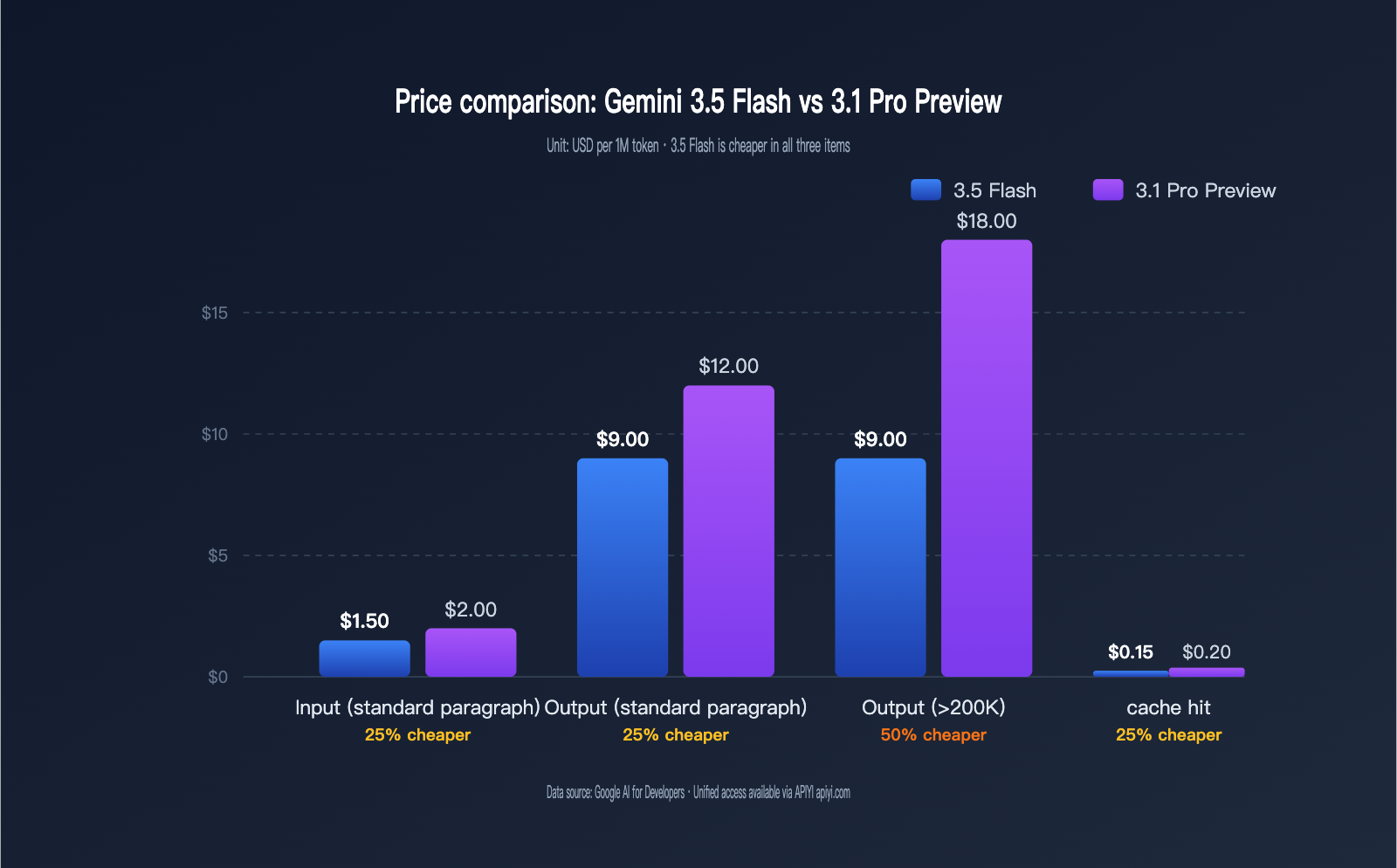
The table below provides a complete pricing structure comparison for both models. All prices are in USD per 1 million tokens.
| Price Item | Gemini 3.5 Flash | Gemini 3.1 Pro Preview | Difference |
|---|---|---|---|
| Standard Input (<200K) | $1.50 | $2.00 | 25% cheaper |
| Standard Output (<200K) | $9.00 | $12.00 | 25% cheaper |
| Long Input (>200K) | $1.50 (no tiers) | $4.00 | 62.5% cheaper |
| Long Output (>200K) | $9.00 (no tiers) | $18.00 | 50% cheaper |
| Cache Hit Input | $0.15 | $0.20 | 25% cheaper |
| Cache Write | Free (implicit) | $0.38 | Significantly cheaper |
This comparison highlights three key facts. First, within the standard context range (<200K tokens), 3.5 Flash is 25% cheaper overall than 3.1 Pro Preview, effectively giving you a permanent 25% discount. Second, the extra-long context range is where the real savings happen; 3.1 Pro Preview triggers tiered price hikes once you exceed 200K tokens (input doubles to $4/1M, output jumps to $18/1M), while 3.5 Flash remains flat, leading to actual cost differences of 50–62.5% for long-document RAG and million-token context Agents. Third, the $0.15 cache hit input price is 25% cheaper than 3.1 Pro's $0.20, and when combined with free cache writes, it can push the actual cost of scenarios like "long system prompt + multi-turn conversation" down to one-third of 3.1 Pro's cost.
💡 Cost Estimation Tip: If your workload's average context is under 200K, choosing 3.5 Flash saves you 25% immediately. If your context frequently exceeds 200K (e.g., code repository scanning, long paper analysis, enterprise knowledge base RAG), the budget saved by 3.5 Flash compared to 3.1 Pro might be enough to support double the call volume. We recommend running your real traffic on APIYI (apiyi.com) for a week before making a final model routing decision.
Gemini 3.5 Flash vs. 3.1 Pro Benchmark Comparison: Where Flash Actually Takes the Lead
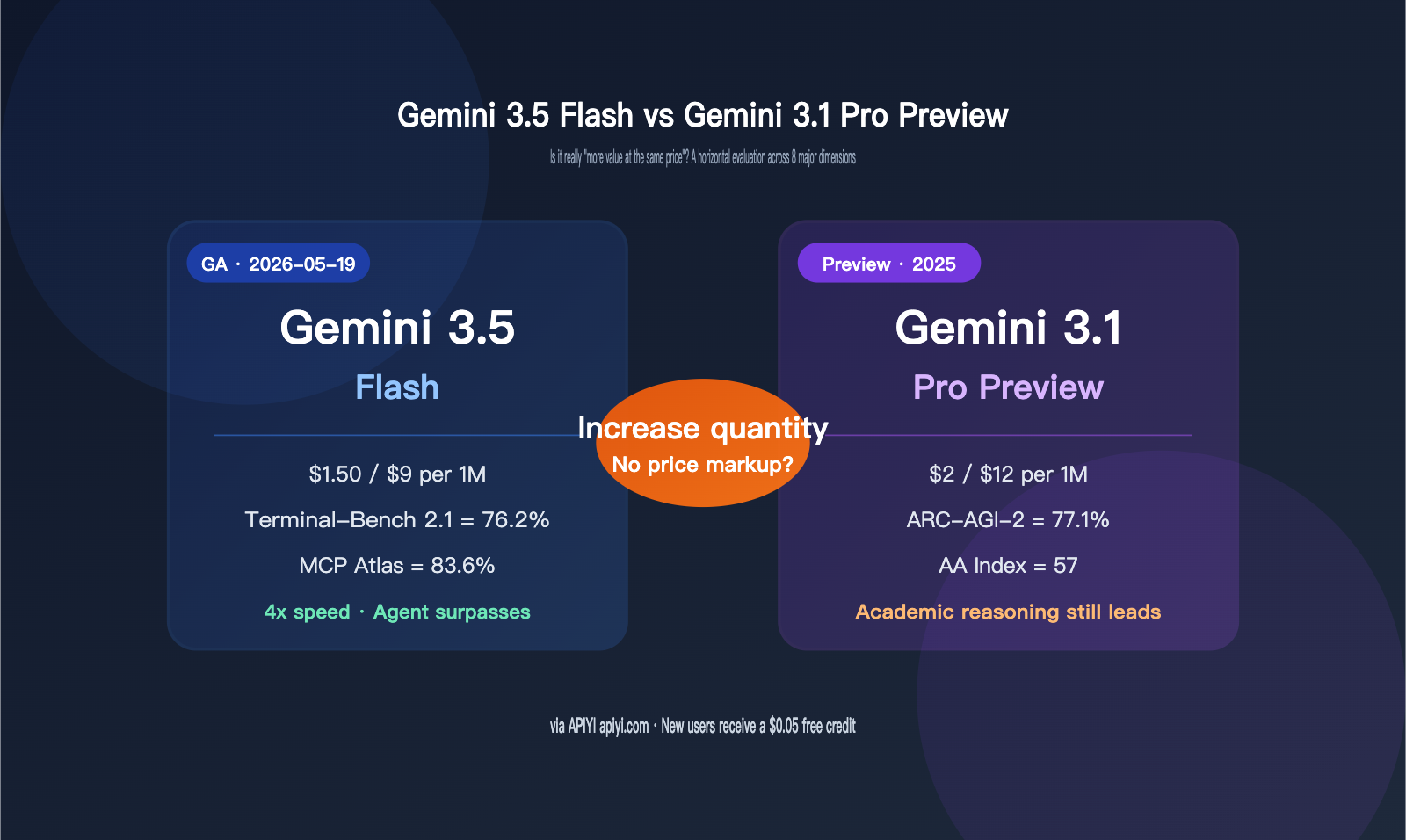
Lower prices don't mean much if the performance doesn't keep up. Data from Google and LLM-Stats shows that Gemini 3.5 Flash indeed outperforms Gemini 3.1 Pro in Agents, tool invocation, and coding tasks, though it still lags behind in pure academic and abstract reasoning. The table below summarizes the results of 8 representative benchmarks.
| Benchmark | Gemini 3.5 Flash | Gemini 3.1 Pro Preview | Winner | Primary Capability |
|---|---|---|---|---|
| Terminal-Bench 2.1 | 76.2% | 70.3% | 3.5 Flash | Terminal Coding Agent |
| MCP Atlas | 83.6% | 78.2% | 3.5 Flash | MCP Tool Invocation |
| Finance Agent v2 | 57.9% | 43.0% | 3.5 Flash | Financial Doc Agent |
| GDPval-AA (Elo) | 1656 | 1314 | 3.5 Flash | General Agent |
| CharXiv Reasoning | 84.2% | Lower | 3.5 Flash | Chart Reasoning |
| Humanity's Last Exam | 40.2% | 44.4% | 3.1 Pro | Pure Academic Reasoning |
| ARC-AGI-2 | 72.1% | 77.1% | 3.1 Pro | Abstract Pattern Reasoning |
| AA Intelligence Index | 55 | 57 | 3.1 Pro (+2) | Comprehensive Intelligence |
The right way to read this table is to look at it in two groups. The first group covers Agent and tool tasks, where Gemini 3.5 Flash dominates: a +14.9 point lead in Finance Agent v2 and a 342 Elo lead in GDPval-AA indicate a generational leap in multi-step tool orchestration, error recovery, and structured document processing. The second group covers pure cognitive tasks, where Gemini 3.1 Pro Preview still holds the high ground: it leads by 5 points in ARC-AGI-2, 4.2 points in Humanity's Last Exam, and 2 points in the Artificial Analysis comprehensive intelligence index.
It's worth mentioning the BenchLM leaderboard data. In their comparison, Gemini 3.1 Pro scored 92 vs. Gemini 3.5 Flash's 87. That 5-point gap mainly comes from Pro's advantage in reasoning (77.1 vs 74.7) and knowledge, which is partially offset by Flash's lead in agentic and coding tasks. In short: The closer you are to an Agent workflow, the more Flash excels; the closer you are to static Q&A, the more Pro excels. This difference determines your selection strategy, and you can use the unified interface at APIYI (apiyi.com) to verify the real performance gap for your specific tasks at a low cost.
Scenario Recommendations: When to Choose 3.5 Flash vs. 3.1 Pro
Instead of just listing an 8-dimensional comparison, I’ve distilled the data into actionable selection advice. This table isn't meant to be the "final word," but rather a guide to help you determine the optimal solution for your specific business use cases.
| Scenario | Recommended Model | Key Reason |
|---|---|---|
| Code Copilot / IDE Assistant | Gemini 3.5 Flash | 5.9 points higher on Terminal-Bench 2.1, 4x faster |
| Agent Multi-step Tool Use | Gemini 3.5 Flash | Significant lead in MCP Atlas / GDPval-AA |
| Long-document RAG (50K-1M tokens) | Gemini 3.5 Flash | Cheaper standard rates, free cache writes |
| Finance/Legal/Accounting Docs | Gemini 3.5 Flash | 14.9 points higher on Finance Agent v2 |
| Math Competitions & AIME Reasoning | Gemini 3.1 Pro Preview | Leads in academic reasoning |
| ARC-AGI Abstract Reasoning | Gemini 3.1 Pro Preview | 5 points higher |
| Single-pass Analysis of Long Papers/Books | Gemini 3.1 Pro Preview | Still holds an edge in dense long-context reasoning |
| General Chatbots | Gemini 3.5 Flash | Better price + speed |
| Enterprise Automation Workflows | Gemini 3.5 Flash | Proven in Shopify/Salesforce/Databricks |
| "General Tool Layer" for Model Routing | Gemini 3.5 Flash | Best overall cost-performance ratio |
In practice, the ideal strategy isn't "either-or," but rather "task-based routing." I recommend setting Gemini 3.5 Flash as your default for Agents and coding tasks, while keeping Gemini 3.1 Pro Preview as a fallback for complex reasoning. You can switch models seamlessly using the unified API from APIYI (apiyi.com) under a single authentication key. This way, you capture the cost benefits of 3.5 Flash while maintaining a high performance ceiling for tougher challenges.
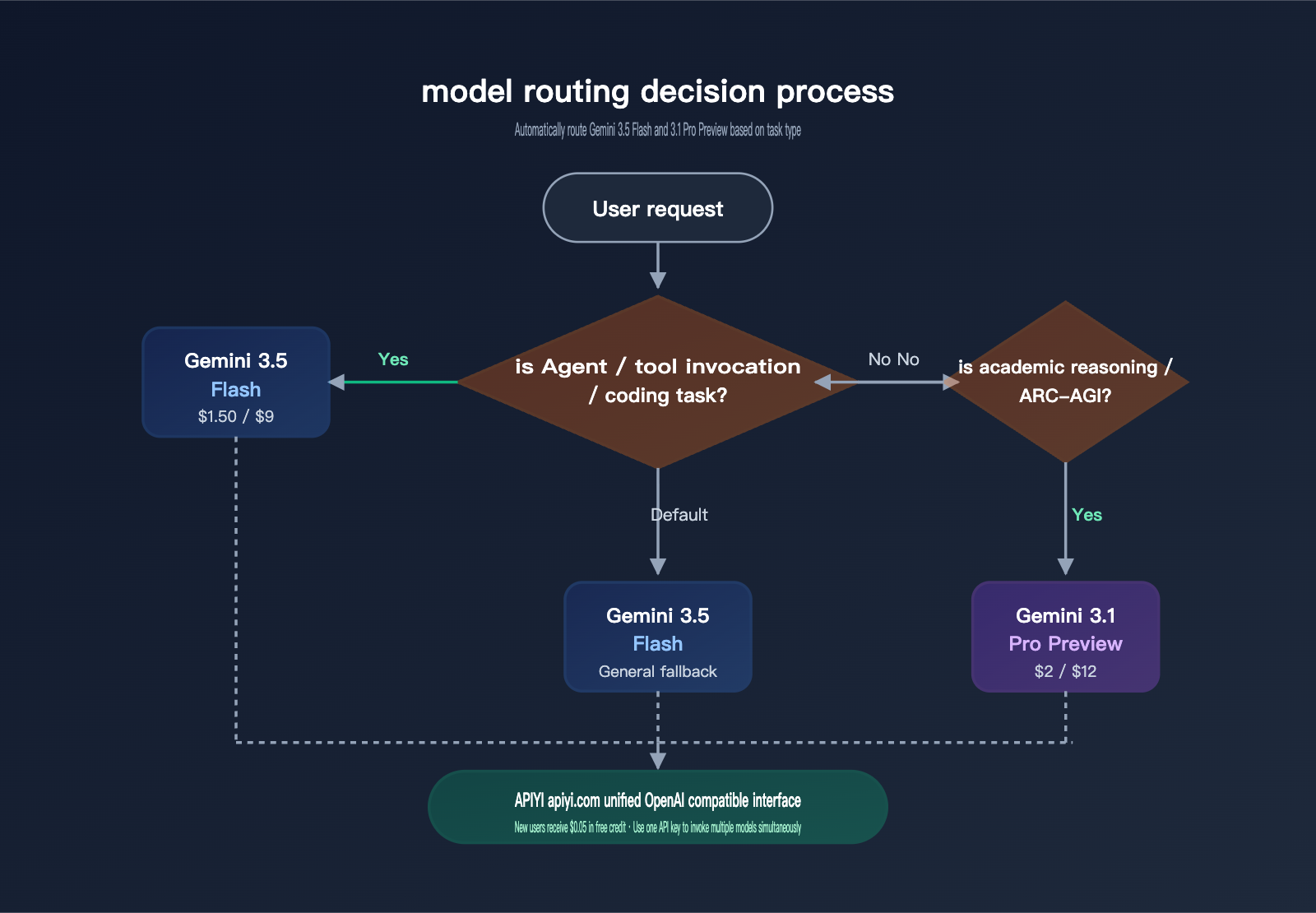
Typical Scenarios for Choosing Gemini 3.5 Flash
If your product features a "read document → call tool → output structured result" workflow, Gemini 3.5 Flash is arguably your best bet right now. Engadget reports that Google has already deployed it into production environments for companies like Shopify (data analysis), Macquarie Bank (financial documents), Salesforce (enterprise automation), Ramp (invoice OCR), Xero (tax workflows), and Databricks (dataset monitoring). With the OpenAI-compatible interface from APIYI (apiyi.com), your migration cost is essentially zero.
Typical Scenarios Still Recommending Gemini 3.1 Pro Preview
If your core task involves high-difficulty reasoning like "Humanity's Last Exam," abstract pattern recognition like ARC-AGI, or long-chain mathematical proofs, Gemini 3.1 Pro Preview still maintains a stable +2 to +5 point advantage. In these scenarios, cost isn't the primary concern—the model's "ceiling" in complex reasoning is what matters most. You can continue to call gemini-3.1-pro-preview via APIYI (apiyi.com) for these tasks until the expected release of Gemini 3.5 Pro this June.
Decision Recommendations and How to Integrate Gemini 3.5 Flash / 3.1 Pro Preview
Returning to the core question of this article—"Is it more value for the same price?"—our conclusion is: For over 70% of real-world business cases, the answer is "yes." 3.5 Flash gives you stronger Agent intelligence at a lower cost. However, for the remaining 30% of complex reasoning and abstract deduction tasks, the high-scoring range of 3.1 Pro Preview is still worth keeping. The safest integration strategy isn't to choose one over the other, but to route both models through your workflow.
Below is a minimal Python integration example showing how to call both Gemini 3.5 Flash and Gemini 3.1 Pro Preview on APIYI (apiyi.com), while fully maintaining OpenAI-compatible syntax.
from openai import OpenAI
client = OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1",
)
def call_gemini(model_id: str, prompt: str) -> str:
resp = client.chat.completions.create(
model=model_id,
messages=[{"role": "user", "content": prompt}],
)
return resp.choices[0].message.content
flash_answer = call_gemini("gemini-3.5-flash", "Plan a GitHub PR weekly report Agent in three steps")
pro_answer = call_gemini("gemini-3.1-pro-preview", "Prove that for any natural number n, n^3 - n is divisible by 6")
print("Flash:", flash_answer)
print("Pro Preview:", pro_answer)
View full implementation with routing strategy
from openai import OpenAI
client = OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1",
)
AGENT_KEYWORDS = ("tool", "function", "agent", "code", "call", "workflow")
REASONING_KEYWORDS = ("prove", "derive", "ARC", "AIME", "math competition", "olymp")
def route_model(task_prompt: str) -> str:
lower = task_prompt.lower()
if any(k in lower for k in REASONING_KEYWORDS):
return "gemini-3.1-pro-preview"
if any(k in task_prompt for k in AGENT_KEYWORDS):
return "gemini-3.5-flash"
return "gemini-3.5-flash"
def smart_call(prompt: str) -> dict:
model = route_model(prompt)
resp = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": prompt}],
)
return {
"model": model,
"content": resp.choices[0].message.content,
"usage": resp.usage.model_dump() if resp.usage else None,
}
if __name__ == "__main__":
print(smart_call("Help me write an Agent to call the GitHub API and pull merged PRs for this week"))
print(smart_call("Prove that the solution space for ARC-AGI problem 42 is no more than 8"))
💡 Trial Suggestion: New users on APIYI (apiyi.com) receive $0.05 in free credits. At the $1.50/$9 pricing for Gemini 3.5 Flash, you can run 30–50 medium-length calls; at the $2/$12 pricing for Gemini 3.1 Pro Preview, you can run 20–30. We recommend using your free credits to run the same set of real-world tasks to compare output quality and latency between the two models before deciding on your production traffic split.
Gemini 3.5 Flash vs 3.1 Pro Preview FAQ
Q1: Can Gemini 3.5 Flash completely replace Gemini 3.1 Pro Preview?
It cannot replace it 100%, but it is sufficient for over 70% of business scenarios. 3.5 Flash performs better and is cheaper for Agents, tool invocation, coding, and long document processing. However, for tasks like "Humanity's Last Exam," ARC-AGI-2, and complex mathematical reasoning, 3.1 Pro Preview still leads by 2–5 points. We recommend mounting both models on APIYI (apiyi.com) and routing based on prompt keywords or task types: use Flash for Agent tasks and Pro for difficult reasoning tasks.
Q2: Why is Gemini 3.5 Flash considered “more value for the same price”?
The "more value" comes from three areas: First, it comprehensively outperforms 3.1 Pro on Agent/coding benchmarks (Terminal-Bench 2.1 is 5.9 points higher, MCP Atlas is 5.4 points higher, and Finance Agent v2 is 14.9 points higher). Second, the knowledge cutoff has been extended from the end of 2025 to January 2026. Third, dynamic thinking is enabled by default, with no need for manual thinking budget configuration. The "same price" (or rather, better value) is reflected in the standard pricing of $1.50/$9, which is 25% cheaper than 3.1 Pro's $2/$12, with the gap widening to 50–62% once you exceed a 200K context window.
Q3: How long will Gemini 3.1 Pro Preview be maintained? Should I migrate now?
Google hasn't provided a specific sunset date, but according to external reports, Gemini 3.5 Pro is expected to be released in June 2026, at which point 3.1 Pro Preview will likely enter maintenance mode. We suggest not rushing to fully decommission 3.1 Pro Preview, but rather demoting it to a "fallback model for difficult reasoning" while shifting the bulk of your traffic to 3.5 Flash. The APIYI (apiyi.com) platform will continue to track the Gemini model lifecycle and provide advance warnings before 3.1 Pro Preview enters the deprecation path.
Q4: Is there a difference in multimodal input between Gemini 3.5 Flash and Gemini 3.1 Pro?
There isn't much difference. Both models support text, image, audio, and video input. Gemini 3.1 Pro Preview explicitly lists "code" as a separate modality in its documentation, and in practice, it is slightly more stable when handling very long code blocks. If your core task is "image understanding + tool invocation," we recommend starting with Gemini 3.5 Flash because it is 4x faster and supports dynamic thinking. Only switch back to Gemini 3.1 Pro Preview if you encounter scenarios requiring single-turn processing of massive codebases. Both can be toggled with one click via the APIYI (apiyi.com) platform.
Summary: The Perfect Partnership Between Gemini 3.5 Flash and 3.1 Pro Preview
Let's circle back to the core question: "Is it more value for the same price?" From a pricing perspective, it's definitely a "no price hike" scenario. The standard tier for Gemini 3.5 Flash is 25% cheaper, the ultra-long context tier is up to 62.5% cheaper, and cache hits save you an additional 25%. In terms of capabilities, it outperforms 3.1 Pro in agentic tasks and coding, though it still trails by 2-5 points in academic and abstract reasoning. You could say it's "an upgrade in 70% of scenarios, with minor trade-offs in the other 30%."
The most pragmatic conclusion is to stop viewing these two models as competitors and start seeing them as partners. Use Gemini 3.5 Flash as your workhorse for daily agent tasks and coding, and keep Gemini 3.1 Pro Preview as a fallback for complex reasoning. You can easily handle the routing between them using the unified OpenAI-compatible interface provided by APIYI (apiyi.com). New users get a $0.05 free credit upon registration, allowing you to benchmark both models at zero cost before deciding on the traffic distribution for your production pipeline.
Author: APIYI Technical Team · apiyi.com
Published: May 20, 2026
References: Google AI for Developers, Google DeepMind Model Card, LLM-Stats, Artificial Analysis, Engadget, DataCamp, BenchLM, OfficeChai