A principios de abril de 2026, un misterioso modelo de vídeo por IA llamado HappyHorse apareció silenciosamente en la tabla de clasificación de pruebas ciegas de Artificial Analysis Video Arena. Las versiones V1 y V2 actualizaron casi simultáneamente las puntuaciones Elo en las categorías de texto a vídeo (Text-to-Video) e imagen a vídeo (Image-to-Video), dejando atrás a pesos pesados como Seedance 2.0, Kling 3.0 y PixVerse V6. Sin embargo, apenas unos días después, HappyHorse 1.0 desapareció repentinamente de la lista, dejando solo unas pocas capturas de pantalla y una página oficial con información vaga.
Las especulaciones sobre el modelo HappyHorse estallaron en la comunidad de IA en inglés: ¿es un disfraz de Wan 2.7? ¿Es el experimento de próxima generación del equipo de ByteDance Seedance? ¿O es un laboratorio asiático desconocido que ha mostrado sus cartas de repente? Este artículo, basado en información verificable públicamente, realiza un análisis completo de la arquitectura, el rendimiento, el estado de código abierto y el posible origen de HappyHorse 1.0, para ayudarte a decidir si vale la pena incluir este "caballo negro" en tu stack de herramientas de generación de vídeo.
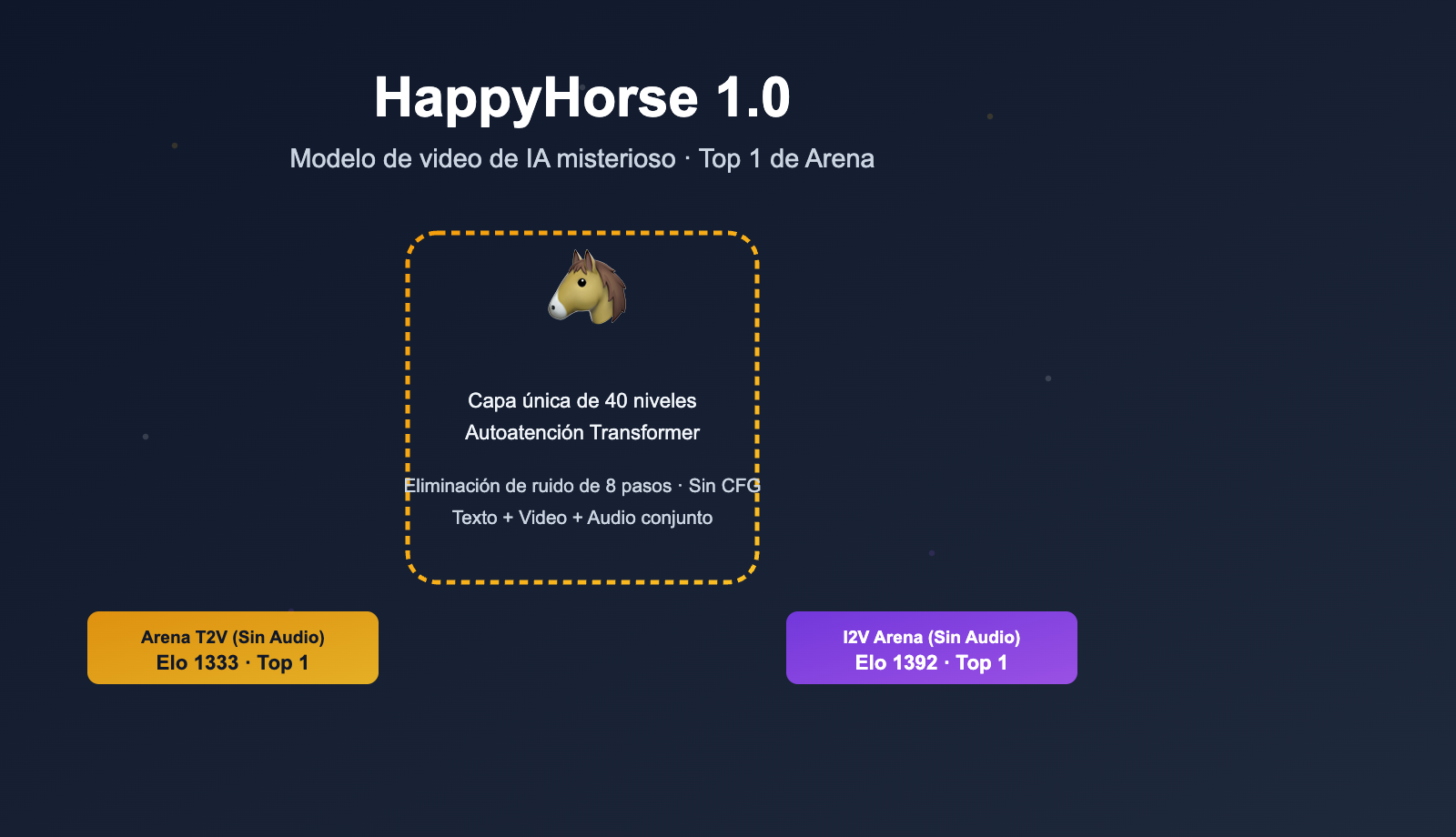
Resumen de información clave del modelo HappyHorse
Antes de desglosar los detalles técnicos, hemos condensado la información conocida en una tabla para facilitar una comprensión rápida.
| Dimensión | Información conocida de HappyHorse 1.0 |
|---|---|
| Tipo de modelo | Modelo de generación de vídeo (texto+imagen a vídeo, generación conjunta de imagen y audio) |
| Arquitectura | Transformer de flujo único (Single-stream) de 40 capas con autoatención, sin atención cruzada (Cross-Attention) |
| Pasos de inferencia | Solo requiere 8 pasos de eliminación de ruido, sin necesidad de CFG (Guía libre de clasificador) |
| Soporte multilingüe | Chino, inglés, japonés, coreano, alemán, francés |
| Lanzamiento | Modelo base / Modelo destilado / Modelo de superresolución / Código de inferencia (oficialmente declarado como código abierto) |
| Ubicación de aparición | Artificial Analysis Video Arena (algunos informes también mencionan la categoría de vídeo de LMArena) |
| Estado actual | V1/V2 han desaparecido de la lista pública, el sitio web sigue activo pero GitHub/Model Hub indica "Próximamente" |
| Posible origen | De un equipo asiático; la comunidad especula que está relacionado con el ecosistema Wan 2.7 / Seedance, pero no ha sido confirmado oficialmente |
🎯 Consejo de prueba rápida: Dado que los pesos oficiales del modelo HappyHorse aún no están abiertos en las principales plataformas de inferencia, si deseas comparar modelos de vídeo del mismo nivel (como Seedance 2.0, Kling 3.0, Veo 3.1) en un entorno de producción, te recomendamos utilizar primero una plataforma de servicio proxy de API unificada como APIYI (apiyi.com) para invocar múltiples modelos de vídeo en paralelo. Así, podrás cambiar sin problemas una vez que HappyHorse se lance oficialmente, evitando trabajos de reingeniería innecesarios.
Cronología del lanzamiento del modelo HappyHorse
Para entender por qué este "caballo feliz" causó tanto revuelo en la comunidad internacional de IA, debemos analizar su cronología paso a paso.
El "Año del Caballo" y la coincidencia en el nombre
El 2026 coincide con el Año del Caballo en el calendario lunar chino. Desde el Festival de Primavera en febrero, medios internacionales y columnas como UX Tigers mencionaron repetidamente que el ecosistema de IA en China estaba preparando una serie de lanzamientos centrados en el "caballo". El nombre "HappyHorse" no solo hace eco del zodiaco, sino que también genera asociaciones con otro modelo lanzado en el mismo periodo, abreviado como "The Horse". Esta fue una de las pistas clave que llevó a la comunidad a identificar, desde el primer momento, que provenía de un equipo asiático.
Explosión y desaparición en el Arena
Según las capturas de pantalla y reportes publicados a principios de abril por evaluadores de video IA en X (anteriormente Twitter), como Brent Lynch, la trayectoria de HappyHorse 1.0 fue aproximadamente la siguiente:
- Aparición inicial: La versión V1 llegó al Artificial Analysis Video Arena como una entrada anónima y, en pocas horas, se coló en el top 3 de las pruebas ciegas de texto a video;
- Lanzamiento de la V2: Casi simultáneamente apareció una variante V2, y ambos modelos ocuparon al mismo tiempo el primer y segundo lugar en la tabla de clasificación de imagen a video;
- Liderazgo: En la categoría sin audio, HappyHorse 1.0 superó a modelos de primer nivel como Seedance 2.0 720p, Kling 3.0 y PixVerse V6;
- Desaparición: En cuestión de días, tanto la V1 como la V2 fueron retiradas de la tabla pública, dejando solo capturas de pantalla y registros de terceros. Poco después, la página oficial publicó un aviso indicando que el "modelo base pronto será de código abierto".
Este patrón de "aparición repentina, dominio de la tabla y retiro silencioso" suele significar dos cosas: o bien un laboratorio estaba realizando pruebas A/B anónimas, o el fabricante detrás del modelo aún estaba preparando el lanzamiento oficial y retiró el modelo tras una exposición prematura al tráfico. Ambas explicaciones elevaron aún más el aura de misterio del modelo HappyHorse.

Análisis de la arquitectura del modelo HappyHorse: ¿Cómo triunfó su Transformer de flujo único de 40 capas?
Aunque la documentación oficial aún no se ha publicado, a través de las descripciones en happyhorse-ai.com y el sitio espejo happy-horse.net, podemos deducir varias decisiones de diseño clave en la arquitectura de HappyHorse 1.0.
Self-Attention de flujo único frente a estructuras complejas multiflujo
Los modelos de generación de video tradicionales (especialmente los modelos multimodales que procesan audio, texto e imagen simultáneamente) suelen adoptar una arquitectura de flujo múltiple (multi-stream), donde el texto, el video y el audio tienen sus propios codificadores y luego interactúan mediante Cross-Attention. Esta estructura es flexible, pero desperdicia muchos parámetros y requiere mover tensores entre ramas durante la inferencia.
HappyHorse 1.0 simplifica todo esto en una sola línea de procesamiento: un Transformer de Self-Attention de 40 capas que procesa tokens de texto, video y audio simultáneamente, sin Cross-Attention intermedia ni subredes diseñadas específicamente para una modalidad. Todos los datos se codifican de forma unificada en una secuencia de tokens, modelándose directamente en el mismo espacio de atención. Este diseño ofrece varias ventajas teóricas:
- Alta eficiencia de parámetros: Ya no se necesitan parámetros redundantes para aislar modalidades;
- Ruta de inferencia corta: Sin traslados adicionales entre modalidades, lo que hace que el kernel sea más continuo;
- Objetivo de entrenamiento unificado: Texto, imagen y audio comparten la misma función de pérdida, facilitando la optimización de extremo a extremo;
- Soporte nativo para sincronización audiovisual: El sonido y la imagen son tokens en la misma secuencia, lo que garantiza la sincronización por diseño.
Inferencia extrema: 8 pasos de eliminación de ruido y sin CFG
Para los desarrolladores que han utilizado modelos como Stable Video Diffusion, Sora o Kling, "decenas de pasos de eliminación de ruido + Classifier-Free Guidance (CFG)" es casi una memoria muscular. Sin embargo, la descripción oficial de HappyHorse 1.0 es bastante audaz: solo requiere 8 pasos de eliminación de ruido y no utiliza CFG para producir la calidad de imagen que lo llevó al primer puesto del Arena.
Esto sugiere que, durante la fase de entrenamiento, el modelo aplicó técnicas como Consistency Distillation / Rectified Flow / Progressive Distillation, comprimiendo el muestreo de múltiples pasos en una predicción directa de pocos pasos. Junto con el "modelo de destilación" y el "modelo de superresolución" lanzados oficialmente, toda la pila de inferencia se ajusta perfectamente al objetivo dual de "amigable para dispositivos finales + alto rendimiento en servidor".
Posible escala de parámetros y requisitos de VRAM
Dado que los pesos aún no son públicos, no es posible verificar directamente la cantidad de parámetros del modelo HappyHorse. Sin embargo, considerando su descripción de 40 capas, flujo único y soporte para 6 idiomas, junto con su rendimiento en el Arena, es razonable suponer que su tamaño está en el mismo rango que modelos públicos como Wan 2.x, Seedance 1.x o Hunyuan Video, probablemente en el intervalo de 10B a 30B de parámetros. Esto significa que, para una implementación local real, se requeriría al menos una tarjeta profesional con alta VRAM; las GPU de consumo general aún deberán esperar a versiones cuantizadas en INT8/FP8.
🎯 Recomendación de arquitectura: Si estás evaluando la "infraestructura de generación de video de próxima generación" para tu equipo, te sugerimos seguir de cerca el paradigma de HappyHorse 1.0 de "Transformer de flujo único + inferencia de pasos mínimos". Antes de que sea completamente de código abierto, puedes utilizar modelos como Seedance, Kling o Veo a través del servicio proxy de API de APIYI (apiyi.com) para realizar ajustes de ingeniería, pulir tus prompts, guiones de cámara y flujos de trabajo de postproducción, y cambiar a HappyHorse una vez que los pesos estén disponibles.
Datos de rendimiento del modelo HappyHorse: ¿Cómo alcanzó la cima en el Arena?
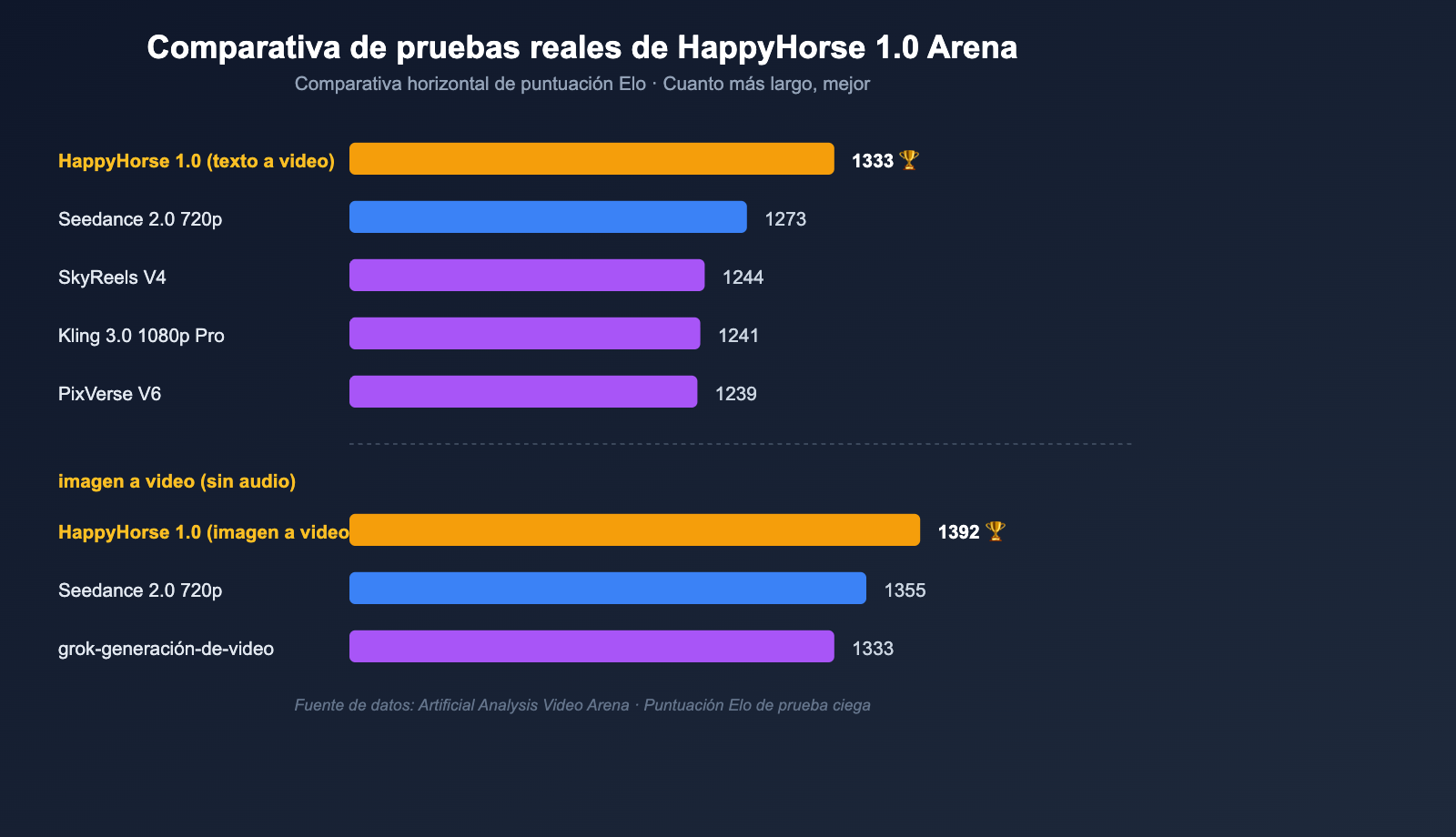
Una vez explicada la arquitectura, lo que realmente convence a los equipos técnicos son los números. La siguiente tabla resume las puntuaciones Elo de pruebas ciegas del HappyHorse 1.0 en el Video Arena de Artificial Analysis, junto con la posición de sus principales competidores.
Comparativa Elo: Texto a video / Imagen a video
| Categoría | Puesto | Modelo | Puntuación Elo |
|---|---|---|---|
| Texto a video (sin audio) | 1 | HappyHorse-1.0 | 1333 |
| Texto a video (sin audio) | 2 | Dreamina Seedance 2.0 720p | 1273 |
| Texto a video (sin audio) | 3 | SkyReels V4 | 1244 |
| Texto a video (sin audio) | 4 | Kling 3.0 1080p (Pro) | 1241 |
| Texto a video (sin audio) | 5 | PixVerse V6 | 1239 |
| Texto a video (con audio) | 1 | Dreamina Seedance 2.0 720p | 1219 |
| Texto a video (con audio) | 2 | HappyHorse-1.0 | 1205 |
| Imagen a video (sin audio) | 1 | HappyHorse-1.0 | 1392 |
| Imagen a video (sin audio) | 2 | Dreamina Seedance 2.0 720p | 1355 |
| Imagen a video (sin audio) | 3 | PixVerse V6 | 1338 |
| Imagen a video (sin audio) | 4 | grok-imagine-video | 1333 |
| Imagen a video (sin audio) | 5 | Kling 3.0 Omni 1080p (Pro) | 1297 |
Algunas observaciones clave:
- La mayor ventaja competitiva está en el segmento de imagen a video: 1392 frente a 1355, una diferencia de casi 40 puntos Elo, lo cual, en sistemas de prueba ciega, se considera un nivel donde "los usuarios pueden notar una diferencia estable".
- También es el número uno en texto a video: 1333 frente a 1273, liderando por 60 puntos, lo que significa que incluso sin una imagen de referencia, el modelo HappyHorse supera a Seedance 2.0 en capacidades fundamentales como la composición de planos y el movimiento de personajes.
- Segundo lugar temporal en el segmento de audio: Seedance 2.0 sigue liderando en la sincronización audiovisual, lo cual está relacionado con el refinamiento de ingeniería que han realizado para la "dirección de IA" en narrativas largas.
- Variante V2: La versión V2 apareció brevemente en algunas capturas de pantalla, pero la versión oficial solo ha publicado la descripción de la 1.0; aún no se ha confirmado si la V2 es la versión que "desapareció".
Soporte multilingüe y escenarios centrados en el ser humano
La documentación oficial indica explícitamente que HappyHorse 1.0 admite de forma nativa 6 idiomas: chino, inglés, japonés, coreano, alemán y francés, destacando que el rendimiento del modelo es especialmente sobresaliente en escenarios "centrados en el ser humano (human-centric)", incluyendo:
- Actuación facial detallada (facial performance);
- Coordinación del habla natural (speech coordination);
- Movimientos corporales realistas (body motion);
- Sincronización labial precisa (lip sync).
Esta descripción posiciona claramente al modelo HappyHorse en el sector de "humanos virtuales / contenido digital / miniseries", y no solo en el de "videos promocionales de paisajes". Esto explica por qué tiene una ventaja tan grande en el segmento de imagen a video (animar una foto de una persona), ya que es la necesidad principal de los humanos digitales.
Origen del modelo HappyHorse: ¿WAN 2.7? ¿Seedance? ¿O un nuevo caballo oscuro?
Cuando las capturas de pantalla de HappyHorse 1.0 comenzaron a circular en la comunidad de IA en inglés, la discusión más animada fue "¿de quién es?". Combinando las pistas de la comunidad, podemos organizar las especulaciones en la siguiente tabla.
Comparativa de las tres especulaciones principales
| Origen supuesto | Argumento principal | Argumento en contra |
|---|---|---|
| Disfraz de Alibaba Wan 2.7 | Lanzado al mismo tiempo que Wan 2.7; Alibaba Tongyi Lab es agresivo en video; el nombre "Horse" hace eco del año del caballo | La descripción oficial de Wan 2.7 se inclina más hacia la imagen / modo de pensamiento, lo que no encaja con la arquitectura de flujo único de 40 capas de HappyHorse |
| Versión experimental del equipo de ByteDance Seedance | Seedance 2.0 es el competidor chino que lidera el Arena; ByteDance tiene motivos para pruebas anónimas | Seedance 2.0 sigue liderando en audio; ByteDance no tendría motivos para subir una "versión mejor" bajo otro nombre |
| Laboratorio no revelado / Consorcio académico | El lanzamiento conjunto de "código abierto + modelo destilado + modelo de superresolución" parece más un estilo de investigación; nombre extraño y sitio web minimalista | La calidad del modelo ya alcanza un nivel comercial; es difícil para un equipo puramente académico entrenar algo de tal escala |
Nos inclinamos a pensar que la probabilidad de la tercera hipótesis está aumentando: es más probable que HappyHorse 1.0 provenga de un nuevo equipo que busca darse a conocer de la noche a la mañana mediante una estrategia de código abierto, eligiendo el anonimato en el Arena para establecer credibilidad con datos de pruebas ciegas antes de un lanzamiento oficial. Esta táctica de "primero posicionarse en el ranking, luego abrir el código y finalmente lanzar el producto" ha sido validada con éxito por varios laboratorios asiáticos en los últimos 18 meses.
Sin embargo, esto es solo una especulación. Hasta que el repositorio de GitHub y el Model Hub no estén oficialmente en línea, ninguna afirmación de que "es X" debe tomarse como un hecho. La actitud más pragmática para los desarrolladores es: centrarse en su curva de capacidades, no en su apellido.
🎯 Consejo prudente: Mientras los pesos del modelo HappyHorse no estén abiertos al público y su origen no sea confirmado oficialmente, no se recomienda apostar directamente los procesos de producción en él. Es mejor utilizar plataformas maduras como APIYI (apiyi.com) para invocar modelos de video ya comercializados como Seedance 2.0, Kling 3.0 o Veo 3.1 para completar sus proyectos, mientras evalúan internamente el progreso del código abierto de HappyHorse.
El impacto en tres niveles del modelo HappyHorse en la industria
Incluso si HappyHorse 1.0 termina siendo solo una campaña de marketing cuidadosamente orquestada, ya ha dejado tres impactos dignos de mención en todo el sector de la generación de vídeo mediante IA.
Primer nivel: Una señal sobre el paradigma arquitectónico
Durante los últimos dos años, los modelos de vídeo convencionales se han centrado en perfeccionar la ruta de "Difusión multiflujo + Cross-Attention". El modelo HappyHorse, al alcanzar el primer puesto en el Arena, demostró directamente que el camino de "Self-Attention de flujo único + inferencia de muy pocos pasos" también puede llegar al estado del arte (SOTA), siendo además más limpio a nivel de ingeniería. Esto obligará a muchos equipos a replantearse: ¿es hora de ahorrarse ese "impuesto de complejidad" que supone la capa de Cross-Attention?
Segundo nivel: La evolución de las estrategias de código abierto
HappyHorse eligió un ritmo de "aparecer de forma anónima → anunciar públicamente que será de código abierto → publicar los pesos", en lugar del enfoque tradicional de "primero publicar el artículo académico y luego los pesos". Esta es una estrategia más cercana al lanzamiento de productos de consumo, donde se prioriza la "percepción de los datos por parte del usuario" sobre el artículo científico. Si finalmente cumple su promesa de abrir el código, HappyHorse 1.0 podría convertirse en otro modelo base de vídeo ampliamente desarrollado por la comunidad, siguiendo los pasos de Wan, Hunyuan Video y Open-Sora.
Tercer nivel: La credibilidad de los rankings de pruebas ciegas
Desde otra perspectiva, la aparición y desaparición repentina de HappyHorse ha hecho sonar las alarmas en plataformas de pruebas ciegas como Artificial Analysis y LMArena. Con la creciente cantidad de entradas anónimas, distinguir entre un "modelo realmente nuevo" y un "checkpoint de un modelo existente" se convertirá en un desafío ineludible para los mantenedores de estos rankings. Para los desarrolladores, esto significa que, al leer las clasificaciones Elo, debemos combinar más factores como la "ficha del modelo + ejemplos de inferencia + datos de negocio reales", en lugar de fijarnos solo en una cifra.

Cómo afrontar eventos de "ataque sorpresa" como el modelo HappyHorse
Para los equipos de ingeniería y creadores de contenido, en lugar de perderse en especulaciones sobre "quiénes son o cuándo abrirán el código", es mejor establecer un protocolo de respuesta estándar ante este tipo de eventos.
Flujo de respuesta recomendado en cuatro pasos
| Paso | Acción | Objetivo |
|---|---|---|
| 1 | Estandarizar la interfaz para los flujos de generación de vídeo actuales | Asegurar una transición fluida ante cualquier modelo nuevo |
| 2 | Recopilar prompts de negocio típicos y material de referencia | Crear un "conjunto de pruebas de referencia" interno, independiente del Arena público |
| 3 | Ejecutar pruebas internas tan pronto como el nuevo modelo esté disponible | Validar con datos propios si la puntuación del Arena es reproducible |
| 4 | Evaluar el coste total (precio de API / latencia de inferencia / cumplimiento) | Decidir si reemplazar el modelo principal |
El núcleo de este flujo es: no dejarse secuestrar por el ritmo de lanzamiento de un solo modelo, sino convertir la "capacidad de integrar rápidamente nuevos modelos" en una competencia fundamental. HappyHorse 1.0 es solo el comienzo; es previsible que en la segunda mitad de 2026 veamos más modelos anónimos similares apareciendo en diversos Arenas de vídeo.
🎯 Consejo de ingeniería: Para los equipos que deseen seguir de cerca el modelo HappyHorse y a sus competidores como Seedance, Kling o Veo, recomendamos integrar la generación de vídeo a través de un servicio proxy de API como APIYI (apiyi.com), que permite la invocación de múltiples modelos en paralelo. De esta forma, independientemente de quién encabece el ranking, el equipo de desarrollo solo tendrá que cambiar el parámetro
modelpara completar la comparación y el despliegue gradual.
Preguntas frecuentes sobre el modelo HappyHorse
Q1: ¿Ya se puede descargar y utilizar HappyHorse 1.0?
Hasta principios de abril de 2026, la página oficial de HappyHorse 1.0 sigue marcando el repositorio de GitHub y el enlace al Model Hub como "Próximamente" (Coming Soon). En otras palabras, los pesos y el código de inferencia aún no se han hecho públicos, por lo que debes ser muy cauteloso con cualquier canal que afirme que "ya se puede descargar y desplegar". Te recomendamos seguir de cerca el sitio web oficial y, mientras se liberan los pesos, utilizar plataformas como APIYI (apiyi.com) para realizar la invocación del modelo de opciones ya comercializadas como Seedance 2.0 o Kling 3.0 para tus proyectos.
Q2: ¿Por qué desapareció el modelo HappyHorse de la clasificación de Arena?
No existe una explicación oficial definitiva en la información pública sobre por qué desapareció. Basándonos en las discusiones de la comunidad, existen dos explicaciones principales: primero, que los autores del modelo lo retiraron voluntariamente para reorganizar los resultados antes de un lanzamiento oficial; segundo, que la plataforma lo eliminó temporalmente debido a que la identidad de la entrada anónima no estaba clara. En cualquier caso, no debe interpretarse simplemente como que "el modelo no funciona": su puntuación Elo antes de desaparecer es un dato real obtenido mediante pruebas ciegas.
Q3: ¿HappyHorse 1.0 y Wan 2.7 son el mismo modelo?
No hay información oficial que confirme esto. Wan 2.7 es un modelo de imagen/video lanzado oficialmente por Alibaba Tongyi Lab en abril de 2026, enfocado en el "modo de pensamiento" y el renderizado de texto largo; por otro lado, el modelo HappyHorse destaca por su Transformer de flujo único de 40 capas y una inferencia de eliminación de ruido de 8 pasos. Las descripciones técnicas de ambos no coinciden. Algunos miembros de la comunidad especulan que tienen un origen común, pero actualmente parece más una situación de "dos productos en la misma pista al mismo tiempo" que diferentes empaquetados del mismo modelo.
Q4: ¿Puede el modelo HappyHorse realizar generación conjunta de audio y video?
Sí. La documentación oficial indica claramente que HappyHorse 1.0 procesa tokens de texto, video y audio de forma conjunta dentro del mismo Transformer de 40 capas, por lo que admite de forma nativa la función de "entrada de texto → salida de cortometraje con sonido". Actualmente ocupa el segundo lugar en la categoría de audio de Arena, solo por detrás de Seedance 2.0, pero sigue perteneciendo al primer nivel.
Q5: Como desarrollador, ¿cómo debería prepararme ahora?
La estrategia más eficiente es mantener la neutralidad en tu cadena de herramientas: integra tus servicios de generación de video en una plataforma unificada como APIYI (apiyi.com), que admite la invocación paralela de múltiples modelos. Esto te permite tener listos tus prompts, guiones de cámara y procesos de revisión. Una vez que el modelo HappyHorse sea de código abierto o tenga una API disponible, solo tendrás que cambiar el parámetro del modelo para incorporar a este nuevo competidor sin necesidad de reescribir tu código.
Q6: ¿Para qué escenarios de negocio es adecuado el modelo HappyHorse?
Dada la insistencia oficial en "escenarios humanos, actuación facial, sincronización labial y multilingüismo", las áreas más adecuadas para el modelo HappyHorse incluyen: streamers virtuales / videos cortos de avatares digitales, miniseries de IA, videos promocionales en varios idiomas y fragmentos de personajes en publicidad. Si tu negocio se centra principalmente en paisajes o tomas de productos, Seedance 2.0, Veo 3.1 o Kling 3.0 siguen siendo opciones más sólidas y listas para usar.
Conclusión: Lo que el modelo HappyHorse nos enseña
Al unir todas las piezas, el modelo HappyHorse 1.0 merece un análisis completo no solo porque su puntuación Elo en el Artificial Analysis Video Arena es impresionante, sino porque representa una cristalización del paradigma de lanzamiento de modelos de video en 2026: Transformer de flujo único reemplazando estructuras complejas de múltiples flujos, inferencia de muy pocos pasos reemplazando decenas de pasos de eliminación de ruido, entradas anónimas en listas de clasificación reemplazando la publicación previa de artículos científicos, y promesas de código abierto reemplazando APIs cerradas. Ninguno de estos cuatro cambios es disruptivo por sí solo, pero juntos significan que estamos entrando en un nuevo ritmo de iteración para los modelos de video.
El consejo para los equipos de primera línea es simple y directo: no te pierdas en las adivinanzas sobre "quién es", tómalo como una prueba de estrés de ingeniería: ¿puede tu flujo de trabajo de generación de video integrarse y evaluarse el mismo día que aparece un nuevo modelo? Si la respuesta es sí, entonces, independientemente de si el modelo HappyHorse se vuelve realmente de código abierto, si se confirma que es una marca secundaria de algún fabricante o si desaparece en silencio, podrás sacar provecho de la situación.
🎯 Recomendación final: Si deseas experimentar con todos los modelos de video de IA convencionales (Seedance 2.0 / Kling 3.0 / Veo 3.1 / PixVerse V6, etc.) además de HappyHorse 1.0, y mantener la capacidad de cambiar a HappyHorse con un solo clic en el futuro, te recomendamos utilizar una plataforma de servicio proxy de API unificada como APIYI (apiyi.com). Esto te permite evitar la integración repetitiva con el SDK de cada fabricante y reducir al mínimo los costos de migración cuando se lancen nuevos modelos.
Autor: APIYI Team | Enfocados en la implementación y práctica de ingeniería de Modelos de Lenguaje Grande de IA. Para más evaluaciones de video y modelos multimodales, visita APIYI (apiyi.com).