Début avril 2026, un mystérieux modèle de génération vidéo par IA nommé HappyHorse a fait une apparition discrète dans le classement en aveugle de l'Artificial Analysis Video Arena. Les versions V1 et V2 ont presque simultanément fait grimper leurs scores Elo dans les catégories texte vers image et image vers vidéo, reléguant des poids lourds comme Seedance 2.0, Kling 3.0 et PixVerse V6 au second plan. Cependant, quelques jours plus tard, HappyHorse 1.0 a soudainement disparu du classement, ne laissant derrière lui que quelques captures d'écran et une page officielle aux informations vagues.
Les spéculations autour du modèle HappyHorse ont immédiatement enflammé la communauté IA anglophone : s'agit-il d'un pseudonyme pour Wan 2.7 ? D'une expérimentation de nouvelle génération par l'équipe de ByteDance Seedance ? Ou d'un coup d'éclat d'un laboratoire asiatique encore inconnu ? Cet article, basé sur des données vérifiables publiquement, propose une analyse complète de l'architecture, des performances, de l'état de l'open source et des origines potentielles de HappyHorse 1.0, afin de vous aider à déterminer si ce cheval noir mérite une place dans votre pile technologique de génération vidéo.
Aperçu des informations clés sur le modèle HappyHorse
Avant de décortiquer les détails techniques, résumons les informations connues dans ce tableau pour une compréhension rapide.
| Dimension | Informations connues sur HappyHorse 1.0 |
|---|---|
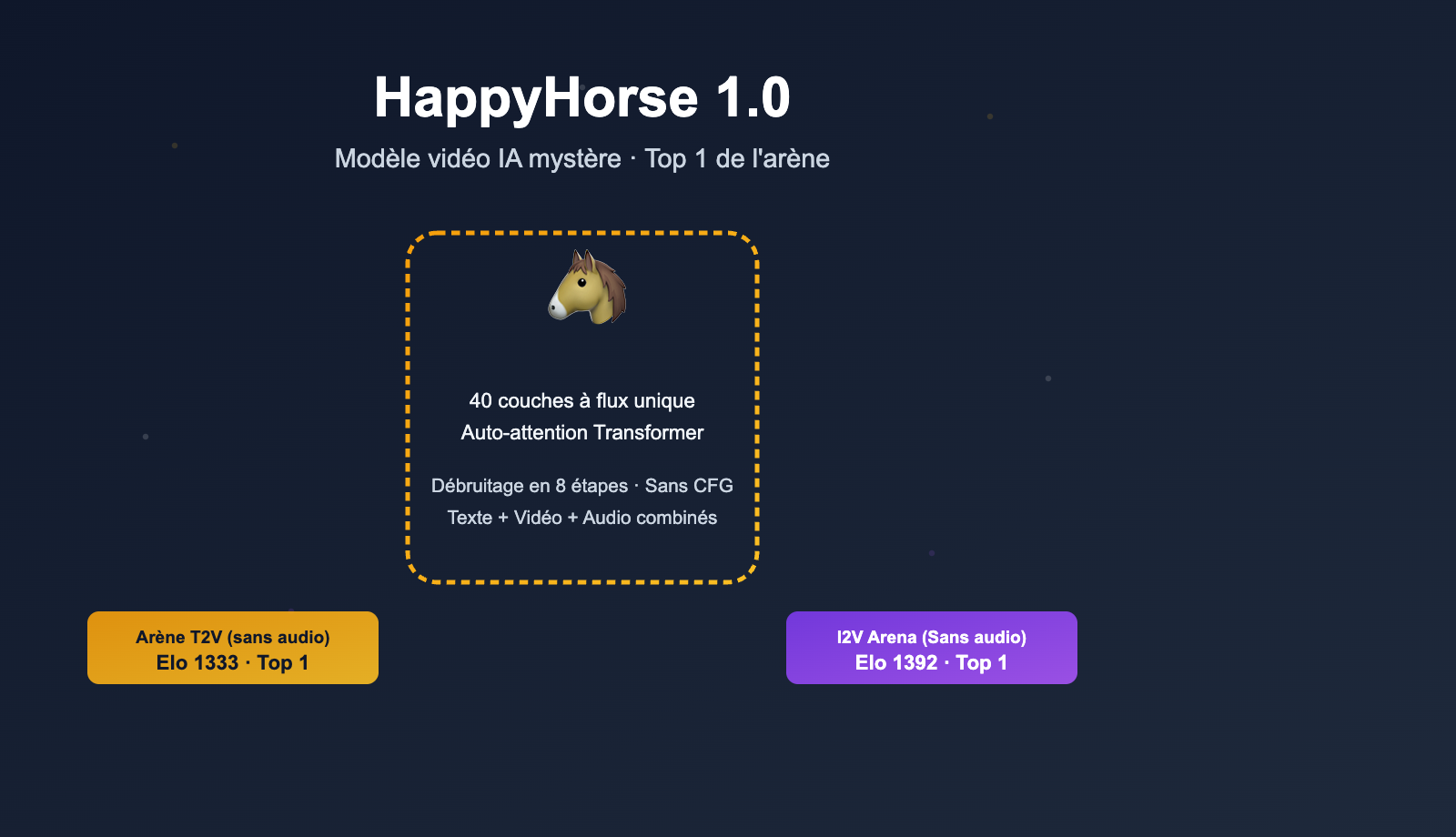
| Type de modèle | Modèle de génération vidéo par texte et image (génération conjointe image et audio) |
| Architecture | Transformer à flux unique (Self-Attention) de 40 couches, sans Cross-Attention |
| Étapes d'inférence | Seulement 8 étapes de débruitage, sans CFG (Classifier-Free Guidance) |
| Support multilingue | Chinois, anglais, japonais, coréen, allemand, français |
| Livrables | Modèle de base / Modèle distillé / Modèle de super-résolution / Code d'inférence (officiellement annoncé comme open source) |
| Lieu d'apparition | Artificial Analysis Video Arena (certaines sources mentionnent aussi la catégorie vidéo de LMArena) |
| État actuel | V1/V2 retirés des classements publics, site officiel en ligne mais GitHub/Model Hub indiquent "À venir" |
| Origine suspectée | Équipe asiatique, spéculations communautaires liées à l'écosystème Wan 2.7 / Seedance, non confirmé officiellement |
🎯 Conseil pour des tests rapides : Comme les poids officiels du modèle HappyHorse ne sont pas encore disponibles sur les plateformes d'inférence grand public, si vous souhaitez comparer dès maintenant des modèles vidéo de même catégorie (comme Seedance 2.0, Kling 3.0, Veo 3.1) dans votre environnement de production, nous vous recommandons d'utiliser une plateforme de service proxy API unifiée comme APIYI (apiyi.com) pour invoquer plusieurs modèles en parallèle. Vous pourrez ainsi basculer vers HappyHorse sans effort dès sa sortie officielle, évitant ainsi des travaux de refonte inutiles.
Chronologie de l'émergence du modèle HappyHorse
Pour comprendre pourquoi ce "cheval heureux" a provoqué une telle onde de choc dans la communauté IA internationale, il est nécessaire de retracer les événements dans l'ordre.
L'année du Cheval et une coïncidence de nommage
L'année 2026 correspond précisément à l'année du Cheval dans le calendrier lunaire chinois. Depuis le Nouvel An en février, les médias internationaux et des colonnes spécialisées comme UX Tigers ont mentionné à plusieurs reprises que la scène IA chinoise préparait une série de lancements centrés sur le "cheval". Le nom "HappyHorse" fait écho à la fois au signe du zodiaque et à un autre modèle, surnommé simplement "The Horse", apparu à la même période. C'est l'un des indices clés qui a permis à la communauté d'identifier immédiatement qu'il provenait d'une équipe asiatique.
Explosion et disparition sur l'Arena
D'après les captures d'écran et les rapports publiés début avril par des testeurs de vidéos IA sur X (anciennement Twitter) comme Brent Lynch, le rythme d'apparition de HappyHorse 1.0 a été le suivant :
- Première apparition : La version V1 a été ajoutée sous forme d'entrée anonyme sur l'Artificial Analysis Video Arena, atteignant le top 3 des tests en aveugle texte-vidéo en quelques heures ;
- Lancement de la version V2 : Presque simultanément, une variante V2 est apparue, les deux versions occupant brièvement les première et deuxième places du classement image-vidéo ;
- Au sommet : Dans la catégorie sans audio, HappyHorse 1.0 a surpassé des modèles de premier plan tels que Seedance 2.0 720p, Kling 3.0 et PixVerse V6 ;
- Disparition : En quelques jours, les V1/V2 ont été retirées du classement public, ne laissant derrière elles que des captures d'écran et des enregistrements tiers. La page officielle a ensuite affiché une note indiquant qu'un "modèle de base sera bientôt open source".
Ce rythme de "montée en puissance soudaine, domination du classement, puis retrait discret" signifie généralement deux choses : soit un laboratoire effectue des tests A/B anonymes, soit le fabricant derrière le modèle prépare un lancement officiel et a retiré le modèle après une exposition prématurée au trafic. Ces deux explications renforcent le mystère entourant le modèle HappyHorse.

Analyse de l'architecture du modèle HappyHorse : comment un Transformer à flux unique de 40 couches domine-t-il le classement ?
Bien que l'article officiel n'ait pas encore été publié, les descriptions sur happyhorse-ai.com et le site miroir happy-horse.net permettent de reconstituer plusieurs choix de conception clés de HappyHorse 1.0.
Le Self-Attention à flux unique remplace les structures complexes multi-flux
Les modèles de génération vidéo traditionnels (en particulier les modèles multimodaux traitant simultanément l'audio, le texte et l'image) utilisent généralement une architecture multi-flux, où le texte, la vidéo et l'audio possèdent chacun leur propre encodeur, interagissant ensuite via Cross-Attention. Cette structure est flexible mais gaspille énormément de paramètres, nécessitant le transfert de tenseurs entre plusieurs branches lors de l'inférence.
HappyHorse 1.0 simplifie tout cela en un seul pipeline : un Transformer Self-Attention de 40 couches traite simultanément les jetons de texte, de vidéo et d'audio, sans aucune Cross-Attention intermédiaire, ni sous-réseau dédié à une modalité spécifique. Tous les modes sont encodés uniformément en une séquence de jetons, modélisés directement dans le même espace d'attention. Cette conception présente plusieurs avantages théoriques :
- Efficacité des paramètres élevée : Plus besoin de paramètres redondants pour isoler les modalités ;
- Chemin d'inférence court : Pas de transfert intermodal supplémentaire, le noyau (kernel) est plus continu ;
- Objectif d'entraînement unifié : Le texte, l'image et l'audio partagent la même fonction de perte, facilitant l'optimisation de bout en bout ;
- Support natif de la synchronisation audio-vidéo : Le son et l'image sont des jetons au sein de la même séquence, garantissant une contrainte de synchronisation intrinsèque.
Inférence extrême : 8 étapes de débruitage sans CFG
Pour les développeurs habitués aux modèles comme Stable Video Diffusion, Sora ou Kling, "des dizaines d'étapes de débruitage + Classifier-Free Guidance (CFG)" sont devenues une seconde nature. La description officielle de HappyHorse 1.0 est assez radicale : seulement 8 étapes de débruitage, sans utiliser de CFG, suffisent pour produire la qualité d'image qui occupe actuellement la première place de l'Arena.
Cela signifie généralement que le modèle a bénéficié, lors de l'entraînement, de techniques telles que la distillation par cohérence (Consistency Distillation), le flux rectifié (Rectified Flow) ou la distillation progressive, compressant l'échantillonnage multi-étapes en quelques prédictions directes. Avec le "modèle distillé" et le "modèle de super-résolution" publiés simultanément, toute la pile d'inférence est très proche des objectifs de "compatibilité avec le terminal + haut débit côté serveur".
Échelle des paramètres et besoins en VRAM
Comme les poids n'ont pas encore été rendus publics, il est impossible de vérifier directement le nombre de paramètres du modèle HappyHorse. Cependant, compte tenu de ses 40 couches, de son flux unique, de la prise en charge de 6 langues et de ses performances sur l'Arena, il est raisonnable de supposer qu'il se situe dans la même catégorie que des modèles publics comme Wan 2.x, Seedance 1.x ou Hunyuan Video, probablement dans la fourchette de 10B à 30B paramètres. Cela signifie qu'un déploiement local nécessite au moins une carte professionnelle avec une grande mémoire vidéo, et que les GPU grand public devront attendre des versions quantifiées INT8/FP8.
🎯 Conseils de sélection d'architecture : Si vous évaluez actuellement l'infrastructure de "génération vidéo de nouvelle génération" pour votre équipe, nous vous suggérons de garder un œil attentif sur le paradigme du "Transformer à flux unique + inférence en très peu d'étapes" de HappyHorse 1.0. En attendant son ouverture complète, vous pouvez utiliser les modèles Seedance, Kling ou Veo sur APIYI (apiyi.com) pour peaufiner vos invites, vos scripts de caméra et vos pipelines de post-production, puis basculer une fois les poids de HappyHorse disponibles.
Données de test du modèle HappyHorse : Comment il a conquis le classement Arena
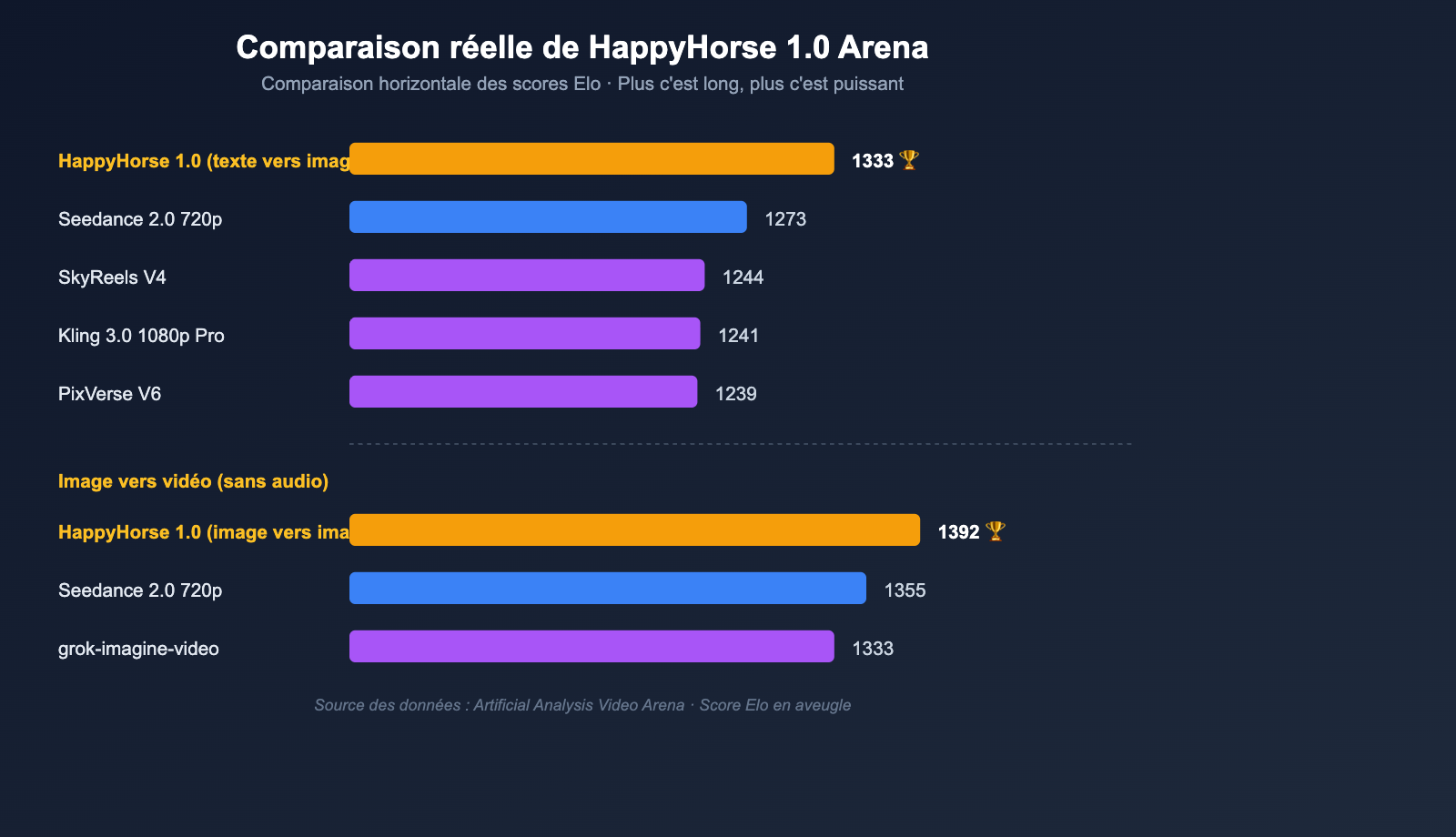
Une fois l'architecture expliquée, ce sont les chiffres qui convainquent réellement les équipes de terrain. Le tableau ci-dessous résume les scores Elo obtenus lors des tests en aveugle sur l'Artificial Analysis Video Arena pour HappyHorse 1.0, ainsi que la position de ses principaux concurrents, d'après les relevés publics tiers.
Comparaison des scores Elo : Texte vers vidéo / Image vers vidéo
| Catégorie | Rang | Modèle | Score Elo |
|---|---|---|---|
| Texte vers vidéo (sans audio) | 1 | HappyHorse-1.0 | 1333 |
| Texte vers vidéo (sans audio) | 2 | Dreamina Seedance 2.0 720p | 1273 |
| Texte vers vidéo (sans audio) | 3 | SkyReels V4 | 1244 |
| Texte vers vidéo (sans audio) | 4 | Kling 3.0 1080p (Pro) | 1241 |
| Texte vers vidéo (sans audio) | 5 | PixVerse V6 | 1239 |
| Texte vers vidéo (avec audio) | 1 | Dreamina Seedance 2.0 720p | 1219 |
| Texte vers vidéo (avec audio) | 2 | HappyHorse-1.0 | 1205 |
| Image vers vidéo (sans audio) | 1 | HappyHorse-1.0 | 1392 |
| Image vers vidéo (sans audio) | 2 | Dreamina Seedance 2.0 720p | 1355 |
| Image vers vidéo (sans audio) | 3 | PixVerse V6 | 1338 |
| Image vers vidéo (sans audio) | 4 | grok-imagine-video | 1333 |
| Image vers vidéo (sans audio) | 5 | Kling 3.0 Omni 1080p (Pro) | 1297 |
Quelques observations clés :
- Avantage majeur dans la catégorie image vers vidéo : 1392 contre 1355, soit un écart de près de 40 points Elo, ce qui, dans un système de test en aveugle, correspond à un niveau où "les utilisateurs perçoivent une différence stable" ;
- Premier également en texte vers vidéo pur : 1333 contre 1273, soit 60 points d'avance, ce qui signifie que même sans image de référence, le modèle HappyHorse surpasse Seedance 2.0 en termes de composition de plan, de mouvements de personnages et d'autres capacités fondamentales ;
- Deuxième place temporaire pour l'audio : Seedance 2.0 reste en tête sur la synchronisation audio-visuelle, grâce au travail d'ingénierie réalisé pour la narration longue typique d'un "réalisateur IA" ;
- Variante V2 : La V2 est apparue brièvement en tête dans certaines captures d'écran, mais comme le site officiel ne propose que la version 1.0, il n'est pas confirmé si la V2 est la version qui a "disparu" par la suite.
Support multilingue et scénarios centrés sur l'humain
L'équipe officielle a clairement indiqué que HappyHorse 1.0 prend nativement en charge 6 langues : chinois, anglais, japonais, coréen, allemand et français, tout en soulignant que le modèle excelle particulièrement dans les scénarios "centrés sur l'humain", notamment :
- Performance faciale détaillée ;
- Coordination vocale naturelle ;
- Mouvements corporels réalistes ;
- Synchronisation labiale précise.
Cette description positionne clairement le modèle HappyHorse sur le segment des "humains virtuels / contenu numérique / mini-séries", et non simplement sur celui des "vidéos de paysages". Cela explique pourquoi il domine la catégorie image vers vidéo (animer une photo de personnage), qui est le besoin fondamental des humains numériques.
Origine du modèle HappyHorse : WAN 2.7 ? Seedance ? Ou un nouveau venu surprise ?
Lorsque les captures d'écran de HappyHorse 1.0 ont commencé à circuler dans la communauté IA anglophone, la question la plus débattue était : "À qui appartient-il ?". En recoupant les indices de la communauté, nous avons résumé les hypothèses dans le tableau suivant.
Comparaison des trois hypothèses principales
| Hypothèse | Argument principal | Argument contraire |
|---|---|---|
| Alias de Alibaba Wan 2.7 | Sortie concomitante avec Wan 2.7, Alibaba Tongyi Lab est agressif sur la vidéo ; le nom "Horse" fait écho à l'année du cheval | La description officielle de Wan 2.7 est plus axée sur l'image / mode réflexion, ce qui ne correspond pas à l'architecture monocouche à 40 couches de HappyHorse |
| Version expérimentale de l'équipe ByteDance Seedance | Seedance 2.0 est un acteur chinois majeur de l'Arena, ByteDance a des raisons de tester anonymement | L'équipe officielle de Seedance 2.0 reste en tête sur l'audio, ByteDance n'aurait aucune raison de publier une "version supérieure" sous un autre nom |
| Laboratoire inconnu / Consortium académique | Le pack "Open source complet + modèle de distillation + modèle de super-résolution" ressemble à une approche de recherche ; nom étrange, site minimaliste | La qualité du modèle atteint un niveau commercial, il est difficile pour une équipe purement académique d'entraîner un modèle de cette envergure |
Nous penchons personnellement de plus en plus vers la troisième hypothèse : HappyHorse 1.0 provient probablement d'une nouvelle équipe souhaitant se faire connaître du jour au lendemain grâce à une stratégie open source. Le choix de l'anonymat sur l'Arena servirait à établir sa crédibilité par les données de test en aveugle avant une sortie officielle. Cette tactique de "classement d'abord, open source ensuite, produit enfin" a déjà fait ses preuves pour plusieurs laboratoires asiatiques ces 18 derniers mois.
Cependant, cela reste une supposition. Tant que le dépôt GitHub et le Model Hub ne seront pas officiellement en ligne, aucune affirmation du type "c'est X" ne doit être considérée comme un fait. L'attitude la plus pragmatique pour un développeur est : concentrez-vous sur sa courbe de performance, pas sur son pedigree.
🎯 Conseil prudent : Tant que les poids du modèle HappyHorse ne sont pas ouverts et que son origine n'est pas confirmée officiellement, il est déconseillé de baser vos activités de production directement dessus. Vous pouvez d'abord utiliser des plateformes matures comme APIYI (apiyi.com) pour invoquer des modèles vidéo déjà commercialisés comme Seedance 2.0, Kling 3.0 ou Veo 3.1 pour vos projets, tout en évaluant en parallèle la progression open source de HappyHorse en interne.
L'impact du modèle HappyHorse sur l'industrie en trois niveaux
Même si le HappyHorse 1.0 finit par n'être qu'une campagne de teasing savamment orchestrée, il a déjà laissé trois traces indélébiles sur le secteur de la génération de vidéo par IA.
Premier niveau : Le signal d'un changement de paradigme architectural
Au cours des deux dernières années, les modèles vidéo dominants ont continué à se perfectionner sur la voie du "Multi-stream Diffusion + Cross-Attention". Le modèle HappyHorse, en atteignant la première place de l'Arena, a prouvé qu'une approche "Single-stream Self-Attention + inférence en très peu d'étapes" pouvait tout aussi bien atteindre le SOTA (State-of-the-Art), tout en étant plus propre sur le plan de l'ingénierie. Cela poussera davantage d'équipes à se remettre en question : ne serait-il pas temps de se débarrasser de cette "taxe de complexité" qu'est la Cross-Attention ?
Deuxième niveau : L'évolution des stratégies open source
HappyHorse a choisi une stratégie de "classement anonyme → annonce d'ouverture → publication des poids", plutôt que la méthode traditionnelle "publication de l'article → publication des poids". C'est une approche plus proche du lancement de produits grand public, qui privilégie les "données de perception utilisateur" avant même la publication académique. S'il finit par être publié en open source comme promis, le HappyHorse 1.0 pourrait devenir, après Wan, Hunyuan Video et Open-Sora, un nouveau modèle de base vidéo massivement utilisé pour le développement secondaire.
Troisième niveau : La crédibilité des classements en aveugle
D'un autre point de vue, l'ascension fulgurante et la disparition soudaine de HappyHorse ont tiré la sonnette d'alarme pour les plateformes de test en aveugle comme Artificial Analysis ou LMArena. Avec la multiplication des entrées anonymes, la distinction entre un "nouveau modèle réel" et un simple "checkpoint d'un modèle existant" devient un défi majeur pour les mainteneurs de classements. Pour les développeurs, cela signifie qu'en consultant les scores Elo, nous devons désormais croiser davantage les informations avec la "fiche du modèle + exemples d'inférence + données métier réelles", plutôt que de nous fier uniquement à un chiffre.

Comment les développeurs doivent réagir face aux "attaques surprises" comme le modèle HappyHorse
Pour les équipes d'ingénierie et les créateurs de contenu, plutôt que de se perdre en conjectures sur "qui est-ce et quand sera-t-il open source", il vaut mieux établir un protocole standard de réponse à ce type d'événement.
Processus de réponse en quatre étapes recommandé
| Étape | Action | Objectif |
|---|---|---|
| 1 | Utiliser une interface unifiée pour fluidifier l'activité de génération vidéo | Garantir une transition transparente lors de l'apparition de nouveaux modèles |
| 2 | Collecter des invites (prompts) métier types et des supports de référence | Créer un "jeu de test de référence" interne, indépendant de l'Arena publique |
| 3 | Exécuter les tests de référence internes dès la disponibilité du nouveau modèle | Vérifier avec ses propres données si le score Arena est reproductible |
| 4 | Évaluer le coût total (prix de l'API / latence d'inférence / conformité) | Décider s'il faut remplacer le modèle principal |
Le cœur de cette approche est le suivant : ne vous laissez pas dicter votre rythme par la sortie d'un modèle unique, mais faites de la "capacité à intégrer rapidement de nouveaux modèles" une compétence fondamentale. Le HappyHorse 1.0 n'est qu'un début ; on peut s'attendre à ce que d'autres modèles anonymes similaires apparaissent sur les différentes Arena vidéo d'ici le second semestre 2026.
🎯 Conseil d'ingénierie : Pour les équipes souhaitant suivre sur le long terme le modèle HappyHorse ainsi que ses concurrents comme Seedance, Kling ou Veo, nous recommandons d'intégrer la génération vidéo via une plateforme de service proxy API comme APIYI (apiyi.com), qui prend en charge l'invocation parallèle de plusieurs modèles. Ainsi, quel que soit le modèle qui monte dans le classement, il suffit de modifier un paramètre
modelcôté métier pour effectuer des comparaisons et des déploiements progressifs.
FAQ sur le modèle HappyHorse
Q1 : Le modèle HappyHorse 1.0 est-il déjà disponible au téléchargement ?
À l'heure actuelle (début avril 2026), la page officielle de HappyHorse 1.0 indique toujours que le dépôt GitHub et le lien vers le Model Hub sont "Coming Soon" (bientôt disponibles). En d'autres termes, les poids et le code d'inférence ne sont pas encore publics. Soyez très prudent avec toute source prétendant qu'il est "déjà possible de le télécharger et de le déployer". Nous vous conseillons de surveiller le site officiel et, en attendant la sortie officielle, d'utiliser des plateformes comme APIYI (apiyi.com) pour invoquer des modèles déjà commercialisés tels que Seedance 2.0 ou Kling 3.0 pour vos projets.
Q2 : Pourquoi le modèle HappyHorse a-t-il disparu du classement Arena ?
Les informations publiques ne fournissent aucune explication précise sur cette disparition. Selon les discussions au sein de la communauté, deux hypothèses principales se dégagent : soit les auteurs du modèle l'ont retiré volontairement pour réorganiser les résultats avant une publication officielle, soit la plateforme l'a temporairement délisté en raison du statut anonyme de l'entrée. Dans les deux cas, cela ne signifie pas que le "modèle n'est pas performant" — son score Elo avant sa disparition reposait sur des données réelles issues de tests en aveugle.
Q3 : HappyHorse 1.0 et Wan 2.7 sont-ils le même modèle ?
Aucune information officielle ne confirme cette hypothèse. Wan 2.7 est un modèle d'image/vidéo publié officiellement par Alibaba Tongyi Lab en avril 2026, axé sur le "mode réflexion" et le rendu de textes longs ; tandis que le modèle HappyHorse met en avant un Transformer à flux unique de 40 couches et une inférence de débruitage en 8 étapes. Les descriptions techniques diffèrent. Certains membres de la communauté spéculent sur une origine commune, mais il s'agit actuellement davantage de "deux produits concurrents sur le même segment" que de versions différentes d'un même modèle.
Q4 : Le modèle HappyHorse peut-il générer de l'audio et de la vidéo simultanément ?
Oui. L'équipe officielle a clairement indiqué que HappyHorse 1.0 traite conjointement les jetons (tokens) de texte, de vidéo et d'audio au sein d'un même Transformer de 40 couches, ce qui permet nativement la fonction "saisie de texte → sortie de court-métrage sonore". Dans la catégorie audio de l'Arena, il se classe actuellement deuxième, derrière Seedance 2.0, ce qui le place dans le premier groupe de tête.
Q5 : En tant que développeur, comment dois-je me préparer ?
La stratégie la plus rentable est de maintenir une chaîne d'outils neutre : connectez vos services de génération vidéo à une plateforme unifiée comme APIYI (apiyi.com) qui prend en charge l'invocation parallèle de plusieurs modèles. Préparez vos invites (prompts), vos scripts de plans et vos processus de vérification dès maintenant. Une fois que le modèle HappyHorse sera officiellement open source ou disponible via API, il vous suffira de modifier le paramètre du modèle pour intégrer ce nouveau venu sans avoir à réécrire votre code.
Q6 : À quels cas d'usage le modèle HappyHorse est-il adapté ?
Au vu de l'accent mis par les officiels sur les "scènes humaines, performances faciales, synchronisation labiale et multilinguisme", les domaines les plus pertinents pour le modèle HappyHorse incluent : les streamers virtuels / vidéos courtes de personnages numériques, les mini-séries IA, les vidéos promotionnelles multilingues et les séquences de personnages dans la publicité. Si votre activité se concentre principalement sur les paysages ou les plans produits, Seedance 2.0, Veo 3.1 ou Kling 3.0 restent des choix plus stables et éprouvés.
Conclusion : Ce que le modèle HappyHorse nous enseigne
En recoupant tous les indices, si le HappyHorse 1.0 mérite une analyse complète, ce n'est pas seulement pour son score Elo impressionnant sur l'Artificial Analysis Video Arena, mais parce qu'il incarne une évolution majeure dans le paradigme de publication des modèles de génération vidéo en 2026 : le remplacement des structures complexes multi-flux par des Transformers à flux unique, l'inférence en très peu d'étapes au lieu de dizaines, l'anonymat au classement avant la publication d'articles scientifiques, et la promesse d'open source plutôt que des API fermées. Aucun de ces changements n'est révolutionnaire pris isolément, mais leur combinaison annonce un nouveau rythme d'itération pour les modèles vidéo.
Le conseil pour les équipes de terrain est simple : ne vous perdez pas dans les conjectures sur son identité, considérez-le plutôt comme un test de résistance technique : votre pipeline de génération vidéo est-il capable d'intégrer et d'évaluer un nouveau modèle dès le jour de sa sortie ? Si la réponse est oui, alors peu importe que le modèle HappyHorse devienne réellement open source, qu'il soit lié à un fabricant spécifique ou qu'il sombre dans l'oubli, vous en sortirez gagnant.
🎯 Conseil final : Pour tester tous les modèles vidéo IA grand public (Seedance 2.0 / Kling 3.0 / Veo 3.1 / PixVerse V6, etc.) dès leur sortie et conserver la possibilité de basculer vers HappyHorse en un clic, nous vous recommandons d'utiliser une plateforme de service proxy API comme APIYI (apiyi.com). Cela vous évite de devoir intégrer le SDK de chaque fournisseur et réduit au minimum les coûts de migration lors du lancement de nouveaux modèles.
Auteur : APIYI Team | Focus sur le déploiement et l'ingénierie des grands modèles de langage IA. Pour plus d'évaluations de modèles vidéo et multimodaux, visitez APIYI (apiyi.com).