By 2026, 41% of code commits will be AI-assisted—yet AI-generated code has a defect rate 1.7 times higher than human-written code. While code generation is accelerating, our capacity for code review is falling woefully behind, with a projected 40% quality gap by 2026.
AI-powered code review isn't a question of "if" you should do it, but "how" to do it right. In this article, we’ll walk through 7 proven best practices and dive into why Claude Opus 4.6 and Sonnet 4.6 are currently the top-tier AI models for code review.
Core Value: By the end of this article, you’ll have a complete workflow for AI code review and know exactly how to choose the best model to level up your team's code quality.
The Current State of AI Code Review: Why It’s Now Essential
Challenges in Code Review for 2026
| Challenge | Data | Impact |
|---|---|---|
| Surge in AI-generated code | 41% of commits are AI-assisted | Massive increase in review demand |
| AI code defect rate | 1.7x higher than human code | Stricter reviews required |
| Quality gap | 40% gap projected by 2026 | Review capacity can't keep up with generation speed |
| Security risks | 45% of AI code introduces OWASP Top 10 vulnerabilities | Security reviews are increasingly urgent |
| Suggestion adoption rate | AI suggestions at 16.6%, human at 56.5% | AI review quality needs improvement |
AI Code Review vs. Human Code Review
AI isn't here to replace human reviewers; it's here to augment their capabilities. Teams using AI code review report:
- 40-60% reduction in review time
- Higher defect detection rates—especially for security vulnerabilities and edge cases
- Significant improvement in code style consistency
However, AI review has clear limitations:
- ❌ Cannot understand business deadlines and project context
- ❌ Cannot perceive historical compromises in legacy systems
- ❌ Cannot take final responsibility for the review
- ❌ Cannot facilitate team knowledge transfer or mentorship
🎯 Best Strategy: Let AI handle the first pass (style, bugs, security) and have humans make the final call (architecture, intent, risk). By using the APIYI (apiyi.com) platform to invoke Claude Opus 4.6 or Sonnet 4.6 APIs, you can quickly integrate AI code review into your existing CI/CD pipelines.
7 Best Practices for AI Code Review

Practice 1: Keep Changes Small and Focused
AI reviewers significantly lose coherence after a diff exceeds 1,000 lines. Even though Claude Opus 4.6 has a 1-million-token context window, the quality of review for large changes still lags behind smaller ones.
Best Practices:
- Keep individual PRs within 200-400 lines.
- Break large refactors into multiple, logically independent PRs.
- Ensure each PR does only one thing.
Practice 2: AI First, Human Final Review
The most effective workflow is a "two-layer review" model:
Code Submission → AI Automated Review (First Pass)
↓
Flag issues + categorize by severity
↓
Human reviewer focuses on high-risk areas (Final Review)
↓
Merge or Reject
AI handles scanning for all routine issues (style, naming, dead code, simple bugs), while humans focus on:
- Architectural soundness
- Business logic correctness
- Security-critical decisions
- Performance impact assessment
Practice 3: Provide Sufficient Context
The more information you give the AI reviewer, the higher the quality of the review. We recommend including the following in your PR description:
## Change Intent
Explain "why this change is being made" in 1-2 sentences.
## Verification Method
- [ ] Unit tests passed
- [ ] Manually tested XX scenario
- [ ] No performance regression
## Risk Level
Low/Medium/High + Description
## AI-Assisted Declaration
In this update, the XX section was generated by AI; please prioritize your review of this part.
## Focus Area
Please pay close attention to the permission logic changes in the `src/auth/` directory.
Practice 4: Tiered Review Labeling
A common issue with AI-driven reviews is "too much noise"—mixing stylistic suggestions with critical bugs, which often leads developers to overlook important feedback.
Recommended Severity Labels:
| Label | Meaning | Handling |
|---|---|---|
| 🔴 Bug | Critical defects that must be fixed before merging | Blocks merge |
| 🟡 Nit | Minor issues worth fixing but not blocking | Optional fix |
| 🟣 Pre-existing | Legacy issues not introduced in this PR | Logged but non-blocking |
| 💡 Suggestion | Improvement recommendations | Discussed and decided |
Claude Code's native code review feature has already implemented this tiered system (Red/Yellow/Purple).
Practice 5: Customizing Review Rules
Generic AI reviews might not align with your team's specific standards. You can customize review behavior via a configuration file:
# REVIEW.md (Place in the project root)
## Mandatory Checks
- All database queries must use parameterized statements
- API endpoints must include authentication middleware
- All user input must be validated
You Can Skip These
- CSS class naming conventions (already auto-formatted by Prettier)
- Import sorting (already handled by Ruff)
- Comment language (both English and Chinese are acceptable)
Team Conventions
- Favor composition over inheritance
- Use the Result pattern for error handling
- Log levels: Use INFO for business events, DEBUG for debugging
Practice 6: Integrating into the CI/CD Pipeline
AI code review should be automated, not triggered manually.
Recommended Integration Method:
# GitHub Actions example
name: AI Code Review
on:
pull_request:
types: [opened, synchronize]
jobs:
ai-review:
runs-on: ubuntu-latest
steps:
- uses: anthropics/claude-code-action@v1
with:
anthropic_api_key: ${{ secrets.ANTHROPIC_API_KEY }}
review_mode: "auto"
You can also perform custom reviews by calling the Claude model directly via API:
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # APIYI unified interface
)
diff_content = open("pr_diff.patch").read()
response = client.chat.completions.create(
model="claude-opus-4-6",
messages=[
{"role": "system", "content": """You are a senior code review expert.
Please analyze the following code changes and categorize them by severity:
- 🔴 Bug: Must be fixed
- 🟡 Nit: Recommended fix
- 💡 Suggestion: Improvement suggestion
For each issue, point out the specific line number and provide a fix."""},
{"role": "user", "content": f"Please review the following code changes:\n\n{diff_content}"}
],
max_tokens=8192
)
print(response.choices[0].message.content)
Practice 7: Tracking Review Effectiveness
AI code review doesn't end once it's deployed. You need to track key metrics continuously:
- False Positive Rate: How many of the issues flagged by the AI are actual problems?
- False Negative Rate: How many bugs discovered after deployment were missed by the AI?
- Adoption Rate: The percentage of AI suggestions actually accepted by developers.
- Review Time Change: Has the average review time for human reviewers decreased?
💡 Implementation Tip: If your team is just starting with AI code review, I recommend piloting it on non-critical PRs. Use Claude Sonnet 4.6 via APIYI (apiyi.com) for initial trials; it costs only 1/5 of Opus while providing near-Opus quality, making it the most cost-effective way to get started.
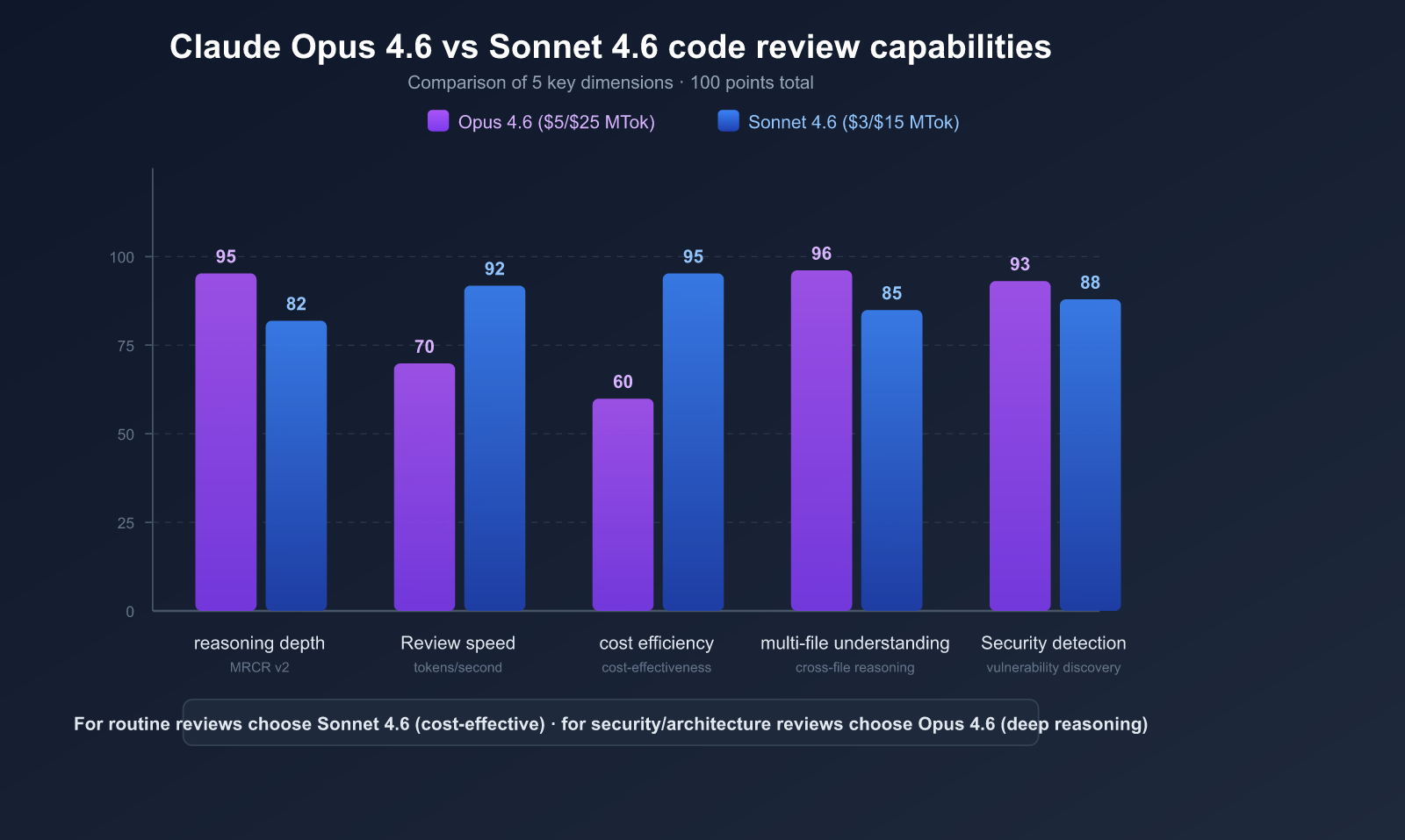
Why We Recommend Claude Opus 4.6 and Sonnet 4.6 for Code Reviews
Among the many AI models available, the Claude 4.6 series stands out with unique advantages for code review scenarios.
Claude 4.6 Model Core Parameter Comparison
| Parameter | Claude Opus 4.6 | Claude Sonnet 4.6 |
|---|---|---|
| Model ID | claude-opus-4-6 |
claude-sonnet-4-6 |
| Release Date | February 5, 2026 | February 17, 2026 |
| Context Window | 1M tokens (beta) | 1M tokens (beta) |
| Max Output | 128K tokens | 64K tokens |
| SWE-bench Verified | 81.42% | 79.6% |
| Pricing (Input/Output) | $5/$25 per million tokens | $3/$15 per million tokens |
| Use Case | Complex architecture review, security audits | Daily PR reviews, style checks |
| APIYI Price | More affordable | More affordable |
Advantage 1: 1 Million Token Context Window
This is the most critical technical advantage for code review.
A single PR in a large project might involve dozens of files. The context window limits of traditional AI models mean you have to truncate code, leaving the reviewer without the full picture.
Claude 4.6's 1 million token context window can accommodate:
- Complete PR diffs (usually hundreds to thousands of lines)
- Full code of related files (import chains, called functions)
- Dependency graphs and type definitions
- Test files and configuration files
- Project README and architecture documentation
This allows the AI to review code like a senior developer, with a full understanding of the project context.
Advantage 2: Top-Tier Cross-File Reasoning
The most valuable part of a code review isn't finding syntax errors, but uncovering cross-file logic issues.
Claude Opus 4.6 scored 76% in the MRCR v2 (Multi-file Retrieval and Reasoning) test, compared to just 18.5% for Sonnet 4.5. This means Opus 4.6 excels in scenarios like:
- Detecting that a file's interface was modified, but the calls in another file weren't updated.
- Finding missing validation in the data flow from the entry point to the database.
- Identifying race conditions in concurrent scenarios.
Real-world case: In testing, Claude Opus 4.6 identified a race condition in a 2400-line database migration PR—a flaw in the rollback logic that only triggers if the migration is interrupted midway. This is a scenario that automated tests often miss.
Advantage 3: Adaptive Thinking Depth
Claude 4.6 introduces an adaptive thinking mode, where the AI automatically decides how "deeply" to think based on the complexity of the problem.
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # APIYI unified interface
)
response = client.chat.completions.create(
model="claude-opus-4-6",
messages=[
{"role": "system", "content": "Review this code change for security issues."},
{"role": "user", "content": diff_content}
],
# Claude 4.6 adaptive thinking: fast for simple tasks, deep for complex ones
extra_body={"thinking": {"type": "adaptive"}}
)
- Simple style issues → Quick judgment, saving tokens.
- Complex concurrency or security issues → Deep reasoning, providing a detailed analysis.
Advantage 4: Security Vulnerability Detection Beyond Traditional Tools
Research shows that Claude-level LLMs significantly outperform traditional static analysis tools in security code reviews:
| Comparison Dimension | Claude (LLM) | CodeQL (Traditional SAST) |
|---|---|---|
| Vulnerabilities Detected | 55 | 27 |
| Zero-day Discovery | 4 | 0 |
| Categories | 10+ (Injection, Auth, Data Leak, Crypto, Logic, etc.) | Pattern matching based |
| Language Support | Any programming language | Language-specific |
| False Positive Filtering | Automatic | Manual filtering required |
Security vulnerability types Claude can detect:
- SQL/Command/LDAP/XPath/NoSQL Injection
- Authentication and Authorization flaws
- Hardcoded keys, sensitive data in logs
- Weak encryption algorithms, improper key management
- Race conditions (TOCTOU)
- Insecure default configurations, CORS
- Deserialization RCE, pickle/eval injection
- XSS (Reflected, Stored, DOM-based)
Advantage 5: Cost Flexibility
Sonnet 4.6 is priced at just 1/5 of Opus 4.6, yet it only trails by 1-2 percentage points on the SWE-bench.
Recommended Selection Strategy:
| Scenario | Recommended Model | Reason |
|---|---|---|
| Daily PR Review | Sonnet 4.6 | Best price-performance, quality close to Opus |
| Security-Critical Code | Opus 4.6 | Deepest reasoning, catches high-risk issues |
| Large Refactoring | Opus 4.6 | Best cross-file reasoning capability |
| Style/Linting | Sonnet 4.6 | Simple tasks don't require Opus |
| CI/CD Automation | Sonnet 4.6 | Controlled costs, suitable for every commit |
🚀 Selection Advice: Anthropic officially suggests "defaulting to Sonnet 4.6, and upgrading to Opus 4.6 only when the deepest reasoning is required." In internal Claude Code tests, developer preference for Sonnet 4.6 was 70% higher than the previous Sonnet 4.5, and even 59% higher than the former flagship, Opus 4.5. You can enjoy more favorable pricing for both models by using APIYI (apiyi.com).
A Complete AI Code Review Workflow
Workflow Overview
Developer submits PR
↓
AI triggers automatic review (Sonnet 4.6)
↓
┌─── Low-risk changes ──→ AI marks as Nit, auto-approves
│
├─── Medium-risk changes ──→ AI flags issues, manual quick confirmation
│
└─── High-risk changes ──→ Escalate to Opus 4.6 for deep review
↓
Manual final review by security expert
↓
Merge or reject
Code Example: Building a Custom AI Review System
import openai
import subprocess
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # APIYI unified interface
)
def get_pr_diff(pr_number):
"""Get the diff content of a PR"""
result = subprocess.run(
["gh", "pr", "diff", str(pr_number)],
capture_output=True, text=True
)
return result.stdout
def review_code(diff, risk_level="medium"):
"""Select a model for review based on risk level"""
model = "claude-opus-4-6" if risk_level == "high" else "claude-sonnet-4-6"
response = client.chat.completions.create(
model=model,
messages=[
{"role": "system", "content": REVIEW_PROMPT},
{"role": "user", "content": f"Review the following changes:\n\n{diff}"}
],
max_tokens=8192
)
return response.choices[0].message.content
# Usage example
diff = get_pr_diff(123)
review = review_code(diff, risk_level="high")
print(review)
View Full Review Prompt Template
REVIEW_PROMPT = """You are an experienced senior software engineer performing a code review.
## Review Focus
1. **Logical Correctness**: Does the code implement the intended functionality? Are there any missed edge cases?
2. **Security**: Are there any security risks such as injection, XSS, CSRF, or hardcoded API keys?
3. **Performance**: Are there N+1 queries, unnecessary memory allocations, or blocking operations?
4. **Maintainability**: Are the names clear? Is the complexity under control? Is there any duplicate code?
5. **Error Handling**: Are exceptions properly caught and handled?
6. **Concurrency Safety**: Are there any race conditions or deadlock risks?
Output Format
Categorize the output by severity:
🔴 Must Fix (Bug/Security)
- [Filename:Line Number] Issue description
- Impact: …
- Suggested fix: …
🟡 Recommended Fix (Nit)
- [Filename:Line Number] Issue description
- Suggestion: …
💡 Improvement Suggestion (Suggestion)
- [Filename:Line Number] Improvement point
- Explanation: …
If the code quality is good and no issues are found, please explicitly state "Review passed, no issues found."
Do not fabricate non-existent issues just to generate output.
💰 Cost Optimization: Use APIYI (apiyi.com) to invoke Claude 3.5 models for code reviews at a more affordable rate than the official pricing. The platform supports flexible switching between Opus and Sonnet models, allowing you to automatically select the most cost-effective model based on the risk level of your PR.
Limitations and Considerations for AI Code Review
5 Limitations You Must Know
- Recall Rate of ~50%: Vulnerabilities identified by LLMs are usually genuine (precision ~80%), but they tend to miss about half of the existing issues.
- Prompt Injection Risk: AI review tools are susceptible to injection attacks when processing untrusted PRs.
- Context Blind Spots: AI cannot grasp the business context, team capabilities, or historical decision-making of a project.
- Cost Accumulation: If you trigger a review for every commit, costs for high-frequency repositories can add up quickly.
- Risk of Over-reliance: Team members might gradually become less rigorous with their own manual reviews.
Mitigation Strategies
| Limitation | Mitigation Strategy |
|---|---|
| High Miss Rate | Combine AI review with manual review for double protection |
| Prompt Injection | Only review PRs from trusted sources |
| Lack of Context | Provide project background in a REVIEW.md file |
| High Costs | Use Sonnet for daily tasks and Opus for critical paths |
| Over-reliance | Establish an "AI suggestions + human decision" policy |
FAQ
Q1: Can AI code review completely replace human review?
No, it can't. AI code review is meant to "augment" rather than "replace" human effort. AI excels at spotting pattern-based issues (like coding style, common bugs, or known vulnerability patterns), but it can't grasp business intent, the trade-offs behind architectural decisions, or the implicit knowledge shared within a team. The best practice is to have AI perform the first pass, with a human making the final judgment. By using Claude 4.6 models via APIYI (apiyi.com), you can quickly set up an AI review workflow that lets human reviewers focus on higher-value tasks.
Q2: Should I choose Opus 4.6 or Sonnet 4.6 for code review?
For most scenarios, go with Sonnet 4.6. It scores only 1-2 percentage points lower than Opus on SWE-bench, but it costs just one-fifth as much. You should only upgrade to Opus 4.6 when dealing with security-critical code, major architectural refactoring, or tasks requiring deep cross-file reasoning. With APIYI (apiyi.com), you can flexibly switch between these two models as needed.
Q3: Roughly how much does AI code review cost?
The native Claude Code review feature averages $15–$25 per run, depending on the PR size and codebase complexity. If you build your own review system via API, the cost depends on your token usage. Taking Sonnet 4.6 as an example, reviewing a 500-line PR (approx. 2,000 input tokens + 1,000 output tokens) costs about $0.02. You can enjoy even better rates through APIYI (apiyi.com).
Q4: How can I evaluate the effectiveness of AI code review?
We recommend tracking four core metrics: (1) False positive rate—the proportion of AI-flagged issues that are actually valid; (2) False negative rate—the proportion of bugs discovered post-deployment that the AI failed to flag; (3) Adoption rate—the percentage of AI suggestions actually accepted by developers; and (4) Review time—whether the average time spent by human reviewers has decreased. It's a good idea to review these metrics weekly for the first two months.
Q5: How can I get started with AI code review quickly?
The easiest way is a three-step process: (1) Register at APIYI (apiyi.com) to get your API key; (2) Run a test review on a recent PR using Sonnet 4.6; (3) Decide whether to integrate it into your CI/CD pipeline based on the results. Start by piloting it on non-critical code paths before rolling it out across the board.
Summary: AI Code Review is a Productivity Multiplier for Teams
AI code review isn't just an option anymore; it's a must-have capability for software development teams in 2026. With a 1-million-token context window, an 81%+ score on SWE-bench, adaptive reasoning, and powerful security detection capabilities, Claude Opus 4.6 and Sonnet 4.6 are currently the top choices for code review.
Selection Advice:
- Daily Reviews: Default to Sonnet 4.6—the king of cost-effectiveness.
- Security/Architectural Reviews: Upgrade to Opus 4.6 for uncompromising reasoning depth.
We recommend using APIYI (apiyi.com) to quickly access the full Claude 4.6 model series and build AI code review capabilities for your team at the best possible cost.
References
-
Anthropic Official: Claude Opus 4.6 and Sonnet 4.6 Release Announcement
- Link:
anthropic.com/news
- Link:
-
Claude Code Code Review Documentation: Guide to using native review features
- Link:
code.claude.com/docs/en/code-review
- Link:
-
Claude Code Security Review: Open-source security review GitHub Action
- Link:
github.com/anthropics/claude-code-security-review
- Link:
-
AI Code Review Best Practices 2026: Comprehensive industry analysis
- Link:
verdent.ai/guides
- Link:
-
IRIS Research Paper: LLM-assisted static analysis for vulnerability detection
- Link:
arxiv.org
- Link:
Author: APIYI Team | Exploring best practices for AI-powered software development. Visit APIYI at apiyi.com for API keys and technical support for the full range of Claude 4.6 models.